はじめに
素直なやり方ではできなかったのでむりくりなんとかする黒魔術シリーズです。もっといい方法があれば教えてください。
この記事では、離散型の確率分布(カテゴリ分布)の次元を入れ替えてKL情報量を最小にします。
【他の内容】
【目次】
KL情報量が最小となるように確率分布の次元を入れ替えたい
サンプリングなどで得られたカテゴリ分布の次元(インデックス)を入れ替えて、目的の分布(真の分布など)との当て嵌まりをよくしたい。そこで、インデックスの全てのパターン(順列)を作成して、それぞれKL情報量(カルバック・ライブラー・ダイバージェンス)を計算し最小となる(目的の分布に一番近い)並びを求める。
KL情報量については「1.1.8-10:カルバック・ライブラー・ダイバージェンスとイェンゼンの不等式【『トピックモデル』の勉強ノート】 - からっぽのしょこ」を参照のこと。
次のパッケージを利用する。
# 利用パッケージ library(tidyverse) library(gtools)
基本的にパッケージ名::関数名()の記法を使うので、パッケージを読み込む必要はない。ただし、作図コードがごちゃごちゃしないようにパッケージ名を省略しているので、ggplot2を読み込む必要がある。
また、magrittrパッケージのパイプ演算子%>%ではなく、ネイティブパイプ演算子|>を使っている。%>%に置き換えても処理できるが、その場合はmagrittrを読み込む必要がある。
真の分布の設定
まずは、真の確率分布(近付けたい確率分布)を作成する。
# 真の確率を指定 true_prob_k <- c(0.2, 0.1, 0.4, 0.3) # 次元数を設定 K <- length(true_prob_k) # 真の確率分布を格納 true_dist_df <- tibble::tibble( k = factor(1:K), prob = true_prob_k ) true_dist_df
## # A tibble: 4 × 2 ## k prob ## <fct> <dbl> ## 1 1 0.2 ## 2 2 0.1 ## 3 3 0.4 ## 4 4 0.3
K個の確率値をtrue_prob_kとして指定する。確率分布の条件を満たすために、それぞれ0以上の値で総和が1となる必要がある。
指定した要素(次元)数をKとして、1からKの整数(次元番号・インデックス)と合わせてデータフレームに格納する。
真の分布をグラフで確認する。
# 真の確率分布を作図 ggplot() + geom_bar(data = true_dist_df, mapping = aes(x = k, y = prob, fill = k), stat = "identity", show.legend = FALSE) + coord_cartesian(ylim = c(0, 1)) + # 描画範囲 labs(title = "true distribution", x = "k", y = "probability")
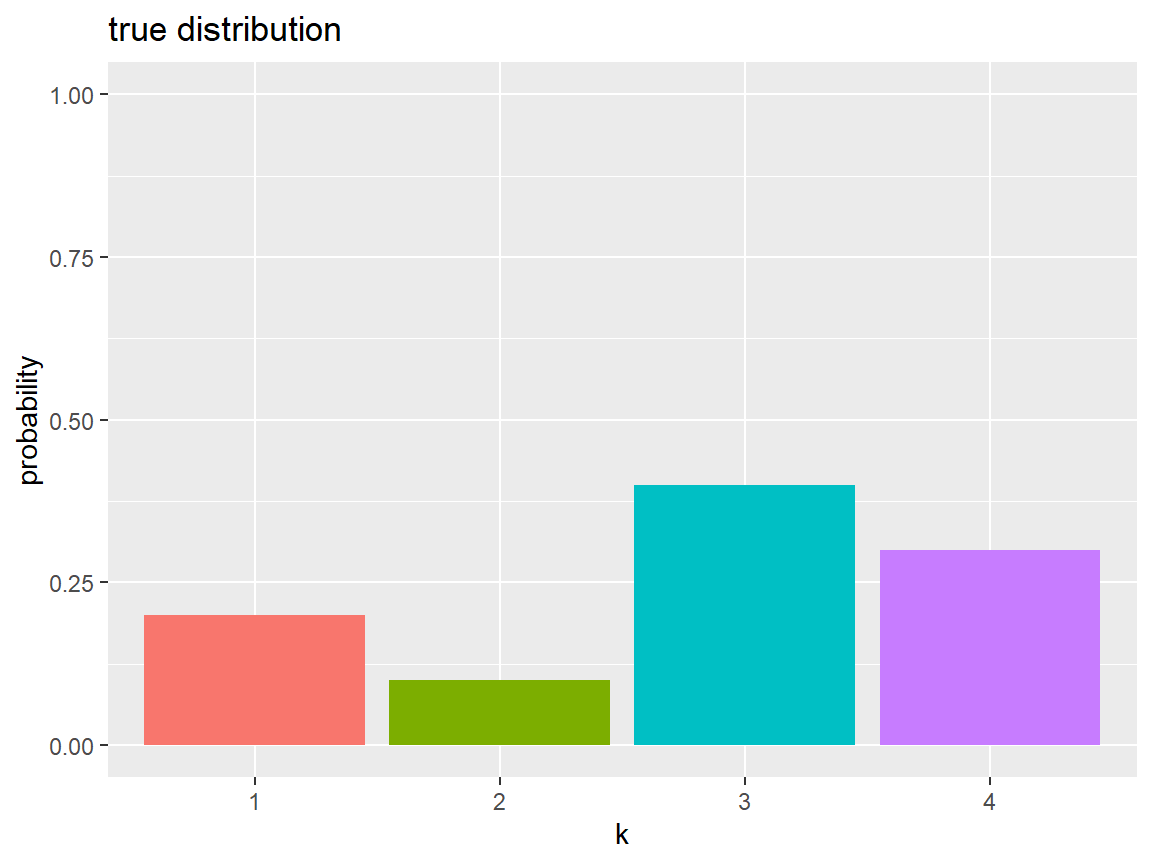
各インデックスと対応する確率を棒グラフで表す。
分布の生成(推定の代用)
次に、推定された(に相当する)確率分布を作成する。ここでは簡単に、ディリクレ分布からカテゴリ分布(のパラメータ)をサンプリングする。
# 確率(カテゴリ分布)を生成 sample_prob_j <- MCMCpack::rdirichlet(n = 1, alpha = rep(1, times = K)) |> as.vector() # 確率分布のサンプルを格納 sample_dist_df <- tibble::tibble( j = factor(1:K), prob = sample_prob_j ) sample_dist_df
## # A tibble: 4 × 2 ## j prob ## <fct> <dbl> ## 1 1 0.0442 ## 2 2 0.374 ## 3 3 0.0774 ## 4 4 0.505
MCMCpackパッケージのrdirichlet()を使って、ディリクレ分布の乱数を生成する。パラメータの引数alphaにK個の0より大きい値を指定する。この例では、全て1とする。マトリクスが出力されるのでベクトルに変換してsample_prob_jとする。
真の分布のときと同様に、インデックスと合わせてデータフレームに格納する。
サンプリングした分布をグラフで確認する。
# 確率分布のサンプルを作図 ggplot() + geom_bar(data = sample_dist_df, mapping = aes(x = j, y = prob, fill = j), stat = "identity", show.legend = FALSE) + coord_cartesian(ylim = c(0, 1)) + # 描画範囲 labs(title = "sampled distribution", x = "j", y = "probability")

カテゴリ分布は、二項分布やポアソン分布とは異なり、x軸の並びに(それほど)意味を持たない。
この記事ではトピックモデルのように、各トピック(カテゴリ)における確率を推定するが、トピック(カテゴリ)番号はランダムに割り当てられ真の分布(トイデータの生成分布)と対応しないようなアルゴリズムを想定している。トピックモデルについては「『トピックモデル』の勉強ノート:記事一覧 - からっぽのしょこ」を参照のこと。
推定分布が真の分布を近似できているものして、KL情報量が最小となるようにカテゴリ番号を入れ替えることを考える。
KL情報量の計算
インデックスの全ての並びを作成して、それぞれの順番に分布のサンプルを並べ替えて真の分布とのKL情報量を計算する。
# インデックスの組み合わせを作成してKL情報量を計算 kl_df <- tidyr::expand_grid( group = 1:gamma(K+1), # 組み合わせ番号 k = factor(1:K) # 真の分布・並べ替え後のインデックス ) |> tibble::add_column( j = gtools::permutations(n = K, r = K, v = 1:K) |> # インデックスの順列を作成 t() |> as.vector() |> factor() # 元のインデックス・並べ替え用の値 ) |> dplyr::group_by(group) |> # 組み合わせごとの計算用 dplyr::mutate( kl = sum(true_prob_k * (log(true_prob_k) - log(sample_prob_j[j]))), # KL情報量 true_prob = true_prob_k, # 真の確率 sample_prob = sample_prob_j[j] # 確率のサンプル ) |> dplyr::ungroup() |> dplyr::arrange(kl, k) # 当て嵌まりが良い順に並べ替え kl_df
## # A tibble: 96 × 6 ## group k j kl true_prob sample_prob ## <int> <fct> <fct> <dbl> <dbl> <dbl> ## 1 14 1 3 0.113 0.2 0.0774 ## 2 14 2 1 0.113 0.1 0.0442 ## 3 14 3 4 0.113 0.4 0.505 ## 4 14 4 2 0.113 0.3 0.374 ## 5 13 1 3 0.143 0.2 0.0774 ## 6 13 2 1 0.143 0.1 0.0442 ## 7 13 3 2 0.143 0.4 0.374 ## 8 13 4 4 0.143 0.3 0.505 ## 9 4 1 1 0.169 0.2 0.0442 ## 10 4 2 3 0.169 0.1 0.0774 ## # … with 86 more rows
個のインデックスの並べ方(順列)はKの階乗
通りあるので、
1からgamma(K+1)の整数をgroup列として各並びを区別する番号(列)とする。gamma()は、ガンマ関数で、階乗を計算する組み込み関数がないので代用する。
1からKの整数を「真の分布・並べ替え後のインデックス列k」として、group列とk列の値の全ての組み合わせをexpand_grid()で作成する。これにより、インデックスをそれぞれK!個に複製できる。
1からKの整数の順列をgtoolsパッケージのpermutations()で作成して、「元の分布のインデックス・並べ替え用の値列j」とする。
group列でグループ化することで、インデックスの組み合わせ(並び)ごとにK行ずつ処理できる。
離散型確率分布と
のKL情報量は、
で定義される。対数の性質より
なので、
で計算する。
真の確率true_prob_kをそのまま(k列の値に応じて)、サンプリングした確率sample_prob_jをj列の値を添字にして順番を入れ替えて格納する。
求めたKL情報量が昇順になるようにarange()で行を並べ替える。
インデックスの組み合わせ(並び)ごとにグラフを作成して確認する。
# インデックスの組み合わせごとに確率分布のサンプルを作図 ggplot() + geom_bar(data = kl_df, mapping = aes(x = k, y = sample_prob, fill = j), stat = "identity", alpha = 0.5) + # 分布のサンプル geom_bar(data = kl_df, mapping = aes(x = k, y = true_prob, color = k), stat = "identity", fill = NA, size = 1, linetype = "dashed", show.legend = FALSE) + # 真の分布 facet_wrap(kl ~ ., labeller = label_bquote(kl==.(kl))) + # 分割 #coord_cartesian(ylim = c(0, 1)) + # 描画範囲 labs(title = "sampled distribution with changed index", x = "k", y = "probability")
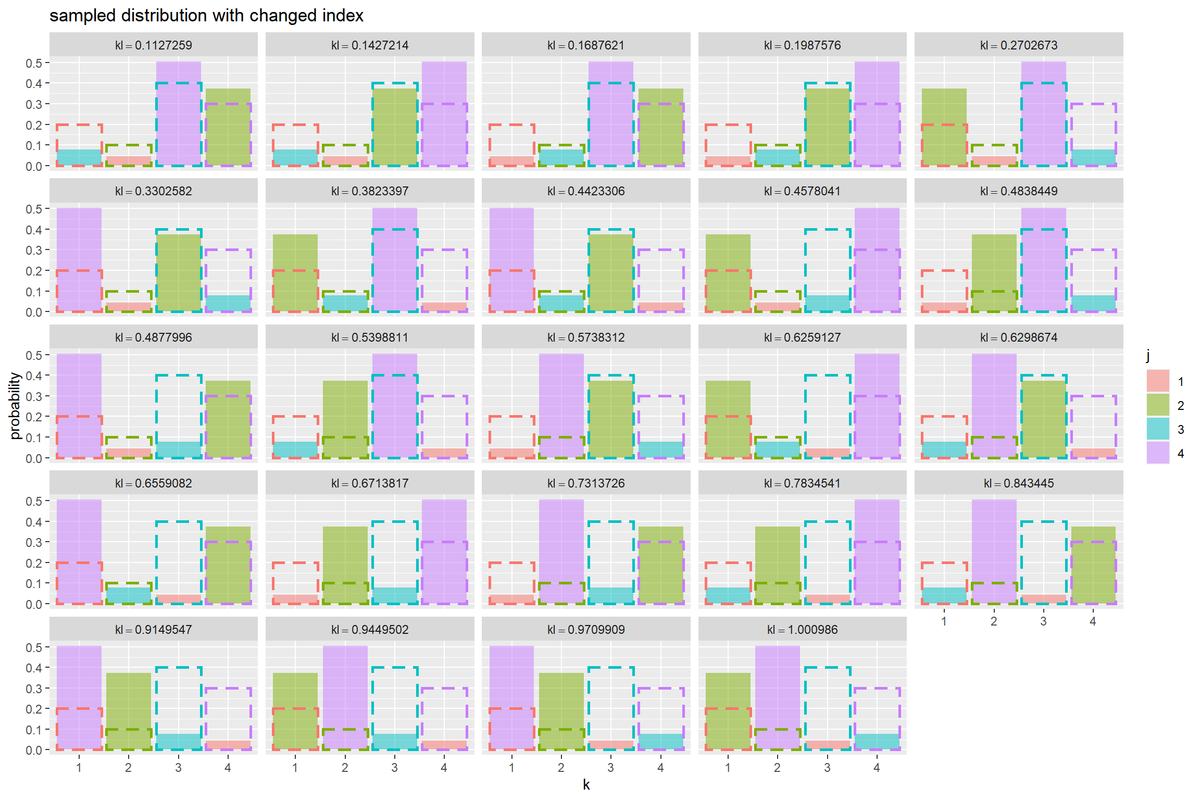
サンプリングした確率分布を塗りつぶし、真の分布を破線で描画する。また、x軸の値(バーの並び順)は変更後のインデックス列kを使い、色付けは元のインデックス列jを使う。
facet_wrap()にkl列またはgroup列を指定して、グラフを分割して描画する。kl列だとKL情報量が小さい順に、group列だとpermutations()の出力の順に、行方向にグラフが並ぶ。
インデックスの入替
KL情報量が最小となるインデックスの組み合わせを取り出す。
# インデックスの対応ベクトルを作成 adapt_idx <- kl_df |> dplyr::slice_head(n = K) |> # 当て嵌まりが良い組み合わせを抽出 dplyr::pull(j) |> # 列をベクトルに変換 as.numeric() # 数値に変換 adapt_idx
## [1] 3 1 4 2
kl_dfはKL情報量に応じて昇順に並んでいるので、slice_heas()で上からK行を取り出して、pull()でj列をベクトルとして取り出す。jの値は因子型なので、as.numeric()で数値型に変更してadapt_idxとする。
サンプリングした確率分布を並べ替えて格納する。
# インデックスを入れ替えた確率分布のサンプルを格納 adapt_dist_df <- tibble::tibble( j = factor(adapt_idx), # 元のインデックス k = factor(1:K), # KL情報量が最小になるインデックス prob = sample_prob_j[adapt_idx] # 確率を入れ替え ) adapt_dist_df
## # A tibble: 4 × 3 ## j k prob ## <fct> <fct> <dbl> ## 1 3 1 0.0774 ## 2 1 2 0.0442 ## 3 4 3 0.505 ## 4 2 4 0.374
adapt_idxを添字として使って、sample_prob_jの要素を並べ替えてデータフレームに格納する。また、元のインデックスとしてadapt_idxをj列、変更後のインデックスとして1からKの整数をk列として格納する。
インデックスを入れ替えた(KL情報量が最小となる)確率分布をグラフで確認します。
# KL情報量が最小になる確率分布を作図 ggplot() + geom_bar(data = adapt_dist_df, mapping = aes(x = k, y = prob, fill = j), stat = "identity", alpha = 0.5) + # 分布のサンプル geom_bar(data = true_dist_df, mapping = aes(x = k, y = prob, color = k), stat = "identity", fill = NA, size = 1, linetype = "dashed", show.legend = FALSE) + # 真の分布 coord_cartesian(ylim = c(0, 1)) + # 描画範囲 labs(title = "sampled distribution with adapted index", x = "k", y = "probability")
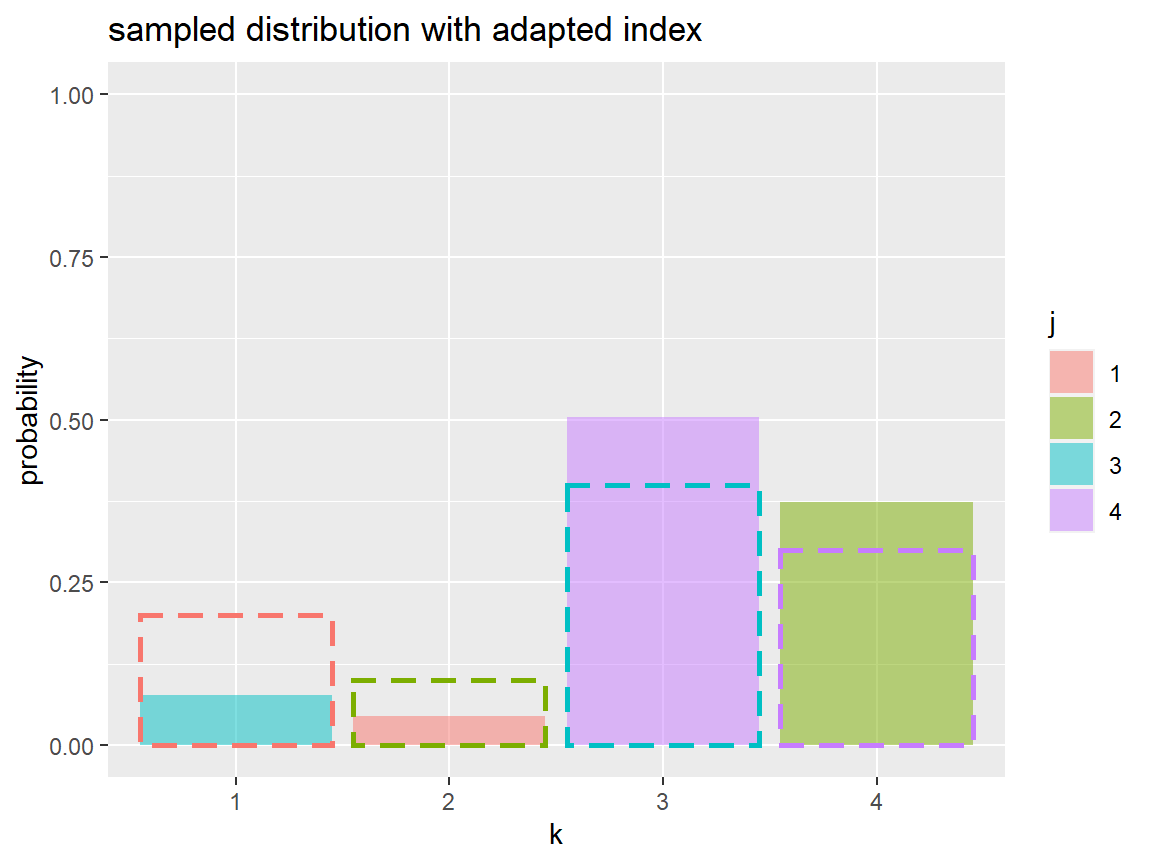
1つ前のグラフにおける1つ目のグラフに対応する。
以上で、元の分布を近似するように並べ替えた分布を得られた。つまり、真の分布と推定した分布のカテゴリ(トピック)を対応付けられた。
おわりに
トピックモデルシリーズの加筆修正をしている際に必要になって生えた記事です。
tidyverseパッケージを使ってちょちょいとできると思いきや意外と難しかったです。もっと簡単にできるあるいは組み込み・tidyverseの関数のみでできるのであれば教えてください。
かえでぃーのソロ活動一発目が発表&Twitterアカウントが開設されました!
ムーラン・ルージュ!ザ・ミュージカル
— 加賀楓Official (@K_KAEDEofficial) 2023年2月2日
ニニ役で出演させていただきます!
精一杯頑張りますので
皆様よろしくお願いします🙇♀️https://t.co/ABZgUt2JJU
最初の活動から凄い!(らしい、教養がなくミュージカルのことをよく知らない…)