はじめに
『トピックモデル』(MLPシリーズ)の勉強会資料のまとめです。各種モデルやアルゴリズムを「数式」と「プログラム」を用いて解説します。
本の補助として読んでください。
この記事では、無限混合ユニグラムモデル(無限次元の混合カテゴリモデル)の生成モデルをPythonでスクラッチ実装します。
【前節の内容】
【他の節の内容】
【この節の内容】
8.1 無限混合ユニグラムモデルの生成モデルの実装
中華料理店過程(CRP・chinese restaurant process)を用いてトピック数を追加する無限混合ユニグラムモデル(infinite mixture of unigram models)の生成モデル(生成過程)を実装して、簡易的な文書データ(トイデータ)を作成する。
無限混合ユニグラムモデルについては「無限混合ユニグラムモデルの生成モデルの導出(あとで書く)」を参照のこと。
利用するライブラリを読み込む。
# 利用ライブラリ import numpy as np import matplotlib.pyplot as plt
文書データの簡易生成
まずは、無限混合ユニグラムモデルの生成モデルに従って、文書集合に対応するデータを生成する。
真の分布や真のトピックなど本来は得られない情報についてはオブジェクト名に true を付けて表す。
パラメータの設定
文書集合に関する値を設定する。
# 文書数を指定 D = 30 # 語彙数を指定 V = 100
文書数 、語彙(単語の種類)数
を指定する。
トピック分布のハイパーパラメータを設定する。
# トピック分布のハイパーパラメータを指定 true_alpha = 2.0
新規トピックの生成確率を制御する値 を指定する。0より大きい値
を満たす必要がある。(新規の)トピックが割り当てられた文書数に相当するパラメータであり、値が大きいほど新規トピックが生成されやすくなる。
単語分布のハイパーパラメータを設定する。
# 語彙分布のハイパーパラメータを指定 true_beta = 1.0 true_beta_v = np.repeat(true_beta, repeats=V) # 一様なパラメータの場合 #true_beta_v = np.random.uniform(low=1, high=2, size=V) # 多様なパラメータの場合 print(true_beta_v[:5]) # 非負の値 print(true_beta_v.shape) # 語彙数
[1. 1. 1. 1. 1.]
(100,)
個の値(ベクトル)
を指定する。各値は0より大きい値
を満たす必要がある。全てを同じ値
とする場合は、1個の値(スカラ)
で表す。
文書データの生成
設定したパラメータに従う文書集合を作成する。
# トピック数を初期化 true_K = 0 # 文書ごとの各単語の語彙を初期化 w_dic = {} # 各文書のトピックを初期化 true_z_d = np.tile(np.nan, reps=D) # 各トピックの割り当て文書数を初期化 true_D_k = np.array([]) # 各文書の単語数を初期化 N_d = np.zeros(shape=D, dtype='int') # 文書ごとの各語彙の単語数を初期化 N_dv = np.zeros(shape=(D, V), dtype='int') # 文書データを生成 for d in range(D): # 文書ごと # トピック分布のパラメータを計算:式(8.2) if true_K == 0: # (初回の場合) true_theta_k = np.array([1.0]) else: true_theta_k = np.hstack([true_D_k, true_alpha]) / (d + true_alpha) # 既存・新規の確率を結合 # トピックを生成 onehot_k = np.random.multinomial(n=1, pvals=true_theta_k, size=1).reshape(true_K+1) # one-hot符号 k, = np.where(onehot_k == 1) # トピック番号 k = k.item() # トピックを割当 true_z_d[d] = k if k == true_K: # (新規で割り当てられた場合) # トピックを追加 true_K += 1 true_D_k = np.hstack([true_D_k, 0]) # 語彙分布のパラメータを生成 if true_K == 1: # (初回の場合) true_phi_kv = np.random.dirichlet(alpha=true_beta_v, size=1) else: true_phi_kv = np.vstack( [true_phi_kv, np.random.dirichlet(alpha=true_beta_v, size=1)] # 既存・新規の確率を結合 ) # 割当数をカウント true_D_k[k] += 1 # 単語数を生成 N_d[d] = np.random.randint(low=100, high=200, size=1) # 下限・上限を指定 # 各単語の語彙を初期化 tmp_w_n = np.repeat(np.nan, repeats=N_d[d]) # 各単語の語彙 for n in range(N_d[d]): # 単語ごと # 語彙を生成 onehot_v = np.random.multinomial(n=1, pvals=true_phi_kv[k], size=1).reshape(V) # one-hot符号 v, = np.where(onehot_v == 1) # 語彙番号 v = v.item() # 語彙を割当 tmp_w_n[n] = v # 頻度をカウント N_dv[d, v] += 1 # データを記録 w_dic[d] = tmp_w_n.copy() # 途中経過を表示 print(f'document: {d+1}, words: {N_d[d]}, topic: {k+1}')
document: 1, words: 196, topic: 1
document: 2, words: 114, topic: 2
document: 3, words: 165, topic: 3
document: 4, words: 129, topic: 4
document: 5, words: 157, topic: 4
(省略)
document: 26, words: 100, topic: 8
document: 27, words: 169, topic: 6
document: 28, words: 195, topic: 5
document: 29, words: 110, topic: 4
document: 30, words: 124, topic: 3
- トピック数を
で初期化しておく。
個の文書
について、順番に単語を生成していく。
番目までの文書のトピックに応じて、式(8.2)によりトピック分布のパラメータ
を作成する。
- 文書
のトピック
に、トピック分布(カテゴリ分布)
に従い、
個のトピック
からトピック番号を割り当てる。
- 新規トピック
が割り当てられた場合は、トピック数
を更新する。
- トピック
の単語分布のパラメータ
を生成して、
個の単語分布のパラメータ
に結合する。
- 新規トピック
- 割り当てられたトピック
の文書数
をカウントする。
- 文書
をランダムに決める。この例では、上限数・下限数を指定して一様乱数を生成する。
について、順番に語彙を生成していく。
- 割り当てられたトピック
に従い、
個の語彙
から語彙番号を割り当てる。
- 割り当てられたトピック
文書間で単語数が異なる(2次元配列として扱えない)ので、単語集合 については、ディクショナリで扱う。
既存トピック数が のときの新規トピックの割当確率を含むトピック分布のパラメータ
を次の式で計算する。
個の値はそれぞれ0から1の値
で、総和が1になる値
を満たす。
各トピックの単語分布パラメータ を
np.random.dirichlet() で作成する。alpha 引数にハイパーパラメータ 、
size 引数に 1 を指定する。
個の値はそれぞれ0から1の値
で、総和が1になる値
を満たす。
カテゴリ分布の乱数は、np.random.multinomial() で生成できる。試行回数の引数 n に 1、パラメータの引数 pvals にトピック分布 または語彙分布
、サンプルサイズの引数
size に 1 を指定する。
one-hotベクトルが生成されるので、np.where() で値が 1 の要素番号を得る。np.argmax() でも抽出できる。
または、np.random.choice() で直接番号を得られる。
文書ごとに全ての語彙で和をとると各文書の単語数に一致する。
# 単語数を確認 print(N_d[:5]) # 各文書の単語数 print(N_dv[:5].sum(axis=1)) # 各文書の単語数
[196 114 165 129 157]
[196 114 165 129 157]
データの可視化
次は、生成した文書データと真の分布のグラフを作成する。
アニメーションの作図コードは「generative_model.py at anemptyarchive/Topic-Models-AO · GitHub」を参照のこと。
カラーマップを設定する。
# 作図用に変換 true_z_d = true_z_d.astype('int') # 配色の共通化用のカラーマップを作成 cmap = plt.get_cmap('tab10') # カラーマップの色数を設定:(カラーマップに応じて固定) color_num = 10
トピックごとに共通の配色をするために、カラーマップを指定して配色用のオブジェクト cmap を作成する。また、カラーマップで扱える色数を color_num とする。
この記事では、トピック番号 k に応じて色付けする。その際に、トピック番号を色数で割った整数部分 k % color_num を使うことで、トピック番号が色数を超える場合にカラーマップの配色がサイクルして割り当てられる。
文書データの作図
(処理の確認用に、)各トピックの割り当て文書数を集計する。オブジェクトはデータ生成時に作成されている。
# 各トピックの文書数を集計 true_D_k = np.zeros(shape=true_K) for d in range(D): k = true_z_d[d] true_D_k[k] += 1 print(true_D_k)
[2. 3. 6. 4. 8. 2. 4. 1.]
各文書に割り当てられたトピック からトピック番号
を取り出して、各トピックの文書数
をカウントする(対応する要素に
1 を加えていく)。
全てのトピックで和をとると文書数に一致する。
# 文書数を確認 print(D) print(true_D_k.sum())
30
30.0
描画する文書の数を指定して、文書データのグラフを作成する。
# 描画する文書数を指定 #doc_num = D doc_num = 10 # グラフサイズを設定 u = 5 axis_Ndv_max = np.ceil(N_dv[:doc_num].max() /u)*u # u単位で切り上げ axis_Dk_max = np.ceil(true_D_k.max() /u)*u # u単位で切り上げ # サブプロットの列数を指定:(1 < 列数 < D+1) col_num = 3 # サブプロットの行数を計算:(1行or1列だとエラー) row_num = np.ceil((doc_num+1) / col_num).astype('int') # 文書データを作図 fig, axes = plt.subplots(nrows=row_num, ncols=col_num, constrained_layout=True, figsize=(30, 20), dpi=100, facecolor='white') for d in range(doc_num): # サブプロットのインデックスを計算 r = d // col_num c = d % col_num # サブプロットを抽出 ax = axes[r, c] # トピック番号を取得 k = true_z_d[d] # 語彙頻度を描画 ax.bar(x=np.arange(stop=V)+1, height=N_dv[d], color=cmap(k%color_num)) # 単語数 ax.set_ylim(ymin=0, ymax=axis_Ndv_max) ax.set_xlabel('vocabulary ($v$)') ax.set_ylabel('frequency ($N_{dv}$)') ax.set_title(f'$d = {d+1}, k = {k+1}$', loc='left') ax.grid() # 残りのサブプロットを非表示 if c == col_num-1: # (最後の文書が右端の列の場合) r = row_num - 1 c = -1 for c in range(c+1, col_num-1): axes[r, c].axis('off') # トピックの割当を描画 ax = axes[row_num-1, col_num-1] ax.bar(x=np.arange(stop=true_K)+1, height=true_D_k, color=[cmap(k%color_num) for k in range(true_K)]) # 文書数 ax.set_ylim(ymin=0, ymax=axis_Dk_max) ax.set_xlabel('topic ($k$)') ax.set_ylabel('count ($D_k$)') ax.set_title(f'$D = {D}, K = {true_K}$', loc='left') ax.grid() fig.supxlabel('document ($d$)') fig.supylabel('document ($d$)') fig.suptitle('document data (true topic)', fontsize=20) plt.show()
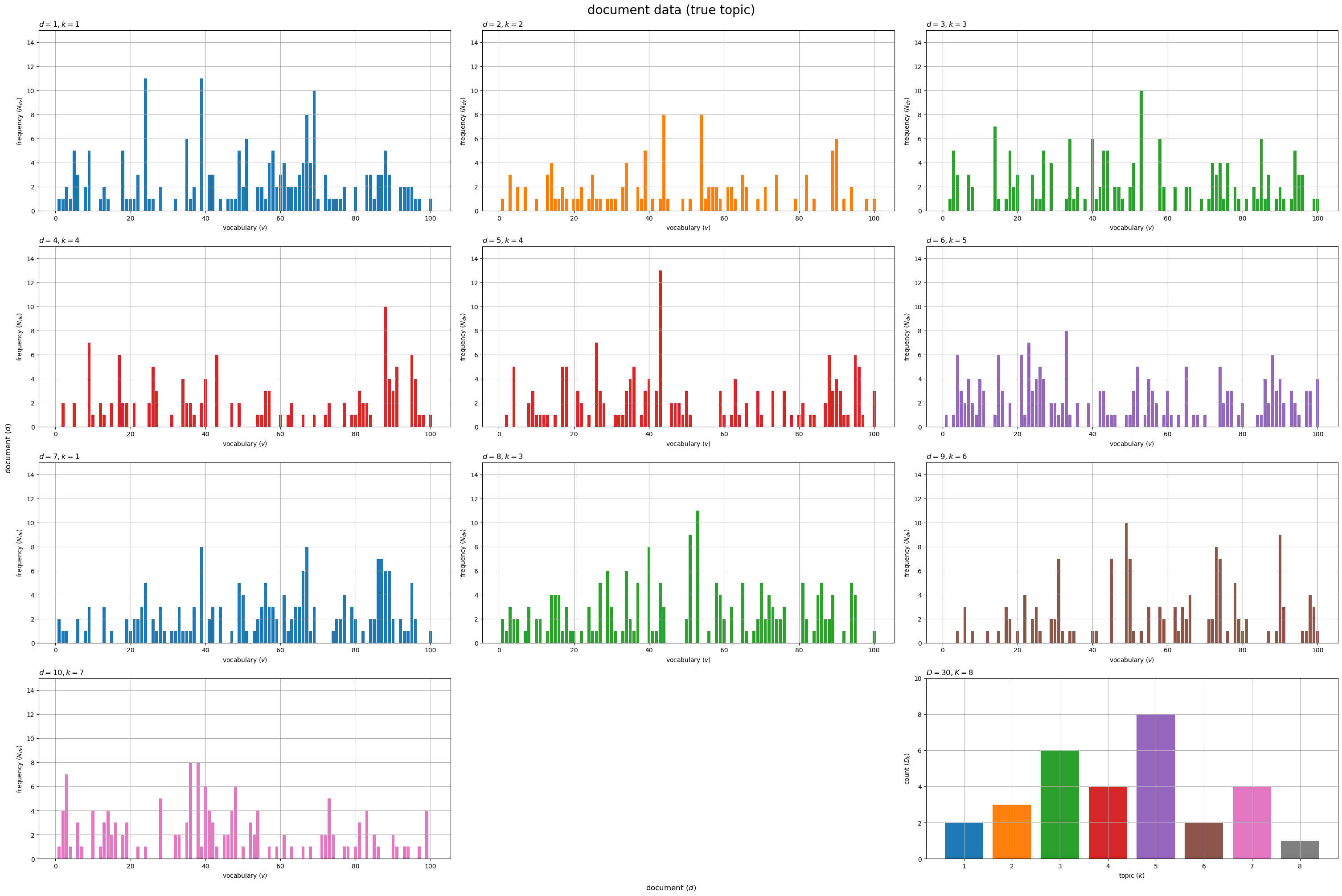
文書ごとに各語彙の出現回数 を棒グラフとして縦横に並べて描画する。各グラフは割り当てられたトピック
で色付けしている。
最後(右下)の図は、各トピックが割り当てられた文書数 を棒グラフで表している。
データ数が増えると、最後の図はトピック分布、それ以外の図は対応するトピックの単語分布の形状に近付く。
真の分布の作図
トピック分布のパラメータを作成する。
# D+1番目の文書のトピック分布のパラメータを計算 true_theta_k = np.hstack([true_D_k, true_alpha]) / (D + true_alpha) # 既存・新規の確率を結合 print(true_theta_k[:5].round(2)) # 0から1の値 print(true_theta_k.sum()) # 総和が1の値 print(len(true_theta_k)) # 既存トピック数 + 新規トピック print(true_K) # 既存トピック数
[0.06 0.09 0.19 0.12 0.25]
1.0
9
8
新規( 番目)の文書に対するトピックの割り当て確率を計算する。
トピック分布のグラフを作成する。
# グラフサイズを設定 u = 0.1 axis_size = np.ceil(true_theta_k.max() /u)*u # u単位で切り上げ # トピック分布を作図 fig, ax = plt.subplots(figsize=(8, 6), dpi=100, facecolor='white') ax.bar(x=np.arange(stop=true_K+1)+1, height=true_theta_k, color=[cmap(k%color_num) for k in range(true_K)]+['whitesmoke']) # 確率 ax.bar(x=true_K+1, height=true_theta_k[true_K], color='none', edgecolor='black', linestyle='dashed', linewidth=1) # 新規確率 ax.set_ylim(ymin=0, ymax=axis_size) ax.set_xlabel('topic ($k$)') ax.set_ylabel('probability ($\\theta_k$)') ax.set_title(f'$\\alpha = {true_alpha}, K = {true_K}$', loc='left') fig.suptitle('topic distribution (truth)', fontsize=20) ax.grid() plt.show()
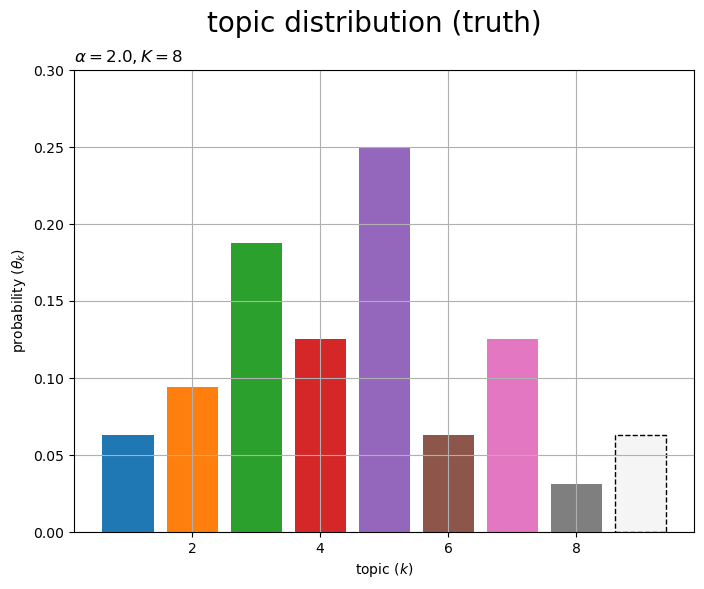
トピック分布 を棒グラフとして描画する。各トピックの割り当て確率
がバーに対応し、最後(
番目)のバーは新規トピックの割り当て確率
を示す。
各グラフの値(バーの高さ)の総和が1になる。
トピックごとの割り当て文書数とトピック分布の関係のアニメーションを作成する。
左図は各トピックが割り当てられた文書数、右図はトピック分布である。
割り当てられた文書数の多少と割り当て確率の大小が対応するのを確認できる。 は一定なので、文書数
が増えて割り当て文書数
が大きくなるほど影響が小さくなる。
描画するトピックの数を指定して、単語分布のグラフを作成する。
# 描画するトピック数を指定 topic_num = true_K #topic_num = 5 # グラフサイズを設定 u = 0.01 axis_size = np.ceil(true_phi_kv[:topic_num].max() /u)*u # u単位で切り上げ # サブプロットの列数を指定:(1 < 列数 < K) col_num = 3 # サブプロットの行数を計算:(1行or1列だとエラー) row_num = np.ceil(topic_num / col_num).astype('int') # 語彙分布を作図 fig, axes = plt.subplots(nrows=row_num, ncols=col_num, constrained_layout=True, figsize=(30, 20), dpi=100, facecolor='white') for k in range(topic_num): # サブプロットのインデックスを計算 r = k // col_num c = k % col_num # サブプロットを抽出 ax = axes[r, c] # 語彙分布を描画 ax.bar(x=np.arange(stop=V)+1, height=true_phi_kv[k], color=cmap(k%color_num)) # 確率 ax.set_ylim(ymin=0, ymax=axis_size) ax.set_xlabel('vocabulary ($v$)') ax.set_ylabel('probability ($\phi_{kv}$)') ax.set_title(f'$k = {k+1}, \\beta = {true_beta}$', loc='left') # (一様パラメータ用) #ax.set_title('$k = {}, \\beta_v = ({}, ...)$'.format(k+1, ', '.join([str(true_beta_v[v].round(2)) for v in range(5)])), loc='left') # (多様パラメータ用) ax.grid() # 残りのサブプロットを非表示 for c in range(c+1, col_num): axes[r, c].axis('off') fig.supxlabel('topic ($k$)') fig.supylabel('topic ($k$)') fig.suptitle('word distribution (truth)', fontsize=20) plt.show()
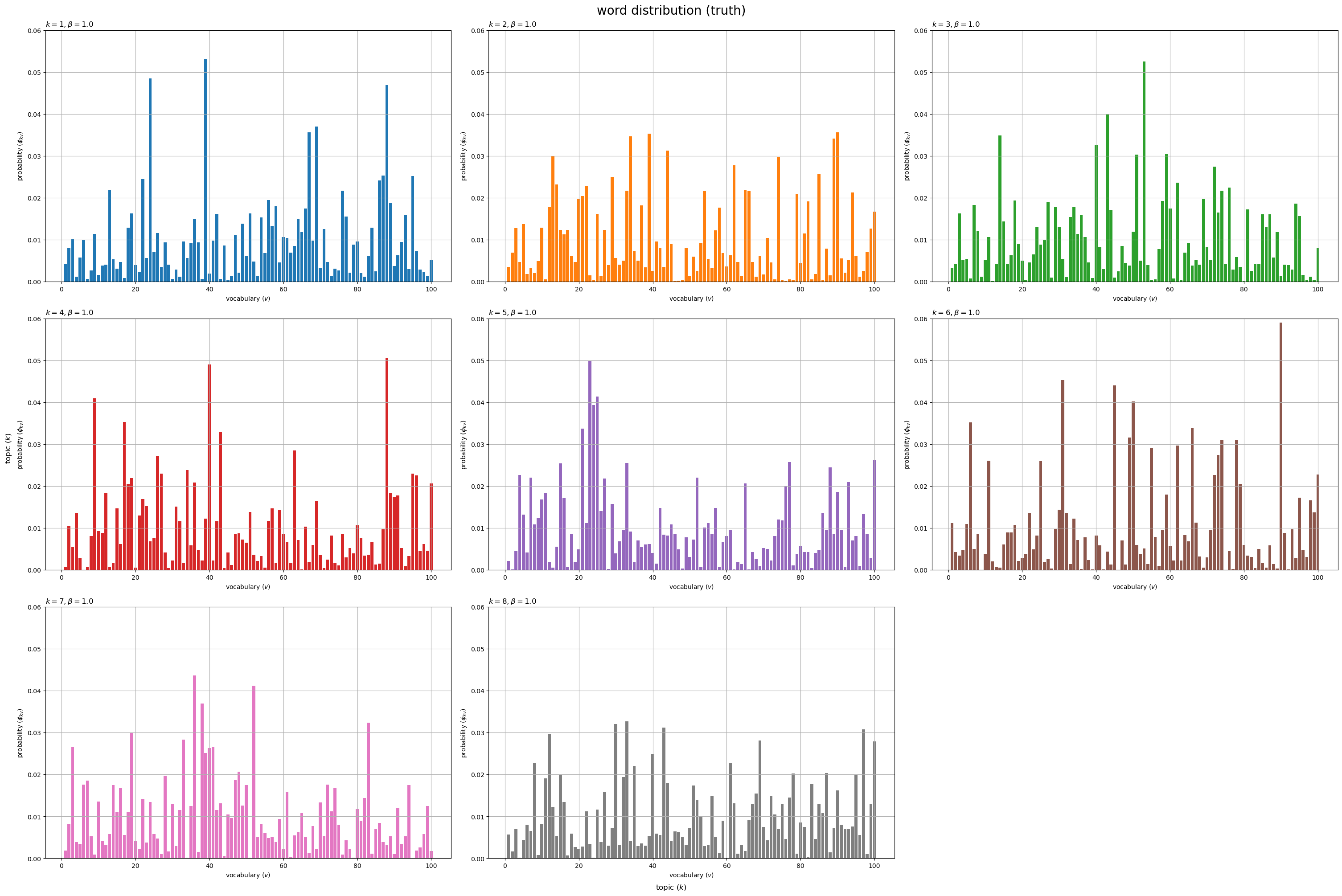
トピックごとの単語分布(語彙分布) をそれぞれ棒グラフとして縦横に並べて描画する。各トピックにおける各語彙の出現確率
がバーに対応する。
各グラフの値(バーの高さ)の総和が1になる。
この記事では無限混合ユニグラムモデルの生成モデルを実装して、各種アルゴリズムに用いる人工データを作成した。次の記事では、推論処理を実装する。
参考書籍
- 岩田具治(2015)『トピックモデル』(機械学習プロフェッショナルシリーズ)講談社
おわりに
色々あって8章突入です。6・7章は流し読みもせずに飛ばしました。5章は数式読解のみで実装はしませんでした。8章はとりあえず数式は読むだけで実装しています。
最終章にして混合ユニグラムモデルに戻るのかと思ったのですが、生成モデルだけでもトピックモデルの方はかなり激しかったので、準備運動や復習がてらここからやるのがいい構成なんだと組み終わってから思いました。ところで、無限次元のトピックモデルの疑似コードはどこでしょうか~。
さて、ノンパラメトリック編ですねと言いつつ、これで無限次元と呼んじゃっていいのという気もします。それと回るタイプの中華料理を食べたい。
2024年4月12日は、鈴木愛理さんの30歳のお誕生日です。
歌にドラマにバラエティにモデルにと色んなメディアで見かけるようになっていよいよハロプロの至宝が世間に認識されて幸せです。
他のカバー曲もグループ(℃-ute)・ユニット(Buono!他)時代の曲もソロ活動後の曲も素晴らしいのでぜひとも聴いてください。
【次節の内容】
つづく