はじめに
機械学習で登場する確率分布について色々な角度から理解したいシリーズです。
この記事では、ガウス-ガンマ分布(正規-ガンマ分布)の乱数を生成します。
【前の内容】
【他の記事一覧】
【この記事の内容】
ガウス-ガンマ分布の乱数生成
ガウス-ガンマ分布(Gaussian-Gamma Distribution)または正規-ガンマ分布(Normal-Gamma Distribution)に従う乱数を生成します。ガウス-ガンマ分布については「ガウス-ガンマ分布の定義式 - からっぽのしょこ」を参照してください。
利用するパッケージを読み込みます。
# 利用パッケージ library(tidyverse) library(gganimate)
この記事では、基本的にパッケージ名::関数名()の記法を使うので、パッケージを読み込む必要はありません。ただし、作図コードがごちゃごちゃしないようにパッケージ名を省略しているため、ggplot2は読み込む必要があります。
magrittrパッケージのパイプ演算子%>%ではなく、ベースパイプ(ネイティブパイプ)演算子|>を使っています。%>%に置き換えても処理できます。
分布の変化をアニメーション(gif画像)で確認するのにgganimateパッケージを利用します。不要であれば省略してください。
サンプリング
まずは、ガウス-ガンマ分布の乱数を生成します。1次元ガウス分布の乱数については「【R】1次元ガウス分布の乱数生成 - からっぽのしょこ」、ガンマ分布の乱数については「【R】ガンマ分布の乱数生成 - からっぽのしょこ」を参照してください。
ガウス-ガンマ分布のパラメータ$m, \beta, a, b$とデータ数$N$を設定します。
# ガウス分布の平均パラメータを指定 m <- 0 # ガウス分布の精度パラメータの係数を指定 beta <- 2 # ガンマ分布のパラメータを指定 a <- 5 b <- 6 # データ数(サンプルサイズ)を指定 N <- 10000
ガウス分布の平均パラメータ$m$と精度パラメータの係数$\beta > 0$、ガンマ分布の形状パラメータ$a > 0$と尺度パラメータ$b > 0$、データ数(サンプルサイズ)$N$を指定します。
ガウス-ガンマ分布に従う乱数を生成します。
# ガンマ分布に従う乱数を生成 lambda_n <- rgamma(n = N, shape = a, rate = b) # ガウス分布に従う乱数を生成 mu_n <- rnorm(n = N, mean = m, sd = 1/sqrt(beta*lambda_n)) # サンプルを格納 data_df <- tidyr::tibble( mu = mu_n, # μのサンプル lambda = lambda_n # λのサンプル ) data_df
## # A tibble: 10,000 × 2 ## mu lambda ## <dbl> <dbl> ## 1 -0.412 0.316 ## 2 1.95 0.520 ## 3 -0.910 0.425 ## 4 0.116 0.845 ## 5 0.175 0.851 ## 6 -0.108 1.03 ## 7 0.350 0.477 ## 8 1.21 0.656 ## 9 -0.514 0.221 ## 10 1.03 0.691 ## # … with 9,990 more rows
先にガンマ分布の乱数を生成して、生成した乱数を精度パラメータ(に比例する値)$\lambda$としてガウス分布の乱数を生成します。
ガンマ分布の乱数は、rgamma()で生成できます。データ数の引数nにN、形状の引数shapeにa、尺度の引数rateにbを指定します。
ガウス分布の乱数は、rnorm()で生成できます。データ数の引数nにN、平均の引数meanにm、標準偏差の引数sdにbetaとlambda_nの積の平方根の逆数を指定します。
ガウス-ガンマ分布がとり得る値$\mu, \lambda$を作成して、$\mu, \lambda$の格子点ごとに確率密度を計算します。
# μの値を作成 mu_vals <- seq( from = m - 1/sqrt(beta*a/b) * 4, to = m + 1/sqrt(beta*a/b) * 4, length.out = 200 ) # λの値を作成 lambda_vals <- seq(from = 0, to = a/b * 3, length.out = 200) # ガウス-ガンマ分布を計算 dens_df <- tidyr::expand_grid( mu = mu_vals, # 確率変数μ lambda = lambda_vals # 確率変数λ ) |> # 確率変数(μとλの格子点)を作成 dplyr::mutate( N_dens = dnorm(x = mu, mean = m, sd = 1/sqrt(beta*lambda)), # μの確率密度 Gam_dens = dgamma(x = lambda, shape = a, rate = b), # λの確率密度 density = N_dens * Gam_dens # 確率密度 ) dens_df
## # A tibble: 40,000 × 5 ## mu lambda N_dens Gam_dens density ## <dbl> <dbl> <dbl> <dbl> <dbl> ## 1 -3.10 0 0 0 0 ## 2 -3.10 0.0126 0.0561 0.00000748 0.000000420 ## 3 -3.10 0.0251 0.0703 0.000111 0.00000780 ## 4 -3.10 0.0377 0.0763 0.000521 0.0000398 ## 5 -3.10 0.0503 0.0781 0.00153 0.000119 ## 6 -3.10 0.0628 0.0774 0.00346 0.000268 ## 7 -3.10 0.0754 0.0751 0.00665 0.000500 ## 8 -3.10 0.0879 0.0719 0.0114 0.000822 ## 9 -3.10 0.101 0.0682 0.0181 0.00123 ## 10 -3.10 0.113 0.0641 0.0269 0.00172 ## # … with 39,990 more rows
詳しくは「【R】ガウス-ガンマ分布の作図 - からっぽのしょこ」を参照してください。
乱数の可視化
続いて、生成した乱数のグラフを作成します。
サンプルの散布図を確率分布と重ねて作成します。
# サンプルの散布図を作成 ggplot() + geom_point(data = data_df, mapping = aes(x = mu, y = lambda), color = "orange", alpha = 0.5) + # サンプル geom_contour(data = dens_df, mapping = aes(x = mu, y = lambda, z = density, color = ..level..)) + # 元の分布 labs(title = "Gaussian-Gamma Distribution", subtitle = parse(text = paste0("list(m==", m, ", beta==", beta, ", a==", a, ", b==", b, ", N==", N, ")")), color = "density", x = expression(mu), y = expression(lambda)) # ラベル

サンプルの度数のヒートマップを作成します。
# サンプルのヒストグラムを作成:度数 ggplot() + geom_bin_2d(data = data_df, mapping = aes(x = mu, y = lambda, fill = ..count..), alpha = 0.8) + # サンプル geom_contour(data = dens_df, mapping = aes(x = mu, y = lambda, z = density, color = ..level..)) + # 元の分布 scale_fill_distiller(palette = "Spectral") + # 塗りつぶしの色 scale_color_distiller(palette = "Spectral") + # 等高線の色 labs(title = "Gaussian-Gamma Distribution", subtitle = parse(text = paste0("list(m==", m, ", beta==", beta, ", a==", a, ", b==", b, ", N==", N, ")")), fill = "frequency", color = "density", x = expression(mu), y = expression(lambda)) # ラベル

geom_bin_2d()で2次元の変数に対するヒートマップを描画できます。タイルの色の引数fillに..count..を指定すると度数、..density..を指定すると密度に応じて色付けされます。
密度の等高線図を作成します。
# サンプルのヒストグラムを作成:密度 ggplot() + geom_density_2d_filled(data = data_df, mapping = aes(x = mu, y = lambda, fill = ..level..), alpha = 0.8) + # サンプル geom_contour(data = dens_df, mapping = aes(x = mu, y = lambda, z = density, color = ..level..)) + # 元の分布 scale_color_viridis_c(option = "D") + # 等高線の色 labs(title = "Gaussian-Gamma Distribution", subtitle = paste0("m=", m, ", beta=", beta, ", a=", a, ", b=", b, ", N=", N), fill = "density", color = "density", x = expression(mu), y = expression(lambda)) # ラベル

geom_density_2d_filled()で密度の等高線図を描画できます。
データ数が十分に増えると、ヒストグラムの形が分布の形に近付きます。
乱数と分布の関係をアニメーションで可視化
次は、サンプルサイズとヒストグラムの形状の関係をアニメーションで確認します。
1データずつ可視化
1データずつ乱数を生成するアニメーションを作成します。
・作図コード(クリックで展開)
パラメータ$m, \beta, a, b$とデータ数$N$を指定して、ガウス-ガンマ分布の乱数を生成します。
# ガウス分布の平均パラメータを指定 m <- 0 # ガウス分布の精度パラメータの係数を指定 beta <- 2 # ガンマ分布のパラメータを指定 a <- 5 b <- 6 # データ数(フレーム数)を指定 N <- 100 # ガンマ分布に従う乱数を生成 lambda_n <- rgamma(n = N, shape = a, rate = b) # ガウス分布に従う乱数を生成 mu_n <- rnorm(n = N, mean = m, sd = 1/sqrt(beta*lambda_n)) head(mu_n); head(lambda_n)
## [1] -1.35356449 -1.56200355 -2.28947587 0.41861164 0.07763862 1.77409005 ## [1] 0.7231435 0.7438824 0.2414799 1.6562908 1.4599007 0.5077297
mu_n, lambda_nのn番目の要素を、n番目のデータ(n回目にサンプリングされた値)とみなします。アニメーションのn番目のフレームでは、n個のサンプルmu_n[1:n], lambda_n[1:n]のグラフを描画します。
サンプルをデータフレームに格納します。
# サンプルを格納 anime_data_df <- tibble::tibble( n = 1:N, # データ番号 mu = mu_n, # μのサンプル lambda = lambda_n, # λのサンプル parameter = paste0("m=", m, ", beta=", beta, ", a=", a, ", b=", b, ", N=", 1:N) |> factor(levels = paste0("m=", m, ", beta=", beta, ", a=", a, ", b=", b, ", N=", 1:N)) # フレーム切替用ラベル ) anime_data_df
## # A tibble: 100 × 4 ## n mu lambda parameter ## <int> <dbl> <dbl> <fct> ## 1 1 -1.35 0.723 m=0, beta=2, a=5, b=6, N=1 ## 2 2 -1.56 0.744 m=0, beta=2, a=5, b=6, N=2 ## 3 3 -2.29 0.241 m=0, beta=2, a=5, b=6, N=3 ## 4 4 0.419 1.66 m=0, beta=2, a=5, b=6, N=4 ## 5 5 0.0776 1.46 m=0, beta=2, a=5, b=6, N=5 ## 6 6 1.77 0.508 m=0, beta=2, a=5, b=6, N=6 ## 7 7 -0.131 0.666 m=0, beta=2, a=5, b=6, N=7 ## 8 8 -0.559 0.670 m=0, beta=2, a=5, b=6, N=8 ## 9 9 0.688 1.52 m=0, beta=2, a=5, b=6, N=9 ## 10 10 -1.91 0.312 m=0, beta=2, a=5, b=6, N=10 ## # … with 90 more rows
$\mu$のサンプルmu_nと$\lambda$のサンプルlambda_nをデータフレームに格納して、フレーム切替用のラベルを作成します。ラベルが文字列型だと文字列の基準で順序が決まるので、因子型にしてサンプリング回数に応じたレベル(順序)を設定します。
このデータフレームは、各試行におけるサンプルを描画するのに使います。
サンプリング回数ごとに、それまでのサンプルを持つデータフレームを作成します。
# サンプルを複製して格納 anime_freq_df <- tidyr::expand_grid( frame = 1:N, # フレーム番号 n = 1:N # データ番号 ) |> # 全ての組み合わせを作成 dplyr::filter(n <= frame) |> # 各フレームで利用するサンプルを抽出 dplyr::mutate( mu = mu_n[n], # μのサンプル lambda = lambda_n[n], # λのサンプル parameter = paste0("m=", m, ", beta=", beta, ", a=", a, ", b=", b, ", N=", frame) |> factor(levels = paste0("m=", m, ", beta=", beta, ", a=", a, ", b=", b, ", N=", 1:N)) # フレーム切替用ラベル ) anime_freq_df
## # A tibble: 5,050 × 5 ## frame n mu lambda parameter ## <int> <int> <dbl> <dbl> <fct> ## 1 1 1 -1.35 0.723 m=0, beta=2, a=5, b=6, N=1 ## 2 2 1 -1.35 0.723 m=0, beta=2, a=5, b=6, N=2 ## 3 2 2 -1.56 0.744 m=0, beta=2, a=5, b=6, N=2 ## 4 3 1 -1.35 0.723 m=0, beta=2, a=5, b=6, N=3 ## 5 3 2 -1.56 0.744 m=0, beta=2, a=5, b=6, N=3 ## 6 3 3 -2.29 0.241 m=0, beta=2, a=5, b=6, N=3 ## 7 4 1 -1.35 0.723 m=0, beta=2, a=5, b=6, N=4 ## 8 4 2 -1.56 0.744 m=0, beta=2, a=5, b=6, N=4 ## 9 4 3 -2.29 0.241 m=0, beta=2, a=5, b=6, N=4 ## 10 4 4 0.419 1.66 m=0, beta=2, a=5, b=6, N=4 ## # … with 5,040 more rows
フレーム番号とデータ番号(それぞれ1からNの整数)の全ての組み合わせをexpand_grid()で作成して、フレーム番号以下のデータ番号を抽出します。
データ番号をインデックスとして使って、mu_n, lambdanから対応するサンプルを抽出します。
フレーム番号をデータ番号として、フレーム切替用のラベルを作成します。
このデータフレームは、ヒートマップなどのグラフを描画するのに使います。
サンプルの散布図のグラフに重ねてアニメーション(gif画像)を作成します。
# 散布図のアニメーションを作図 anime_freq_graph <- ggplot() + geom_contour(data = dens_df, mapping = aes(x = mu, y = lambda, z = density, color = ..level..)) + # 元の分布 geom_point(data = anime_freq_df, mapping = aes(x = mu, y = lambda), color = "orange", alpha = 0.5, size = 3) + # n個のサンプル geom_point(data = anime_data_df, mapping = aes(x = mu, y = lambda), color = "orange", size = 6) + # n番目のサンプル gganimate::transition_manual(parameter) + # フレーム labs(title = "Gaussian-Gamma Distribution", subtitle = "{current_frame}", color = "density", x = expression(mu), y = expression(lambda)) # ラベル # gif画像を作成 gganimate::animate(anime_freq_graph, nframes = N, fps = 10, width = 800, height = 600)
transition_manual()にフレームの順序を表す列を指定します。この例では、因子型のラベルのレベルの順に描画されます。
animate()のフレーム数の引数nframesにデータ数(サンプルサイズ)、フレームレートの引数fpsに1秒当たりのフレーム数を指定します。fps引数の値が大きいほどフレームが早く切り替わります。ただし、値が大きいと指定した通りに動作しません。
サンプルの度数のヒートマップのアニメーションを作成します。
# メッシュ用の値を設定 mu_breaks <- seq(from = min(mu_vals), to = max(mu_vals), length.out = 30) lambda_breaks <- seq(from = min(lambda_vals), to = max(lambda_vals), length.out = 30) # 度数のヒートマップのアニメーションを作図 anime_freq_graph <- ggplot() + geom_bin_2d(data = anime_freq_df, mapping = aes(x = mu, y = lambda, fill = ..count..), breaks = list(x = mu_breaks, y = lambda_breaks), alpha = 0.8) + # n個のサンプル geom_contour(data = dens_df, mapping = aes(x = mu, y = lambda, z = density, color = ..level..)) + # 元の分布 geom_point(data = anime_data_df, mapping = aes(x = mu, y = lambda), color = "orange", size = 6) + # n番目のサンプル gganimate::transition_manual(parameter) + # scale_fill_distiller(palette = "Spectral") + # 塗りつぶしの色 scale_color_distiller(palette = "Spectral") + # 等高線の色 labs(title = "Gaussian-Gamma Distribution", subtitle = "{current_frame}", fill = "frequency", color = "density", x = expression(mu), y = expression(lambda)) # ラベル # gif画像を作成 gganimate::animate(anime_freq_graph, nframes = N, fps = 10, width = 800, height = 600)
集計範囲(メッシュ)を固定するために、geom_bin_2d()のbreaks引数に区切り位置を指定します。x軸とy軸を分けて指定する場合は、リストにして渡します。この例では、mu_vals, lambda_valsそれぞれの最小値から最大値の範囲を30分割します。(指定しなくてもよしなにしてくれるっぽい?)
サンプルの密度の等高線のアニメーションを作成します。
# (データが少ないと密度を計算できないため)最初のフレームを除去 n_min <- 10 tmp_data_df <- anime_data_df|> dplyr::filter(n > n_min) |> # 始めのデータを削除 dplyr::mutate( parameter = parameter |> as.character() |> (\(.){factor(., levels = unique(.))})() # レベルを再設定 ) tmp_freq_df <- anime_freq_df |> dplyr::filter(frame > n_min) |> # 始めのデータを削除 dplyr::mutate( parameter = parameter |> as.character() |> (\(.){factor(., levels = unique(.))})() # レベルを再設定 ) # 密度の等高線のアニメーションを作図 anime_freq_graph <- ggplot() + geom_density_2d_filled(data = tmp_freq_df, mapping = aes(x = mu, y = lambda, fill = ..level..), alpha = 0.8) + # n個のサンプル geom_contour(data = dens_df, mapping = aes(x = mu, y = lambda, z = density, color = ..level..)) + # 元の分布 geom_point(data = tmp_data_df, mapping = aes(x = mu, y = lambda), color = "orange", size = 6) + # n番目のサンプル gganimate::transition_manual(parameter) + # scale_color_viridis_c(option = "D") + # 等高線の色 labs(title = "Gaussian-Gamma Distribution", subtitle = "{current_frame}", fill = "density", color = "density", x = expression(mu), y = expression(lambda)) # ラベル # gif画像を作成 gganimate::animate(anime_freq_graph, nframes = N-n_min, fps = 10, width = 800, height = 600)
データが1つだと密度を計算できず、またデータが少ないと密度が大きくなり(z軸の最大値が大きくなり)アニメーション全体でのグラデーション(等高線)が分かりにくくなるので、始めのフレームに対応する行を取り除いておきます。
データフレームからデータを除いても、因子レベルの情報がアニメーションのフレームに影響してしまうので、因子の情報を再設定する必要があります。

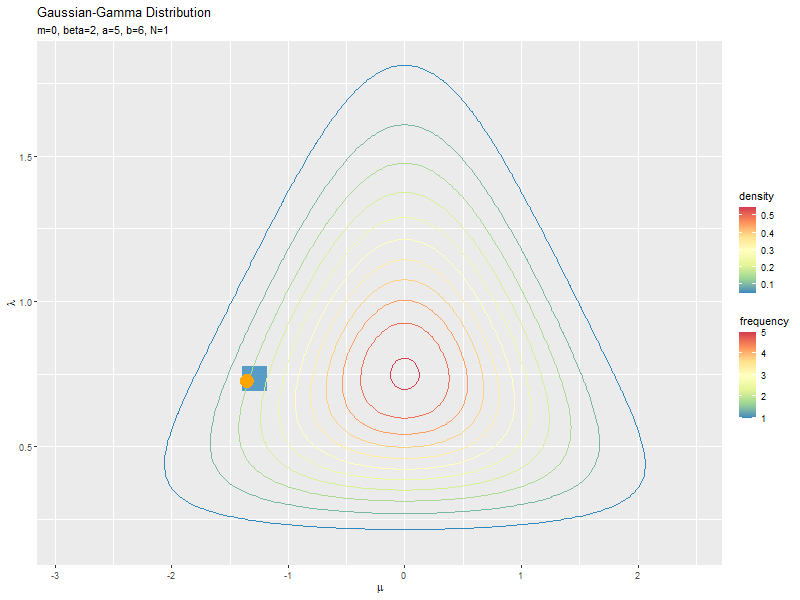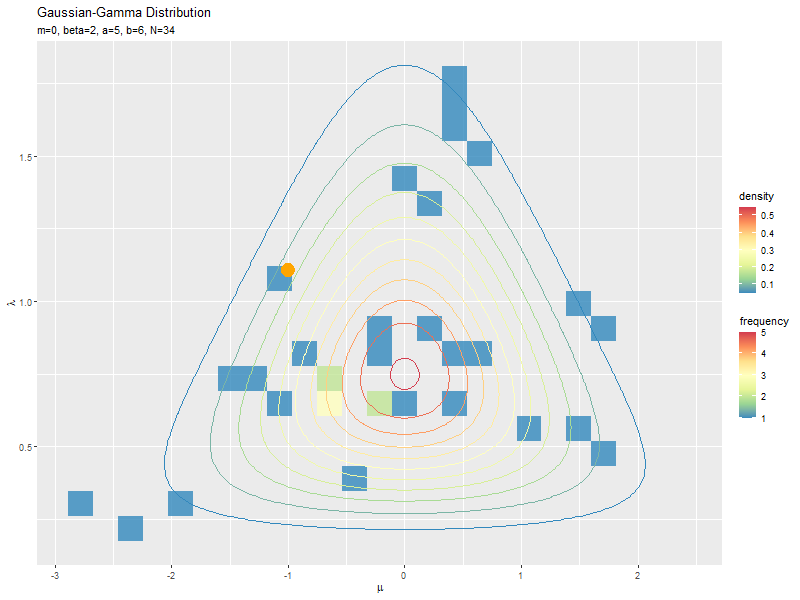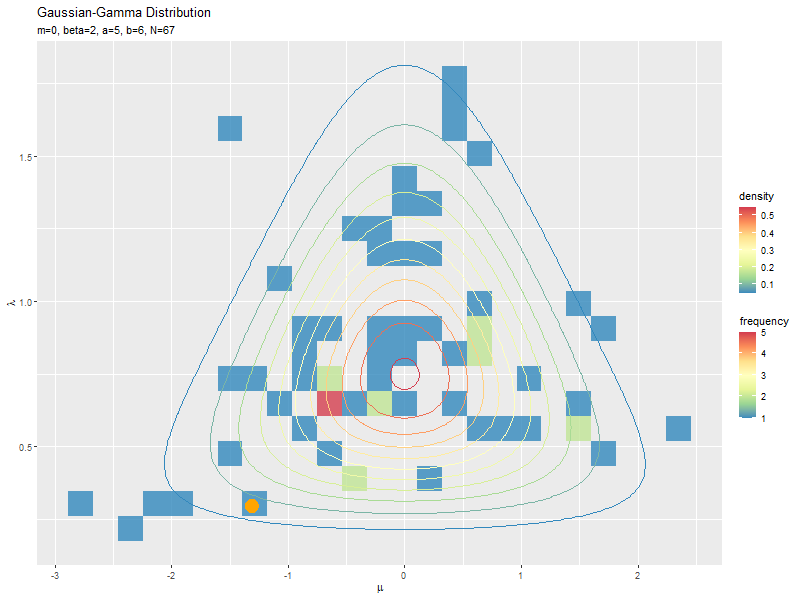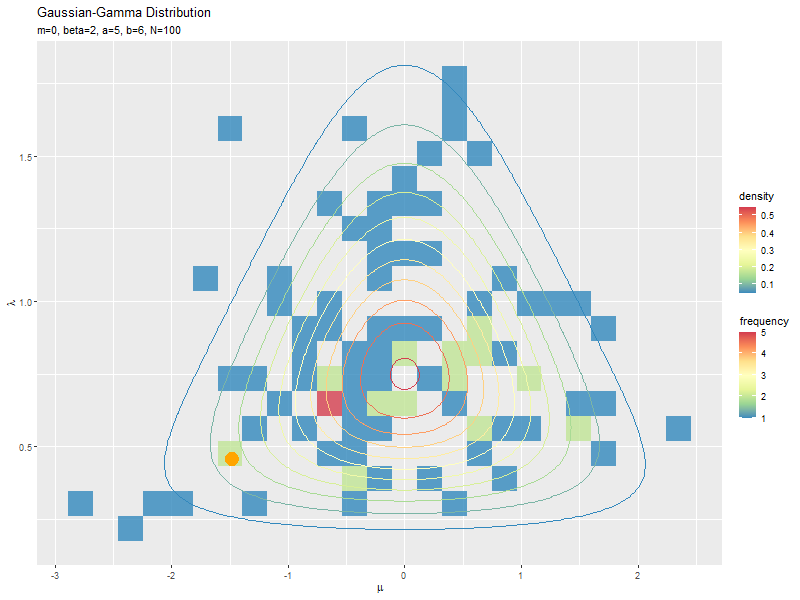

複数データずつ可視化
続いて、フレームごとに複数データを生成します。
・作図コード(クリックで展開)
$\mu, \lambda$のサンプルを生成します。
# データ数(フレーム数)を指定 N <- 10000 # ガンマ分布に従う乱数を生成 lambda_n <- rgamma(n = N, shape = a, rate = b) # ガウス分布に従う乱数を生成 mu_n <- rnorm(n = N, mean = m, sd = 1/sqrt(beta*lambda_n))
フレーム数を指定します。
# フレーム数を指定 frame_num <- 100 # 1フレーム当たりのデータ数を計算 n_per_frame <- N %/% frame_num n_per_frame
## [1] 100
フレーム数frame_numを指定して、1フレーム当たりのデータ数n_per_frameを計算します。
フレームごとに、n_per_frame個ずつサンプルが増えるデータフレームを作成します。
# サンプルを複製して格納 anime_freq_df <- tidyr::expand_grid( frame = 1:frame_num, # フレーム番号 n = 1:N # データ番号 ) |> # 全ての組み合わせを作成 dplyr::filter(n <= frame*n_per_frame) |> # 各試行までのサンプルを抽出 dplyr::mutate( mu = mu_n[n], # μのサンプル lambda = lambda_n[n], # λのサンプル parameter = paste0("m=", m, ", beta=", beta, ", a=", a, ", b=", b, ", N=", frame*n_per_frame) |> factor(levels = paste0("m=", m, ", beta=", beta, ", a=", a, ", b=", b, ", N=", 1:frame_num*n_per_frame)) # フレーム切替用ラベル ) anime_freq_df
## # A tibble: 505,000 × 5 ## frame n mu lambda parameter ## <int> <int> <dbl> <dbl> <fct> ## 1 1 1 -0.407 0.848 m=0, beta=2, a=5, b=6, N=100 ## 2 1 2 -0.230 2.42 m=0, beta=2, a=5, b=6, N=100 ## 3 1 3 -0.129 0.636 m=0, beta=2, a=5, b=6, N=100 ## 4 1 4 -0.265 0.500 m=0, beta=2, a=5, b=6, N=100 ## 5 1 5 1.02 0.479 m=0, beta=2, a=5, b=6, N=100 ## 6 1 6 -0.452 0.886 m=0, beta=2, a=5, b=6, N=100 ## 7 1 7 0.303 1.12 m=0, beta=2, a=5, b=6, N=100 ## 8 1 8 -0.594 1.11 m=0, beta=2, a=5, b=6, N=100 ## 9 1 9 -0.273 0.827 m=0, beta=2, a=5, b=6, N=100 ## 10 1 10 -0.0702 0.797 m=0, beta=2, a=5, b=6, N=100 ## # … with 504,990 more rows
1データずつのときと同様に、作図用のデータを作成します。こちらは、フレームごとに「フレーム番号」掛ける「1フレーム当たりのデータ数」番目までのサンプルを抽出します。
散布図のアニメーションを作成します。
# 散布図のアニメーションを作図 anime_freq_graph <- ggplot() + geom_point(data = anime_freq_df, mapping = aes(x = mu, y = lambda), color = "orange", alpha = 0.5, size = 3) + # サンプル geom_contour(data = dens_df, mapping = aes(x = mu, y = lambda, z = density, color = ..level..)) + # 元の分布 gganimate::transition_manual(parameter) + # フレーム labs(title = "Gaussian-Gamma Distribution", subtitle = "{current_frame}", color = "density", x = expression(mu), y = expression(lambda)) # ラベル # gif画像を作成 gganimate::animate(anime_freq_graph, nframes = frame_num+10, end_pause = 10, fps = 10, width = 800, height = 600)
1データずつのときと同様に処理します。
サンプルの度数のヒートマップのアニメーションを作成します。
# メッシュ用の値を設定 mu_breaks <- seq(from = min(mu_vals), to = max(mu_vals), length.out = 30) lambda_breaks <- seq(from = min(lambda_vals), to = max(lambda_vals), length.out = 30) # 度数のヒートマップのアニメーションを作図 anime_freq_graph <- ggplot() + geom_bin2d(data = anime_freq_df, mapping = aes(x = mu, y = lambda, fill = ..count..), breaks = list(x = mu_breaks, y = lambda_breaks), alpha = 0.8) + # サンプル geom_contour(data = dens_df, mapping = aes(x = mu, y = lambda, z = density, color = ..level..)) + # 元の分布 gganimate::transition_manual(parameter) + # scale_fill_distiller(palette = "Spectral") + # 塗りつぶしの色 scale_color_distiller(palette = "Spectral") + # 等高線の色 labs(title = "Gaussian-Gamma Distribution", subtitle = "{current_frame}", fill = "frequency", color = "density", x = expression(mu), y = expression(lambda)) # ラベル # gif画像を作成 gganimate::animate(anime_freq_graph, nframes = frame_num+10, end_pause = 10, fps = 10, width = 800, height = 600)
サンプルの密度の等高線のアニメーションを作成します。
# 密度の等高線のアニメーションを作図 anime_freq_graph <- ggplot() + geom_density2d_filled(data = anime_freq_df, mapping = aes(x = mu, y = lambda, fill = ..level..), alpha = 0.8) + # サンプル geom_contour(data = dens_df, mapping = aes(x = mu, y = lambda, z = density, color = ..level..)) + # 元の分布 gganimate::transition_manual(parameter) + # scale_color_viridis_c(option = "D") + # 等高線の色 coord_cartesian(xlim = c(min(mu_vals), max(mu_vals)), ylim = c(min(lambda_vals), max(lambda_vals))) + # 軸の表示範囲 labs(title = "Gaussian-Gamma Distribution", subtitle = "{current_frame}", fill = "density", color = "density", x = expression(mu), y = expression(lambda)) # ラベル # gif画像を作成 gganimate::animate(anime_freq_graph, nframes = frame_num+10, end_pause = 10, fps = 10, width = 800, height = 600)

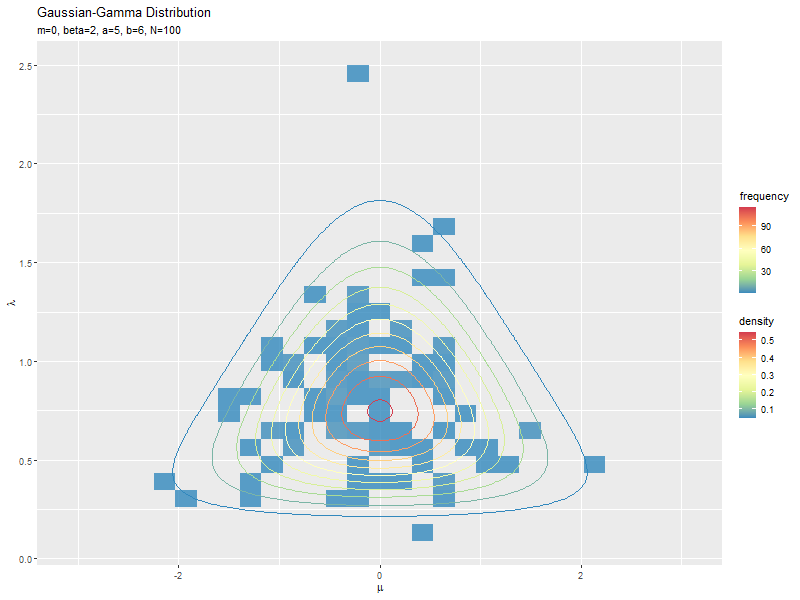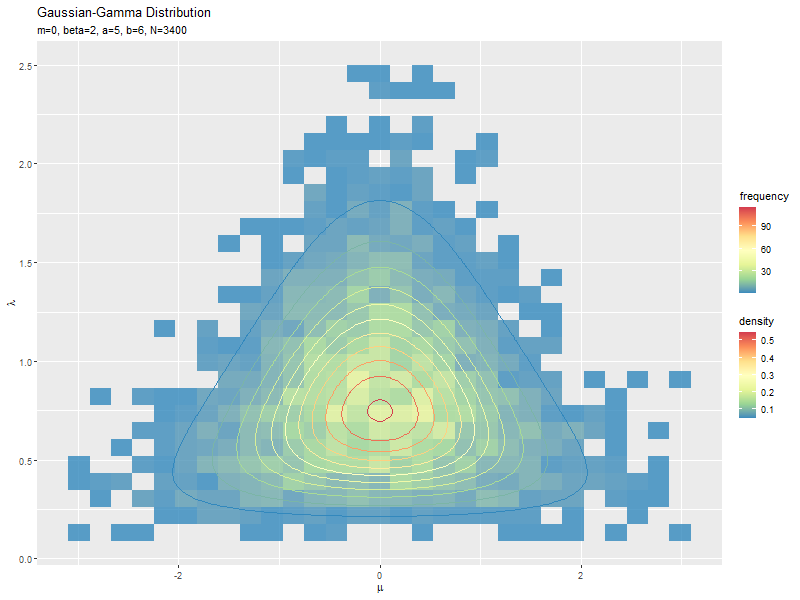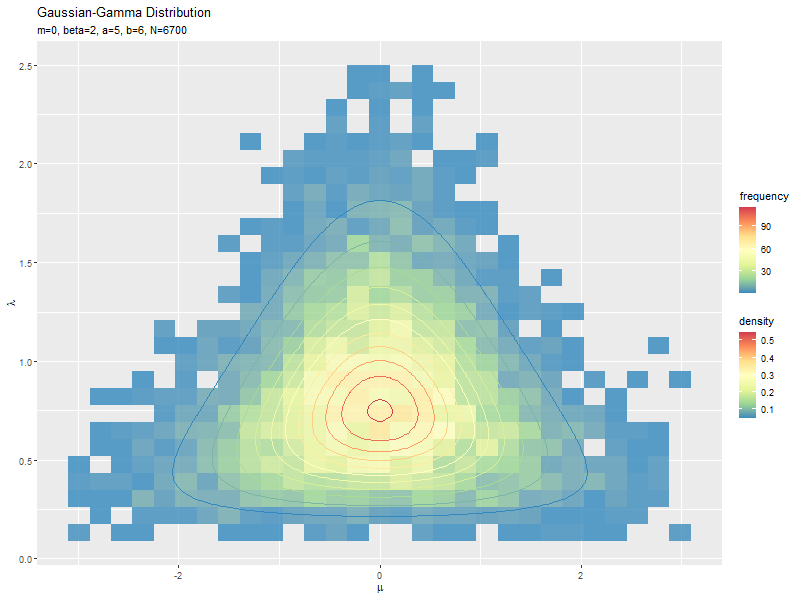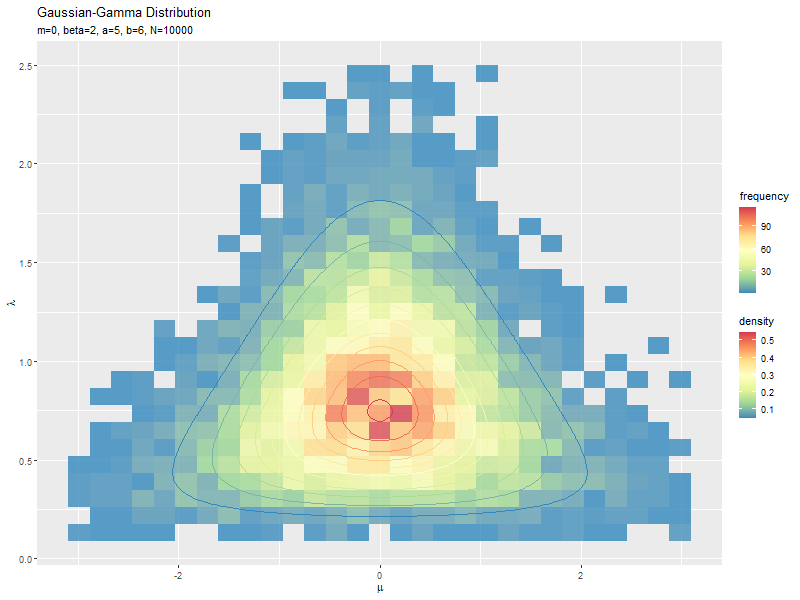

サンプルが増えるに従って、元の分布に近付くのを確認できます。
この記事では、ガウス-ガンマ分布の乱数生成を確認しました。次は、ガウス-ガンマ分布から確率分布を生成します。
参考文献
- C.M.ビショップ著,元田 浩・他訳『パターン認識と機械学習 上』,丸善出版,2012年.
おわりに
加筆修正の際に「ガウス-ガンマ分布の作図」から記事を分割しました。
【次の内容】