はじめに
機械学習で登場する確率分布について色々な角度から理解したいシリーズです。
この記事では、R言語でベータ分布の乱数を生成します。
【前の内容】
【他の記事一覧】
【この記事の内容】
ベータ分布の乱数生成
ベータ分布(Beta Distribution)の乱数を生成します。ベータ分布については「1.2.3:ベータ分布【『トピックモデル』の勉強ノート】 - からっぽのしょこ」を参照してください。
利用するパッケージを読み込みます。
# 利用するパッケージ library(tidyverse) library(gganimate)
この記事では、基本的にパッケージ名::関数名()の記法を使うので、パッケージを読み込む必要はありません。ただし、作図コードがごちゃごちゃしないようにパッケージ名を省略しているため、ggplot2は読み込む必要があります。また、基本的にベースパイプ(ネイティブパイプ)演算子|>を使いますが、パイプ演算子%>%ででないと処理できない部分があるため、magrittrも読み込む必要があります。
分布の変化をアニメーション(gif画像)で確認するのにgganimateパッケージを利用します。不要であれば省略してください。
サンプリング
ベータ分布の乱数を生成します。
ベータ分布のパラメータ$\alpha, \beta$とデータ数$N$を設定します。
# パラメータを指定 alpha <- 5 beta <- 2 # データ数(サンプルサイズ)を指定 N <- 1000
$\alpha > 0, \beta > 0$とデータ数(サンプルサイズ)$N$を指定します。
ベータ分布に従う乱数を生成します。
# ベータ分布に従う乱数を生成 phi_n <- rbeta(n = N, shape1 = alpha, shape2 = beta) head(phi_n)
## [1] 0.5639846 0.7676211 0.5163029 0.6619760 0.8350099 0.8554610
ベータ分布の乱数は、rbeta()で生成できます。データ数(サンプルサイズ)の引数nにN、パラメータの引数shape1, shape2にalpha, betaを指定します。
乱数の可視化
サンプルのヒストグラムを作成します。
# サンプルを格納 data_df <- tidyr::tibble(phi = phi_n) # サンプルのヒストグラムを作成:度数 ggplot(data = data_df, mapping = aes(x = phi)) + # データ geom_histogram(fill = "#00A968", bins = 30) + # 度数 labs(title = "Beta Distribution", subtitle = paste0("alpha=", alpha, ", beta=", beta, ", N=", N), # (文字列表記用) #subtitle = parse(text = paste0("list(alpha==", alpha, ", beta==", beta, ", N==", N, ")")), # (数式表記用) x = expression(phi), y = "frequency") # ラベル
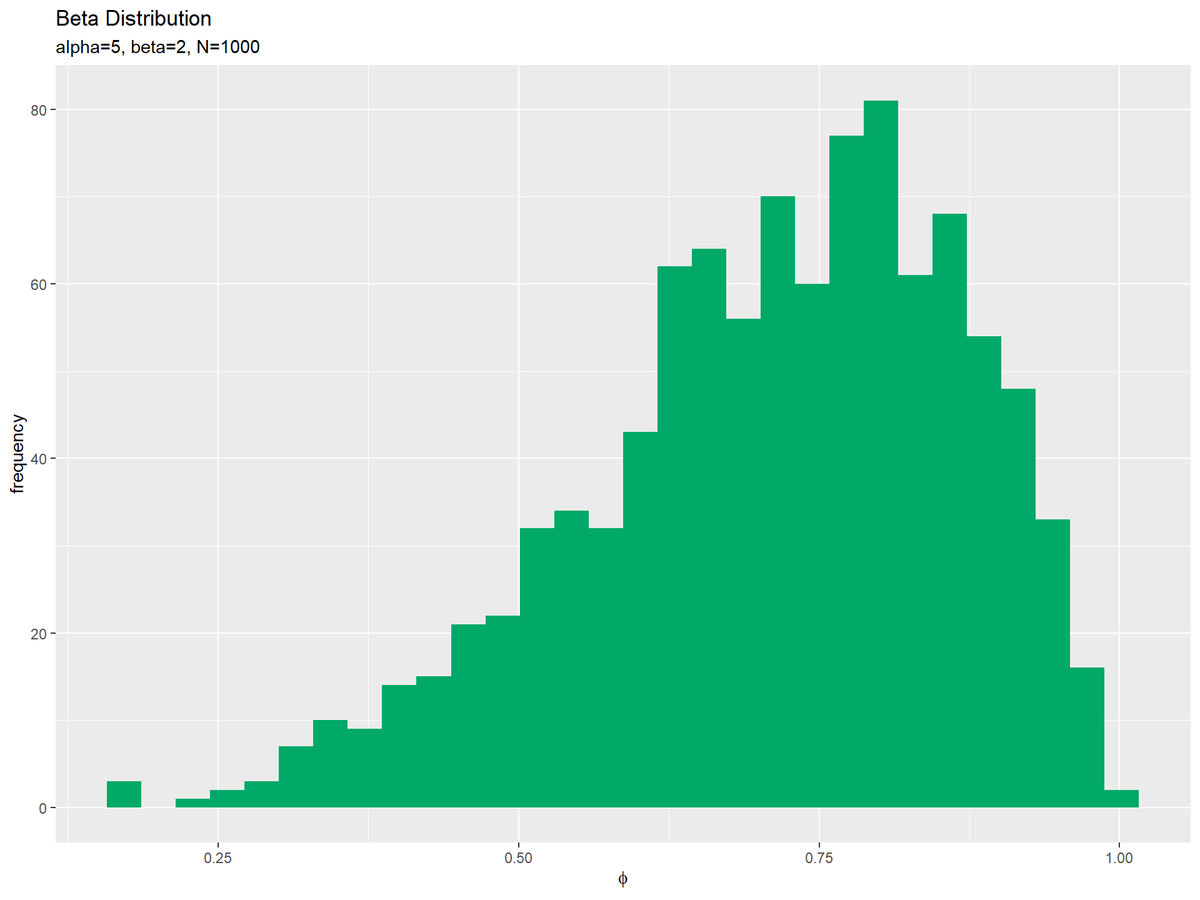
サンプルをデータフレームに格納して、geom_histgram()でヒストグラムを描画します。バーの数の引数binsまたはバーのサイズの引数binwidthを指定します。
ギリシャ文字などの記号を使った数式を表示する場合は、expression()の記法を使います。等号は"=="、複数の(数式上の)変数を並べるには"list(変数1, 変数2)"とします。(プログラム上の)変数の値を使う場合は、parse()のtext引数に指定します。
サンプルの密度を確率分布と重ねて描画します。
# phiのとり得る値を作成 phi_vals <- seq(from = 0, to = 1, length.out = 501) # ベータ分布を計算 dens_df <- tidyr::tibble( phi = phi_vals, # x軸の値 dens = dbeta(x = phi_vals, shape1 = alpha, shape2 = beta) # 確率密度 ) # サンプルのヒストグラムを作成:密度 ggplot() + geom_histogram(data = data_df, mapping = aes(x = phi, y = ..density..), fill = "#00A968", bins = 30) + # 密度 geom_line(data = dens_df, mapping = aes(x = phi, y = dens), color = "darkgreen", size = 1,linetype = "dashed") + # 元の分布 labs(title = "Beta Distribution", subtitle = parse(text = paste0("list(alpha==", alpha, ", beta==", beta, ", N==", N, ")")), x = expression(phi), y = "density") # ラベル
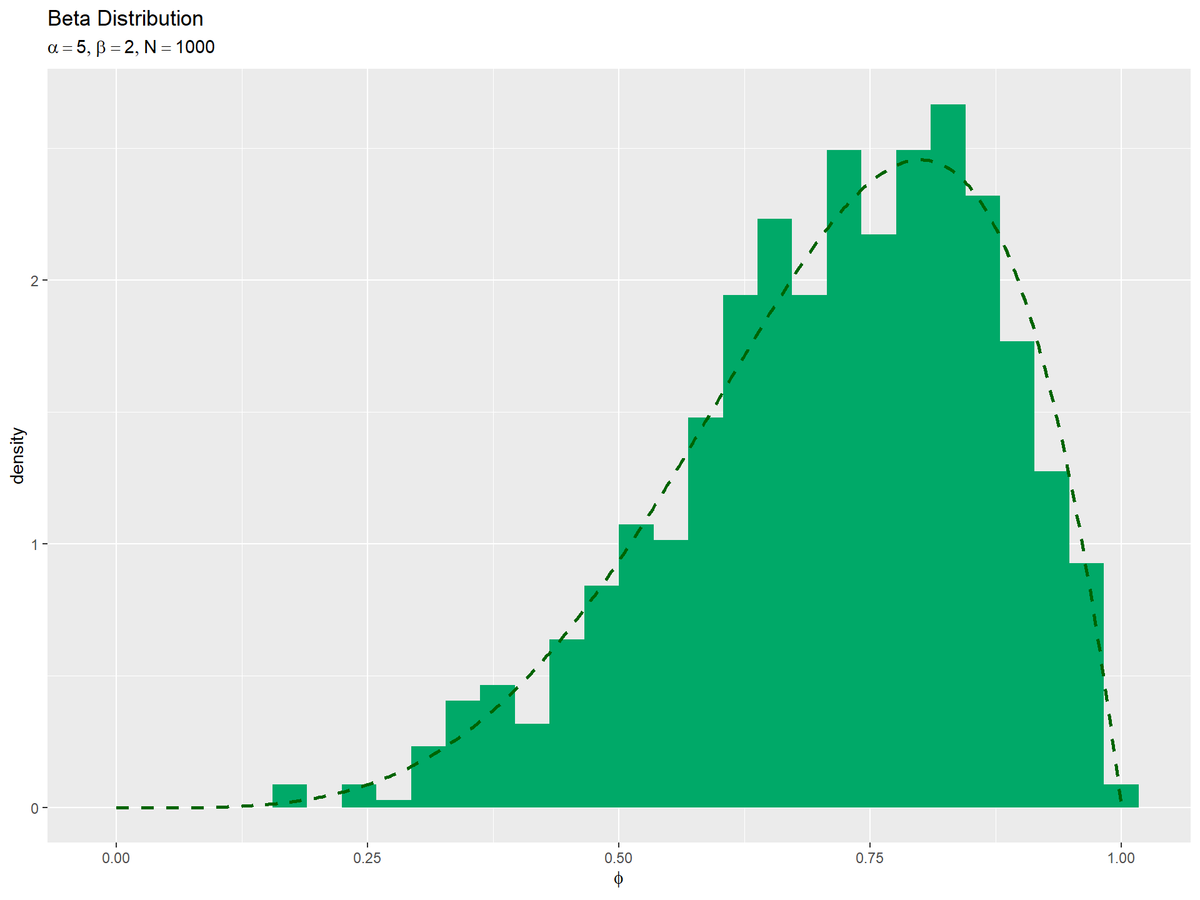
geom_histogram()のy軸の引数yに..density..を指定すると、密度に変換したヒストグラムを描画します。
データ数(サンプルサイズ)が十分に増えると、ヒストグラムの形が分布の形に近付きます。
乱数と分布の関係をアニメーションで可視化
サンプルサイズとヒストグラムの形状の関係をアニメーションで確認します。
・作図コード(クリックで展開)
パラメータ$\alpha, \beta$とデータ数$N$を指定して、ベータ分布の乱数を生成します。
# パラメータを指定 alpha <- 5 beta <- 2 # データ数(フレーム数)を指定 N <- 300 # ベータ分布に従う乱数を生成 phi_n <- rbeta(n = N, shape1 = alpha, shape2 = beta) head(phi_n)
## [1] 0.7258288 0.3209897 0.4716758 0.7977496 0.7508228 0.8733358
phi_nのn番目の要素を、n回目にサンプリングされた値とみなします。アニメーションのn番目のフレームでは、n個のサンプルphi_n[1:n]のヒストグラムを描画します。
サンプリング回数ごとに、それまでのサンプルを持つデータフレームを作成します。
# サンプルを複製して格納 anime_freq_df <- tibble::tibble( phi = rep(phi_n, times = N), # サンプル n = rep(1:N, times = N), # データ番号 frame = rep(1:N, each = N) # フレーム番号 ) |> dplyr::filter(n <= frame) |> # サンプリング回数以前のサンプルを抽出 dplyr::mutate( parameter = paste0("alpha=", alpha, ", beta=", beta, ", N=", frame) |> factor(levels = paste0("alpha=", alpha, ", beta=", beta, ", N=", 1:N)) ) # フレーム切替用ラベルを追加 anime_freq_df
## # A tibble: 45,150 × 4 ## phi n frame parameter ## <dbl> <int> <int> <fct> ## 1 0.726 1 1 alpha=5, beta=2, N=1 ## 2 0.726 1 2 alpha=5, beta=2, N=2 ## 3 0.321 2 2 alpha=5, beta=2, N=2 ## 4 0.726 1 3 alpha=5, beta=2, N=3 ## 5 0.321 2 3 alpha=5, beta=2, N=3 ## 6 0.472 3 3 alpha=5, beta=2, N=3 ## 7 0.726 1 4 alpha=5, beta=2, N=4 ## 8 0.321 2 4 alpha=5, beta=2, N=4 ## 9 0.472 3 4 alpha=5, beta=2, N=4 ## 10 0.798 4 4 alpha=5, beta=2, N=4 ## # … with 45,140 more rows
データ番号(n列)は1からNの整数がN回繰り返すように、フレーム番号(frame列)は1からNの整数がN個ずつ並ぶように作成します。サンプルはデータ番号に対応するように複製します。
フレーム番号ごとに、それ以下の番号のサンプルをfilter()で抽出します。
フレーム番号をデータ番号として、フレーム切替用のラベル列を作成します。これにより、各フレーム(サンプリング回数)ごとにそれ以前のサンプルを使ってグラフを作成できます。ラベルが文字列型だと文字列の基準で順序が決まるので、因子型にしてサンプリング回数に応じたレベル(順序)を設定します。
このデータフレームは、ヒストグラムを描画するのに使います。
サンプルと対応するラベルをデータフレームに格納します。
# サンプルを格納 anime_data_df <- tidyr::tibble( phi = phi_n, parameter = paste0("alpha=", alpha, ", beta=", beta, ", N=", 1:N) |> factor(levels = paste0("alpha=", alpha, ", beta=", beta, ", N=", 1:N)) # フレーム切替用ラベル ) anime_data_df
## # A tibble: 300 × 2 ## phi parameter ## <dbl> <fct> ## 1 0.726 alpha=5, beta=2, N=1 ## 2 0.321 alpha=5, beta=2, N=2 ## 3 0.472 alpha=5, beta=2, N=3 ## 4 0.798 alpha=5, beta=2, N=4 ## 5 0.751 alpha=5, beta=2, N=5 ## 6 0.873 alpha=5, beta=2, N=6 ## 7 0.925 alpha=5, beta=2, N=7 ## 8 0.546 alpha=5, beta=2, N=8 ## 9 0.633 alpha=5, beta=2, N=9 ## 10 0.855 alpha=5, beta=2, N=10 ## # … with 290 more rows
このデータフレームは、各サンプリングにおけるサンプルの値を描画するのに使います。
サンプルのヒストグラムのアニメーション(gif画像)を作成します。
# サンプルのヒストグラムを作成:度数 anime_freq_graph <- ggplot() + geom_histogram(data = anime_freq_df, mapping = aes(x = phi), breaks = seq(from = 0, to = 1, length.out = 30), fill = "#00A968") + # 度数 geom_point(data = anime_data_df, mapping = aes(x = phi, y = 0), color = "orange", size = 6) + # gganimate::transition_manual(parameter) + # フレーム labs(title = "Beta Distribution", subtitle = "{current_frame}", x = expression(phi), y = "frequency") # ラベル # gif画像を作成 gganimate::animate(anime_freq_graph, nframes = N, fps = 10, width = 800, height = 600)
集計範囲を固定するために、geom_histogram()のbreaks引数に区切り位置を指定します。この例では、seq()を使って0から1の範囲を30等分しています。
transition_manual()にフレームの順序を表す列を指定します。この例では、因子型のラベルのレベルの順に描画されます。
animate()のフレーム数の引数nframesにデータ数(サンプルサイズ)、フレームレートの引数fpsに1秒当たりのフレーム数を指定します。fps引数の値が大きいほどフレームが早く切り替わります。
サンプルの密度を確率分布と重ねたアニメーションを作成します。
# phiのとり得る値を作成 phi_vals <- seq(from = 0, to = 1, length.out = 501) # ベータ分布を計算 dens_df <- tidyr::tibble( phi = phi_vals, # x軸の値 density = dbeta(x = phi_vals, shape1 = alpha, shape2 = beta) # 確率密度 ) # サンプルのヒストグラムを作成:密度 anime_freq_graph <- ggplot() + geom_histogram(data = anime_freq_df, mapping = aes(x = phi, y = ..density..), breaks = seq(from = 0, to = 1, length.out = 30), fill = "#00A968") + # 度数 geom_line(data = dens_df, mapping = aes(x = phi, y = density), color = "darkgreen", size = 1, linetype = "dashed") + # 元の分布 geom_point(data = anime_data_df, mapping = aes(x = phi, y = 0), color = "orange", size = 6) + # gganimate::transition_manual(parameter) + # フレーム coord_cartesian(ylim = c(0, 5)) + # 軸の表示範囲 labs(title = "Beta Distribution", subtitle = "{current_frame}", x = expression(phi), y = "density") # ラベル # gif画像を作成 gganimate::animate(anime_freq_graph, nframes = N, fps = 10, width = 800, height = 600)
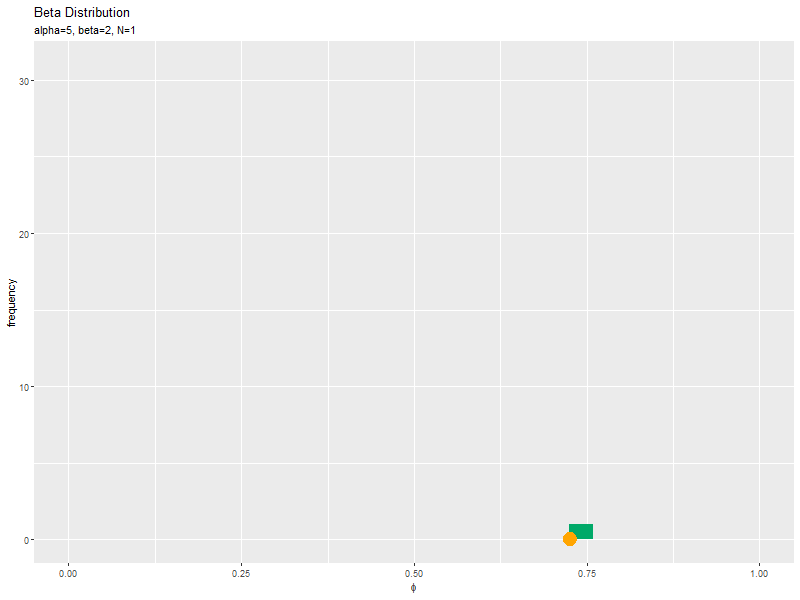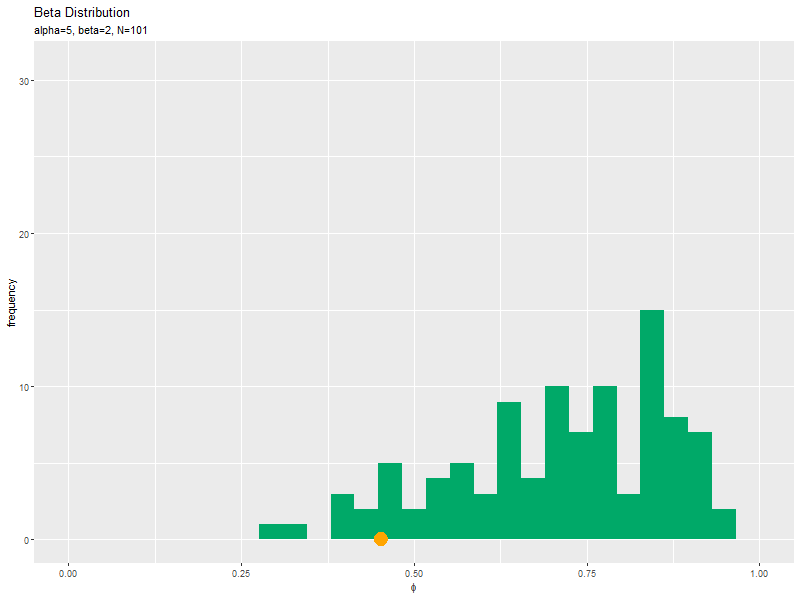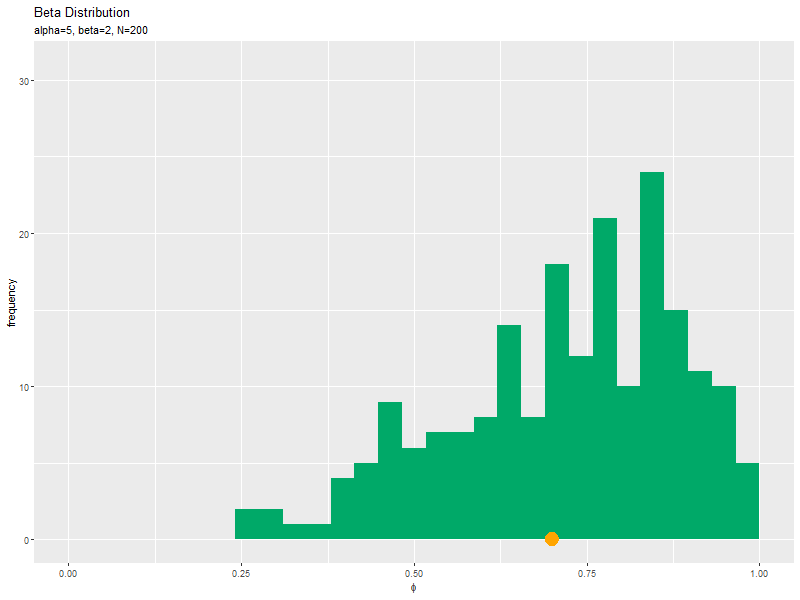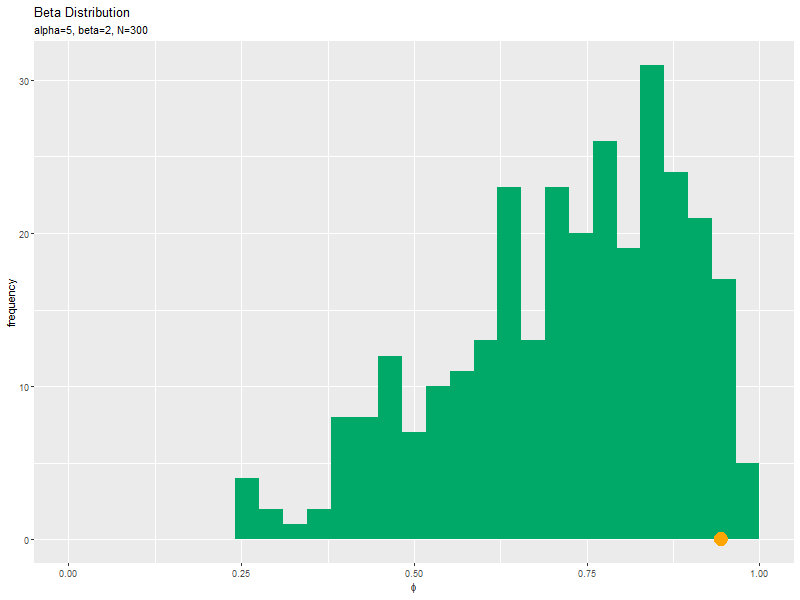
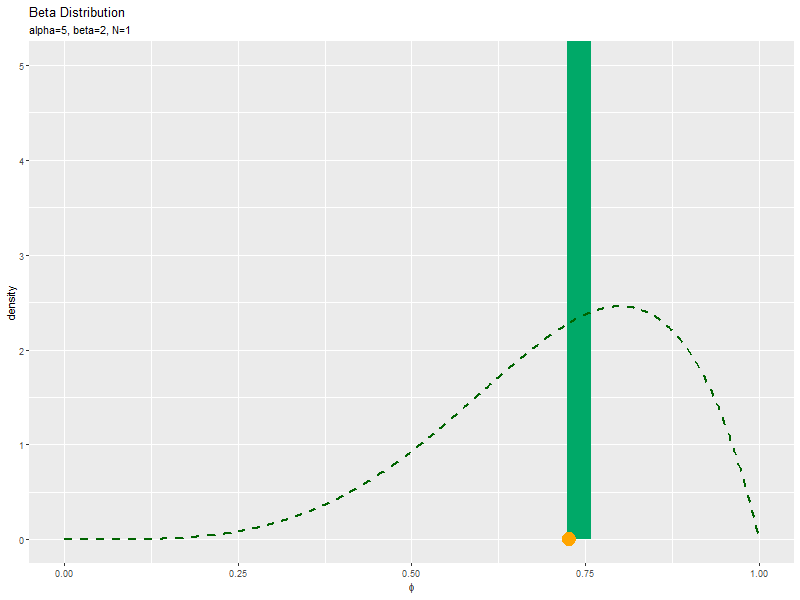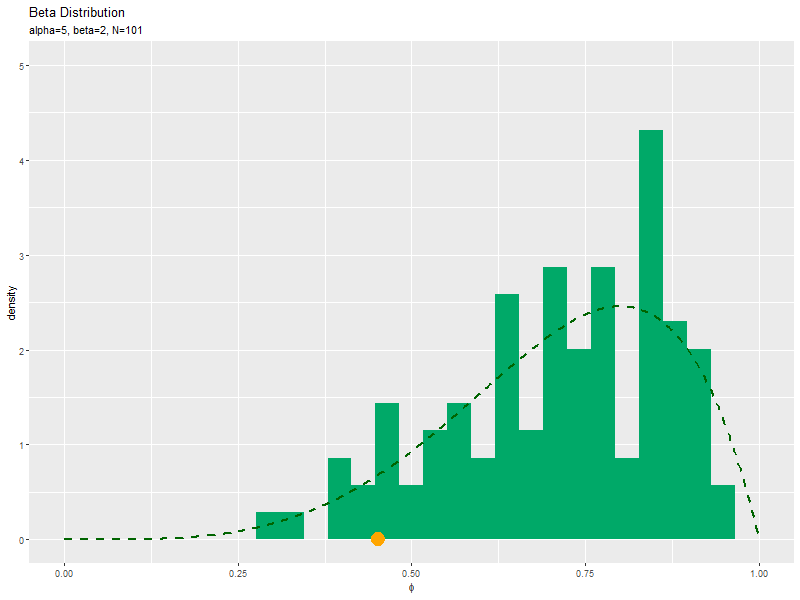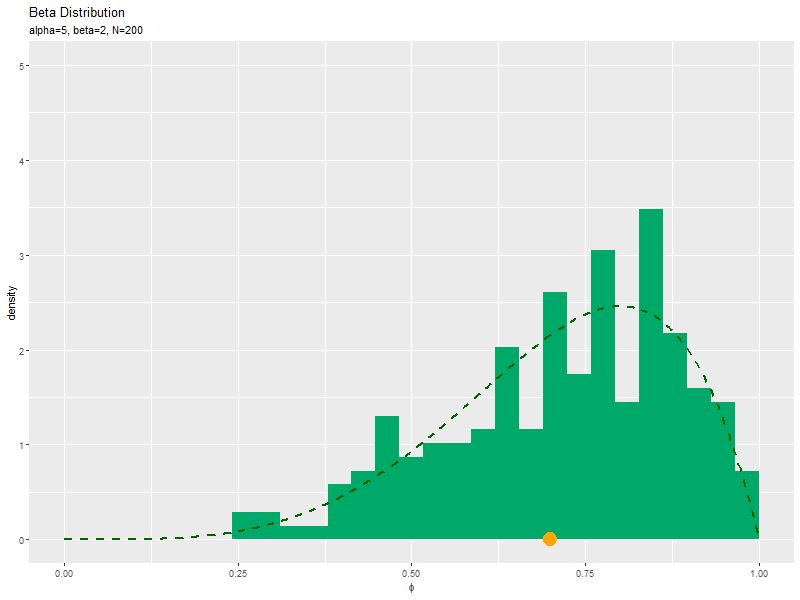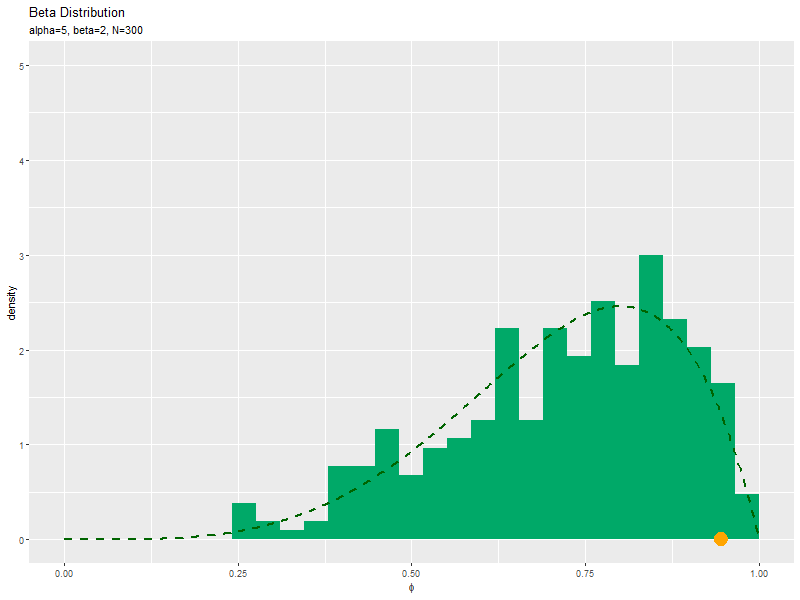
サンプルが増えるに従って、ヒストグラムが元の分布に近付くのを確認できます。
この記事では、ベータ分布の乱数生成を確認しました。次は、ベータ分布から確率分布を生成します。
参考文献
- 岩田具治『トピックモデル』(機械学習プロフェッショナルシリーズ)講談社,2015年.
おわりに
随分前にコードを書き始めたのですが、放置したり追加したりでようやくブログまで辿り着けました。
【次の内容】