はじめに
機械学習で登場する確率分布について色々な角度から理解したいシリーズです。
この記事では、R言語でディリクレ分布のグラフを作成します。
【前の内容】
【他の記事一覧】
【この記事の内容】
ディリクレ分布の作図
ディリクレ分布(Dirichlet Distribution)のグラフを作成します。ディリクレ分布については「ディリクレ分布の定義式 - からっぽのしょこ」を参照してください。
利用するパッケージを読み込みます。
# 利用するパッケージ library(tidyverse) library(MCMCpack) library(gganimate)
この記事では、基本的にパッケージ名::関数名()の記法を使うので、パッケージを読み込む必要はありません。ただし、作図コードがごちゃごちゃしないようにパッケージ名を省略しているため、ggplot2は読み込む必要があります。
magrittrパッケージのパイプ演算子%>%ではなく、ベースパイプ(ネイティブパイプ)演算子|>を使っています。%>%に置き換えても処理できます。
分布の変化をアニメーション(gif画像)で確認するのにgganimateパッケージを利用します。不要であれば省略してください。
定義式の確認
まずは、ディリクレ分布の定義式を確認します。
ディリクレ分布は、次の式で定義されます。
ここで、$V$は次元数で、$\boldsymbol{\beta} = (\beta_1, \beta_2, \cdots, \beta_V)$はパラメータです。$\beta_v > 0$を満たす必要があります。確率変数の実現値$\boldsymbol{\phi} = (\phi_1, \phi_2, \cdots, \phi_V)$は、$0 < \phi_v < 1$、$\sum_{v=1}^V \phi_v = 1$となります。
ディリクレ分布は、総和が1となる非負の$V$次元ベクトルを生成することから、カテゴリ分布と多項分布のパラメータ(出現確率)の生成分布や事前分布として利用されます。
ベータ分布の期待値は、次の式で計算できます。詳しくは「統計量の導出」を参照してください。
これらの計算を行いグラフを作成します。
三角座標の準備
ディリクレ分布を三角図により可視化するために、三角座標を描画するための準備をします。詳しくは「ggplot2で三角グラフを作図したい - からっぽのしょこ」と「ggplot2で三角グラフの等高線を作図したい - からっぽのしょこ」を参照してください。
・作図用のコード(クリックで展開)
軸目盛の間隔を設定して、三角座標を描画するためのデータフレームを作成します。
# 軸目盛の位置を指定 axis_vals <- seq(from = 0, to = 1, by = 0.1) # 枠線用の値を作成 ternary_axis_df <- tibble::tibble( y_1_start = c(0.5, 0, 1), # 始点のx軸の値 y_2_start = c(0.5*sqrt(3), 0, 0), # 始点のy軸の値 y_1_end = c(0, 1, 0.5), # 終点のx軸の値 y_2_end = c(0, 0, 0.5*sqrt(3)), # 終点のy軸の値 axis = c("x_1", "x_2", "x_3") # 元の軸 ) # グリッド線用の値を作成 ternary_grid_df <- tibble::tibble( y_1_start = c( 0.5 * axis_vals, axis_vals, 0.5 * axis_vals + 0.5 ), # 始点のx軸の値 y_2_start = c( sqrt(3) * 0.5 * axis_vals, rep(0, times = length(axis_vals)), sqrt(3) * 0.5 * (1 - axis_vals) ), # 始点のy軸の値 y_1_end = c( axis_vals, 0.5 * axis_vals + 0.5, 0.5 * rev(axis_vals) ), # 終点のx軸の値 y_2_end = c( rep(0, times = length(axis_vals)), sqrt(3) * 0.5 * (1 - axis_vals), sqrt(3) * 0.5 * rev(axis_vals) ), # 終点のy軸の値 axis = c("x_1", "x_2", "x_3") |> rep(each = length(axis_vals)) # 元の軸 ) # 軸ラベル用の値を作成 ternary_axislabel_df <- tibble::tibble( y_1 = c(0.25, 0.5, 0.75), # x軸の値 y_2 = c(0.25*sqrt(3), 0, 0.25*sqrt(3)), # y軸の値 label = c("phi[1]", "phi[2]", "phi[3]"), # 軸ラベル h = c(3, 0.5, -2), # 水平方向の調整用の値 v = c(0.5, 3, 0.5), # 垂直方向の調整用の値 axis = c("x_1", "x_2", "x_3") # 元の軸 ) # 軸目盛ラベル用の値を作成 ternary_ticklabel_df <- tibble::tibble( y_1 = c( 0.5 * axis_vals, axis_vals, 0.5 * axis_vals + 0.5 ), # x軸の値 y_2 = c( sqrt(3) * 0.5 * axis_vals, rep(0, times = length(axis_vals)), sqrt(3) * 0.5 * (1 - axis_vals) ), # y軸の値 label = c( rev(axis_vals), axis_vals, rev(axis_vals) ), # 軸目盛ラベル h = c( rep(1.5, times = length(axis_vals)), rep(1.5, times = length(axis_vals)), rep(-0.5, times = length(axis_vals)) ), # 水平方向の調整用の値 v = c( rep(0.5, times = length(axis_vals)), rep(0.5, times = length(axis_vals)), rep(0.5, times = length(axis_vals)) ), # 垂直方向の調整用の値 angle = c( rep(-60, times = length(axis_vals)), rep(60, times = length(axis_vals)), rep(0, times = length(axis_vals)) ), # ラベルの表示角度 axis = c("x_1", "x_2", "x_3") |> rep(each = length(axis_vals)) # 元の軸 )
4つのデータフレームを使って以降の作図を行います。
グラフの作成
ggplot2パッケージを利用して、ディリクレ分布のグラフを作成します。ディリクレ分布の確率密度の計算については「【R】ディリクレ分布の計算 - からっぽのしょこ」を参照してください。
パラメータの設定
ディリクレ分布のパラメータ$\boldsymbol{\beta}$を設定します。この例では、三角図で描画するため、次元数を$V = 3$とします。
# パラメータを指定 beta_v <- c(4, 2, 3)
$V$次元ベクトル$\boldsymbol{\beta} = (\beta_1, \beta_2, \beta_3)$、$\beta_v > 0$の値を指定します。
2つの処理方法でグラフを作成します。
散布図によるヒートマップ
1つ目の方法は、散布図によって簡易的にヒートマップを作成します。こちらの方が直感的に処理できます。
ディリクレ分布の確率変数がとり得る値$\boldsymbol{\phi}$の各要素$\phi_v$の値を作成します。
# Φがとり得る値を作成 phi_vals <- seq(from = 0, to = 1, length.out = 51) head(phi_vals)
## [1] 0.00 0.02 0.04 0.06 0.08 0.10
$0 < \phi_v < 1$の値をphi_valsとします。グラフが粗い場合や処理が重い場合は、phi_valsの間隔(by引数)や要素数(length.out引数)を調整してください。
$\boldsymbol{\phi}$の値を作成します。
# Φがとり得る点を作成 phi_scatter_mat <- tidyr::expand_grid( phi_1 = phi_vals, phi_2 = phi_vals, phi_3 = phi_vals ) |> # 格子点を作成 dplyr::mutate( sum_phi = rowSums(cbind(phi_1, phi_2, phi_3)), phi_1 = phi_1 / sum_phi, phi_2 = phi_2 / sum_phi, phi_3 = phi_3 / sum_phi ) |> # 正規化 dplyr::distinct(phi_1, phi_2, phi_3) |> # 重複を除去 as.matrix() # マトリクスに変換 head(phi_scatter_mat)
## phi_1 phi_2 phi_3 ## [1,] NaN NaN NaN ## [2,] 0 0.0000000 1.0000000 ## [3,] 0 1.0000000 0.0000000 ## [4,] 0 0.5000000 0.5000000 ## [5,] 0 0.3333333 0.6666667 ## [6,] 0 0.2500000 0.7500000
3つの要素分のphi_valsの全ての組み合わせ(格子状の点)をexpand_grid()で作成します。データフレームが出力されるので、as.matrix()でマトリクスに変換してphi_scatter_matとします。phi_scatter_matの各行が点$\boldsymbol{\phi} = (\phi_1, \phi_2, \phi_3)$に対応します。
ただし、$\sum_{v=1}^V \phi_v = 1$を満たす必要があるため、行ごとに総和で割って正規化します。正規化によって重複する組み合わせ(行)ができるので、distinct()で取り除きます。全ての要素が0の行はゼロ除算になるため非数NaNになっています(作図に影響しないのでこのままとします)。
$\boldsymbol{\phi}$の点ごとの確率密度を計算します。
# ディリクレ分布を計算 dens_scatter_df <- tibble::tibble( phi_1 = phi_scatter_mat[, 1], # 三次元座標のx軸の値 phi_2 = phi_scatter_mat[, 2], # 三次元座標のy軸の値 phi_3 = phi_scatter_mat[, 3], # 三次元座標のz軸の値 y_1 = phi_scatter_mat[, 2] + 0.5 * phi_scatter_mat[, 3], # 三角座標のx軸の値 y_2 = sqrt(3) * 0.5 * phi_scatter_mat[, 3], # 三角座標のy軸の値 density = MCMCpack::ddirichlet(x = phi_scatter_mat, alpha = beta_v) # 確率密度 ) dens_scatter_df
## # A tibble: 113,019 × 6 ## phi_1 phi_2 phi_3 y_1 y_2 density ## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> ## 1 NaN NaN NaN NaN NaN 0 ## 2 0 0 1 0.5 0.866 0 ## 3 0 1 0 1 0 0 ## 4 0 0.5 0.5 0.75 0.433 0 ## 5 0 0.333 0.667 0.667 0.577 0 ## 6 0 0.25 0.75 0.625 0.650 0 ## 7 0 0.2 0.8 0.6 0.693 0 ## 8 0 0.167 0.833 0.583 0.722 0 ## 9 0 0.143 0.857 0.571 0.742 0 ## 10 0 0.125 0.875 0.562 0.758 0 ## # … with 113,009 more rows
phi_scatter_matの値を三角座標に変換してデータフレームに格納します。
ディリクレ分布の確率密度は、MCMCpackパッケージのddirichlet()で計算できます。確率変数の引数xにphi_scatter_mat、パラメータの引数alphaにbeta_vを指定します。
散布図によって、ディリクレ分布のヒートマップを作成します。
# ディリクレ分布の(散布図による)ヒートマップを作成 ggplot() + geom_point(data = dens_scatter_df, mapping = aes(x = y_1, y = y_2, color = density)) + # 確率密度の散布図 #geom_tile(data = dens_contour_df, # mapping = aes(x = y_1, y = y_2, fill = density, alpha = fill_flg)) + # 確率密度のヒートマップ #scale_alpha_manual(breaks = c(TRUE, FALSE), values = c(0.8, 0), guide = "none") + # 透過 scale_alpha_manual(breaks = c(TRUE, FALSE), values = c(0.5, 0), guide = "none") + # 透過 scale_color_viridis_c() + # グラデーション #scale_color_gradientn(colors = c("blue", "green", "yellow", "orange")) + # グラデーション geom_segment(data = ternary_grid_df, mapping = aes(x = y_1_start, y = y_2_start, xend = y_1_end, yend = y_2_end), color = "gray50", alpha = 0.5, linetype = "dashed") + # 三角図のグリッド線 geom_segment(data = ternary_axis_df, mapping = aes(x = y_1_start, y = y_2_start, xend = y_1_end, yend = y_2_end), color = "gray50") + # 三角図の枠線 geom_text(data = ternary_ticklabel_df, mapping = aes(x = y_1, y = y_2, label = label, hjust = h, vjust = v, angle = angle)) + # 三角図の軸目盛ラベル geom_text(data = ternary_axislabel_df, mapping = aes(x = y_1, y = y_2, label = label, hjust = h, vjust = v), parse = TRUE, size = 6) + # 三角図の軸ラベル scale_x_continuous(breaks = c(0, 0.5, 1), labels = NULL) + # x軸 scale_y_continuous(breaks = c(0, 0.25*sqrt(3), 0.5*sqrt(3)), labels = NULL) + # y軸 coord_fixed(ratio = 1, clip = "off") + # アスペクト比 theme(axis.ticks = element_blank(), panel.grid.minor = element_blank()) + # 図の体裁 labs(title = "Dirichlet Distribution", subtitle = paste0("beta=(", paste0(beta_v, collapse = ", "), ")"), # (文字列表示用) #subtitle = parse(text = paste0("beta==(list(", paste0(beta_v, collapse = ", "), "))")), # (数式表示用) fill = "density", x = "", y = "")
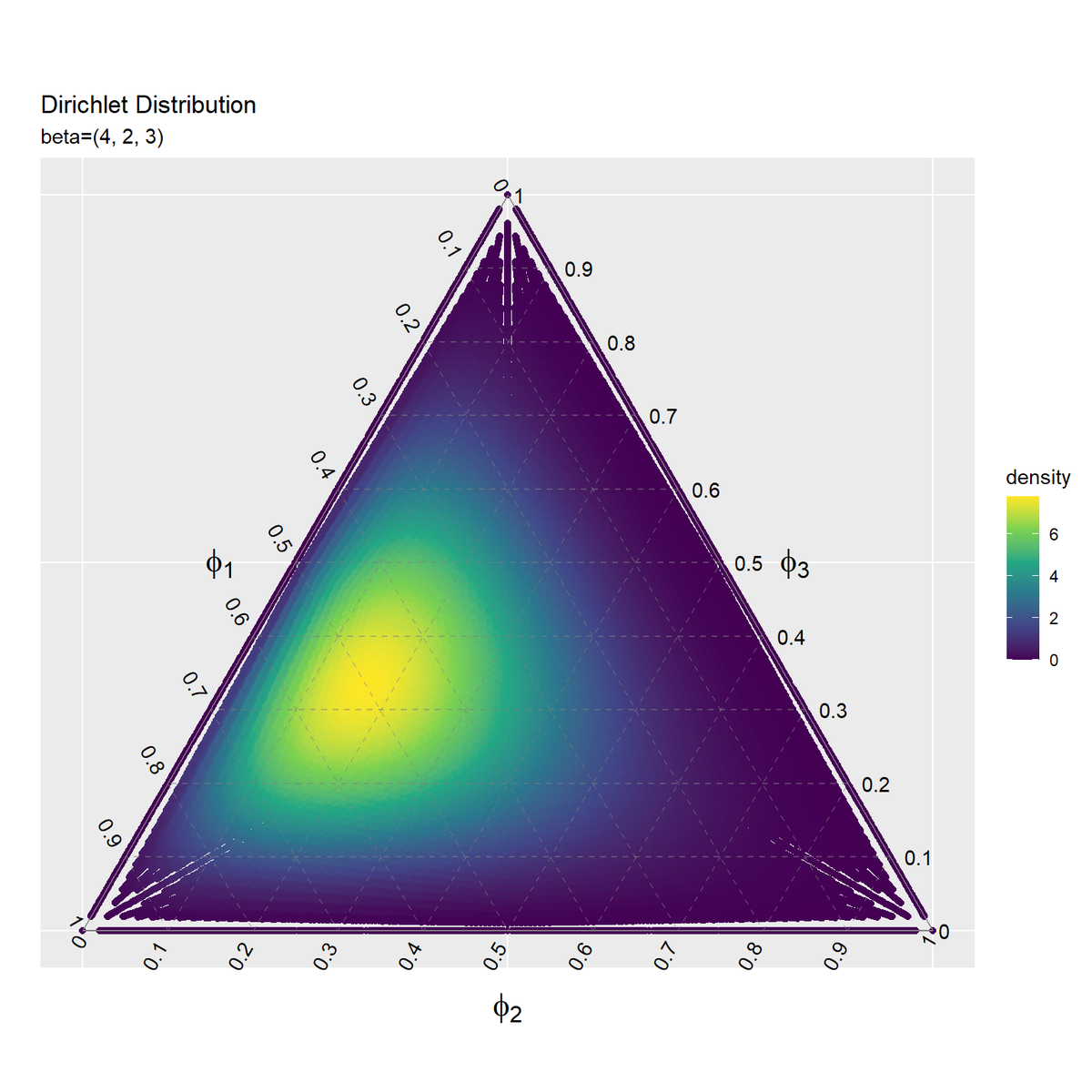
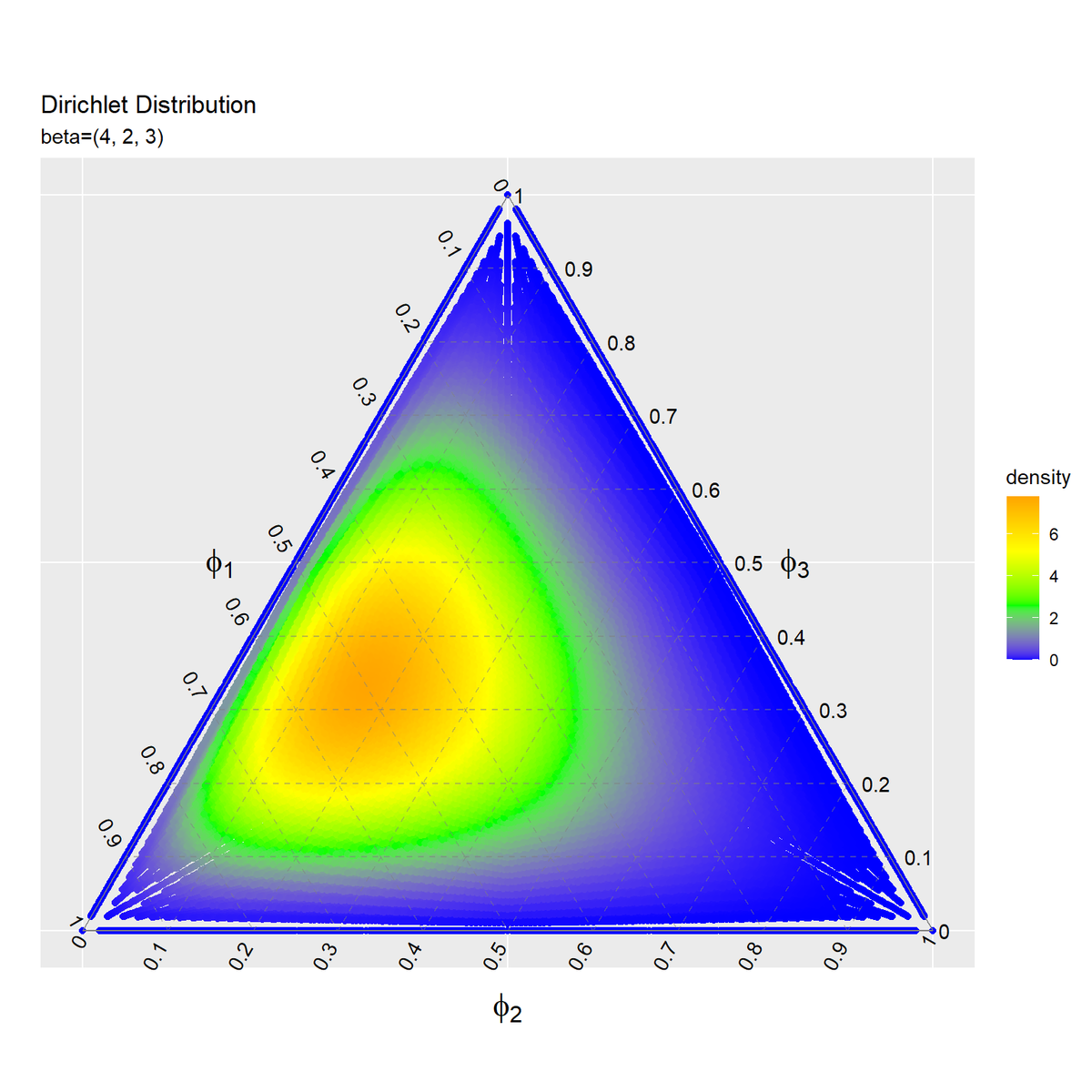
scale_color_viridis_c()やscale_color_gradientn()を使ってグラデーションのカラーマップを指定します。
ギリシャ文字などの記号を使った数式を表示する場合は、expression()の記法を使います。等号は"=="、複数の(数式上の)変数を並べるには"list(変数1, 変数2)"とします。(プログラム上の)変数の値を使う場合は、parse()のtext引数に指定します。
phi_valsの要素数を増やす(間隔を狭くする)と隅の空白が埋まりますが、処理が重くなります。
等高線図
2つ目の方法は、三角座標を含めた2次元座標上の格子点を作成し、元の3次元座標に戻して確率密度を計算します。こちらの方が綺麗なグラフを作成できます。
グラフ用と計算用の$\boldsymbol{\phi}$の値を作成します。
# 三角座標の値を作成 y_1_vals <- seq(from = 0, to = 1, length.out = 301) y_2_vals <- seq(from = 0, to = 0.5*sqrt(3), length.out = 300) # 格子点を作成 y_mat <- tidyr::expand_grid( y_1 = y_1_vals, y_2 = y_2_vals ) |> # 格子点を作成 as.matrix() # マトリクスに変換 # 3次元変数に変換 phi_mat <- tibble::tibble( phi_2 = y_mat[, 1] - y_mat[, 2] / sqrt(3), phi_3 = 2 * y_mat[, 2] / sqrt(3) ) |> # 元の座標に変換 dplyr::mutate( phi_2 = dplyr::if_else(phi_2 >= 0 & phi_2 <= 1, true = phi_2, false = as.numeric(NA)), phi_3 = dplyr::if_else(phi_3 >= 0 & phi_3 <= 1 & !is.na(phi_2), true = phi_3, false = as.numeric(NA)), phi_1 = 1 - phi_2 - phi_3, phi_1 = dplyr::if_else(phi_1 >= 0 & phi_1 <= 1, true = phi_1, false = as.numeric(NA)) ) |> # 範囲外の値をNAに置換 dplyr::select(phi_1, phi_2, phi_3) |> # 順番を変更 as.matrix() # マトリクスに変換 head(phi_mat)
## phi_1 phi_2 phi_3 ## [1,] 1 0 0 ## [2,] NA NA NA ## [3,] NA NA NA ## [4,] NA NA NA ## [5,] NA NA NA ## [6,] NA NA NA
三角座標を含めた2次元座標上の格子点を作成してy_matとします。
y_matを3次元座標上の点($\boldsymbol{\phi}$の点)に変換してphi_matとします。ただし、三角座標外の点については、総和が1の値($\boldsymbol{\phi}$を満たす値)にならないので欠損値NAに置き換えます。
ディリクレ分布を計算します。
# ディリクレ分布の確率密度を計算 dens_contour_df <- tibble::tibble( y_1 = y_mat[, 1], # x軸の値 y_2 = y_mat[, 2], # y軸の値 density = MCMCpack::ddirichlet(x = phi_mat, alpha = beta_v), # 確率密度 ) |> dplyr::mutate( fill_flg = !is.na(rowSums(phi_mat)), density = dplyr::if_else(fill_flg, true = density, false = as.numeric(NA)) ) # 範囲外の値をNAに置換 dens_contour_df
## # A tibble: 90,300 × 4 ## y_1 y_2 density fill_flg ## <dbl> <dbl> <dbl> <lgl> ## 1 0 0 0 TRUE ## 2 0 0.00290 NA FALSE ## 3 0 0.00579 NA FALSE ## 4 0 0.00869 NA FALSE ## 5 0 0.0116 NA FALSE ## 6 0 0.0145 NA FALSE ## 7 0 0.0174 NA FALSE ## 8 0 0.0203 NA FALSE ## 9 0 0.0232 NA FALSE ## 10 0 0.0261 NA FALSE ## # … with 90,290 more rows
グラフ用の値y_matと、計算用の値x_matにより求めた確率密度をデータフレームに格納します。ただし、三角座標外の要素(phi_matの欠損値を含む行)については欠損値NAに置き換えます。
ディリクレ分布の等高線図を作成します。
# ディリクレ分布の等高線図を作成 ggplot() + geom_segment(data = ternary_grid_df, mapping = aes(x = y_1_start, y = y_2_start, xend = y_1_end, yend = y_2_end), color = "gray50", linetype = "dashed") + # 三角図のグリッド線 geom_segment(data = ternary_axis_df, mapping = aes(x = y_1_start, y = y_2_start, xend = y_1_end, yend = y_2_end), color = "gray50") + # 三角図の枠線 geom_text(data = ternary_ticklabel_df, mapping = aes(x = y_1, y = y_2, label = label, hjust = h, vjust = v, angle = angle)) + # 三角図の軸目盛ラベル geom_text(data = ternary_axislabel_df, mapping = aes(x = y_1, y = y_2, label = label, hjust = h, vjust = v), parse = TRUE, size = 6) + # 三角図の軸ラベル geom_contour_filled(data = dens_contour_df, mapping = aes(x = y_1, y = y_2, z = density, fill = ..level..), alpha = 0.8) + # 確率密度の等高線 scale_x_continuous(breaks = c(0, 0.5, 1), labels = NULL) + # x軸 scale_y_continuous(breaks = c(0, 0.25*sqrt(3), 0.5*sqrt(3)), labels = NULL) + # y軸 coord_fixed(ratio = 1, clip = "off") + # アスペクト比 theme(axis.ticks = element_blank(), panel.grid.minor = element_blank()) + # 図の体裁 labs(title = "Dirichlet Distribution", #subtitle = paste0("beta=(", paste0(beta_v, collapse = ", "), ")"), # (文字列表示用) subtitle = parse(text = paste0("beta==(list(", paste0(beta_v, collapse = ", "), "))")), # (数式表示用) fill = "density", x = "", y = "")
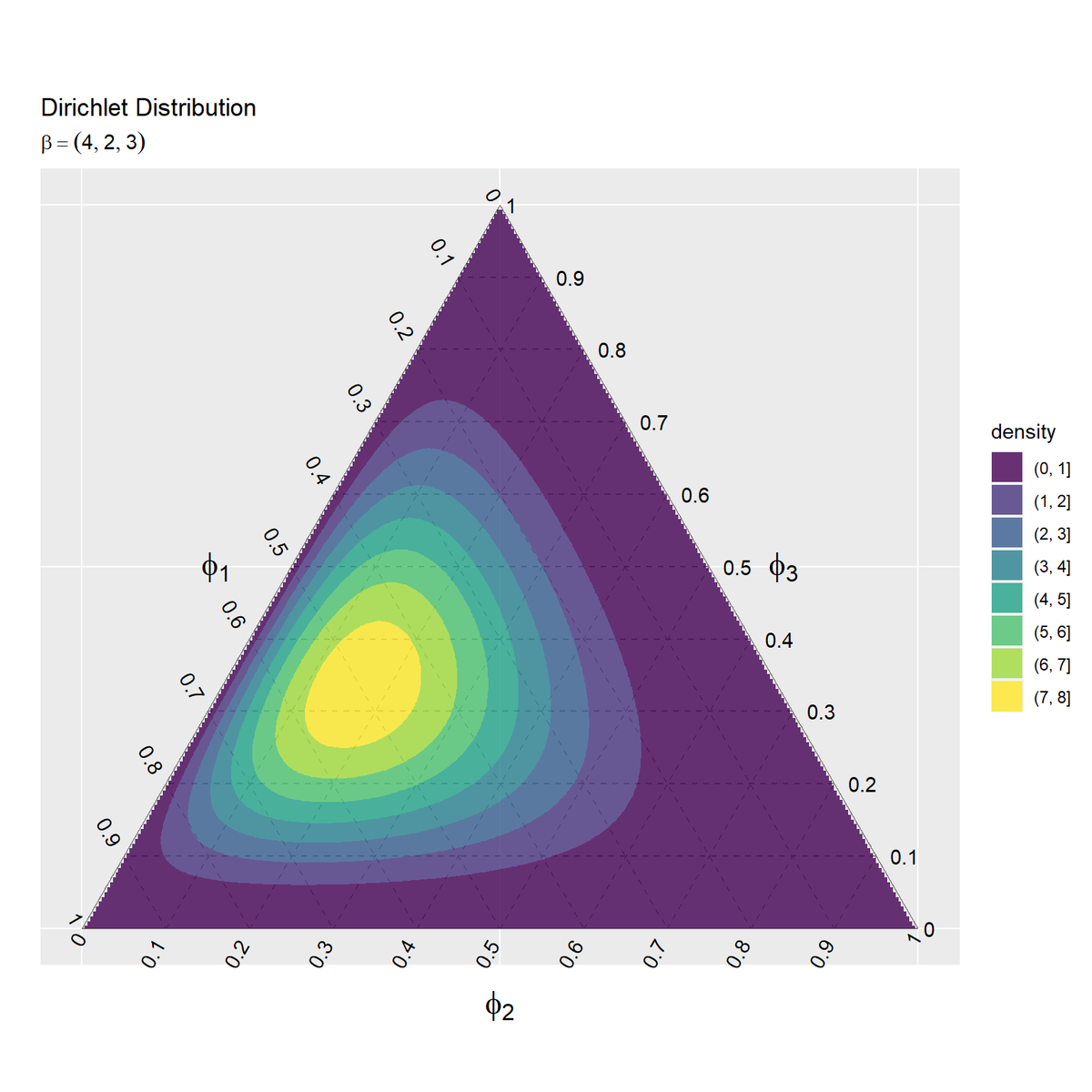
geom_contour()またはgeom_contour_filled()で等高線図を描画します。三角図外の点は欠損値NAなので描画されません(つまりデータの半分を捨てています)。
ヒートマップ
等高線図用のデータフレームを加工して、ヒートマップを作成します。
三角座標外の点(行)を削除します。
# 範囲外の要素を除去 dens_heatmap_df <- dens_contour_df |> dplyr::filter(fill_flg) dens_heatmap_df
## # A tibble: 45,002 × 4 ## y_1 y_2 density fill_flg ## <dbl> <dbl> <dbl> <lgl> ## 1 0 0 0 TRUE ## 2 0.00333 0 0 TRUE ## 3 0.00333 0.00290 0.0000615 TRUE ## 4 0.00667 0 0 TRUE ## 5 0.00667 0.00290 0.000183 TRUE ## 6 0.00667 0.00579 0.000485 TRUE ## 7 0.00667 0.00869 0.000539 TRUE ## 8 0.01 0 0 TRUE ## 9 0.01 0.00290 0.000302 TRUE ## 10 0.01 0.00579 0.000961 TRUE ## # … with 44,992 more rows
fill_flg列がFALSEまたはdensity列がNAの行をfilter()で取り除きます。
ディリクレ分布のヒートマップを作成します。
# ディリクレ分布のヒートマップを作成 ggplot() + geom_tile(data = dens_heatmap_df, mapping = aes(x = y_1, y = y_2, fill = density)) + # 確率密度のヒートマップ geom_segment(data = ternary_grid_df, mapping = aes(x = y_1_start, y = y_2_start, xend = y_1_end, yend = y_2_end), color = "gray50", linetype = "dashed") + # 三角図のグリッド線 geom_segment(data = ternary_axis_df, mapping = aes(x = y_1_start, y = y_2_start, xend = y_1_end, yend = y_2_end), color = "gray50") + # 三角図の枠線 geom_text(data = ternary_ticklabel_df, mapping = aes(x = y_1, y = y_2, label = label, hjust = h, vjust = v, angle = angle)) + # 三角図の軸目盛ラベル geom_text(data = ternary_axislabel_df, mapping = aes(x = y_1, y = y_2, label = label, hjust = h, vjust = v), parse = TRUE, size = 6) + # 三角図の軸ラベル scale_fill_viridis_c() + # グラデーション #scale_fill_gradientn(colors = c("blue", "green", "yellow", "orange")) + # グラデーション scale_x_continuous(breaks = c(0, 0.5, 1), labels = NULL) + # x軸 scale_y_continuous(breaks = c(0, 0.25*sqrt(3), 0.5*sqrt(3)), labels = NULL) + # y軸 coord_fixed(ratio = 1, clip = "off") + # アスペクト比 theme(axis.ticks = element_blank(), panel.grid.minor = element_blank()) + # 図の体裁 labs(title = "Dirichlet Distribution", #subtitle = paste0("beta=(", paste0(beta_v, collapse = ", "), ")"), # (文字列表示用) subtitle = parse(text = paste0("beta==(list(", paste0(beta_v, collapse = ", "), "))")), # (数式表示用) fill = "density", x = "", y = "")
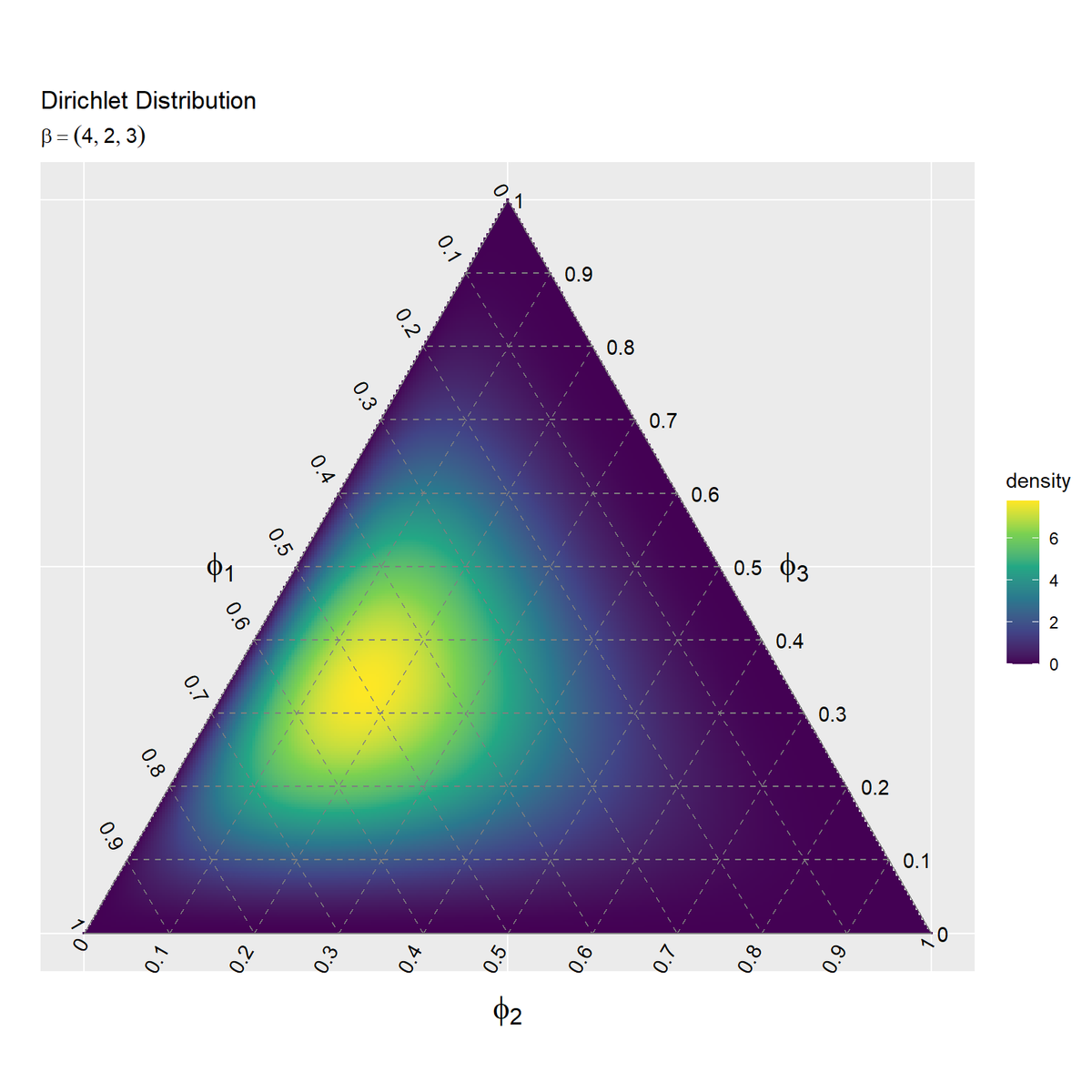
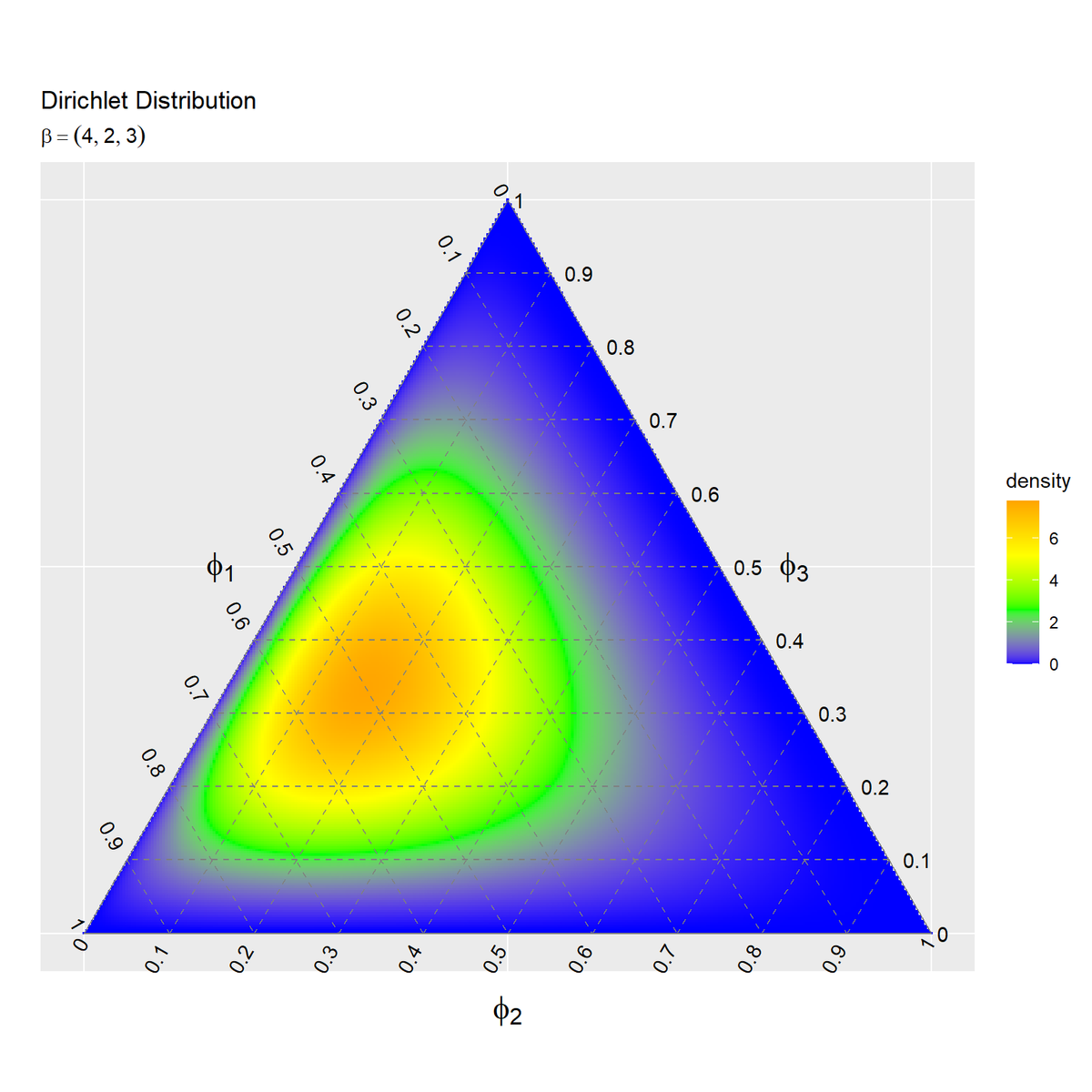
geom_tile()でヒートマップを描画します。
統計量の可視化
次は、統計量の情報を重ねて表示します。
期待値と最頻値を計算します。
# 補助線用の統計量を計算 E_phi_v <- beta_v / sum(beta_v) mode_phi_v <- (beta_v - 1) / (sum(beta_v) - length(beta_v)) E_phi_v; mode_phi_v
## [1] 0.4444444 0.2222222 0.3333333 ## [1] 0.5000000 0.1666667 0.3333333
最頻値は$\beta_v > 1$の場合に定義されます。
それぞれの値(点)で交わるグリッド線用のデータフレームを作成します。
# 期待値のグリッド線用の値を作成 stat_grid_df <- tibble::tibble( y_1_start = c( 0.5 * (1 - c(E_phi_v[1], mode_phi_v[1])), c(E_phi_v[2], mode_phi_v[2]), 0.5 * (1 - c(E_phi_v[3], mode_phi_v[3])) + 0.5 ), # 始点のx軸の値 y_2_start = c( sqrt(3) * 0.5 * (1 - c(E_phi_v[1], mode_phi_v[1])), c(0, 0), sqrt(3) * 0.5 * c(E_phi_v[3], mode_phi_v[3]) ), # 始点のy軸の値 y_1_end = c( 1 - c(E_phi_v[1], mode_phi_v[1]), 0.5 * c(E_phi_v[2], mode_phi_v[2]) + 0.5, 0.5 * c(E_phi_v[3], mode_phi_v[3]) ), # 終点のx軸の値 y_2_end = c( c(0, 0), sqrt(3) * 0.5 * (1 - c(E_phi_v[2], mode_phi_v[2])), sqrt(3) * 0.5 * c(E_phi_v[3], mode_phi_v[3]) ), # 終点のy軸の値 axis = c("x_1", "x_2", "x_3") |> rep(each = 2), # 軸ラベル statistic = c("mean", "mode") |> rep(times = 3) # 色分け用ラベル ) stat_grid_df
## # A tibble: 6 × 6 ## y_1_start y_2_start y_1_end y_2_end axis statistic ## <dbl> <dbl> <dbl> <dbl> <chr> <chr> ## 1 0.278 0.481 0.556 0 x_1 mean ## 2 0.25 0.433 0.5 0 x_1 mode ## 3 0.222 0 0.611 0.674 x_2 mean ## 4 0.167 0 0.583 0.722 x_2 mode ## 5 0.833 0.289 0.167 0.289 x_3 mean ## 6 0.833 0.289 0.167 0.289 x_3 mode
期待値と最頻値の各要素(成分)ごとに軸線を引くための値を用意します。詳しくは「三角座標の準備」を参照してください。
各統計量を区別するための文字列を格納しておき、色分けに使います。
等高線図に統計量の情報を重ねて作図します。
# 統計量を重ねたディリクレ分布の等高線図を作成 ggplot() + geom_segment(data = ternary_grid_df, mapping = aes(x = y_1_start, y = y_2_start, xend = y_1_end, yend = y_2_end), color = "gray50", linetype = "dashed") + # 三角図のグリッド線 geom_segment(data = ternary_axis_df, mapping = aes(x = y_1_start, y = y_2_start, xend = y_1_end, yend = y_2_end), color = "gray50") + # 三角図の枠線 geom_text(data = ternary_ticklabel_df, mapping = aes(x = y_1, y = y_2, label = label, hjust = h, vjust = v, angle = angle)) + # 三角図の軸目盛ラベル geom_text(data = ternary_axislabel_df, mapping = aes(x = y_1, y = y_2, label = label, hjust = h, vjust = v), parse = TRUE, size = 6) + # 三角図の軸ラベル geom_contour_filled(data = dens_contour_df, mapping = aes(x = y_1, y = y_2, z = density, fill = ..level..), alpha = 0.8) + # 確率密度の等高線 geom_segment(data = stat_grid_df, mapping = aes(x = y_1_start, y = y_2_start, xend = y_1_end, yend = y_2_end, color = statistic), size = 1, linetype ="dashed") + # 統計量のグリッド線 scale_color_manual(breaks = c("mean", "mode"), values = c("blue", "chocolate"), labels = c(expression(E(phi[v])), expression(mode(phi[v]))), name = "statistic") + # 線の色 guides(color = guide_legend(override.aes = list(size = 0.5))) + # 凡例の体裁 scale_x_continuous(breaks = c(0, 0.5, 1), labels = NULL) + # x軸 scale_y_continuous(breaks = c(0, 0.25*sqrt(3), 0.5*sqrt(3)), labels = NULL) + # y軸 coord_fixed(ratio = 1, clip = "off") + # アスペクト比 theme(axis.ticks = element_blank(), panel.grid.minor = element_blank()) + # 図の体裁 labs(title = "Dirichlet Distribution", subtitle = parse(text = paste0("beta==(list(", paste0(beta_v, collapse = ", "), "))")), fill = "density", x = "", y = "")
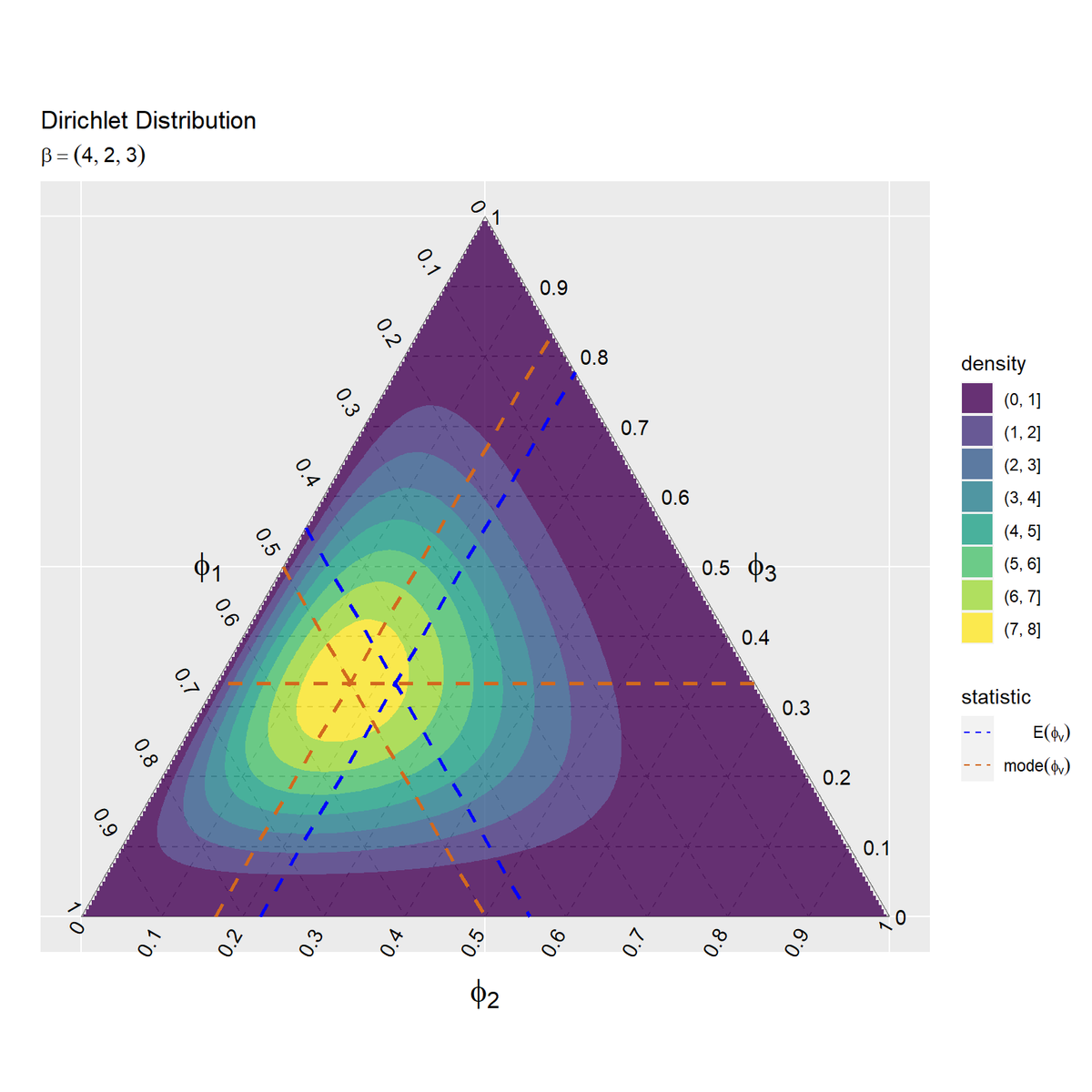
geom_segment()のcolor引数に色分け用の列(統計量ラベル列)statisticを指定して、期待値と最頻値の線の色を変えます。
scale_color_manual()のbreaks引数にcolor引数に指定した値(文字列)、values引数に線の色、labels引数に項目ラベルを指定します。凡例ラベルを指定する場合は、scale_color_manual()のname引数か、labs()のcolor引数に文字列を指定します。
ここまでで、ディリクレ分布のグラフを描画できました。以降は、ここまでの作図処理を用いて、パラメータの影響を確認していきます。
パラメータと分布の形状の関係を並べて比較
複数のパラメータのグラフを比較することで、パラメータの値と分布の形状の関係を確認します。
複数のパラメータを設定します。
# パラメータとして利用する値を指定 beta_1_vals <- c(1, 0.9, 3, 10, 4, 3) beta_2_vals <- c(1, 0.9, 3, 10, 2, 0.9) beta_3_vals <- c(1, 0.9, 3, 10, 3, 2)
$\beta_1, \beta_2, \beta_3$の値をそれぞれbeta_*_valsとして、要素数が同じになるように値を指定します。
パラメータごとに分布を計算します。
# パラメータごとにディリクレ分布を計算 res_dens_df <- tidyr::expand_grid( param_i = seq(beta_1_vals), # パラメータ phi_i = 1:nrow(y_mat) # 点番号 ) |> # パラメータごとに格子点を複製 dplyr::group_by(param_i) |> # 分布の計算用にグループ化 dplyr::mutate( y_1 = y_mat[phi_i, 1], y_2 = y_mat[phi_i, 2], beta_1 = beta_1_vals[unique(param_i)], beta_2 = beta_2_vals[unique(param_i)], beta_3 = beta_3_vals[unique(param_i)], density = MCMCpack::ddirichlet( x = phi_mat, alpha = c(unique(beta_1), unique(beta_2), unique(beta_3)) ), # 確率密度 beta = paste0("(", unique(beta_1), ", ", unique(beta_2), ", ", unique(beta_3), ")") |> factor(levels = paste0("(", beta_1_vals, ", ", beta_2_vals, ", ", beta_3_vals, ")")) # フレーム切替用ラベル ) |> dplyr::mutate( fill_flg = !is.na(rowSums(phi_mat)), density = dplyr::if_else(fill_flg, true = density, false = as.numeric(NA)) ) # 範囲外を非表示化 res_dens_df
## # A tibble: 541,800 × 10 ## # Groups: param_i [6] ## param_i phi_i y_1 y_2 beta_1 beta_2 beta_3 density beta fill_flg ## <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <fct> <lgl> ## 1 1 1 0 0 1 1 1 NaN (1, 1, 1) TRUE ## 2 1 2 0 0.00290 1 1 1 NA (1, 1, 1) FALSE ## 3 1 3 0 0.00579 1 1 1 NA (1, 1, 1) FALSE ## 4 1 4 0 0.00869 1 1 1 NA (1, 1, 1) FALSE ## 5 1 5 0 0.0116 1 1 1 NA (1, 1, 1) FALSE ## 6 1 6 0 0.0145 1 1 1 NA (1, 1, 1) FALSE ## 7 1 7 0 0.0174 1 1 1 NA (1, 1, 1) FALSE ## 8 1 8 0 0.0203 1 1 1 NA (1, 1, 1) FALSE ## 9 1 9 0 0.0232 1 1 1 NA (1, 1, 1) FALSE ## 10 1 10 0 0.0261 1 1 1 NA (1, 1, 1) FALSE ## # … with 541,790 more rows
パラメータ番号として1からbeta_*_valsの要素数までの整数を作成し、y_matの行番号との全ての組み合わせをexpand_grid()で作成します。これにより、パラメータごとにy_matを複製できます。
パラメータ列param_iでグループ化することで、phi_matごとに確率密度を計算できます。
param_i列をインデックスとして使ってbeta_*_valsから値を取り出して、phi_matごとに確率密度を計算できます。
パラメータごとにグラフを分割してディリクレ分布を作図します。
# パラメータごとにディリクレ分布の等高線図を作成 ggplot() + geom_segment(data = ternary_grid_df, mapping = aes(x = y_1_start, y = y_2_start, xend = y_1_end, yend = y_2_end), color = "gray50", linetype = "dashed") + # 三角図のグリッド線 geom_segment(data = ternary_axis_df, mapping = aes(x = y_1_start, y = y_2_start, xend = y_1_end, yend = y_2_end), color = "gray50") + # 三角図の枠線 geom_text(data = ternary_ticklabel_df, mapping = aes(x = y_1, y = y_2, label = label, hjust = h, vjust = v, angle = angle)) + # 三角図の軸目盛ラベル geom_text(data = ternary_axislabel_df, mapping = aes(x = y_1, y = y_2, label = label, hjust = h, vjust = v), parse = TRUE, size = 6) + # 三角図の軸ラベル geom_contour_filled(data = res_dens_df, mapping = aes(x = y_1, y = y_2, z = density, fill = ..level..), alpha = 0.8) + # 確率密度の等高線 scale_x_continuous(breaks = c(0, 0.5, 1), labels = NULL) + # x軸 scale_y_continuous(breaks = c(0, 0.25*sqrt(3), 0.5*sqrt(3)), labels = NULL) + # y軸 facet_wrap(. ~ beta, nrow = 2, labeller = label_bquote(beta==.(as.character(beta)))) + # グラフを分割 coord_fixed(ratio = 1, clip = "off") + # アスペクト比 theme(axis.ticks = element_blank(), panel.grid.minor = element_blank()) + # 図の体裁 labs(title = "Dirichlet Distribution", fill = "density", x = "", y = "")
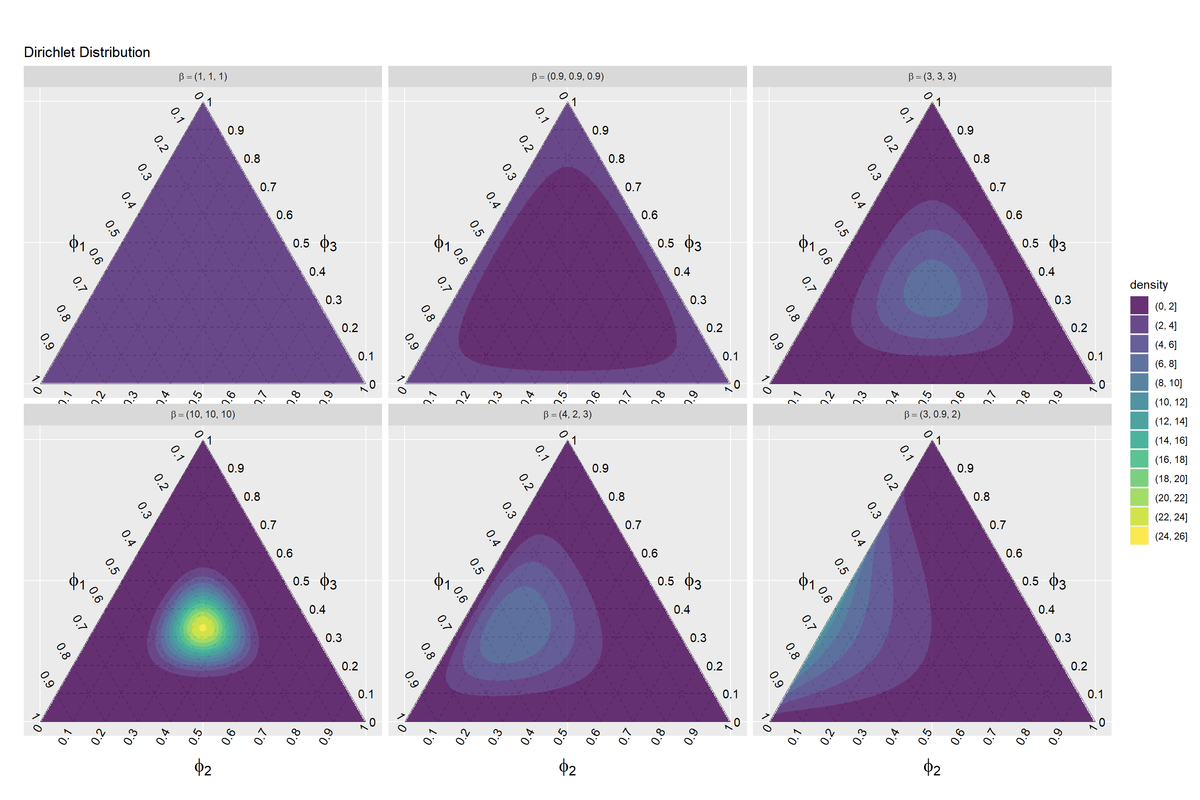
facet_wrap()に列を指定すると、その列の値ごとにグラフを分割して描画できます。
パラメータと分布の形状の関係をアニメーションで可視化
前節では、複数のパラメータのグラフを並べて比較しました。次は、パラメータの値を少しずつ変化させて、分布の形状の変化をアニメーションで確認します。
第1成分の影響
まずは、$\beta_1$の値を変化させ、$\beta_2, \beta_3$を固定します。
・作図コード(クリックで展開)
# パラメータとして利用する値を指定 beta_1_vals <- seq(from = 1, to = 10, by = 0.2) |> round(digits = 1) # 固定するパラメータを指定 beta_2 <- 2 beta_3 <- 3 # フレーム数の設定 frame_num <- length(beta_1_vals) frame_num
## [1] 46
値の間隔が一定になるように$\beta_1$の値をbeta_1_valsとして作成します。パラメータごとにフレームを切り替えるので、beta_1_valsの要素数がアニメーションのフレーム数になります。
また$\beta_2, \beta_3$をbeta_2, beta_3として値を指定します。
パラメータごとに分布を計算します。
# パラメータごとにディリクレ分布を計算 anime_dens_df <- tidyr::expand_grid( beta_1 = beta_1_vals, # パラメータ i = 1:nrow(y_mat) # 点番号 ) |> # パラメータごとに格子点を複製 dplyr::group_by(beta_1) |> # 分布の計算用にグループ化 dplyr::mutate( y_1 = y_mat[i, 1], y_2 = y_mat[i, 2], density = MCMCpack::ddirichlet( x = phi_mat, alpha = c(unique(beta_1), beta_2, beta_3) ), # 確率密度 parameter = paste0("beta=(", unique(beta_1), ", ", beta_2, ", ", beta_3, ")") |> factor(levels = paste0("beta=(", beta_1_vals, ", ", beta_2, ", ", beta_3, ")")) # フレーム切替用ラベル ) |> dplyr::mutate( fill_flg = !is.na(rowSums(phi_mat)), density = dplyr::if_else(fill_flg, true = density, false = as.numeric(NA)) ) # 範囲外を非表示化 anime_dens_df
## # A tibble: 4,153,800 × 7 ## # Groups: beta_1 [46] ## beta_1 i y_1 y_2 density parameter fill_flg ## <dbl> <int> <dbl> <dbl> <dbl> <fct> <lgl> ## 1 1 1 0 0 0 beta=(1, 2, 3) TRUE ## 2 1 2 0 0.00290 NA beta=(1, 2, 3) FALSE ## 3 1 3 0 0.00579 NA beta=(1, 2, 3) FALSE ## 4 1 4 0 0.00869 NA beta=(1, 2, 3) FALSE ## 5 1 5 0 0.0116 NA beta=(1, 2, 3) FALSE ## 6 1 6 0 0.0145 NA beta=(1, 2, 3) FALSE ## 7 1 7 0 0.0174 NA beta=(1, 2, 3) FALSE ## 8 1 8 0 0.0203 NA beta=(1, 2, 3) FALSE ## 9 1 9 0 0.0232 NA beta=(1, 2, 3) FALSE ## 10 1 10 0 0.0261 NA beta=(1, 2, 3) FALSE ## # … with 4,153,790 more rows
パラメータbeta_1_valsの要素とy_matの行番号の全ての組み合わせをexpand_grid()で作成します。これにより、パラメータごとにy_matを複製できます。
パラメータ列beta_1でグループ化することで、phi_matごとに確率密度を計算できます。
パラメータごとにフレーム切替用のラベルを作成します。文字列型だと文字列の基準で順序が決まるので、因子型にしてパラメータに応じたレベル(順序)を設定します。
ディリクレ分布のヒートマップのアニメーション(gif画像)を作成します。
# ディリクレ分布のアニメーションを作成:ヒートマップ anime_dens_graph <- ggplot() + geom_segment(data = ternary_grid_df, mapping = aes(x = y_1_start, y = y_2_start, xend = y_1_end, yend = y_2_end), color = "gray50", linetype = "dashed") + # 三角図のグリッド線 geom_segment(data = ternary_axis_df, mapping = aes(x = y_1_start, y = y_2_start, xend = y_1_end, yend = y_2_end), color = "gray50") + # 三角図の枠線 geom_text(data = ternary_ticklabel_df, mapping = aes(x = y_1, y = y_2, label = label, hjust = h, vjust = v, angle = angle)) + # 三角図の軸目盛ラベル geom_text(data = ternary_axislabel_df, mapping = aes(x = y_1, y = y_2, label = label, hjust = h, vjust = v), parse = TRUE, size = 6) + # 三角図の軸ラベル geom_tile(data = anime_dens_df, mapping = aes(x = y_1, y = y_2, fill = density, alpha = fill_flg)) + # 確率密度のヒートマップ gganimate::transition_manual(parameter) + # フレーム scale_alpha_manual(breaks = c(TRUE, FALSE), values = c(0.8, 0), guide = "none") + # 透過 scale_fill_viridis_c() + # グラデーション #scale_fill_gradientn(colors = c("blue", "green", "yellow", "orange")) + # グラデーション scale_x_continuous(breaks = c(0, 0.5, 1), labels = NULL) + # x軸 scale_y_continuous(breaks = c(0, 0.25*sqrt(3), 0.5*sqrt(3)), labels = NULL) + # y軸 coord_fixed(ratio = 1, clip = "off") + # アスペクト比 theme(axis.ticks = element_blank(), panel.grid.minor = element_blank()) + # 図の体裁 labs(title = "Dirichlet Distribution", subtitle = "{current_frame}", fill = "density", x = "", y = "") # gif画像を作成 gganimate::animate(anime_dens_graph, nframes = frame_num, fps = 10, width = 600, height = 600)
transition_manual()にフレームの順序を表す列を指定します。この例では、因子型のラベルのレベルの順に描画されます。
animate()のフレーム数の引数nframesにパラメータ数、フレームレートの引数fpsに1秒当たりのフレーム数を指定します。fps引数の値が大きいほどフレームが早く切り替わります。ただし、値が大きいと意図通りに動作しません。
同様に、ディリクレ分布の等高線図のアニメーションを作成します。
# ディリクレ分布のアニメーションを作成:等高線図 anime_dens_graph <- ggplot() + geom_segment(data = ternary_grid_df, mapping = aes(x = y_1_start, y = y_2_start, xend = y_1_end, yend = y_2_end), color = "gray50", linetype = "dashed") + # 三角図のグリッド線 geom_segment(data = ternary_axis_df, mapping = aes(x = y_1_start, y = y_2_start, xend = y_1_end, yend = y_2_end), color = "gray50") + # 三角図の枠線 geom_text(data = ternary_ticklabel_df, mapping = aes(x = y_1, y = y_2, label = label, hjust = h, vjust = v, angle = angle)) + # 三角図の軸目盛ラベル geom_text(data = ternary_axislabel_df, mapping = aes(x = y_1, y = y_2, label = label, hjust = h, vjust = v), parse = TRUE, size = 6) + # 三角図の軸ラベル geom_contour_filled(data = anime_dens_df, mapping = aes(x = y_1, y = y_2, z = density, fill = ..level..), alpha = 0.8) + # 確率密度の等高線 gganimate::transition_manual(parameter) + # フレーム scale_x_continuous(breaks = c(0, 0.5, 1), labels = NULL) + # x軸 scale_y_continuous(breaks = c(0, 0.25*sqrt(3), 0.5*sqrt(3)), labels = NULL) + # y軸 coord_fixed(ratio = 1, clip = "off") + # アスペクト比 theme(axis.ticks = element_blank(), panel.grid.minor = element_blank()) + # 図の体裁 labs(title = "Dirichlet Distribution", subtitle = "{current_frame}", fill = "density", x = "", y = "") # gif画像を作成 gganimate::animate(anime_dens_graph, nframes = frame_num, fps = 10, width = 600, height = 600)
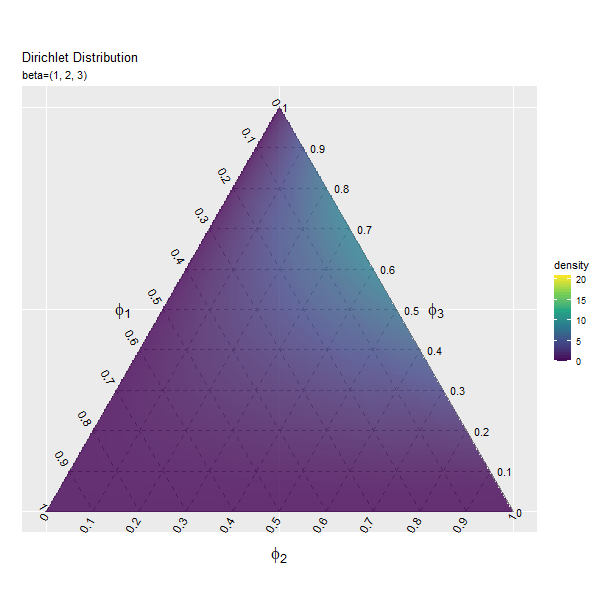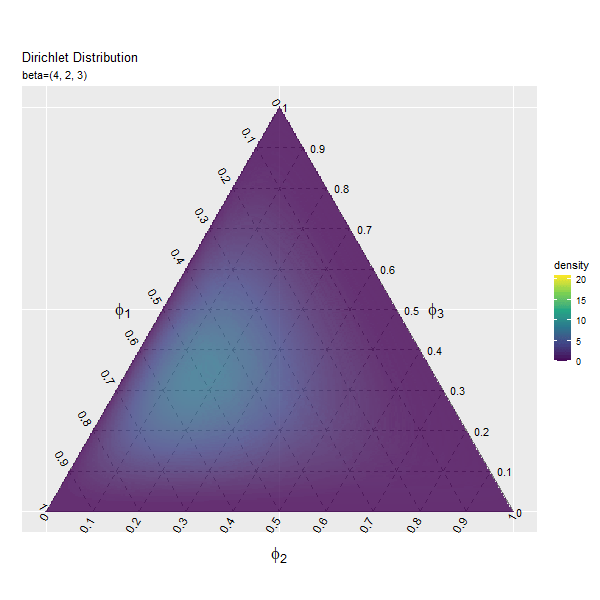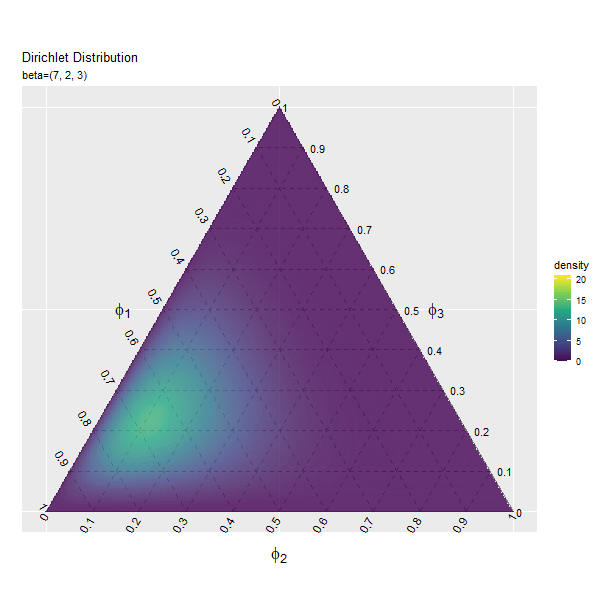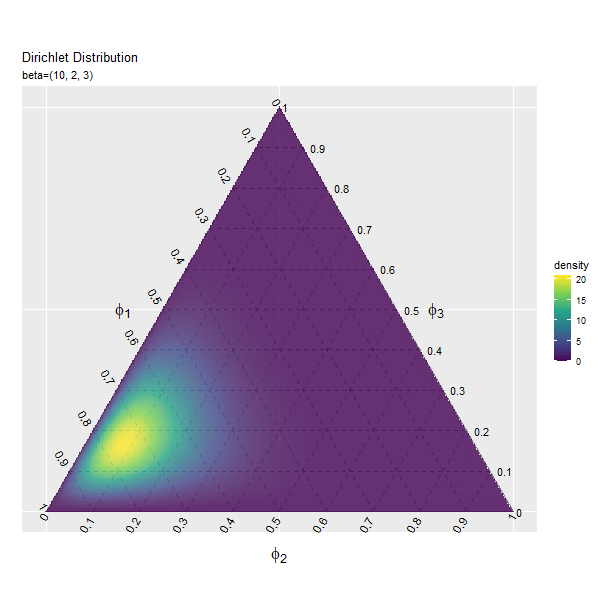
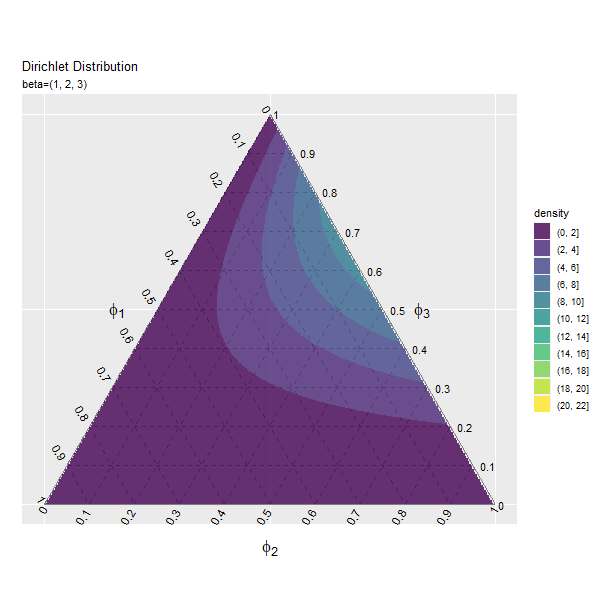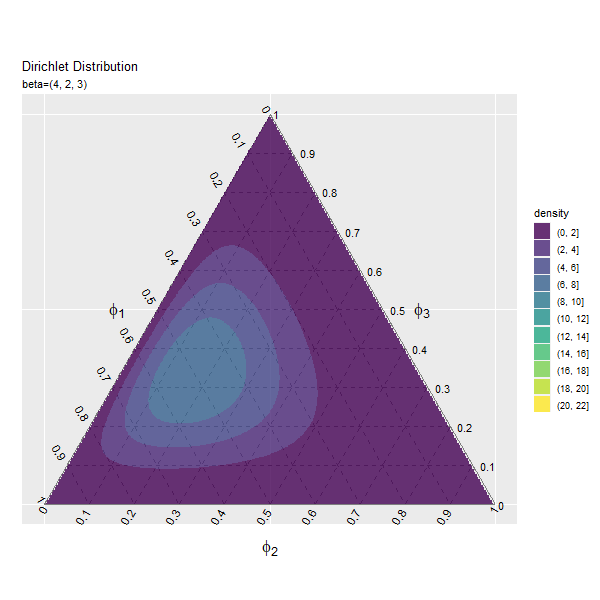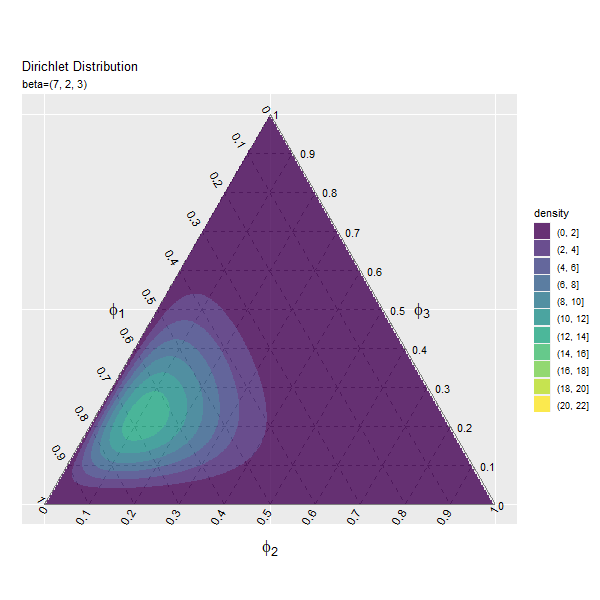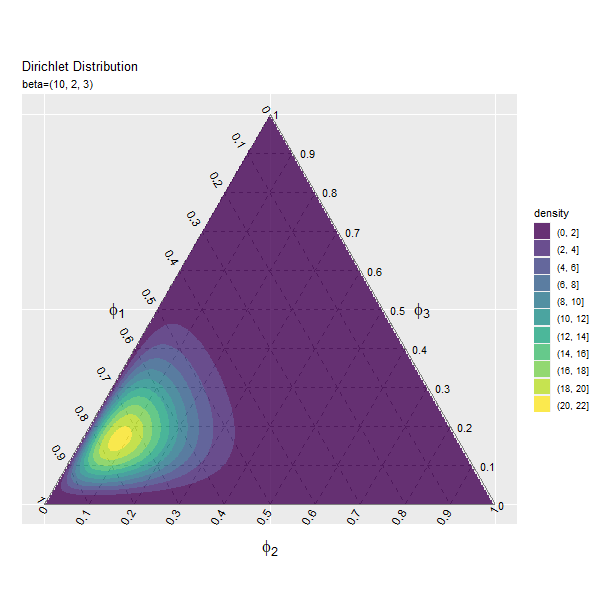
第2成分の影響
続いて、$\beta_2$の値を変化させ、$\beta_1, \beta_3$を固定します。
・作図コード(クリックで展開)
# パラメータとして利用する値を指定 beta_2_vals <- seq(from = 1, to = 10, by = 0.2) |> round(digits = 1) # 固定するパラメータを指定 beta_1 <- 2 beta_3 <- 3 # フレーム数の設定 frame_num <- length(beta_2_vals)
値の間隔が一定になるように$\beta_2$の値をbeta_2_valsとして作成し、$\beta_1, \beta_3$をbeta_1, beta_3として値を指定します。
パラメータごとに分布を計算します。
# パラメータごとにディリクレ分布を計算 anime_dens_df <- tidyr::expand_grid( beta_2 = beta_2_vals, # パラメータ i = 1:nrow(y_mat) # 点番号 ) |> # パラメータごとに格子点を複製 dplyr::group_by(beta_2) |> # 分布の計算用にグループ化 dplyr::mutate( y_1 = y_mat[i, 1], y_2 = y_mat[i, 2], density = MCMCpack::ddirichlet( x = phi_mat, alpha = c(beta_1, unique(beta_2), beta_3) ), # 確率密度 parameter = paste0("beta=(", beta_1, ", ", unique(beta_2), ", ", beta_3, ")") |> factor(levels = paste0("beta=(", beta_1, ", ", beta_2_vals, ", ", beta_3, ")")) # フレーム切替用ラベル ) |> dplyr::mutate( fill_flg = !is.na(rowSums(phi_mat)), density = dplyr::if_else(fill_flg, true = density, false = as.numeric(NA)) ) # 範囲外を非表示化 anime_dens_df
## # A tibble: 4,153,800 × 7 ## # Groups: beta_2 [46] ## beta_2 i y_1 y_2 density parameter fill_flg ## <dbl> <int> <dbl> <dbl> <dbl> <fct> <lgl> ## 1 1 1 0 0 NaN beta=(2, 1, 3) TRUE ## 2 1 2 0 0.00290 NA beta=(2, 1, 3) FALSE ## 3 1 3 0 0.00579 NA beta=(2, 1, 3) FALSE ## 4 1 4 0 0.00869 NA beta=(2, 1, 3) FALSE ## 5 1 5 0 0.0116 NA beta=(2, 1, 3) FALSE ## 6 1 6 0 0.0145 NA beta=(2, 1, 3) FALSE ## 7 1 7 0 0.0174 NA beta=(2, 1, 3) FALSE ## 8 1 8 0 0.0203 NA beta=(2, 1, 3) FALSE ## 9 1 9 0 0.0232 NA beta=(2, 1, 3) FALSE ## 10 1 10 0 0.0261 NA beta=(2, 1, 3) FALSE ## # … with 4,153,790 more rows
「第1成分の影響」のbeta_1, beta_1_valsとbeta_2, beta_2_valsを入れ換えるように処理します。
「第1成分の影響」のコードで作図できます。
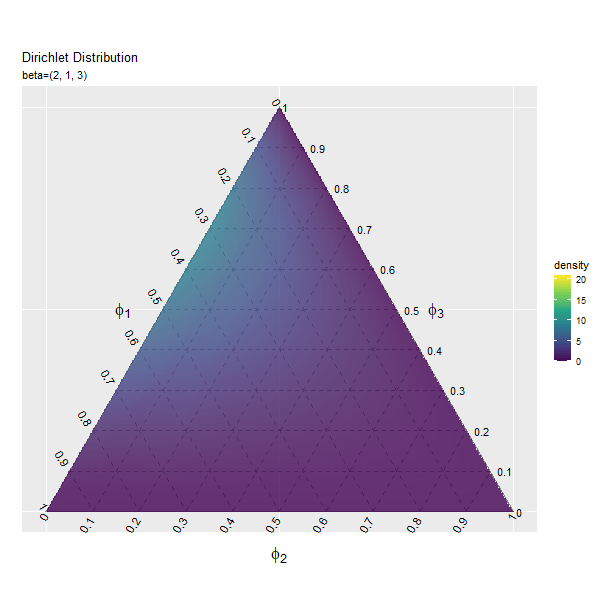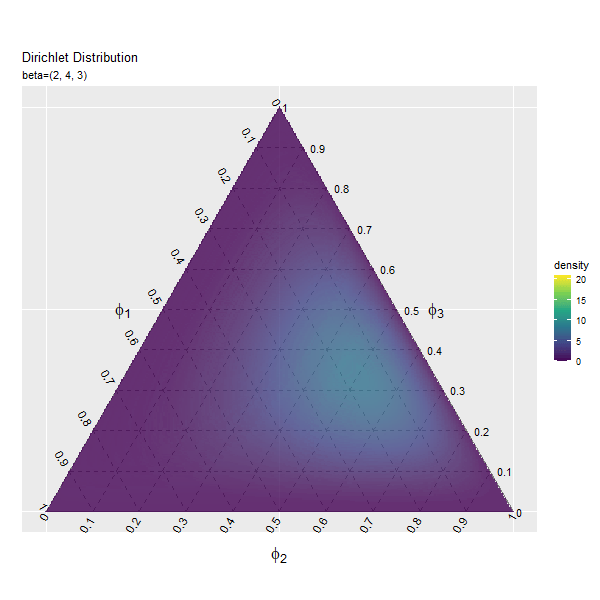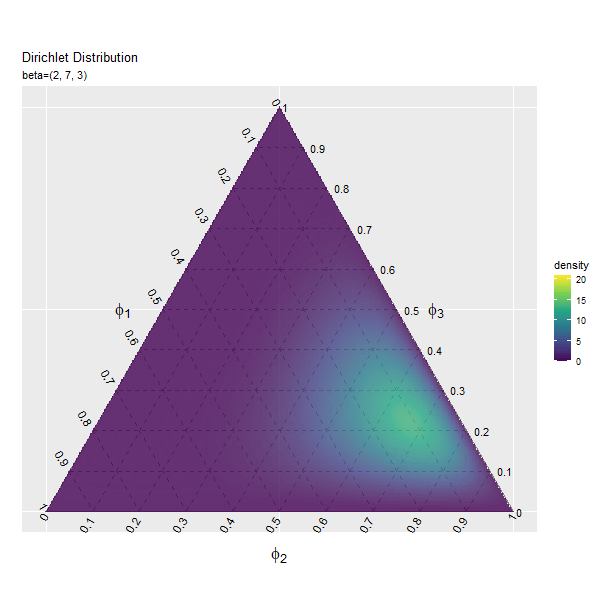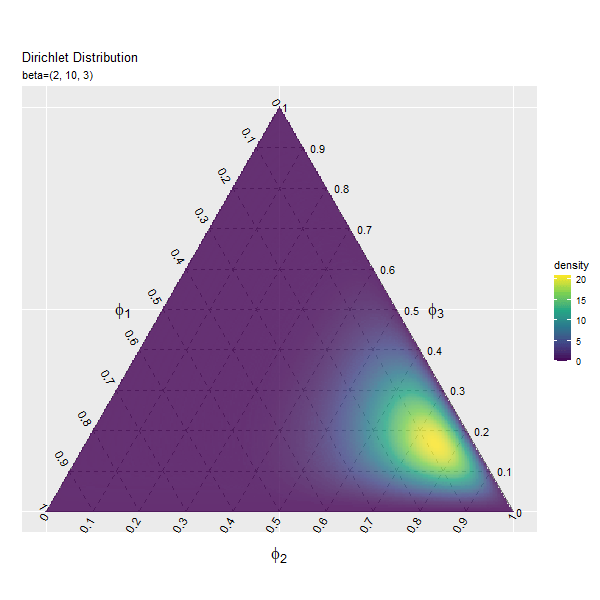
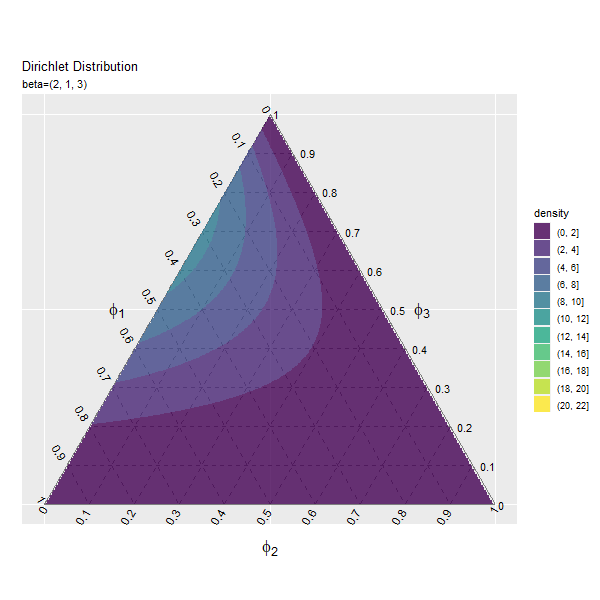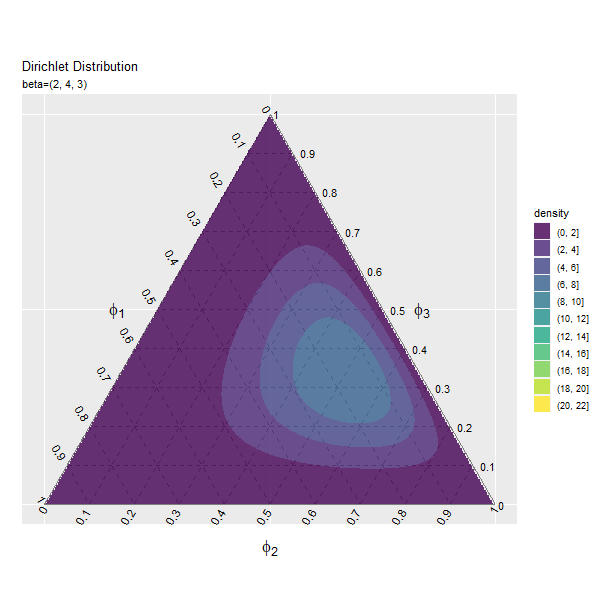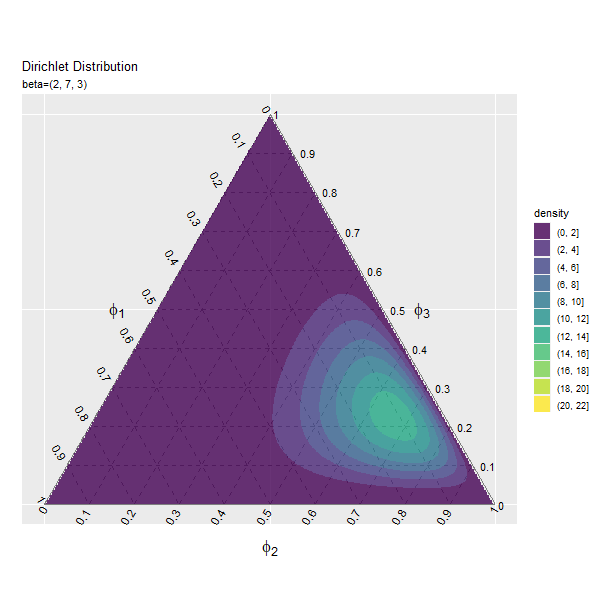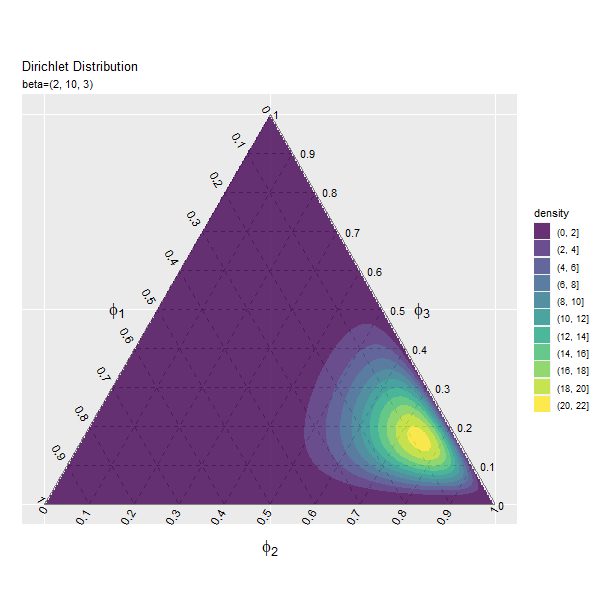
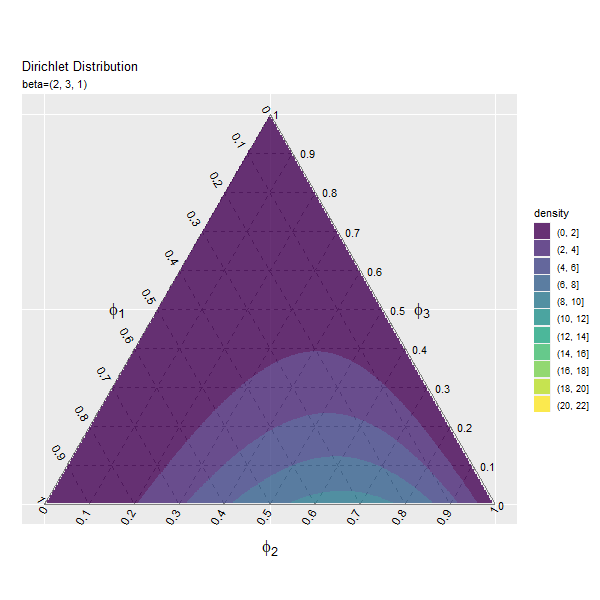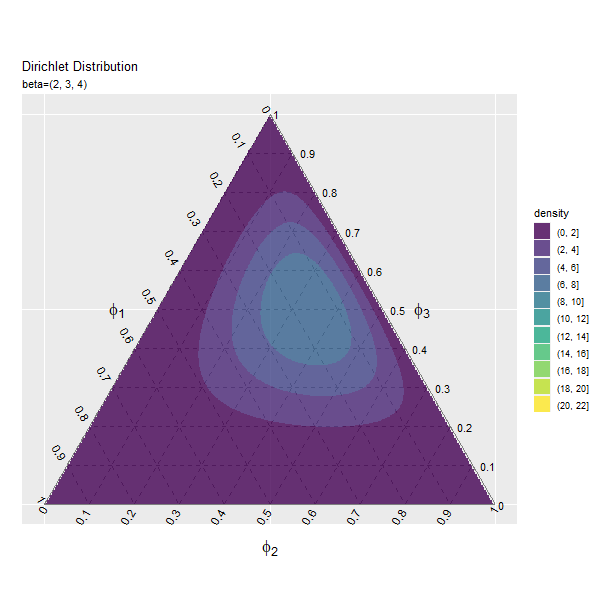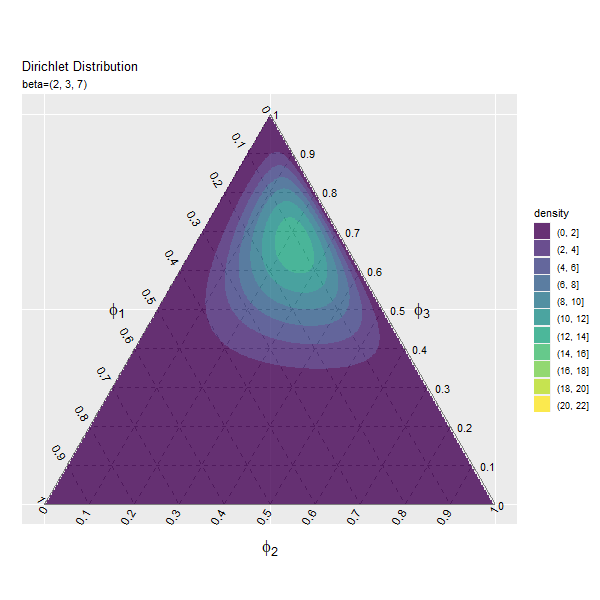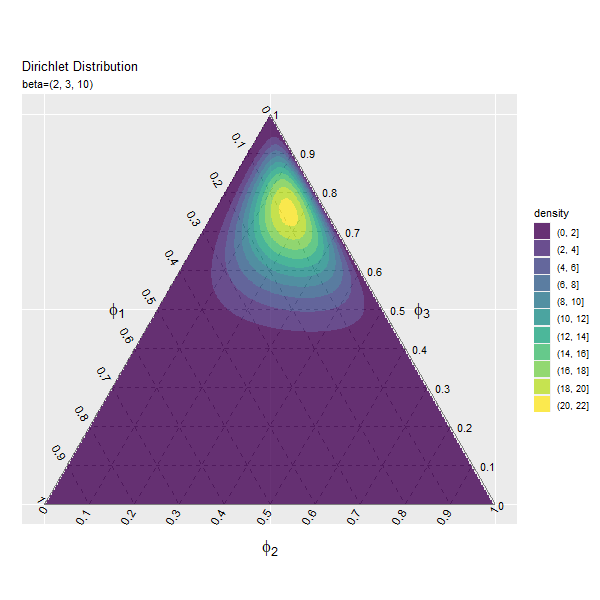
第3成分の影響
$\beta_3$の値を変化させ、$\beta_1, \beta_2$を固定します。
・作図コード(クリックで展開)
# パラメータとして利用する値を指定 beta_3_vals <- seq(from = 1, to = 10, by = 0.2) |> round(digits = 1) # 固定するパラメータを指定 beta_1 <- 2 beta_2 <- 3 # フレーム数の設定 frame_num <- length(beta_3_vals)
同様に指定します。
パラメータごとに分布を計算します。
# パラメータごとにディリクレ分布を計算 anime_dens_df <- tidyr::expand_grid( beta_3 = beta_3_vals, # パラメータ i = 1:nrow(y_mat) # 点番号 ) |> # パラメータごとに格子点を複製 dplyr::group_by(beta_3) |> # 分布の計算用にグループ化 dplyr::mutate( y_1 = y_mat[i, 1], y_2 = y_mat[i, 2], density = MCMCpack::ddirichlet( x = phi_mat, alpha = c(beta_1, beta_2, unique(beta_3)) ), # 確率密度 parameter = paste0("beta=(", beta_1, ", ", beta_2, ", ", unique(beta_3), ")") |> factor(levels = paste0("beta=(", beta_1, ", ", beta_2, ", ", beta_3_vals, ")")) # フレーム切替用ラベル ) |> dplyr::mutate( fill_flg = !is.na(rowSums(phi_mat)), density = dplyr::if_else(fill_flg, true = density, false = as.numeric(NA)) ) # 範囲外を非表示化 anime_dens_df
## # A tibble: 4,153,800 × 7 ## # Groups: beta_3 [46] ## beta_3 i y_1 y_2 density parameter fill_flg ## <dbl> <int> <dbl> <dbl> <dbl> <fct> <lgl> ## 1 1 1 0 0 NaN beta=(2, 3, 1) TRUE ## 2 1 2 0 0.00290 NA beta=(2, 3, 1) FALSE ## 3 1 3 0 0.00579 NA beta=(2, 3, 1) FALSE ## 4 1 4 0 0.00869 NA beta=(2, 3, 1) FALSE ## 5 1 5 0 0.0116 NA beta=(2, 3, 1) FALSE ## 6 1 6 0 0.0145 NA beta=(2, 3, 1) FALSE ## 7 1 7 0 0.0174 NA beta=(2, 3, 1) FALSE ## 8 1 8 0 0.0203 NA beta=(2, 3, 1) FALSE ## 9 1 9 0 0.0232 NA beta=(2, 3, 1) FALSE ## 10 1 10 0 0.0261 NA beta=(2, 3, 1) FALSE ## # … with 4,153,790 more rows
「第1成分の影響」のbeta_1, beta_1_valsとbeta_3, beta_3_valsを入れ換えるように処理します。
「第1成分の影響」のコードで作図できます。
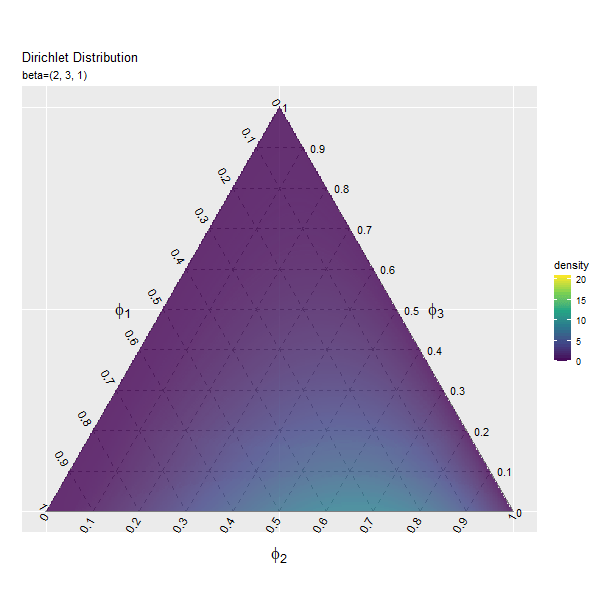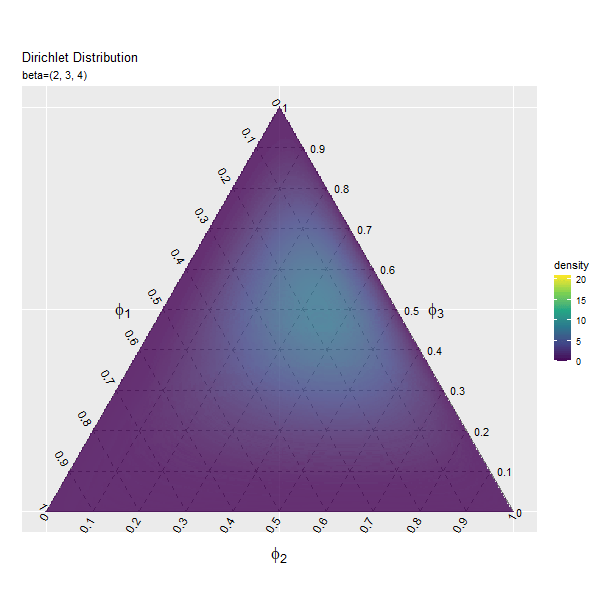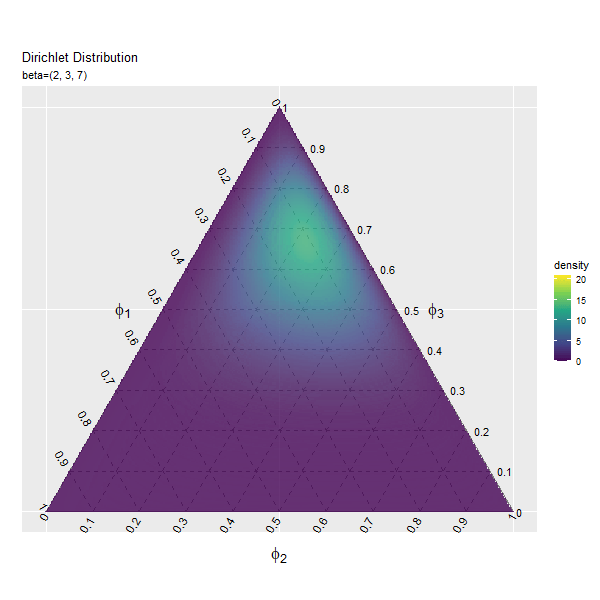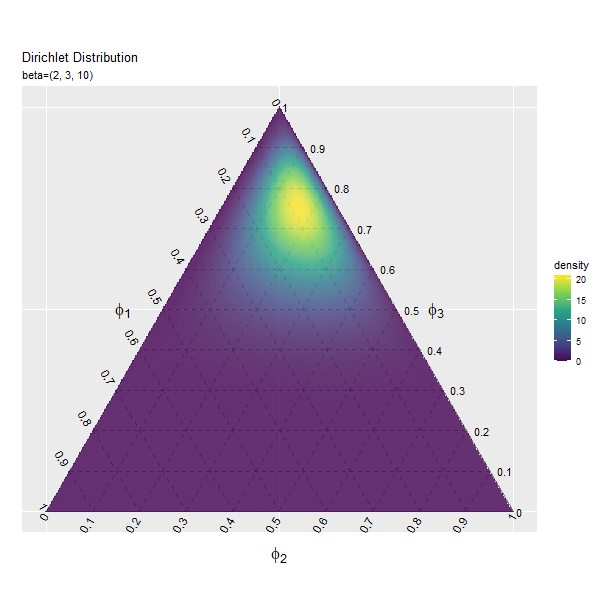
3つの成分の影響
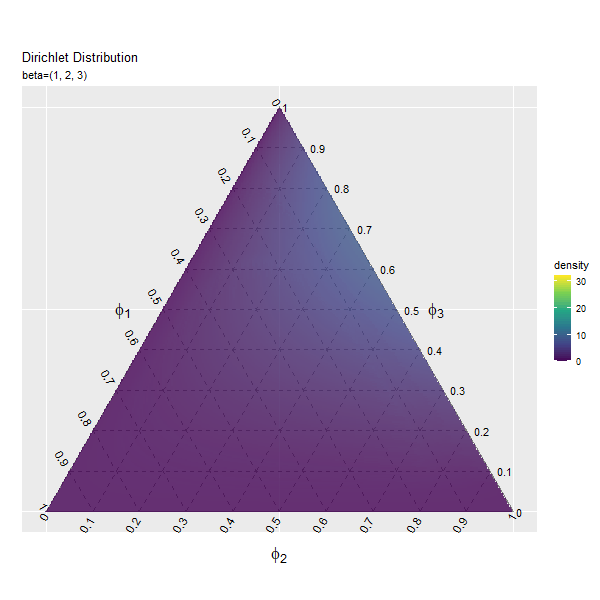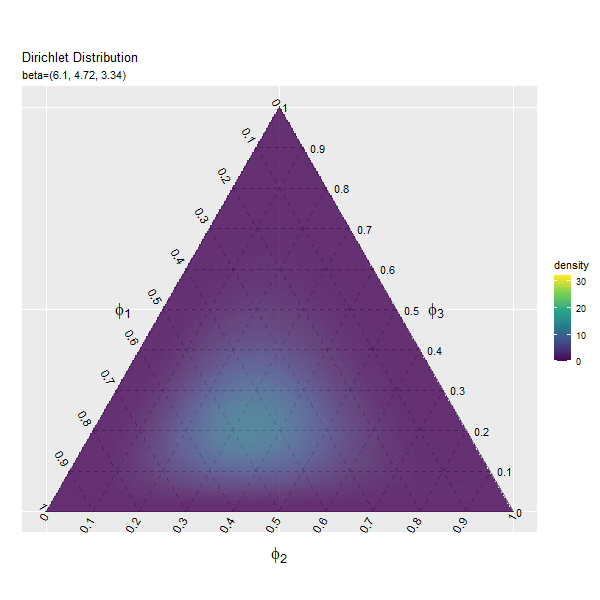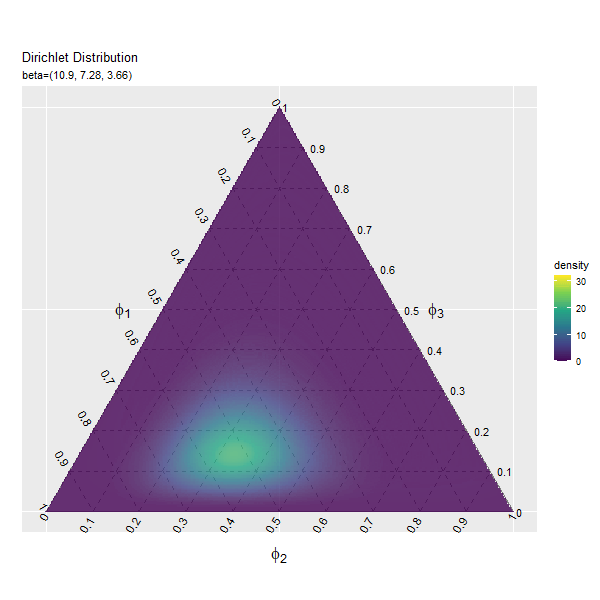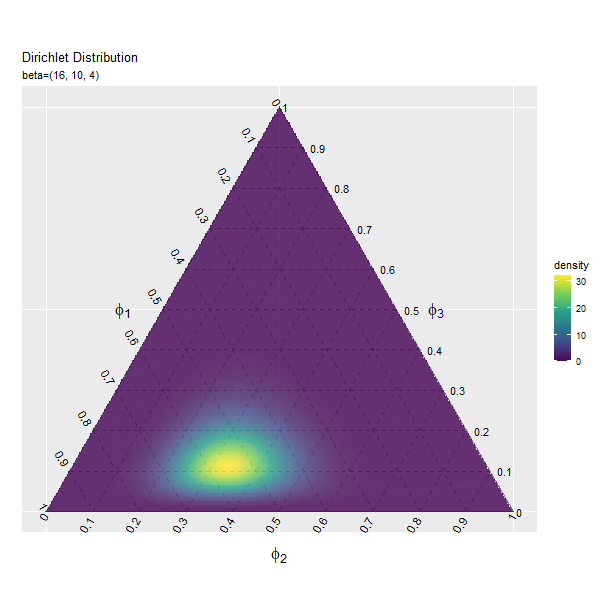
最後に、$\boldsymbol{\beta}$の値を変化させます。
・作図コード(クリックで展開)
# フレーム番号を指定 frame_num <- 51 # パラメータとして利用する値を指定 beta_1_vals <- seq(from = 1, to = 16, length.out = frame_num) |> round(digits = 2) beta_2_vals <- seq(from = 2, to = 10, length.out = frame_num) |> round(digits = 2) beta_3_vals <- seq(from = 3, to = 4, length.out = frame_num) |> round(digits = 2)
3つのbeta_*_valsの要素数が同じになるように値を指定します。
パラメータごとに分布を計算します。
# パラメータごとにディリクレ分布を計算 anime_dens_df <- tidyr::expand_grid( param_i = 1:frame_num, # パラメータ phi_i = 1:nrow(y_mat) # 点番号 ) |> # パラメータごとに格子点を複製 dplyr::group_by(param_i) |> # 分布の計算用にグループ化 dplyr::mutate( y_1 = y_mat[phi_i, 1], y_2 = y_mat[phi_i, 2], beta_1 = beta_1_vals[unique(param_i)], beta_2 = beta_2_vals[unique(param_i)], beta_3 = beta_3_vals[unique(param_i)], density = MCMCpack::ddirichlet( x = phi_mat, alpha = c(unique(beta_1), unique(beta_2), unique(beta_3)) ), # 確率密度 parameter = paste0("beta=(", unique(beta_1), ", ", unique(beta_2), ", ", unique(beta_3), ")") |> factor(levels = paste0("beta=(", beta_1_vals, ", ", beta_2_vals, ", ", beta_3_vals, ")")) # フレーム切替用ラベル ) |> dplyr::mutate( fill_flg = !is.na(rowSums(phi_mat)), density = dplyr::if_else(fill_flg, true = density, false = as.numeric(NA)) ) # 範囲外を非表示化 anime_dens_df
## # A tibble: 4,605,300 × 10 ## # Groups: param_i [51] ## param_i phi_i y_1 y_2 beta_1 beta_2 beta_3 density parameter fill_flg ## <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <fct> <lgl> ## 1 1 1 0 0 1 2 3 0 beta=(1, 2… TRUE ## 2 1 2 0 0.00290 1 2 3 NA beta=(1, 2… FALSE ## 3 1 3 0 0.00579 1 2 3 NA beta=(1, 2… FALSE ## 4 1 4 0 0.00869 1 2 3 NA beta=(1, 2… FALSE ## 5 1 5 0 0.0116 1 2 3 NA beta=(1, 2… FALSE ## 6 1 6 0 0.0145 1 2 3 NA beta=(1, 2… FALSE ## 7 1 7 0 0.0174 1 2 3 NA beta=(1, 2… FALSE ## 8 1 8 0 0.0203 1 2 3 NA beta=(1, 2… FALSE ## 9 1 9 0 0.0232 1 2 3 NA beta=(1, 2… FALSE ## 10 1 10 0 0.0261 1 2 3 NA beta=(1, 2… FALSE ## # … with 4,605,290 more rows
パラメータ番号として1からframe_numまでの整数を作成し、y_matの行番号との全ての組み合わせを作成します。
パラメータ列param_iでグループ化し、param_i列をインデックスとして使ってbeta_*_valsから値を取り出して、phi_matごとに確率密度を計算できます。
「第1成分の影響」のコードで作図できます。
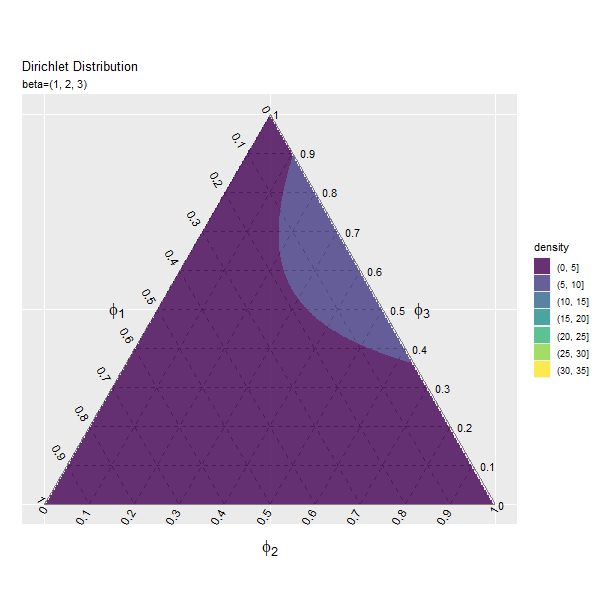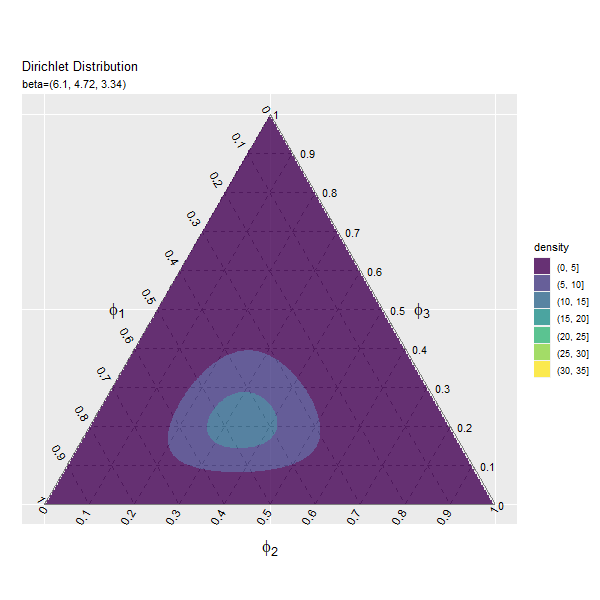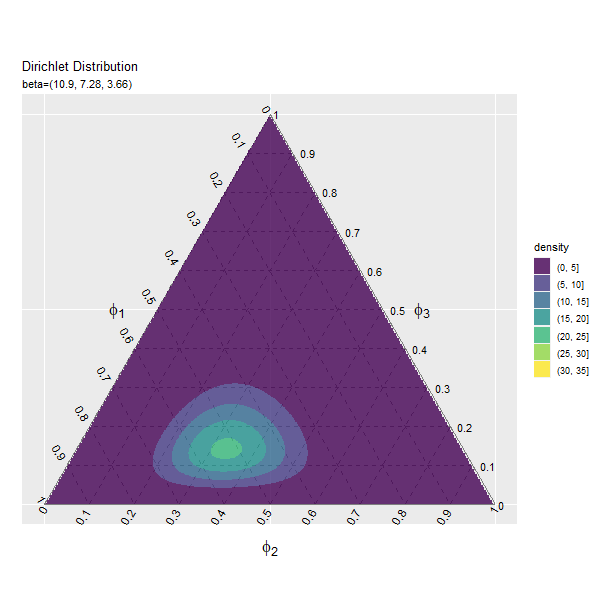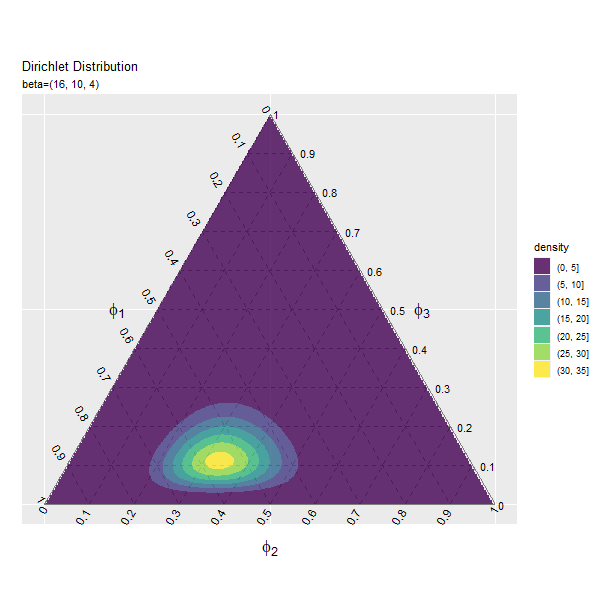
この記事では、ディリクレ分布のグラフを作成しました。次は、乱数を生成します。
参考文献
- 岩田具治『トピックモデル』(機械学習プロフェッショナルシリーズ)講談社,2015年.
おわりに
孵化して最初に見た分布と言っても過言ではないので一番思い入れが強いのですが、素直には可視化できないので後回しにしていました。色々試行錯誤してようやくいい感じにグラフを描けるようになったので記事としてまとめられました。
2022年9月29日は、モーニング娘。の10期メンバーのデビュー11周年記念日です🐥🐥🐥🐥
私が知ったときにはもう凄かったけど、それからもっと凄くなっていて本当に凄く凄い。
【次の内容】