はじめに
『トピックモデル』(MLPシリーズ)の勉強会資料のまとめです。各種モデルやアルゴリズムを「数式」と「プログラム」を用いて解説します。
本の補助として読んでください。
この記事では、MeCabを利用して各種モデルによる推論用の頻度データをRで作成します。
【前節の内容】
【他の節の内容】
【この節の内容】
2.1 トピックモデルの文書集合の作成
RMeCabパッケージを利用してテキストファイルから、トピックモデルなどの各種モデルで用いるbag-of-words表現の文書データ(文書と語彙ごとの頻度データ)を作成する。
文書集合については「トピックモデルの文書表現」、真の分布(パラメータ類)を設定して生成モデルに従う簡易的な文書データ(トイデータ)を作成する場合は「各種モデルの生成モデルの実装」を参照のこと。
利用するパッケージを読み込む。
# 利用パッケージ library(RMeCab) library(tidyverse)
この記事では、基本的に パッケージ名::関数名() の記法を使うので、パッケージの読み込みは不要である。ただし、作図コードについてはパッケージ名を省略するので、ggplot2 を読み込む必要がある。
また、ネイティブパイプ演算子 |> を使う。magrittrパッケージのパイプ演算子 %>% に置き換えられるが、その場合は magrittr を読み込む必要がある。
文字コードの変換
まずは、MeCabはUTF-8のテキストファイルしか扱えないので、Shift-JISなどの場合は文字コードを変換しておく必要がある。
テキストファイルの文字コードをShift-JISからUTF-8に変換する。
# 変換前のフォルダパスを指定 dir_path_jis <- "data/text_jis" # 変換後のフォルダパスを指定 dir_path <- "data/text" # ファイル名を取得 file_name_vec <- list.files(path = dir_path_jis) # 文書ごとに文字コードを変換 for(i in 1:length(file_name_vec)) { # ファイルを読込 df <- read.csv( file = paste(dir_path_jis, file_name_vec[i], sep = "/"), # 読み込みファイルパス fileEncoding = "cp932", header = FALSE ) # ファイルを書出 write.table( x = df, file = paste(dir_path, file_name_vec[i], sep = "/"), # 書き出しファイルパス fileEncoding = "utf8", quote = FALSE, row.names = FALSE, col.names = FALSE ) }
read.csv() の fileEncoding 引数に元の文字コードを指定してテキストファイルを読み込み、write.table() の fileEncoding 引数に変換する文字コード(UTF-8)を指定してテキストファイルとして書き出す。
文書データの整形
次は、テキストデータの前処理を行い文書集合と頻度データを作成する。この記事では、(正確には異なる単位だが)形態素を語彙として扱う。
語順を記録しない場合
トピックモデルでは単語が出現した順番は考慮しないので、こちらの方法では、語順の情報を記録(文書集合を作成)せずに語彙ごとの頻度の情報に整形する。作成したbag-of-words表現の文書データからは元の文章を再現できない。
フォルダを指定して、形態素解析を行う。
# フォルダパスを指定 dir_path <- "data/text" # 文書数を設定 D <- list.files(path = dir_path) |> length() # 形態素解析と頻度を集計 mecab_df <- RMeCab::docDF(target = dir_path, type = 1) |> tibble::as_tibble() |> magrittr::set_colnames(c("TERM", "POS1", "POS2", paste0("V", 1:D))) # 列名を文書番号に変更 mecab_df
# A tibble: 1,461 × 25 TERM POS1 POS2 V1 V2 V3 V4 V5 V6 V7 V8 V9 V10 <chr> <chr> <chr> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int> 1 ' 名詞 サ変… 0 0 0 0 0 0 0 0 0 0 2 ( 名詞 サ変… 7 0 2 0 2 8 10 3 3 0 3 ) 名詞 サ変… 6 0 2 0 2 8 5 3 3 0 4 )… 名詞 サ変… 1 0 0 0 0 0 0 0 0 0 5 )「 名詞 サ変… 0 0 0 0 0 0 3 0 0 0 6 1 名詞 数 0 0 0 1 0 0 0 0 0 0 7 100 名詞 数 0 0 0 0 1 0 0 0 0 0 8 119 名詞 数 0 0 0 0 0 0 0 0 0 0 9 4 名詞 数 2 0 0 0 0 0 0 0 0 0 10 8 名詞 数 0 0 0 0 0 0 0 0 0 0 # ℹ 1,451 more rows # ℹ 12 more variables: V11 <int>, V12 <int>, V13 <int>, V14 <int>, V15 <int>, # V16 <int>, V17 <int>, V18 <int>, V19 <int>, V20 <int>, V21 <int>, V22 <int>
(テキストファイルのみが保存されている)フォルダパスを指定して、フォルダ内のテキスト(文書)の形態素解析と語彙の出現頻度(出現回数)の集計を行う。docDF() の分割形式の引数 type に 1 を指定して文章を形態素(語彙)ごとに分割する。
TERM 列に語彙(の原形)、POS1 列に品詞大分類、POS2 列に品詞細分類、その他の列にそれぞれの文書における頻度を格納したデータフレームが出力される。
ファイル名が列名になるので、集計や可視化の処理用に、通し番号(文書番号)の列名にしておく。
集計(分析)に用いる語彙を設定する。
# 抽出する品詞を指定 pos1_vec <- c("名詞", "形容詞", "動詞", "感動詞") # 大分類 pos2_vec <- c("一般", "代名詞", "ナイ形容詞語幹", "形容動詞語幹", "副詞可能", "サ変接続","自立") # 細分類 # 除去する文字列を指定 stop_word_vec <- c("(", ")", "<", ">", "ー") # 合計頻度の下限を指定 lower_total_freq <- 3 # 分析用の語彙を抽出 freq_wide_df <- mecab_df |> dplyr::filter(POS1 %in% pos1_vec) |> # 品詞を抽出 dplyr::filter(POS2 %in% pos2_vec) |> # 品詞を抽出 dplyr::filter(!(TERM %in% stop_word_vec)) |> # ストップワードを除去 dplyr::reframe(dplyr::across(dplyr::starts_with("V")), .by = TERM) |> # 別品詞の頻度を合計 dplyr::rowwise() |> # 行和の計算用 dplyr::mutate( total = sum(dplyr::c_across(dplyr::starts_with("V"))), .before = 2 # 別文書の頻度を合計 ) |> dplyr::ungroup() |> dplyr::filter(total >= lower_total_freq) |> # 低頻度語を除去 |> dplyr::mutate( v = dplyr::row_number(), .before = 1 # 語彙番号 ) freq_wide_df
# A tibble: 250 × 25
v TERM total V1 V2 V3 V4 V5 V6 V7 V8 V9 V10
<int> <chr> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int>
1 1 ' 4 0 0 0 0 0 0 0 0 0 0
2 2 )「 3 0 0 0 0 0 0 3 0 0 0
3 3 AH 6 0 0 0 0 0 0 0 0 0 0
4 4 Baby 8 0 0 0 0 0 0 6 0 0 0
5 5 GO 3 0 0 0 0 0 0 0 0 0 0
6 6 Go 11 0 0 8 0 0 0 0 0 0 0
7 7 I 7 0 0 0 0 0 0 0 0 0 0
8 8 Just 3 0 0 0 0 0 0 0 0 0 0
9 9 Keep 3 0 0 0 0 0 0 0 0 0 0
10 10 Live 4 0 0 0 0 0 0 0 0 0 0
# ℹ 240 more rows
# ℹ 12 more variables: V11 <int>, V12 <int>, V13 <int>, V14 <int>, V15 <int>,
# V16 <int>, V17 <int>, V18 <int>, V19 <int>, V20 <int>, V21 <int>, V22 <int>
品詞(大分類・小分類)を指定して語彙(行)を抽出する。%in% 演算子の左側に対象のベクトル(列)、右側に条件(パターン)のベクトルを指定すると、マッチする要素(行)を抽出できる。
文書(列)ごとに品詞の異なる同じ文字列の語彙の頻度の和を求める。across() と starts_with() を使って、頻度列(列名が V から始まる列)の和を計算できる。
語彙(行)ごとに全ての文書(列)の頻度の和を求めて、全文書での出現回数が少ない語彙(行)を除去する。rowwise() と c_across() を使って、語彙(行)ごとに頻度列の和を計算できる。
その他必要に応じて、ストップワードや記号の除去などの前処理を行う。
bag-of-words表現の文書データ(頻度データ)のマトリクスを作成する。
# 文書ごとの各語彙の出現回数を作成 N_dv <- freq_wide_df |> dplyr::select(!c(v, TERM, total)) |> # 頻度列を取得 t() # 行と列を入替・マトリクスに変換 dimnames(N_dv) <- NULL # 列名・行名を削除 N_dv[1:10, 1:10]
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [1,] 0 0 0 0 0 0 0 0 0 0 [2,] 0 0 0 0 0 0 0 0 0 0 [3,] 0 0 0 0 0 8 0 0 0 0 [4,] 0 0 0 0 0 0 0 0 0 0 [5,] 0 0 0 0 0 0 0 0 0 0 [6,] 0 0 0 0 0 0 0 0 0 0 [7,] 0 3 0 6 0 0 0 0 0 0 [8,] 0 0 0 0 0 0 0 0 0 0 [9,] 0 0 0 0 0 0 0 0 0 0 [10,] 0 0 0 0 0 0 0 0 0 0
各文書の頻度列を取り出して、行が文書、列が語彙に対応するように転置する。t() で転置する際にマトリクスに変換される。
magrittrパッケージのパイプ演算子を使うと次のように処理できる。
# 一部でmagrittrパイプ演算子を使う場合 N_dv <- mecab_df |> dplyr::filter(POS1 %in% pos1_vec) |> # 品詞を抽出 dplyr::filter(POS2 %in% pos2_vec) |> # 品詞を抽出 dplyr::filter(!(TERM %in% stop_word_vec)) |> # ストップワードを除去 dplyr::reframe(dplyr::across(dplyr::starts_with("V")), .by = TERM) |> # 別品詞の頻度を合計 dplyr::select(!TERM) %>% # 頻度列を取得 dplyr::filter(rowSums(.) >= lower_total_freq) |> # 低頻度語を除去 t() # 行と列を入替・マトリクスに変換 dimnames(N_dv) <- NULL # 列名・行名を削除 N_dv[1:10, 1:10]
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [1,] 0 0 0 0 0 0 0 0 0 0 [2,] 0 0 0 0 0 0 0 0 0 0 [3,] 0 0 0 0 0 8 0 0 0 0 [4,] 0 0 0 0 0 0 0 0 0 0 [5,] 0 0 0 0 0 0 0 0 0 0 [6,] 0 0 0 0 0 0 0 0 0 0 [7,] 0 3 0 6 0 0 0 0 0 0 [8,] 0 0 0 0 0 0 0 0 0 0 [9,] 0 0 0 0 0 0 0 0 0 0 [10,] 0 0 0 0 0 0 0 0 0 0
magrittrパイプのプレースホルダ . は、ネイティブパイプのプレースホルダ _ よりも柔軟に処理できる。
各文書の単語数のベクトルを作成する。
# 各文書の単語数を集計 N_d <- rowSums(N_dv) N_d
[1] 80 70 86 34 90 77 118 66 65 48 112 79 77 54 98 79 77 88 61 [20] 42 58 89
各文書の単語数 は、それぞれの文書の全ての語彙の出現回数の和で計算できる。
文書集合に関する値を取得する。
# 文書数を取得 D <- nrow(N_dv) D <- length(N_d) # 語彙数を取得 V <- ncol(N_dv) # 全文書の単語数を取得 N <- sum(N_dv) N <- sum(N_d) D; V; N
[1] 22 [1] 250 [1] 1648
文書数 は
N_dv の行数または N_d の要素数、語彙数 は
N_dv の列数に対応する。
全文書の単語数(総単語数) は、全ての文書の単語数の和で計算できる。
トピックモデルにおける推論処理では単語ごとに計算を行うので、(実際の出現順や意味の通る語順である必要はないが)単語番号と語彙番号の対応関係の情報を用いる。そこで、ランダムに語順を決めて(重複を含む語彙番号を並べ替えて)、単語番号を指定すると対応する語彙番号を得られるオブジェクトを作成しておく。
頻度データのマトリクスから、分析用の(元のデータとは異なる)文書集合のリストを作成する。
# リストを初期化 w_lt <- list() # 文書ごとに単語集合を作成 for(d in 1:D) { # 語彙の出現フラグを作成 flag_vec <- N_dv[d, ] > 0 # 語彙番号を作成 v_vec <- mapply( FUN = \(v, n) {rep(v, times = n)}, (1:V)[flag_vec], N_dv[d, flag_vec] ) |> unlist() # 語彙番号を割当 w_n <- sample(x = v_vec, size = N_d[d], replace = FALSE) # 単語集合 # 単語集合を格納 w_lt[[d]] <- w_n } head(w_lt, n = 3)
[[1]] [1] 57 28 43 103 31 40 130 85 57 50 28 121 84 172 202 103 40 47 50 [20] 81 239 46 34 202 202 47 40 34 68 40 84 57 146 40 196 46 25 196 [39] 177 84 172 81 85 225 144 34 47 86 42 40 40 28 81 69 34 103 25 [58] 57 34 92 85 85 14 81 185 42 16 155 166 40 103 40 34 86 121 92 [77] 92 84 159 92 [[2]] [1] 41 57 41 78 72 111 69 132 46 181 70 143 57 190 79 129 60 145 60 [20] 67 210 129 227 190 72 171 53 148 41 126 93 234 64 132 111 70 72 41 [39] 46 93 144 232 67 111 181 109 109 173 78 109 60 79 207 179 210 129 79 [58] 46 234 57 171 78 53 41 72 191 79 179 57 53 [[3]] [1] 41 62 6 241 112 238 140 140 62 6 120 140 16 16 6 16 222 139 162 [20] 43 174 241 140 241 241 112 57 69 16 140 16 210 183 57 241 25 169 162 [39] 69 179 140 179 183 6 25 41 140 203 6 25 162 162 229 241 6 175 16 [58] 210 6 25 183 16 69 183 210 62 25 25 237 62 241 57 25 140 113 37 [77] 69 221 241 16 188 25 81 69 6 37
文書と語彙ごとの頻度データ N_dv を用いて、D 個のベクトルを格納した文書集合のリストを作成する。各ベクトルは、N_d[d] 個の語彙番号を格納した単語集合のベクトルである。文書ごとに単語数が異なるので、データフレームやマトリクスでは扱えない。
文書(行)ごとに、語彙番号(列インデックス)を単語数(要素の値)個に複製して、ランダムに番号(要素)を入れ替える。mapply() を使って、語彙番号 1:V と各語彙の単語数 N_dv[d, ] のベクトルの要素ごとに処理できる。各要素の処理結果が格納されたリストが出力されるので、unlist() でベクトルに変換する。
単語を指定して語彙を取り出せる。
# 文書番号・単語番号を指定 d <- 3 n <- 5 # 語彙を抽出 v <- w_lt[[d]][n] v_term <- freq_wide_df[v, "TERM"] |> unlist(use.names = FALSE) v; v_term
[1] 112 [1] "人生"
文書集合のリスト w_lt に対して、文書番号をリストのインデックス、単語番号をベクトルのインデックスとして用いると、指定した単語の語彙番号が得られる。
語彙番号と語彙の文字列の対応関係は freq_wide_df から得られる。
文書集合のリストから、各文書の単語数のベクトルを作成する。
# 各文書の単語数を取得 N_d <- lapply(w_lt, FUN = length) |> unlist() # 全文書の単語数を取得 N <- sum(N_d) N_d; N
[1] 80 70 86 34 90 77 118 66 65 48 112 79 77 54 98 79 77 88 61 [20] 42 58 89 [1] 1648
単語集合のベクトル w_lt[[d]] の要素数が単語数に対応する。lapply() を使って、リストに格納された要素ごとに処理できる。
語順を記録する場合
こちらの方法では、可視化時などに利用できる形で単語の出現順(語順)を別のオブジェクトに保存しておき、語彙ごとの頻度の情報に整形する。
ファイルを指定して、形態素解析を行う。
# フォルダパスを指定 dir_path <- "data/text" # ファイルパスを取得 file_path_vec <- list.files(path = dir_path) |> # ファイル名を取得 (\(vec) {paste(dir_path, vec, sep = "/")})() # ファイルパスを作成 # 文書数を取得 D <- length(file_path_vec) # リストを初期化 mecab_lt <- list() # 文書ごとにテキストデータを整形 for(d in 1:D) { # 形態素解析 res_lt <- RMeCab::RMeCabText(file_path_vec[d]) # 結果を抽出 tmp_df <- tibble::tibble( term = lapply(res_lt, FUN = \(vec){vec[1]}) |> unlist(), TERM = lapply(res_lt, FUN = \(vec){vec[8]}) |> unlist(), POS1 = lapply(res_lt, FUN = \(vec){vec[2]}) |> unlist(), POS2 = lapply(res_lt, FUN = \(vec){vec[3]}) |> unlist() ) |> dplyr::mutate( TERM = dplyr::if_else(TERM == "*", true = term, false = TERM) ) |> # (英語などの)原形状態がない場合は活用状態に置換 dplyr::select(TERM, POS1, POS2) # 不要な列を削除 # 結果を格納 mecab_lt[[d]] <- tmp_df } head(res_lt); mecab_lt[[D]]
[[1]] [1] "Vivid" "名詞" "固有名詞" "組織" "*" "*" [7] "*" "*" "" "" [[2]] [1] "Midnight" "名詞" "一般" "*" "*" "*" [7] "*" "*" "" "" [[3]] [1] "…" "記号" "一般" "*" "*" "*" "*" "…" "…" "…" [[4]] [1] "ビビっ" "動詞" "自立" "*" "*" [6] "五段・ラ行" "連用タ接続" "ビビる" "ビビッ" "ビビッ" [[5]] [1] "と" "助詞" "格助詞" "引用" "*" "*" "*" "と" [9] "ト" "ト" [[6]] [1] "し" "動詞" "自立" "*" "*" [6] "サ変・スル" "連用形" "する" "シ" "シ"
# A tibble: 360 × 3 TERM POS1 POS2 <chr> <chr> <chr> 1 Vivid 名詞 固有名詞 2 Midnight 名詞 一般 3 … 記号 一般 4 ビビる 動詞 自立 5 と 助詞 格助詞 6 する 動詞 自立 7 たい 助動詞 * 8 Midnight 名詞 固有名詞 9 自信 名詞 一般 10 も 助詞 係助詞 # ℹ 350 more rows
(テキストファイルのみが保存されている)フォルダパスを指定して、フォルダ内のテキスト(文書)のファイルパスを作成する。
1ファイルずつ順番に RMeCabText() で文章を順番を保ったまま形態素(語彙)ごとに分割する。単語ごとの情報がそれぞれベクトルに格納され、全ての単語のベクトルが格納されたリストが出力される。
各ベクトルの 1 番目の要素に文書中での活用形の語彙、8 番目の要素に原形の語彙、2 番目の要素に品詞大分類、3 番目の要素に品詞小分類が格納される。ただし、英語などの場合は原型が格納されない( 8 番目の要素が * になる)。
文書ごとに TERM 列に語彙の原型、POS1 列に品詞大分類、POS2 列に品詞細分類を格納したデータフレームを作成して、全ての文書のデータフレームをリストに格納していく。ただし、原形の情報がない場合は活用した形の語彙を格納する。lapply() の FUN 引数に処理を指定して、リストに格納された要素ごとに処理できる。
集計(分析)に用いる語彙を設定する。
# 抽出する品詞を指定 pos1_vec <- c("名詞", "形容詞", "動詞", "感動詞") # 大分類 pos2_vec <- c("一般", "代名詞", "ナイ形容詞語幹", "形容動詞語幹", "副詞可能", "サ変接続","自立") # 細分類 # 除去する文字列を指定 stop_word_vec <- c("(", ")", "<", ">", "ー") # 合計頻度の下限を指定 lower_total_freq <- 3 # 分析用の語彙を抽出 vocab_df <- mecab_lt |> dplyr::bind_rows() |> # 全文書を結合 dplyr::filter(POS1 %in% pos1_vec) |> # 品詞を抽出 dplyr::filter(POS2 %in% pos2_vec) |> # 品詞を抽出 dplyr::filter(!(TERM %in% stop_word_vec)) |> # ストップワードを除去 dplyr::summarise( total = dplyr::n(), .by = TERM # 別品詞・別文書の頻度を集計 ) |> dplyr::filter(total >= lower_total_freq) |> # 低頻度語を除去 dplyr::mutate( v = dplyr::row_number(), .before = 1 # 語彙番号 ) vocab_df
# A tibble: 250 × 3
v TERM total
<int> <chr> <int>
1 1 Ready 9
2 2 to 7
3 3 イケイケ 4
4 4 イケ 4
5 5 ーメケメケフィーバー 4
6 6 あばれる 9
7 7 ハヴアグッタイ 4
8 8 ここ 11
9 9 いる 18
10 10 我慢 3
# ℹ 240 more rows
分かち書きした文書データのリスト mecab_lt に格納した全ての文書のデータフレームを行方向に結合する。
品詞(大分類・小分類)を指定して語彙(行)を抽出する。%in% 演算子の左側に対象のベクトル(列)、右側に条件(パターン)のベクトルを指定すると、マッチする要素(行)を抽出できる。
語彙ごとに全ての文書の頻度の和を求めて、文書全体での出現回数が少ない語彙(行)を除去する。summarise() と n() を使って、語彙ごとの頻度(行数)を集計できる。
その他必要に応じて、ストップワードや記号の除去などの前処理を行う。
こちらの方法だと、文書データ全体で出現した順に語彙番号が割り振られる。
中間オブジェクトとして、単語集合のデータフレームを格納した文書集合のリストを作成する。
# 文書集合を作成 word_lt <- mecab_lt |> lapply( FUN = \(df) { df |> dplyr::filter(POS1 %in% pos1_vec) |> # 品詞を抽出 dplyr::filter(POS2 %in% pos2_vec) |> # 品詞を抽出 dplyr::inner_join(vocab_df, by = "TERM") |> # 語彙番号を結合 dplyr::mutate( n = dplyr::row_number() # 単語番号 ) |> dplyr::select(n, v, TERM) } ) word_lt[[D]]
# A tibble: 89 × 3
n v TERM
<int> <int> <chr>
1 1 245 ビビる
2 2 11 する
3 3 69 自信
4 4 237 ほしい
5 5 17 キリ
6 6 18 ない
7 7 245 ビビる
8 8 246 綺羅星
9 9 247 冴える
10 10 219 '
# ℹ 79 more rows
mecab_lt の各文書データから語彙の設定時と同様に語彙を抽出し、集計用の語彙データ vocab_df から対応する語彙番号を結合して、単語番号を追加する。
単語集合のベクトルを格納した文書集合のリストを作成する。
# 文書集合を作成 w_lt <- word_lt |> lapply( FUN = \(df){df[["v"]]} # 単語集合を格納 ) tail(w_lt, n = 3)
[[1]] [1] 45 207 77 88 176 170 191 130 52 192 137 47 243 11 210 136 117 21 11 [20] 90 233 207 197 36 230 191 128 26 89 176 47 85 243 11 52 192 18 11 [39] 243 11 243 11 [[2]] [1] 177 244 244 119 96 244 244 130 67 47 127 95 26 74 11 107 166 244 244 [20] 119 136 211 244 244 238 160 91 11 215 167 101 140 11 91 116 156 244 244 [39] 119 115 211 244 244 133 77 100 11 74 244 244 119 136 211 244 244 238 160 [58] 91 [[3]] [1] 245 11 69 237 17 18 245 246 247 219 134 129 35 134 157 11 68 112 248 [20] 245 11 69 237 17 18 249 249 249 245 11 69 237 17 18 29 172 37 18 [39] 165 198 52 219 48 137 157 11 218 51 112 31 248 250 250 245 246 247 249 [58] 249 245 246 247 95 29 166 21 29 95 95 95 29 157 11 218 51 112 31 [77] 248 250 250 245 246 247 249 249 245 246 247 95 29
単語番号と語彙番号の対応データ word_lt から、文書(データフレーム)ごとに、語彙番号列をベクトルとしてリストに格納する。
単語を指定して語彙を取り出せる。
# 文書番号・単語番号を指定 d <- D n <- 7 # 語彙を抽出 v <- w_lt[[D]][n] v_term <- vocab_df[v, "TERM"] |> unlist(use.names = FALSE) v; v_term
[1] 245 [1] "ビビる"
語彙番号と語彙の文字列の対応関係は freq_wide_df から得られる。
bag-of-words表現の文書データ(頻度データ)のマトリクスを作成する。
# 文書ごとの各語彙の出現回数を作成 N_dv <- word_lt |> lapply( FUN = \(df) { df |> dplyr::summarise( freq = dplyr::n(), .by = v # 頻度を集計 ) |> dplyr::right_join(vocab_df, by = "v") |> # 語彙情報に頻度情報を結合 dplyr::mutate( freq = dplyr::if_else(is.na(freq), true = 0, false = freq) # 未出現語を頻度0に置換 ) |> dplyr::arrange(v) |> # 列の結合用 dplyr::pull(freq) # 頻度列を取得 } ) |> dplyr::bind_cols(.name_repair = ~paste0("V", 1:D)) |> # 全文書の頻度列を結合 t() # 行と列を入替・マトリクスに変換 dimnames(N_dv) <- NULL # 列名・行名を削除 N_dv[1:10, 1:10]
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [1,] 1 1 4 4 4 9 4 2 2 2 [2,] 0 0 0 0 0 0 0 0 3 0 [3,] 8 0 0 0 0 0 0 0 0 0 [4,] 0 0 0 0 0 0 0 0 0 0 [5,] 0 0 0 0 0 0 0 1 1 0 [6,] 0 0 0 0 0 0 0 2 2 0 [7,] 0 0 0 0 0 0 0 3 0 0 [8,] 0 0 0 0 0 0 0 0 0 0 [9,] 0 0 0 0 0 0 0 2 6 0 [10,] 0 0 0 0 0 0 0 0 0 0
word_lt から文書(データフレーム)ごとに、語彙(語彙番号列の値)ごとの頻度(行数)を集計して、集計用の語彙データ vocab_df に対応する頻度を結合する。文書に含まれない語彙は頻度が欠損値になるので 0 に置き換える。
全ての語彙と(頻度0を含む)頻度の対応データフレームになるので、全ての文書の頻度列を列方向に結合して、行が文書、列が語彙に対応するように転置する。t() で転置する際にマトリクスに変換される。
各文書の単語数のベクトルを作成する。
# 各文書の単語数を集計 N_d <- rowSums(N_dv) N_d
[1] 80 70 86 34 90 77 118 66 65 48 112 79 77 54 98 79 77 88 61 [20] 42 58 89
文書集合に関する値を取得する。
# 文書数を取得 D <- nrow(N_dv) # 語彙数を取得 V <- ncol(N_dv) # 全文書の単語数を取得 N <- sum(N_dv) D; V; N
[1] 22 [1] 250 [1] 1648
以上の2つの方法で、テキストデータから、単語集合のベクトル w_n を格納した文書集合のリスト w_lt と、bag-of-words表現の文書データ(文書と語彙の頻度データ)のマトリクス N_dv を作成した。「各種推論アルゴリズムの実装」では N_dv を用いてパラメータ類の推論を行う。
データの可視化
最後は、作成した文書データのグラフを作成する。
文書データの作図
頻度データのデータフレームを作成する。
# 文書と頻度ごとの頻度データを格納 freq_long_df <- N_dv |> t() |> # 行と列を入替 tibble::as_tibble(.name_repair = ~paste0("V", 1:D)) |> # 文書番号の列名を設定 dplyr::mutate( v = 1:V, # 語彙番号 TERM = vocab_df[["TERM"]], .before = 1 ) |> # 語彙情報を追加 tidyr::pivot_longer( cols = !c(v, TERM), names_to = "d", names_prefix = "V", names_transform = list(d = as.numeric), values_to = "freq" ) |> # 語彙ごとの頻度列をまとめる dplyr::select(d, v, TERM, freq) |> # 確認用 dplyr::arrange(d, v) # 確認用 freq_long_df
# A tibble: 5,500 × 4
d v TERM freq
<dbl> <int> <chr> <dbl>
1 1 1 Ready 1
2 1 2 to 1
3 1 3 イケイケ 4
4 1 4 イケ 4
5 1 5 ーメケメケフィーバー 4
6 1 6 あばれる 9
7 1 7 ハヴアグッタイ 4
8 1 8 ここ 2
9 1 9 いる 2
10 1 10 我慢 2
# ℹ 5,490 more rows
文書と語彙ごとの頻度データ N_dv の行と列を入れ替えて、頻度列を並べたデータフレームを作成して、(マトリクスの作成時に削除した)語彙情報を追加する。
pivot_longer() で頻度列を1列にまとめて、列名を文書番号に変換する。
文書ごとに語彙の出現回数のグラフを作成する。
# ラベル用の文字列を作成 doc_df <- tibble::tibble( d = 1:D, max_n = N_d ) data_label <- paste0( "list(", "D == ", D, ", ", "V == ", V, ", ", "N == ", N, ")" ) # 文書ごとの頻度を作図 ggplot() + geom_bar(data = freq_long_df, mapping = aes(x = v, y = freq, fill = factor(v)), stat = "identity") + # 頻度 geom_label(data = doc_df, mapping = aes(x = -Inf, y = Inf, label = paste("N[d] ==", max_n)), parse = TRUE, hjust = 0, vjust = 1, alpha = 0.5) + # 各文書の単語数 facet_wrap(. ~ d, labeller = label_bquote(document~(d): .(d))) + # グラフを分割 guides(fill = "none") + # 凡例の体裁 labs(title = "document set", subtitle = parse(text = data_label), x = expression(vocabulary~(v)), y = expression(frequency~(N[dv])))
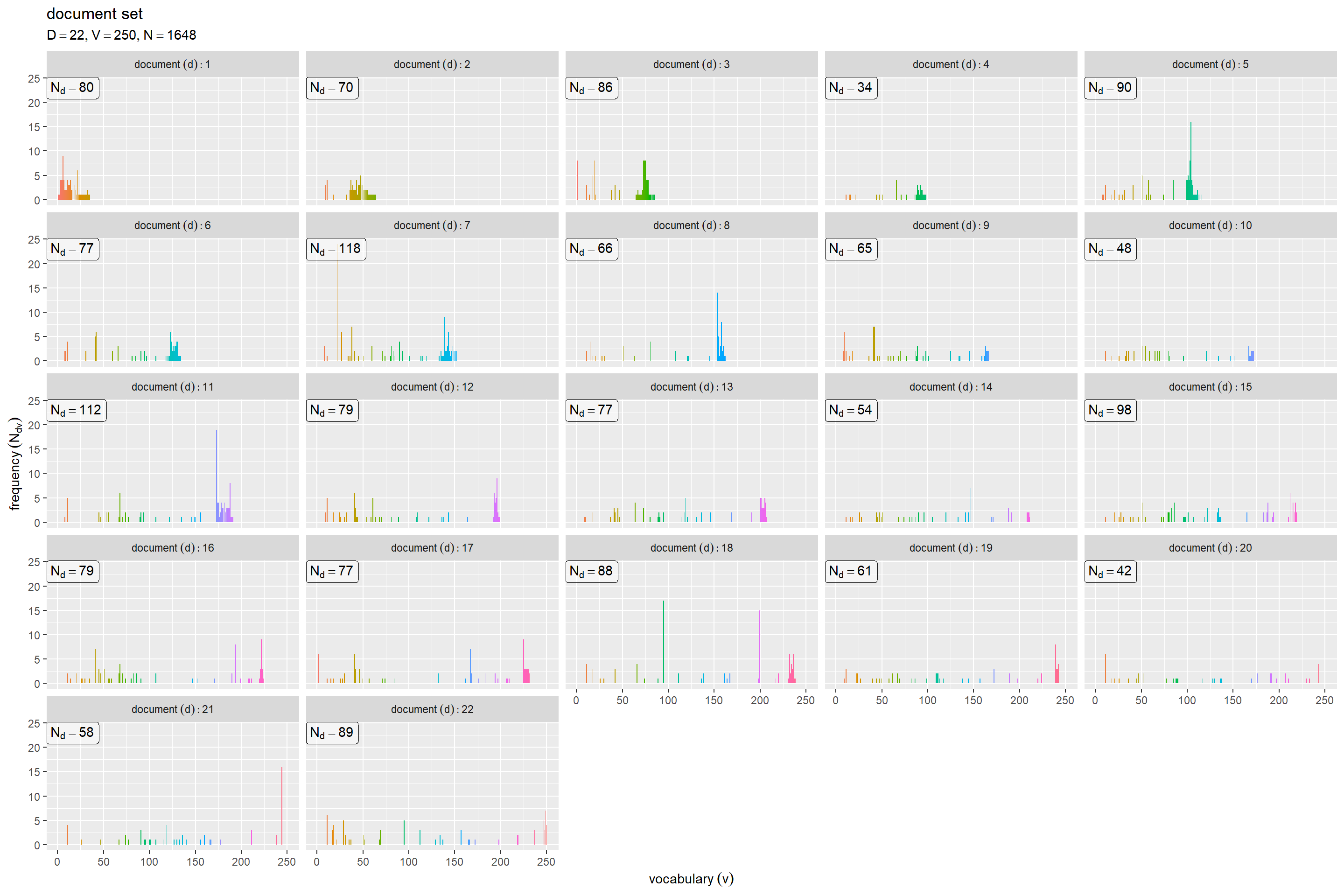
「語順を記録する場合」の方法だと、文書データ全体で出現した順に語彙番号が割り振られるので、文書番号が小さいほど山が左に偏っている。
全文書での出現回数に応じて順位付けする。
# 表示語数を指定 lower_rank <- 25 # 順位を集計 rank_df <- freq_long_df |> dplyr::summarise( total = sum(freq), .by = c(v, TERM) # 総頻度を計算 ) |> dplyr::mutate( rank = dplyr::row_number(-total) # 順位付け ) |> dplyr::filter(rank <= lower_rank) |> # 上位を抽出 dplyr::mutate( rev_rank = dplyr::row_number(-rank) # (反転表示用)逆順の順位付け ) |> dplyr::arrange(rank) # 確認用 rank_df
# A tibble: 25 × 5
v TERM total rank rev_rank
<int> <chr> <dbl> <int> <int>
1 11 する 64 1 25
2 41 君 42 2 24
3 42 私 31 3 23
4 18 ない 30 4 22
5 22 wow 30 5 21
6 95 愛 29 6 20
7 51 なる 26 7 19
8 47 ある 20 8 18
9 74 夢 19 9 17
10 173 ON 19 10 16
# ℹ 15 more rows
語彙ごとに頻度の和を求めて、合計頻度の降順に通し番号を割り当て、指定した語数分の行を取り出す。
y座標の値として、逆順の順位列を追加する。
全文書での高頻度語彙のグラフを作成する。
# 全文書での出現頻度を作図 ggplot() + geom_bar(data = rank_df, mapping = aes(x = reorder(x = paste0(TERM, " (", v, ")"), X = rev_rank), y = total, fill = factor(v)), stat = "identity") + # 合計頻度 geom_text(data = rank_df, mapping = aes(x = rev_rank, y = 0, label = paste(" ", total)), hjust = 0, size = 3) + # 合計頻度 scale_y_continuous(sec.axis = sec_axis(trans = ~.)) + # 頻度軸の第2軸を追加 coord_flip() + # 軸を入替 guides(fill = "none") + # 凡例の体裁 labs(title = "document data", subtitle = parse(text = data_label), x = expression(vocabulary~(v)), y = expression(frequency~(N[v])))
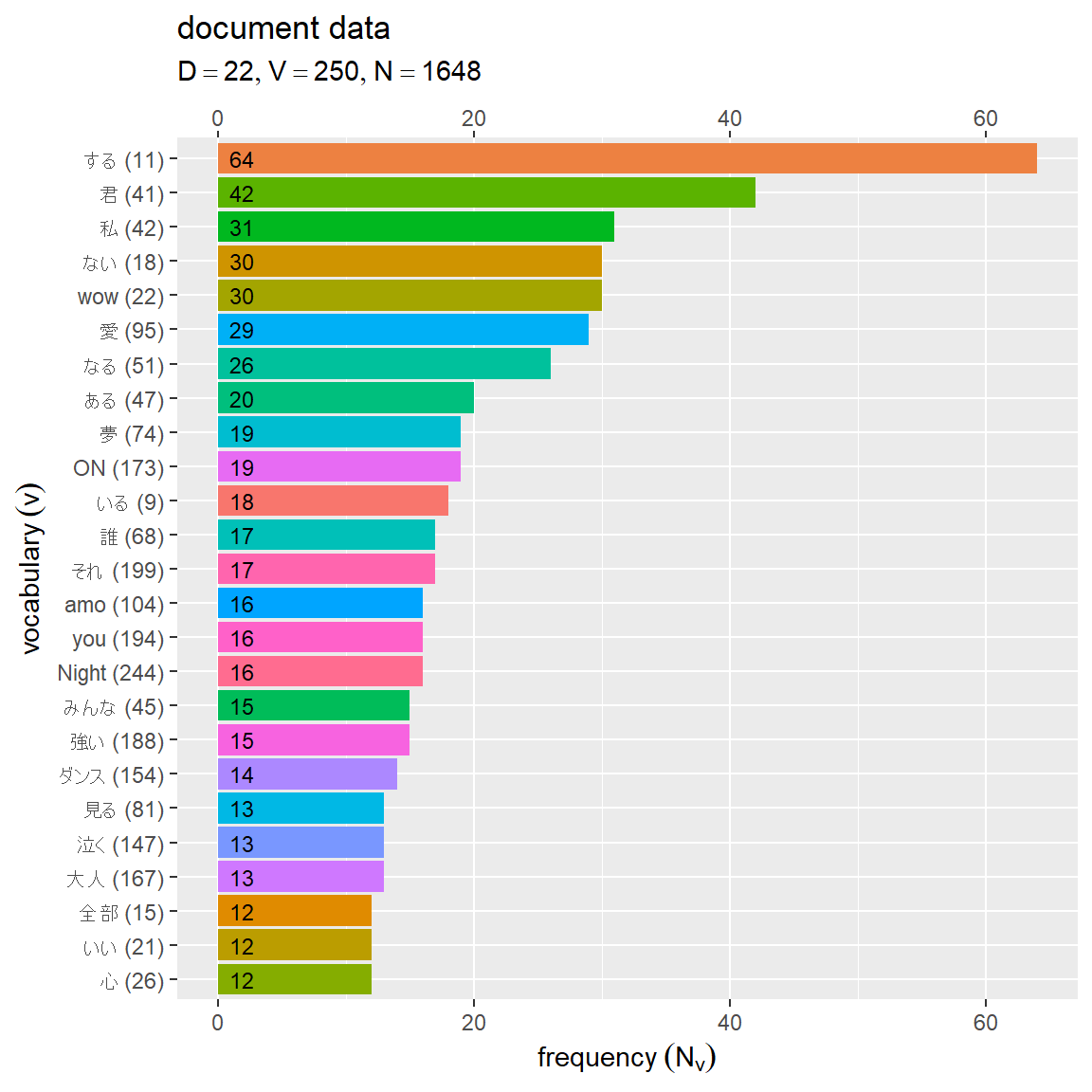
棒グラフのみであれば reorder() に順位列 rank を使った方がシンプルに作図できる。他の geom_***() を重ねるのであれば逆順位列 rev_rank を使った方がシンプルに作図できる。
文書ごとに出現回数に応じて順位付けする。
# 表示語数を指定 lower_rank <- 10 # 文書ごとの rank_df <- freq_long_df |> dplyr::mutate( rank = dplyr::row_number(-freq), .by = d # 順位付け ) |> dplyr::filter(rank <= lower_rank) |> # 上位を抽出 dplyr::mutate( rev_rank = dplyr::row_number(-rank), # 逆順の順位付け reorder = (d-1)*lower_rank + rev_rank, # (反転表示用)プロット位置 .by = d ) |> dplyr::arrange(reorder) # 確認用 rank_df
# A tibble: 220 × 7
d v TERM freq rank rev_rank reorder
<dbl> <int> <chr> <dbl> <int> <int> <dbl>
1 1 13 うち 3 10 1 1
2 1 12 現代 3 9 2 2
3 1 14 やる 4 8 3 3
4 1 11 する 4 7 4 4
5 1 7 ハヴアグッタイ 4 6 5 5
6 1 5 ーメケメケフィーバー 4 5 6 6
7 1 4 イケ 4 4 7 7
8 1 3 イケイケ 4 3 8 8
9 1 22 wow 6 2 9 9
10 1 6 あばれる 9 1 10 10
# ℹ 210 more rows
文書ごとに、頻度の降順に通し番号を割り当て、指定した語数分の行を取り出す。
y座標の値として、文書1から順番に lower_rank 語ずつ降順に並べたときの通し番号を reorder 列とする。
各文書の高頻度語彙のグラフを作成する。
# 文書ごとの出現頻度を作図 ggplot() + geom_bar(data = rank_df, mapping = aes(x = reorder, y = freq, fill = factor(v)), stat = "identity") + # 頻度 geom_text(data = rank_df, mapping = aes(x = reorder, y = 0, label = paste(" ", freq)), hjust = 0, size = 3) + # 頻度 geom_label(data = doc_df, mapping = aes(x = Inf, y = Inf, label = paste("N[d] ==", max_n)), parse = TRUE, hjust = 1, vjust = 1, alpha = 0.5) + # 各文書の単語数 facet_wrap(. ~ d, scales = "free_y", labeller = label_bquote(document~(d): .(d))) + # グラフを分割 scale_x_continuous(breaks = rank_df[["reorder"]], labels = paste0(rank_df[["TERM"]], " (", rank_df[["v"]], ")")) + # 語彙軸目盛ラベルを設定 coord_flip() + # 軸を入替 guides(fill = "none") + # 凡例の体裁 labs(title = "document data", subtitle = parse(text = data_label), x = expression(vocabulary~(v)), y = expression(frequency~(N[dv])))

fracet_***() でグラフを分割する場合、reorder() はデータ全体に対して入れ替えるので(?)、分割したグラフごとの並べ替えにならない。そこで、データ全体での並び順(通し番号)列 reorder を作成しておく。
他に、tidytextパッケージ reorder_within() と scale_y_reordered() を使う方法もある(メモ)。
ストップワードを含めた単語情報を作成する。
# 描画する文書数を指定 doc_num <- 9 # 単語の列数を指定 col_num <- 20 # 文書ごとに単語情報を作成 word_df <- tibble::tibble() for(d in 1:doc_num) { # プロット位置を計算 tmp_df <- mecab_lt[[d]] |> dplyr::left_join( vocab_df |> dplyr::select(v, TERM), by = "TERM" ) |> # 語彙番号を結合 dplyr::mutate( d = d, # 文書番号 v = dplyr::if_else(POS1 %in% pos1_vec, true = v, false = NA), # 別品詞の語彙番号を除去 v = dplyr::if_else(POS2 %in% pos2_vec, true = v, false = NA), # 別品詞の語彙番号を除去 n = dplyr::if_else(!is.na(v), true = cumsum(!is.na(v)), false = NA), # 単語番号 i = dplyr::row_number(), # 座標の計算用 r = (i-1) %/% col_num + 1, # x座標 c = (i-1) %% col_num + 1 # y座標 ) # 単語情報を結合 word_df <- dplyr::bind_rows(word_df, tmp_df) } # 単語の行数を取得 row_num <- max(word_df[["r"]]) word_df
# A tibble: 2,837 × 9 TERM POS1 POS2 v d n i r c <chr> <chr> <chr> <int> <int> <int> <int> <dbl> <dbl> 1 Feel 名詞 固有名詞 NA 1 NA 1 1 1 2 Your 名詞 一般 NA 1 NA 2 1 2 3 FUNK 名詞 一般 NA 1 NA 3 1 3 4 ! 記号 一般 NA 1 NA 4 1 4 5 Are 名詞 固有名詞 NA 1 NA 5 1 5 6 You 名詞 一般 NA 1 NA 6 1 6 7 Ready 名詞 一般 1 1 1 7 1 7 8 to 名詞 一般 2 1 2 8 1 8 9 FUNK 名詞 一般 NA 1 NA 9 1 9 10 ! 記号 一般 NA 1 NA 10 1 10 # ℹ 2,827 more rows
分かち書きした文書データのリスト mecab_lt の全ての単語に対して、集計用の語彙データ vocab_df から語彙番号を結合する。品詞の異なる同じ文字列の単語に対して語彙番号が結合されるので、ストップワードとして除去した( vocab_df に含まれない)単語の番号を欠損値にする。
集計用に抽出した(語彙番号が欠損値でない)単語に対して通し番号を割り当てて、抽出した語彙の単語番号を再現する。
ストップワードを含めた全ての単語に対して通し番号を割り当てて、単語のプロット位置を計算する。
文書ごとに単語を並べたグラフを作成する。
# ラベル用の文字列を作成 doc_df <- tibble::tibble( d = 1:doc_num, max_n = N_d[d], upper_n = word_df |> dplyr::filter(i == max(i), .by = d) |> # 語数を抽出 dplyr::pull(i) ) # 単語情報を作図 ggplot() + geom_tile(data = word_df, mapping = aes(x = c, y = r, fill = factor(POS1)), alpha = 0.2) + # 語彙情報 geom_text(data = word_df, mapping = aes(x = c, y = r, label = TERM, color = factor(v))) + # 語彙ラベル geom_label(data = doc_df, mapping = aes(x = Inf, y = Inf, label = paste("N[d] ==", max_n, "~(", upper_n, ")")), parse = TRUE, hjust = 1, vjust = 0, alpha = 0.5) + # 各文書の単語数 scale_x_continuous(minor_breaks = NULL) + scale_y_reverse(minor_breaks = NULL) + facet_wrap(. ~ d, labeller = label_bquote(document~(d): .(d))) + # グラフを分割 guides(color = "none") + # 凡例の体裁 labs(title = "document data", subtitle = parse(text = data_label), fill = "part of speech", x = "", y = "")
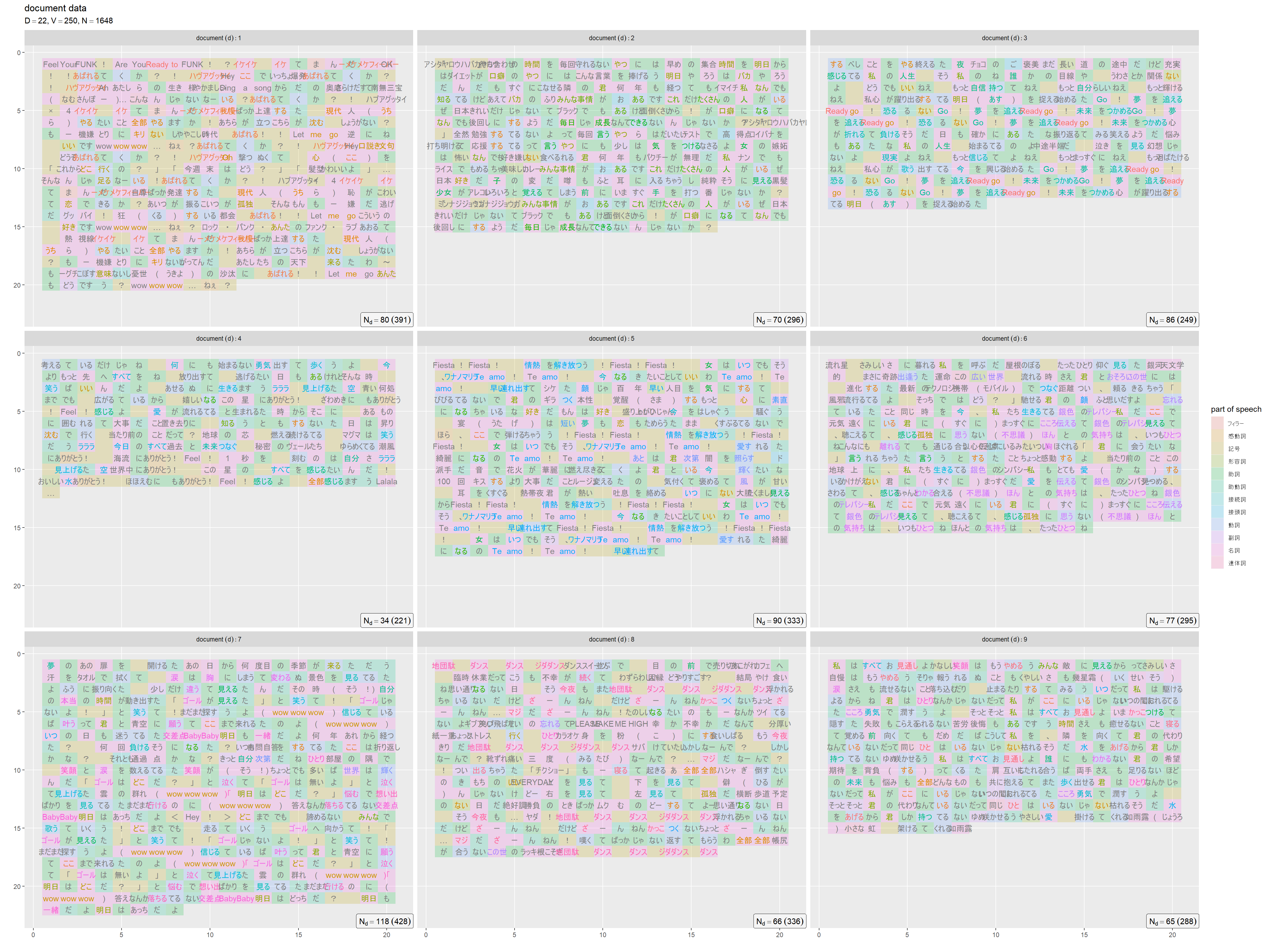
ここでは、文字列を語彙番号、セルを品詞に応じて配色している。グレー色の単語は、ストップワードとして削除された語彙を表す。各グラフの右下のラベルは、抽出した(分析に用いる)語彙の単語数であり、丸括弧の値は除去した(分析に用いない)語彙も含めた数である。
推論結果などの可視化では、トピックごとに色付けするなどして各文書の特徴を見る。
この記事では、各種モデルに対応した文書データをテキストファイルから作成した。各種推論アルゴリズムで利用できる。
参考書籍
- 岩田具治(2015)『トピックモデル』(機械学習プロフェッショナルシリーズ)講談社
- Juice=Juice(2018)『Juice=Juice#2 -¡Una más!-』(CD)アップフロントワークス
おわりに
トイデータ作りをモデルごとに実装してるので、生データの集計も一応やっておくことにしました。あくまでアルゴリズムの理解のためのスクラッチ実装であって、生データを使う(分析する)つもりはないんだけどなぁ。
元々は自然言語処理をするために勉強を始めたのですが、MeCabを触るは本当に久しぶりです。どれくらいぶりかというと、PCにMeCabは入っていたものの、現在使っているバージョンのR用にはRMeCabパッケージが入っていませんでした。最後に使った記憶もありません。
軽い気持ちで書き始めたので当初は、頻度の集計データの作成と、表4.2に対応する図に再利用できる頻度の図の作成の2本立てのつもりで書き始めました。ところが筆がノって、語順を残す処理を書き足し、語順情報があるならと図2.1の図を作り、その完成図を見たら物足りなくて削除した語も含めた図(白本の図2.2)にアップデートしました。
いいリハビリになりましたが、想定の数倍の時間がかかりました。そろそろ数式読解編と実装編の修正作業に取り組みます。
2024年4月20日は、OCHA NORMAの石栗奏美の20歳のお誕生日です!
バラエティができるタイプのハロメンなので早くお茶の間さまに見つかってほしいー。
【次節の内容】