はじめに
機械学習でも登場する情報理論におけるエントロピーを1つずつ確認していくシリーズです。
この記事では、条件付きエントロピーを扱います。
【前の内容】
【今回の内容】
条件付きエントロピーの定義
依存関係のある事象に関する平均情報量(avarage information)である条件付きエントロピー(conditional entropy)の定義を数式とグラフで確認します。エントロピーについては「平均情報量(エントロピー)の定義 - からっぽのしょこ」、結合エントロピーについては「結合エントロピーの定義 - からっぽのしょこ」を参照してください。
定義
まずは、条件付き確率(conditional probability)と条件付きエントロピーの定義を数式で確認します。
条件付き確率の定義式
事象 が事象
に依存するとき、
の「条件付き確率」は、「各事象の結合確率(同時確率)」と「条件の確率」の商で定義されます。
この式の両辺に を掛けると、「条件の確率」と「条件付き確率」の積が「結合確率」になるのが分かります。
依存関係がない場合は、「各事象の確率」の積が「結合確率」になります。
依存関係がない場合については「結合エントロピーの定義」で扱います。
条件付きエントロピーの定義式
事象 の自己情報量
は、生起確率
の負の対数で定義されるのでした。定数の底は
(またはネイピア数
)とします。
2つの事象系 の確率分布を
とします。
が
に依存するとき、
の条件付きエントロピー
は、結合確率による「条件付き確率の自己情報量」の期待値で定義されます。
「結合確率」と「条件付き確率の自己情報量(負の対数)」の積和で計算できます。条件付き確率ではなく、結合確率を用いて期待値をとります。
を条件として結合確率を分割
して、式を整理します。
は
の影響を受けないので
の外に出せます。
「条件付き確率」と「条件付き確率の自己情報量」の積和を「条件の確率」で期待値をとっても計算できます。
生起確率 と自己情報量
が非負の値
なので、条件付きエントロピーも非負の値
をとります。
他のエントロピーとの関係
さらに式(1)を整理して、エントロピー(平均情報量)と結合エントロピーとの関係を導出します。
条件付き確率を分割 します。
対数の性質より です。
さらに、総和についての括弧を展開します。
後の因子の結合確率を分割します。
は
の影響を受けないので
の外に出せます。
の
に関する総和は、全事象の確率の和なので、
です。
前の因子は結合エントロピー、後の因子は符号を反転させる(-1を掛けると)エントロピーの定義式なので、次の関係が得られます。
「条件付きエントロピー」は、「結合エントロピー」と条件の「エントロピー」の差です。この関係は、結合エントロピーの定義式からも導出しました。
条件を入れ替えた場合も同様に求められます。
各種エントロピーは非負の値なので、式(2)(3)から、条件付きエントロピーは結合エントロピー以下の値なのが分かります。
また、条件付きエントロピーは、事象のエントロピー以下の値になります。
詳しくは「相互情報量の定義」で求めます。
以上で、各エントロピーとの関係が得られました。
可視化
次は、2変数(2次元)の条件付き確率と自己情報量のヒートマップから条件付きエントロピーをグラフで確認します。また、2変数間に依存関係を持つ場合の結合確率と自己情報量も可視化します。結合確率に関する可視化や、依存関係を持たない場合の可視化については「結合エントロピーの定義 - からっぽのしょこ」を参照してください。
利用するパッケージを読み込みます。
# 利用パッケージ library(tidyverse)
この記事では、基本的にパッケージ名::関数名()の記法を使うので、パッケージを読み込む必要はありません。ただし、作図コードがごちゃごちゃしないようにパッケージ名を省略しているため、ggplot2を読み込む必要があります。
また、ネイティブパイプ演算子|>を使っています。magrittrパッケージのパイプ演算子%>%に置き換えても処理できますが、その場合はmagrittrも読み込む必要があります。
インデックスの確認
色々ややこしいので、インデックスとプロット位置の関係を確認しておきます。可視化自体には不要な処理です。
・作図コード(クリックで展開)
事象系 それぞれの事象数を指定して、インデックスを作成します。
# 事象のインデックス(事象数)を指定 x_idx <- 1:4 y_idx <- 1:6 # xのインデックスを作成 index_x_df <- tibble::tibble( i = x_idx, # xのインデックス p_x = 1 / length(x_idx), # xの確率:(等確率) I_x = - log2(p_x), # xの自己情報量 var_label = paste0("x[", i, "]") # 変数の式 ) # yのインデックスを作成 index_y_df <- tibble::tibble( j = y_idx, # yのインデックス p_y = 1 / length(y_idx), # yの確率:(等確率) I_y = - log2(p_y), # yの自己情報量 var_label = paste0("y[", j, "]") # 変数の式 ) index_x_df; index_y_df
## # A tibble: 4 × 4 ## i p_x I_x var_label ## <int> <dbl> <dbl> <chr> ## 1 1 0.25 2 x[1] ## 2 2 0.25 2 x[2] ## 3 3 0.25 2 x[3] ## 4 4 0.25 2 x[4] ## # A tibble: 6 × 4 ## j p_y I_y var_label ## <int> <dbl> <dbl> <chr> ## 1 1 0.167 2.58 y[1] ## 2 2 0.167 2.58 y[2] ## 3 3 0.167 2.58 y[3] ## 4 4 0.167 2.58 y[4] ## 5 5 0.167 2.58 y[5] ## 6 6 0.167 2.58 y[6]
1:事象数の形式で事象の数を指定して、1から事象数までの整数を作成しインデックス*_idxとします。
インデックスをデータフレームに格納して、変数ラベルを作成します。数式を描画する場合はexpression()の記法を使います。下付き文字は変数[添字]の形式です。
確認のため、事象ごとに一様な確率を作成して、自己情報量を計算していますが、ここでは使いません。
インデックス について横方向に並べたグラフを作成します。
# xのインデックスを作図 index_x_graph <- ggplot() + geom_tile(data = index_x_df, mapping = aes(x = i, y = 0), fill = "white", color = "black") + # インデックスのマップ geom_text(data = index_x_df, mapping = aes(x = i, y = 0, label = var_label), parse = TRUE) + # 変数の式 scale_x_continuous(breaks = x_idx, limits = c(0.5, max(x_idx)+0.5)) + # xのインデックス scale_y_continuous(breaks = 0, limits = c(-0.6, 0.6), labels = NULL) + # yのインデックス coord_fixed(ratio = 1) + # アスペクト比 theme(panel.grid.minor = element_blank()) + # 図の体裁 labs(title = "index", subtitle = expression(x == (list(x[1], cdots, x[n]))), x = "i", y = "") index_x_graph
geom_tile()でヒートマップ用の事象セル、geom_text()で事象ラベルを描画します。数式を描画する場合はparse引数にTRUEを指定します。
scale_*_continuous()のlimits引数に描画範囲の最小値と最大値を指定することでプロット領域のサイズを調整できます。
同様に、インデックス について縦方向に並べたグラフを作成します。
# yのインデックスを作図 index_y_graph <- ggplot() + geom_tile(data = index_y_df, mapping = aes(x = 0, y = j), fill = "white", color = "black") + # インデックスのマップ geom_text(data = index_y_df, mapping = aes(x = 0, y = j, label = var_label), parse = TRUE) + # 変数の式 scale_x_continuous(breaks = 0, limits = c(-0.6, 0.6), labels = NULL) + # xのインデックス scale_y_continuous(breaks = y_idx, limits = c(0.5, max(y_idx)+0.5)) + # yのインデックス coord_fixed(ratio = 1) + # アスペクト比 theme(panel.grid.minor = element_blank()) + # 図の体裁 labs(title = "index", subtitle = expression(y == (list(y[1], cdots, y[m]))), x = "", y = "j") index_y_graph
2種類のインデックスの組み合わせを作成します。
# x・yのインデックスを作成 index_xy_df <- tidyr::expand_grid( i = x_idx, # xのインデックス j = y_idx # yのインデックス ) |> # 全ての組み合わせを作成 dplyr::mutate( p_x = 1 / length(unique(i)), # xの確率:(等確率) p_y = 1 / length(unique(j)), # yの確率:(等確率) p_xy = p_x * p_y, # xyの結合確率 I_xy = - log2(p_xy), # xyの自己情報量 var_label = paste0("list(x[", i, "], y[", j, "])") # 変数の式 ) index_xy_df
## # A tibble: 24 × 7 ## i j p_x p_y p_xy I_xy var_label ## <int> <int> <dbl> <dbl> <dbl> <dbl> <chr> ## 1 1 1 0.25 0.167 0.0417 4.58 list(x[1], y[1]) ## 2 1 2 0.25 0.167 0.0417 4.58 list(x[1], y[2]) ## 3 1 3 0.25 0.167 0.0417 4.58 list(x[1], y[3]) ## 4 1 4 0.25 0.167 0.0417 4.58 list(x[1], y[4]) ## 5 1 5 0.25 0.167 0.0417 4.58 list(x[1], y[5]) ## 6 1 6 0.25 0.167 0.0417 4.58 list(x[1], y[6]) ## 7 2 1 0.25 0.167 0.0417 4.58 list(x[2], y[1]) ## 8 2 2 0.25 0.167 0.0417 4.58 list(x[2], y[2]) ## 9 2 3 0.25 0.167 0.0417 4.58 list(x[2], y[3]) ## 10 2 4 0.25 0.167 0.0417 4.58 list(x[2], y[4]) ## # … with 14 more rows
インデックス を格納して、
expand_grid()で全ての組み合わせを作成します。
組み合わせごとに変数ラベルを作成します。複数の変数はlist(変数1, 変数2)の形式です。
2種類のインデックス を横・縦方向に並べたグラフを作成します。
# x・yのインデックスの組み合わせを作図 index_xy_graph <- ggplot() + geom_tile(data = index_xy_df, mapping = aes(x = i, y = j), fill = "white", color = "black") + # インデックスのマップ geom_text(data = index_xy_df, mapping = aes(x = i, y = j, label = var_label), parse = TRUE) + # 変数の式 scale_x_continuous(breaks = x_idx, limits = c(0.5, max(x_idx)+0.5)) + # xのインデックス scale_y_continuous(breaks = y_idx, limits = c(0.5, max(y_idx)+0.5)) + # yのインデックス coord_fixed(ratio = 1) + # アスペクト比 theme(panel.grid.minor = element_blank()) + # 図の体裁 labs(title = "joint index", subtitle = expression(list(x == (list(x[1], cdots, x[n])), y == (list(y[1], cdots, y[m])))), x = "i", y = "j") index_xy_graph

先ほどと同様に作図します。
3つのグラフを並べて描画します。
# グラフサイズ用の値を設定 x_size <- length(x_idx) - 1 y_size <- length(y_idx) - 1 # 並べて描画 index_joint_graph <- patchwork::wrap_plots( patchwork::plot_spacer(), index_x_graph, index_y_graph, index_xy_graph, nrow = 2, ncol = 2, widths = c(1, x_size), heights = c(1, y_size) ) index_joint_graph
patchworkパッケージのwrap_plots()を使って、複数のグラフを並べて描画します。グラフを配置しない場所にはplot_spacer()を指定します。
(この例では、アスペクト比を1にしているので、縦・横のサイズは事象数に依存しますが、(たぶんタイトルなどの領域の関係で)事象数のままだと微妙にズレたので、*_sizeの作成の際に値を調整しています。画像サイズの影響も受けます。)
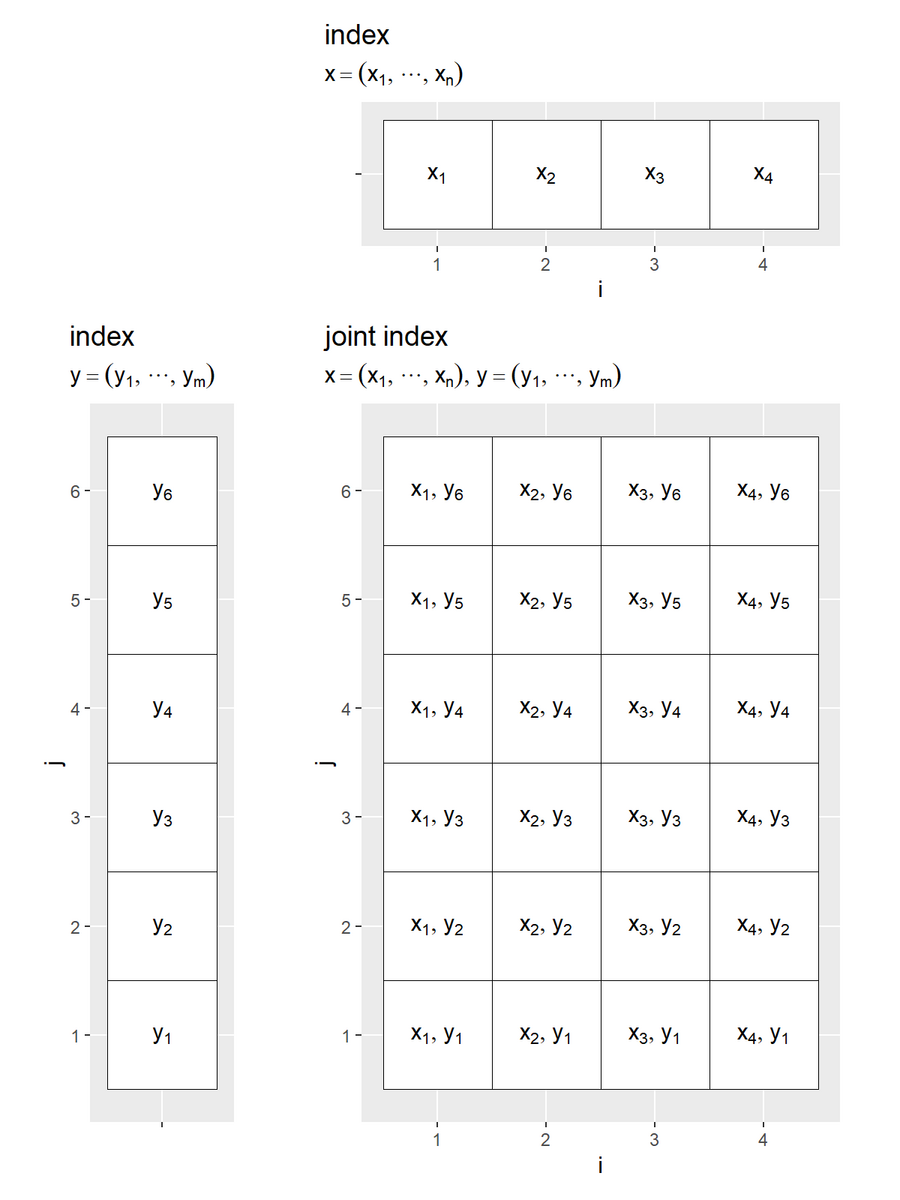
のインデックス
について横方向、
のインデックス
について縦方向に並べて配置すると、格子点が全ての組み合わせになるのが分かります。
セルの縦または横サイズを確率の値に、セルの色を確率またはエントロピーの値に対応させて可視化します。
条件付き確率のヒートマップ
では、条件付き確率をヒートマップで可視化します。
この例では、事象の値をインデックス 、
の関係を倍数
とします。
は整数です。定数倍でない事象の確率を
とします。
・作図コード(クリックで展開)
事象数を指定して、2つの事象系のインデックスと確率を作成します。
# 事象のインデックス(事象数)を指定 x_idx <- 1:5 y_idx <- 1:10 # 事象の確率を一様に作成 p_x_vec <- rep(1 / length(x_idx), times = length(x_idx)) p_y_vec <- rep(1 / length(y_idx), times = length(y_idx)) # 事象の確率をランダムに作成 p_x_vec <- MCMCpack::rdirichlet(n = 1, alpha = rep(1, times = length(x_idx))) |> as.vector() p_y_vec <- MCMCpack::rdirichlet(n = 1, alpha = rep(1, times = length(y_idx))) |> as.vector() p_x_vec; p_y_vec
## [1] 0.1032874 0.2096567 0.4195162 0.1477788 0.1197610 ## [1] 0.01399987 0.05867132 0.04362165 0.05413158 0.36693466 0.07624233 ## [7] 0.10037045 0.04537982 0.15732262 0.08332569
1:事象数の形で事象の数を指定して、インデックスを作成します。
各事象の確率を等しく設定する場合は、(事象の数をnとして)n分の1の値をn個作成します。
各事象の確率をランダムに設定する場合は、ディリクレ分布に従う乱数(総和が1になる非負の値)を使います。ディリクレ乱数は、MCMCpackパッケージのrdirichlet()で生成できます。サンプルサイズの引数nに1、パラメータの引数alphaにn個の値を指定します。
確率に応じてプロットするための座標を作成します。
# 座標を作成 coord_x_vec <- c(0, cumsum(p_x_vec)[-length(p_x_vec)]) + 0.5*p_x_vec coord_y_vec <- c(0, cumsum(p_y_vec)[-length(p_y_vec)]) + 0.5*p_y_vec coord_x_vec; coord_y_vec
## [1] 0.05164369 0.20811573 0.52270217 0.80634965 0.94011951 ## [1] 0.006999937 0.043335536 0.094482023 0.143358637 0.353891755 0.575480248 ## [7] 0.663786638 0.736661775 0.838012996 0.958337153
各セルの縦または横サイズを確率に合わせます。そのため、各セルの中心の座標を「累積確率」+「その事象の確率の半分」の値とします。
各事象の自己情報量を計算します。
# xの自己情報量を計算 entropy_x_df <- tibble::tibble( i = x_idx, # xのインデックス p_x = p_x_vec, # xの確率 I_x = - log2(p_x), # xの自己情報量 coord_x = coord_x_vec, # x軸の値 p_label = paste0("p(x[", i, "])") # 確率の式 ) # yの自己情報量を計算 entropy_y_df <- tibble::tibble( j = y_idx, # yのインデックス p_y = p_y_vec, # yの確率 I_y = - log2(p_y), # yの自己情報量 coord_y = coord_y_vec, # y軸の値 p_label = paste0("p(y[", j, "])") # 確率の式 ) entropy_x_df; entropy_y_df
## # A tibble: 5 × 5 ## i p_x I_x coord_x p_label ## <int> <dbl> <dbl> <dbl> <chr> ## 1 1 0.103 3.28 0.0516 p(x[1]) ## 2 2 0.210 2.25 0.208 p(x[2]) ## 3 3 0.420 1.25 0.523 p(x[3]) ## 4 4 0.148 2.76 0.806 p(x[4]) ## 5 5 0.120 3.06 0.940 p(x[5]) ## # A tibble: 10 × 5 ## j p_y I_y coord_y p_label ## <int> <dbl> <dbl> <dbl> <chr> ## 1 1 0.0140 6.16 0.00700 p(y[1]) ## 2 2 0.0587 4.09 0.0433 p(y[2]) ## 3 3 0.0436 4.52 0.0945 p(y[3]) ## 4 4 0.0541 4.21 0.143 p(y[4]) ## 5 5 0.367 1.45 0.354 p(y[5]) ## 6 6 0.0762 3.71 0.575 p(y[6]) ## 7 7 0.100 3.32 0.664 p(y[7]) ## 8 8 0.0454 4.46 0.737 p(y[8]) ## 9 9 0.157 2.67 0.838 p(y[9]) ## 10 10 0.0833 3.59 0.958 p(y[10])
インデックス と確率
をデータフレームに格納して、自己情報量
を計算します。
についても同様です。
座標列とラベル列も作成します。
条件付けした事象の自己情報量を計算します。
# 条件付きyの自己情報量を計算 entropy_y.x_df <- tidyr::expand_grid( i = x_idx, # xのインデックス j = y_idx # yのインデックス ) |> # 全ての組み合わせを作成 dplyr::mutate( x = i, # xの事象 y = j, # yの事象 p_x = p_x_vec[i], # xの確率 p_y = p_y_vec[j], # yの確率 p_y.x = dplyr::if_else(condition = y %% x == 0, true = p_y, false = 0) # yの条件付き確率用の値を作成 ) |> dplyr::group_by(x) |> # 確率の正規化と座標計算用 dplyr::mutate( p_y.x = p_y.x / sum(p_y.x), # yの条件付き確率を正規化 coord_y = c(0, cumsum(p_y.x)[-length(p_y.x)]) + 0.5*p_y.x # y軸の値 ) |> dplyr::ungroup() |> dplyr::mutate( p_xy = p_x * p_y.x, # xyの結合確率 I_y.x = - log2(p_y.x), # 条件付きyの自己情報量 p_label = dplyr::if_else(condition = p_y.x > 0, true = paste0("p(y[", j, "]~'|'~x[", i, "])"), false = "") # 確率の式 ) entropy_y.x_df |> dplyr::select(!c(x, y)) # 資料作成用に間引き
## # A tibble: 50 × 9 ## i j p_x p_y p_y.x coord_y p_xy I_y.x p_label ## <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <chr> ## 1 1 1 0.103 0.0140 0.0140 0.00700 0.00145 6.16 p(y[1]~'|'~x[1]) ## 2 1 2 0.103 0.0587 0.0587 0.0433 0.00606 4.09 p(y[2]~'|'~x[1]) ## 3 1 3 0.103 0.0436 0.0436 0.0945 0.00451 4.52 p(y[3]~'|'~x[1]) ## 4 1 4 0.103 0.0541 0.0541 0.143 0.00559 4.21 p(y[4]~'|'~x[1]) ## 5 1 5 0.103 0.367 0.367 0.354 0.0379 1.45 p(y[5]~'|'~x[1]) ## 6 1 6 0.103 0.0762 0.0762 0.575 0.00787 3.71 p(y[6]~'|'~x[1]) ## 7 1 7 0.103 0.100 0.100 0.664 0.0104 3.32 p(y[7]~'|'~x[1]) ## 8 1 8 0.103 0.0454 0.0454 0.737 0.00469 4.46 p(y[8]~'|'~x[1]) ## 9 1 9 0.103 0.157 0.157 0.838 0.0162 2.67 p(y[9]~'|'~x[1]) ## 10 1 10 0.103 0.0833 0.0833 0.958 0.00861 3.59 p(y[10]~'|'~x[1]) ## # … with 40 more rows
インデックス を
i, j列として格納して、expand_grid()で全ての組み合わせを作成します。
の値を用いて、
として事象列
x, yを作成し、対応する確率を取り出してp_x, p_y列として格納します。
の依存関係を持つ条件付き確率
を
p_y.x列として作成します。yがxの倍数(y, xの商余が0)の行をy_pの値、倍数でない行を0とする列を作成しておき、条件の事象 ごとに(
xでグループ化して)、総和で割ることで正規化(確率値に変換)します。
条件付き確率に応じた座標列を作成します。
結合確率 を
p_xy列、条件付けられた事象(条件付き確率による)の自己情報量 を
I_y.x列として計算します。
条件付き確率が0のラベルを描画しない場合は、ラベル用の文字列を空白""にしておきます。
確率分布 のヒートマップを作成します。
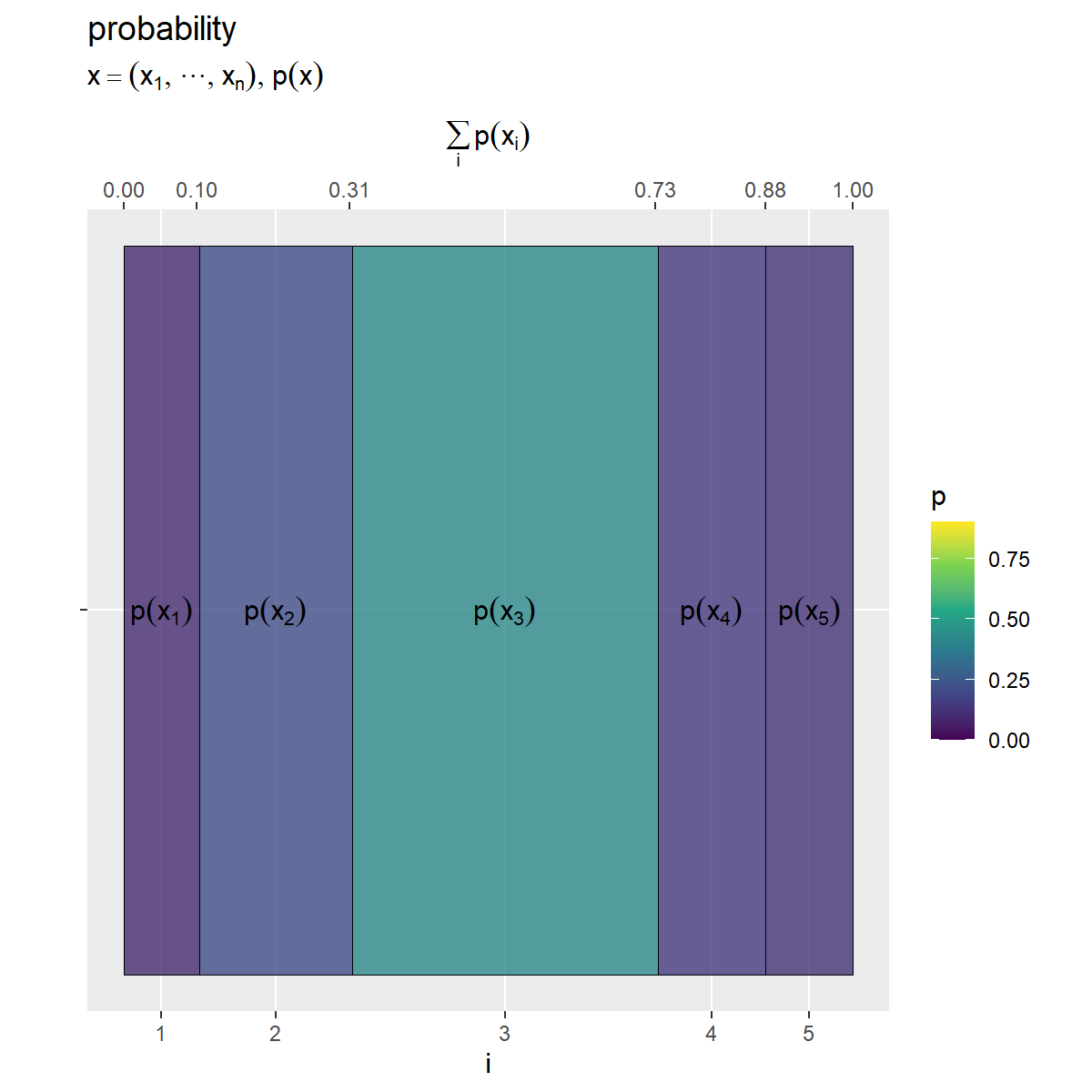
# 確率(グラデーション)の最大値を設定 p_max <- c(entropy_x_df[["p_x"]], entropy_y_df[["p_y"]], entropy_y.x_df[["p_y.x"]]) |> max() |> (\(.){ceiling(. * 10) / 10})() # 小数点第二位で切り上げ # xの確率を作図 prob_x_graph <- ggplot() + geom_tile(data = entropy_x_df, mapping = aes(x = coord_x, y = 0, width = p_x, height = 1, fill = p_x), color = "black", alpha = 0.8) + # 確率 geom_text(data = entropy_x_df, mapping = aes(x = coord_x, y = 0, label = p_label), parse = TRUE) + # 確率の式 scale_x_continuous(breaks = coord_x_vec, labels = x_idx, sec.axis = sec_axis(trans = ~., breaks = round(cumsum(c(0, p_x_vec)), digits = 2), name = expression(sum(p(x[i]), i)))) + # xのインデックスと累積確率 scale_y_continuous(breaks = 0, labels = NULL) + # yのインデックス scale_fill_viridis_c(limits = c(0, p_max)) + # グラデーション coord_fixed(ratio = 1) + # アスペクト比 theme(panel.grid.minor = element_blank()) + # 図の体裁 labs(title = "probability", subtitle = expression(list(x == (list(x[1], cdots, x[n])), p(x))), fill = "p", x = "i", y = "") prob_x_graph
他のヒートマップとグラデーションの基準を統一するために、確率の最大値をp_maxとしておきます。
geom_tile()でヒートマップを描画します。x引数に座標列coord_x、width引数に確率列p_xを指定して、各セルの横サイズを確率に対応付けます。y引数の値は何でもよく、height引数に1を指定して、ヒートマップ全体の面積が1×1になるようにします。また、fill引数に確率列を指定して、各セルの色を確率に対応付けます。
scale_*_continuous()で軸目盛を設定します。breaks引数に確率に応じた座標coord_x_vec、labels引数にインデックスx_idxを指定して、主軸(第1軸)目盛が各セルの中心に対応するようにインデックスを表示します。sec.axis引数にsec_axis()を使って、第2軸が各セルの端に対応するように累積確率を表示します。
同様に、確率分布 のヒートマップを作成します。
# yの確率を作図 prob_y_graph <- ggplot() + geom_tile(data = entropy_y_df, mapping = aes(x = 0, y = coord_y, width = 1, height = p_y, fill = p_y), color = "black", alpha = 0.8) + # 確率 geom_text(data = entropy_y_df, mapping = aes(x = 0, y = coord_y, label = p_label), parse = TRUE) + # 確率の式 scale_x_continuous(breaks = 0, labels = NULL) + # xのインデックス scale_y_continuous(breaks = coord_y_vec, labels = y_idx, sec.axis = sec_axis(trans = ~., breaks = round(cumsum(c(0, p_y_vec)), digits = 2), name = expression(sum(p(y[j]), j)))) + # yのインデックスと累積確率 scale_fill_viridis_c(limits = c(0, p_max)) + # グラデーション coord_fixed(ratio = 1) + # アスペクト比 theme(panel.grid.minor = element_blank()) + # 図の体裁 labs(title = "probability", subtitle = expression(list(y == (list(y[1], cdots, y[m])), p(y))), fill = "p", x = "", y = "j") prob_y_graph
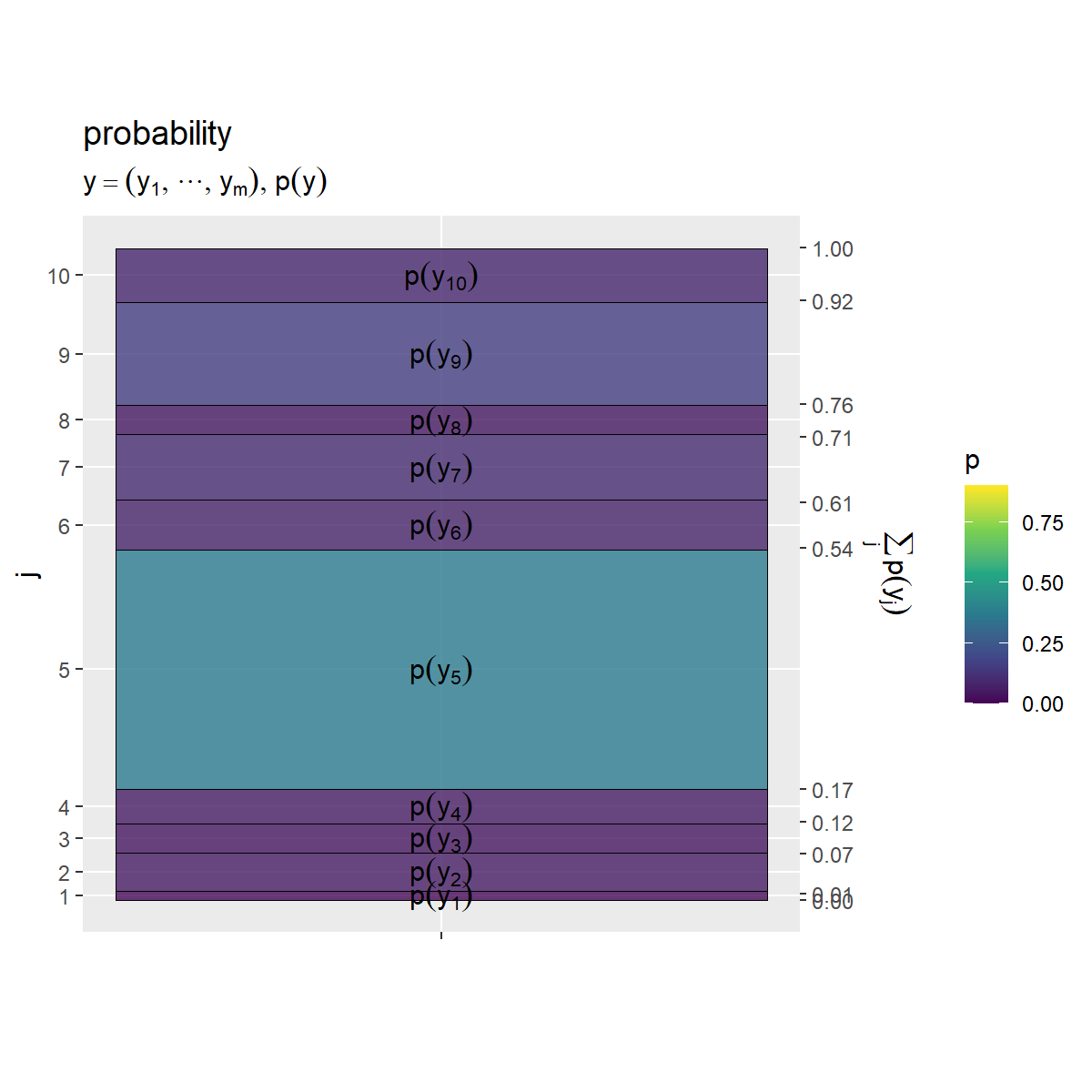
のヒートマップを作成します。
# ラベル用の文字列を作成 fnc_label <- paste0( "list(", "x[i] == i, y[j] == j", ", ", "y[j] == n * x[i]", ", ", "p(y[j]~'|'~x[i]) == frac(p(x[i], y[j]), p(x[i]))", ")" ) # yの条件付き確率を作図 prob_y.x_graph <- ggplot() + geom_tile(data = entropy_y.x_df, mapping = aes(x = 0, y = coord_y, width = 1, height = p_y.x, fill = p_y.x), color = "black", alpha = 0.8) + # 確率 geom_text(data = entropy_y.x_df, mapping = aes(x = 0, y = coord_y, label = p_label), parse = TRUE, angle = 0) + # 確率の式 scale_x_continuous(breaks = 0, labels = NULL) + # xのインデックス scale_y_continuous(breaks = 0.5, labels = NULL, sec.axis = sec_axis(trans = ~., breaks = seq(from = 0, to = 1, by = 0.25), name = expression(sum(p(y[j]~'|'~x[i]), j)))) + # yのインデックスと累積確率 scale_fill_viridis_c(limits = c(0, p_max)) + # グラデーション facet_grid(. ~ i, labeller = label_bquote(cols = x[.(i)])) + # xの事象(条件)ごとに分割 coord_fixed(ratio = 1) + # アスペクト比 theme(panel.grid.minor = element_blank()) + # 図の体裁 labs(title = "conditional probability", subtitle = parse(text = fnc_label), fill = "p", x = "i", y = "j") prob_y.x_graph
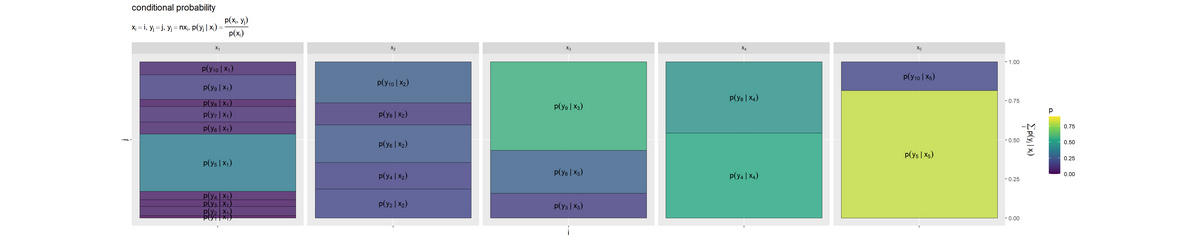
facet_grid()で条件(事象 )ごとにグラフを分割して描画します。
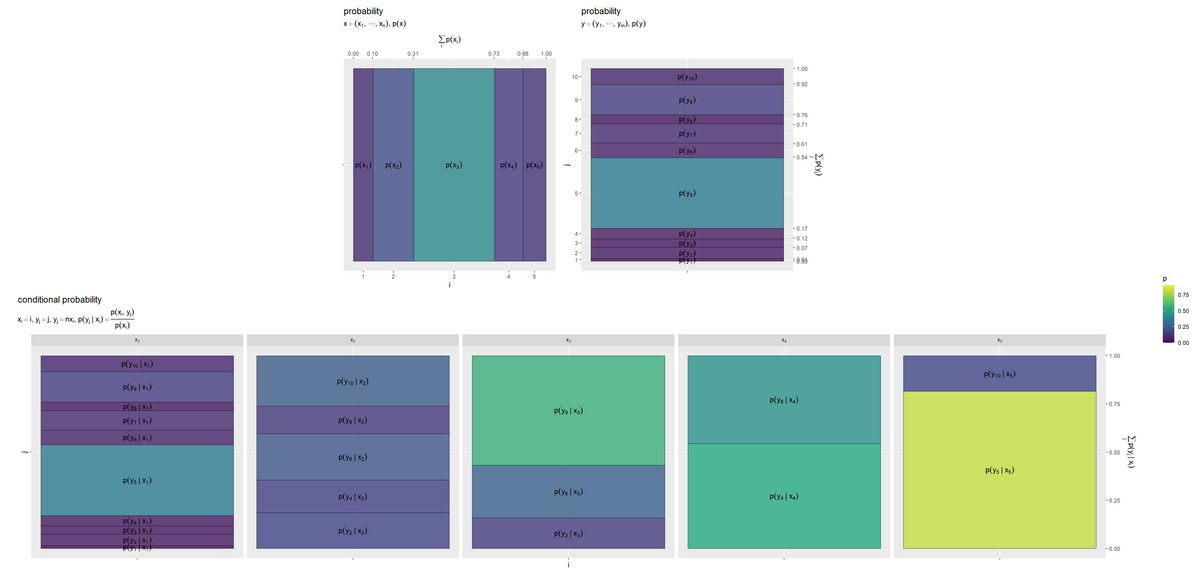
3つのグラフを並べて描画します。
# 並べて描画 prob_condition_graph <- patchwork::wrap_plots( (prob_x_graph | prob_y_graph) / prob_y.x_graph, heights = 1, guides = "collect" ) prob_condition_graph
wrap_plots()でグラフを並べて描画します。|演算子で横に、/演算子で縦に並べて描画します。()で囲ったグラフを1つのまとまりとして扱います。
アスペクト比を1にしてセルの縦または横サイズを確率に合わせることで、全体の面積に占めるセル面積の割合が各事象の確率に対応します。セルが大きいほど確率が大きく、セルが小さいほど確率も小さいことを表します。
事象(条件) ごとに条件付き分布
になるので、
個の確率分布(グラフ)それぞれの総和が1(全体の面積が1×1)
です。ただしこの図では、確率が0の事象(
の倍数でない
)のセルラベルは表示していません。
条件付き分布(グラフ)は、 の値(縦方向のサイズ)により
の値(セルサイズ)が決まるのが分かります。
変数間に依存関係がある場合の結合確率をヒートマップで可視化します。
・作図コード(クリックで展開)
依存関係のある2事象の自己情報量を計算します。
# x・yの自己情報量を計算 entropy_xy_df <- entropy_y.x_df |> dplyr::mutate( coord_x = coord_x_vec[i], # x軸の値 I_xy = - log2(p_xy), # xyの自己情報量 p_label = dplyr::if_else(condition = p_xy > 0, true = paste0("p(x[", i, "], y[", j, "])"), false = "") # 確率の式 ) |> dplyr::select(i, j, p_x, p_y.x, p_xy, I_xy, coord_x, coord_y, p_label) entropy_xy_df
## # A tibble: 50 × 9 ## i j p_x p_y.x p_xy I_xy coord_x coord_y p_label ## <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <chr> ## 1 1 1 0.103 0.0140 0.00145 9.43 0.0516 0.00700 p(x[1], y[1]) ## 2 1 2 0.103 0.0587 0.00606 7.37 0.0516 0.0433 p(x[1], y[2]) ## 3 1 3 0.103 0.0436 0.00451 7.79 0.0516 0.0945 p(x[1], y[3]) ## 4 1 4 0.103 0.0541 0.00559 7.48 0.0516 0.143 p(x[1], y[4]) ## 5 1 5 0.103 0.367 0.0379 4.72 0.0516 0.354 p(x[1], y[5]) ## 6 1 6 0.103 0.0762 0.00787 6.99 0.0516 0.575 p(x[1], y[6]) ## 7 1 7 0.103 0.100 0.0104 6.59 0.0516 0.664 p(x[1], y[7]) ## 8 1 8 0.103 0.0454 0.00469 7.74 0.0516 0.737 p(x[1], y[8]) ## 9 1 9 0.103 0.157 0.0162 5.94 0.0516 0.838 p(x[1], y[9]) ## 10 1 10 0.103 0.0833 0.00861 6.86 0.0516 0.958 p(x[1], y[10]) ## # … with 40 more rows
条件付き確率に関するデータフレームentropy_y.x_dfから、作図に利用する列を取り出して、座標を格納してラベルを作成します。
2事象(結合確率による)の自己情報量 を計算します。
のヒートマップを作成します。
# ラベル用の文字列を作成 fnc_label <- paste0( "list(", "x[i] == i, y[j] == j", ", ", "y[j] == n * x[i]", ", ", "p(x[i], y[j]) == p(x[i]) * p(y[j]~'|'~x[i])", ")" ) # x・yの結合確率を作図 prob_xy_graph <- ggplot() + geom_tile(data = entropy_xy_df, mapping = aes(x = coord_x, y = coord_y, width = p_x, height = p_y.x, fill = p_xy), color = "black", alpha = 0.8) + # 確率 geom_text(data = entropy_xy_df, mapping = aes(x = coord_x, y = coord_y, label = p_label), parse = TRUE, angle = 0) + # 確率の式 scale_x_continuous(breaks = coord_x_vec, labels = x_idx, sec.axis = sec_axis(trans = ~., breaks = round(cumsum(c(0, p_x_vec)), digits = 2), name = expression(sum(p(x[i]), i)))) + # xのインデックスと累積確率 scale_y_continuous(breaks = 0.5, labels = NULL, sec.axis = sec_axis(trans = ~., breaks = seq(from = 0, to = 1, by = 0.25), name = expression(sum(p(y[j]~'|'~x[i]), j)))) + # yのインデックスと累積確率 scale_fill_viridis_c(limits = c(0, p_max)) + # グラデーション coord_fixed(ratio = 1, clip = "off") + # アスペクト比 theme(panel.grid.minor = element_blank()) + # 図の体裁 labs(title = "joint probability", subtitle = parse(text = fnc_label), fill = "p", x = "i", y = "j") prob_xy_graph
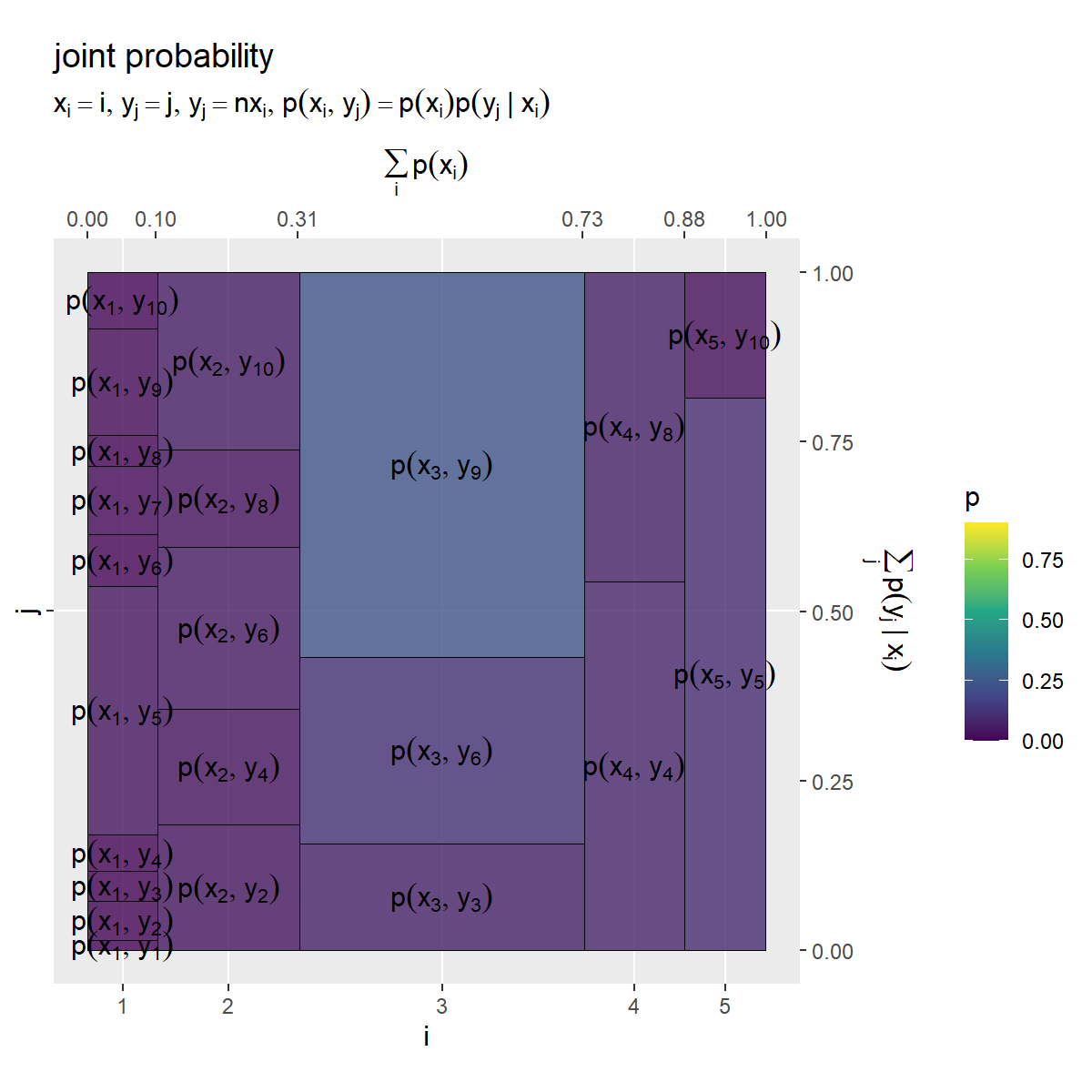
ここまでと同様に、x軸とy軸を確率に対応付けて作図します。
4つのグラフを並べて描画します。
# 並べて描画 prob_joint_graph <- patchwork::wrap_plots( prob_y_graph, prob_y.x_graph, prob_x_graph, prob_xy_graph, nrow = 2, ncol = 2, widths = c(1, 5, 1, 1), heights = 1, guides = "collect" ) prob_joint_graph
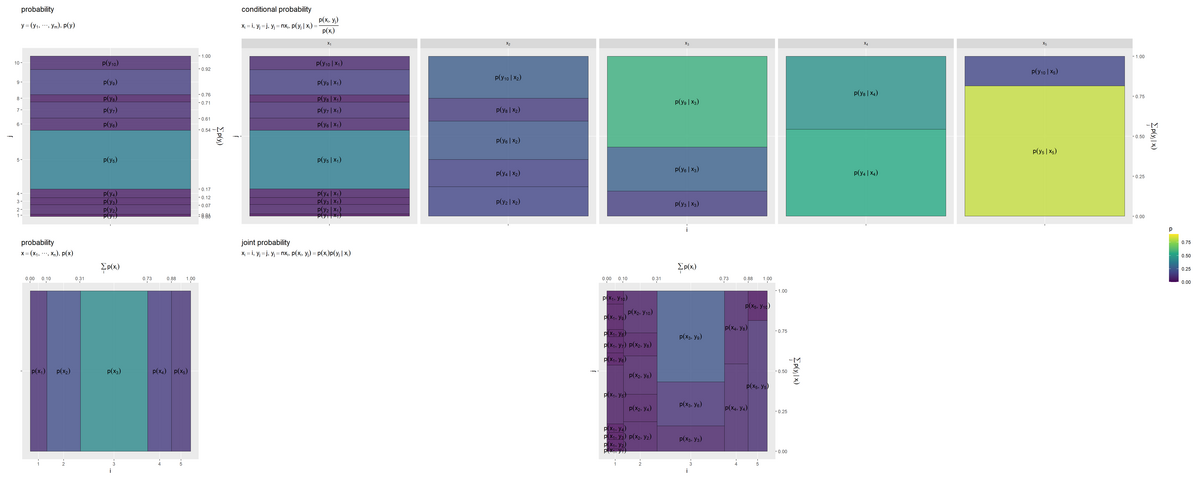
の値(横方向のサイズ)と
の値(縦方向のサイズ)により
の値(セルサイズ)が決まり、2事象に関する総和が1(全体の面積が1×1)
になるのが分かります。
個の条件付き分布(グラフ)が、条件の確率により加重平均をとるように、横方向に縮小されています。
自己情報量のヒートマップ
続いて、自己情報量をヒートマップで可視化して、結合エントロピーを確認します。
・作図コード(クリックで展開)
の各事象の自己情報量のヒートマップを作成します。
# 自己情報量(グラデーション)の最大値を設定 I_max <- c(entropy_x_df[["I_x"]], entropy_y_df[["I_y"]], entropy_y.x_df[["I_y.x"]], entropy_xy_df[["I_xy"]]) |> (\(.){.[. < Inf]})() |> # 確率が0の事象を除く max() |> ceiling() # 小数点以下を切り上げ # 平均情報量を計算 H_x <- sum(entropy_x_df[["p_x"]] * entropy_x_df[["I_x"]], na.rm = TRUE) # ラベル用の文字列を作成 fnc_label <- paste0( "list(", "I(x[i]) == - log[2]*p(x[i])", ", ", "H(x) == sum(p(x[i]) * I(x[i]), i==1, n)", ")" ) H_x_label <- paste0("H(x) == ", round(H_x, digits = 3)) # xの自己情報量を作図 entropy_x_graph <- ggplot() + geom_tile(data = entropy_x_df, mapping = aes(x = coord_x, y = 0, width = p_x, height = 1, fill = I_x), color = "black", alpha = 0.8) + # 自己情報量 geom_text(data = entropy_x_df, mapping = aes(x = coord_x, y = 0, label = p_label), parse = TRUE) + # 確率の式 geom_label(mapping = aes(x = -Inf, y = Inf), label = H_x_label, hjust = 0, vjust = 1, parse = TRUE, alpha = 0.5) + # エントロピーの値 scale_x_continuous(breaks = coord_x_vec, labels = x_idx, sec.axis = sec_axis(trans = ~., breaks = round(cumsum(c(0, p_x_vec)), digits = 2), name = expression(sum(p(x[i]), i)))) + # xのインデックスと累積確率 scale_y_continuous(breaks = 0, labels = NULL) + # yのインデックス scale_fill_viridis_c(limits = c(0, I_max)) + # グラデーション coord_fixed(ratio = 1) + # アスペクト比 theme(panel.grid.minor = element_blank()) + # 図の体裁 labs(title = "self-information", subtitle = parse(text = fnc_label), fill = "I", x = "i", y = "") entropy_x_graph
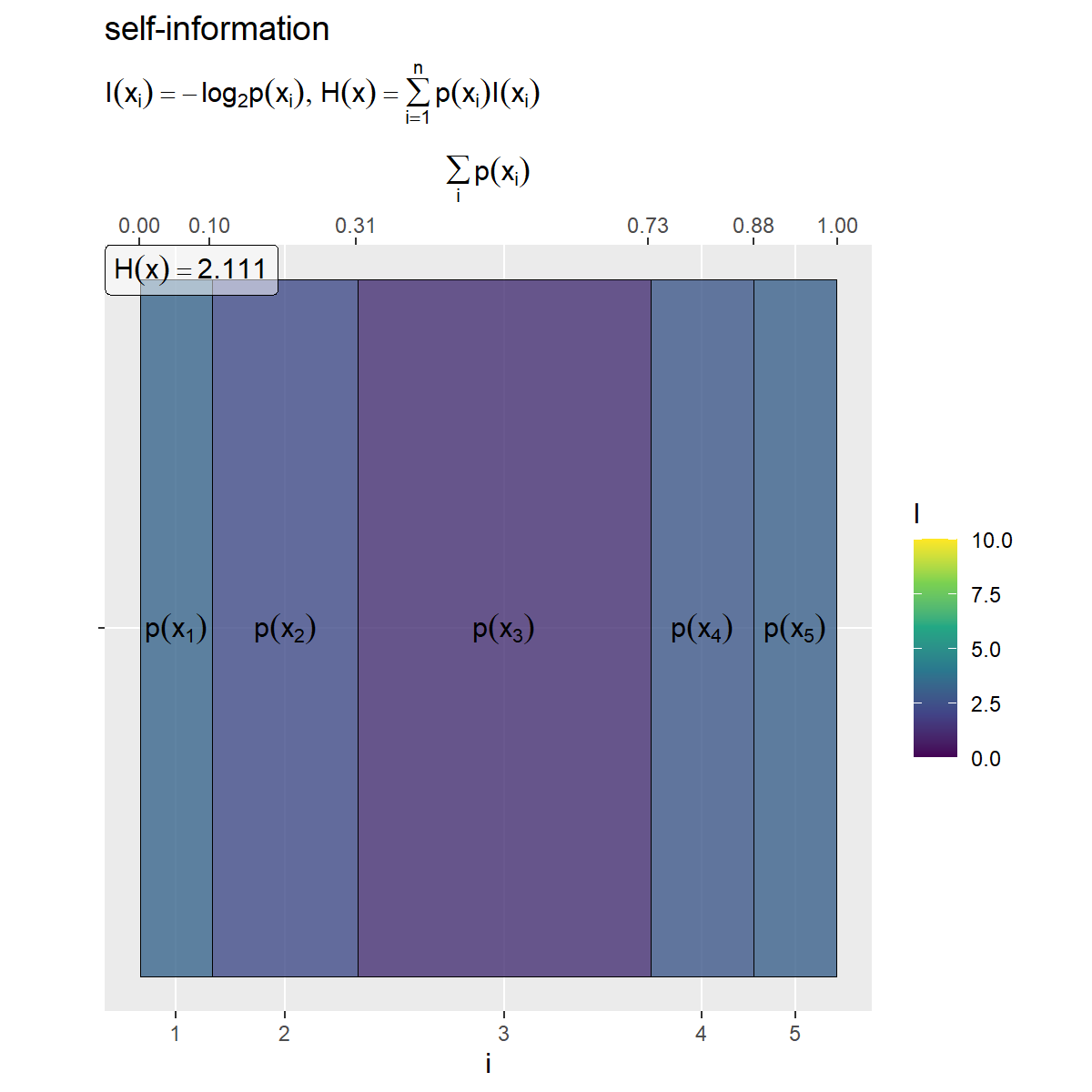
自己情報量の最大値をI_maxとしておき、「条件付き確率のヒートマップ」のときと同様に作図します。 は、
の最大値より大きな値にならないので、
p_maxの計算にp_xy列を含めませんでした。 は、
の最大値より大きな値になることがあるので、
I_maxの計算にI_xy列を含めます。
塗りつぶし色(z軸の値)を自己情報量列I_xとします。
エントロピー(平均情報量) を計算して、
geom_label()でラベルとして表示します。
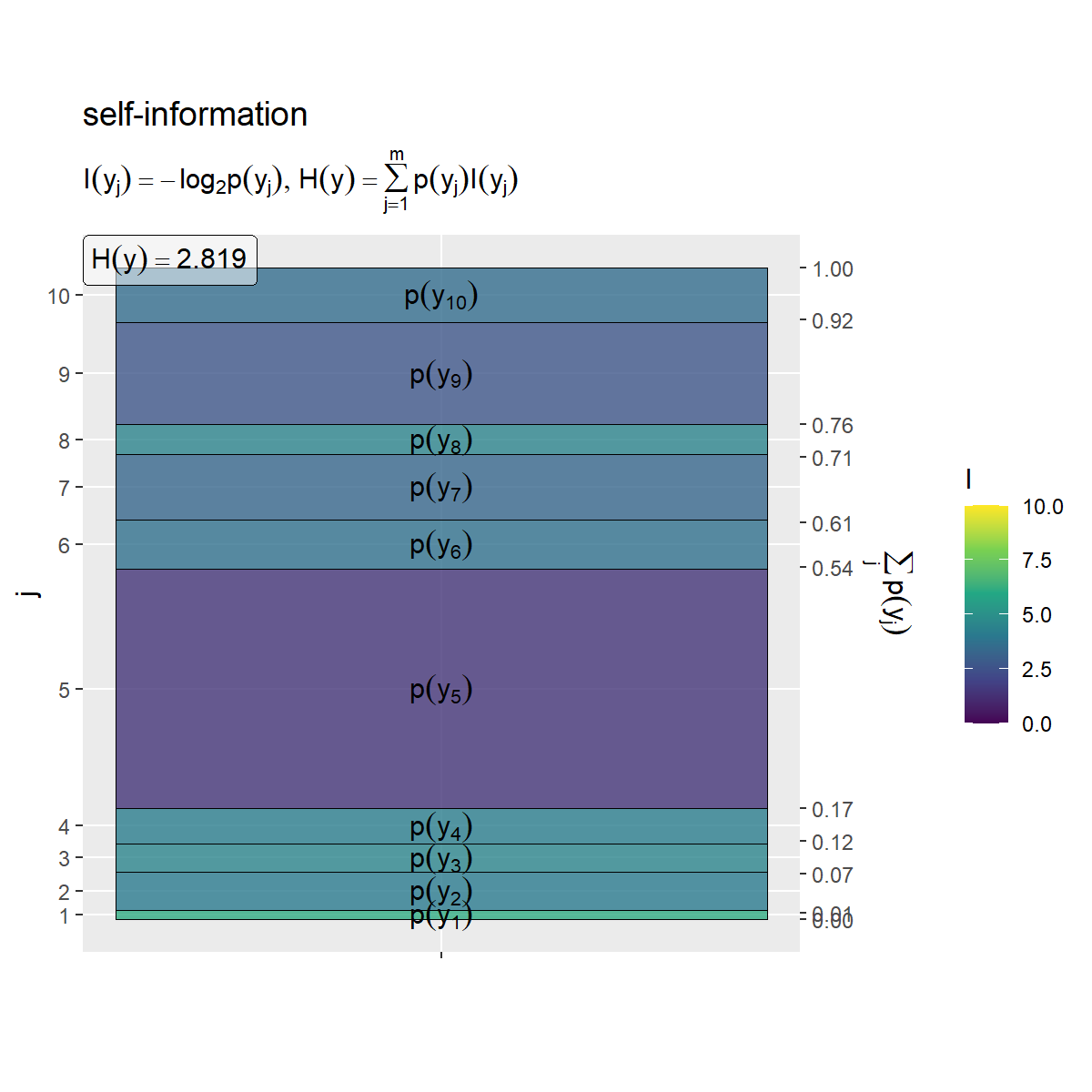
同様に、 の各事象の自己情報量のヒートマップを作成します。
# 平均情報量を計算 H_y <- sum(entropy_y_df[["p_y"]] * entropy_y_df[["I_y"]], na.rm = TRUE) # ラベル用の文字列を作成 fnc_label <- paste0( "list(", "I(y[j]) == - log[2]*p(y[j])", ", ", "H(y) == sum(p(y[j]) * I(y[j]), j==1, m)", ")" ) H_y_label <- paste0("H(y) == ", round(H_y, digits = 3)) # yの自己情報量を作図 entropy_y_graph <- ggplot() + geom_tile(data = entropy_y_df, mapping = aes(x = 0, y = coord_y, width = 1, height = p_y, fill = I_y), color = "black", alpha = 0.8) + # 自己情報量 geom_text(data = entropy_y_df, mapping = aes(x = 0, y = coord_y, label = p_label), parse = TRUE) + # 確率の式 geom_label(mapping = aes(x = -Inf, y = Inf), label = H_y_label, hjust = 0, vjust = 1, parse = TRUE, alpha = 0.5) + # エントロピーの値 scale_x_continuous(breaks = 0, labels = NULL) + # xのインデックス scale_y_continuous(breaks = coord_y_vec, labels = y_idx, sec.axis = sec_axis(trans = ~., breaks = round(cumsum(c(0, p_y_vec)), digits = 2), name = expression(sum(p(y[j]), j)))) + # yのインデックスと累積確率 scale_fill_viridis_c(limits = c(0, I_max)) + # グラデーション coord_fixed(ratio = 1) + # アスペクト比 theme(panel.grid.minor = element_blank()) + # 図の体裁 labs(title = "self-information", subtitle = parse(text = fnc_label), fill = "I", x = "", y = "j") entropy_y_graph
条件付けされた の各事象の自己情報量のヒートマップを作成します。
# 平均情報量を計算 H_y.x <- sum(entropy_y.x_df[["p_xy"]] * entropy_y.x_df[["I_y.x"]], na.rm = TRUE) # ラベル用の文字列を作成 fnc_label <- paste0( "list(", "x[i] == i, y[j] == j", ", ", "y[j] == n * x[i]", ", ", "I(y[j]~'|'~x[i]) == - log[2]*p(y[j]~'|'~x[i])", ", ", "H(x, y) == sum({}, i==1, n) * sum({}, j==1, m) * p(x[i], y[j]) * I(y[j]~'|'~x[i])", ")" ) H_y.x_label_df <- tibble::tibble( i = 1, # xのインデックス(ラベルを配置する条件番号) H_y.x_label = paste0("H(y~'|'~x) == ", round(H_y.x, digits = 3)) ) # 条件付きyの自己情報量を作図 entropy_y.x_graph <- ggplot() + geom_tile(data = entropy_y.x_df, mapping = aes(x = 0, y = coord_y, width = 1, height = p_y.x, fill = I_y.x), color = "black", alpha = 0.8) + # 自己情報量 geom_text(data = entropy_y.x_df, mapping = aes(x = 0, y = coord_y, label = p_label), parse = TRUE, angle = 0) + # 確率の式 geom_label(data = H_y.x_label_df, mapping = aes(x = -Inf, y = Inf, label = H_y.x_label), hjust = 0, vjust = 1, parse = TRUE, alpha = 0.5) + # エントロピーの値 scale_x_continuous(breaks = 0, labels = NULL) + # xのインデックス scale_y_continuous(breaks = 0.5, labels = NULL, sec.axis = sec_axis(trans = ~., breaks = seq(from = 0, to = 1, by = 0.25), name = expression(sum(p(y[j]~'|'~x[i]), j)))) + # yのインデックスと累積確率 scale_fill_viridis_c(limits = c(0, I_max)) + # グラデーション facet_grid(. ~ i, labeller = label_bquote(cols = x[.(i)])) + # xの事象(条件)ごとに分割 coord_fixed(ratio = 1) + # アスペクト比 theme(panel.grid.minor = element_blank()) + # 図の体裁 labs(title = "conditional information", subtitle = parse(text = fnc_label), fill = "I", x = "i", y = "j") entropy_y.x_graph
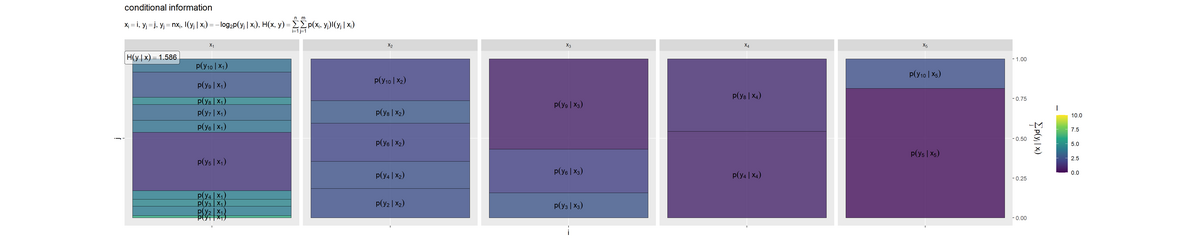
条件付きエントロピー を計算して、ラベルとして表示します。条件付き確率
p_y.xではなく、結合確率p_xyを用いて期待値をとる点に注意してください。
3つのグラフを並べて描画します。
# 並べて描画 entropy_condition_graph <- patchwork::wrap_plots( (entropy_x_graph | entropy_y_graph) / entropy_y.x_graph, heights = 1, guides = "collect" ) entropy_condition_graph
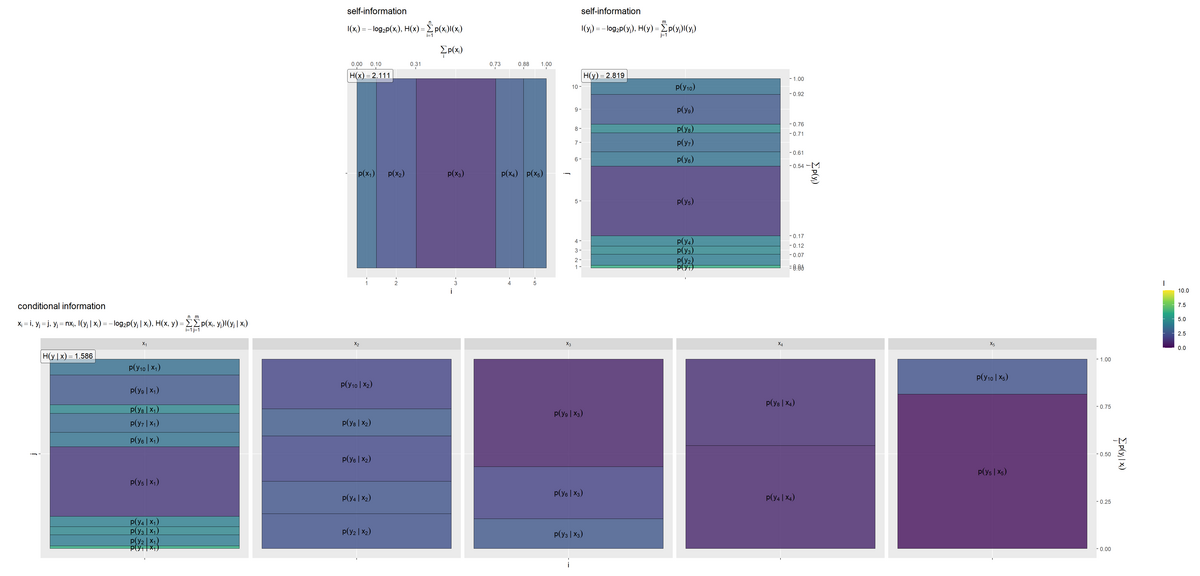
確率(セルサイズ)が小さいほど、自己情報量が大きくなります。各事象の確率と自己情報量の関係については「自己情報量の定義 - からっぽのしょこ」を参照してください。
変数間に依存関係がある場合の結合エントロピーをヒートマップで可視化します。
・作図コード(クリックで展開)
の事象の組み合わせごとの自己情報量のヒートマップを作成します。
# 平均情報量を計算 H_xy <- sum(entropy_xy_df[["p_xy"]] * entropy_xy_df[["I_xy"]], na.rm = TRUE) # ラベル用の文字列を作成 fnc_label <- paste0( "list(", "x[i] == i, y[j] == j", ", ", "y[j] == n * x[i]", ", ", "p(x[i], y[j]) == p(x[i]) * p(y[j]~'|'~x[i])", ", ", "I(x[i], y[j]) == - log[2]*p(x[i], y[j])", ", ", "H(x, y) == sum({}, i==1, n) * sum({}, j==1, m) * p(x[i], y[j]) * I(x[i], y[j])", ")" ) H_xy_label <- paste0("H(x, y) == ", round(H_xy, digits = 3)) # x・yの自己情報量を作図 entropy_xy_graph <- ggplot() + geom_tile(data = entropy_xy_df, mapping = aes(x = coord_x, y = coord_y, width = p_x, height = p_y.x, fill = I_xy), color = "black", alpha = 0.8) + # 自己情報量 geom_text(data = entropy_xy_df, mapping = aes(x = coord_x, y = coord_y, label = p_label), parse = TRUE, angle = 0) + # 確率の式 geom_label(mapping = aes(x = -Inf, y = Inf), label = H_xy_label, hjust = 0, vjust = 1, parse = TRUE, alpha = 0.5) + # エントロピーの値 scale_x_continuous(breaks = coord_x_vec, labels = x_idx, sec.axis = sec_axis(trans = ~., breaks = round(cumsum(c(0, p_x_vec)), digits = 2), name = expression(sum(p(x[i]), i)))) + # xのインデックスと累積確率 scale_y_continuous(breaks = 0.5, labels = NULL, sec.axis = sec_axis(trans = ~., breaks = seq(from = 0, to = 1, by = 0.25), name = expression(sum(p(y[j]~'|'~x[i]), j)))) + # yのインデックスと累積確率 scale_fill_viridis_c(limits = c(0, I_max)) + # グラデーション coord_fixed(ratio = 1, clip = "off") + # アスペクト比 theme(panel.grid.minor = element_blank()) + # 図の体裁 labs(title = "joint information", subtitle = parse(text = fnc_label), fill = "I", x = "i", y = "j") entropy_xy_graph
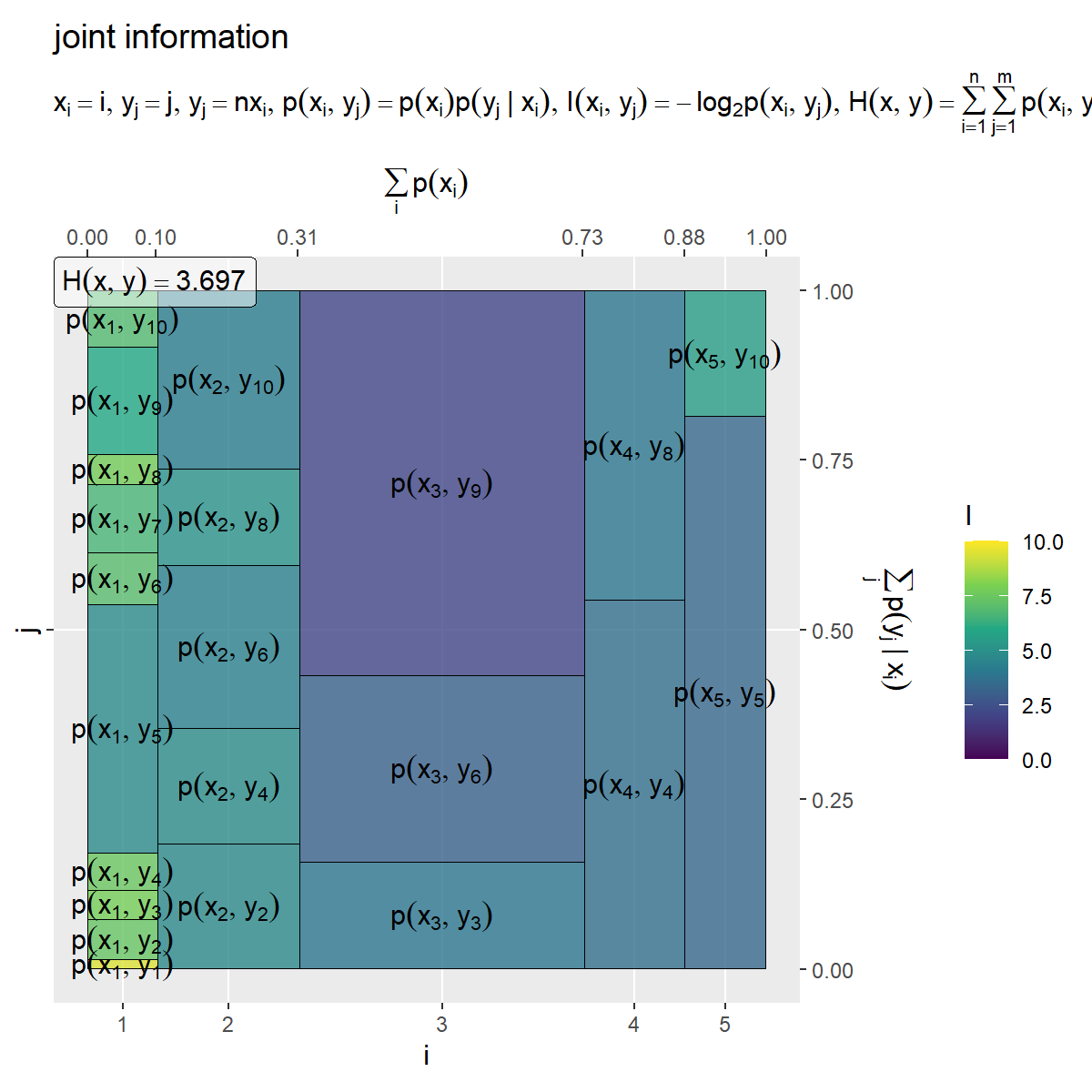
結合エントロピー(多変数の平均情報量) を計算して、ラベルとして表示します。
4つのグラフを並べて描画します。
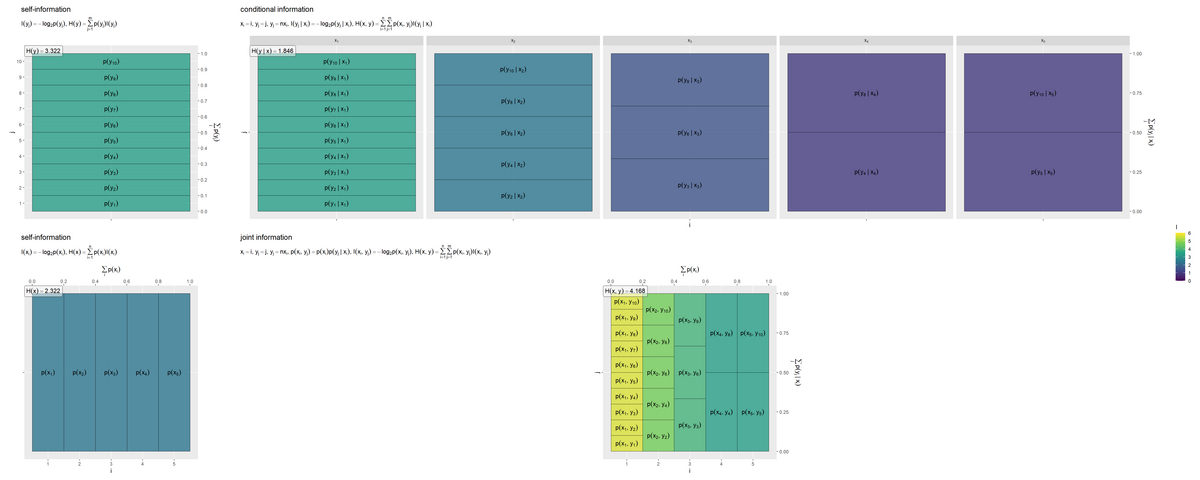
# 並べて描画 entropy_joint_graph <- patchwork::wrap_plots( entropy_y_graph, entropy_y.x_graph, entropy_x_graph, entropy_xy_graph, nrow = 2, ncol = 2, widths = c(1, 5, 1, 1), heights = 1, guides = "collect" ) entropy_joint_graph
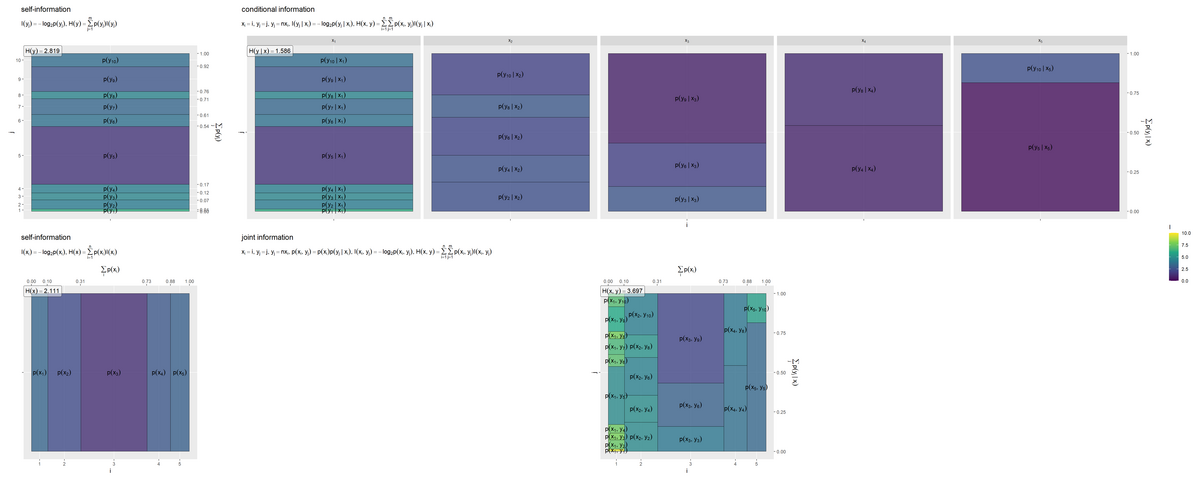
事象(セル)ごとの自己情報量(色を高さとみなして)の期待値(面積の割合と高さの加重平均)がエントロピーや結合エントロピーの値です。
条件付きエントロピーは、条件付き確率(右上のグラフの各セル)の自己情報量を、結合確率(右下のグラフの各セル)により期待値(加重平均)をとった値です。条件付き確率自体による期待値は、(条件付けられた事象の)エントロピーです。

この記事では、条件付きエントロピーの定義を確認しました。次の記事では、相互情報量の定義を確認します。
参考文献
- 『わかりやすい ディジタル情報理論』(改訂2版)塩野 充・蜷川 繁,オーム社,2021年.
おわりに
変数間に依存関係を持たせる操作が分かるようでよく分かっていません。そういえば今までは、確率分布のパラメータの値を条件としている例ばかりを扱っていました。今回は分かりやすい図を作りたかったので、変数のレベルで関連させましたが、確率的に関連させた方がいいのかもしれません。
確率分布の勉強していていつも思うのが何よりggplot2の扱いが上手くなってる。
【次の内容】