はじめに
機械学習で登場する確率分布について色々な角度から理解したいシリーズです。
この記事では、R言語でベータ分布からのベルヌーイ分布と二項分布を生成します。
【前の内容】
【他の記事一覧】
【この記事の内容】
ベータ分布から確率分布の生成
ベータ分布(Beta Distribution)からベルヌーイ分布(Bernoulli Distribution)と二項分布(Binomial Distribution)を生成します。ベータ分布・ベルヌーイ分布・二項分布についてはそれぞれの記事「確率分布ネタの記事まとめ - からっぽのしょこ」を参照してください。
利用するパッケージを読み込みます。
# 利用するパッケージ library(tidyverse) library(patchwork)
この記事では、基本的にパッケージ名::関数名()の記法を使うので、パッケージを読み込む必要はありません。ただし、作図コードがごちゃごちゃしないようにパッケージ名を省略しているため、ggplot2は読み込む必要があります。
magrittrパッケージのパイプ演算子%>%ではなく、ベースパイプ(ネイティブパイプ)演算子|>を使っています。%>%に置き換えても処理できます。
生成分布の設定
まずは、パラメータの生成分布としてベータ分布を設定して、ベルヌーイ分布と二項分布のパラメータを生成(サンプリング)します。
ベータ分布のパラメータ$\alpha, \beta$とサンプルサイズ$N$を設定します。
# パラメータを指定 alpha <- 5 beta <- 2 # データ数(サンプルサイズ)を指定 N <- 10
$\alpha > 0, \beta > 0$の値とサンプルサイズ(パラメータ数)$N$を指定します。
ベータ分布に従う乱数を生成します。
# ベルヌーイ分布・二項分布のパラメータを生成 phi_n <- rbeta(n = N, shape1 = alpha, shape2 = beta) |> # ベータ分布の乱数を生成 sort() # 昇順に並べ替え # パラメータを格納 param_df <- tibble::tibble( phi = phi_n, label = round(phi, 3) |> factor() # 色分け用ラベル ) param_df
## # A tibble: 10 × 2 ## phi label ## <dbl> <fct> ## 1 0.411 0.411 ## 2 0.468 0.468 ## 3 0.690 0.69 ## 4 0.712 0.712 ## 5 0.769 0.769 ## 6 0.784 0.784 ## 7 0.806 0.806 ## 8 0.855 0.855 ## 9 0.879 0.879 ## 10 0.953 0.953
ベータ分布の乱数生成関数rbeta()のデータ数(サンプルサイズ)の引数nにN、パラメータの引数shape1, shape2にalpha, betaを指定します。
生成した値をベルヌーイ分布と二項分布のパラメータ$\phi$として使います。
ベータ分布を計算します。
# phiがとり得る値を作成 phi_vals <- seq(from = 0, to = 1, length.out = 501) # ベータ分布を計算 beta_df <- tibble::tibble( phi = phi_vals, # 確率変数 density = dbeta(x = phi_vals, shape1 = alpha, shape2 = beta) # 確率密度 ) beta_df
## # A tibble: 501 × 2 ## phi density ## <dbl> <dbl> ## 1 0 0 ## 2 0.002 4.79e-10 ## 3 0.004 7.65e- 9 ## 4 0.006 3.86e- 8 ## 5 0.008 1.22e- 7 ## 6 0.01 2.97e- 7 ## 7 0.012 6.15e- 7 ## 8 0.014 1.14e- 6 ## 9 0.016 1.93e- 6 ## 10 0.018 3.09e- 6 ## # … with 491 more rows
ベータ分布の確率変数がとり得る値$0 \leq \phi \leq 1$を作成して、確率密度を計算します。
ベータ分布の確率密度は、dbeta()で計算できます。確率変数の引数xにphi_vals、パラメータの引数shape1, shape2にalpha, betaを指定します。
phi_valsと、phi_valsの各要素に対応する確率密度をデータフレームに格納します。
ベータ分布の期待値$\mathbb{E}[\phi]$を計算します。
# ベータ分布の期待値を計算 E_phi <- alpha / (alpha + beta) E_phi
## [1] 0.7142857
サンプリングされたパラメータとその分布の基準を示すのに使います。
生成分布(ベータ分布)とパラメータのサンプルをプロットします。
# 生成分布とパラメータのサンプルを作図 beta_graph <- ggplot() + geom_line(data = beta_df, mapping = aes(x = phi, y = density), color = "#00A968", size = 1) + # パラメータの生成分布 geom_point(data = param_df, mapping = aes(x = phi, y = 0, color = label), size = 6, alpha = 0.5, show.legend = FALSE) + # パラメータのサンプル geom_vline(mapping = aes(xintercept = E_phi), color = "red", size = 1, linetype = "dashed") + # labs(title = "Beta Distribution", subtitle = parse(text = paste0("list(alpha==", alpha, ", beta==", beta, ")")), x = expression(phi), y = "density") beta_graph
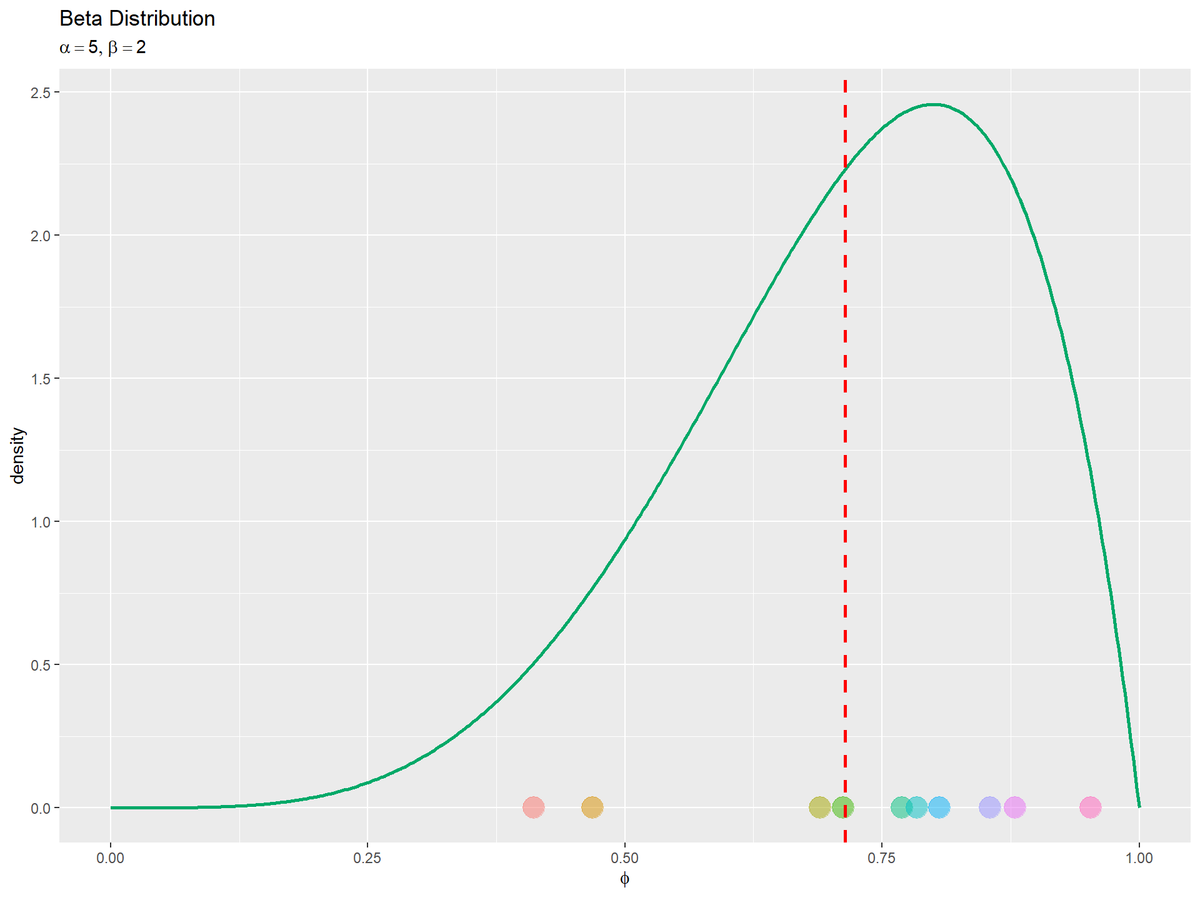
期待値を破線で示します。
以上で、生成分布を設定して、パラメータを生成しました。次は、パラメータのサンプルを用いて、ベルヌーイ分布と二項分布を作図します。
分布の作図:ベルヌーイ分布
次に、生成した値をベルヌーイ分布のパラメータとして利用します。グラフ作成については「【R】ベルヌーイ分布の作図 - からっぽのしょこ」を参照してください。
パラメータのサンプルごとにベルヌーイ分布を計算します。
# xがとり得る値を作成 x_vals <- 0:1 # パラメータのサンプルごとにベルヌーイ分布を計算 res_bern_df <- tidyr::expand_grid( x = x_vals, # 確率変数 phi = phi_n # パラメータ ) |> # 全ての組み合わせを作成 dplyr::arrange(phi, x) |> # パラメータごとに並べ替え dplyr::mutate( probability = dbinom(x = x, size = 1, prob = phi), # 確率 label = round(phi, 3) |> factor() # 色分け用ラベル ) # 確率を計算 res_bern_df
## # A tibble: 20 × 4 ## x phi probability label ## <int> <dbl> <dbl> <fct> ## 1 0 0.411 0.589 0.411 ## 2 1 0.411 0.411 0.411 ## 3 0 0.468 0.532 0.468 ## 4 1 0.468 0.468 0.468 ## 5 0 0.690 0.310 0.69 ## (省略) ## 16 1 0.855 0.855 0.855 ## 17 0 0.879 0.121 0.879 ## 18 1 0.879 0.879 0.879 ## 19 0 0.953 0.0472 0.953 ## 20 1 0.953 0.953 0.953
ベルヌーイ分布の確率変数がとり得る値$x \in {0, 1}$を作成してx_valsとします。
x_valsとphi_nそれぞれの要素の全ての組み合わせをexpand_grid()で作成して、組み合わせごとに確率を計算します。
ベルヌーイ分布の確率は、二項分布の確率関数binom()の試行回数の引数sizeに1を指定すると計算できます。成功回数の引数xにx_valsの値、成功確率の引数probにphi_nの値を指定します。
ベータ分布の期待値(ベルヌーイ分布のパラメータの期待値)を用いて、ベルヌーイ分布を計算します。
# パラメータの期待値によるベルヌーイ分布を計算 E_bern_df <- tibble::tibble( x = x_vals, probability = dbinom(x = x_vals, size = 1, prob = E_phi) ) E_bern_df
## # A tibble: 2 × 2 ## x probability ## <int> <dbl> ## 1 0 0.286 ## 2 1 0.714
prob引数にE_phiを指定します。
$N$個のサンプルによるベルヌーイ分布に、期待値によるベルヌーイ分布を重ねて作図します。
# サンプルと期待値によるベルヌーイ分布を作図 bern_graph <- ggplot() + geom_bar(data = res_bern_df, mapping = aes(x = x, y = probability, fill = label), stat = "identity", show.legend = FALSE) + # サンプルによる分布 geom_bar(data = E_bern_df, mapping = aes(x = x, y = probability), stat = "identity", fill = NA, color = "red", linetype = "dashed") + # 期待値による分布 facet_wrap(. ~ phi, nrow = 2, labeller = label_bquote(phi==.(round(phi, 3)))) + # グラフを分割 scale_x_continuous(breaks = x_vals, labels = x_vals) + # x軸目盛 ylim(c(0, 1)) + # y軸の表示範囲 labs(title = "Bernoulli Distribution", subtitle = parse(text = paste0("E(phi)==", round(E_phi, 3))), fill = expression(phi), x = "x", y = "probability") # ラベル bern_graph
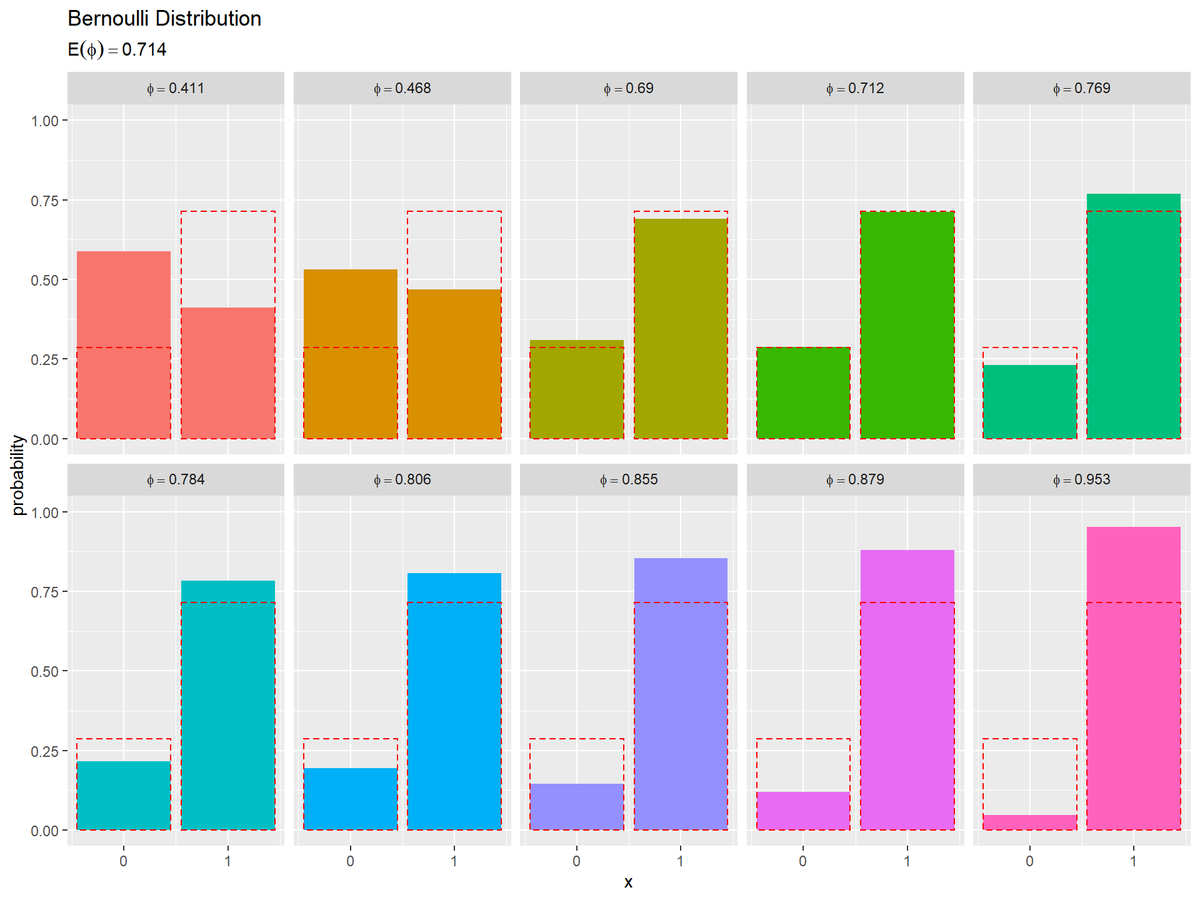
facet_wrap()に列を指定すると、その列の値ごとにグラフを分割して描画できます。
期待値による分布を破線で示します。
パラメータの生成分布(ベータ分布)と生成された分布(ベルヌーイ分布)を並べて描画します。
# グラフを並べて描画 beta_graph / bern_graph
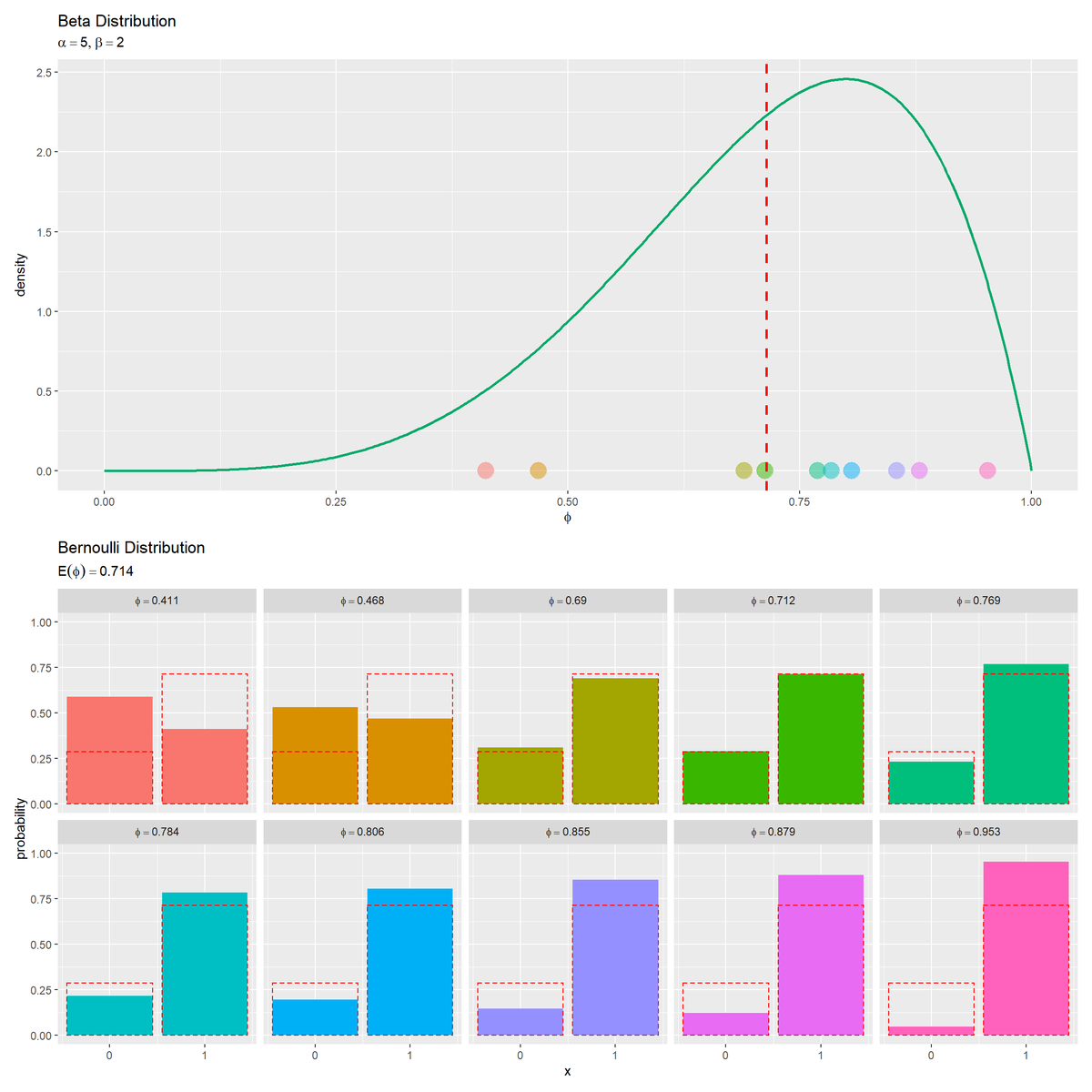
patchworkパッケージの/演算子を使うと上下に並べて描画できます。
$\phi$が0に近いほど$x = 0$となる確率(失敗確率)が高く、$\phi$が1に近いほど$x = 1$となる確率(成功確率)が高くなります。
分布の作図:二項分布
続いて、生成した値を二項分布のパラメータとして利用します。グラフ作成については「【R】二項分布の作図 - からっぽのしょこ」を参照してください。
試行回数$M$を指定して、パラメータのサンプルごとに二項分布を計算します。
# 試行回数を指定 M <- 10 # xがとり得る値を作成 x_vals <- 0:M # パラメータのサンプルごとに二項分布を計算 res_binom_df <- tidyr::expand_grid( x = x_vals, # 確率変数 phi = phi_n # パラメータ ) |> # 全ての組み合わせを作成 dplyr::arrange(phi, x) |> # パラメータごとに並べ替え dplyr::mutate( probability = dbinom(x = x, size = M, prob = phi), label = round(phi, 3) |> factor() # 色分け用ラベル ) # 確率を計算 res_binom_df
## # A tibble: 110 × 4 ## x phi probability label ## <int> <dbl> <dbl> <fct> ## 1 0 0.411 0.00500 0.411 ## 2 1 0.411 0.0349 0.411 ## 3 2 0.411 0.110 0.411 ## 4 3 0.411 0.205 0.411 ## 5 4 0.411 0.250 0.411 ## 6 5 0.411 0.210 0.411 ## 7 6 0.411 0.122 0.411 ## 8 7 0.411 0.0487 0.411 ## 9 8 0.411 0.0128 0.411 ## 10 9 0.411 0.00198 0.411 ## # … with 100 more rows
二項分布の確率変数がとり得る値$x \in {0, 1, \ldots, M}$を作成してx_valsとします。
x_valsとphi_nそれぞれの要素の全ての組み合わせをexpand_grid()で作成して、組み合わせごとに確率を計算します。
二項分布の確率は、binom()で計算できます。成功回数の引数xにx_valsの値、試行回数のsizeにM、成功確率の引数probにphi_nの値を指定します。
ベータ分布の期待値(二項分布のパラメータの期待値)を用いて、二項分布を計算します。
# パラメータの期待値による二項分布を計算 E_binom_df <- tibble::tibble( x = x_vals, probability = dbinom(x = x, size = M, prob = E_phi) ) E_binom_df
## # A tibble: 11 × 2 ## x probability ## <int> <dbl> ## 1 0 0.00000363 ## 2 1 0.0000906 ## 3 2 0.00102 ## 4 3 0.00680 ## 5 4 0.0297 ## 6 5 0.0892 ## 7 6 0.186 ## 8 7 0.266 ## 9 8 0.249 ## 10 9 0.138 ## 11 10 0.0346
prob引数にE_phiを指定します。
$N + 1$個の二項分布を作図します。
# サンプルと期待値による二項分布を作図 binom_graph <- ggplot() + geom_point(data = E_binom_df, mapping = aes(x = x, y = probability), color = "red", size = 3) + # 期待値による分布 geom_line(data = E_binom_df, mapping = aes(x = x, y = probability), color = "red", size = 1, linetype = "dashed") + # 期待値による分布 geom_point(data = res_binom_df, mapping = aes(x = x, y = probability, color = label), size = 3, alpha = 0.5) + # サンプルによる分布 geom_line(data = res_binom_df, mapping = aes(x = x, y = probability, color = label), size = 1, alpha = 0.5) + # サンプルによる分布 scale_x_continuous(breaks = x_vals, labels = x_vals) + # x軸目盛 theme(panel.grid.minor.x = element_blank()) + # 図の体裁 guides(color = guide_legend(override.aes = list(alpha = 1))) + # 凡例の体裁 labs(title = "Binomial Distribution", subtitle = parse(text = paste0("list(E(phi)==", round(E_phi, 3), ", M==", M, ")")), color = expression(phi), x = "x", y = "probability") # タイトル binom_graph
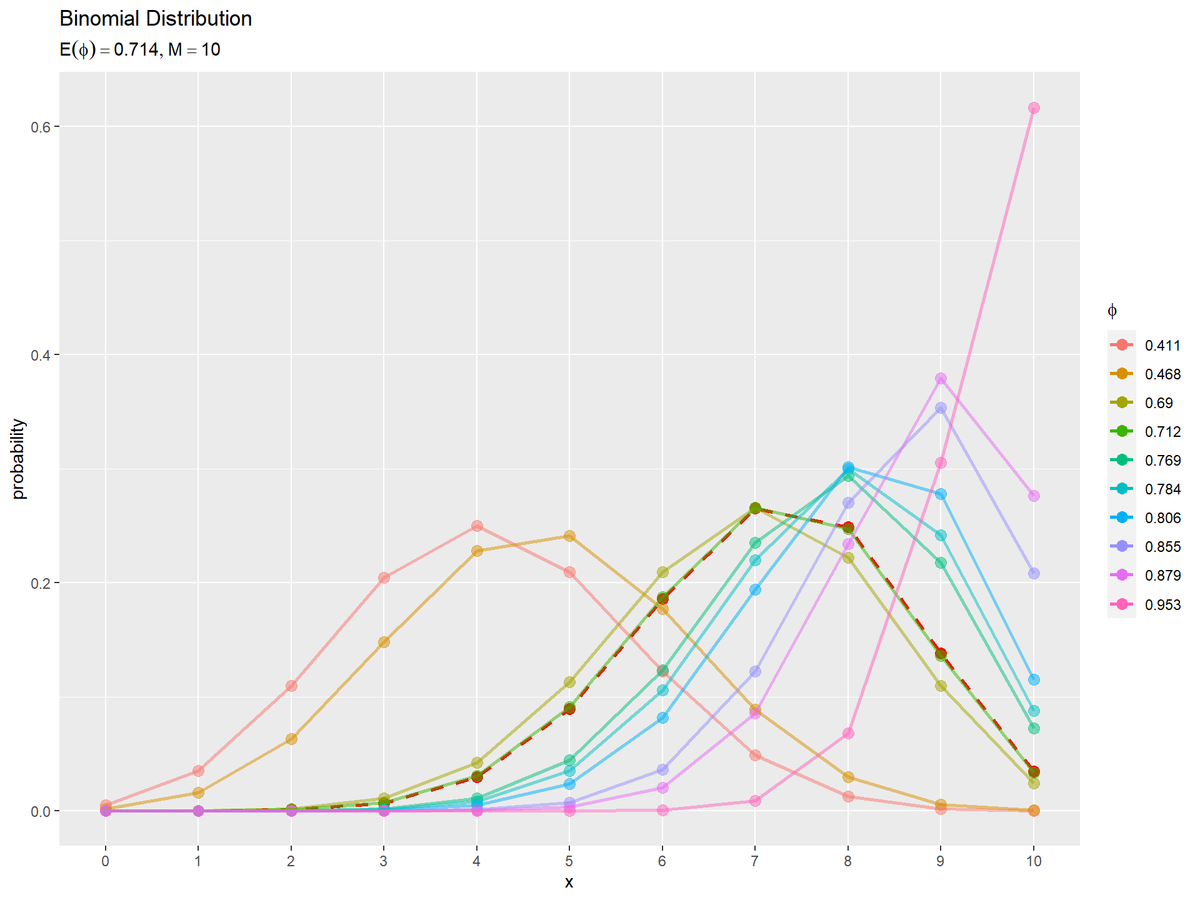
(棒グラフだと分かりにくいので)散布図と折れ線グラフで二項分布を描画します。期待値による分布を破線で示します。
パラメータの生成分布(ベータ分布)と生成された分布(二項分布)を並べて描画します。
# グラフを並べて描画 beta_graph / binom_graph + patchwork::plot_layout(guides = "collect")
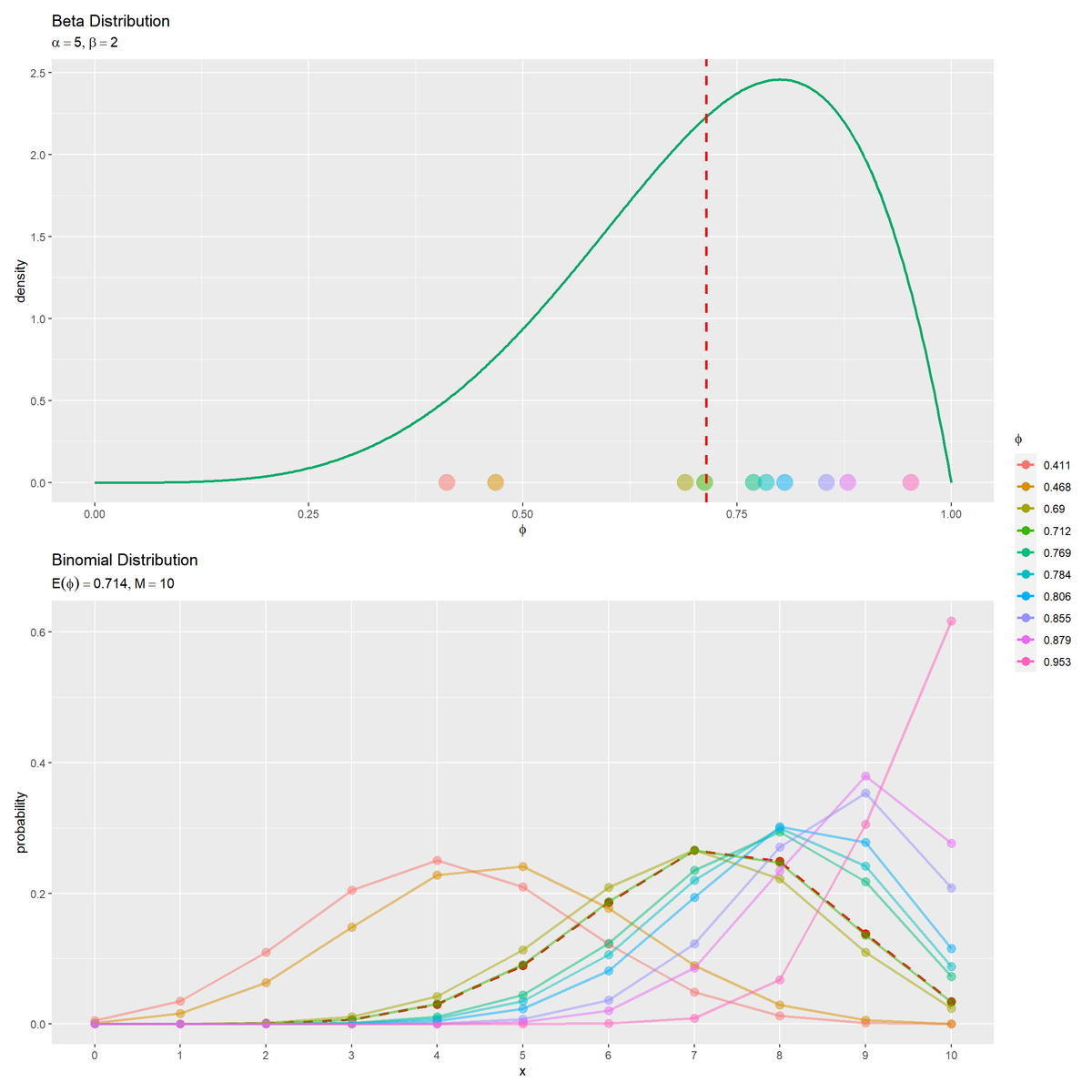
$\phi$が0に近いほど$x$が小さい(失敗回数が多い)確率が高く、$\phi$が1に近いほど$x$が大きい(成功回数が多い)確率が高くなります。
この記事では、ベータ分布からの分布生成を確認しました。
参考文献
- 岩田具治『トピックモデル』(機械学習プロフェッショナルシリーズ)講談社,2015年.
おわりに
思ったよりうまく可視化できて満足しました。このシリーズはグダグダ進めてますが、これを思いつけたので良しとします。
初めてpatchworkパッケージを使いました。gganimateパッケージと組み合わせられないのがもどかしいけど、できたらまたアレコレして進まないからいいのかもしれない。
2022年7月2日は、元Juice=Juiceの金澤朋子さんの27歳のお誕生日です。
突然の引退はまだ残念だけど、これまで続けてくれたことに感謝でいっぱいです。
【次の内容】