はじめに
機械学習で登場する確率分布について色々な角度から理解したいシリーズです。
この記事では、R言語でディリクレ分布からカテゴリ分布と多項分布を生成します。
【前の内容】
【他の記事一覧】
【この記事の内容】
ディリクレ分布から確率分布の生成
ディリクレ分布(Dirichlet Distribution)からカテゴリ分布(Categorical Distribution)と多項分布(Multinomial Distribution)を生成します。各分布についてはそれぞれ「ディリクレ分布の定義式 - からっぽのしょこ」「カテゴリ分布の定義式 - からっぽのしょこ」「多項分布の定義式 - からっぽのしょこ」を参照してください。
利用するパッケージを読み込みます。
# 利用パッケージ library(tidyverse) library(MCMCpack) library(patchwork)
この記事では、基本的にパッケージ名::関数名()の記法を使うので、パッケージを読み込む必要はありません。ただし、作図コードがごちゃごちゃしないようにパッケージ名を省略しているため、ggplot2は読み込む必要があります。
また、patchworkパッケージの演算子を使うため、patchworkも読み込む必要があります。
magrittrパッケージのパイプ演算子%>%ではなく、ベースパイプ(ネイティブパイプ)演算子|>を使っています。%>%に置き換えても処理できます。
三角座標の準備
ディリクレ分布を三角図により可視化するために、三角座標を描画するための準備をします。詳しくは「ggplot2で三角グラフを作図したい - からっぽのしょこ」と「ggplot2で三角グラフの等高線を作図したい - からっぽのしょこ」を参照してください。
・作図用のコード(クリックで展開)
軸目盛の間隔を設定して、三角座標を描画するためのデータフレームを作成します。
# 軸目盛の位置を指定 axis_vals <- seq(from = 0, to = 1, by = 0.1) # 枠線用の値を作成 ternary_axis_df <- tibble::tibble( y_1_start = c(0.5, 0, 1), # 始点のx軸の値 y_2_start = c(0.5*sqrt(3), 0, 0), # 始点のy軸の値 y_1_end = c(0, 1, 0.5), # 終点のx軸の値 y_2_end = c(0, 0, 0.5*sqrt(3)), # 終点のy軸の値 axis = c("x_1", "x_2", "x_3") # 元の軸 ) # グリッド線用の値を作成 ternary_grid_df <- tibble::tibble( y_1_start = c( 0.5 * axis_vals, axis_vals, 0.5 * axis_vals + 0.5 ), # 始点のx軸の値 y_2_start = c( sqrt(3) * 0.5 * axis_vals, rep(0, times = length(axis_vals)), sqrt(3) * 0.5 * (1 - axis_vals) ), # 始点のy軸の値 y_1_end = c( axis_vals, 0.5 * axis_vals + 0.5, 0.5 * rev(axis_vals) ), # 終点のx軸の値 y_2_end = c( rep(0, times = length(axis_vals)), sqrt(3) * 0.5 * (1 - axis_vals), sqrt(3) * 0.5 * rev(axis_vals) ), # 終点のy軸の値 axis = c("x_1", "x_2", "x_3") |> rep(each = length(axis_vals)) # 元の軸 ) # 軸ラベル用の値を作成 ternary_axislabel_df <- tibble::tibble( y_1 = c(0.25, 0.5, 0.75), # x軸の値 y_2 = c(0.25*sqrt(3), 0, 0.25*sqrt(3)), # y軸の値 label = c("phi[1]", "phi[2]", "phi[3]"), # 軸ラベル h = c(3, 0.5, -2), # 水平方向の調整用の値 v = c(0.5, 3, 0.5), # 垂直方向の調整用の値 axis = c("x_1", "x_2", "x_3") # 元の軸 ) # 軸目盛ラベル用の値を作成 ternary_ticklabel_df <- tibble::tibble( y_1 = c( 0.5 * axis_vals, axis_vals, 0.5 * axis_vals + 0.5 ), # x軸の値 y_2 = c( sqrt(3) * 0.5 * axis_vals, rep(0, times = length(axis_vals)), sqrt(3) * 0.5 * (1 - axis_vals) ), # y軸の値 label = c( rev(axis_vals), axis_vals, rev(axis_vals) ), # 軸目盛ラベル h = c( rep(1.5, times = length(axis_vals)), rep(1.5, times = length(axis_vals)), rep(-0.5, times = length(axis_vals)) ), # 水平方向の調整用の値 v = c( rep(0.5, times = length(axis_vals)), rep(0.5, times = length(axis_vals)), rep(0.5, times = length(axis_vals)) ), # 垂直方向の調整用の値 angle = c( rep(-60, times = length(axis_vals)), rep(60, times = length(axis_vals)), rep(0, times = length(axis_vals)) ), # ラベルの表示角度 axis = c("x_1", "x_2", "x_3") |> rep(each = length(axis_vals)) # 元の軸 )
4つのデータフレームを使って以降の作図を行います。
生成分布の設定
パラメータの生成分布としてディリクレ分布を設定して、カテゴリ分布と多項分布のパラメータを生成(サンプリング)します。生成分布を$\mathrm{Dir}(\boldsymbol{\phi}_n | \boldsymbol{\beta})$、生成されたカテゴリ分布を$\mathrm{Cat}(\mathbf{x} | \boldsymbol{\phi}_n)$、多項分布を$\mathrm{Mult}(\mathbf{x} | M, \boldsymbol{\phi}_n)$で表します。ディリクレ分布のグラフ作成については「【R】ディリクレ分布の作図 - からっぽのしょこ」を参照してください。
ディリクレ分布のパラメータ$\boldsymbol{\beta}$とサンプルサイズ$N$を設定します。この例では、三角図で可視化するため、次元数を$V = 3$とします。乱数の生成自体は次元数に関わらず行えます。
# パラメータを指定 beta_v <- c(4, 2, 3) # データ数(サンプルサイズ)を指定 N <- 9
$V$次元ベクトル$\boldsymbol{\beta} = (\beta_1, \beta_2, \beta_3)$、$\beta_v > 0$の値と、分布の数$N$を指定します。
ディリクレ分布に従う乱数を生成します。
# カテゴリ分布・多項分布のパラメータを生成 phi_nv <- MCMCpack::rdirichlet(n = N, alpha = beta_v) head(phi_nv)
## [,1] [,2] [,3] ## [1,] 0.1765590 0.5479360 0.2755049 ## [2,] 0.2530468 0.2235521 0.5234011 ## [3,] 0.4801258 0.2513939 0.2684804 ## [4,] 0.5630276 0.2822568 0.1547156 ## [5,] 0.3821360 0.2625861 0.3552778 ## [6,] 0.4282786 0.0321182 0.5396032
ディリクレ分布の乱数は、MCMCpackパッケージのrdirichlet()で生成できます。データ数の引数nにN、パラメータの引数alphaにbeta_vを指定します。
生成した値(出力されるマトリクスの各行)をカテゴリ分布と多項分布のパラメータのサンプル$\boldsymbol{\phi}_n = (\phi_{n,1}, \phi_{n,2}, \phi_{n,3})$とします。
生成したパラメータ(乱数)をデータフレームに格納します。
# パラメータのサンプルを格納 param_df <- tibble::tibble( phi_1 = phi_nv[, 1], # 元の座標のx軸の値 phi_2 = phi_nv[, 2], # 元の座標のy軸の値 phi_3 = phi_nv[, 3], # 元の座標のz軸の値 y_1 = phi_nv[, 2] + 0.5 * phi_nv[, 3], # 三角座標のx軸の値 y_2 = sqrt(3) * 0.5 * phi_nv[, 3], # 三角座標のy軸の値 phi = paste0("(", apply(round(phi_nv, 2), 1, paste0, collapse = ", "), ")") # 色分け用ラベル ) |> dplyr::arrange(-round(phi_3, 1), round(phi_2, 1), -round(phi_1, 1)) |> # グラフの配置調整用に並べ替え dplyr::mutate( phi = factor(phi, levels = phi) # 色分け用ラベル ) param_df
## # A tibble: 9 × 6 ## phi_1 phi_2 phi_3 y_1 y_2 phi ## <dbl> <dbl> <dbl> <dbl> <dbl> <fct> ## 1 0.428 0.0321 0.540 0.302 0.467 (0.43, 0.03, 0.54) ## 2 0.253 0.224 0.523 0.485 0.453 (0.25, 0.22, 0.52) ## 3 0.530 0.119 0.351 0.295 0.304 (0.53, 0.12, 0.35) ## 4 0.382 0.263 0.355 0.440 0.308 (0.38, 0.26, 0.36) ## 5 0.480 0.251 0.268 0.386 0.233 (0.48, 0.25, 0.27) ## 6 0.177 0.548 0.276 0.686 0.239 (0.18, 0.55, 0.28) ## 7 0.563 0.282 0.155 0.360 0.134 (0.56, 0.28, 0.15) ## 8 0.866 0.0632 0.0710 0.0987 0.0615 (0.87, 0.06, 0.07) ## 9 0.562 0.302 0.136 0.370 0.118 (0.56, 0.3, 0.14)
サンプルごとに、2次元座標におけるx軸($y_1$軸)の値$y_{n,1} = \phi_{n,2} + \frac{\phi_{n,3}}{2}$、y軸($y_2$軸)の値$y_{n,2} = \frac{\sqrt{3} \phi_{n,3}}{2}$に変換して、データフレームに格納します。
グラフを分割して描画する際にx軸の値が小さい順に並ぶように、行を並べ替えてラベル列を作成します。
作図用と計算用のディリクレ分布の確率変数の値$\boldsymbol{\phi}$を作成して、確率密度を計算します。
# 三角座標の値を作成 y_1_vals <- seq(from = 0, to = 1, length.out = 301) y_2_vals <- seq(from = 0, to = 0.5*sqrt(3), length.out = 300) # 格子点を作成 y_mat <- tidyr::expand_grid( y_1 = y_1_vals, y_2 = y_2_vals ) |> # 格子点を作成 as.matrix() # マトリクスに変換 # 3次元変数に変換 phi_mat <- tibble::tibble( phi_2 = y_mat[, 1] - y_mat[, 2] / sqrt(3), phi_3 = 2 * y_mat[, 2] / sqrt(3) ) |> # 元の座標に変換 dplyr::mutate( phi_2 = dplyr::if_else(phi_2 >= 0 & phi_2 <= 1, true = phi_2, false = as.numeric(NA)), phi_3 = dplyr::if_else(phi_3 >= 0 & phi_3 <= 1 & !is.na(phi_2), true = phi_3, false = as.numeric(NA)), phi_1 = 1 - phi_2 - phi_3, phi_1 = dplyr::if_else(phi_1 >= 0 & phi_1 <= 1, true = phi_1, false = as.numeric(NA)) ) |> # 範囲外の値をNAに置換 dplyr::select(phi_1, phi_2, phi_3) |> # 順番を変更 as.matrix() # マトリクスに変換 # ディリクレ分布を計算 dir_df <- tibble::tibble( y_1 = y_mat[, 1], # x軸の値 y_2 = y_mat[, 2], # y軸の値 density = MCMCpack::ddirichlet(x = phi_mat, alpha = beta_v), # 確率密度 ) |> dplyr::mutate( fill_flg = !is.na(rowSums(phi_mat)), density = dplyr::if_else(fill_flg, true = density, false = as.numeric(NA)) ) # 範囲外の値をNAに置換 dir_df
## # A tibble: 90,300 × 4 ## y_1 y_2 density fill_flg ## <dbl> <dbl> <dbl> <lgl> ## 1 0 0 0 TRUE ## 2 0 0.00290 NA FALSE ## 3 0 0.00579 NA FALSE ## 4 0 0.00869 NA FALSE ## 5 0 0.0116 NA FALSE ## 6 0 0.0145 NA FALSE ## 7 0 0.0174 NA FALSE ## 8 0 0.0203 NA FALSE ## 9 0 0.0232 NA FALSE ## 10 0 0.0261 NA FALSE ## # … with 90,290 more rows
三角座標を含めた2次元座標上の格子点を作成してy_matとします。
y_matを3次元座標上の点($\boldsymbol{\phi}$の点)に変換してphi_matとします。ただし、三角座標外の点については、総和が1の値($\boldsymbol{\phi}$を満たす値)にならないので欠損値NAに置き換えます。
ディリクレ分布の確率密度は、MCMCpackパッケージのddirichlet()で計算できます。確率変数の引数xにphi_mat、パラメータの引数alphaにbeta_vを指定します。
作図用の値y_matと、計算用の値x_matにより求めた確率密度をデータフレームに格納します。ただし、三角座標外の要素(phi_matの欠損値を含む行)については欠損値NAに置き換えます。
ディリクレ分布の期待値$\mathbb{E}[\boldsymbol{\phi}]$を計算します。
# パラメータの期待値を計算 E_phi_v <- beta_v / sum(beta_v) E_phi_v
## [1] 0.4444444 0.2222222 0.3333333
$\boldsymbol{\phi}$の期待値$\mathbb{E}[\boldsymbol{\phi}] = \frac{\boldsymbol{\beta}}{\sum_{v=1}^V \phi_v}$をE_phi_dとします。
これは、サンプリングされたパラメータとその分布の基準を示すのに使います。
パラメータの期待値$\mathbb{E}[\boldsymbol{\phi}]$をデータフレームに格納します。
# パラメータの期待値を格納 E_param_df <- tibble::tibble( y_1 = E_phi_v[2] + 0.5 * E_phi_v[3], # 三角座標のx軸の値 y_2 = sqrt(3) * 0.5 * E_phi_v[3] # 三角座標のy軸の値 ) E_param_df
## # A tibble: 1 × 2 ## y_1 y_2 ## <dbl> <dbl> ## 1 0.389 0.289
三角座標に変換して格納します。
パラメータの期待値$\mathbb{E}[\boldsymbol{\phi}]$で交わるグリッド線を作成します。
# 期待値のグリッド線用の値を作成 E_grid_df <- tibble::tibble( y_1_start = c( 0.5 * (1 - E_phi_v[1]), E_phi_v[2], 0.5 * (1 - E_phi_v[3]) + 0.5 ), # 始点のx軸の値 y_2_start = c( sqrt(3) * 0.5 * (1 - E_phi_v[1]), 0, sqrt(3) * 0.5 * E_phi_v[3] ), # 始点のy軸の値 y_1_end = c( 1 - E_phi_v[1], 0.5 * E_phi_v[2] + 0.5, 0.5 * E_phi_v[3] ), # 終点のx軸の値 y_2_end = c( 0, sqrt(3) * 0.5 * (1 - E_phi_v[2]), sqrt(3) * 0.5 * E_phi_v[3] ), # 終点のy軸の値 axis = c("x_1", "x_2", "x_3") # 色分け用ラベル ) E_grid_df
## # A tibble: 3 × 5 ## y_1_start y_2_start y_1_end y_2_end axis ## <dbl> <dbl> <dbl> <dbl> <chr> ## 1 0.278 0.481 0.556 0 x_1 ## 2 0.222 0 0.611 0.674 x_2 ## 3 0.833 0.289 0.167 0.289 x_3
期待値の各要素(成分)ごとに軸線を引くための値を用意します。詳しくは「三角座標の準備」を参照してください。
生成分布(ディリクレ分布)とパラメータのサンプルを描画します。
# パラメータラベル用の文字列を作成 dir_param_text <- paste0( "beta==(list(", paste0(beta_v, collapse = ", "), "))" ) # サンプルの散布図を作成 dir_graph <- ggplot() + geom_segment(data = ternary_axis_df, mapping = aes(x = y_1_start, y = y_2_start, xend = y_1_end, yend = y_2_end), color = "gray50") + # 三角図の枠線 geom_segment(data = ternary_grid_df, mapping = aes(x = y_1_start, y = y_2_start, xend = y_1_end, yend = y_2_end), color = "gray50", linetype = "dashed") + # 三角図のグリッド線 geom_text(data = ternary_ticklabel_df, mapping = aes(x = y_1, y = y_2, label = label, hjust = h, vjust = v, angle = angle)) + # 三角図の軸目盛ラベル geom_text(data = ternary_axislabel_df, mapping = aes(x = y_1, y = y_2, label = label, hjust = h, vjust = v), parse = TRUE, size = 6) + # 三角図の軸ラベル geom_contour_filled(data = dir_df, mapping = aes(x = y_1, y = y_2, z = density, fill = ..level..), alpha = 0.8) + # パラメータの生成分布 geom_segment(data = E_grid_df, mapping = aes(x = y_1_start, y = y_2_start, xend = y_1_end, yend = y_2_end, linetype = axis), color = c("red", "green4", "blue"), size = 1) + # パラメータの期待値のグリッド線 scale_linetype_manual(breaks = c("x_1", "x_2", "x_3"), values = c("dashed", "dashed", "dashed"), labels = c(expression(phi[1]), expression(phi[2]), expression(phi[3])), name = "axis") + guides(linetype = guide_legend(override.aes = list(color = c("red", "green4", "blue"), size = 0.5))) + # 凡例の体裁 geom_point(data = E_param_df, mapping = aes(x = y_1, y = y_2), color = "hotpink", size = 5, shape = 4, stroke = 2) + # パラメータの期待値 geom_point(data = param_df, mapping = aes(x = y_1, y = y_2, color = phi), alpha = 0.8, size = 5) + # パラメータのサンプル coord_fixed(ratio = 1, clip = "off") + # アスペクト比 scale_x_continuous(breaks = c(0, 0.5, 1), labels = NULL) + # x軸の体裁 scale_y_continuous(breaks = c(0, 0.25*sqrt(3), 0.5*sqrt(3)), labels = NULL) + # y軸の体裁 theme(axis.ticks = element_blank(), panel.grid.minor = element_blank()) + # 図の体裁 labs(title = "Dirichlet Distribution", subtitle = parse(text = dir_param_text), color = expression(phi), fill = "density", x = "", y = "") dir_graph
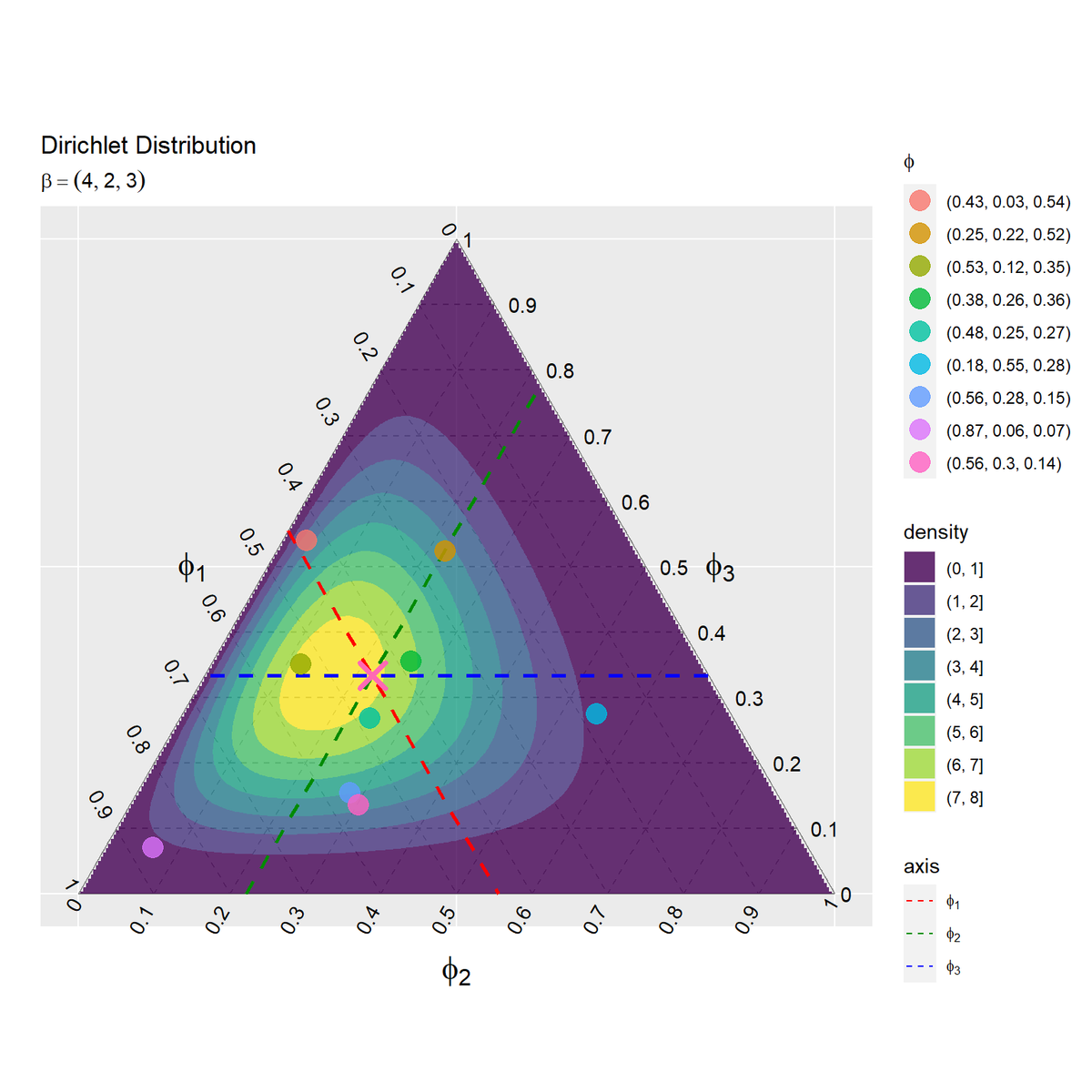
期待値をバツ印、さらに各要素の値を破線で示します。
以上で、生成分布を設定して、パラメータを生成しました。次は、パラメータのサンプルを用いて、カテゴリ分布と多項分布を作図します。
分布の作図:カテゴリ分布
生成した値をカテゴリ分布のパラメータとして利用します。カテゴリ分布のグラフ作成については「【R】カテゴリ分布の作図 - からっぽのしょこ」を参照してください。
生成分布の期待値(カテゴリ分布のパラメータの期待値)を用いて、カテゴリ分布の確率を計算します。
# パラメータの期待値によるカテゴリ分布を計算 E_cat_df <- tibble::tibble( v = 1:3, # 次元番号 probability = E_phi_v, # 確率 axis = c("x_1", "x_2", "x_3") # 色分け用ラベル ) E_cat_df
## # A tibble: 3 × 3 ## v probability axis ## <int> <dbl> <chr> ## 1 1 0.444 x_1 ## 2 2 0.222 x_2 ## 3 3 0.333 x_3
カテゴリ分布の確率は、パラメータの値です。
パラメータのサンプルごとにカテゴリ分布を計算します。
# パラメータのサンプルごとにカテゴリ分布を計算 res_cat_df <- tidyr::expand_grid( n = 1:N, # サンプル番号 v = 1:3 # 次元番号 ) |> # サンプルごとに次元番号を複製 dplyr::group_by(n) |> # 確率の計算用に dplyr::mutate( probability = phi_nv[unique(n), ] |> as.vector(), # 確率 phi = paste0("(", paste0(round(phi_nv[unique(n), ], 2), collapse = ", "), ")") |> factor(levels = levels(param_df[["phi"]])) # 色分け用ラベル ) |> dplyr::ungroup() # グループ化を解除 res_cat_df
## # A tibble: 27 × 4 ## n v probability phi ## <int> <int> <dbl> <fct> ## 1 1 1 0.177 (0.18, 0.55, 0.28) ## 2 1 2 0.548 (0.18, 0.55, 0.28) ## 3 1 3 0.276 (0.18, 0.55, 0.28) ## 4 2 1 0.253 (0.25, 0.22, 0.52) ## 5 2 2 0.224 (0.25, 0.22, 0.52) ## 6 2 3 0.523 (0.25, 0.22, 0.52) ## 7 3 1 0.480 (0.48, 0.25, 0.27) ## 8 3 2 0.251 (0.48, 0.25, 0.27) ## 9 3 3 0.268 (0.48, 0.25, 0.27) ## 10 4 1 0.563 (0.56, 0.28, 0.15) ## # … with 17 more rows
パラメータ番号を表す1からNの整数と確率変数の次元番号を表す1から3($V$)の整数の全ての組み合わせをexpand_grid()を作成します。これにより、サンプルごとに1:3を複製できます。
パラメータ列nでグループ化することで、1:3ごとに確率を格納できます。
param_dfと対応するようにラベル列を作成します。
N個のカテゴリ分布のグラフを分割して描画します。
# パラメータラベル用の文字列を作成 cat_param_text <- paste0( "E(phi)==(list(", paste0(round(E_phi_v, 2), collapse = ", "), "))" ) # サンプルによるカテゴリ分布を作図 cat_graph <- ggplot() + geom_bar(data = E_cat_df, mapping = aes(x = v, y = probability, color = axis), stat = "identity", alpha = 0, size = 1, linetype ="dashed", show.legend = FALSE) + # 期待値による分布 geom_bar(data = res_cat_df, mapping = aes(x = v, y = probability, fill = phi), stat = "identity", alpha = 0.8, show.legend = FALSE) + # サンプルによる分布 facet_wrap(. ~ phi, labeller = label_bquote(phi==.(as.character(phi)))) + # グラフの分割 scale_color_manual(breaks = c("x_1", "x_2", "x_3"), values = c("red", "green4", "blue")) + # 各次元の期待値の色 labs(title = "Categorical Distribution", subtitle = parse(text = cat_param_text), fill = expression(phi), x = "v", y = "probability") cat_graph

facet_wrap()に列を指定すると、その列の値ごとにグラフを分割して描画できます。
期待値による分布を破線で重ねて描画します。
パラメータの生成分布(ディリクレ分布)と生成された分布(カテゴリ分布)を並べて描画します。
# グラフを並べて描画 dir_graph + cat_graph + patchwork::plot_layout(guides = "collect")
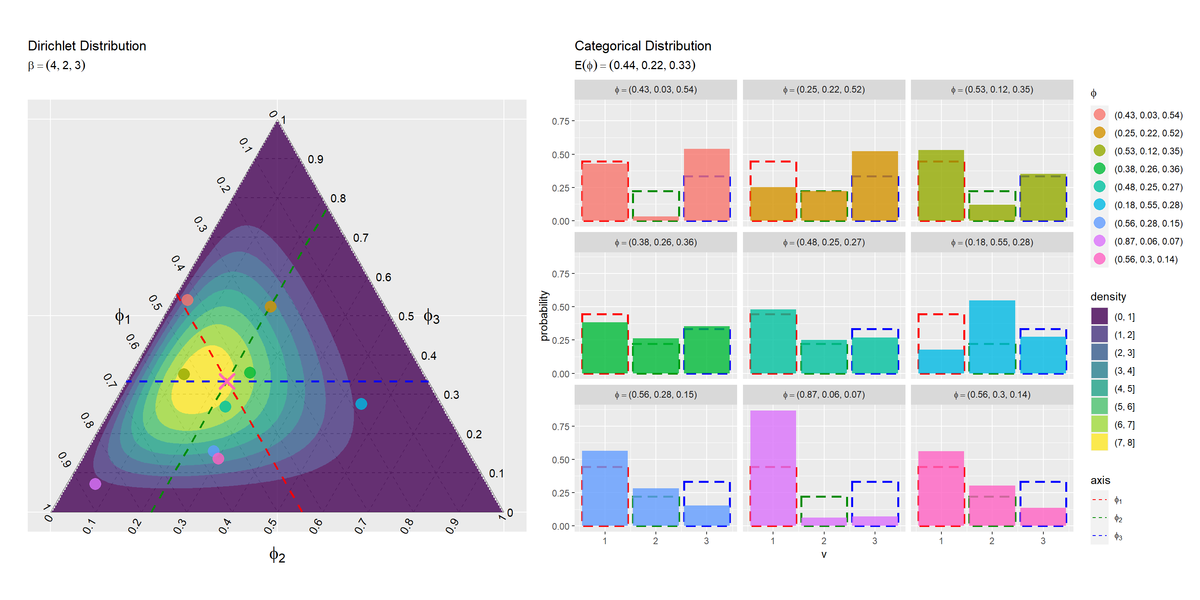
patchworkパッケージの+演算子を使うと左右に並べて描画できます。
左図においてパラメータの点が赤色の破線よりも左にあれば$\phi_{n,1} > \mathbb{E}[\phi_1]$であり、右図の対応する分布の1つ目のバーが破線のバーよりも高くなります。同様に、緑色の破線よりも右であれば$\phi_{n,2} > \mathbb{E}[\phi_2]$であり2つ目のバーが破線より高く、青色の破線よりも上であれば$\phi_{n,3} > \mathbb{E}[\phi_3]$であり3つ目のバーが破線より高くなります。
分布の作図:多項分布
続いて、生成した値を多項分布のパラメータとして利用します。多項分布のグラフ作成については「【R】多項分布の作図 - からっぽのしょこ」を参照してください。
多項分布の試行回数$M$を設定します。
# 試行回数を指定 M <- 10
整数$M$を指定します。
設定したパラメータに応じて、多項分布の確率変数の値$\mathbf{x}$を作成して、生成分布の期待値(多項分布のパラメータの期待値)を用いて多項分布の確率を計算します。
# xがとり得る値を作成 x_vals <- 0:M |> as.numeric() # 作図用のxの点を作成 x_mat <- tidyr::expand_grid( x_1 = x_vals, # x軸の値 x_2 = x_vals, # y軸の値 x_3 = x_vals # z軸の値 ) |> # 格子点を作成 as.matrix() # マトリクスに変換 # パラメータの期待値による多項分布を計算 E_mult_df <- tibble::tibble( i = 1:nrow(x_mat), # 点番号 x_1 = x_mat[, 1], # x軸の値 x_2 = x_mat[, 2], # y軸の値 x_3 = x_mat[, 3] # z軸の値 ) |> dplyr::filter(x_1+x_2+x_3 == M) |> # 範囲外の点を除去 dplyr::group_by(i) |> # 確率の計算用にグループ化 dplyr::mutate( probability = dmultinom(x = x_mat[i, ], size = M, prob = E_phi_v) # 確率 ) |> dplyr::ungroup() # グループ化を解除 E_mult_df
## # A tibble: 66 × 5 ## i x_1 x_2 x_3 probability ## <int> <dbl> <dbl> <dbl> <dbl> ## 1 11 0 0 10 0.0000169 ## 2 21 0 1 9 0.000113 ## 3 31 0 2 8 0.000339 ## 4 41 0 3 7 0.000602 ## 5 51 0 4 6 0.000702 ## 6 61 0 5 5 0.000562 ## 7 71 0 6 4 0.000312 ## 8 81 0 7 3 0.000119 ## 9 91 0 8 2 0.0000297 ## 10 101 0 9 1 0.00000441 ## # … with 56 more rows
カテゴリ分布の確率は、dmultinom()で計算できます。確率変数の引数xにx_matの値、試行回数の引数sizeにM、パラメータの引数probにE_phi_vを指定します。
パラメータのサンプルごとに多項分布を計算します。
# パラメータのサンプルごとに多項分布を計算 res_mult_df <- tidyr::expand_grid( n = 1:N, # パラメータ番号 i = 1:nrow(x_mat), # 点番号 ) |> # サンプルごとに格子点を複製 dplyr::mutate( x_1 = x_mat[i, 1], # x軸の値 x_2 = x_mat[i, 2], # y軸の値 x_3 = x_mat[i, 3] # z軸の値 ) |> dplyr::filter(x_1+x_2+x_3 == M) |> # 範囲外の非表示化用のフラグ dplyr::group_by(n, i) |> # 確率の計算用にグループ化 dplyr::mutate( probability = dmultinom(x = x_mat[i, ], size = M, prob = phi_nv[n, ]), # 確率 phi = paste0("(", paste0(round(phi_nv[n, ], 2), collapse = ", "), ")") |> factor(levels = levels(param_df[["phi"]])) # 色分け用ラベル ) |> dplyr::ungroup() # グループ化を解除 res_mult_df
## # A tibble: 594 × 7 ## n i x_1 x_2 x_3 probability phi ## <int> <int> <dbl> <dbl> <dbl> <dbl> <fct> ## 1 1 11 0 0 10 0.00000252 (0.18, 0.55, 0.28) ## 2 1 21 0 1 9 0.0000501 (0.18, 0.55, 0.28) ## 3 1 31 0 2 8 0.000448 (0.18, 0.55, 0.28) ## 4 1 41 0 3 7 0.00238 (0.18, 0.55, 0.28) ## 5 1 51 0 4 6 0.00828 (0.18, 0.55, 0.28) ## 6 1 61 0 5 5 0.0198 (0.18, 0.55, 0.28) ## 7 1 71 0 6 4 0.0327 (0.18, 0.55, 0.28) ## 8 1 81 0 7 3 0.0372 (0.18, 0.55, 0.28) ## 9 1 91 0 8 2 0.0278 (0.18, 0.55, 0.28) ## 10 1 101 0 9 1 0.0123 (0.18, 0.55, 0.28) ## # … with 584 more rows
パラメータ番号を表す1からNの整数と確率変数の点番号を表す1からx_matの行数の整数の全ての組み合わせをexpand_grid()を作成します。これにより、サンプルごとにx_matを複製できます。
パラメータ列nとデータ点番号列iでグループ化することで、x_matの行ごとに確率を計算できます。
param_dfと対応するようにラベル列を作成します。
パラメータの期待値による多項分布を描画します。
# パラメータラベル用の文字列を作成 mult_param_text <- paste0( "list(", "E(phi)==(list(", paste0(round(E_phi_v, 2), collapse = ", "), "))", ", M==", M, ")" ) # 期待値による多項分布のグラフを作成 E_mult_graph <- ggplot() + # データ geom_tile(data = E_mult_df, mapping = aes(x = x_2, y = x_3, fill = probability, alpha = fill_flg), alpha = 0.8) + # 期待値による分布 geom_point(mapping = aes(x = M*E_phi_v[2], y = M*E_phi_v[3]), color = "hotpink", size = 5, shape = 4, stroke = 2) + # パラメータの期待値 scale_fill_gradientn(colors = c("blue", "green", "yellow", "red")) + # グラデーション coord_fixed(ratio = 1) + # アスペクト比 scale_x_continuous(breaks = 0:M) + # x軸目盛 scale_y_continuous(breaks = 0:M) + # y軸目盛 theme(panel.grid.minor = element_blank()) + # 図の体裁 labs(title = "Multinomial Distribution", subtitle = parse(text = mult_param_text), fill = "probability", x = expression(x[2]), y = expression(x[3])) E_mult_graph

geom_tile()でヒートマップを描画します。$x_1$をx軸、$x_2$をy軸とする方が自然ですが、生成分布のグラフ(におけるパラメータの点)との対応関係が分かりやすいように、$x_2$をx軸、$x_3$をy軸として作図します。
N個の多項分布のグラフを分割して描画します。
# サンプルによる多項分布のグラフを作成 res_mult_graph <- ggplot() + # データ geom_tile(data = res_mult_df, mapping = aes(x = x_2, y = x_3, fill = probability)) + # サンプルによる分布 geom_point(data = param_df, mapping = aes(x = M*phi_2, y = M*phi_3, color = phi), alpha = 0.8, size = 5, shape = 4, stroke = 2, show.legend = FALSE) + # サンプルによる分布の期待値 scale_fill_gradientn(colors = c("blue", "green", "yellow", "red")) + # グラデーション scale_x_continuous(breaks = 0:M, labels = 0:M) + # x軸目盛 scale_y_continuous(breaks = 0:M, labels = 0:M) + # y軸目盛 coord_fixed(ratio = 1) + # アスペクト比 facet_wrap(. ~ phi, nrow = 2, labeller = label_bquote(phi==.(as.character(phi)))) + # グラフを分割 theme(panel.grid.minor = element_blank()) + # 図の体裁 labs(title = "Multinomial Distribution", subtitle = parse(text = paste0("M==", M)), color = expression(phi), fill = "probability", x = expression(x[2]), y = expression(x[3])) res_mult_graph
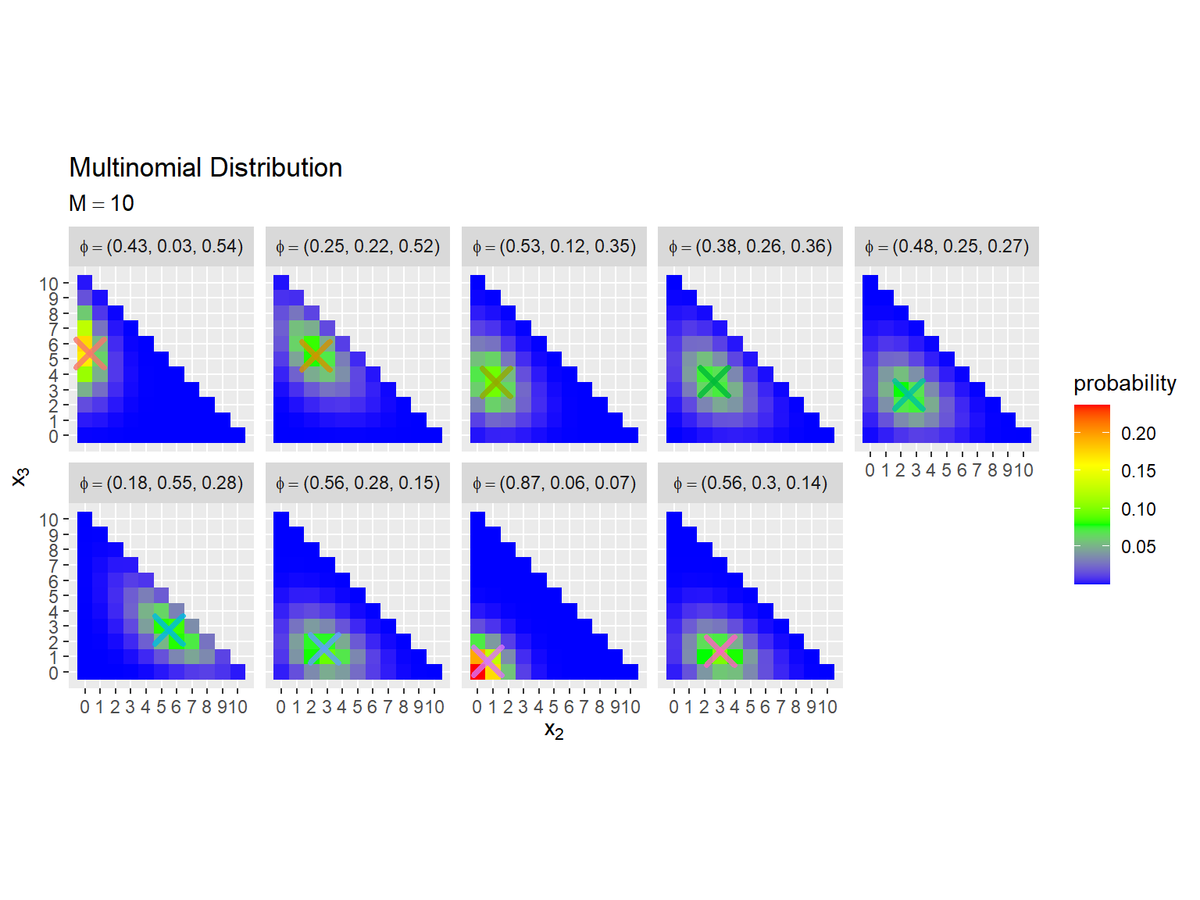
facet_wrap()に列を指定すると、その列の値ごとにグラフを分割して描画できます。
期待値による分布を破線で重ねて描画します。
生成分布(ディリクレ分布)と期待値による分布・生成された分布(多項分布)を並べて描画します。
# グラフを並べて描画 (dir_graph + E_mult_graph) / res_mult_graph
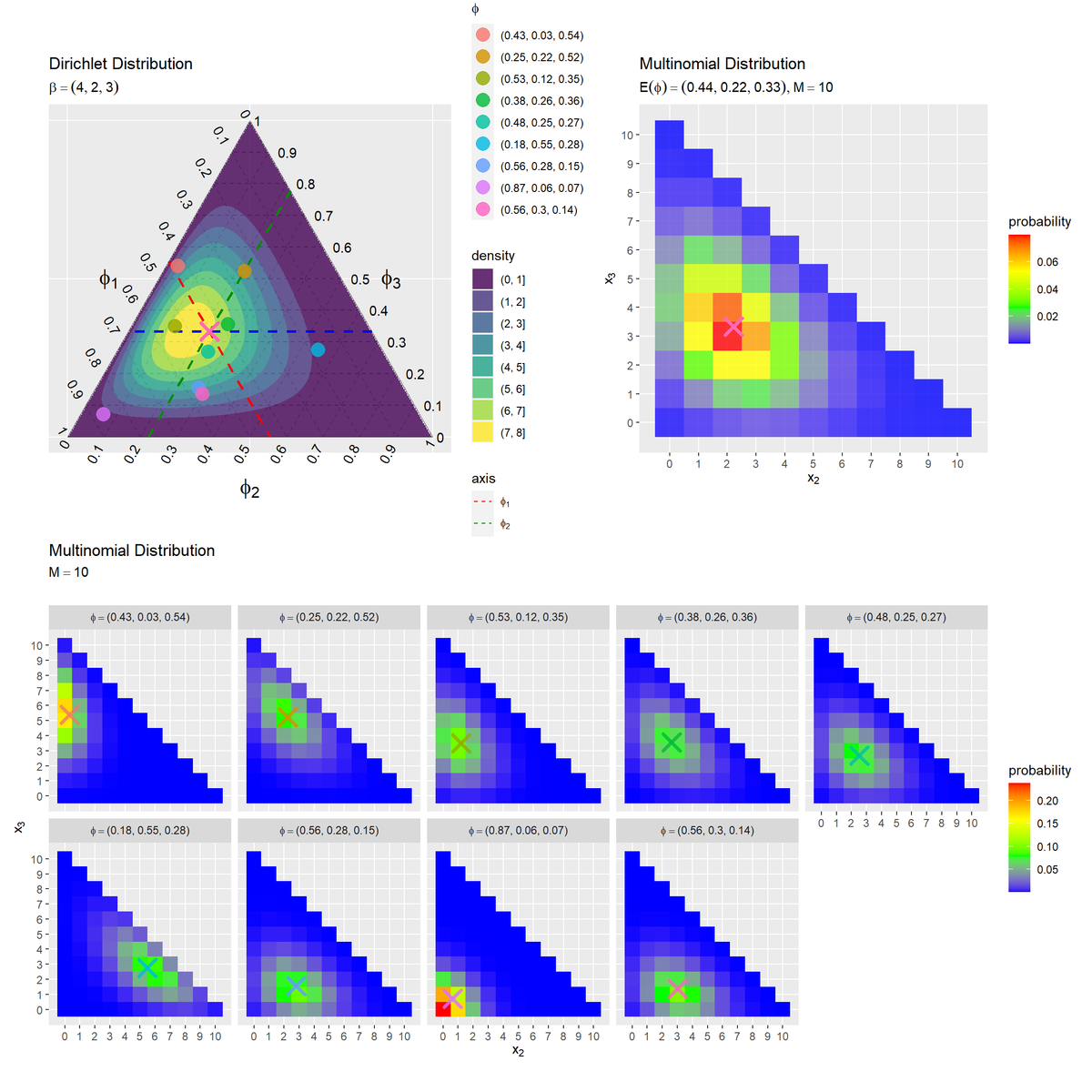
patchworkパッケージの+を使うと左右、/演算子を使うと上下に並べて描画できます。
左図において$\phi_{n,1}$が大きいほどパラメータの点が左下に近くなり、右図の対応する分布のピーク(赤色や黄色のタイル)や期待値(バツ印)が左下に近付きます。これは$x_1$が大きい($x_2, x_3$が小さい)ほど確率が高くなることを表します。同様に、$\phi_{n,2}$が大きい(点が右下に近い)ほど$x_2$が大きいほど確率が高く(ピークが右下に近く)、$\phi_{n,3}$が大きい(点が上に近い)ほど$x_3$が大きいほど確率が高く(ピークが左上に近く)なります。
参考文献
- 岩田具治『トピックモデル』(機械学習プロフェッショナルシリーズ)講談社,2015年.
おわりに
割りと上手く可視化できたのではないでしょうか。自分ではとても満足しています。
10月10日はJuice=Juiceの日!ということで先ほどアップされたMVを観ましょう♬
世界一可愛い喧嘩なのでは。
【次の内容】