はじめに
『ベイズ推論による機械学習入門』の学習時のノートです。基本的な内容は「数式の行間を読んでみた」とそれを「RとPythonで組んでみた」になります。「数式」と「プログラム」から理解するのが目標です。
この記事は、4.3.4項の内容です。「観測モデルをポアソン混合分布」、「事前分布をガンマ分布とディリクレ分布」とするポアソン混合モデルに対する崩壊型ギブスサンプリング(周辺化ギブスサンプリング)をR言語で実装します。
省略してある内容等ありますので、本とあわせて読んでください。初学者な自分が理解できるレベルまで落として書き下していますので、分かる人にはかなりくどくなっています。同じような立場の人のお役に立てれば幸いです。
【数式読解編】
【他の節の内容】
【この節の内容】
・Rでやってみる
人工的に生成したデータを用いて、ベイズ推論を行ってみましょう。アルゴリズム4.4を参考に実装します。
利用するパッケージを読み込みます。
# 4.3.4項で利用するパッケージ library(tidyverse)
・観測モデルの設定
まずは、観測モデルを設定します。この例では、$K$個の観測モデルをポアソン分布$\mathrm{Poi}(x_n | \lambda_k)$とします。また、各データに対する$K$個の観測モデルの割り当てをカテゴリ分布$\mathrm{Cat}(\mathbf{s}_n | \boldsymbol{\pi})$によって行います。
観測モデルのパラメータと混合比率を設定します。
# K個の真のパラメータを指定 lambda_truth_k <- c(10, 25, 40) # 真の混合比率を指定 pi_truth_k <- c(0.35, 0.25, 0.4) # クラスタ数を取得 K <- length(lambda_truth_k)
観測モデルの$K$個のパラメータ$\boldsymbol{\lambda} = \{\lambda_1, \lambda_2, \cdots, \lambda_K\}$をlambda_truth_kとして、$\lambda_k \geq 0$の値を指定します。
混合比率パラメータ$\boldsymbol{\pi} = (\pi_1, \pi_2, \cdots, \pi_K)$をpi_truth_kとして、$\sum_{k=1}^K \pi_k = 1$、$\pi_k \geq 0$の値を指定します。
この2つのパラメータの値を求めるのがここでの目的です。
設定したモデルをグラフで確認しましょう。グラフ用の点を作成します。
# 作図用のxの点を作成 x_vec <- seq(0, 2 * max(lambda_truth_k)) # 確認 x_vec[1:5]
## [1] 0 1 2 3 4
作図用に、ポアソン分布に従う変数$x_n$がとり得る非負の整数をseq()で作成してx_vecとします。この例では、0から$\boldsymbol{\lambda}$の最大値の2倍を範囲とします。
ポアソン混合分布の確率を計算します。
# 観測モデルを計算 model_prob <- 0 for(k in 1:K) { # クラスタkの分布の確率を計算 tmp_prob <- dpois(x = x_vec, lambda = lambda_truth_k[k]) # K個の分布の加重平均を計算 model_prob <- model_prob + pi_truth_k[k] * tmp_prob }
$K$個のパラメータlambda_truth_kを使って、x_vecの値ごとに次の式で確率を計算します。
$K$個のポアソン分布に対して、$\boldsymbol{\pi}$を使って加重平均をとります。
ポアソン分布の確率は、dpois()で計算できます。データの引数xにx_vec、パラメータの引数lambdaにlambda_truth_k[k]を指定します。
この計算をfor()ループでK回繰り返し行います。各パラメータによって求めた$K$回分の確率をpi_truth_k[k]で割り引いてmodel_probに加算していきます。
計算結果をデータフレームに格納します。
# 観測モデルをデータフレームに格納 model_df <- tibble( x = x_vec, prob = model_prob ) # 確認 head(model_df)
## # A tibble: 6 x 2 ## x prob ## <int> <dbl> ## 1 0 0.0000159 ## 2 1 0.000159 ## 3 2 0.000794 ## 4 3 0.00265 ## 5 4 0.00662 ## 6 5 0.0132
ggplot2パッケージを利用して作図するには、データフレームを渡す必要があります。
観測モデルを作図します。
# 観測モデルを作図 ggplot(model_df, aes(x = x, y = prob)) + geom_bar(stat = "identity", position = "dodge", fill = "blue", color = "blue") + # 真の分布 labs(title = "Poisson Mixture Model", subtitle = paste0("lambda=(", paste0(lambda_truth_k, collapse = ", "), ")"))

$K$個の分布を重ねたような分布になります。ただし、総和が1となるようにしているため、$K$個の分布そのものよりも1つ1つの山が小さく(確率値が小さく)なっています。
・データの生成
続いて、構築したモデルに従ってデータを生成します。先に、潜在変数$\mathbf{S} = \{\mathbf{s}_1, \mathbf{s}_2, \cdots, \mathbf{s}_N\}$、$\mathbf{s}_n = (s_{n,1}, s_{n,2}, \cdots, s_{n,K})$を生成し、各データに割り当てられたクラスタに従い観測データ$\mathbf{X} = \{x_1, x_2, \cdots, x_N\}$を生成します。
$N$個の潜在変数$\mathbf{S}$を生成します。
# (観測)データ数を指定 N <- 250 # クラスタを生成 s_truth_nk <- rmultinom(n = N, size = 1, prob = pi_truth_k) %>% t()
生成するデータ数$N$をNとして値を指定します。
カテゴリ分布に従う乱数は、多項分布に従う乱数生成関数rmultinom()のsize引数を1にすることで生成できます。また、試行回数の引数nにN、確率(パラメータ)の引数probにpi_truth_kを指定します。生成した$N$個の$K$次元ベクトルをs_nkとします。ただし、クラスタが行でデータが列方向に並んで出力されるので、t()で転置しておきます。
結果は次のようになります。
# 確認 s_truth_nk[1:5, ]
## [,1] [,2] [,3] ## [1,] 0 0 1 ## [2,] 0 0 1 ## [3,] 0 1 0 ## [4,] 0 0 1 ## [5,] 0 0 1
これが本来は観測できない潜在変数であり、真のクラスタです。各行がデータを表し、値が1の列番号が割り当てられたクラスタ番号を表します。
s_nkから各データのクラスタ番号を抽出します。
# クラスタ番号を抽出 s_truth_n <- which(t(s_truth_nk) == 1, arr.ind = TRUE) %>% .[, "row"] # 確認 s_truth_n[1:5]
## [1] 3 3 2 3 3
which()を使って要素が1の行番号を抽出します。
各データのクラスタに従い$N$個のデータを生成します。
# (観測)データを生成 x_n <- rpois(n = N, lambda = lambda_truth_k[s_truth_n])
ポアソン分布に従う乱数は、rpois()で生成できます。試行回数の引数nにN、パラメータの引数lambdaにlambda_truth_k[s_truth_n]を指定します。各データのクラスタ番号s_truth_nを添字に使うことで、各データのクラスタに対応したパラメータ$\lambda_k$をlambda_truth_kから取り出すことができます。生成した$N$個のデータをx_nとします。式(4.28)を再現して、lambdaにapply(lambda_truth_k^t(s_truth_nk), 2, prod)を渡しても生成できます。
観測したデータとクラスタ番号をデータフレームに格納します。
# 観測データをデータフレームに格納 x_df <- tibble( x_n = x_n, cluster = as.factor(s_truth_n) ) # 確認 head(x_df)
## # A tibble: 6 x 2 ## x_n cluster ## <int> <fct> ## 1 45 3 ## 2 38 3 ## 3 20 2 ## 4 40 3 ## 5 48 3 ## 6 27 3
観測データは非負の整数、クラスタは1からKの整数になっているのを確認できます。
観測データをヒストグラムで確認しましょう。
# 観測データのヒストグラムを作成 ggplot() + geom_histogram(data = x_df, aes(x = x_n, y = ..density..), binwidth = 1) + # 観測データ geom_bar(data = model_df, aes(x = x, y = prob), stat = "identity", position = "dodge", alpha = 0, color = "red", linetype = "dashed") + # 真の分布 labs(title = "Poisson Mixture Model", subtitle = paste0("N=", N, ", lambda=(", paste0(lambda_truth_k, collapse = ", "), ")"), x = "x")
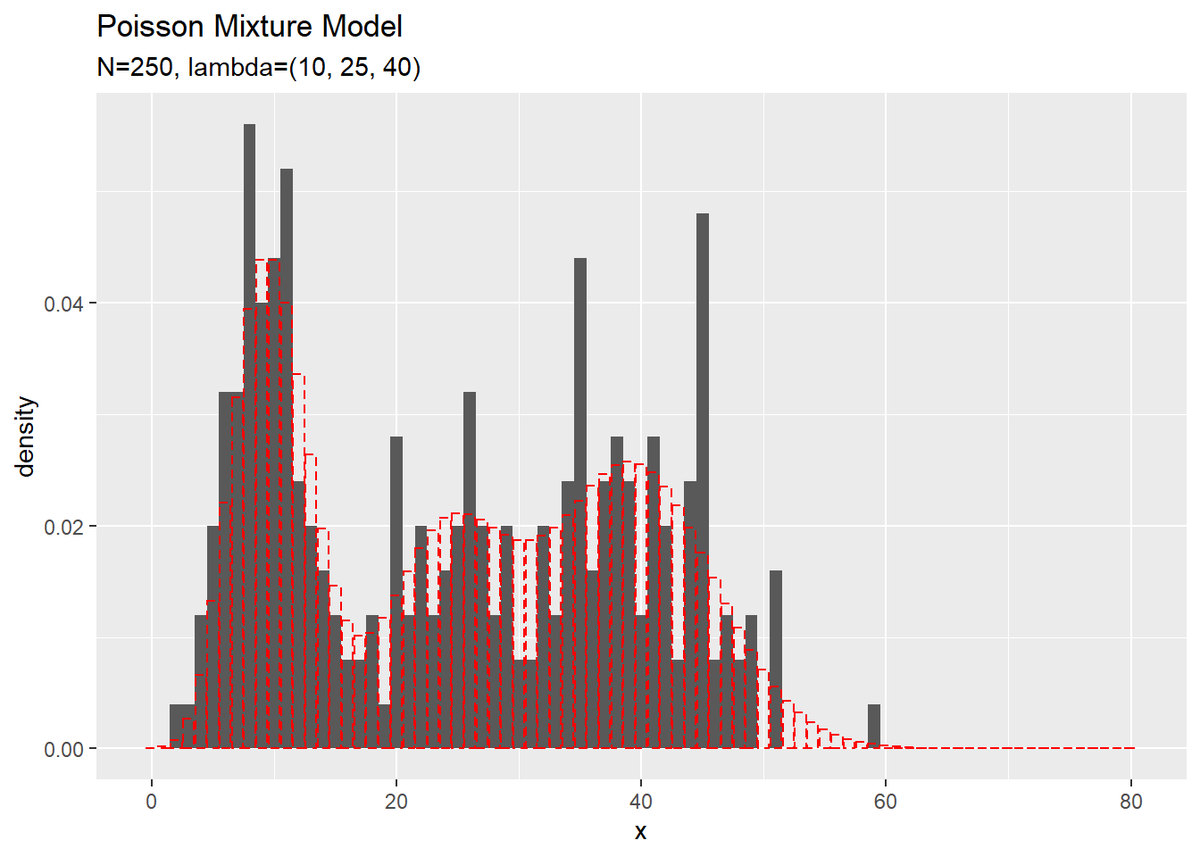
真の分布を重ねて描画しています。
また、クラスタもヒストグラムで確認しましょう。
# クラスタのヒストグラムを作成 ggplot() + geom_histogram(data = x_df, aes(x = x_n, fill = cluster), binwidth = 1, position = "identity", alpha = 0.5) + # クラスタ labs(title = "Poisson Mixture Model", subtitle = paste0("N=", N, ", lambda=(", paste0(lambda_truth_k, collapse = ", "), ")", ", pi=(", paste0(pi_truth_k, collapse = ", "), ")"), x = "x")

どちらの分布もデータが十分に大きいと真の分布に近づきます。
・事前分布の設定
次に、観測モデル(観測データの分布)$p(\mathbf{X} | \boldsymbol{\lambda})$と潜在変数の分布$p(\mathbf{S} | \boldsymbol{\pi})$に対する共役事前分布を設定します。ポアソン分布のパラメータ$\boldsymbol{\lambda}$に対する事前分布$p(\boldsymbol{\lambda})$としてガンマ分布$\mathrm{Gam}(\boldsymbol{\lambda} | a, b)$、カテゴリ分布のパラメータ$\boldsymbol{\pi}$に対する事前分布$p(\boldsymbol{\pi})$としてディリクレ分布$p(\boldsymbol{\pi} | \boldsymbol{\alpha})$を設定します。
$\boldsymbol{\lambda}$の事前分布と$\boldsymbol{\pi}$の事前分布のパラメータ(超パラメータ)を設定します。
# lambdaの事前分布のパラメータを指定 a <- 1 b <- 1 # piの事前分布のパラメータを指定 alpha_k <- rep(2, K)
ガンマ分布のパラメータ$a,\ b$をそれぞれa, bとして、$a > 0,\ b > 0$の値を指定します。
ディリクレ分布のパラメータ$\boldsymbol{\alpha} = (\alpha_1, \alpha_2, \cdots, \alpha_K)$をalpha_kとして、$\alpha_k > 0$の値を指定します。
超パラメータを設定できたので、$\boldsymbol{\lambda}$の事前分布を確認しましょう。グラフ用の点を作成して、確率密度を計算します。
# 作図用のlambdaの点を作成 lambda_vec <- seq(0, 2 * max(lambda_truth_k), length.out = 1000) # lambdaの事前分布を計算 prior_df <- tibble( lambda = lambda_vec, density = dgamma(x = lambda, shape = a, rate = b) )
ガンマ分布に従う変数$\lambda_k$がとり得る0以上の値をseq()で作成してlambda_vecとします。この例では、0から$\boldsymbol{\lambda}$の最大値の2倍を範囲とします。length.out引数を使うと指定した要素数で等間隔に切り分けます。by引数を使うと切り分ける間隔を指定できます。処理が重い場合は、この値を調整してください。
作成したlambda_vecの値ごとに確率密度を計算します。ガンマ分布の確率密度は、dgamma()で計算できます。データの引数xにlambda_vec、shape引数にa、rate引数にbを指定します。
作成したデータフレームは次のようになります。
# 確認 head(prior_df)
## # A tibble: 6 x 2 ## lambda density ## <dbl> <dbl> ## 1 0 1 ## 2 0.0801 0.923 ## 3 0.160 0.852 ## 4 0.240 0.786 ## 5 0.320 0.726 ## 6 0.400 0.670
$\boldsymbol{\lambda}$の事前分布を作図します。
# lambdaの事前分布を作図 ggplot(prior_df, aes(x = lambda, y = density)) + geom_line(color = "purple") + # 事前分布 geom_vline(xintercept = lambda_truth_k, color = "red", linetype = "dashed") + # 真の値 labs(title = "Gamma Distribution", subtitle = paste0("a=", b, ", b=", b), x = expression(lambda))

真の値を垂直線geom_vline()で描画しています。
$\boldsymbol{\pi}$の事前分布(と事後分布)については省略します。詳しくは、3.2.2項「カテゴリ分布の学習と予測」をご参照ください。
・初期値の設定
設定した事前分布に従い、潜在変数$\mathbf{S}$をランダムに生成して初期値とします。
alpha_kを用いて、$\mathbf{S}$の初期値を生成します。
# 潜在変数の初期値をランダムに生成 s_nk <- rmultinom(n = N, size = 1, prob = alpha_k / sum(alpha_k)) %>% t()
真のクラスタのときと同様に生成してs_nkとします。
ただしここでは、各クラスタとなる確率として、$\boldsymbol{\alpha}$から求めた混合比率の期待値$\mathbb{E}[\boldsymbol{\pi}]$を使うことにします。クラスタ$k$となる確率の期待値$\mathbb{E}[\pi_k]$は、ディリクレ分布の期待値(2.51)より
で計算します。
生成した潜在変数を確認します。
# 確認 s_nk[1:5, ]
## [,1] [,2] [,3] ## [1,] 0 0 1 ## [2,] 0 0 1 ## [3,] 0 1 0 ## [4,] 0 1 0 ## [5,] 0 0 1
s_nkを用いて、$\boldsymbol{\lambda}$の事後分布のパラメータの初期値を計算します。
# 初期値によるlambdaの事後分布のパラメータを計算:式(4.24) a_hat_k <- colSums(s_nk * x_n) + a b_hat_k <- colSums(s_nk) + b
$\boldsymbol{\lambda}$の事後分布(ガンマ分布)のパラメータ$\hat{\mathbf{a}} = \{\hat{a}_1, \hat{a}_2, \cdots, \hat{a}_K\}$、$\hat{\mathbf{b}} = \{\hat{b}_1, \hat{b}_2, \cdots, \hat{b}_K\}$の各項は
で計算して、結果をa_hat_k, b_hat_kとします。この時点では、$N$個全てのデータを使っているため(崩壊型ではない)ギブスサンプリング(4.3.2項)の式(4.42)です。
# 確認
a_hat_k
b_hat_k
## [1] 2080 1992 2166 ## [1] 84 85 84
ちなみに、$\hat{a}_k$の計算式に関して、$s_{n,k} x_n$の計算は
x_n[1:5] s_nk[1:5, ] * x_n[1:5]
## [1] 45 38 20 40 48 ## [,1] [,2] [,3] ## [1,] 0 0 45 ## [2,] 0 0 38 ## [3,] 0 20 0 ## [4,] 0 40 0 ## [5,] 0 0 48
各観測データをクラスタごとに仕分ける操作であり、$\sum_{n=1}^N s_{n,k} x_n$は
colSums(s_nk[1:5, ] * x_n[1:5])
## [1] 0 60 131
割り当てられたクラスタごとに観測データの値の和をとる操作と言えます。また、$\sum_{n=1}^N s_{n,k}$の計算は
s_nk[1:5, ] colSums(s_nk[1:5, ])
## [,1] [,2] [,3] ## [1,] 0 0 1 ## [2,] 0 0 1 ## [3,] 0 1 0 ## [4,] 0 1 0 ## [5,] 0 0 1 ## [1] 0 2 3
各クラスタを割り当てられたデータ数です。
同様に、$\boldsymbol{\pi}$の事後分布のパラメータの初期値を計算します。
# 初期値によるpiの事後分布のパラメータを計算:式(4.45) alpha_hat_k <- colSums(s_nk) + alpha_k
$\boldsymbol{\pi}$の事後分布(ディリクレ分布)のパラメータ$\hat{\boldsymbol{\alpha}} = (\hat{\alpha}_1, \hat{\alpha}_2, \cdots, \hat{\alpha}_K)$の各項は
で計算して、結果をalpha_hat_kとします。こちらも$N$個全てデータから求めています。
# 確認
alpha_hat_k
## [1] 85 86 85
超パラメータの初期値が得られたので、$\boldsymbol{\lambda}$の事後分布を確認しましょう。$K$個の事後分布を計算します。
# 初期値によるlambdaの近似事後分布をデータフレームに格納 init_lambda_df <- tibble() for(k in 1:K) { # クラスタkの事後分布を計算 tmp_init_df <- tibble( lambda = lambda_vec, density = dgamma(x = lambda, shape = a_hat_k[k], rate = b_hat_k[k]), cluster = as.factor(k) ) # 結果を結合 init_lambda_df <- rbind(init_lambda_df, tmp_init_df) }
事前分布と同様に計算します。ただし、超パラメータが$K$個になったので、ガンマ分布も$K$個になります。$K$回分の計算結果をデータフレームに格納していきます。
作成したデータフレームは次のようになります。
# 確認 head(init_lambda_df)
## # A tibble: 6 x 3 ## lambda density cluster ## <dbl> <dbl> <fct> ## 1 0 0 1 ## 2 0.0801 0 1 ## 3 0.160 0 1 ## 4 0.240 0 1 ## 5 0.320 0 1 ## 6 0.400 0 1
$\boldsymbol{\lambda}$の事後分布の初期値を作図します。
# 初期値によるlambdaの近似事後分布を作図 ggplot(init_lambda_df, aes(x = lambda, y = density, color = cluster)) + geom_line() + # 初期値による事後分布 geom_vline(xintercept = lambda_truth_k, color = "red", linetype = "dashed") + # 真の値 labs(title = "Gamma Distribution", subtitle = paste0("iter:", 0, ", a=(", paste0(round(a_hat_k, 1), collapse = ", "), ")", ", b=(", paste0(round(b_hat_k, 1), collapse = ", "), ")"), x = expression(lambda))
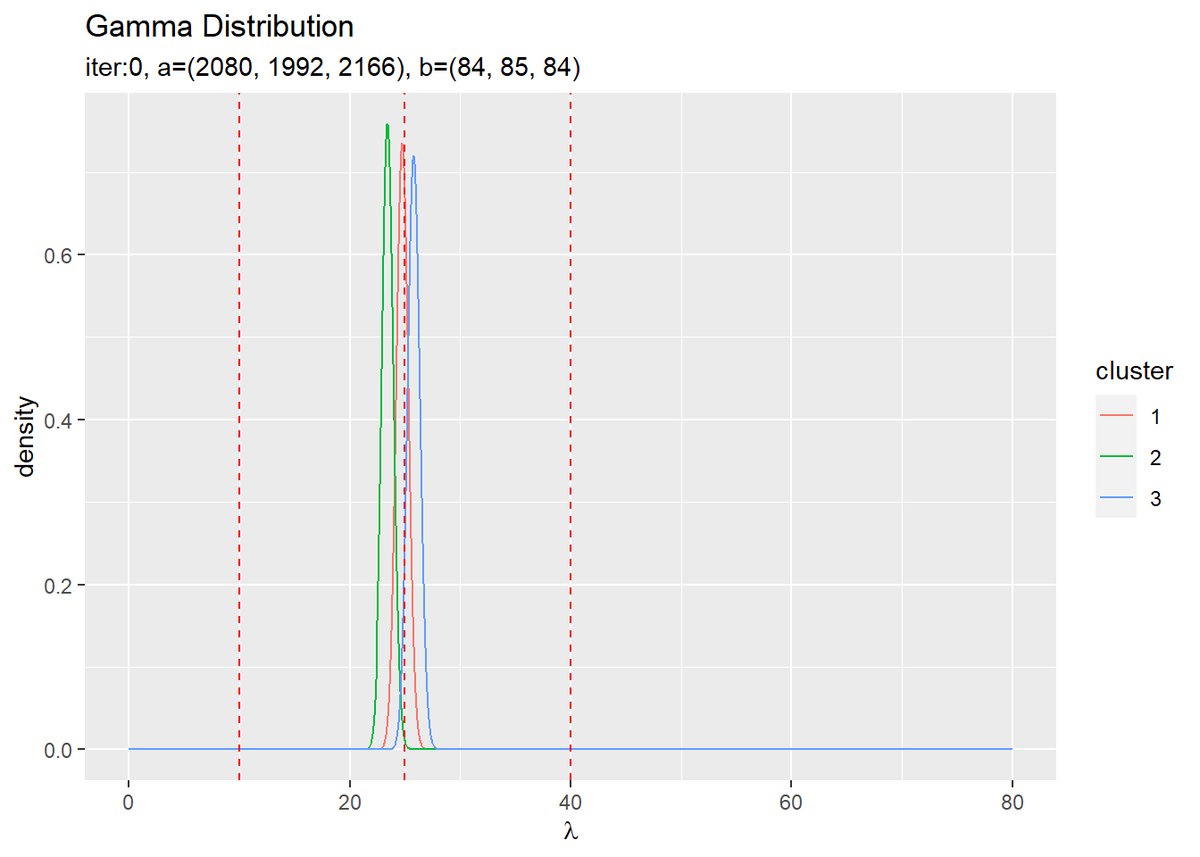
超パラメータの初期値からパラメータの期待値$\mathbb{E}[\lambda_k],\ \mathbb{E}[\pi_k]$を求めて、混合分布を計算します。
# lambdaの平均値を計算:式(2.59) E_lambda_k <- a_hat_k / b_hat_k # piの平均値を計算:式(2.51) E_pi_k <- alpha_hat_k / sum(alpha_hat_k) # 初期値による混合分布を計算 init_prob <- 0 for(k in 1:K) { # クラスタkの分布の確率を計算 tmp_prob <- dpois(x = x_vec, E_lambda_k[k]) # K個の分布の加重平均を計算 init_prob <- init_prob + E_pi_k[k] * tmp_prob }
$\mathbb{E}[\lambda_k]$は、ガンマ分布の期待値(2.59)より
で計算します。また、$\mathbb{E}[\pi_k]$は、先ほど計算した
です。
超パラメータの初期値から求めた分布を作図します。
# 初期値による分布をデータフレームに格納 init_df <- tibble( x = x_vec, prob = init_prob ) # 初期値による分布を作図 ggplot() + geom_bar(data = init_df, aes(x = x, y = prob), stat = "identity", position = "dodge", fill = "purple", color = "purple") + # 初期値による分布 geom_bar(data = model_df, aes(x = x, y = prob), stat = "identity", position = "dodge", alpha = 0, color = "red", linetype = "dashed") + # 真の分布 labs(title = "Poisson Mixture Model", subtitle = paste0("iter:", 0, ", E[lambda]=(", paste0(round(E_lambda_k, 2), collapse = ", "), ")", ", E[pi]=(", paste0(round(E_pi_k, 2), collapse = ", "), ")"))
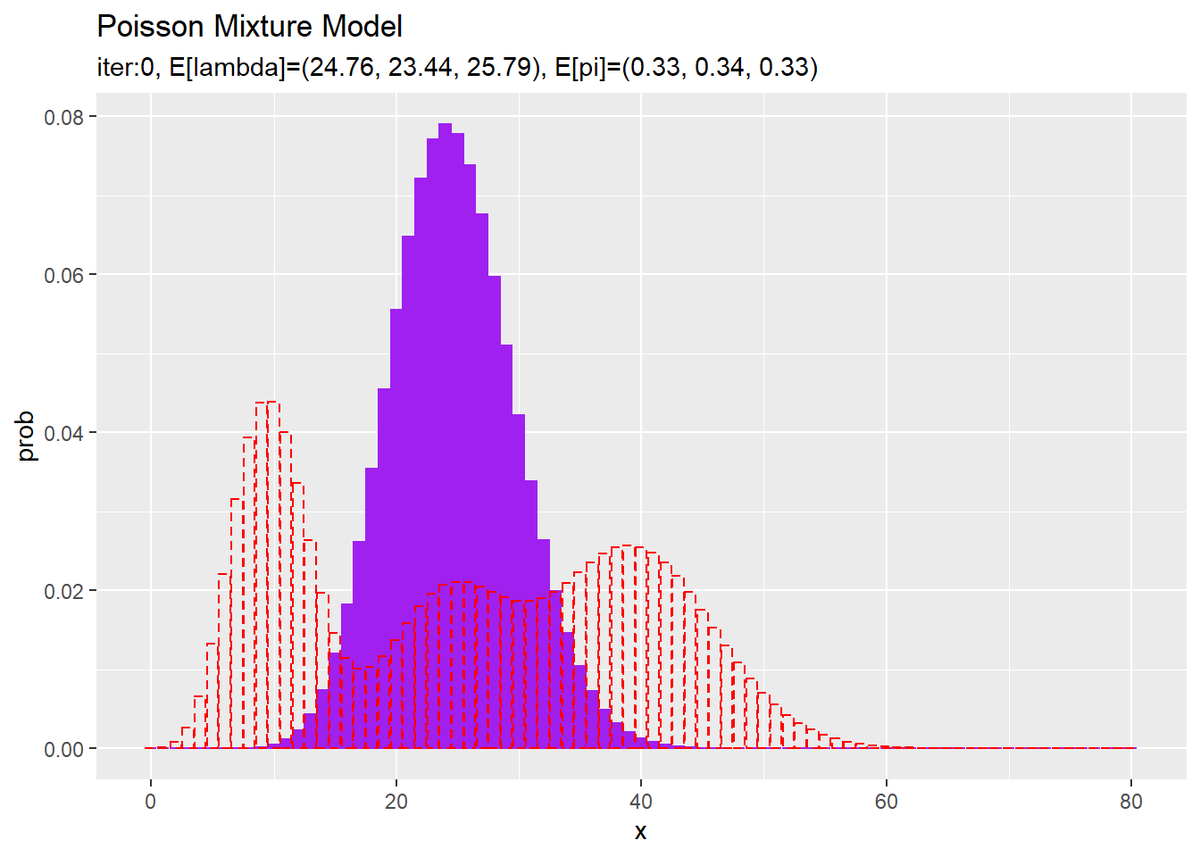
観測モデルのときと同様に作図します。
・崩壊型ギブスサンプリング
崩壊型ギブスサンプリングにより、パラメータと潜在変数を推定します。
・コード全体
後で各パラメータの更新値や分布の推移を確認するために、それぞれ試行ごとにtrace_***に値を保存していきます。
# 試行回数を指定 MaxIter <- 100 # 推移の確認用の受け皿を初期化 trace_s_in <- matrix(0, nrow = MaxIter + 1, ncol = N) trace_a_ik <- matrix(0, nrow = MaxIter + 1, ncol = K) trace_b_ik <- matrix(0, nrow = MaxIter + 1, ncol = K) trace_alpha_ik <- matrix(0, nrow = MaxIter + 1, ncol = K) # 初期値を記録 trace_s_in[1, ] <- which(t(s_nk) == 1, arr.ind = TRUE) %>% .[, "row"] trace_a_ik[1, ] <- a_hat_k trace_b_ik[1, ] <- b_hat_k trace_alpha_ik[1, ] <- alpha_hat_k # 崩壊型ギブスサンプリング for(i in 1:MaxIter) { for(n in 1:N) { # n番目のデータの現在のクラスタ番号を取得 k <- which(s_nk[n, ] == 1) # n番目のデータに関する統計量を除算:式(4.80-4.73) a_hat_k[k] <- a_hat_k[k] - x_n[n] b_hat_k[k] <- b_hat_k[k] - 1 alpha_hat_k[k] <- alpha_hat_k[k] - 1 # 負の二項分布(4.81)のパラメータを計算 r_hat_k <- a_hat_k p_hat_k <- 1 / (b_hat_k + 1) # 負の二項分布の確率を計算:式(4.81) prob_nb_k <- dnbinom(x = x_n[n], size = r_hat_k, prob = 1 - p_hat_k) # カテゴリ分布(4.74)のパラメータを計算:式(4.75) eta_k <- alpha_hat_k / sum(alpha_hat_k) # n番目のクラスタのサンプリング確率を計算:式(4.66) prob_s_k <- (prob_nb_k + 1e-7) * eta_k prob_s_k <- prob_s_k / sum(prob_s_k) # 正規化 # n番目のクラスタをサンプル:式(4.74) s_nk[n, ] <- rmultinom(n = 1, size = 1, prob = prob_s_k) %>% as.vector() # n番目のデータの新しいクラスタ番号を取得 k <- which(s_nk[n, ] == 1) # n番目のデータに関する統計量を加算:式(4.82-4.83) a_hat_k[k] <- a_hat_k[k] + x_n[n] b_hat_k[k] <- b_hat_k[k] + 1 alpha_hat_k[k] <- alpha_hat_k[k] + 1 } # i回目の結果を記録 trace_s_in[i + 1, ] <- which(t(s_nk) == 1, arr.ind = TRUE) %>% .[, "row"] %>% as.vector() trace_a_ik[i + 1, ] <- a_hat_k trace_b_ik[i + 1, ] <- b_hat_k trace_alpha_ik[i + 1, ] <- alpha_hat_k # 動作確認 #print(paste0(i, ' (', round(i / MaxIter * 100, 1), '%)')) }
・処理の確認
続いて、変分推論で行う処理を確認していきます。
・潜在変数$\boldsymbol{s}_n$の事後分布$p(\boldsymbol{s}_n | \mathbf{X}, \mathbf{S}_{\backslash n})$のパラメータの計算
崩壊型ギブスサンプリングにおける$\boldsymbol{s}_n$の事後分布パラメータを計算します。
# n番目のデータの現在のクラスタ番号を取得 k <- which(s_nk[n, ] == 1) # n番目のデータに関する統計量を除算:式(4.82-4.83) a_hat_k[k] <- a_hat_k[k] - x_n[n] b_hat_k[k] <- b_hat_k[k] - 1 alpha_hat_k[k] <- alpha_hat_k[k] - 1
$n$番目データを除いた超パラメータ$\hat{\mathbf{a}}_{\backslash n},\ \hat{\mathbf{b}}_{\backslash n},\ \hat{\boldsymbol{\alpha}}_{\backslash n}$の各項は次の式で計算できます。
ただし、処理上は次の式のように、$N$個のデータから求めた$\hat{\mathbf{a}},\ \hat{\mathbf{b}},\ \hat{\boldsymbol{\alpha}}$から$n$番目のデータに関して取り除くことにします。
このとき、$n$番目のデータのクラスタが$k$であればそれ以外の$s_{n,1}, \cdots, s_{n,k-1}, s_{n,k+1}, \cdots, s_{n,K}$は0です。よって、$s_{n,k} = 1$である$k$番目の項のみ処理すればいいことが分かります。
which(s_nk[n, ] == 1)で値が1のインデックスを抽出して、kとします。kが、$n$番目のデータに関して割り当てられたクラスタ番号です。a_hat_k、b_hat_k、alpha_hat_kのk番目の要素のみ上の計算をします。
・潜在変数$\mathbf{s}_n$のサンプリング
$\mathbf{s}_n$の事後分布$p(\mathbf{s}_n | \mathbf{X}, \mathbf{S}_{\backslash n})$から$\mathbf{s}_n$をサンプルします。
$\mathbf{s}_n$の事後分布($\mathbf{s}_n$のサンプリング確率)は
を正規化することで求まります。サンプリングに用いるこの2つの分布を計算しましょう。
a_hat_k, b_hat_kを用いて、式(4.66)の前の項のパラメータを計算します。
# 負の二項分布(4.81)のパラメータを計算 r_hat_k <- a_hat_k p_hat_k <- 1 / (b_hat_k + 1)
負の二項分布のパラメータ$\hat{\mathbf{r}}_{\backslash n} = \{\hat{r}_{1 \backslash n}, \hat{r}_{2 \backslash n}, \cdots, \hat{r}_{K \backslash n}\}$、$\hat{\mathbf{p}}_{\backslash n} = \{\hat{p}_{1 \backslash n}, \hat{p}_{2 \backslash n}, \cdots, \hat{p}_{K \backslash n}\}$の各項は
で計算して、結果をr_hat_k, p_hat_kとします
# 確認
r_hat_k
p_hat_k
## [1] 1327 835 4060 ## [1] 0.017241379 0.010752688 0.009615385
r_hat_k, p_hat_kを用いて、負の二項分布の確率を計算します。
# 負の二項分布の確率を計算:式(4.81) prob_nb_k <- dnbinom(x = x_n[n], size = r_hat_k, prob = 1 - p_hat_k)
負の二項分布の確率は、dnbinom()で計算できます。データ(試行回数)の引数xに$n$番目の観測データの値x_n[n]、成功回数の引数sizeにr_hat_k、成功確率の引数pに1 - p_hat_kを指定します。
# 確認
prob_nb_k
## [1] 2.796239e-02 1.180977e-02 1.317827e-05
a_hat_kを用いて、式(4.66)の後の項のパラメータを計算します。
# カテゴリ分布(4.74)のパラメータを計算:式(4.75) eta_k <- alpha_hat_k / sum(alpha_hat_k)
カテゴリ分布のパラメータ$\boldsymbol{\eta}_{\backslash n} = (\eta_{1 \backslash n}, \eta_{2 \backslash n}, \cdots, \eta_{K \backslash n})$の各項は
で計算して、結果をeta_kとします。
# 確認
eta_k
## [1] 0.2274510 0.3647059 0.4078431
式(4.66)の2つの項が得られたので、$\mathbf{s}_n$のサンプリング確率を計算します。
# n番目のクラスタのサンプリング確率を計算:式(4.66) prob_s_k <- prob_nb_k * eta_k prob_s_k <- prob_s_k / sum(prob_s_k) # 正規化
負の二項分布とカテゴリ分布のパラメータの積を計算をしてprob_s_kとします。また、総和が1となるように正規化します。
# 確認
prob_s_k
## [1] 0.5959251983 0.4035673876 0.0005074141
以上で潜在変数のサンプリング確率が得られました。
prob_s_kを用いて、$\mathbf{s}_n$をサンプルします。
# n番目のクラスタをサンプル:式(4.74) s_nk[n, ] <- rmultinom(n = 1, size = 1, prob = prob_s_k) %>% as.vector()
データの生成時と同様に、多項分布に従いサンプルします。
新たな$n$番目の潜在変数が得られたので、再度$N$個のデータを用いた超パラメータを計算します。
# n番目のデータの新しいクラスタ番号を取得 k <- which(s_nk[n, ] == 1) # n番目のデータに関する統計量を加算:式(4.82-4.83) a_hat_k[k] <- a_hat_k[k] + x_n[n] b_hat_k[k] <- b_hat_k[k] + 1 alpha_hat_k[k] <- alpha_hat_k[k] + 1
今度は、$n$番目データに関して新たに割り当てられたクラスタに従って加算することで、$N$個のデータから求めた超パラメータを計算します。
この処理をfor()ループで$N$回繰り返し行うことで、全ての潜在変数のサンプルが得られます。同時に、更新された潜在変数$\mathbf{S}$を用いた超パラメータ$\hat{\mathbf{a}},\ \hat{\mathbf{b}},\ \hat{\boldsymbol{\alpha}}$も得られます。
さらにこの処理を指定した回数繰り返します。
・推論結果の確認
推論結果を確認していきます。
・最後のパラメータの確認
超パラメータa_hat_kとb_hat_kの最後の更新値を用いて、$\boldsymbol{\lambda}$の事後分布を計算します。
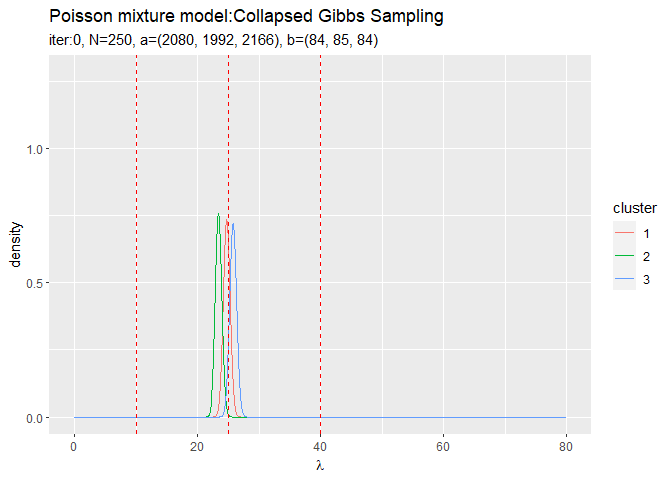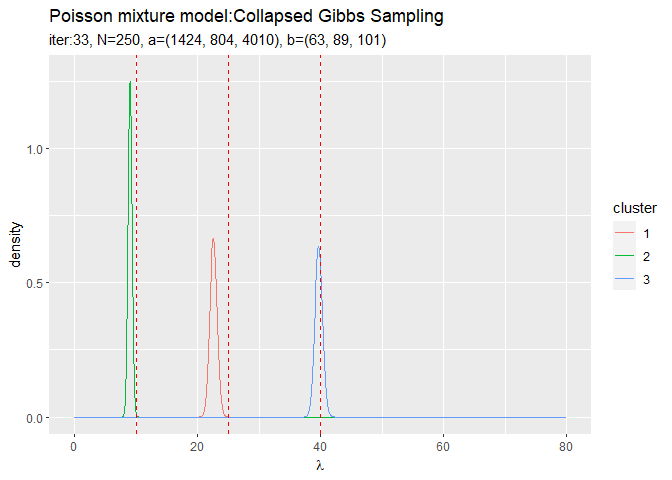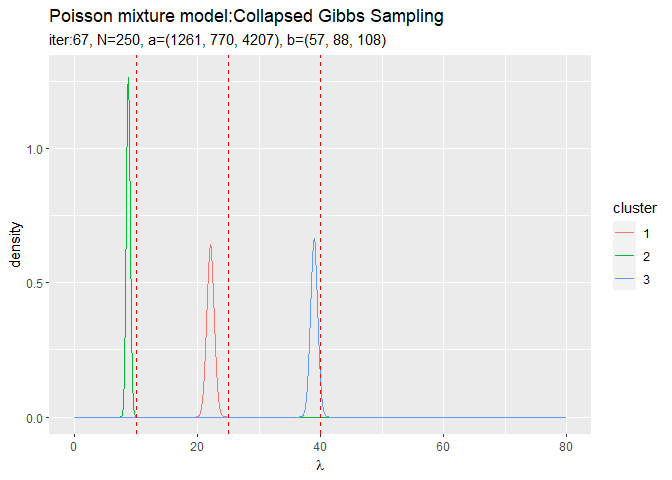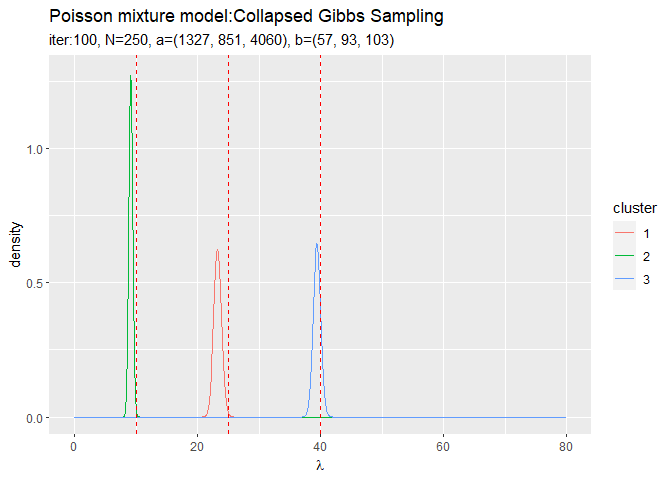
# lambdaの近似事後分布をデータフレームに格納 posterior_lambda_df <- tibble() for(k in 1:K) { # クラスタkの事後分布を計算 tmp_posterior_df <- tibble( lambda = lambda_vec, density = dgamma(x = lambda, shape = a_hat_k[k], rate = b_hat_k[k]), cluster = as.factor(k) ) # 結果を結合 posterior_lambda_df <- rbind(posterior_lambda_df, tmp_posterior_df) } # lambdaの近似事後分布を作図 ggplot(posterior_lambda_df, aes(x = lambda, y = density, color = cluster)) + geom_line() + # lambdaの事後分布 geom_vline(xintercept = lambda_truth_k, color = "red", linetype = "dashed") + # 真の値 labs(title = "Poisson Mixture Model:Collapsed Gibbs Sampling", subtitle = paste0("iter:", MaxIter, ", N=", N, ", a=(", paste0(round(a_hat_k, 1), collapse = ", "), ")", ", b=(", paste0(round(b_hat_k, 1), collapse = ", "), ")"), x = expression(lambda))
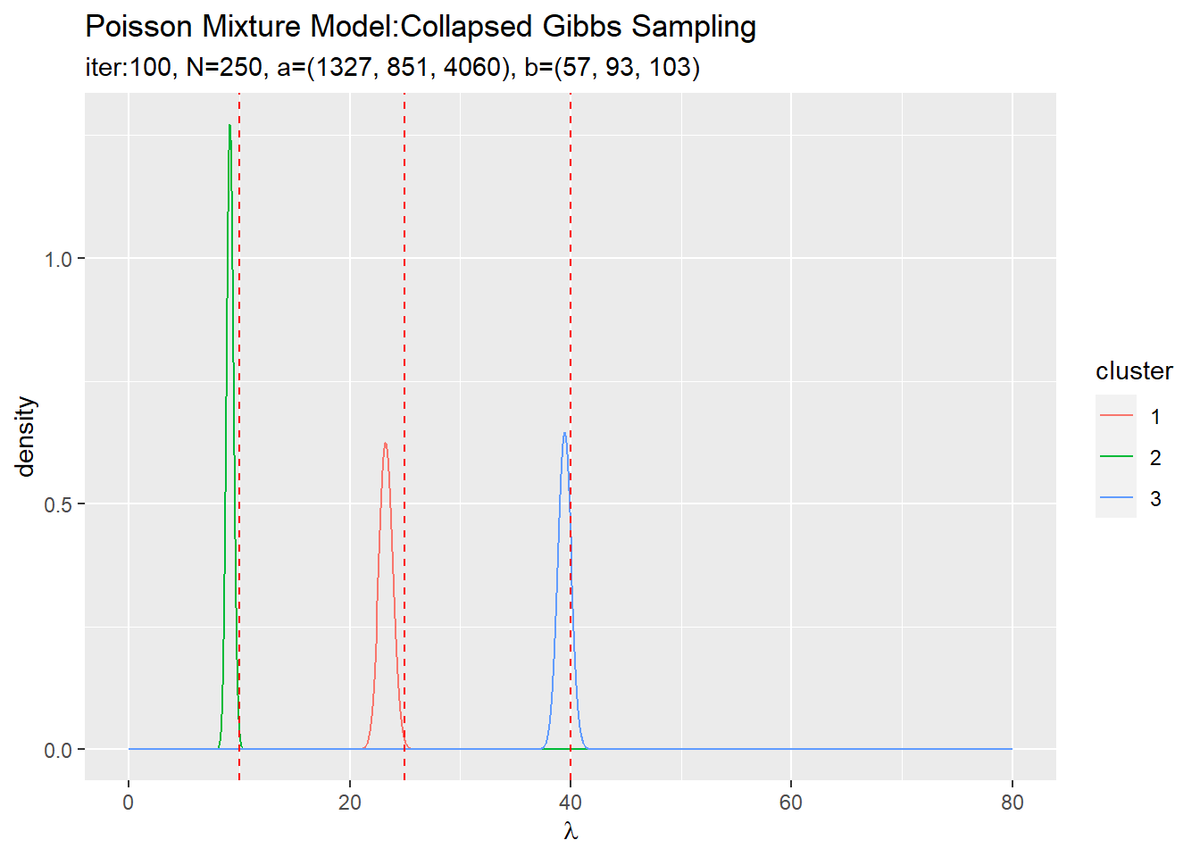
初期値の設定のときと同様にして作図します。
3つのガンマ分布がそれぞれ3つの真の値付近をピークとする分布を推定できています。
また、a_hat_k, b_hat_kとalpha_hat_kを用いて、混合分布を計算します。
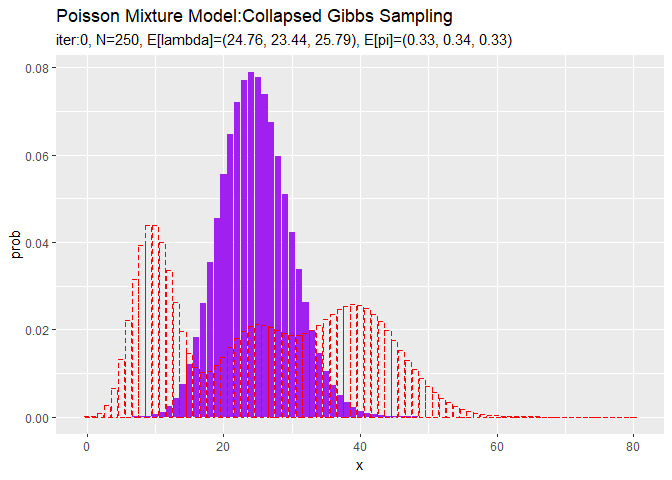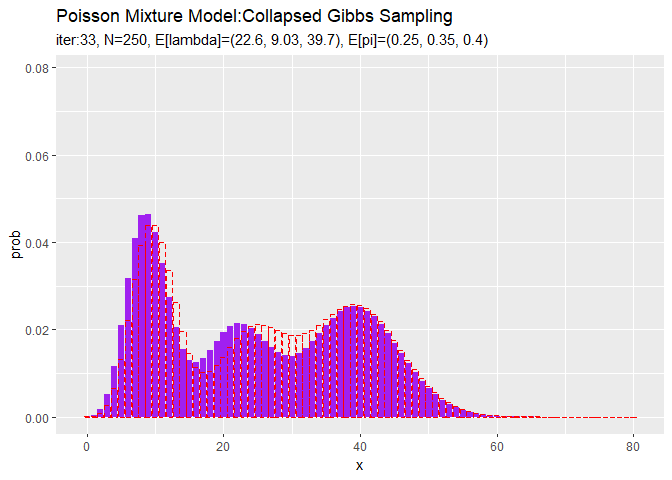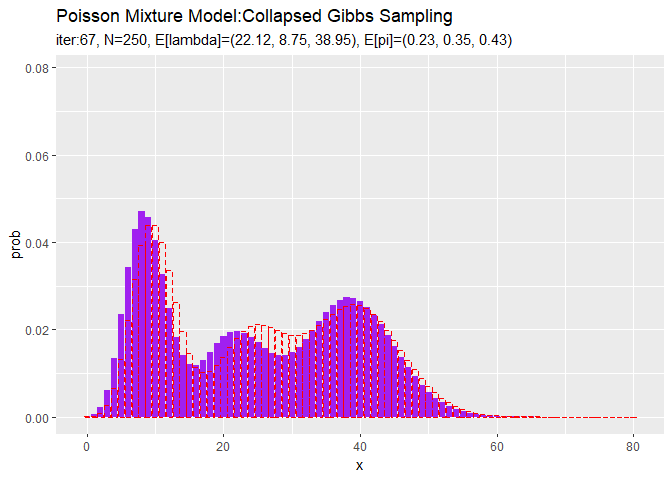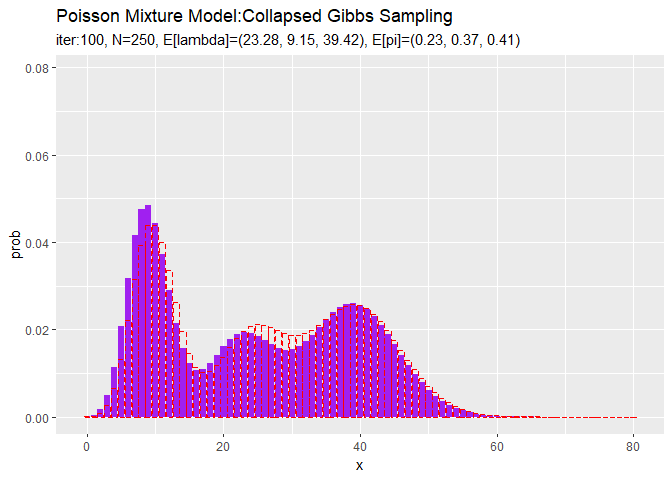
# 最後の推定値による混合分布を計算 res_prob <- 0 for(k in 1:K) { # クラスタkの分布の確率を計算 tmp_prob <- dpois(x = x_vec, lambda = a_hat_k[k] / b_hat_k[k]) # K個の分布の加重平均を計算 res_prob <- res_prob + alpha_hat_k[k] / sum(alpha_hat_k) * tmp_prob } # 最後のサンプルによる分布をデータフレームに格納 res_df <- tibble( x = x_vec, prob = res_prob ) # 最後の推定値による分布を作図 ggplot() + geom_bar(data = res_df, aes(x = x, y = prob), stat = "identity", position = "dodge", fill = "purple", color = "purple") + # 最後の推定値による分布 geom_bar(data = model_df, aes(x = x, y = prob), stat = "identity", position = "dodge", alpha = 0, color = "red", linetype = "dashed") + # 真の分布 labs(title = "Poisson Mixture Model:Collapsed Gibbs Sampling", subtitle = paste0("iter:", MaxIter, ", N=", N, ", E[lambda]=(", paste0(round(a_hat_k / b_hat_k, 2), collapse = ", "), ")", ", E[pi]=(", paste0(round(alpha_hat_k / sum(alpha_hat_k), 2), collapse = ", "), ")"))

初期値の設定のときと同様にして作図します。
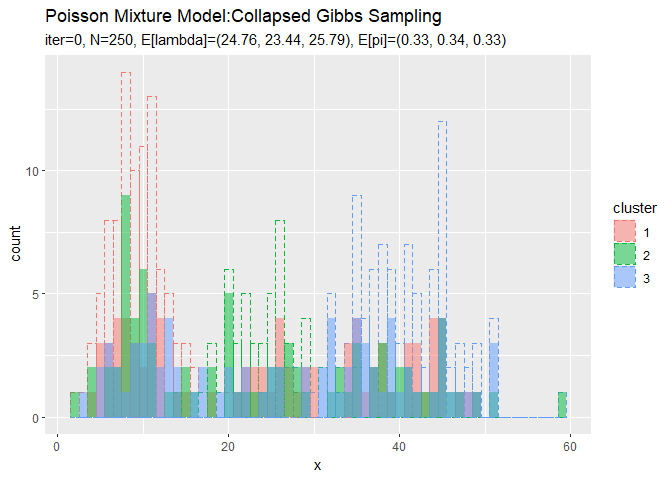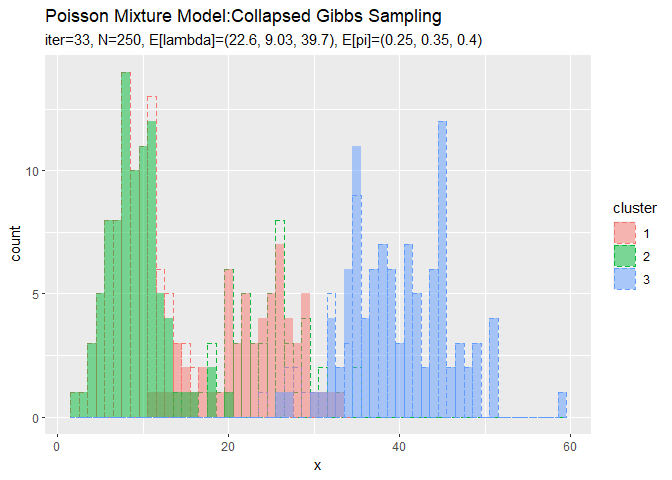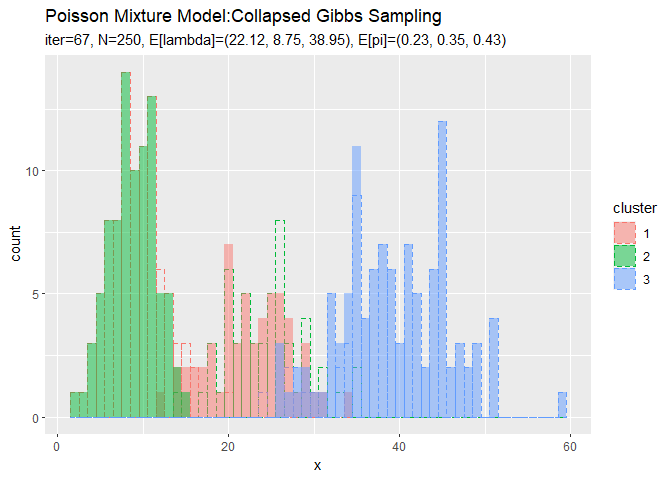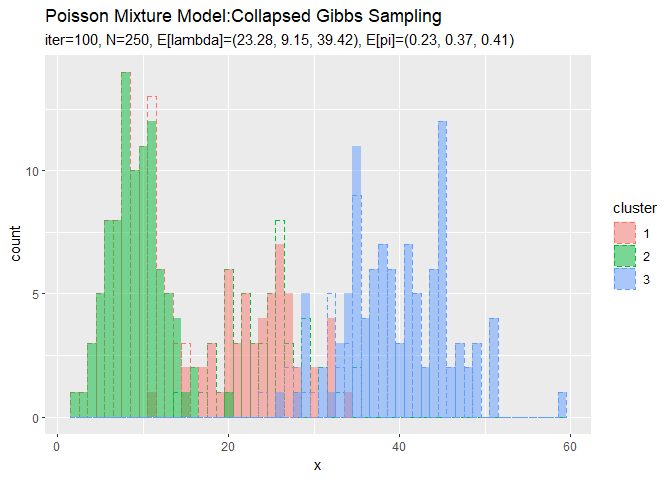
潜在変数s_nkの最後のサンプルを用いて、クラスタのヒストグラムを作成します。
# 最後のクラスタをデータフレームに格納 s_df <- tibble( x_n = x_n, cluster = which(t(s_nk) == 1, arr.ind = TRUE) %>% .[, "row"] %>% as.factor() ) # 最後のクラスタのヒストグラムを作成 ggplot() + geom_histogram(data = s_df, aes(x = x_n, fill = cluster), binwidth = 1, position = "identity", alpha = 0.5) + # 最後のクラスタ geom_histogram(data = x_df, aes(x = x_n, color = cluster), binwidth = 1, position = "identity", alpha = 0, linetype = "dashed") + # 真のクラスタ labs(title = "Poisson Mixture Model:Collapsed Gibbs Sampling", subtitle = paste0("iter:", MaxIter, ", N=", N, ", E[lambda]=(", paste0(round(a_hat_k / b_hat_k, 2), collapse = ", "), ")", ", E[pi]=(", paste0(round(alpha_hat_k / sum(alpha_hat_k), 2), collapse = ", "), ")"), x = "x")

クラスタはランダムに決まるため、クラスタ番号は一致しません。
・超パラメータの推移の確認
超パラメータの更新値の推移を確認します。
・コード(クリックで展開)
各パラメータの学習ごとの値を格納したマトリクスtrace_***をtidyr::pivot_longer()で縦長のデータフレームに変換して作図します。
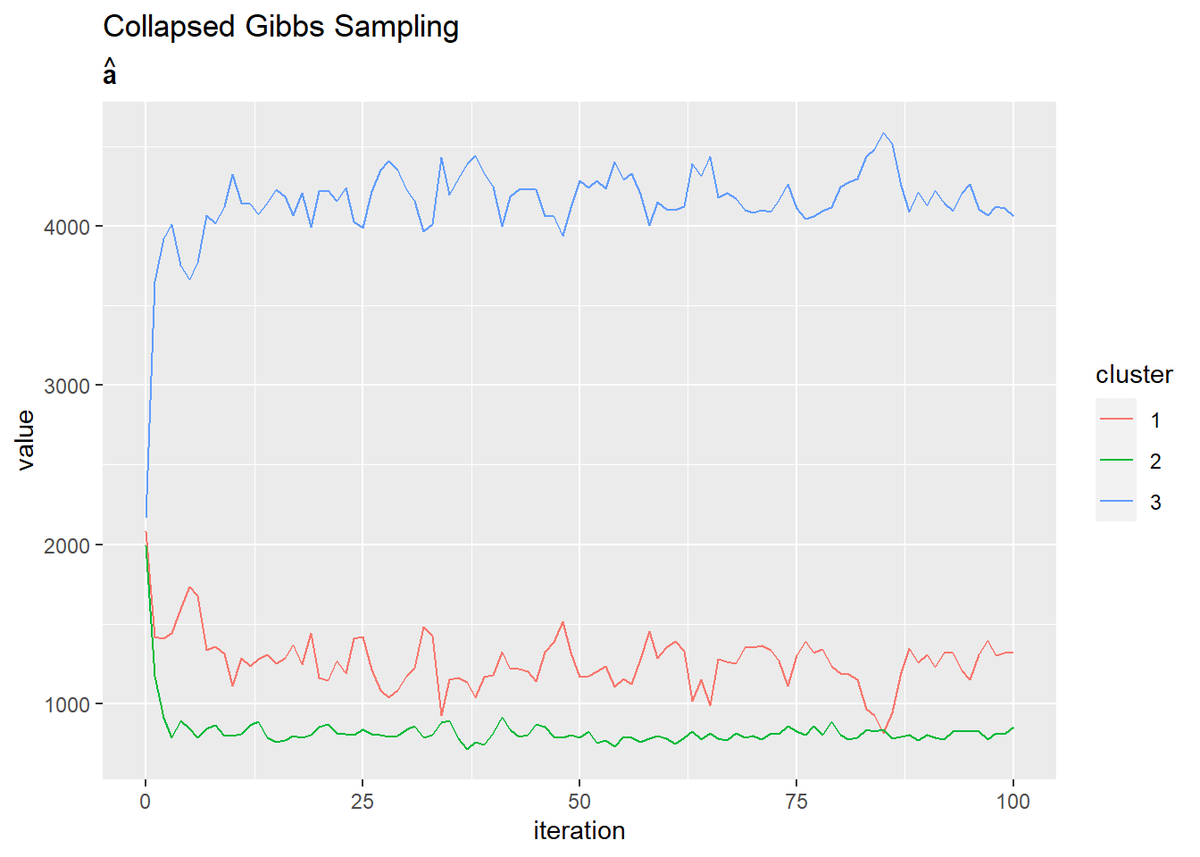
# aの推移をデータフレームに格納 trace_a_df <- dplyr::as_tibble(trace_a_ik) %>% # データフレームに変換 cbind(iteration = 0:MaxIter) %>% # 試行回数の列を追加 tidyr::pivot_longer( cols = -iteration, # 変換しない列 names_to = "cluster", # 現列名を格納する列名 names_prefix = "V", # 現列名の頭から取り除く文字列 names_ptypes = list(cluster = factor()), # 現列名を値とする際の型 values_to = "value" # 現セルを格納する列名 ) # 縦持ちに変換 # aの推移を作図 ggplot(trace_a_df, aes(x = iteration, y = value, color = cluster)) + geom_line() + labs(title = "Collapsed Gibbs Sampling", subtitle = expression(hat(bold(a))))
# bの推移をデータフレームに格納 trace_a_df <- dplyr::as_tibble(trace_b_ik) %>% # データフレームに変換 cbind(iteration = 0:MaxIter) %>% # 試行回数の列を追加 tidyr::pivot_longer( cols = -iteration, # 変換しない列 names_to = "cluster", # 現列名を格納する列名 names_prefix = "V", # 現列名の頭から取り除く文字列 names_ptypes = list(cluster = factor()), # 現列名を値とする際の型 values_to = "value" # 現セルを格納する列名 ) # 縦持ちに変換 # bの推移を作図 ggplot(trace_a_df, aes(x = iteration, y = value, color = cluster)) + geom_line() + labs(title = "Collapsed Gibbs Sampling", subtitle = expression(hat(bold(b))))
# alphaの推移を作図 trace_alpha_df <- dplyr::as_tibble(trace_alpha_ik) %>% # データフレームに変換 cbind(iteration = 0:MaxIter) %>% # 試行回数の列を追加 tidyr::pivot_longer( cols = -iteration, # 変換しない列 names_to = "cluster", # 現列名を格納する列名 names_prefix = "V", # 現列名の頭から取り除く文字列 names_ptypes = list(cluster = factor()), # 現列名を値とする際の型 values_to = "value" # 現セルを格納する列名 ) # 縦持ちに変換 # alphaの推移を作図 ggplot(trace_alpha_df, aes(x = iteration, y = value, color = cluster)) + geom_line() + labs(title = "Collapsed Gibbs Sampling", subtitle = expression(hat(alpha)))


・おまけ:アニメーションによる推移の確認
gganimateパッケージを利用して、各分布の推移のアニメーション(gif画像)を作成するためのコードです。
・コード(クリックで展開)
# 追加パッケージ library(gganimate)
・パラメータの事後分布の推移
作図用のデータフレームを作成します。
# 作図用のデータフレームを作成 trace_posterior_lambda_df <- tibble() for(i in 1:(MaxIter + 1)) { for(k in 1:K) { # クラスタkの事後分布を計算 tmp_posterior_df <- tibble( lambda = lambda_vec, density = dgamma(x = lambda, shape = trace_a_ik[i, k], rate = trace_b_ik[i, k]), cluster = as.factor(k), label = paste0( "iter:", i - 1, ", N=", N, ", a=(", paste0(round(trace_a_ik[i, ], 1), collapse = ", "), ")", ", b=(", paste0(round(trace_b_ik[i, ], 1), collapse = ", "), ")" ) %>% as.factor() ) # 結果を結合 trace_posterior_lambda_df <- rbind(trace_posterior_lambda_df, tmp_posterior_df) } # 動作確認 #print(paste0((i - 1), ' (', round((i - 1) / MaxIter * 100, 1), '%)')) }
各試行における計算結果を同じデータフレームに格納していく必要があります。
分布の推移をgif画像で出力します。
# lambdaの事後分布を作図 trace_graph <- ggplot() + geom_line(data = trace_posterior_lambda_df, aes(x = lambda, y = density, color = cluster)) + # lambdaの事後分布 geom_vline(xintercept = lambda_truth_k, color = "red", linetype = "dashed") + # 真の値 gganimate::transition_manual(label) + # フレーム labs(title = "Poisson mixture model:Collapsed Gibbs Sampling", subtitle = "{current_frame}", x = expression(lambda)) # gif画像を作成 gganimate::animate(trace_graph, nframes = MaxIter + 1, fps = 10)
各フレームの順番を示す列をgganimate::transition_manual()に指定します。初期値を含むため、フレーム数はMaxIter + 1です。
・パラメータの期待値と潜在変数のサンプルの推移
・コード(クリックで展開)
作図用のデータフレームを作成します。
# 作図用のデータフレームを作成 trace_model_df <- tibble() trace_cluster_df <- tibble() for(i in 1:(MaxIter + 1)) { # i回目の分布を計算 res_prob <- 0 for(k in 1:K) { # クラスタkの分布の確率を計算 tmp_prob <- dpois(x = x_vec, lambda = trace_a_ik[i, k] / trace_b_ik[i, k]) # K個の分布の加重平均を計算 res_prob <- res_prob + tmp_prob * trace_alpha_ik[i, k] / sum(trace_alpha_ik[i, ]) } # i回目の分布をデータフレームに格納 res_df <- tibble( x = x_vec, prob = res_prob, label = paste0( "iter:", i - 1, ", N=", N, ", E[lambda]=(", paste0(round(trace_a_ik[i, ] / trace_b_ik[i, ], 2), collapse = ", "), ")", ", E[pi]=(", paste0(round(trace_alpha_ik[i, ] / sum(trace_alpha_ik[i, ]), 2), collapse = ", "), ")" ) %>% as.factor() ) # 結果を結合 trace_model_df <- rbind(trace_model_df, res_df) # i回目のクラスタをデータフレームに格納 s_df <- tibble( x_n = x_n, cluster = as.factor(trace_s_in[i, ]), label = paste0( "iter=", i - 1, ", N=", N, ", E[lambda]=(", paste0(round(trace_a_ik[i, ] / trace_b_ik[i, ], 2), collapse = ", "), ")", ", E[pi]=(", paste0(round(trace_alpha_ik[i, ] / sum(trace_alpha_ik[i, ]), 2), collapse = ", "), ")" ) %>% as.factor() ) # 結果を結合 trace_cluster_df <- rbind(trace_cluster_df, s_df) # 動作確認 #print(paste0((i - 1), ' (', round((i - 1) / MaxIter * 100, 1), '%)')) }
・パラメータの期待値による分布の推移
# アニメーション用に複製 rep_model_df <- tibble( x = rep(model_df[["x"]], times = MaxIter + 1), prob = rep(model_df[["prob"]], times = MaxIter + 1), label = trace_model_df[["label"]] ) # 分布の推移を作図 trace_graph <- ggplot() + geom_bar(data = trace_model_df, aes(x = x, y = prob), stat = "identity", fill = "purple") + # 推定した分布 geom_bar(data = rep_model_df, aes(x = x, y = prob), stat = "identity", alpha = 0, color = "red", linetype = "dashed") + # 真の分布 gganimate::transition_manual(label) + # フレーム labs(title = "Poisson Mixture Model:Collapsed Gibbs Sampling", subtitle = "{current_frame}") # gif画像を作成 gganimate::animate(trace_graph, nframes = MaxIter + 1, fps = 10)
・クラスタのヒストグラムの推移
# アニメーション用に複製 rep_x_df <- tibble( x_n = rep(x_n, times = MaxIter + 1), cluster = rep(as.factor(s_truth_n), times = MaxIter + 1), label = trace_cluster_df[["label"]] ) # クラスタの推移を作図 trace_graph <- ggplot() + geom_histogram(data = rep_x_df, aes(x = x_n, color = cluster), binwidth = 1, position = "identity", alpha = 0, linetype = "dashed") + # 真のクラスタ geom_histogram(data = trace_cluster_df, aes(x = x_n, fill = cluster), binwidth = 1, position = "identity", alpha = 0.5) + # 最後のクラスタ gganimate::transition_manual(label) + # フレーム labs(title = "Poisson Mixture Model:Collapsed Gibbs Sampling", subtitle = "{current_frame}", x = "x") # gif画像を作成 gganimate::animate(trace_graph, nframes = MaxIter + 1, fps = 10)
参考文献
- 須山敦志『ベイズ推論による機械学習入門』(機械学習スタートアップシリーズ)杉山将監修,講談社,2017年.
- 混合ポアソン分布のための崩壊型ギブスサンプリング · GitHub
参考にさせていただきました。
おわりに
一年越しで実装できました!
2021年5月9日は、モーニング娘。'21の15期メンバー岡村ほまれさんの16歳のお誕生日です。
サムネの右端の方です。おめでとうございます!!!
【次節の内容】