はじめに
機械学習で登場する確率分布について色々な角度から理解したいシリーズです。
この記事では、R言語でウィシャート分布から多次元ガウス分布を生成します。
【前の内容】
【他の記事一覧】
【この記事の内容】
ウィシャート分布から確率分布の生成
ウィシャート分布(Wishart Distribution)から多次元ガウス分布(Multivariate Gaussian Distribution)・多変量正規分布(Multivariate Normal Distribution)を生成します。ウィシャート分布については「ウィシャート分布の定義式 - からっぽのしょこ」、ガウス分布については「多次元ガウス分布の定義式 - からっぽのしょこ」を参照してください。
利用するパッケージを読み込みます。
# 利用パッケージ library(tidyverse)
この記事では、基本的にパッケージ名::関数名()の記法を使うので、パッケージを読み込む必要はありません。ただし、作図コードがごちゃごちゃしないようにパッケージ名を省略しているため、ggplot2は読み込む必要があります。
magrittrパッケージのパイプ演算子%>%ではなく、ベースパイプ(ネイティブパイプ)演算子|>を使っています。%>%に置き換えても処理できます。
生成分布の設定
まずは、パラメータの生成分布としてウィシャート分布を設定して、ガウス分布の精度行列(分散共分散行列の逆行列)を生成(サンプリング)します。生成分布を$\mathcal{W}(\boldsymbol{\Lambda}_n | \nu, \mathbf{W})$、生成された分布を$\mathcal{N}(\mathbf{x} | \boldsymbol{\mu}, \boldsymbol{\Lambda}_n^{-1})$で表すことにします。
ウィシャート分布(生成分布)のパラメータ$\nu, \mathbf{W}$とサンプルサイズ$N$を設定します。この例では、2次元のグラフで可視化するため、次元数を$D = 2$とします。分布の生成自体は次元数に関わらず行えます。
# 次元数を指定 D <- 2 # 自由度を指定 nu <- D + 8 # パラメータを指定 w_dd <- matrix(c(6, 0.4, 0.4, 11), nrow = D, ncol = D) # 分布の数(サンプルサイズ)を指定 N <- 9
自由度$\nu$、逆スケール行列$\mathbf{W}$とサンプルサイズ$N$を指定します。
自由度は$\nu > D - 1$、逆スケール行列は$D \times D$の正定値行列を満たす必要があります。
ウィシャート分布に従う乱数を生成します。
# 多次元ガウス分布の分散共分散行列を生成 lambda_ddn <- rWishart(n = N, df = nu, Sigma = w_dd) lambda_ddn[, , 1:3]
## , , 1 ## ## [,1] [,2] ## [1,] 36.90440 -4.72435 ## [2,] -4.72435 27.11654 ## ## , , 2 ## ## [,1] [,2] ## [1,] 60.00848 35.58396 ## [2,] 35.58396 92.92031 ## ## , , 3 ## ## [,1] [,2] ## [1,] 125.53328 -93.97577 ## [2,] -93.97577 148.12655
ウィシャート分布の乱数は、rWishart()で生成できます。データ数の引数nにN、自由度の引数dfにnu、逆スケール行列の引数Sigmaにw_ddを指定します。
生成した値をガウス分布の精度行列$\boldsymbol{\Lambda}_n = (\lambda_{1,1,n}, \cdots, \lambda_{D,D, n})$のN個のサンプルlambda_ddnとします。
分布の作図:多次元ガウス分布
次に、生成した値をガウス分布の精度行列として利用します。ガウス分布のグラフ作成については「【R】2次元ガウス分布の作図 - からっぽのしょこ」、分散共分散行列の固有ベクトルによる軸については「【R】2.3.0:分散共分散行列と固有値・固有ベクトルの関係の計算【PRMLのノート】 - からっぽのしょこ」や「【R】2次元ガウス分布の作図 - からっぽのしょこ」を参照してください。
ガウス分布の平均ベクトル$\boldsymbol{\mu}$を設定します。
# 平均ベクトルを指定 mu_d <- c(0, 0)
平均ベクトル$\boldsymbol{\mu} = (\mu_1, \mu_2)$を指定します。全てのサンプルで共通の値とします。
ウィシャート分布の期待値の逆行列$\mathbb{E}[\boldsymbol{\Sigma}]$を計算します。
# 分散共分散行列の期待値を計算 E_sigma_dd <- solve(nu * w_dd) E_sigma_dd
## [,1] [,2] ## [1,] 0.0167071689 -0.0006075334 ## [2,] -0.0006075334 0.0091130012
ウィシャート分布の期待値(精度行列$\boldsymbol{\Lambda}$の期待値)$\mathbb{E}[\boldsymbol{\Lambda}] = \nu \mathbf{W}$の逆行列をとり、分散共分散行列の期待値$\mathbb{E}[\boldsymbol{\Sigma}] = (\nu \mathbf{W})^{-1}$をE_sigma_dとします。
生成された分布の確率変数の値$\mathbf{x}$を作成します。
# xの値を作成 x_1_vals <- seq( from = mu_d[1] - sqrt(E_sigma_dd[1, 1]) * 3, to = mu_d[1] + sqrt(E_sigma_dd[1, 1]) * 3, length.out = 100 ) x_2_vals <- seq( from = mu_d[2] - sqrt(E_sigma_dd[2, 2]) * 3, to = mu_d[2] + sqrt(E_sigma_dd[2, 2]) * 3, length.out = 100 ) # xの点を作成 x_mat <- tidyr::expand_grid( x_1 = x_1_vals, x_2 = x_2_vals ) |> # 格子点を作成 as.matrix() # マトリクスに変換 head(x_mat)
## x_1 x_2 ## [1,] -0.3877686 -0.2863861 ## [2,] -0.3877686 -0.2806005 ## [3,] -0.3877686 -0.2748150 ## [4,] -0.3877686 -0.2690294 ## [5,] -0.3877686 -0.2632438 ## [6,] -0.3877686 -0.2574582
$x_1$(x軸)の値をx_1_vals、$x_2$(y軸)の値をx_2_valsとします。この例では、それぞれ平均を中心に標準偏差の期待値の3倍を範囲とします。
x_1_valsとx_2_valsの要素の全ての組み合わせ(格子状の点)をexpand_grid()で作成します。データフレームが出力されるので、as.matrix()でマトリクスに変換してx_matとします。x_matの各行が点$\mathbf{x} = (x_1, x_2)$に対応します。
生成分布の期待値(精度行列の期待値)の逆行列$\mathbb{E}[\boldsymbol{\Sigma}]$を用いて、ガウス分布を計算します。
# パラメータの期待値によるガウス分布を計算 E_gaussian_df <- tibble::tibble( x_1 = x_mat[, 1], # x軸の値 x_2 = x_mat[, 2], # y軸の値 density = mvnfast::dmvn(X = x_mat, mu = mu_d, sigma = E_sigma_dd) # 確率密度 ) E_gaussian_df
## # A tibble: 10,000 × 3 ## x_1 x_2 density ## <dbl> <dbl> <dbl> ## 1 -0.388 -0.286 0.00100 ## 2 -0.388 -0.281 0.00121 ## 3 -0.388 -0.275 0.00146 ## 4 -0.388 -0.269 0.00175 ## 5 -0.388 -0.263 0.00209 ## 6 -0.388 -0.257 0.00248 ## 7 -0.388 -0.252 0.00295 ## 8 -0.388 -0.246 0.00348 ## 9 -0.388 -0.240 0.00410 ## 10 -0.388 -0.234 0.00482 ## # … with 9,990 more rows
多次元ガウス分布の確率密度は、mvnfastパッケージのdmvn()で計算できます。確率変数の引数Xにx_mat、平均の引数muにmu_d、共分散の引数sigmaにE_sigma_ddを指定します。
分散共分散行列の期待値$\mathbb{E}[\boldsymbol{\Sigma}]$の固有値と固有ベクトルを計算します。
# 分散共分散行列の期待値の固有値・固有ベクトルを計算 res_eigen <- eigen(E_sigma_dd) E_lambda_d <- res_eigen[["values"]] E_u_dd <- res_eigen[["vectors"]] |> t() E_lambda_d; E_u_dd
## [1] 0.016755464 0.009064706 ## [,1] [,2] ## [1,] -0.99685521 0.07924446 ## [2,] -0.07924446 -0.99685521
固有値$\lambda_1, \lambda_2$と固有ベクトル$\mathbf{u}_1 = (u_{1,1}, u_{1,2}), \mathbf{u}_2 = (u_{2,1}, u_{2,2})$をeigen()で計算します。リストが出力されるので、"values"で固有値(をまとめたベクトル)、"vectors"で固有ベクトル(をまとめたマトリクス)を取り出します。数式での成分と合わせるために転置しておきます。
固有値と固有ベクトルを用いて、ガウス分布の断面の軸を計算します。
# パラメータの期待値によるガウス分布の長軸を計算 E_axis_df <- tibble::tibble( xend = mu_d[1] + E_u_dd[1, 1] * sqrt(E_lambda_d[1]), yend = mu_d[2] + E_u_dd[1, 2] * sqrt(E_lambda_d[1]) ) E_axis_df
## # A tibble: 1 × 2 ## xend yend ## <dbl> <dbl> ## 1 -0.129 0.0103
軸番号を$i$、次元を$j$として、軸の先端の点を$\mu_i + u_{j,i} \sqrt{\lambda_j}$で計算します。ここでは、長い方の軸($i = 1$)のデータフレームに格納します。
ここまでは、パラメータの期待値による分布に関して計算しました。続いて、パラメータのサンプルごとの分布に関して計算します。
パラメータのサンプルごとにガウス分布を計算します。
# パラメータごとにガウス分布を計算 gaussian_df <- tidyr::expand_grid( n = 1:N, # データ番号 x_1 = x_1_vals, x_2 = x_2_vals ) |> # パラメータごとに格子点を複製 dplyr::group_by(n) |> # 分布の計算用にグループ化 dplyr::mutate( density = mvnfast::dmvn( X = x_mat, mu = mu_d, sigma = solve(lambda_ddn[, , unique(n)]) ), # 確率密度 parameter = paste0("(", paste0(round(lambda_ddn[, , unique(n)], 2), collapse = ", "), ")") |> as.factor() # 色分け用ラべル ) |> dplyr::ungroup() # グループ化を解除 gaussian_df
## # A tibble: 90,000 × 5 ## n x_1 x_2 density parameter ## <int> <dbl> <dbl> <dbl> <fct> ## 1 1 -0.388 -0.286 0.173 (36.9, -4.72, -4.72, 27.12) ## 2 1 -0.388 -0.281 0.179 (36.9, -4.72, -4.72, 27.12) ## 3 1 -0.388 -0.275 0.185 (36.9, -4.72, -4.72, 27.12) ## 4 1 -0.388 -0.269 0.191 (36.9, -4.72, -4.72, 27.12) ## 5 1 -0.388 -0.263 0.197 (36.9, -4.72, -4.72, 27.12) ## 6 1 -0.388 -0.257 0.203 (36.9, -4.72, -4.72, 27.12) ## 7 1 -0.388 -0.252 0.209 (36.9, -4.72, -4.72, 27.12) ## 8 1 -0.388 -0.246 0.215 (36.9, -4.72, -4.72, 27.12) ## 9 1 -0.388 -0.240 0.221 (36.9, -4.72, -4.72, 27.12) ## 10 1 -0.388 -0.234 0.227 (36.9, -4.72, -4.72, 27.12) ## # … with 89,990 more rows
パラメータ番号とする1からNの整数と確率変数x_1_vals, x_2_valsの要素の全ての組み合わせをexpand_grid()を作成します。これにより、サンプルごとにx_matを複製できます。
パラメータ列nでグループ化することで、x_matごとに確率密度を計算できます。
dmvn()のX引数にx_mat、mu引数にmu_d、sigma引数にlambda_ddnの値(マトリクス)の逆行列を指定します。
パラメータのサンプルごとにガウス分布の断面の軸を計算します。
# パラメータごとに断面図の軸を計算 axis_df <- tidyr::expand_grid( n = 1:N, # データ番号 name = paste0(rep(c("x", "y"), each = 2, times = 2), rep(c("start", "end"), each = 4)) # 列名 ) |> # パラメータごとに受け皿を複製 dplyr::group_by(n) |> # 軸の計算用にグループ化 dplyr::mutate( axis = rep(c("y_1", "y_2"), times = 4), # pivot_wider用の列 mu = rep(mu_d, each = 2, times = 2), # 平均値 sign = rep(c(-1, 1), each = 4), # 始点・終点の計算用の符号 u = lambda_ddn[, , unique(n)] |> solve() |> (\(.){eigen(.)[["vectors"]]})() |> t() |> (\(.){rep(as.vector(.), times = 2)})(), # 固有ベクトル lambda = lambda_ddn[, , unique(n)] |> solve() |> (\(.){eigen(.)[["values"]]})() |> (\(.){rep(sqrt(.), times = 4)})(), # 固有値の平方根 value = mu + sign * u * lambda, # 軸の始点・終点を計算 parameter = paste0("(", paste0(round(lambda_ddn[, , unique(n)], 2), collapse = ", "), ")") |> as.factor() # 色分け用ラベル ) |> dplyr::ungroup() |> # グループ化を解除 dplyr::select(n, axis, name, value, parameter) |> tidyr::pivot_wider( id_cols = c(n, axis, parameter), names_from = name, values_from = value ) # 軸の視点・終点の列を分割 axis_df
## # A tibble: 18 × 7 ## n axis parameter xstart ystart xend yend ## <int> <chr> <fct> <dbl> <dbl> <dbl> <dbl> ## 1 1 y_1 (36.9, -4.72, -4.72, 27.12) -0.0746 -0.185 0.0746 0.185 ## 2 1 y_2 (36.9, -4.72, -4.72, 27.12) 0.149 -0.0601 -0.149 0.0601 ## 3 2 y_1 (60.01, 35.58, 35.58, 92.92) 0.138 -0.0882 -0.138 0.0882 ## 4 2 y_2 (60.01, 35.58, 35.58, 92.92) 0.0501 0.0783 -0.0501 -0.0783 ## 5 3 y_1 (125.53, -93.98, -93.98, 148… 0.115 0.102 -0.115 -0.102 ## 6 3 y_2 (125.53, -93.98, -93.98, 148… -0.0436 0.0492 0.0436 -0.0492 ## 7 4 y_1 (27, 21.67, 21.67, 63.6) 0.220 -0.102 -0.220 0.102 ## 8 4 y_2 (27, 21.67, 21.67, 63.6) 0.0491 0.106 -0.0491 -0.106 ## 9 5 y_1 (44.07, -11.41, -11.41, 252.… 0.151 0.00827 -0.151 -0.00827 ## 10 5 y_2 (44.07, -11.41, -11.41, 252.… -0.00343 0.0628 0.00343 -0.0628 ## 11 6 y_1 (42.82, -33.43, -33.43, 165.… 0.165 0.0420 -0.165 -0.0420 ## 12 6 y_2 (42.82, -33.43, -33.43, 165.… -0.0186 0.0734 0.0186 -0.0734 ## 13 7 y_1 (58.77, 23.78, 23.78, 137.67) 0.133 -0.0371 -0.133 0.0371 ## 14 7 y_2 (58.77, 23.78, 23.78, 137.67) 0.0223 0.0802 -0.0223 -0.0802 ## 15 8 y_1 (62.17, 25.63, 25.63, 96.63) 0.127 -0.0675 -0.127 0.0675 ## 16 8 y_2 (62.17, 25.63, 25.63, 96.63) 0.0448 0.0840 -0.0448 -0.0840 ## 17 9 y_1 (23.74, -12.34, -12.34, 77.9) 0.213 0.0462 -0.213 -0.0462 ## 18 9 y_2 (23.74, -12.34, -12.34, 77.9) -0.0236 0.109 0.0236 -0.109
上手いことして(もっとスマートな方法を教えて下さい)固有値と固有ベクトルを作成して、断面図の軸を格納したデータフレームを作成します。
先ほどの式で、長軸($i = 1$)と短軸($i = 2$)を計算して、x軸の値の列とy軸の値の列にpivot_wider()で分割します。
N個のガウス分布のグラフを分割して描画します。
# N個のガウス分布を分割して作図 ggplot() + geom_contour_filled(data = gaussian_df, mapping = aes(x = x_1, y = x_2, z = density, fill = ..level..), alpha = 0.8) + # サンプルによる分布 geom_segment(data = axis_df, mapping = aes(x = mu_d[1], y = mu_d[2], xend = xend, yend = yend), color = "pink", size = 1, arrow = arrow(length = unit(10, "pt"))) + # サンプルによる分布の軸 facet_wrap(. ~ parameter, labeller = label_bquote(Lambda==.((as.character(parameter))))) + # グラフの分割 coord_fixed(ratio = 1) + # アスペクト比 labs(title = "Multivariate Gaussian Distribution", subtitle = parse(text = paste0("list(nu==", nu, ", W==(list(", paste0(round(w_dd, 2), collapse = ", "), ")), N==", N, ")")), fill = "density", x = expression(x[1]), y = expression(x[2]))
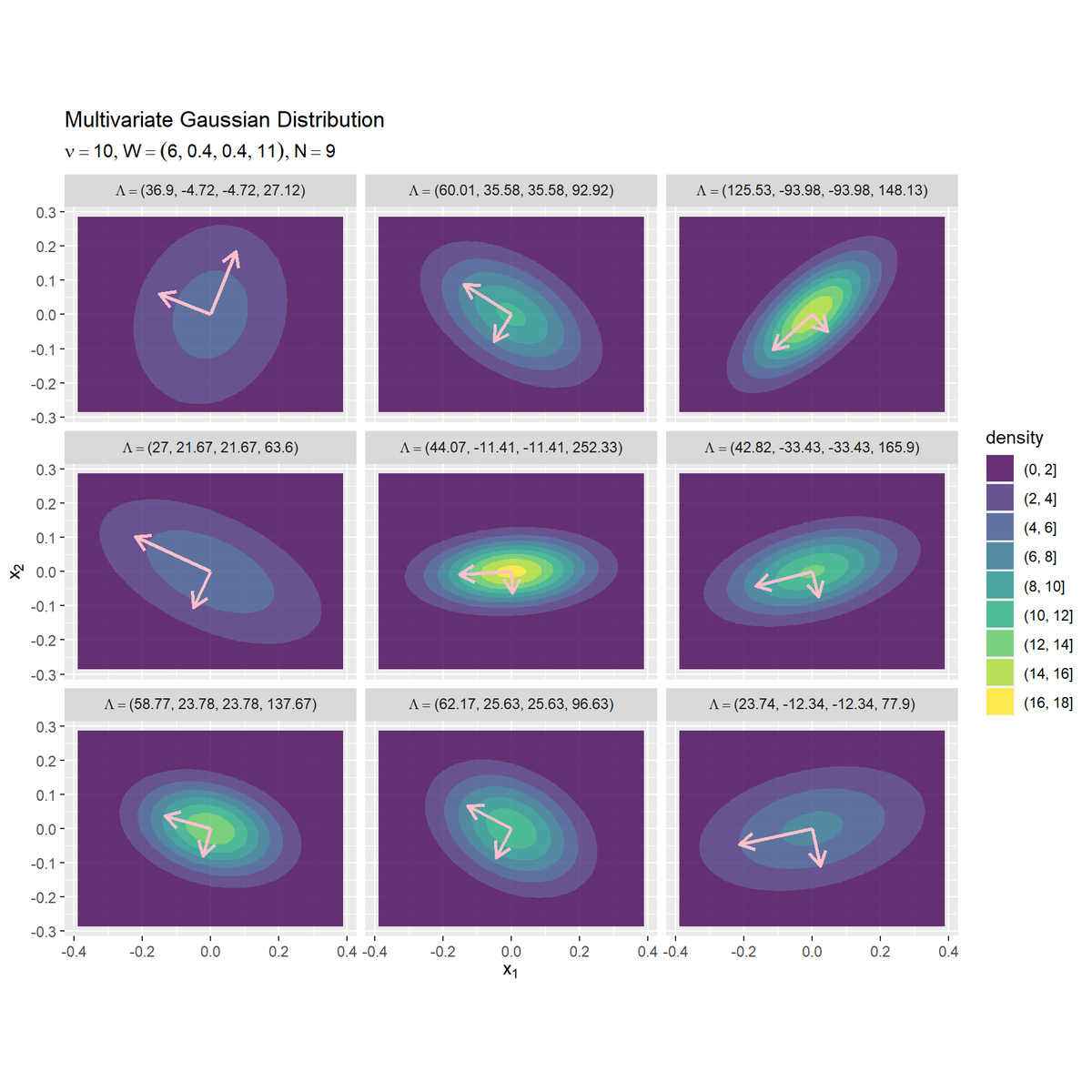
geom_segment()で断面図の軸(線分)を描画します。線分の始点の引数x, yに軸の平均ベクトルの値、終点の引数xend, yendにaxis_dfの値を指定すると、期待値の点から伸びる長さ$\sqrt{\lambda_d}$の固有ベクトルを描画します。
facet_wrap()に列を指定すると、その列の値ごとにグラフを分割して描画できます。
N+1個のガウス分布の楕円を重ねて描画します。
# 期待値による分布の確率密度の最大値を計算 max_dens <- mvnfast::dmvn(X = mu_d, mu = mu_d, sigma = E_sigma_dd) # N+1個のガウス分布の楕円を作図 ggplot() + geom_contour(data = E_gaussian_df, mapping = aes(x = x_1, y = x_2, z = density), breaks = max_dens*exp(-0.5), color ="red", size = 1, linetype = "dashed") + # 期待値による分布 geom_contour(data = gaussian_df, mapping = aes(x = x_1, y = x_2, z = density, color = parameter), breaks = max_dens*exp(-0.5), alpha = 1) + # サンプルによる分布 coord_cartesian(xlim = c(min(x_1_vals), max(x_1_vals)), ylim = c(min(x_2_vals), max(x_2_vals))) + # 描画範囲 labs(title = "Multivariate Gaussian Distribution", subtitle = parse(text = paste0("list(nu==", nu, ", W==(list(", paste0(round(w_dd, 2), collapse = ", "), "))", ", N==", N, ", dens==", round(max_dens*exp(-0.5), 2), ")")), color = expression(Lambda), x = expression(x[1]), y = expression(x[2]))
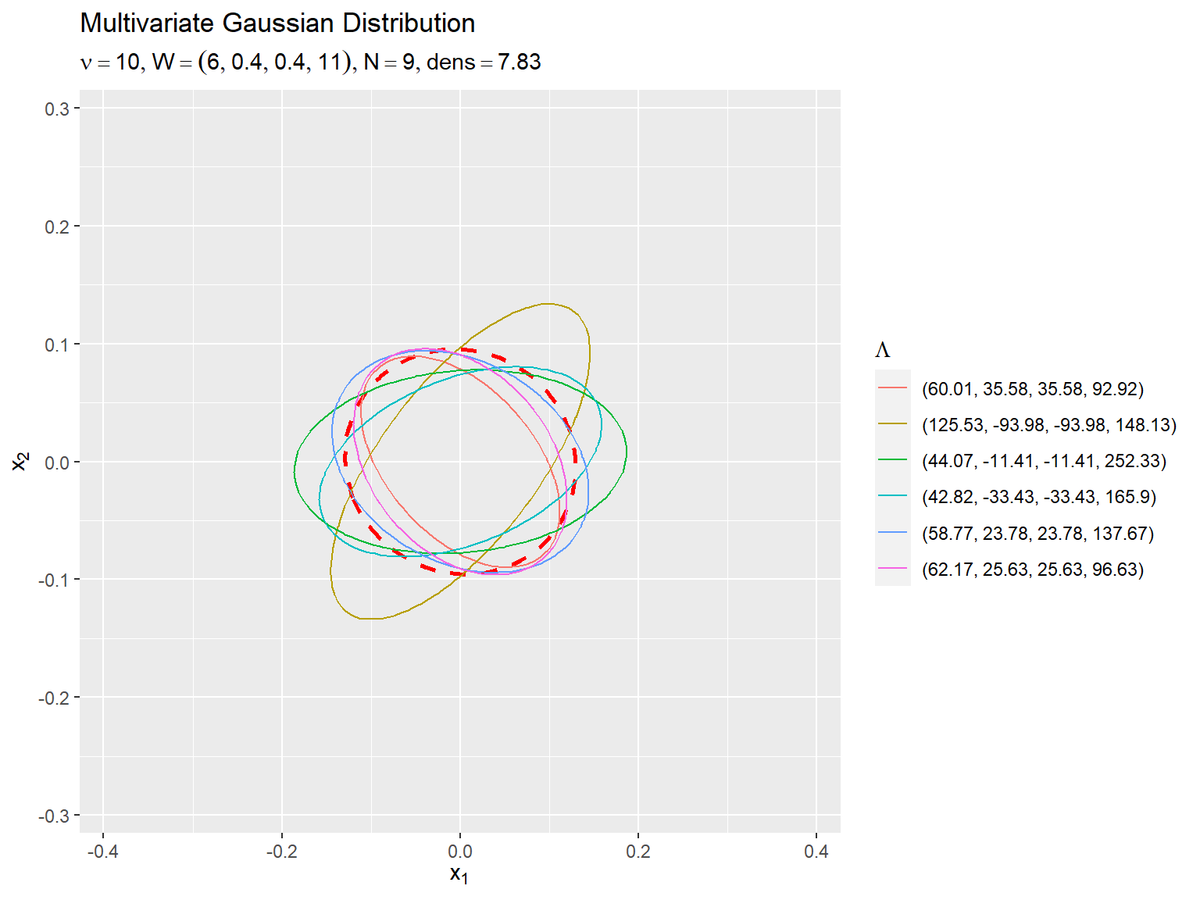
geom_contour()のbreaks引数に値を指定すると、その値で等高線を引きます。この例では目安として、期待値による分布の確率密度の最大値の$\exp(-\frac{1}{2})$倍を指定します。z軸(確率密度)がこの値の面で切断すると断面図(等高線)が軸の先端になります。指定した値を含まない分布の場合は描画されません。
パラメータのサンプルごとにガウス分布の断面の長軸を計算します。
# パラメータごとに断面図の長軸を計算 axis_df <- tibble::tibble( n = 1:N # データ番号 ) |> dplyr::group_by(n) |> # 軸の計算用にグループ化 dplyr::mutate( lambda_1 = lambda_ddn[, , n] |> solve() |> eigen() |> (\(.){.[["values"]][1]})(), # 固有値 u_11 = lambda_ddn[, , n] |> solve() |> eigen() |> (\(.){t(.[["vectors"]])[1, 1]})(), # 固有ベクトルの成分 u_12 = lambda_ddn[, , n] |> solve() |> eigen() |> (\(.){t(.[["vectors"]])[1, 2]})(), # 固有ベクトルの成分 xend = mu_d[1] + u_11 * sqrt(lambda_1), # 終点のx軸の値 yend = mu_d[2] + u_12 * sqrt(lambda_1), # 終点のy軸の値 parameter = paste0("(", paste0(round(lambda_ddn[, , n], 2), collapse = ", "), ")") |> as.factor() # 色分け用ラべル ) |> dplyr::ungroup() # グループ化を解除 axis_df
## # A tibble: 9 × 7 ## n lambda_1 u_11 u_12 xend yend parameter ## <int> <dbl> <dbl> <dbl> <dbl> <dbl> <fct> ## 1 1 0.0397 0.375 0.927 0.0746 0.185 (36.9, -4.72, -4.72, 27.12) ## 2 2 0.0268 -0.843 0.539 -0.138 0.0882 (60.01, 35.58, 35.58, 92.92) ## 3 3 0.0237 -0.748 -0.664 -0.115 -0.102 (125.53, -93.98, -93.98, 148.1… ## 4 4 0.0590 -0.907 0.421 -0.220 0.102 (27, 21.67, 21.67, 63.6) ## 5 5 0.0230 -0.999 -0.0545 -0.151 -0.00827 (44.07, -11.41, -11.41, 252.33) ## 6 6 0.0291 -0.969 -0.246 -0.165 -0.0420 (42.82, -33.43, -33.43, 165.9) ## 7 7 0.0192 -0.963 0.268 -0.133 0.0371 (58.77, 23.78, 23.78, 137.67) ## 8 8 0.0206 -0.883 0.470 -0.127 0.0675 (62.17, 25.63, 25.63, 96.63) ## 9 9 0.0475 -0.977 -0.212 -0.213 -0.0462 (23.74, -12.34, -12.34, 77.9)
重ねて描画すると分かりにくくなるので、こちらは長軸のみを計算します。
N+1個のガウス分布の楕円の長軸を重ねて描画します。
# N+1個のガウス分布の長軸を作図 ggplot() + geom_contour(data = E_gaussian_df, mapping = aes(x = x_1, y = x_2, z = density), breaks = max_dens*exp(-0.5), color ="red", size = 1, linetype = "dashed") + # 期待値による分布 geom_segment(data = E_axis_df, mapping = aes(x = mu_d[1], y = mu_d[2], xend = xend, yend = yend), color = "red", size = 1, linetype = "dashed", arrow = arrow(length = unit(10, "pt"))) + # 期待値による分布の長軸 geom_segment(data = axis_df, mapping = aes(x = mu_d[1], y = mu_d[2], xend = xend, yend = yend, color = parameter), alpha = 1, arrow = arrow(length = unit(10, "pt"))) + # サンプルによる分布の長軸 coord_fixed(ratio = 1, xlim = c(min(x_1_vals), max(x_1_vals)), ylim = c(min(x_2_vals), max(x_2_vals))) + # アスペクト比 labs(title = "Multivariate Gaussian Distribution", subtitle = parse(text = paste0("list(nu==", nu, ", W==(list(", paste0(round(w_dd, 2), collapse = ", "), ")), N==", N, ")")), color = expression(Lambda), x = expression(x[1]), y = expression(x[2]))
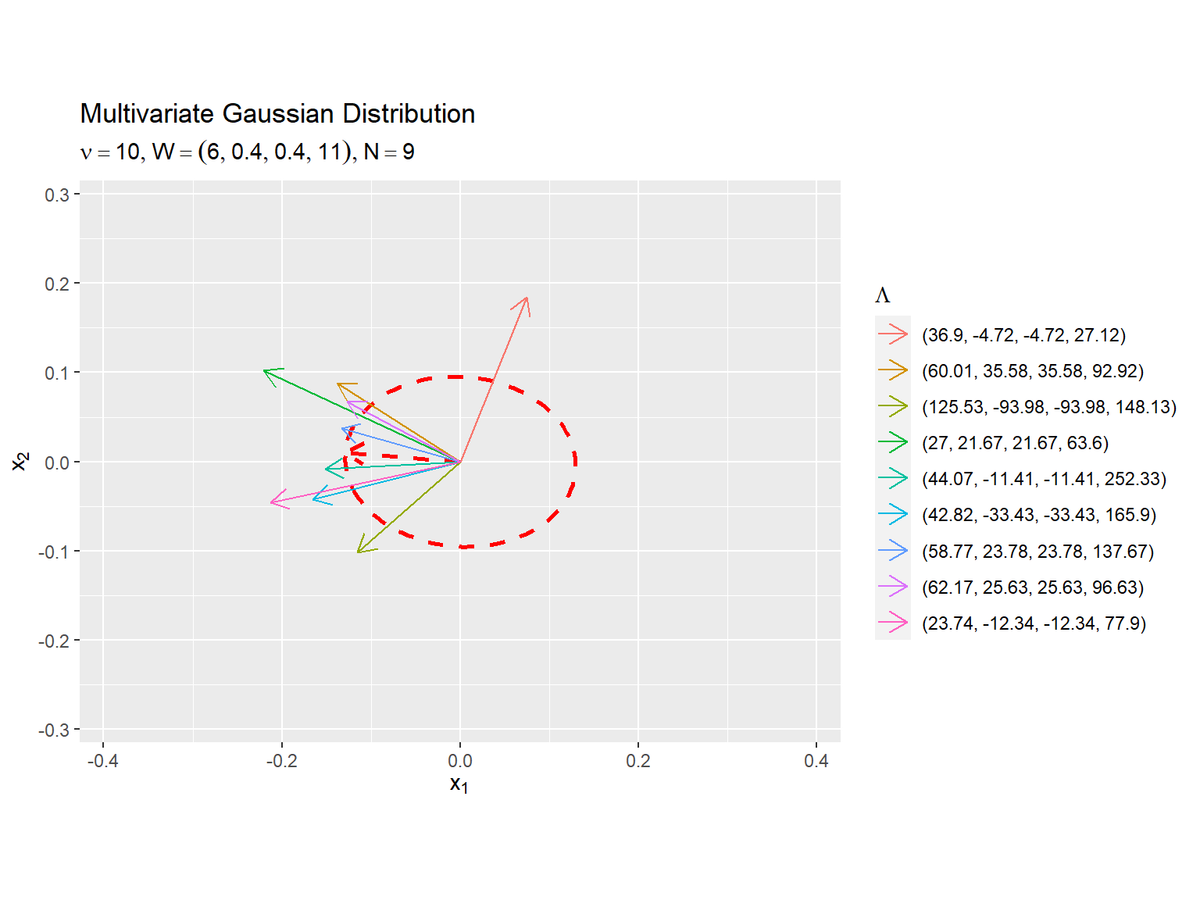
概ね、期待値による分布の軸(赤色の破線の線分)と同じ方向を指しているのが分かります。
この記事では、ウィシャート分布から多次元ガウス分布を生成しました。次は、乱数を用いたマハラノビス距離により可視化します。
参考文献

おわりに
これまでの様に、「生成分布のグラフ上のサンプルの点」と「サンプルによる分布」の対応関係が分かるように可視化できればよかったのですが、ウィシャート分布だと難しかったです。せめて、精度行列か分散共分散行列自体をグラフ化できるといいのですが。
【次の内容】