はじめに
『ベイズ推論による機械学習入門』の学習時のノートです。基本的な内容は「数式の行間を読んでみた」とそれを「RとPythonで組んでみた」になります。「数式」と「プログラム」から理解するのが目標です。
この記事は、4.3.3項の内容です。「観測モデルをポアソン混合分布」、「事前分布をガンマ分布とディリクレ分布」とするポアソン混合モデルに対する変分推論をR言語で実装します。
省略してある内容等ありますので、本とあわせて読んでください。初学者な自分が理解できるレベルまで落として書き下していますので、分かる人にはかなりくどくなっています。同じような立場の人のお役に立てれば幸いです。
【数式読解編】
【他の節の内容】
【この節の内容】
・Rでやってみる
人工的に生成したデータを用いて、ベイズ推論を行ってみましょう。アルゴリズム4.3を参考に実装します。
利用するパッケージを読み込みます。
# 4.3.3項で利用するパッケージ library(tidyverse)
・観測モデルの設定
まずは、観測モデルを設定します。この例では、$K$個の観測モデルをポアソン分布$\mathrm{Poi}(x_n | \lambda_k)$とします。また、各データに対する$K$個の観測モデルの割り当てをカテゴリ分布$\mathrm{Cat}(\mathbf{s}_n | \boldsymbol{\pi})$によって行います。
観測モデルのパラメータと混合比率を設定します。
# K個の真のパラメータを指定 lambda_truth_k <- c(10, 25, 40) # 真の混合比率を指定 pi_truth_k <- c(0.35, 0.25, 0.4) # クラスタ数を取得 K <- length(lambda_truth_k)
観測モデルの$K$個のパラメータ$\boldsymbol{\lambda} = \{\lambda_1, \lambda_2, \cdots, \lambda_K\}$をlambda_truth_kとして、$\lambda_k \geq 0$の値を指定します。
混合比率パラメータ$\boldsymbol{\pi} = (\pi_1, \pi_2, \cdots, \pi_K)$をpi_truth_kとして、$\sum_{k=1}^K \pi_k = 1$、$\pi_k \geq 0$の値を指定します。
この2つのパラメータの値を求めるのがここでの目的です。
設定したモデルをグラフで確認しましょう。グラフ用の点を作成します。
# 作図用のxの点を作成 x_vec <- seq(0, 2 * max(lambda_truth_k)) # 確認 x_vec[1:5]
## [1] 0 1 2 3 4
作図用に、ポアソン分布に従う変数$x_n$がとり得る非負の整数をseq()で作成してx_vecとします。この例では、0から$\boldsymbol{\lambda}$の最大値の2倍を範囲とします。
ポアソン混合分布の確率を計算します。
# 観測モデルを計算 model_prob <- 0 for(k in 1:K) { # クラスタkの分布の確率を計算 tmp_prob <- dpois(x = x_vec, lambda = lambda_truth_k[k]) # K個の分布の加重平均を計算 model_prob <- model_prob + pi_truth_k[k] * tmp_prob }
$K$個のパラメータlambda_truth_kを使って、x_vecの値ごとに次の式で確率を計算します。
$K$個のポアソン分布に対して、$\boldsymbol{\pi}$を使って加重平均をとります。
ポアソン分布の確率は、dpois()で計算できます。データの引数xにx_vec、パラメータの引数lambdaにlambda_truth_k[k]を指定します。
この計算をfor()ループでK回繰り返し行います。各パラメータによって求めた$K$回分の確率をpi_truth_k[k]で割り引いてmodel_probに加算していきます。
計算結果をデータフレームに格納します。
# 観測モデルをデータフレームに格納 model_df <- tibble( x = x_vec, prob = model_prob ) # 確認 head(model_df)
## # A tibble: 6 x 2 ## x prob ## <int> <dbl> ## 1 0 0.0000159 ## 2 1 0.000159 ## 3 2 0.000794 ## 4 3 0.00265 ## 5 4 0.00662 ## 6 5 0.0132
ggplot2パッケージを利用して作図するには、データフレームを渡す必要があります。
観測モデルを作図します。
# 観測モデルを作図 ggplot(model_df, aes(x = x, y = prob)) + geom_bar(stat = "identity", position = "dodge", fill = "blue", color = "blue") + # 真の分布 labs(title = "Poisson Mixture Model", subtitle = paste0("lambda=(", paste0(lambda_truth_k, collapse = ", "), ")"))
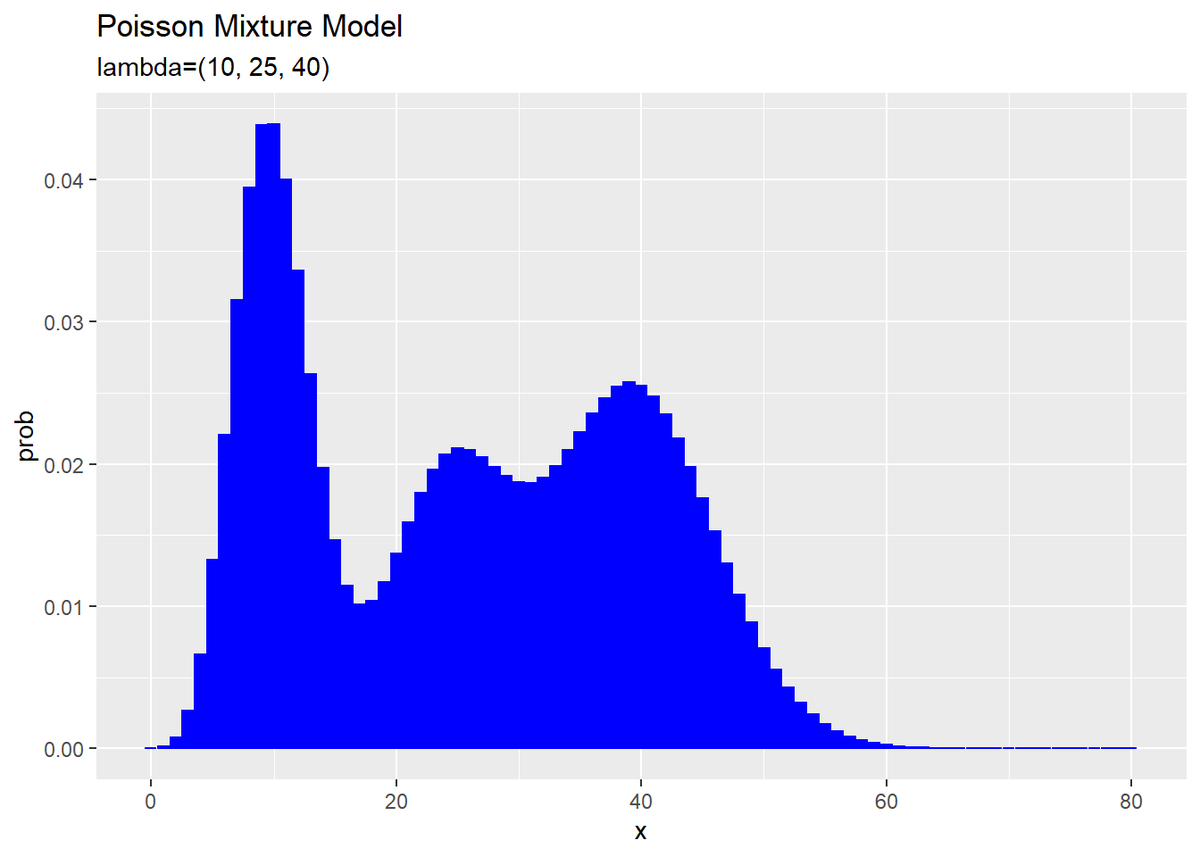
$K$個の分布を重ねたような分布になります。ただし、総和が1となるようにしているため、$K$個の分布そのものよりも1つ1つの山が小さく(確率値が小さく)なっています。
・データの生成
続いて、構築したモデルに従ってデータを生成します。先に、潜在変数$\mathbf{S} = \{\mathbf{s}_1, \mathbf{s}_2, \cdots, \mathbf{s}_N\}$、$\mathbf{s}_n = (s_{n,1}, s_{n,2}, \cdots, s_{n,K})$を生成し、各データに割り当てられたクラスタに従い観測データ$\mathbf{X} = \{x_1, x_2, \cdots, x_N\}$を生成します。
$N$個の潜在変数$\mathbf{S}$を生成します。
# (観測)データ数を指定 N <- 250 # クラスタを生成 s_truth_nk <- rmultinom(n = N, size = 1, prob = pi_truth_k) %>% t()
生成するデータ数$N$をNとして値を指定します。
カテゴリ分布に従う乱数は、多項分布に従う乱数生成関数rmultinom()のsize引数を1にすることで生成できます。また、試行回数の引数nにN、確率(パラメータ)の引数probにpi_truth_kを指定します。生成した$N$個の$K$次元ベクトルをs_nkとします。ただし、クラスタが行でデータが列方向に並んで出力されるので、t()で転置しておきます。
結果は次のようになります。
# 確認 s_truth_nk[1:5, ]
## [,1] [,2] [,3] ## [1,] 1 0 0 ## [2,] 1 0 0 ## [3,] 0 1 0 ## [4,] 0 0 1 ## [5,] 0 1 0
これが本来は観測できない潜在変数であり、真のクラスタです。各行がデータを表し、値が1の列番号が割り当てられたクラスタ番号を表します。
s_nkから各データのクラスタ番号を抽出します。
# クラスタ番号を抽出 s_truth_n <- which(t(s_truth_nk) == 1, arr.ind = TRUE) %>% .[, "row"] # 確認 s_truth_n[1:5]
## [1] 1 1 2 3 2
which()を使って要素が1の行番号を抽出します。
各データのクラスタに従い$N$個のデータを生成します。
# (観測)データを生成 x_n <- rpois(n = N, lambda = lambda_truth_k[s_truth_n])
ポアソン分布に従う乱数は、rpois()で生成できます。試行回数の引数nにN、パラメータの引数lambdaにlambda_truth_k[s_truth_n]を指定します。各データのクラスタ番号s_truth_nを添字に使うことで、各データのクラスタに対応したパラメータ$\lambda_k$をlambda_truth_kから取り出すことができます。生成した$N$個のデータをx_nとします。式(4.28)を再現して、lambdaにapply(lambda_truth_k^t(s_truth_nk), 2, prod)を渡しても生成できます。
観測したデータとクラスタ番号をデータフレームに格納します。
# 観測データをデータフレームに格納 x_df <- tibble( x_n = x_n, cluster = as.factor(s_truth_n) ) # 確認 head(x_df)
## # A tibble: 6 x 2 ## x_n cluster ## <int> <fct> ## 1 7 1 ## 2 12 1 ## 3 24 2 ## 4 43 3 ## 5 19 2 ## 6 31 2
観測データは非負の整数、クラスタは1からKの整数になっているのを確認できます。
観測データをヒストグラムで確認しましょう。
# 観測データのヒストグラムを作成 ggplot() + geom_histogram(data = x_df, aes(x = x_n, y = ..density..), binwidth = 1) + # 観測データ geom_bar(data = model_df, aes(x = x, y = prob), stat = "identity", position = "dodge", alpha = 0, color = "red", linetype = "dashed") + # 真の分布 labs(title = "Poisson Mixture Model", subtitle = paste0("N=", N, ", lambda=(", paste0(lambda_truth_k, collapse = ", "), ")"), x = "x")
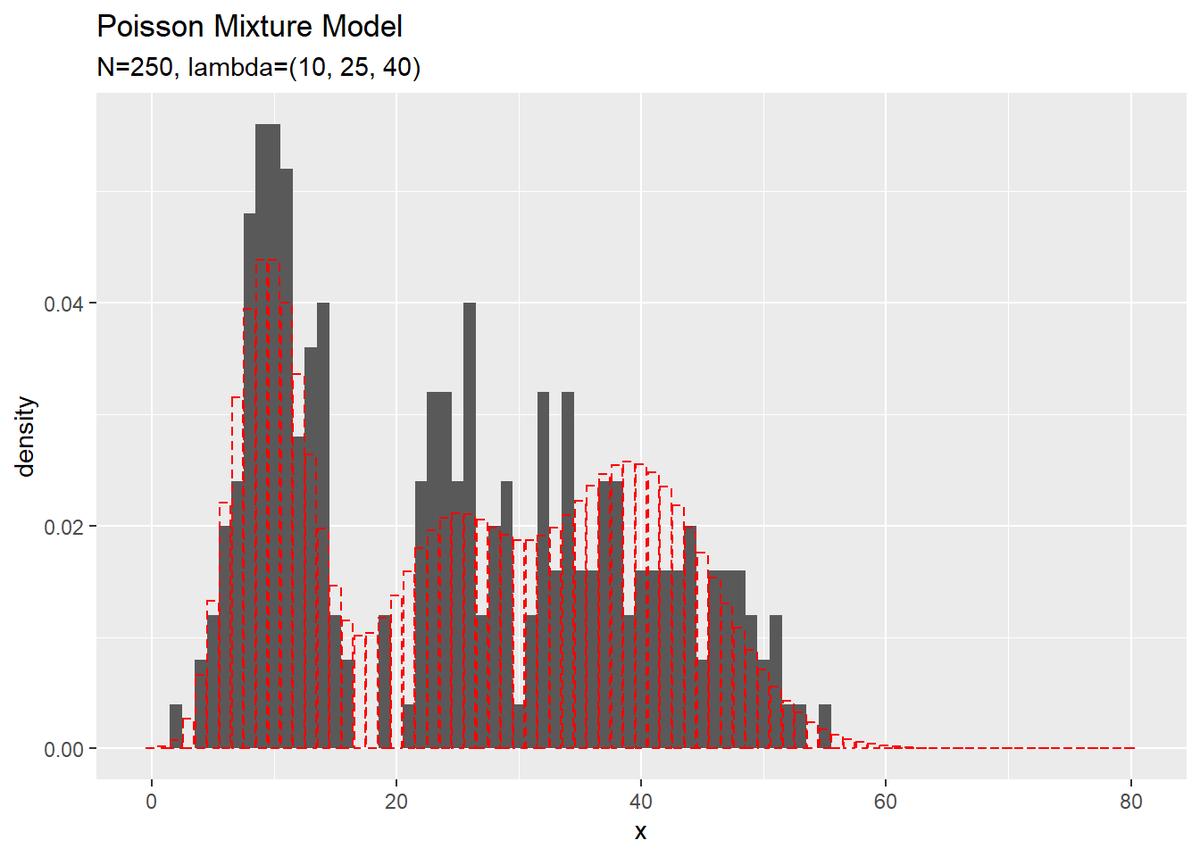
真の分布を重ねて描画しています。
また、クラスタもヒストグラムで確認しましょう。
# クラスタのヒストグラムを作成 ggplot() + geom_histogram(data = x_df, aes(x = x_n, fill = cluster), binwidth = 1, position = "identity", alpha = 0.5) + # クラスタ labs(title = "Poisson Mixture Model", subtitle = paste0("N=", N, ", lambda=(", paste0(lambda_truth_k, collapse = ", "), ")", ", pi=(", paste0(pi_truth_k, collapse = ", "), ")"), x = "x")
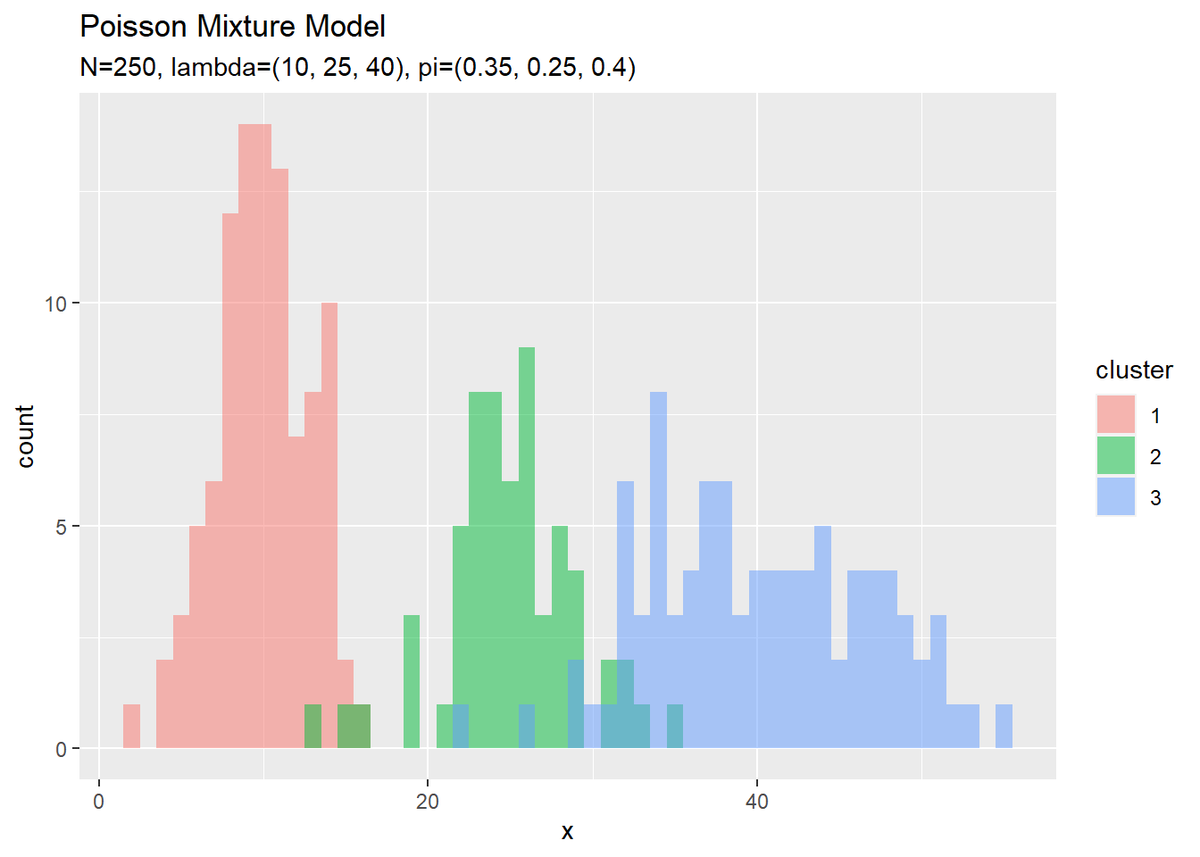
どちらの分布もデータが十分に大きいと真の分布に近づきます。
・事前分布の設定
次に、観測モデル(観測データの分布)$p(\mathbf{X} | \boldsymbol{\lambda})$と潜在変数の分布$p(\mathbf{S} | \boldsymbol{\pi})$に対する共役事前分布を設定します。ポアソン分布のパラメータ$\boldsymbol{\lambda}$に対する事前分布$p(\boldsymbol{\lambda})$としてガンマ分布$\mathrm{Gam}(\boldsymbol{\lambda} | a, b)$、カテゴリ分布のパラメータ$\boldsymbol{\pi}$に対する事前分布$p(\boldsymbol{\pi})$としてディリクレ分布$p(\boldsymbol{\pi} | \boldsymbol{\alpha})$を設定します。
$\boldsymbol{\lambda}$の事前分布と$\boldsymbol{\pi}$の事前分布のパラメータ(超パラメータ)を設定します。
# lambdaの事前分布のパラメータを指定 a <- 1 b <- 1 # piの事前分布のパラメータを指定 alpha_k <- rep(2, K)
ガンマ分布のパラメータ$a,\ b$をそれぞれa, bとして、$a > 0,\ b > 0$の値を指定します。
ディリクレ分布のパラメータ$\boldsymbol{\alpha} = (\alpha_1, \alpha_2, \cdots, \alpha_K)$をalpha_kとして、$\alpha_k > 0$の値を指定します。
超パラメータを設定できたので、$\boldsymbol{\lambda}$の事前分布を確認しましょう。グラフ用の点を作成して、確率密度を計算します。
# 作図用のlambdaの点を作成 lambda_vec <- seq(0, 2 * max(lambda_truth_k), length.out = 1000) # lambdaの事前分布を計算 prior_df <- tibble( lambda = lambda_vec, density = dgamma(x = lambda, shape = a, rate = b) )
ガンマ分布に従う変数$\lambda_k$がとり得る0以上の値をseq()で作成してlambda_vecとします。この例では、0から$\boldsymbol{\lambda}$の最大値の2倍を範囲とします。length.out引数を使うと指定した要素数で等間隔に切り分けます。by引数を使うと切り分ける間隔を指定できます。処理が重い場合は、この値を調整してください。
作成したlambda_vecの値ごとに確率密度を計算します。ガンマ分布の確率密度は、dgamma()で計算できます。データの引数xにlambda_vec、shape引数にa、rate引数にbを指定します。
作成したデータフレームは次のようになります。
# 確認 head(prior_df)
## # A tibble: 6 x 2 ## lambda density ## <dbl> <dbl> ## 1 0 1 ## 2 0.0801 0.923 ## 3 0.160 0.852 ## 4 0.240 0.786 ## 5 0.320 0.726 ## 6 0.400 0.670
$\boldsymbol{\lambda}$の事前分布を作図します。
# lambdaの事前分布を作図 ggplot(prior_df, aes(x = lambda, y = density)) + geom_line(color = "purple") + # 事前分布 geom_vline(xintercept = lambda_truth_k, color = "red", linetype = "dashed") + # 真の値 labs(title = "Gamma Distribution", subtitle = paste0("a=", b, ", b=", b), x = expression(lambda))
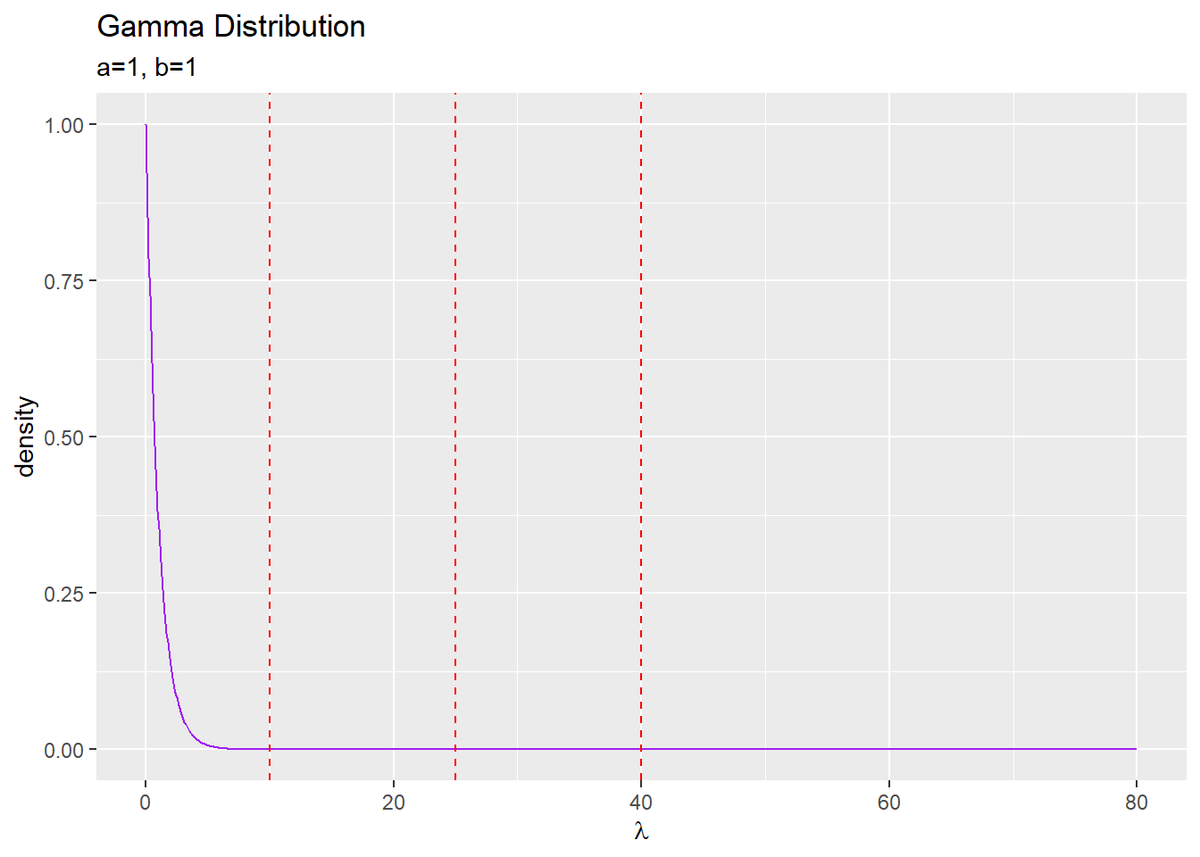
真の値を垂直線geom_vline()で描画しています。
$\pi$の事前分布(と事後分布)については省略します。詳しくは、3.2.2項「カテゴリ分布の学習と予測」をご参照ください。
・初期値の設定
潜在変数の近似事後分布の期待値$\mathbb{E}_{q(\mathbf{S})}[s_{n,k}]$をランダムに生成して初期値とします。
潜在変数の近似事後分布の期待値を初期化します。
# 潜在変数の近似事後分布の期待値を初期化 E_s_nk <- runif(n = N * K, min = 0, max = 1) %>% matrix(nrow = N, ncol = K) E_s_nk <- E_s_nk / rowSums(E_s_nk) # 正規化
一様乱数の生成関数runif()を使って0から1の値を生成し、N行K列のマトリクスを作成してE_s_nkとします。ランダムに生成した値を、行ごとの和が1になるように正規化します。(正規化するので乱数の時点で0から1の値である必要はありませんが、確率であることを明示しておきます。)
生成したパラメータを確認します。
# 確認 E_s_nk[1:5, ]
## [,1] [,2] [,3] ## [1,] 0.6471795 0.03794092 0.3148796 ## [2,] 0.1877457 0.52631652 0.2859377 ## [3,] 0.4701179 0.32613809 0.2037440 ## [4,] 0.2614357 0.21575173 0.5228126 ## [5,] 0.3243464 0.22004449 0.4556092
行がデータ、列がクラスタであり、それぞれのデータが各クラスタとなる確率を表しています。
E_s_nkを用いて、$\boldsymbol{\lambda}$の近似事後分布のパラメータの初期値を計算します。
# 初期値によるlambdaの事後分布のパラメータを計算:式(4.55) a_hat_k <- colSums(E_s_nk * x_n) + a b_hat_k <- colSums(E_s_nk) + b
$\boldsymbol{\lambda}$の近似事後分布のパラメータ$\hat{\mathbf{a}} = \{\hat{a}_1, \hat{a}_2, \cdots, \hat{a}_K\}$、$\hat{\mathbf{b}} = \{\hat{b}_1, \hat{b}_2, \cdots, \hat{b}_K\}$は
で計算して、結果をa_hat_k, b_hat_kとします。
# 確認
a_hat_k
b_hat_k
## [1] 2138.033 1976.014 2031.953 ## [1] 88.94718 81.54459 82.50822
ちなみに、$\sum_{n=1}^N \mathbb{E}_{q(\mathbf{s}_n)} [s_{n,k}] x_n$は各データ$x_n$を各クラスタとなる確率で割り引いた上でのクラスタごとの総和で、$\sum_{n=1}^N \mathbb{E}_{q(\mathbf{s}_n)} [s_{n,k}]$は各クラスタとなる確率の総和です。
同様に、$\boldsymbol{\pi}$の近似事後分布のパラメータの初期値を計算します。
# 初期値によるpiのパラメータを計算:式(4.58) alpha_hat_k <- colSums(E_s_nk) + alpha_k
$\boldsymbol{\pi}$の近似事後分布のパラメータ$\hat{\boldsymbol{\alpha}} = (\hat{\alpha}_1, \hat{\alpha}_2, \cdots, \hat{\alpha}_K)$は
で計算して、結果をalpha_hat_kとします。
# 確認
alpha_hat_k
## [1] 89.94718 82.54459 83.50822
超パラメータの初期値が得られたので、$\boldsymbol{\lambda}$の近似事後分布を確認しましょう。$K$個のガンマ分布を計算します。
# 初期値によるlambdaの近似事後分布をデータフレームに格納 init_lambda_df <- tibble() for(k in 1:K) { # クラスタkの事後分布を計算 tmp_init_df <- tibble( lambda = lambda_vec, density = dgamma(x = lambda, shape = a_hat_k[k], rate = b_hat_k[k]), cluster = as.factor(k) ) # 結果を結合 init_lambda_df <- rbind(init_lambda_df, tmp_init_df) }
事前分布と同様に計算します。ただし、超パラメータが$K$個になったので、ガンマ分布も$K$個になります。$K$回分の計算結果をデータフレームに格納していきます。
作成したデータフレームは次のようになります。
# 確認 head(init_lambda_df)
## # A tibble: 6 x 3 ## lambda density cluster ## <dbl> <dbl> <fct> ## 1 0 0 1 ## 2 0.0801 0 1 ## 3 0.160 0 1 ## 4 0.240 0 1 ## 5 0.320 0 1 ## 6 0.400 0 1
$\boldsymbol{\lambda}$の近似事後分布の初期値を作図します。
# 初期値によるlambdaの近似事後分布を作図 ggplot(init_lambda_df, aes(x = lambda, y = density, color = cluster)) + geom_line() + # 初期値による事後分布 geom_vline(xintercept = lambda_truth_k, color = "red", linetype = "dashed") + # 真の値 labs(title = "Gamma Distribution", subtitle = paste0("iter:", 0, ", a=(", paste0(round(a_hat_k, 1), collapse = ", "), ")", ", b=(", paste0(round(b_hat_k, 1), collapse = ", "), ")"), x = expression(lambda))
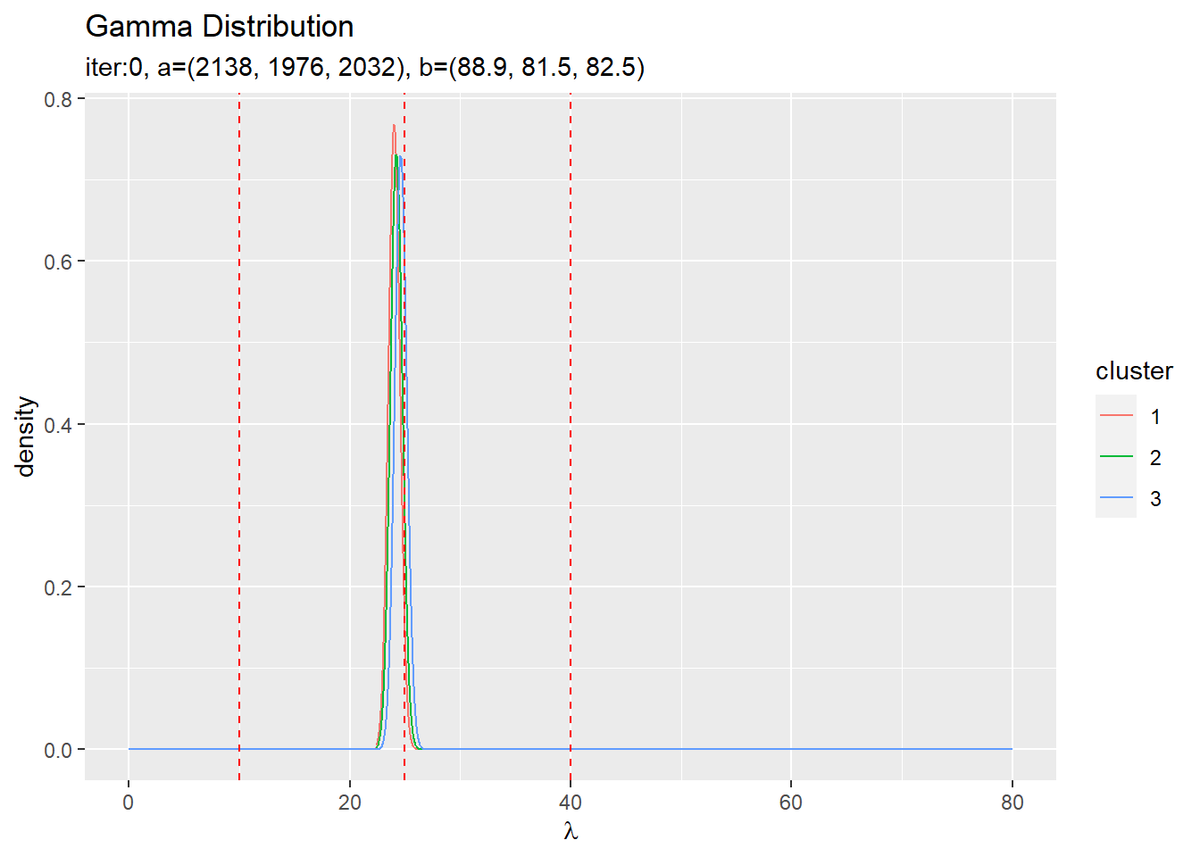
超パラメータ$\hat{a}_k,\ \hat{b}_k,\ \hat{\alpha}_k$からパラメータの期待値$\mathbb{E}[\lambda_k],\ \mathbb{E}[\pi_k]$を求めて、混合分布を計算します。
# lambdaの平均値を計算:式(2.59) E_lambda_k <- a_hat_k / b_hat_k # piの平均値を計算:式(2.51) E_pi_k <- alpha_hat_k / sum(alpha_hat_k) # 初期値による混合分布を計算 init_prob <- 0 for(k in 1:K) { # クラスタkの分布の確率を計算 tmp_prob <- dpois(x = x_vec, lambda = E_lambda_k[k]) # K個の分布の加重平均を計算 init_prob <- init_prob + E_pi_k[k] * tmp_prob }
$\mathbb{E}[\lambda_k]$は、ガンマ分布の期待値(2.59)より
で計算します。また、$\mathbb{E}[\pi_k]$は、ディリクレ分布の期待値(2.51)より
で計算します。
それぞれE_lambda_k, E_pi_kとして、観測モデルと同様にして混合分布を計算します。
超パラメータの初期値から求めた分布を作図します。
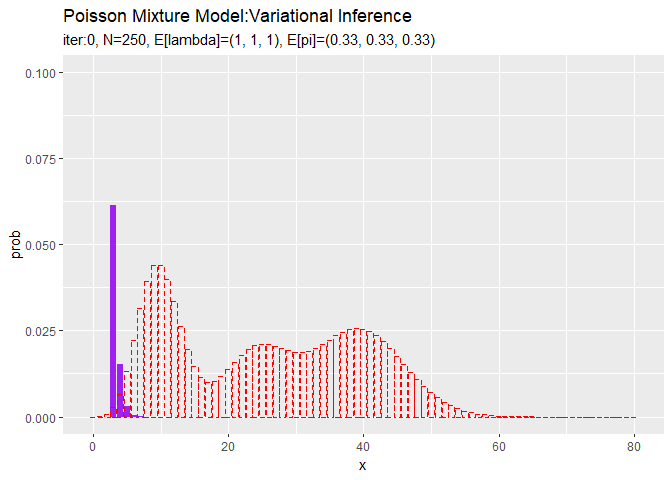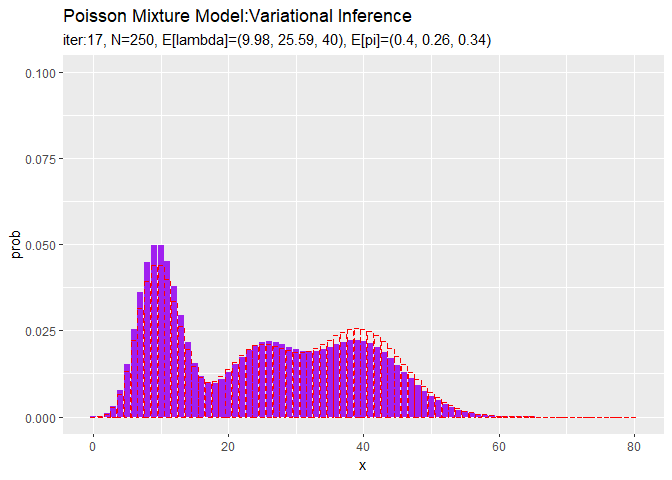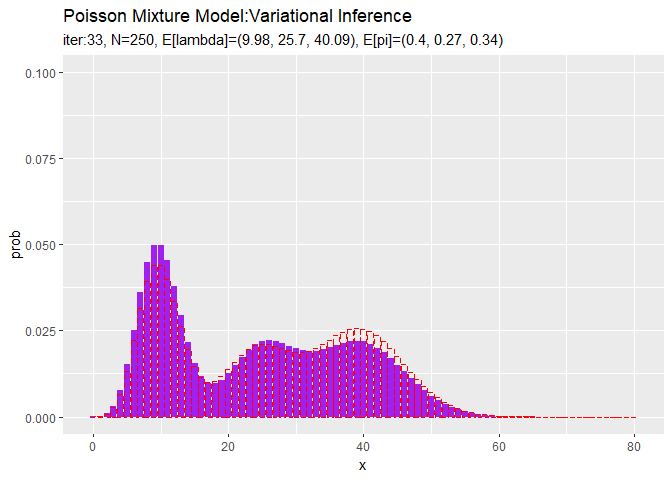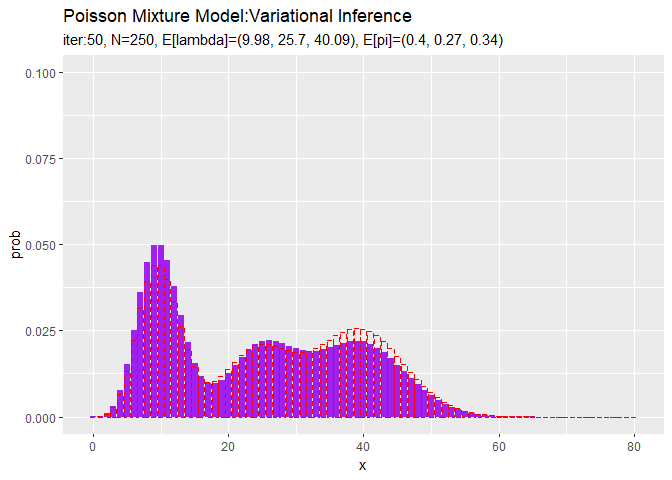
# 初期値による分布をデータフレームに格納 init_df <- tibble( x = x_vec, prob = init_prob ) # 初期値による分布を作図 ggplot() + geom_bar(data = init_df, aes(x = x, y = prob), stat = "identity", position = "dodge", fill = "purple", color = "purple") + # 初期値による分布 geom_bar(data = model_df, aes(x = x, y = prob), stat = "identity", position = "dodge", alpha = 0, color = "red", linetype = "dashed") + # 真の分布 labs(title = "Poisson Mixture Model", subtitle = paste0("iter:", 0, ", E[lambda]=(", paste0(round(E_lambda_k, 2), collapse = ", "), ")", ", E[pi]=(", paste0(round(E_pi_k, 2), collapse = ", "), ")"))
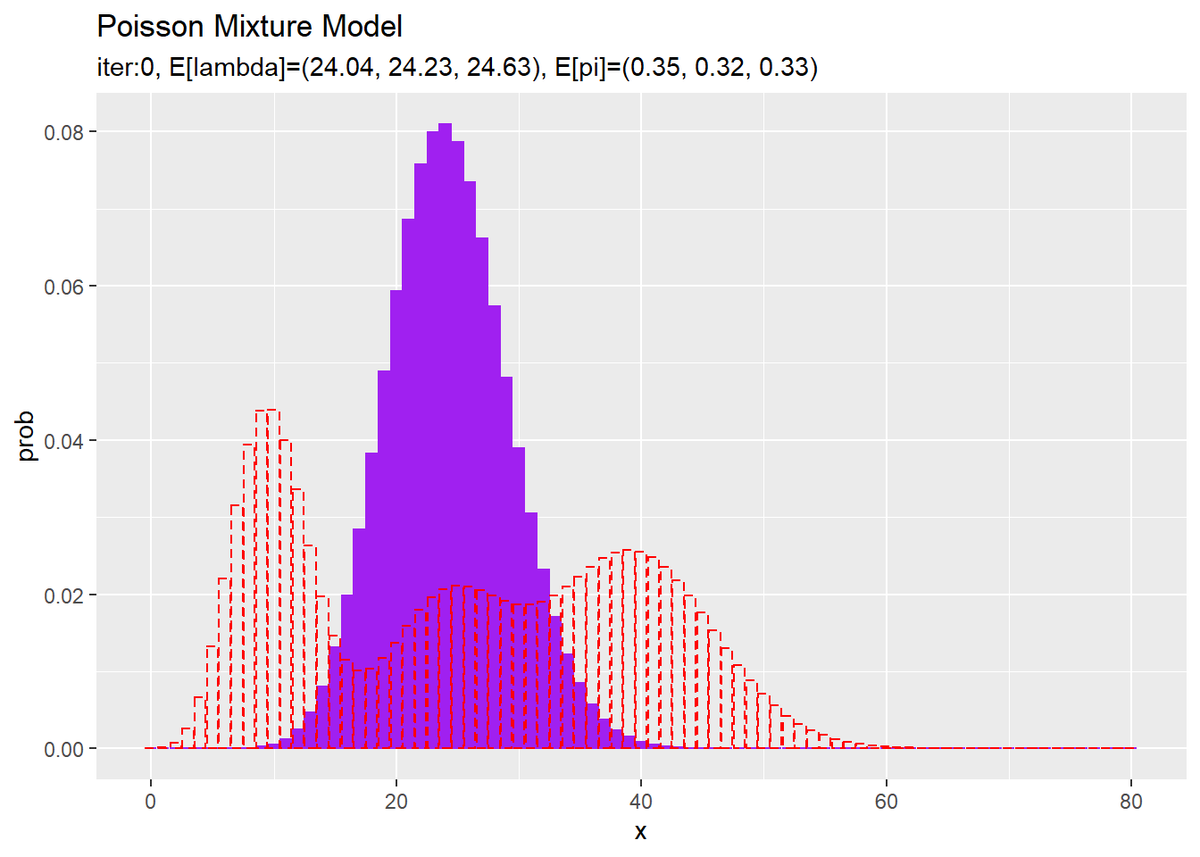
観測モデルのときと同様に作図します。
・変分推論
変分推論により、パラメータと潜在変数を推定します。
・コード全体
eta_nkについては添字を使って代入するため、予め変数を用意しておく必要があります。
また、後で各パラメータの更新値や分布の推移を確認するために、それぞれ試行ごとにtrace_***に値を保存していきます。
# 試行回数を指定 MaxIter <- 50 # 変数を作成 eta_nk <- matrix(0, nrow = N, ncol = K) # 推移の確認用の受け皿を作成 trace_E_s_ink <- array(0, dim = c(MaxIter + 1, N, K)) trace_a_ik <- matrix(0, nrow = MaxIter + 1, ncol = K) trace_b_ik <- matrix(0, nrow = MaxIter + 1, ncol = K) trace_alpha_ik <- matrix(0, nrow = MaxIter + 1, ncol = K) # 初期値を記録 trace_E_s_ink[1, , ] <- E_s_nk trace_a_ik[1, ] <- a_hat_k trace_b_ik[1, ] <- b_hat_k trace_alpha_ik[1, ] <- alpha_k # 変分推論 for(i in 1:MaxIter) { # 潜在変数の事後分布のパラメータの各項を計算:式(4.60-4.62) E_lmd_k <- a_hat_k / b_hat_k E_ln_lmd_k <- digamma(a_hat_k) - log(b_hat_k) E_ln_pi_k <- digamma(alpha_hat_k) - digamma(sum(alpha_hat_k)) for(n in 1:N) { # 潜在変数の事後分布のパラメータを計算:式(4.51) tmp_eta_k <- exp(x_n[n] * E_ln_lmd_k - E_lmd_k + E_ln_pi_k) eta_nk[n, ] <- tmp_eta_k / sum(tmp_eta_k) # 正規化 # 潜在変数の事後分布の期待値を計算:式(4.59) E_s_nk[n, ] <- eta_nk[n, ] } # lambdaの事後分布のパラメータを計算:式(4.55) a_hat_k <- colSums(E_s_nk * x_n) + a b_hat_k <- colSums(E_s_nk) + b # piのパラメータを計算:式(4.58) alpha_hat_k <- colSums(E_s_nk) + alpha_k # i回目の結果を記録 trace_E_s_ink[i + 1, , ] <- E_s_nk trace_a_ik[i + 1, ] <- a_hat_k trace_b_ik[i + 1, ] <- b_hat_k trace_alpha_ik[i + 1, ] <- alpha_hat_k # 動作確認 #print(paste0(i, ' (', round(i / MaxIter * 100, 1), '%)')) }
・処理の確認
変分推論で行う処理を確認していきます。
・潜在変数の近似事後分布$q(\boldsymbol{s}_n)$のパラメータの更新\
$\mathbf{S}$の近似事後分布のパラメータを計算します。
# 潜在変数の事後分布のパラメータの各項を計算:式(4.60-4.62) E_lmd_k <- a_hat_k / b_hat_k E_ln_lmd_k <- digamma(a_hat_k) - log(b_hat_k) E_ln_pi_k <- digamma(alpha_hat_k) - digamma(sum(alpha_hat_k)) for(n in 1:N) { # 潜在変数の事後分布のパラメータを計算:式(4.51) tmp_eta_k <- exp(x_n[n] * E_ln_lmd_k - E_lmd_k + E_ln_pi_k) eta_nk[n, ] <- tmp_eta_k / sum(tmp_eta_k) # 正規化 # 潜在変数の事後分布の期待値を計算:式(4.59) E_s_nk[n, ] <- eta_nk[n, ] }
$n$番目のデータの潜在変数$\mathbf{s}_n$の近似事後分布(カテゴリ分布)のパラメータ$\boldsymbol{\eta}_n = (\eta_{n,1}, \eta_{n,2}, \cdots, \eta_{n,K})$を次の式で計算します。
右辺の計算結果をtmp_eta_kとします。各項は
で計算します。これらの項は、データによって値が変わらないため、ループの外で計算できます。さらに、総和が1になるように次の式で正規化します。
計算結果をeta_nkとします。
ちなみに、式(4.51)の$\exp(\cdot)$の括弧の中を$\tilde{\eta}_{n,k}$とすると、正規化の式は$\frac{\exp (\tilde{\eta}_{n,k})}{\sum_{k'=1}^K \exp (\tilde{\eta}_{n,k'})}$となります。これはソフトマックス関数の計算になります。オーバーフローが起きる場合は、「ソフトマックス関数のオーバーフロー対策【ゼロつく1のノート(数学)】 - からっぽのしょこ」を参考にしてください。
更新したパラメータeta_nk[n, ]を用いて、$\boldsymbol{s}_n$を事後分布の期待値を計算します。カテゴリ分布の期待値(2.31)より
結果は次のようになります。
# 確認 E_s_nk[n, ]
## [1] 9.469019e-01 5.307886e-02 1.920381e-05
この処理をfor()ループで、$N$回繰り返すことで、全ての潜在変数の近似事後分布の期待値が得られます。
更新した$\mathbb{E}_{q(\mathbf{S})} [\mathbf{S}]$を用いて、$\boldsymbol{\lambda}$の近似事後分布と$\boldsymbol{\pi}$の近似事後分布のパラメータ$\hat{\mathbf{a}},\ \hat{\mathbf{b}},\ \hat{\boldsymbol{\alpha}}$を更新します。計算方法は初期値のときと同じです。
さらに、更新した$\hat{\mathbf{a}},\ \hat{\mathbf{b}},\ \hat{\boldsymbol{\alpha}}$を用いて、$\mathbb{E}_{q(\mathbf{S})} [\mathbf{S}]$を更新します。この処理を指定した回数繰り返します。
・推論結果の確認
・最後のパラメータの確認
超パラメータa_hat_kとb_hat_kの最後の更新値を用いて、$\boldsymbol{\lambda}$の近似事後分布を計算します。
# lambdaの近似事後分布をデータフレームに格納 posterior_lambda_df <- tibble() for(k in 1:K) { # クラスタkの事後分布を計算 tmp_posterior_df <- tibble( lambda = lambda_vec, density = dgamma(x = lambda, shape = a_hat_k[k], rate = b_hat_k[k]), cluster = as.factor(k) ) # 結果を結合 posterior_lambda_df <- rbind(posterior_lambda_df, tmp_posterior_df) } # lambdaの近似事後分布を作図 ggplot(posterior_lambda_df, aes(x = lambda, y = density, color = cluster)) + geom_line() + # 近似事後分布 geom_vline(xintercept = lambda_truth_k, color = "red", linetype = "dashed") + # 真の値 labs(title = "Gamma Distribution:Variational Inference", subtitle = paste0("iter:", MaxIter, ", N=", N, ", a=(", paste0(round(a_hat_k, 1), collapse = ", "), ")", ", b=(", paste0(round(b_hat_k, 1), collapse = ", "), ")"), x = expression(lambda))
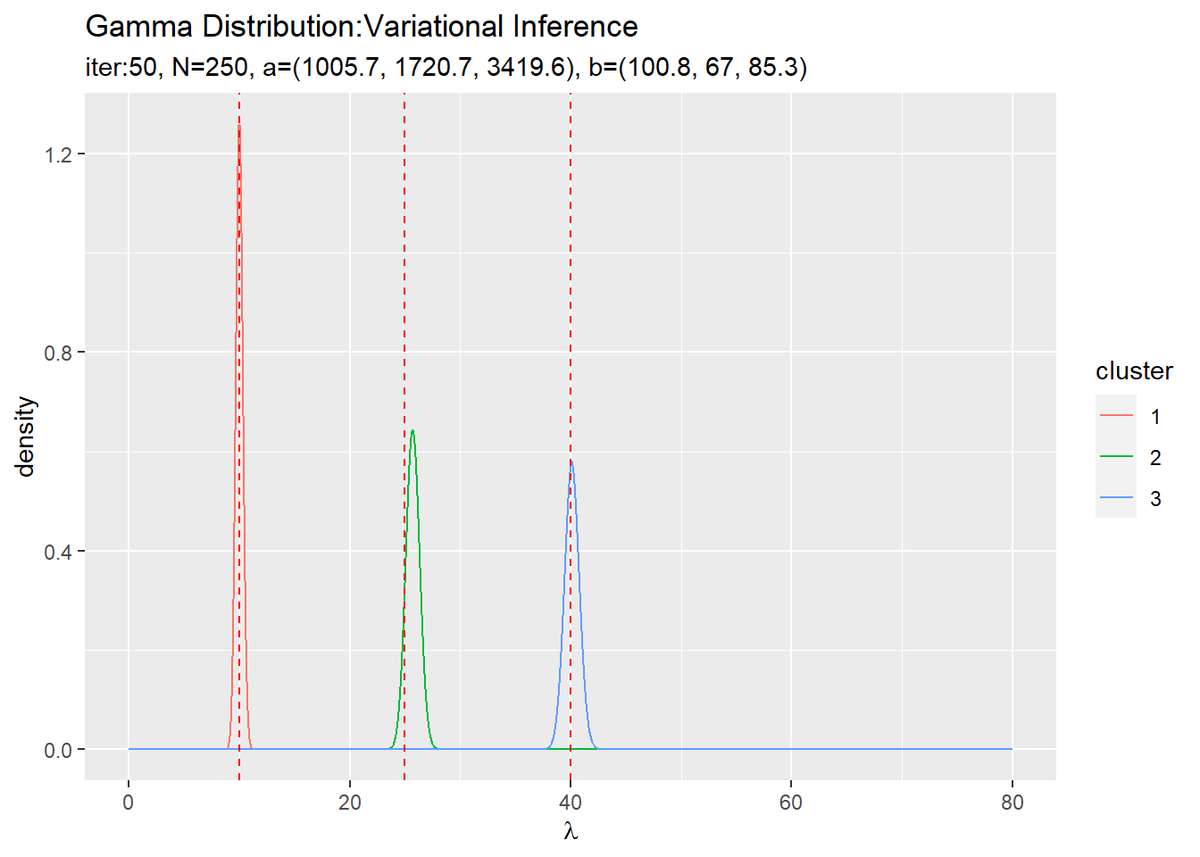
初期値の設定のときと同様にして作図します。
3つのガンマ分布がそれぞれ3つの真の値付近をピークとする分布を推定できています。
また、a_hat_k, b_hat_kとalpha_hat_kを用いて、混合分布を計算します。
# lambdaの平均値を計算:式(2.59) E_lambda_k <- a_hat_k / b_hat_k # piの平均値を計算:式(2.51) E_pi_k <- alpha_hat_k / sum(alpha_hat_k) # 最後の推定値による混合分布を計算 res_prob <- 0 for(k in 1:K) { # クラスタkの分布の確率を計算 tmp_prob <- dpois(x = x_vec, lambda = E_lambda_k[k]) # K個の分布の加重平均を計算 res_prob <- res_prob + E_pi_k[k] * tmp_prob } # 最後のサンプルによる分布をデータフレームに格納 res_df <- tibble( x = x_vec, prob = res_prob ) # 最後の推定値による分布を作図 ggplot() + geom_bar(data = res_df, aes(x = x, y = prob), stat = "identity", position = "dodge", fill = "purple", color = "purple") + # 最後の推定値による分布 geom_bar(data = model_df, aes(x = x, y = prob), stat = "identity", position = "dodge", alpha = 0, color = "red", linetype = "dashed") + # 真の分布 labs(title = "Poisson Mixture Model:Variational Inference", subtitle = paste0("iter:", MaxIter, ", N=", N, ", E[lambda]=(", paste0(round(E_lambda_k, 2), collapse = ", "), ")", ", E[pi]=(", paste0(round(E_pi_k, 2), collapse = ", "), ")"))
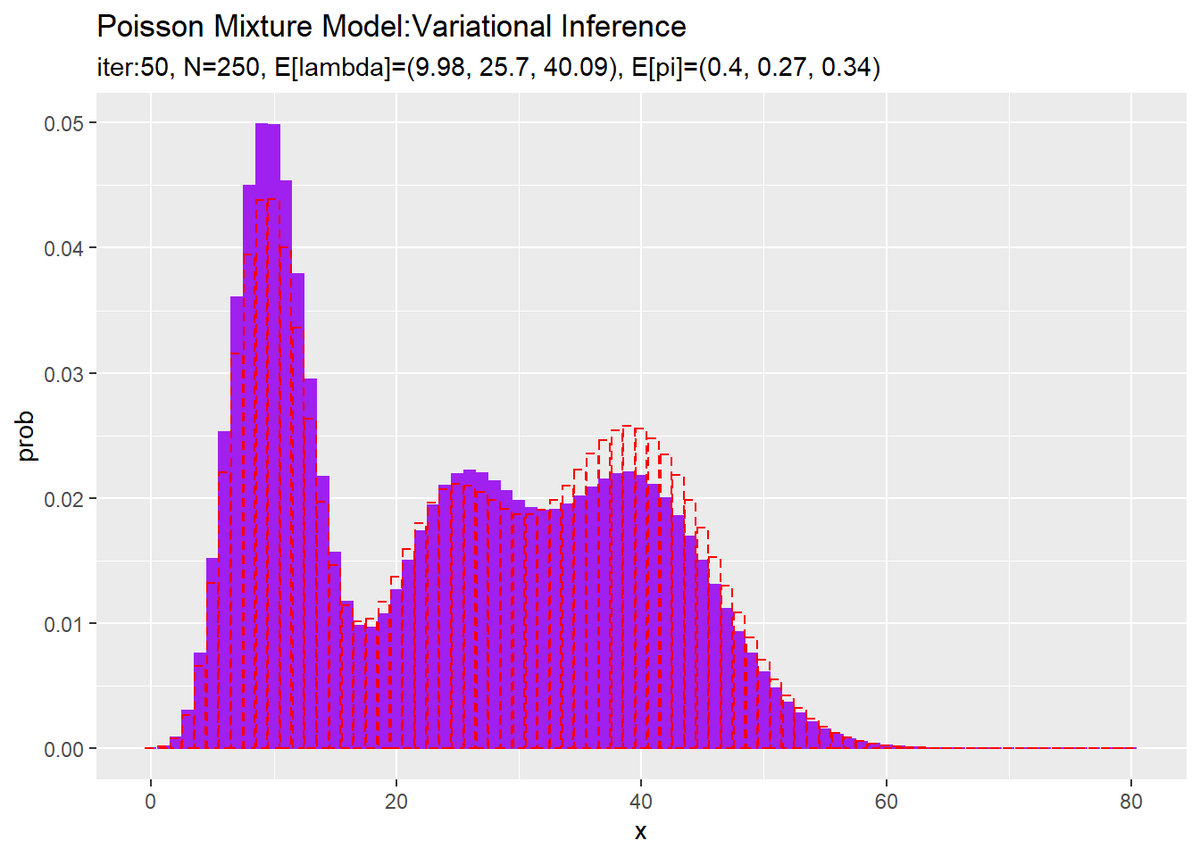
初期値の設定のときと同様にして作図します。
潜在変数の期待値E_s_nkの最後の更新値を用いて、クラスタのヒストグラムを作成します。作図用のデータフレームを作成します。
# 最後のクラスタをデータフレームに格納 cluster_df <- tibble( x = x_n, cluster = max.col(E_s_nk) %>% as.factor(), prob = E_s_nk[cbind(1:N, max.col(E_s_nk))] ) %>% dplyr::count(x, cluster, prob, name = "count")
max.col()を使って行ごとに確率が最大の列番号を抽出して、各データのクラスタ番号とします。また、その確率値も抽出します。
式(4.51)を見ると、観測データ$x_n$の値が同じであれば各クラスタとなる確率も同じ値になるのが分かります。よって、データの値(x列)、割り当てられたクラスタ番号(cluster列)、割り当てられたクラスタとなる確率(prob列)が同じ行数(データ数)をdplyr::count()で求めます。
作成したデータフレームは次のようになります。
# 確認 head(cluster_df)
## # A tibble: 6 x 4 ## x cluster prob count ## <int> <fct> <dbl> <int> ## 1 2 1 1.00 1 ## 2 4 1 1.00 2 ## 3 5 1 1.00 3 ## 4 6 1 1.00 5 ## 5 7 1 1.00 6 ## 6 8 1 1.00 12
確率が最大となったクラスタのヒストグラムを作成します。
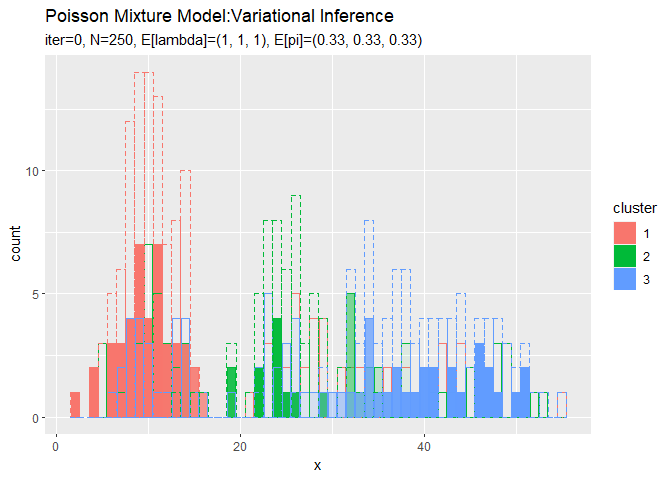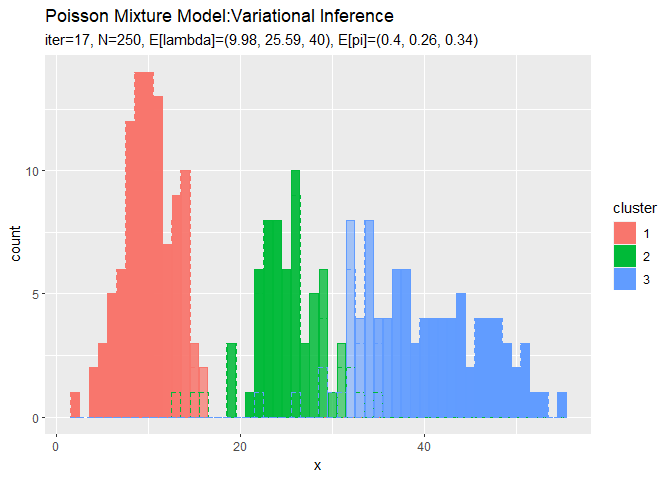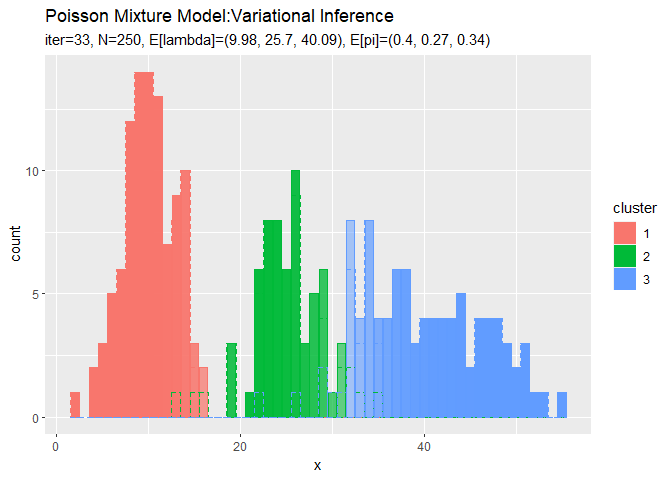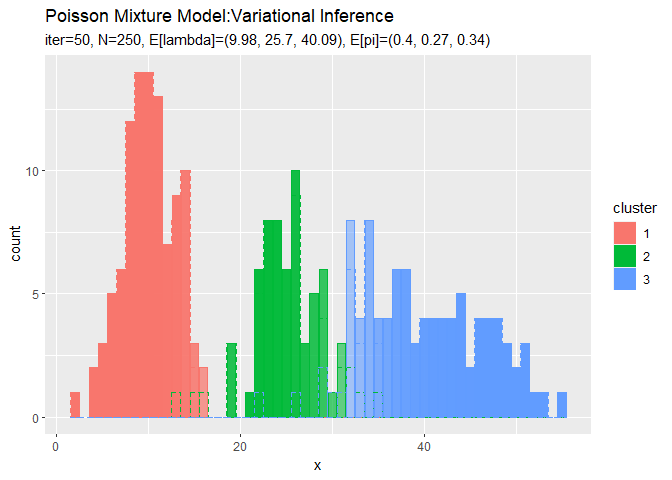
# 最後のクラスタのヒストグラムを作成 ggplot() + geom_bar(data = cluster_df, aes(x = x, y = count, fill = cluster, color = cluster), stat = "identity", position = "identity", alpha = cluster_df[["prob"]]) + # 最後のクラスタ geom_histogram(data = x_df, aes(x = x_n, color = cluster), binwidth = 1, position = "identity", alpha = 0, linetype = "dashed") + # 真のクラスタ labs(title = "Poisson Mixture Model:Variational Inference", subtitle = paste0("iter:", MaxIter, ", N=", N, ", E[lambda]=(", paste0(round(a_hat_k / b_hat_k, 2), collapse = ", "), ")", ", E[pi]=(", paste0(round(alpha_hat_k / sum(alpha_hat_k), 2), collapse = ", "), ")"), x = "x")
各データに割り当てられたクラスタとなる確率をgeom_bar()の引数alphaに指定することで、確率によって棒の色の濃淡を調整します。
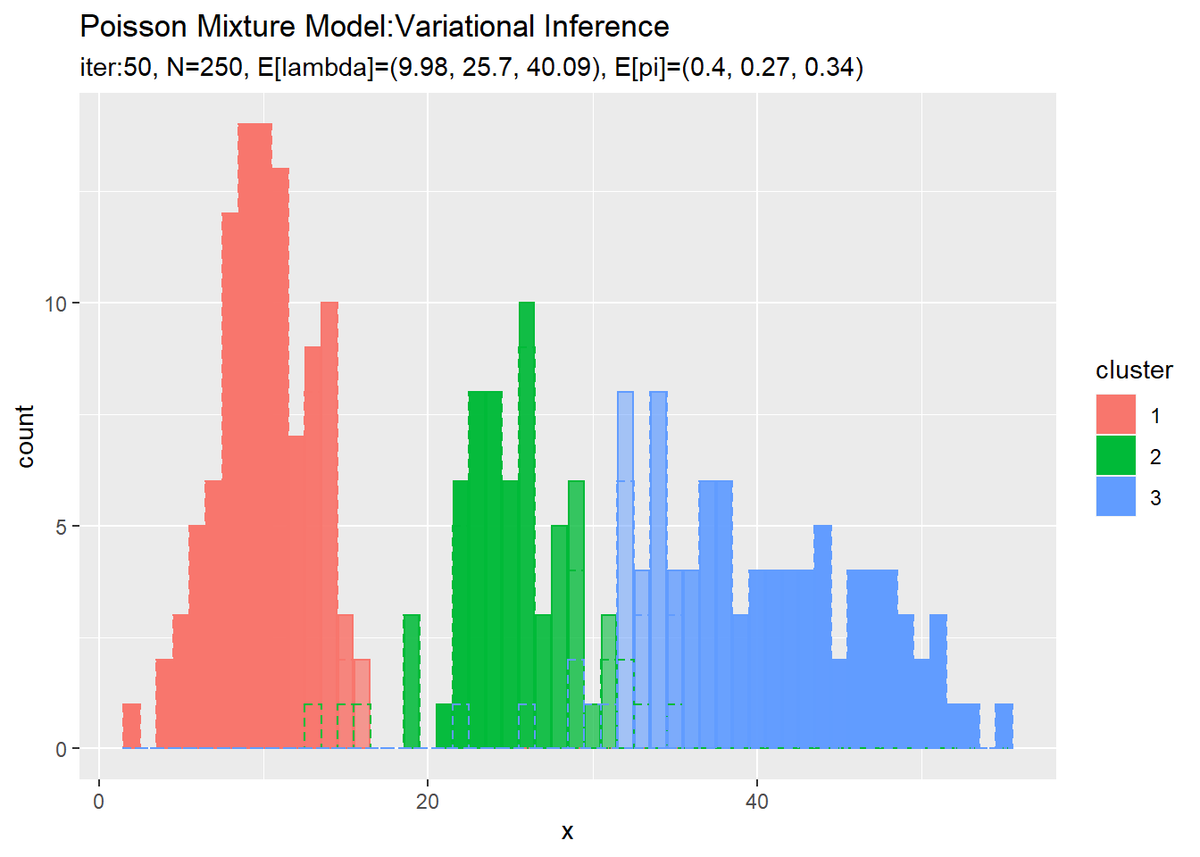
確率の最大値に従って全てのデータのクラスタを決めているので、棒(x軸の値)ごとに1つのクラスタになります。また、クラスタの境界付近のデータは、どちらのクラスタになるのか曖昧になるため色が薄くなる(確率が低くなる)のが分かります。
クラスタはランダムに決まるため、クラスタ番号は一致しません。
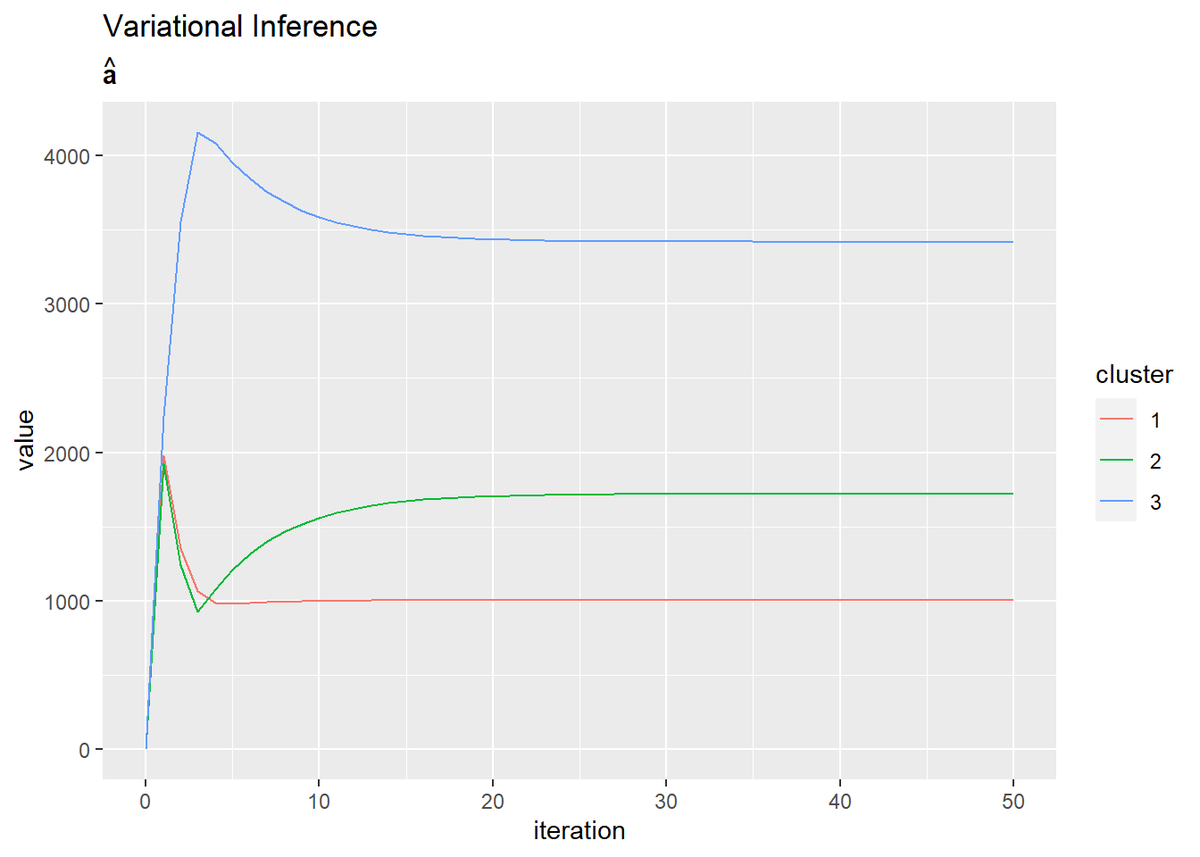
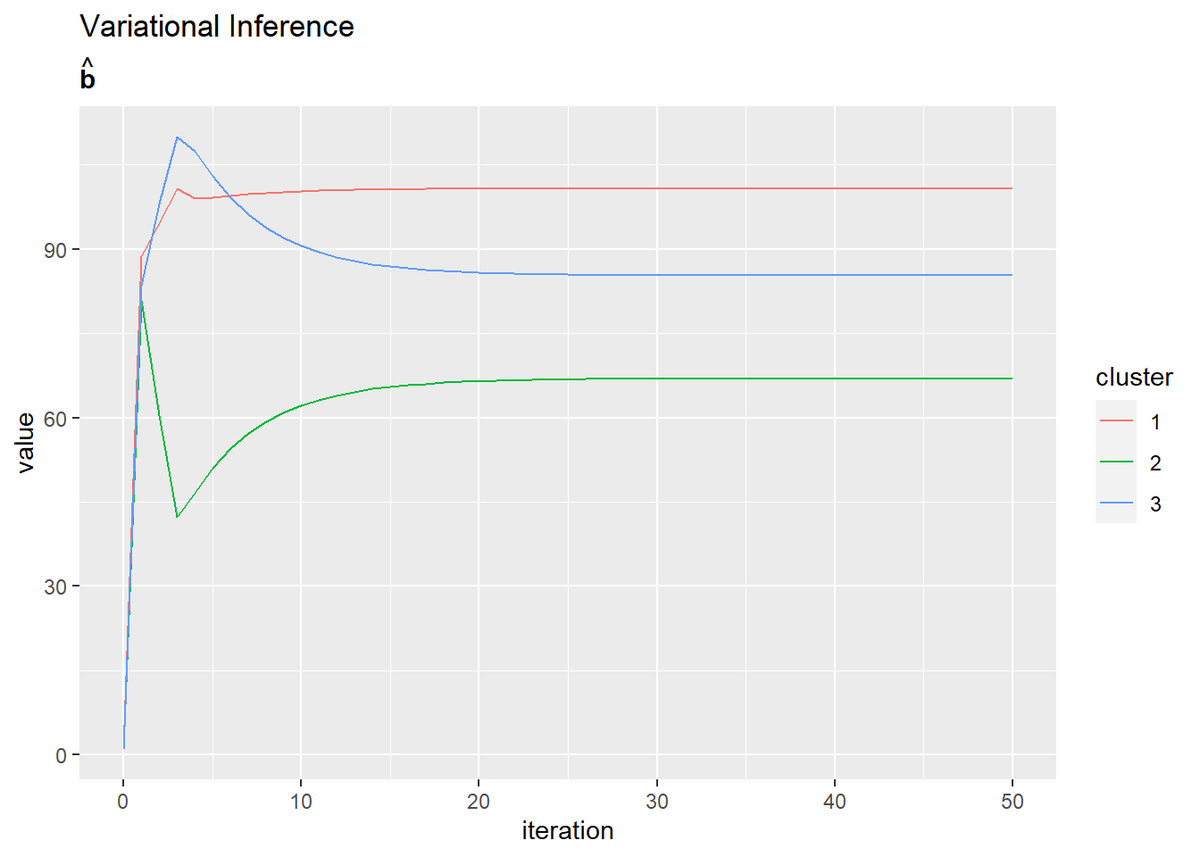
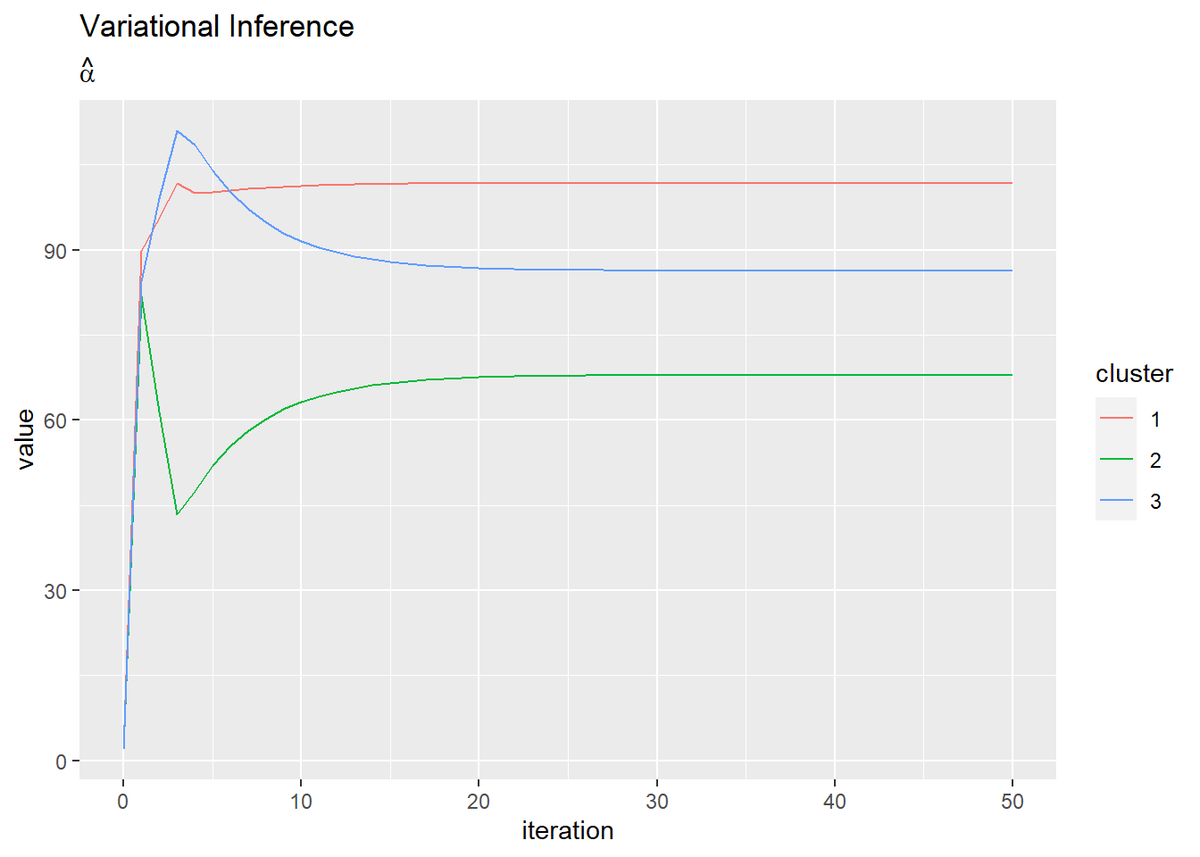
・超パラメータの推移の確認
超パラメータの更新値の推移を確認します。
・コード(クリックで展開)
各パラメータの学習ごとの値を格納したマトリクスtrace_***をtidyr::pivot_longer()で縦長のデータフレームに変換して作図します。
# aの推移をデータフレームに格納 trace_a_df <- dplyr::as_tibble(trace_a_ik) %>% # データフレームに変換 cbind(iteration = 0:MaxIter) %>% # 試行回数の列を追加 tidyr::pivot_longer( cols = -iteration, # 変換しない列 names_to = "cluster", # 現列名を格納する列名 names_prefix = "V", # 現列名の頭から取り除く文字列 names_ptypes = list(cluster = factor()), # 現列名を値とする際の型 values_to = "value" # 現セルを格納する列名 ) # 縦持ちに変換 # aの推移を作図 ggplot(trace_a_df, aes(x = iteration, y = value, color = cluster)) + geom_line() + labs(title = "Variational Inference", subtitle = expression(hat(bold(a))))
# bの推移をデータフレームに格納 trace_a_df <- dplyr::as_tibble(trace_b_ik) %>% # データフレームに変換 cbind(iteration = 0:MaxIter) %>% # 試行回数の列を追加 tidyr::pivot_longer( cols = -iteration, # 変換しない列 names_to = "cluster", # 現列名を格納する列名 names_prefix = "V", # 現列名の頭から取り除く文字列 names_ptypes = list(cluster = factor()), # 現列名を値とする際の型 values_to = "value" # 現セルを格納する列名 ) # 縦持ちに変換 # bの推移を作図 ggplot(trace_a_df, aes(x = iteration, y = value, color = cluster)) + geom_line() + labs(title = "Variational Inference", subtitle = expression(hat(bold(b))))
# alphaの推移を作図 trace_alpha_df <- dplyr::as_tibble(trace_alpha_ik) %>% # データフレームに変換 cbind(iteration = 0:MaxIter) %>% # 試行回数の列を追加 tidyr::pivot_longer( cols = -iteration, # 変換しない列 names_to = "cluster", # 現列名を格納する列名 names_prefix = "V", # 現列名の頭から取り除く文字列 names_ptypes = list(cluster = factor()), # 現列名を値とする際の型 values_to = "value" # 現セルを格納する列名 ) # 縦持ちに変換 # alphaの推移を作図 ggplot(trace_alpha_df, aes(x = iteration, y = value, color = cluster)) + geom_line() + labs(title = "Variational Inference", subtitle = expression(hat(alpha)))
・おまけ:アニメーションによる推移の確認
gganimateパッケージを利用して、各分布の推移のアニメーション(gif画像)を作成するためのコードです。
・コード(クリックで展開)
# 追加パッケージ library(gganimate)
・パラメータの近似事後分布の推移
作図用のデータフレームを作成します。
# 作図用のデータフレームを作成 trace_posterior_lambda_df <- tibble() for(i in 1:(MaxIter + 1)) { for(k in 1:K) { # クラスタkの近似事後分布を計算 tmp_posterior_df <- tibble( lambda = lambda_vec, density = dgamma(x = lambda, shape = trace_a_ik[i, k], rate = trace_b_ik[i, k]), cluster = as.factor(k), label = paste0( "iter:", i - 1, ", N=", N, ", a=(", paste0(round(trace_a_ik[i, ], 1), collapse = ", "), ")", ", b=(", paste0(round(trace_b_ik[i, ], 1), collapse = ", "), ")" ) %>% as.factor() ) # 結果を結合 trace_posterior_lambda_df <- rbind(trace_posterior_lambda_df, tmp_posterior_df) } # 動作確認 #print(paste0((i - 1), ' (', round((i - 1) / MaxIter * 100, 1), '%)')) }
各試行における計算結果を同じデータフレームに格納していく必要があります。
分布の推移をgif画像で出力します。
# lambdaの近似事後分布を作図 trace_graph <- ggplot() + geom_line(data = trace_posterior_lambda_df, aes(x = lambda, y = density, color = cluster)) + # 近似事後分布 geom_vline(xintercept = lambda_truth_k, color = "red", linetype = "dashed") + # 真の値 gganimate::transition_manual(label) + # フレーム labs(title = "Gamma Distribution:Variational Inference", subtitle = "{current_frame}", x = expression(lambda)) # gif画像を作成 gganimate::animate(trace_graph, nframes = MaxIter + 1, fps = 10)
各フレームの順番を示す列をgganimate::transition_manual()に指定します。初期値を含むため、フレーム数はMaxIter + 1です。
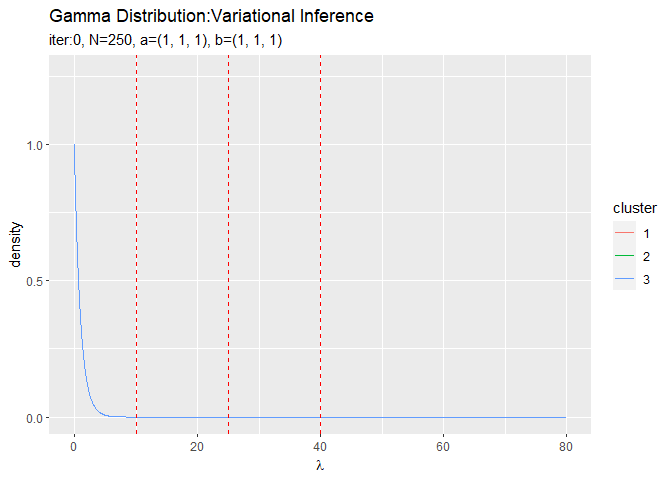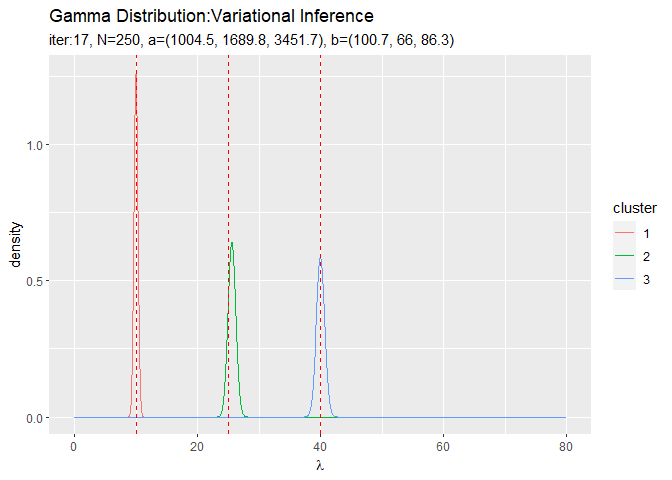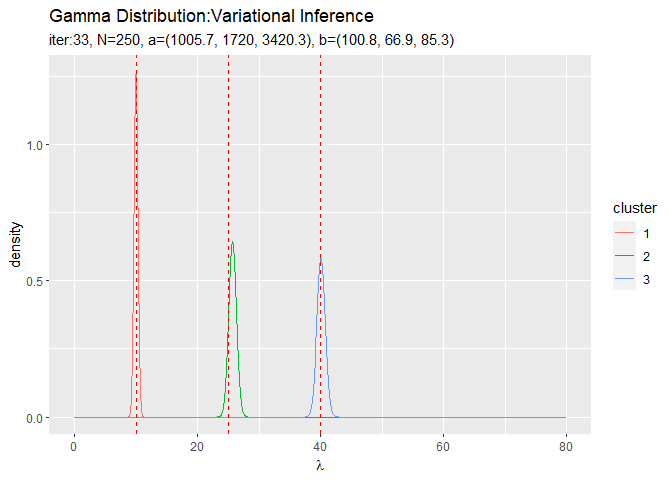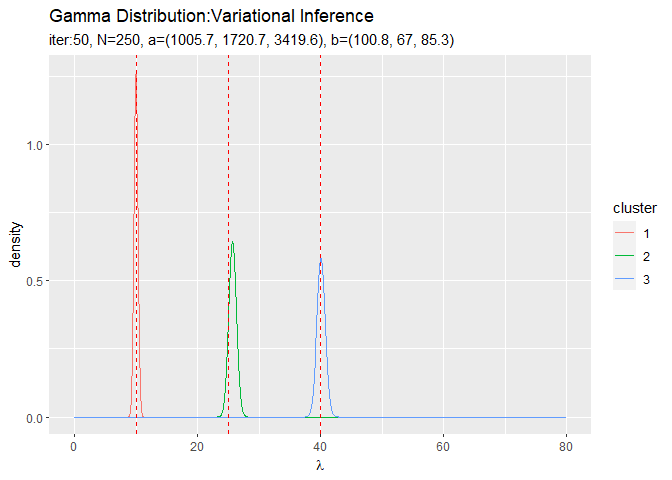
・パラメータの期待値の推移
・コード(クリックで展開)
作図用のデータフレームを作成します。
# 作図用のデータフレームを作成 trace_model_df <- tibble() trace_cluster_df <- tibble() for(i in 1:(MaxIter + 1)) { # lambdaの平均値を計算:式(2.59) E_lambda_k <- trace_a_ik[i, ] / trace_b_ik[i, ] # piの平均値を計算:式(2.51) E_pi_k <- trace_alpha_ik[i, ] / sum(trace_alpha_ik[i, ]) # i回目の混合分布を計算 res_prob <- 0 for(k in 1:K) { # クラスタkの分布の確率を計算 tmp_prob <- dpois(x = x_vec, lambda = E_lambda_k[k]) # K個の分布の加重平均を計算 res_prob <- res_prob + E_pi_k[k] * tmp_prob } # i回目のサンプルによる分布をデータフレームに格納 res_df <- tibble( x = x_vec, prob = res_prob, label = paste0( "iter:", i - 1, ", N=", N, ", E[lambda]=(", paste0(round(E_lambda_k, 2), collapse = ", "), ")", ", E[pi]=(", paste0(round(E_pi_k, 2), collapse = ", "), ")" ) %>% as.factor() ) # i回目のクラスタをデータフレームに格納 cluster_df <- tibble( x = x_n, cluster = max.col(trace_E_s_ink[i, , ]) %>% as.factor(), prob = E_s_nk[cbind(1:N, max.col(trace_E_s_ink[i, , ]))], label = paste0( "iter=", i - 1, ", N=", N, ", E[lambda]=(", paste0(round(E_lambda_k, 2), collapse = ", "), ")", ", E[pi]=(", paste0(round(E_pi_k, 2), collapse = ", "), ")" ) %>% as.factor() ) %>% dplyr::count(x, cluster, prob, label, name = "count") # i回目の結果を結合 trace_model_df <- rbind(trace_model_df, res_df) trace_cluster_df <- rbind(trace_cluster_df, cluster_df) # 動作確認 #print(paste0((i - 1), ' (', round((i - 1) / MaxIter * 100, 1), '%)')) }
・パラメータの期待値による分布の推移
# アニメーション用に複製 rep_model_df <- tibble( x = rep(model_df[["x"]], times = MaxIter + 1), prob = rep(model_df[["prob"]], times = MaxIter + 1), label = trace_model_df[["label"]] ) # 分布の推移を作図 trace_graph <- ggplot() + geom_bar(data = trace_model_df, aes(x = x, y = prob), stat = "identity", fill = "purple") + # 推定した分布 geom_bar(data = rep_model_df, aes(x = x, y = prob), stat = "identity", alpha = 0, color = "red", linetype = "dashed") + # 真の分布 gganimate::transition_manual(label) + # フレーム ylim(c(0, 0.1)) + labs(title = "Poisson Mixture Model:Variational Inference", subtitle = "{current_frame}") # gif画像を作成 gganimate::animate(trace_graph, nframes = MaxIter + 1, fps = 10)
・クラスタの近似事後分布の期待値によるヒストグラムの推移
# アニメーション用に複製 rep_x_df <- tibble( x_n = rep(x_n, times = MaxIter + 1), cluster = rep(as.factor(s_truth_n), times = MaxIter + 1), label = unique(trace_cluster_df[["label"]]) %>% rep(each = N) ) # クラスタの推移を作図 trace_graph <- ggplot() + geom_bar(data = trace_cluster_df, aes(x = x, y = count, color = cluster, fill = cluster), stat = "identity", position = "identity", alpha = trace_cluster_df[["prob"]]) + # 推定したクラスタ geom_histogram(data = rep_x_df, aes(x = x_n, color = cluster), binwidth = 1, position = "identity", alpha = 0, linetype = "dashed") + # 真のクラスタ gganimate::transition_manual(label) + # フレーム labs(title = "Poisson Mixture Model:Variational Inference", subtitle = "{current_frame}", x = "x") # gif画像を作成 gganimate::animate(trace_graph, nframes = MaxIter + 1, fps = 10)
(記事作成時に、最初にtrace_a_ikとtrace_b_ikに記録する値をミスってました。事後分布のパラメータの初期値ではなく事前分布のパラメータを入れてました。なのでiter:0のグラフが事前分布になってます。記事中のコードは修正しましたが、画像の差し替えは非常に手間なのでミスったままです。)
参考文献
- 須山敦志『ベイズ推論による機械学習入門』(機械学習スタートアップシリーズ)杉山将監修,講談社,2017年.
おわりに
○○の△△の◇◇の、みたいな説明が多すぎる。「あるデータがどのクラスタになるかは、確率が最大のものにする。その確率の値。」を一文で説明したかった。ムリだった。
【次節の内容】
- 2021/05/08:加筆修正しました。その際に数式読解編と記事を分割しました。