はじめに
機械学習プロフェッショナルシリーズの『トピックモデル』の勉強時に自分の理解の助けになったことや勉強会資料のまとめです。トピックモデルの各種アルゴリズムを「数式」と「プログラム」から理解することを目指します。
この記事は、1.1.8項「カルバック・ライブラー・ダイバージェンス」と1.1.9項「連続確率変数」と1.1.9項「イェンゼンの不等式」の内容です。情報量からKL情報量までの関係性とイェンゼンの不等式の簡単な利用目的を確認していきます。
【前節の内容】
【他の節一覧】
【この節の内容】
1.1.8 カルバック・ライブラー・ダイバージェンス
カルバック・ライブラー・ダイバージェンス(KLダイバージェンス・KL情報量)とは、確率分布間の非類似度(「どれくらい似ていないか」は「違いの程度」であり、つまりどれくらい似ているのかを表す)として用いられる。相対エントロピーとも呼ばれる。
まずは、情報量という概念から確認していく。
・情報量
情報を定量的に扱うことで、足し引きや大小比較できるようにしたい。そこで、事象$x$の生起確率$p(x)$を基にして情報量$I(x)$を次のように定義する。
$0 \leq p(x) \leq 1$なので、$\log p(x)$は常に負の値になる。よって符号を反転した値を情報量とすることで、常に正の値をとるようにする。$\log$の底が2なのは、IT分野において0と1からなるbitとの相性からよく使われるためである。比較対象と揃っていれば底の値は特に重要ではない。
この定義に従うと、確率$p(x)$が低いほど情報量$I(x)$が大きくなる。これは、分かり切った出来事(事象)の情報よりも予測が難しい(確率が低い)出来事(事象)の情報の方が価値が高いことを表現できるため都合がよい。
例えば、$p(x) = \frac{1}{10},\ p(y) = \frac{1}{4}$としたときの情報量は
となる。4択の答えよりも予測のしづらい10択の答の方が、情報の価値が高いことを表している。
また、2つの事象$x,\ y$の情報を同時に得ることを考える。$x,\ y$の生起確率は(独立していれば)同時確率$p(x, y) = p(x) p(y)$なので、$x$の生起確率と$y$の生起確率の積で表現できる。同時確率の対数をとった値を情報量とすると、情報量$I(x, y)$は
となる。
つまり$x,\ y$の情報を同時に持つ価値は、$x$の情報量$I(x)$と$y$の情報量$I(y)$の和で求められる。これは複数の情報を得たとき情報量が加算的に増えていくことを表現できるため、感覚的な「情報量」の扱いと合致していて都合がよい。
先ほどの例だと
となる。
続いて、確率$p(x)$と情報量$I(x)$の関係をグラフで見る。
# 利用パッケージ library(tidyverse) # 作図 tibble( p = seq(0.01, 0.99, 0.01), # 確率 I = - log2(p) # 情報量 ) %>% ggplot(mapping = aes(x = p, y = I)) + # データ geom_line(color = "#00A968") + # 折れ線グラフ labs(title = "Information Content(bit)") # タイトル
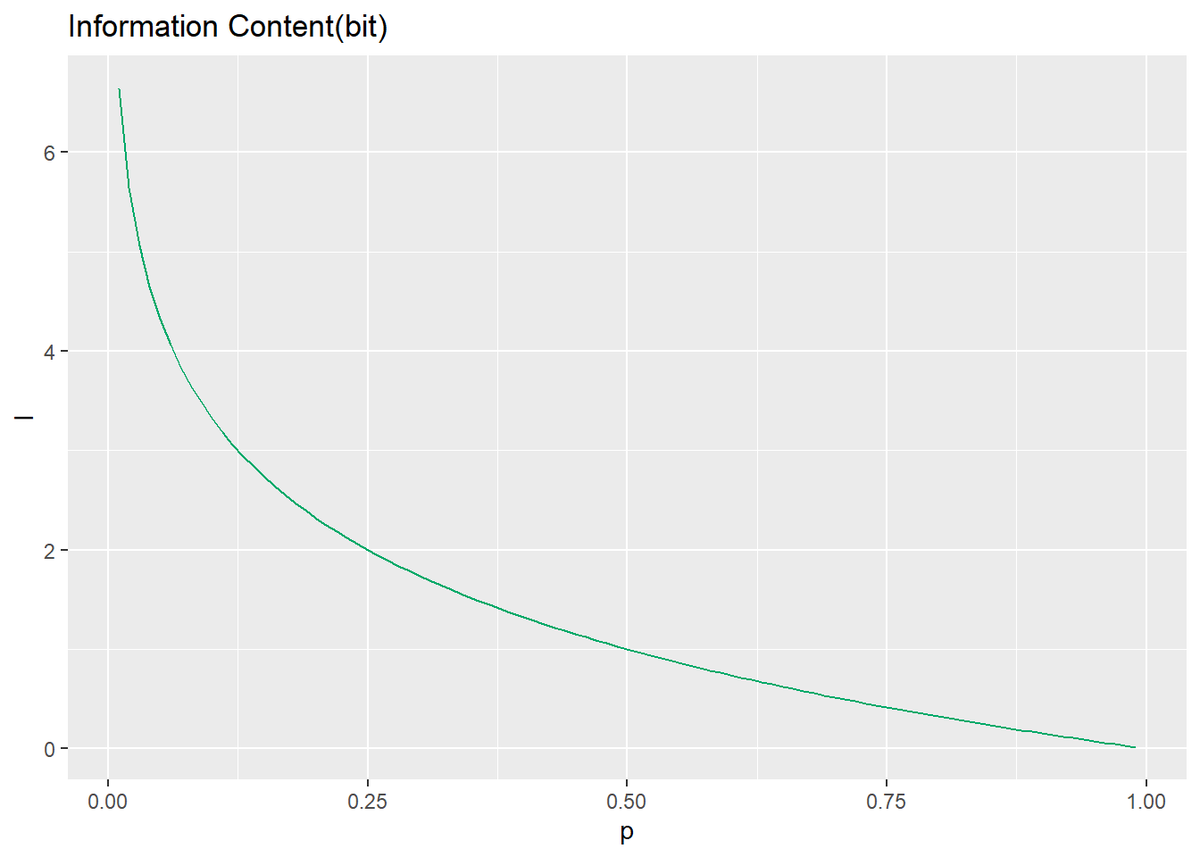
確率が高くなるほど情報量が小さくなるのを確認できる。
・平均情報量
変数$x$の生起確率から情報量が求まるということは、生起確率$p(x)$と情報量$I(x)$で加重平均をとることで情報量の期待値を求められる。それを平均情報量$H(x)$と言う。またエントロピーとも呼ぶ。
確率$p(\boldsymbol{x})$と情報量$- \log_2 p(\boldsymbol{x})$はどちらも常に正の値なので、平均情報量も正の値になる。
二項分布のパラメータ$\phi$と平均情報量$H(x)$の関係をグラフで見る(二項分布については1.2.1節で説明する)。$\phi$はコインが表となる確率を表す。
# 試行回数を指定 N <- 100 # 表の回数 x <- 0:N # 二項分布のパラメータ(コインの歪み具合) phi <- seq(0.01, 0.99, 0.01) # phiごとに平均情報量を計算 H <- NULL # 平均情報量を初期化 for(i in seq_along(phi)) { p <- dbinom(x, N, phi[i]) # 表の回数ごとの確率 I <- - log2(p) # 情報量 H <- c(H, sum(p * I)) # 平均情報量を追加 } # 作図 tibble( phi = phi, # 二項分布のパラメータ H = H # 平均情報量 ) %>% ggplot(mapping = aes(x = phi, y = H)) + # データ geom_line(color = "#00A968") + # 折れ線グラフ labs(title = "Entropy(Binomial Distribution)") # タイトル
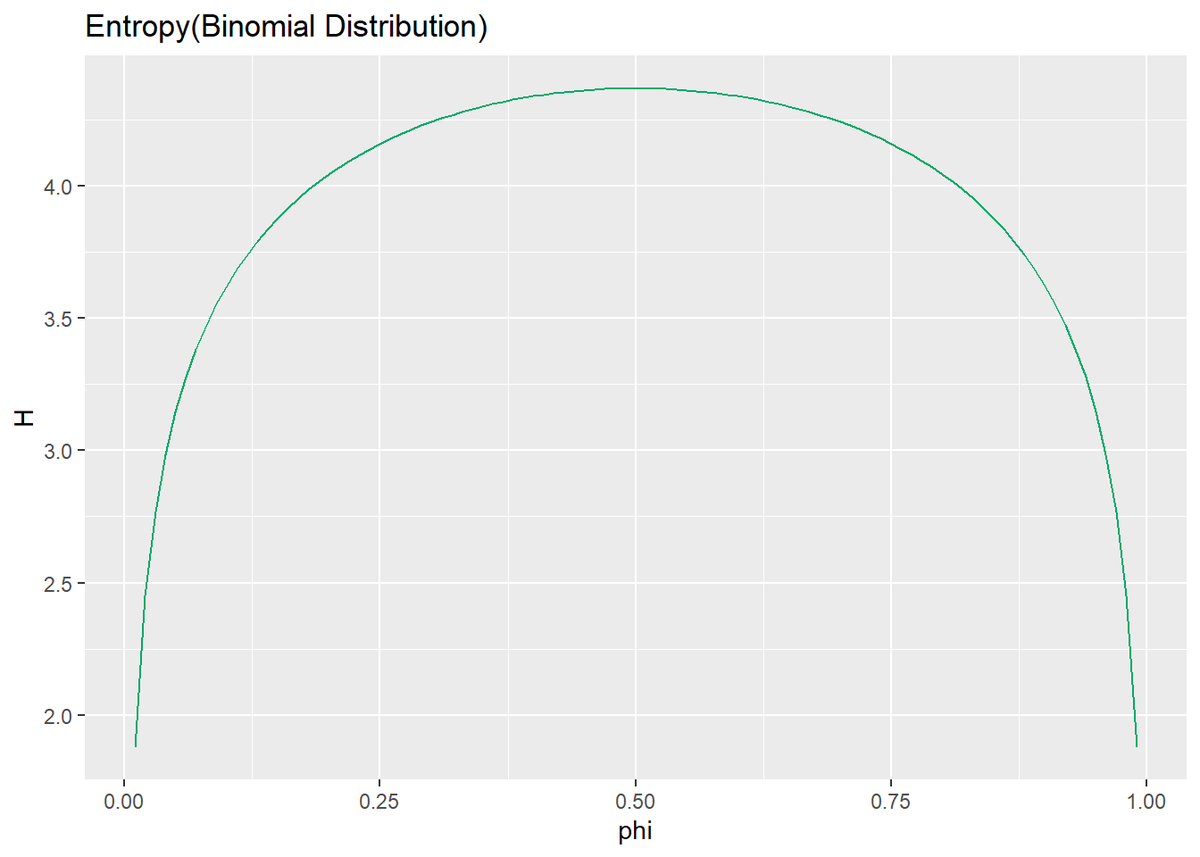
二項分布のパラメータ$\phi$によって、平均情報量$H$が変化している。$\phi$はコインの歪み具合のことで、0に近いほど裏が出やすく、1に近いほど表が出やすくなる。グラフを見ると$\phi = 0.5$のときに平均情報量$H$が高くなっている。つまり、裏表の出やすさが等しい(どちらになるのかに偏りがなく不確実性が一番高い)とき、平均情報量が一番高くなることが確認できる。
ここまでは$\log_2$を使ったが、以降は自然対数$\log$を用いる。統一されていれば問題ないので、情報量に自然対数を用いることもある。
・KL情報量
想定する確率分布$p(x)$が複雑で利用しづらいとき、$p(x)$に近似した分布$q(x)$を用いることがある。このとき、$q(x)$が$p(x)$をどれだけ近似できているのかが重要になる。
そこで、$q(x)$の平均情報量と$p(x)$の平均情報量の差をみることにする。ただし、近似分布の情報量$I(q(x))$に対して、目的の確率分布$p(x)$を使って期待値をとったものを用いる。
これをKLタイバージェンス$\mathrm{KL}(p, q)$とする。$\mathrm{KL}(p, q)$は$\log p(x)$と$\log q(x)$の差を$p(x)$で期待値をとったものとなる。
変数$x$が連続値をとる場合は、総和を積分に置き換えると求められる。
また式(1.6)よりの2行目から、符号を反転させて分母分子を入れ替えた形とすることもある。
このKLダイバージェンス$\mathrm{KL}(p, q)$が小さいほど2つの分布が似ているといえる。
2つの確率分布に非類似度が$\mathrm{KL}(p, q) = 0$(差がない)ということは、同じ分布($p = q$)であるということである。また$p = q$のときのみ$\mathrm{KL}(p, q) = 0$となる。
なお、非類似度を分布間の近さ(距離)のように扱われることもあるが、$\mathrm{KL}(p, q) \neq KL(q, p)$であるため、数学的な距離の公理を満たさない。
本(トピックモデル)では、文書の生成モデル(単語集合の同時確率)$p(\boldsymbol{W})$とその近似分布で構成される変分下限$F[q(\boldsymbol{Z}, \boldsymbol{\theta}, \boldsymbol{\phi})]$のKLダイバージェンス$\mathrm{KL}(q, p)$を最小化することを目指す(下限については1.1.10項のイェンゼンの不等式で説明する。実際に利用するのは3章以降)。
この関係を簡易的に表現すると、$\mathrm{KL}(q, p)$は$\log p(\cdot) - F[\log q(\cdot)]$で構成されている。ここから$\log p(\cdot)$が$\mathrm{KL}(q, p) + F[\log q(\cdot)]$であるといえる。$p(\cdot)$は定数(既に決まっているもの)なので、$KL(q, p)$を最小化と変分下限を最大化とは同義であることが分かる。よって、2つの分布から値が定まるKL情報量の最小化ではなく、(扱いやすく設計した)変分下限の最大化を目標とする。
1.1.9 連続確率変数
これまではサイコロの目のように$1, 2, \cdots$の値をとる離散値を扱ってきた。ここでは値が切れ目なく続く連続値の場合を確認していく。
1から6の値の中から1が出る確率を離散値で考えると$\frac{1}{6}$であるが、連続値だと1から6の値は無限にあるので$\frac{1}{\infty} = 0$となる。
そこで確率密度という概念を導入し、相対的な出やすさで表す。(箱の中に$1, 2, \cdots, \infty$の数字が書かれたカード(これ自体は離散値)が1枚ずつ入っている。その箱から1枚引くとき、カードが1である確率と1から10のどれかである確率は$\frac{1}{\infty} = \frac{10}{\infty} = 0$なのだが、「1」と「1から10」の2つを比較すると「1から10」の方が10倍出やすいよねという考え方。)(これを座標平面(グラフ)上で考えると、点や線ではなく範囲(面積)として表現できる(面積を求める、つまり積分を使って求める)。面積が大きいほど確率が高くなる。)
連続値をとる確率変数$X$が$a$から$b$の値をとる確率$p(a \leq X \leq b)$は、次のようにして求められる(定義される)。
この定義式の$p(x)$を確率密度関数と言う。これに対して離散値の場合は確率質量関数と呼ぶ。
確率密度は0以上の値をとり、全ての可能性を考慮する(全ての範囲で積分する)と値は1となる。($p(a \leq X \leq b)$は確率なので、0から1の値をとる。)
離散変数の期待値は関数$f(x)$と確率質量関数$p(x)$の積の総和をとって求めたが、連続値をとる変数の場合は関数$f(x)$と確率密度関数$p(x)$の積を積分して期待値を求める。
周辺化やKLダイバージェンスの計算でも同様で、和を積分に置き換えることで計算できる。
厳密には確率と確率密度関数を別のものなので書き分ける必要があるが、本(この資料)では実用上に問題がないため特に区別せずにどちらも$p(\cdot)$で表現する。
本(トピックモデル)では、トピック集合の分布$p(\boldsymbol{Z})$は離散確率分布、パラメータの分布$p(\boldsymbol{\theta}),\ p(\boldsymbol{\phi})$は連続確率分布として扱う。
1.1.10 イェンゼンの不等式
上向きの凸関数(窪みのないグラフになる関数)に対して、イェンゼンの不等式を用いることでその関数の下限を求める事ができる。
上に凸な曲線$f(x)$と、その曲線上の任意の2点$(x_1, f(x_1)),\ (x_2, f(x_2))$を結ぶ線分について考える(図1.2)。
$x$軸方向に$x_1$と$x_2$を$\phi_1 : (1 - \phi_1)$で内分する値は$\phi_1 x_1 + (1 - \phi_1) x_2$となる。ただし$\phi_1$は0から1の値とする。
$x$軸がこの値となる曲線上の点の$y$軸の値は、$f(\phi_1 x_1 + (1 - \phi_1) x_2)$と表現できる。また$x$軸がこの値となる線分上の点の$y$軸の値は、$y$軸方向に$f(x_1)$と$f(x_2)$を内分する点なので、$\phi_1 f(x_1) + (1 - \phi_1) f(x_2)$となる。
この2つの値は次の関係が成り立つ。
これはつまり、曲線$f(x)$を曲線上の2点を結ぶ線分で分割したとき、その線分上のどの点よりも大きい曲線上の点が必ず存在することを示している。
これを$V$次元に拡張しても同様である。上に凸な関数$f(x)$に対して、$\phi_1, \phi_2, \cdots, \phi_V$が$\phi_v \geq 0,\ \sum_{v=1}^V \phi_v = 1$を満たすとすると、次の関係が成り立つ。
この式をイェンゼンの不等式と呼ぶ。
この不等式から、右辺の関数は左辺の関数の下限といえる。また右辺を最大するパラメータを求めたとき、そのパラメータは左辺も最大化することが分かる。
つまり求めたい関数の計算が困難であるとき、イェンゼンの不等式を用いてその関数の下限となる関数を求めてそれを最大化することで、求めたい関数も最大化できる。
本(トピックモデル)では、変分ベイズ推定において対数周辺尤度関数$\log p(\boldsymbol{W})$の変分下限を求めるのに用いる。
求めたい分布(1行目)の式が$\log$の中に積分や総和の計算を含み計算することが難しいときに、イェンゼンの不等式を用いて下限となる分布(2行目)を求めて推定していく。対数関数$\log x$も上に凸な関数である。
参考書籍
- 岩田具治(2015)『トピックモデル』(機械学習プロフェッショナルシリーズ)講談社
- 佐藤一誠(2015)『トピックモデルによる統計的潜在意味解析』(自然言語シリーズ8)コロナ社
- 須山敦志(2017)『ベイズ推論による機械学習入門』(機械学習スタートアップシリーズ)講談社
おわりに
2019/08/23:加筆修正しました。
2020/06/09:加筆修正しました。
青本と白本ってほぼ同タイミングで出版されてたんですね。今知りました。
情報量とKL情報量の間の内容(各種エントロピー)についていくつか記事を書きました。
青トピ本の内容には関連しませんが寄り道にどうぞ。
【次節の内容】