はじめに
ハロー!プロジェクトの歴史を可視化しようシリーズです。
この記事では、ハロプログループの歴代メンバーの活動期間をタイムラインにします。
【他の記事】
【目次】
メンバーの活動期間の可視化
ハロー!プロジェクトのグループの歴代メンバーの活動期間をタイムラインチャートで可視化します。
次のパッケージを利用します。
# 利用パッケージ library(tidyverse) library(lubridate) library(gganimate)
この記事では、基本的にパッケージ名::関数名()の記法を使うので、パッケージを読み込む必要はありません。ただし、作図コードがごちゃごちゃしないようにパッケージ名を省略しているため、ggplot2は読み込む必要があります。
magrittrパッケージのパイプ演算子%>%ではなく、ベースパイプ(ネイティブパイプ)演算子|>を使っています。%>%に置き換えても処理できます。
データの読込
次のページのデータを利用します。
GitHub上のcsvデータをRから読み込めたらよかったのですがやり方が分からなかったので、ダウンロードしてローカルフォルダに保存しておきます。
保存先のフォルダパスを指定します。
# フォルダパスを指定 dir_path <- "data/HP_DB-main/"
ファイルの読み込み時にファイル名を結合する(ファイルパスにする)ので、末尾を/にしておきます。
グループの情報を読み込みます。
# グループ一覧を読み込み group_df <- readr::read_csv( file = paste0(dir_path, "group.csv"), col_types = readr::cols( groupID = "i", groupName = "c", formDate = readr::col_date(format = "%Y/%m/%d"), dissolveDate = readr::col_date(format = "%Y/%m/%d"), isUnit = "l" ) ) |> dplyr::arrange(groupID, formDate) # 昇順に並べ替え group_df
## # A tibble: 60 × 5 ## groupID groupName formDate dissolveDate isUnit ## <int> <chr> <date> <date> <lgl> ## 1 1 モーニング娘。 1997-09-14 2013-12-31 FALSE ## 2 1 モーニング娘。 '14 2014-01-01 2014-12-31 FALSE ## 3 1 モーニング娘。 '15 2015-01-01 2015-12-31 FALSE ## 4 1 モーニング娘。 '16 2016-01-01 2016-12-31 FALSE ## 5 1 モーニング娘。 '17 2017-01-01 2017-12-31 FALSE ## 6 1 モーニング娘。 '18 2018-01-01 2018-12-31 FALSE ## 7 1 モーニング娘。 '19 2019-01-01 2019-12-31 FALSE ## 8 1 モーニング娘。 '20 2020-01-01 2020-12-31 FALSE ## 9 1 モーニング娘。 '21 2021-01-01 2021-12-31 FALSE ## 10 1 モーニング娘。 '22 2022-01-01 NA FALSE ## # … with 50 more rows
group.csvは、グループID・グループ名・結成日・解散日・ユニットかどうかの5列のcsvファイルです。改名グループであれば結成日・解散日は改名日を表し、現在活動中であれば解散日が欠損値になります。
例えば、「モーニング娘。とモーニング娘。'14」「スマイレージとアンジュルム」「カントリー娘。とカントリー・ガールズ」は同一のグループとして共通のグループIDを持ちます。よって、groupID列の値は重複し、groupName列の値(文字列)は重複しません。
メンバーの情報を読み込みます。
# メンバー一覧を読み込み member_df <- readr::read_csv( file = paste0(dir_path, "member.csv"), col_types = readr::cols( memberID = "i", memberName = "c", HPjoinDate = readr::col_date(format = "%Y/%m/%d"), debutDate = readr::col_date(format = "%Y/%m/%d"), HPgradDate = readr::col_date(format = "%Y/%m/%d"), memberKana = "c", birthDate = readr::col_date(format = "%Y/%m/%d") ) ) |> dplyr::arrange(memberID) # 昇順に並べ替え member_df
## # A tibble: 275 × 7 ## memberID memberName HPjoinDate debutDate HPgradDate memberKana birthDate ## <int> <chr> <date> <date> <date> <chr> <date> ## 1 1 中澤裕子 1997-09-14 1998-01-28 2009-03-31 なかざわゆう… 1973-06-19 ## 2 2 石黒彩 1997-09-14 1998-01-28 2000-01-07 いしぐろあや 1978-05-12 ## 3 3 飯田圭織 1997-09-14 1998-01-28 2009-03-31 いいだかおり 1981-08-08 ## 4 4 安倍なつみ 1997-09-14 1998-01-28 2009-03-31 あべなつみ 1981-08-10 ## 5 5 福田明日香 1997-09-14 1998-01-28 1999-04-18 ふくだあすか 1984-12-17 ## 6 6 平家みちよ 1997-11-05 1997-11-05 2002-11-07 へいけみちよ 1979-04-06 ## 7 7 保田圭 1998-05-03 1998-05-03 2009-03-31 やすだけい 1980-12-06 ## 8 8 矢口真里 1998-05-03 1998-05-03 2005-04-14 やぐちまり 1983-01-20 ## 9 9 市井紗耶香 1998-05-03 1998-05-03 2000-05-21 いちいさやか 1983-12-31 ## 10 10 信田美帆 1999-02-21 1999-04-21 2000-10-09 しのだみほ 1972-05-18 ## # … with 265 more rows
member.csvは、メンバーID・メンバー名・ハロプロ加入日・メジャーデビュー日・卒業日・メンバー名(かな)の6列のcsvファイルです。
member.csvには、メンバーが重複しているデータがあります。
# 重複データを確認 member_df |> dplyr::group_by(memberID) |> # 重複のカウント用にグループ化 dplyr::mutate(n = dplyr::n()) |> # 重複をカウント dplyr::ungroup() |> # グループ化を解除 dplyr::filter(n > 1) # 重複データを抽出
## # A tibble: 6 × 8 ## memberID memberName HPjoinDate debutDate HPgradDate memberKana birthDate ## <int> <chr> <date> <date> <date> <chr> <date> ## 1 19 戸田鈴音 1999-04-27 NA 2000-04-30 とだりんね 1981-02-06 ## 2 19 りんね 2000-05-01 2001-04-18 2002-10-13 りんね 1981-02-06 ## 3 41 紺野あさ美 2001-08-26 2001-08-26 2006-07-23 こんのあ… 1987-05-07 ## 4 41 紺野あさ美 2007-07-15 2007-07-15 2009-03-31 こんのあ… 1987-05-07 ## 5 73 ストューカス… 2004-08-10 NA 2006-09-30 すとゅー… 1993-03-15 ## 6 73 岡田ロビン翔子 2006-10-01 NA 2007-09-30 おかだろ… 1993-03-15 ## # … with 1 more variable: n <int>
「りんね」さんと「岡田ロビン翔子」は改名によるもので、「紺野あさ美」さんはモーニング娘。を卒業した後にハロプロに復帰したためです。
また、誕生日が欠損しているデータがあります。
# 欠損データを確認 member_df |> dplyr::filter(is.na(birthDate))
## # A tibble: 2 × 7 ## memberID memberName HPjoinDate debutDate HPgradDate memberKana birthDate ## <int> <chr> <date> <date> <date> <chr> <date> ## 1 21 小林梓 1999-04-27 NA 1999-08-23 こばやしあずさ NA ## 2 98 大柳麻帆 2004-08-10 NA 2005-07-01 おおやなぎまほ NA
誕生日が公表されていないようです。
メンバーの加入日・卒業日の情報を読み込みます。
# 加入・卒業日一覧を読み込み join_df <- readr::read_csv( file = paste0(dir_path, "join.csv"), col_types = readr::cols( memberID = "i", groupID = "i", joinDate = readr::col_date(format = "%Y/%m/%d"), gradDate = readr::col_date(format = "%Y/%m/%d") ) ) |> dplyr::arrange(joinDate, memberID, groupID) # 昇順に並べ替え join_df
## # A tibble: 517 × 4 ## memberID groupID joinDate gradDate ## <int> <int> <date> <date> ## 1 1 1 1997-09-14 2001-04-15 ## 2 2 1 1997-09-14 2000-01-07 ## 3 3 1 1997-09-14 2005-01-30 ## 4 4 1 1997-09-14 2004-01-25 ## 5 5 1 1997-09-14 1999-04-18 ## 6 7 1 1998-05-03 2003-05-05 ## 7 8 1 1998-05-03 2005-04-14 ## 8 9 1 1998-05-03 2000-05-21 ## 9 2 2 1998-10-18 2000-01-07 ## 10 3 2 1998-10-18 2002-09-23 ## # … with 507 more rows
join.csvは、メンバーID・グループID・加入日・卒業日の4列のcsvファイルです。現在活動中であれば卒業日が欠損値になります。
member.cscのメンバーID、group.csvのグループIDと対応しています。
このデータを利用して、各メンバーの活動期間を集計します。
データの編集
カントリー娘。とカントリー・ガールズは同じIDが割り当てられています。そのため以降の処理では、同じグループとして処理されます。
別のグループとして扱う場合は、新たなグループIDを割り当てます。
# 分割するグループ名を指定 group_name <- "カントリー・ガールズ" # グループを分割 group_df <- group_df |> dplyr::mutate( groupID = dplyr::if_else( groupName == group_name, true = max(groupID) + 1L, false = groupID ) # 指定したグループのIDを再設定 ) # 分割したグループを確認 group_df |> dplyr::filter(groupID == max(groupID))
## # A tibble: 1 × 5 ## groupID groupName formDate dissolveDate isUnit ## <int> <chr> <date> <date> <lgl> ## 1 45 カントリー・ガールズ 2014-11-05 2019-12-26 FALSE
if_else()を使って、指定したグループのIDをグループIDの最大値に1を加えた値に変更します。数値型ではなく整数型のため、1ではなく1Lを加えます。
タイムラインによる可視化
メンバーごとのタイムラインチャートを作成します。
活動期間の集計:(加入日・卒業日)
グループを指定して、そのグループの歴代メンバーの加入日と卒業日における年齢と活動日数を計算します。
# グループを指定 groupID_val <- 1 # メンバーごとに加入日と卒業日における年齢と活動日数を計算 chart_df <- join_df |> # メンバー情報を追加 dplyr::filter(groupID == groupID_val) |> # 指定したグループを抽出 dplyr::arrange(joinDate, memberID) |> # メンバーIDの再設定用に並べ替え dplyr::mutate( member_id = dplyr::row_number(), # メンバーIDを再設定 gradDate = dplyr::if_else( is.na(gradDate), true = lubridate::today(), false = gradDate ), # 現在活動中であれば現在の日付を設定 joinDate2 = joinDate, # 加入日を複製 ) |> # 加入・卒業情報を編集 dplyr::left_join( member_df |> dplyr::select(memberID, memberName, birthDate) |> # 利用する列を選択 dplyr::group_by(memberID) |> # 重複の除去用にグループ化 dplyr::slice_tail(n = 1) |> # 重複を除去:(slice_headなら改名前、slice_tailなら改名後を抽出) dplyr::ungroup(), # グループ化を解除 by = "memberID" ) |> # メンバー情報を結合 tidyr::pivot_longer( cols = c(joinDate, gradDate), names_to = "date_type", values_to = "date" ) |> # 加入日・卒業日の列をまとめる dplyr::select(date, date_type, member_id, memberName, birthDate, joinDate = joinDate2) |> # 利用するを選択 dplyr::arrange(date, member_id) |> # 昇順に並べ替え # メンバー情報を編集 dplyr::mutate( age = lubridate::interval(start = birthDate, end = date) |> lubridate::time_length(unit = "year") |> floor(), # 年齢を計算 act_y = lubridate::interval(start = joinDate, end = date) |> lubridate::time_length(unit = "year") |> floor(), # 活動年数を計算 act_m = lubridate::interval(start = joinDate, end = date) |> lubridate::time_length(unit = "mon") |> floor() %% 12, # 活動月数-年数を計算 act_d = dplyr::case_when( lubridate::day(date) == lubridate::day(joinDate) ~ 0, # 日にちが同じなら、0 lubridate::day(date) > lubridate::day(joinDate) ~ lubridate::day(date) - lubridate::day(joinDate) |> as.numeric(), # 加入時の日にちが大きいなら、日にちの差 and( lubridate::day(date) < lubridate::day(joinDate), lubridate::day(lubridate::rollback(date)) < lubridate::day(joinDate) ) ~ lubridate::interval( start = date |> lubridate::rollback(), # 前月の末日に変更 end = date ) |> lubridate::time_length(unit = "day"), # 卒業時の日にちが大きく前月に加入時の日にちが存在しない月なら、前月の末日との差 lubridate::day(date) < lubridate::day(joinDate) ~ lubridate::interval( start = date |> lubridate::rollback() |> # 1か月前の末日に変更 lubridate::floor_date(unit = "mon") + lubridate::day(joinDate) - 1, # 加入時と同じ日にちに変更 end = date ) |> lubridate::time_length(unit = "day") # 卒業時の日にちが大きいなら、前月の加入時と同じ日にちとの差 ), # 活動日数-年月数を計算 act_days = lubridate::interval(start = joinDate, end = date) |> lubridate::time_length(unit = "day"), # 活動日数を計算 label = paste0(age, "歳:", act_y, "年", act_m, "か月", act_d, "日") ) |> # ラベル用の値を計算 dplyr::select(date, member_id, memberName, age, act_y, act_m, act_d, label) # 利用する列を選択 chart_df
## # A tibble: 90 × 8 ## date member_id memberName age act_y act_m act_d label ## <date> <int> <chr> <dbl> <dbl> <dbl> <dbl> <chr> ## 1 1997-09-14 1 中澤裕子 24 0 0 0 24歳:0年0か月0日 ## 2 1997-09-14 2 石黒彩 19 0 0 0 19歳:0年0か月0日 ## 3 1997-09-14 3 飯田圭織 16 0 0 0 16歳:0年0か月0日 ## 4 1997-09-14 4 安倍なつみ 16 0 0 0 16歳:0年0か月0日 ## 5 1997-09-14 5 福田明日香 12 0 0 0 12歳:0年0か月0日 ## 6 1998-05-03 6 保田圭 17 0 0 0 17歳:0年0か月0日 ## 7 1998-05-03 7 矢口真里 15 0 0 0 15歳:0年0か月0日 ## 8 1998-05-03 8 市井紗耶香 14 0 0 0 14歳:0年0か月0日 ## 9 1999-04-18 5 福田明日香 14 1 7 4 14歳:1年7か月4日 ## 10 1999-08-22 9 後藤真希 13 0 0 0 13歳:0年0か月0日 ## # … with 80 more rows
グループを指定して、指定したグループの歴代メンバーのID・加入日・卒業日の列を取り出します。
各メンバーの名前と誕生日を結合します。
加入日と卒業日の列をまとめて日付列とします。それぞれ、タイムラインの始点と終点になります。
メンバーラベルとして利用するために、加入時・卒業時における年齢と活動年数を計算します。
各処理を細かく見ます。
・コード(クリックで展開)
指定したグループの歴代メンバーの情報を作成します。
# メンバー情報を作成 df1 <- join_df |> dplyr::filter(groupID == groupID_val) |> # 指定したグループを抽出 dplyr::arrange(joinDate, memberID) |> # メンバーIDの再設定用に並べ替え dplyr::mutate( member_id = dplyr::row_number(), # メンバーIDを再設定 gradDate = dplyr::if_else( is.na(gradDate), true = lubridate::today(), false = gradDate ), # 現在活動中であれば現在の日付を設定 joinDate2 = joinDate, # 加入日を複製 ) |> # 加入・卒業情報を編集 dplyr::left_join( member_df |> dplyr::select(memberID, memberName, birthDate) |> # 利用する列を選択 dplyr::group_by(memberID) |> # 重複の除去用にグループ化 dplyr::slice_tail(n = 1) |> # 重複を除去:(slice_headなら改名前、slice_tailなら改名後を抽出) dplyr::ungroup(), # グループ化を解除 by = "memberID" ) # メンバー情報を結合 df1
## # A tibble: 45 × 8 ## memberID groupID joinDate gradDate member_id joinDate2 memberName ## <int> <int> <date> <date> <int> <date> <chr> ## 1 1 1 1997-09-14 2001-04-15 1 1997-09-14 中澤裕子 ## 2 2 1 1997-09-14 2000-01-07 2 1997-09-14 石黒彩 ## 3 3 1 1997-09-14 2005-01-30 3 1997-09-14 飯田圭織 ## 4 4 1 1997-09-14 2004-01-25 4 1997-09-14 安倍なつみ ## 5 5 1 1997-09-14 1999-04-18 5 1997-09-14 福田明日香 ## 6 7 1 1998-05-03 2003-05-05 6 1998-05-03 保田圭 ## 7 8 1 1998-05-03 2005-04-14 7 1998-05-03 矢口真里 ## 8 9 1 1998-05-03 2000-05-21 8 1998-05-03 市井紗耶香 ## 9 27 1 1999-08-22 2002-09-23 9 1999-08-22 後藤真希 ## 10 29 1 2000-04-16 2005-05-07 10 2000-04-16 石川梨華 ## # … with 35 more rows, and 1 more variable: birthDate <date>
join_dfから、指定したグループのメンバーのID・加入日・卒業日の列を取り出して、データフレームを加工します。
加入順に並べ替えて、新たなメンバーIDをrow_number()で割り当てます。加入順が同じ場合は、元のメンバーID順にします。
現在活動中のメンバーであれば卒業日(gradDate列)がNAなので、if_else()とis.na()を使って、today()で現在の日付に変更します。
加入日の列を複製しておきます。
メンバーIDで対応付けて、member_dfのメンバー名・誕生日の列をleft_join()で結合します。重複するメンバーが存在するため、slice_head()またはslice_tail()で改名前または改名後のデータ(行)を抽出しておきます。改名していない(重複しない)場合は、上からでも下からでも1行なので、影響しません。
加入日と卒業日の列をまとめて日付列を作成します。
# 利用する列を加工 df2 <- df1 |> tidyr::pivot_longer( cols = c(joinDate, gradDate), names_to = "date_type", values_to = "date" ) |> # 加入日・卒業日の列をまとめる dplyr::select(date, date_type, member_id, memberName, birthDate, joinDate = joinDate2) |> # 利用するを選択 dplyr::arrange(date, member_id) # 昇順に並べ替え df2
## # A tibble: 90 × 6 ## date date_type member_id memberName birthDate joinDate ## <date> <chr> <int> <chr> <date> <date> ## 1 1997-09-14 joinDate 1 中澤裕子 1973-06-19 1997-09-14 ## 2 1997-09-14 joinDate 2 石黒彩 1978-05-12 1997-09-14 ## 3 1997-09-14 joinDate 3 飯田圭織 1981-08-08 1997-09-14 ## 4 1997-09-14 joinDate 4 安倍なつみ 1981-08-10 1997-09-14 ## 5 1997-09-14 joinDate 5 福田明日香 1984-12-17 1997-09-14 ## 6 1998-05-03 joinDate 6 保田圭 1980-12-06 1998-05-03 ## 7 1998-05-03 joinDate 7 矢口真里 1983-01-20 1998-05-03 ## 8 1998-05-03 joinDate 8 市井紗耶香 1983-12-31 1998-05-03 ## 9 1999-04-18 gradDate 5 福田明日香 1984-12-17 1997-09-14 ## 10 1999-08-22 joinDate 9 後藤真希 1985-09-23 1999-08-22 ## # … with 80 more rows
pivot_longer()でjoinDate列とgradDate列をまとめます。
加入日列が1つになったので、複製したjoinDate2列を元の名前に戻します。
加入日と卒業日における年齢と活動日数(y年mか月d日のy・m・dの値)を計算します。
# メンバー情報を編集 df3 <- df2 |> dplyr::mutate( age = lubridate::interval(start = birthDate, end = date) |> lubridate::time_length(unit = "year") |> floor(), # 年齢を計算 act_y = lubridate::interval(start = joinDate, end = date) |> lubridate::time_length(unit = "year") |> floor(), # 活動年数を計算 act_m = lubridate::interval(start = joinDate, end = date) |> lubridate::time_length(unit = "mon") |> floor() %% 12, # 活動月数-年数を計算 act_d = dplyr::case_when( lubridate::day(date) == lubridate::day(joinDate) ~ 0, # 日にちが同じなら、0 lubridate::day(date) > lubridate::day(joinDate) ~ lubridate::day(date) - lubridate::day(joinDate) |> as.numeric(), # 加入時の日にちが大きいなら、日にちの差 and( lubridate::day(date) < lubridate::day(joinDate), lubridate::day(lubridate::rollback(date)) < lubridate::day(joinDate) ) ~ lubridate::interval( start = date |> lubridate::rollback(), # 前月の末日に変更 end = date ) |> lubridate::time_length(unit = "day"), # 卒業時の日にちが大きく前月に加入時の日にちが存在しない月なら、前月の末日との差 lubridate::day(date) < lubridate::day(joinDate) ~ lubridate::interval( start = date |> lubridate::rollback() |> # 1か月前の末日に変更 lubridate::floor_date(unit = "mon") + lubridate::day(joinDate) - 1, # 加入時と同じ日にちに変更 end = date ) |> lubridate::time_length(unit = "day") # 卒業時の日にちが大きいなら、前月の加入時と同じ日にちとの差 ), # 活動日数-年月数を計算 act_days = lubridate::interval(start = joinDate, end = date) |> lubridate::time_length(unit = "day"), # 活動日数を計算 label = paste0(age, "歳:", act_y, "年", act_m, "か月", act_d, "日") ) #|> # ラベル用の値を計算 #dplyr::select(date, member_id, memberName, age, act_y, act_m, act_d, label) # 利用する列を選択 df3
## # A tibble: 90 × 12 ## date date_type member_id memberName birthDate joinDate age act_y ## <date> <chr> <int> <chr> <date> <date> <dbl> <dbl> ## 1 1997-09-14 joinDate 1 中澤裕子 1973-06-19 1997-09-14 24 0 ## 2 1997-09-14 joinDate 2 石黒彩 1978-05-12 1997-09-14 19 0 ## 3 1997-09-14 joinDate 3 飯田圭織 1981-08-08 1997-09-14 16 0 ## 4 1997-09-14 joinDate 4 安倍なつみ 1981-08-10 1997-09-14 16 0 ## 5 1997-09-14 joinDate 5 福田明日香 1984-12-17 1997-09-14 12 0 ## 6 1998-05-03 joinDate 6 保田圭 1980-12-06 1998-05-03 17 0 ## 7 1998-05-03 joinDate 7 矢口真里 1983-01-20 1998-05-03 15 0 ## 8 1998-05-03 joinDate 8 市井紗耶香 1983-12-31 1998-05-03 14 0 ## 9 1999-04-18 gradDate 5 福田明日香 1984-12-17 1997-09-14 14 1 ## 10 1999-08-22 joinDate 9 後藤真希 1985-09-23 1999-08-22 13 0 ## # … with 80 more rows, and 4 more variables: act_m <dbl>, act_d <dbl>, ## # act_days <dbl>, label <chr>
interval()とtime_length()のunit引数に"year"を指定して、birthDateからdateまでの年数を求めます。floor()で小数点以下を切り捨てると、各月におけるメンバーの年齢が得られます。
同様に、joinDateからdateまでの年数で活動年数が得られます。
unit引数に"mon"を指定すると月数を返します。%%演算子を使って12で割った余りを計算すると、y年mか月のmの値が得られます。
y年mか月d日のdの値については、「日付列dateの日にち」と「加入時joinDateの日にち」の大小関係により、case_when()で条件分岐して処理します。
dateとjoinDateの日にちが同じであれば、0日です。これは日付列が加入日のときの処理で、以降は卒業日のときの処理です。
dateの日にちが大きければ、joinDateからdateまでの日数を計算します。
joinDateの日にちが大きければ、dateを、rollback()とfloor_date()で1か月前の初日にし、さらに加入時の日にち-1を加え、前月の加入時の日にちにしてdateまでの日数を計算します。
ただし、前月に加入時の日にちがない場合、例えば加入日が30日でdateが3月のときは前月の加入時の日にちではなく3月2日になってしまいます。そこで、dateをrollback()で前月の末日にして、dateまでの日数を計算します。and()を使って、前月に加入時の日がない(前月の末日が加入時の日より小さい)条件も満たす場合に処理します。
総活動日数も計算していますが、この値は使いません。
また確認用として、年齢・活動年数ラベルとして表示するための文字列を作成します。活動年数をyyyy年m月dd日の形式にするために、日にちが1桁の場合はstr_pad()で2桁目を0で埋めます。
以上で、必要なデータを得られました。次は、作図を行います。
タイムラインの作図
タイトル用に、グループ名を設定します。
# グループ名を設定 group_name <- group_df |> dplyr::filter(groupID == groupID_val) |> # 指定したグループを抽出 dplyr::pull(groupName) |> # ベクトルとして取得 unique() |> # 重複を削除 (\(x){x[1]})() # x[n]でn番目の要素を抽出 #group_name <- "モーニング娘。" group_name
## [1] "モーニング娘。"
半自動で処理するためにラムダ関数\()を使っていますが、普通に文字列で指定する方が簡単だと思います。
x軸の値を作成します。
# x軸の値(年)を作成 date_vec <- seq( from = chart_df[["date"]] |> min() |> # 最小値を取得 lubridate::floor_date(unit = "year"), # 年単位で切り捨て to = chart_df[["date"]] |> max() |> # 最大値を取得 lubridate::ceiling_date(unit = "year"), # 年単位で切り上げ by = "year" ) head(date_vec)
## [1] "1997-01-01" "1998-01-01" "1999-01-01" "2000-01-01" "2001-01-01" ## [6] "2002-01-01"
グループの活動期間(date列)の最小値の年から最大値の年までの値を作成します。
加入時用のラベルを作成します。
# 加入時ラベルを作成 label_join_df <- chart_df |> dplyr::group_by(member_id) |> # データ抽出用にグループ化 dplyr::filter(date == min(date)) |> # 加入時のデータを抽出 dplyr::ungroup() |> # グループ化を解除 dplyr::mutate(label = paste0(memberName, " (", age, "歳) ")) # 年齢ラベルを作成 label_join_df
## # A tibble: 45 × 8 ## date member_id memberName age act_y act_m act_d label ## <date> <int> <chr> <dbl> <dbl> <dbl> <dbl> <chr> ## 1 1997-09-14 1 中澤裕子 24 0 0 0 "中澤裕子 (24歳) " ## 2 1997-09-14 2 石黒彩 19 0 0 0 "石黒彩 (19歳) " ## 3 1997-09-14 3 飯田圭織 16 0 0 0 "飯田圭織 (16歳) " ## 4 1997-09-14 4 安倍なつみ 16 0 0 0 "安倍なつみ (16歳) " ## 5 1997-09-14 5 福田明日香 12 0 0 0 "福田明日香 (12歳) " ## 6 1998-05-03 6 保田圭 17 0 0 0 "保田圭 (17歳) " ## 7 1998-05-03 7 矢口真里 15 0 0 0 "矢口真里 (15歳) " ## 8 1998-05-03 8 市井紗耶香 14 0 0 0 "市井紗耶香 (14歳) " ## 9 1999-08-22 9 後藤真希 13 0 0 0 "後藤真希 (13歳) " ## 10 2000-04-16 10 石川梨華 15 0 0 0 "石川梨華 (15歳) " ## # … with 35 more rows
メンバー名と加入時の年齢を文字列結合します。各メンバーの加入時のデータはdateの最小値です。
卒業時用のラベルを作成します。
# 卒業時ラベルを作成 label_grad_df <- chart_df |> dplyr::group_by(member_id) |> # データ抽出用にグループ化 dplyr::filter(date == max(date)) |> # 卒業時のデータを抽出 dplyr::ungroup() |> # グループ化を解除 dplyr::mutate(label = paste0(" (", age, "歳:", act_y, "年", act_m, "か月", act_d, "日)")) # 年齢・活動年数ラベルを作成 label_grad_df
## # A tibble: 45 × 8 ## date member_id memberName age act_y act_m act_d label ## <date> <int> <chr> <dbl> <dbl> <dbl> <dbl> <chr> ## 1 1999-04-18 5 福田明日香 14 1 7 4 " (14歳:1年7か月4日… ## 2 2000-01-07 2 石黒彩 21 2 3 24 " (21歳:2年3か月24… ## 3 2000-05-21 8 市井紗耶香 16 2 0 18 " (16歳:2年0か月18… ## 4 2001-04-15 1 中澤裕子 27 3 7 1 " (27歳:3年7か月1日… ## 5 2002-09-23 9 後藤真希 17 3 1 1 " (17歳:3年1か月1日… ## 6 2003-05-05 6 保田圭 22 5 0 2 " (22歳:5年0か月2日… ## 7 2004-01-25 4 安倍なつみ 22 6 4 11 " (22歳:6年4か月11… ## 8 2004-08-01 12 辻希美 17 4 3 16 " (17歳:4年3か月16… ## 9 2004-08-01 13 加護亜依 16 4 3 16 " (16歳:4年3か月16… ## 10 2005-01-30 3 飯田圭織 23 7 4 16 " (23歳:7年4か月16… ## # … with 35 more rows
メンバー名と卒業時の年齢と活動日数を文字列結合します。各メンバーの卒業時のデータはdateの最大値です。
タイムラインチャートを作成します。
# タイムラインを作成:デフォルトの配色 ggplot() + geom_line(data = chart_df, mapping = aes(x = date, y = member_id, color = factor(member_id)), size = 2) + # 活動期間ライン geom_text(data = label_join_df, mapping = aes(x = date, y = member_id, label = label, color = factor(member_id)), hjust = 1) + # 加入時ラベル geom_text(data = label_grad_df, mapping = aes(x = date, y = member_id, label = label, color = factor(member_id)), hjust = 0) + # 卒業時ラベル scale_x_date(breaks = date_vec, date_labels = "%Y-%m", guide = guide_axis(angle = 45), expand = c(0, 0)) + # x軸目盛 scale_y_reverse(breaks = seq(0, max(chart_df[["member_id"]]), by = 10)) + # y軸を反転 coord_cartesian(clip = "off") + # 表示範囲 theme( plot.title = element_text(color = "black", face = "bold", size = 20, hjust = 0.5), # 全体のタイトル plot.subtitle = element_text(color = "black", size = 15, hjust = 0.5), # 全体のサブタイトル plot.margin = margin(t = 10, r = 120, b = 10, l = 80, unit = "pt"), # 全体の余白 legend.position = "none" # 凡例の表示位置 ) + # 図の体裁 labs( title = paste0(group_name, "歴代メンバーの活動期間"), subtitle = paste0( format(min(chart_df[["date"]]), format = "%Y年%m月%d日"), "~", format(max(chart_df[["date"]]), format = "%Y年%m月%d日"), ":総メンバー", max(chart_df[["member_id"]]), "人" ), x = "年-月", y = "メンバー", caption = "データ:「https://github.com/xxgentaroxx/HP_DB」" ) # ラベル

y軸をメンバーIDにすることで、各メンバーの線を縦に並べて描画します。加入期ごとに昇順に並べるために、scale_y_reverse()でy軸の値を反転させます。
加入時と卒業時のラベルをgeom_text()で描画します。
各メンバーのラインをメンバーカラーで配色します。
# タイムラインを作成:メンバーカラーで配色(color_list.Rを参照) ggplot() + geom_line(data = chart_df, mapping = aes(x = date, y = member_id, color = memberName), size = 2) + # 活動期間ライン geom_label(data = label_join_df, mapping = aes(x = date, y = member_id, label = label, color = memberName), hjust = 1, fill = "gray92", label.size = 0, label.padding = unit(0.09, units = "lines")) + # 加入時ラベル geom_label(data = label_grad_df, mapping = aes(x = date, y = member_id, label = label, color = memberName), hjust = 0, fill = "gray92", label.size = 0, label.padding = unit(0.09, units = "lines")) + # 卒業時ラベル scale_color_manual(breaks = color_df[["member_name"]], values = color_df[["color_code"]]) + # 線の色 scale_fill_manual(breaks = color_df[["member_name"]], values = color_df[["color_code"]]) + # 塗りつぶしの色 scale_x_date(breaks = date_vec, date_labels = "%Y-%m", guide = guide_axis(angle = 45), expand = c(0, 0)) + # x軸目盛 scale_y_reverse(breaks = seq(0, max(chart_df[["member_id"]]), by = 10)) + # y軸を反転 coord_cartesian(clip = "off") + # 表示範囲 theme( plot.title = element_text(color = "black", face = "bold", size = 20, hjust = 0.5), # 全体のタイトル plot.subtitle = element_text(color = "black", size = 15, hjust = 0.5), # 全体のサブタイトル #plot.background = element_rect(fill = "gray"), # 全体の背景 plot.margin = margin(t = 10, r = 120, b = 10, l = 80, unit = "pt"), # 全体の余白 legend.position = "none" # 凡例の表示位置 ) + # 図の体裁 labs( title = paste0(group_name, "歴代メンバーの活動期間"), subtitle = paste0( format(min(chart_df[["date"]]), format = "%Y年%m月%d日"), "~", format(max(chart_df[["date"]]), format = "%Y年%m月%d日"), ":総メンバー", max(chart_df[["member_id"]]), "人" ), x = "年-月", y = "メンバー", caption = "データ:「https://github.com/xxgentaroxx/HP_DB」" ) # ラベル
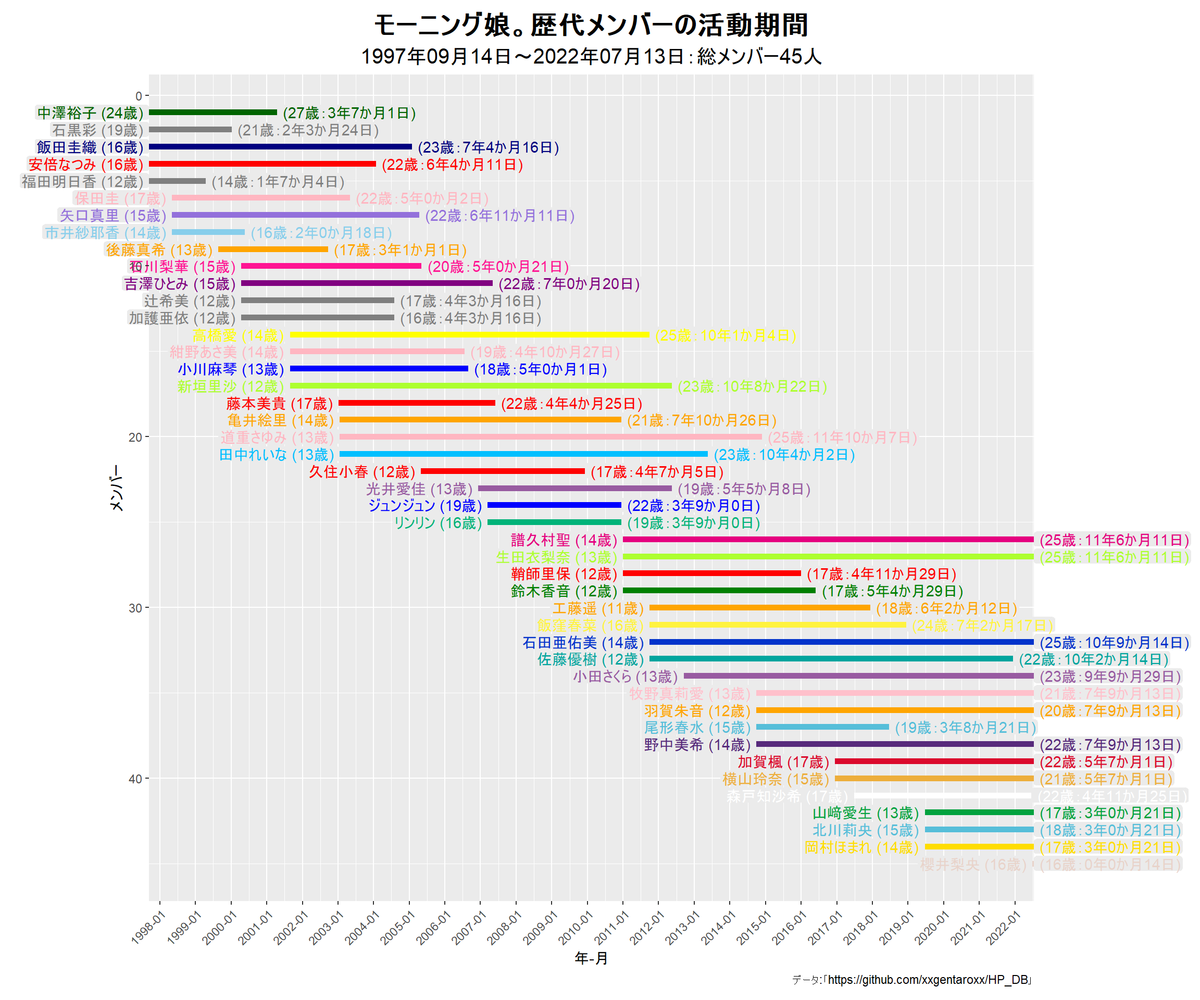
scale_color_manual()のbreaks引数にcolor引数に指定した値(文字列など)、values引数に色(色名やカラーコード)を指定します。各メンバーカラーに対応するカラーコード(のデータフレームcolor_df)については「ハロプロメンバーカラーの色見本の作図 - からっぽのしょこ」を参照してください。
メンバーカラーが白や薄い色だと背景色と被って見えなくなるため、geom_label()でラベルを描画します。この例では、ラベルを塗りつぶし(fill引数)をグラフ領域と同じ色でしています。
他のグループだと次のようになります。
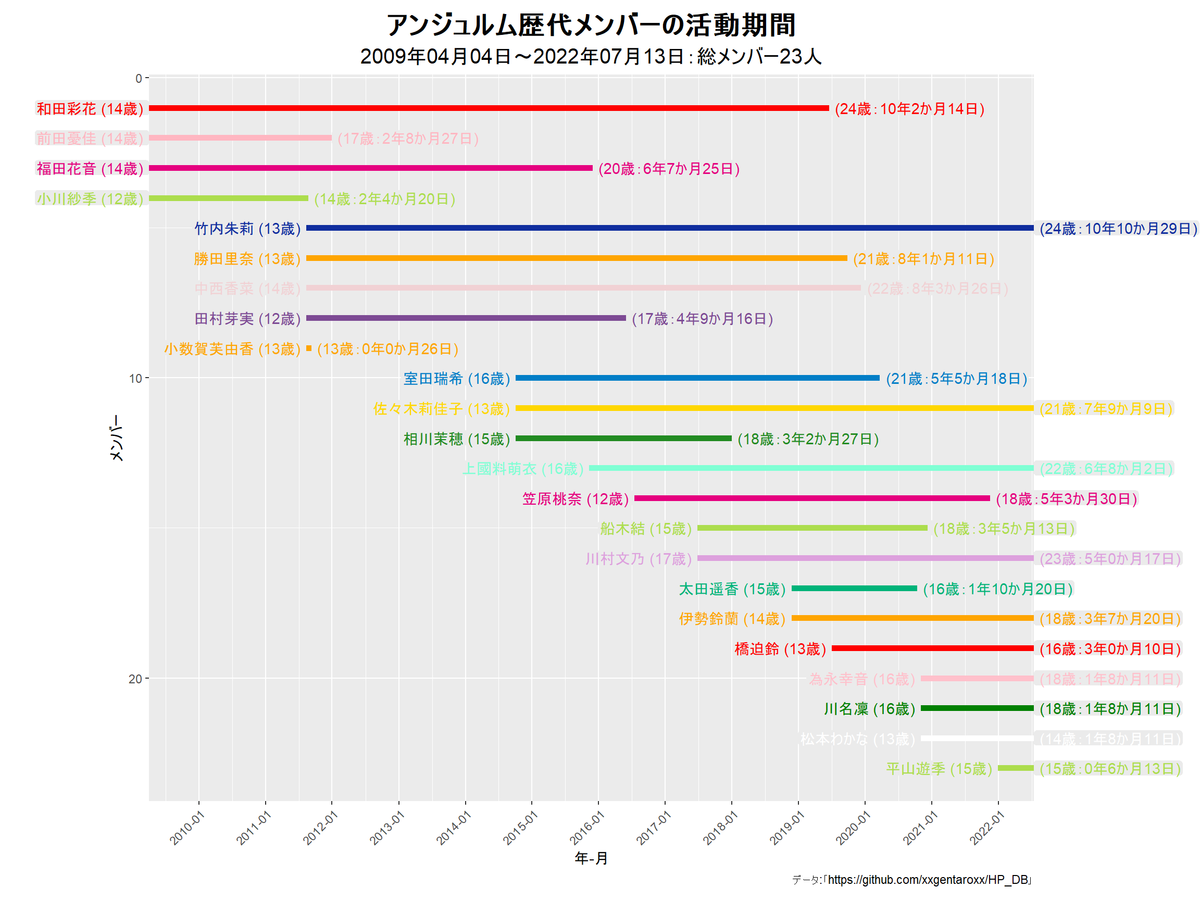
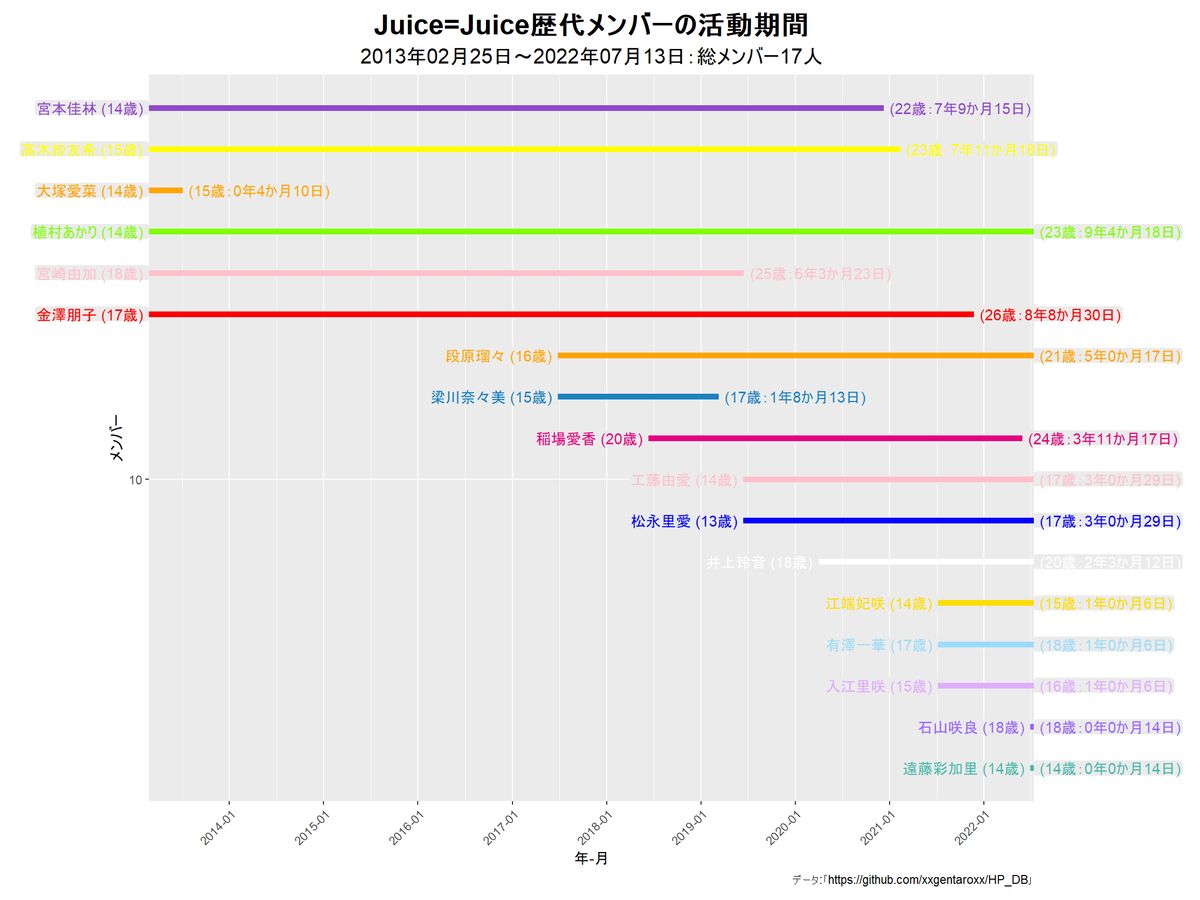
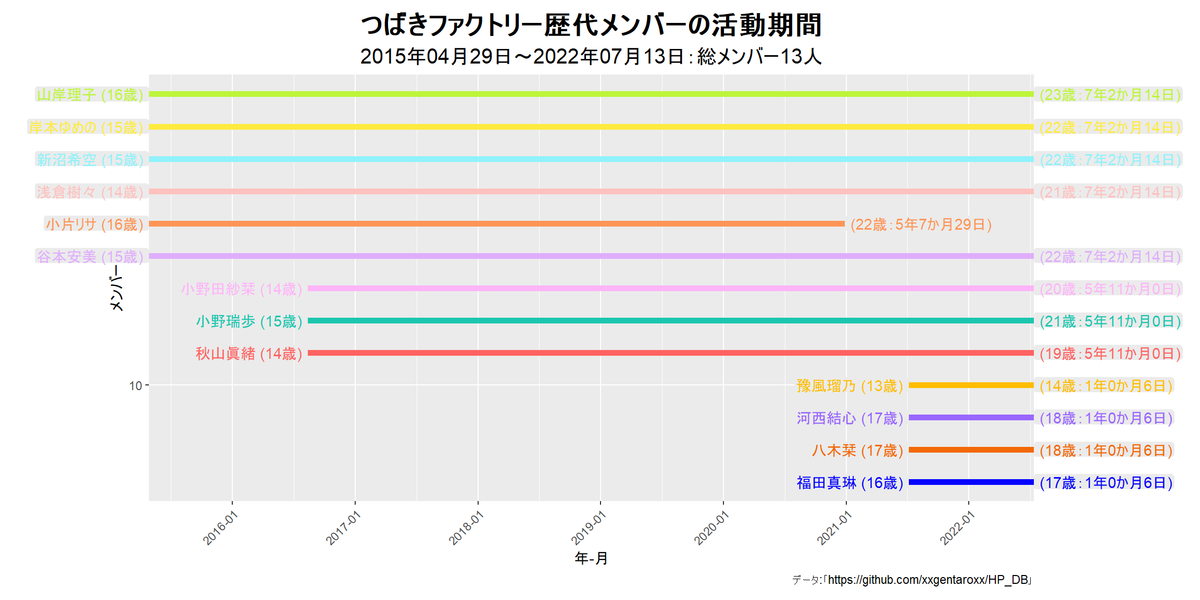


アニメーションによる可視化
次は、タイムラインを1か月ごとに表示するアニメーションを作成します。
活動期間の集計:(月別)
グループを指定して、そのグループの歴代メンバーの活動期間を集計します。
# グループを指定 groupID_val <- 1 # 活動期間を集計 anime_df <- group_df |> # 活動期間に対応した行を作成 dplyr::filter(groupID == groupID_val) |> # 指定したグループを抽出 dplyr::mutate( formDate = formDate |> lubridate::floor_date(unit = "mon"), dissolveDate = dplyr::if_else( is.na(dissolveDate), true = lubridate::today(), false = dissolveDate ) |> # 現在活動中であれば現在の日付を設定 lubridate::floor_date(unit = "mon"), n = lubridate::interval(start = formDate, end = dissolveDate) |> lubridate::time_length(unit = "mon") + 1 ) |> # 月数をカウント tidyr::uncount(n) |> # 月数に応じて行を複製 dplyr::group_by(groupName) |> # 行番号用にグループ化 dplyr::mutate(idx = dplyr::row_number()) |> # 行番号を割り当て dplyr::group_by(groupName, idx) |> # 1か月刻みの値の作成用にグループ化 dplyr::mutate(date = seq(from = formDate, to = dissolveDate, by = "mon")[idx]) |> # 複製した行を1か月刻みの値に変更 dplyr::group_by(date, groupID) |> # 重複の除去用にグループ化 dplyr::slice_max(formDate) |> # 重複する場合は新しい方を抽出 dplyr::ungroup() |> # グループ化を解除 dplyr::select(date, groupID, groupName) |> # 利用する列を取得 # メンバー情報を追加 tidyr::expand_grid( join_df |> dplyr::filter(groupID == groupID_val) |> # 指定したグループを抽出 dplyr::arrange(joinDate, memberID) |> # メンバーIDの再設定用に並べ替え dplyr::mutate( member_id = dplyr::row_number(), # メンバーIDを再設定 gradDate = dplyr::if_else( is.na(gradDate), true = lubridate::today(), false = gradDate ) # 現在活動中であれば現在の日付を設定 ) |> dplyr::select(!groupID), # 結合時に重複する列を削除, ) |> # 日付情報を複製してメンバーIDを結合 dplyr::left_join( member_df |> dplyr::select(memberID, memberName, birthDate) |> # 利用する列を取得 dplyr::group_by(memberID) |> # dplyr::slice_tail(n = 1), # 重複を除去:(slice_headなら改名前、slice_tailなら改名後を抽出) by = "memberID" ) |> # メンバー情報を結合 dplyr::arrange(date, member_id) |> # 昇順に並べ替え dplyr::filter(date >= joinDate, date <= gradDate) |> # 活動期間中のデータを抽出 # メンバー情報を編集 dplyr::mutate( age = lubridate::interval(start = birthDate, end = date) |> lubridate::time_length(unit = "year") |> floor(), # 年齢を計算 act_y = lubridate::interval(start = joinDate, end = date) |> lubridate::time_length(unit = "year") |> floor(), # 活動年数を計算 act_m = lubridate::interval(start = joinDate, end = date) |> lubridate::time_length(unit = "mon") |> floor() %% 12, # 活動月数-年数を計算 act_d = dplyr::if_else( lubridate::day(lubridate::rollback(date)) >= lubridate::day(joinDate), # 加入日の日にちが存在しない月の場合 true = lubridate::interval( start = date |> lubridate::rollback() |> # 1か月前の末日に変更 lubridate::floor_date(unit = "mon") + lubridate::day(joinDate) - 1, # 加入日と同じ日にちに変更 end = date ) |> lubridate::time_length(unit = "day"), # 日にちの差を計算 false = 1 ), # 活動日数-年月数を計算 act_days = lubridate::interval(start = joinDate, end = date) |> lubridate::time_length(unit = "day"), # 活動日数を計算 label = paste0( memberName, " (", age, "歳:", act_y, "年", act_m, "か月", stringr::str_pad(act_d, width = 2, pad = 0), "日)" ) ) |> # ラベルを作成 dplyr::select(date, groupName, member_id, memberName, age, act_y, act_m, act_d, act_days, label) # 利用する列を取得 anime_df
## # A tibble: 3,267 × 10 ## date groupName member_id memberName age act_y act_m act_d act_days ## <date> <chr> <int> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> ## 1 1997-10-01 モーニング… 1 中澤裕子 24 0 0 17 17 ## 2 1997-10-01 モーニング… 2 石黒彩 19 0 0 17 17 ## 3 1997-10-01 モーニング… 3 飯田圭織 16 0 0 17 17 ## 4 1997-10-01 モーニング… 4 安倍なつみ 16 0 0 17 17 ## 5 1997-10-01 モーニング… 5 福田明日香 12 0 0 17 17 ## 6 1997-11-01 モーニング… 1 中澤裕子 24 0 1 18 48 ## 7 1997-11-01 モーニング… 2 石黒彩 19 0 1 18 48 ## 8 1997-11-01 モーニング… 3 飯田圭織 16 0 1 18 48 ## 9 1997-11-01 モーニング… 4 安倍なつみ 16 0 1 18 48 ## 10 1997-11-01 モーニング… 5 福田明日香 12 0 1 18 48 ## # … with 3,257 more rows, and 1 more variable: label <chr>
グループIDを指定して、group_dfから指定したグループのデータを取り出します。
結成月から解散月までの全ての月(の日付)に対応する行を作成します。
全ての月を複製して、各月において在籍していたメンバーの情報を結合します。
ラベルとして表示するために、各月における年齢と活動日数を計算します。
各処理を細かく見ます。
・コード(クリックで展開)
指定したグループの結成日・解散日または改名日のデータを取り出して、結成月(改名月)から解散月(次の改名月)までの全ての月に対応する行を作成します。
# 活動期間に対応した行を作成 df1 <- group_df |> dplyr::filter(groupID == groupID_val) |> # 指定したグループを抽出 dplyr::mutate( formDate = formDate |> lubridate::floor_date(unit = "mon"), dissolveDate = dplyr::if_else( is.na(dissolveDate), true = lubridate::today(), false = dissolveDate ) |> # 現在活動中であれば現在の日付を設定 lubridate::floor_date(unit = "mon"), n = lubridate::interval(start = formDate, end = dissolveDate) |> lubridate::time_length(unit = "mon") + 1 ) |> # 月数をカウント tidyr::uncount(n) |> # 月数に応じて行を複製 dplyr::group_by(groupName) |> # 行番号用にグループ化 dplyr::mutate(idx = dplyr::row_number()) |> # 行番号を割り当て dplyr::group_by(groupName, idx) |> # 1か月刻みの値の作成用にグループ化 dplyr::mutate(date = seq(from = formDate, to = dissolveDate, by = "mon")[idx]) |> # 複製した行を1か月刻みの値に変更 dplyr::group_by(date, groupID) |> # 重複の除去用にグループ化 dplyr::slice_max(formDate) |> # 重複する場合は新しい方を抽出 dplyr::ungroup() # グループ化を解除 df1
## # A tibble: 299 × 7 ## groupID groupName formDate dissolveDate isUnit idx date ## <int> <chr> <date> <date> <lgl> <int> <date> ## 1 1 モーニング娘。 1997-09-01 2013-12-01 FALSE 1 1997-09-01 ## 2 1 モーニング娘。 1997-09-01 2013-12-01 FALSE 2 1997-10-01 ## 3 1 モーニング娘。 1997-09-01 2013-12-01 FALSE 3 1997-11-01 ## 4 1 モーニング娘。 1997-09-01 2013-12-01 FALSE 4 1997-12-01 ## 5 1 モーニング娘。 1997-09-01 2013-12-01 FALSE 5 1998-01-01 ## 6 1 モーニング娘。 1997-09-01 2013-12-01 FALSE 6 1998-02-01 ## 7 1 モーニング娘。 1997-09-01 2013-12-01 FALSE 7 1998-03-01 ## 8 1 モーニング娘。 1997-09-01 2013-12-01 FALSE 8 1998-04-01 ## 9 1 モーニング娘。 1997-09-01 2013-12-01 FALSE 9 1998-05-01 ## 10 1 モーニング娘。 1997-09-01 2013-12-01 FALSE 10 1998-06-01 ## # … with 289 more rows
group_dfは、グループ名groupNameと結成日(改名日)formDate・解散日(次の改名日)dissolveDateの情報を持ちます。(改名グループの場合はグループ名ごとに、)formDateからdissolveDateまでの全ての月を作成します。
指定したグループのデータ(行)をfilter()で抽出します。
formDate, dissolveDate列をfloor_date()で結成月と解散月にします。ただし、現在活動中のグループであれば解散日がNAなので、if_else()とis.na()を使って、today()で現在の日付に変更しておきます。
結成月から解散月までの月数を、interval()とtime_length()を使って計算して、n列とします。解散月 - 結成月が求まるので+1します。
(改名グループの場合はグループ名ごとに、)uncount()でn列の値と同じ行数に複製します。
複製した行にrow_number()で行番号を割り当ててidx列とします。
結成月から解散月までの全ての月をseq()で作成して、行番号に対応するインデックスの要素を抽出してdate列とします。
改名日が月の途中だと月(date列の値)が重複するので、slice_max()で新しい方の行を抽出します。
所属メンバーの加入情報を追加して、さらにメンバー情報を追加します。
# メンバー情報を追加 df2 <- df1 |> dplyr::select(date, groupID, groupName) |> # 利用する列を取得 tidyr::expand_grid( join_df |> dplyr::filter(groupID == groupID_val) |> # 指定したグループを抽出 dplyr::arrange(joinDate, memberID) |> # メンバーIDの再設定用に並べ替え dplyr::mutate( member_id = dplyr::row_number(), # メンバーIDを再設定 gradDate = dplyr::if_else( is.na(gradDate), true = lubridate::today(), false = gradDate ) # 現在活動中であれば現在の日付を設定 ) |> dplyr::select(!groupID), # 結合時に重複する列を削除, ) |> # 日付情報を複製してメンバーIDを結合 dplyr::left_join( member_df |> dplyr::select(memberID, memberName, birthDate) |> # 利用する列を取得 dplyr::group_by(memberID) |> # dplyr::slice_tail(n = 1), # 重複を除去:(slice_headなら改名前、slice_tailなら改名後を抽出) by = "memberID" ) |> # メンバー情報を結合 dplyr::arrange(date, member_id) |> # 昇順に並べ替え dplyr::filter(date >= joinDate, date <= gradDate) # 活動期間中のデータを抽出 df2
## # A tibble: 3,267 × 9 ## date groupID groupName memberID joinDate gradDate member_id ## <date> <int> <chr> <int> <date> <date> <int> ## 1 1997-10-01 1 モーニング娘。 1 1997-09-14 2001-04-15 1 ## 2 1997-10-01 1 モーニング娘。 2 1997-09-14 2000-01-07 2 ## 3 1997-10-01 1 モーニング娘。 3 1997-09-14 2005-01-30 3 ## 4 1997-10-01 1 モーニング娘。 4 1997-09-14 2004-01-25 4 ## 5 1997-10-01 1 モーニング娘。 5 1997-09-14 1999-04-18 5 ## 6 1997-11-01 1 モーニング娘。 1 1997-09-14 2001-04-15 1 ## 7 1997-11-01 1 モーニング娘。 2 1997-09-14 2000-01-07 2 ## 8 1997-11-01 1 モーニング娘。 3 1997-09-14 2005-01-30 3 ## 9 1997-11-01 1 モーニング娘。 4 1997-09-14 2004-01-25 4 ## 10 1997-11-01 1 モーニング娘。 5 1997-09-14 1999-04-18 5 ## # … with 3,257 more rows, and 2 more variables: memberName <chr>, ## # birthDate <date>
join_dfから、指定したグループのメンバーのID・加入日・卒業日を結合します。結合する前に、データフレームを加工しておきます。
加入順に並べ替えて、新たなメンバーIDをrow_number()で割り当てます。加入順が同じ場合は、元のメンバーID順にします。
現在活動中のメンバーであれば卒業日(gradDate列)がNAなので、if_else()とis.na()を使って、today()で現在の日付に変更します。
加工したjoin_dfの行とdf1の行の全ての組み合わせをexpand_grid()で作成します。これにより、全ての月(df1の行)をメンバー数に複製して、各メンバーの加入情報(join_dfの列)を追加できます。
member_dfのメンバーID・メンバー名・誕生日列をleft_join()で結合します。重複するメンバーが存在するため、slice_head()またはslice_tail()で改名前または改名後のデータ(行)を抽出しておきます。改名していない(重複しない)場合は、上からでも下からでも1行なので、影響しません。
ここまでで、全ての月に対してそれぞれ全てのメンバー情報を追加しました。メンバーごとに、活動期間(dateの日付が加入joinDateから卒業gradDateまで)のデータ(行)を抽出します。
expand_grid()は、次のようなデータフレームを作成します。
tidyr::expand_grid( date = c("2022-01-01", "2022-01-02", "2022-01-03"), id = 1:2 )
## # A tibble: 6 × 2 ## date id ## <chr> <int> ## 1 2022-01-01 1 ## 2 2022-01-01 2 ## 3 2022-01-02 1 ## 4 2022-01-02 2 ## 5 2022-01-03 1 ## 6 2022-01-03 2
3日分の日付と2人分のIDの全ての組み合わせを作成します。日付をIDに対応するように複製していると言えます。
各月における年齢と活動日数(y年mか月d日のy・m・dの値)を計算します。
# メンバー情報を編集 df3 <- df2 |> dplyr::mutate( age = lubridate::interval(start = birthDate, end = date) |> lubridate::time_length(unit = "year") |> floor(), # 年齢を計算 act_y = lubridate::interval(start = joinDate, end = date) |> lubridate::time_length(unit = "year") |> floor(), # 活動年数を計算 act_m = lubridate::interval(start = joinDate, end = date) |> lubridate::time_length(unit = "mon") |> floor() %% 12, # 活動月数-年数を計算 act_d = dplyr::if_else( lubridate::day(lubridate::rollback(date)) >= lubridate::day(joinDate), # 加入日の日にちが存在しない月の場合 true = lubridate::interval( start = date |> lubridate::rollback() |> # 1か月前の末日に変更 lubridate::floor_date(unit = "mon") + lubridate::day(joinDate) - 1, # 加入日と同じ日にちに変更 end = date ) |> lubridate::time_length(unit = "day"), # 日にちの差を計算 false = 1 ), # 活動日数-年月数を計算 act_days = lubridate::interval(start = joinDate, end = date) |> lubridate::time_length(unit = "day"), # 活動日数を計算 label = paste0( memberName, " (", age, "歳:", act_y, "年", act_m, "か月", stringr::str_pad(act_d, width = 2, pad = 0), "日)" ) ) #|> # ラベルを作成 #dplyr::select(date, groupName, member_id, memberName, age, act_y, act_m, act_d, act_days, label) # 利用する列を取得 df3
## # A tibble: 3,267 × 15 ## date groupID groupName memberID joinDate gradDate member_id ## <date> <int> <chr> <int> <date> <date> <int> ## 1 1997-10-01 1 モーニング娘。 1 1997-09-14 2001-04-15 1 ## 2 1997-10-01 1 モーニング娘。 2 1997-09-14 2000-01-07 2 ## 3 1997-10-01 1 モーニング娘。 3 1997-09-14 2005-01-30 3 ## 4 1997-10-01 1 モーニング娘。 4 1997-09-14 2004-01-25 4 ## 5 1997-10-01 1 モーニング娘。 5 1997-09-14 1999-04-18 5 ## 6 1997-11-01 1 モーニング娘。 1 1997-09-14 2001-04-15 1 ## 7 1997-11-01 1 モーニング娘。 2 1997-09-14 2000-01-07 2 ## 8 1997-11-01 1 モーニング娘。 3 1997-09-14 2005-01-30 3 ## 9 1997-11-01 1 モーニング娘。 4 1997-09-14 2004-01-25 4 ## 10 1997-11-01 1 モーニング娘。 5 1997-09-14 1999-04-18 5 ## # … with 3,257 more rows, and 8 more variables: memberName <chr>, ## # birthDate <date>, age <dbl>, act_y <dbl>, act_m <dbl>, act_d <dbl>, ## # act_days <dbl>, label <chr>
interval()とtime_length()のunit引数に"year"を指定して、birthDateからdateまでの年数を求めます。floor()で小数点以下を切り捨てると、各月におけるメンバーの年齢が得られます。
同様に、joinDateからdateまでの年数で活動年数が得られます。
unit引数に"mon"を指定すると月数を返します。%%演算子を使って12で割った余りを計算すると、y年mか月のmの値が得られます。
y年mか月d日のdの値については、if_else()で条件分岐して処理します。基本的な(true引数の)計算では、dateを、rollback()とfloor_date()で1か月前の1日にし、さらにday(joinDate)-1を加えて、1か月前の加入日と同じ日にします。この日からdateまでの日数が、dになります。ただし、例えば加入日が30日でdateが3月のときはstart引数の値が3月2日になってしまいます。そこで、前月の末日(lubridate::day(lubridate::rollback(date)))が加入した日(lubridate::day(joinDate))より小さい場合(加入日と同じ日が存在しない月の場合)は、false引数に1を指定します(1日目になります)。
総活動日数も計算していますが、この値は使いません。
年齢・活動年数ラベルとして表示するための文字列を作成します。活動年数をyyyy年m月dd日の形式にするために、日にちが1桁の場合はstr_pad()で2桁目を0で埋めます。
以上で、必要なデータを得られました。次は、作図を行います。
アニメーションの作図
グループ名を設定します。
# グループ名を設定 group_name <- anime_df[["groupName"]] |> unique() |> # 重複を削除 (\(x){x[1]})() # x[n]でn番目の要素を抽出 group_name <- "モーニング娘。"
半自動で処理するためにラムダ関数\()を使っていますが、普通に文字列で指定する方が簡単だと思います。
各月における在籍数を集計します。
# 在籍数を計算 member_n_df <- anime_df |> dplyr::count(date, name = "member_n") |> # メンバー数を集計 dplyr::mutate(label = paste0("在籍数:", member_n, "人")) # ラベルを作成 member_n_df
## # A tibble: 298 × 3 ## date member_n label ## <date> <int> <chr> ## 1 1997-10-01 5 在籍数:5人 ## 2 1997-11-01 5 在籍数:5人 ## 3 1997-12-01 5 在籍数:5人 ## 4 1998-01-01 5 在籍数:5人 ## 5 1998-02-01 5 在籍数:5人 ## 6 1998-03-01 5 在籍数:5人 ## 7 1998-04-01 5 在籍数:5人 ## 8 1998-05-01 5 在籍数:5人 ## 9 1998-06-01 8 在籍数:8人 ## 10 1998-07-01 8 在籍数:8人 ## # … with 288 more rows
count()で同じ月(date列の重複)をカウントして、グラフに表示する用の文字列を作成します。
x軸の値を作成します。
# x軸の値(年)を作成 date_vec <- seq( from = anime_df[["date"]] |> min() |> # 最小値を取得 lubridate::floor_date(unit = "year"), # 年単位で切り捨て to = anime_df[["date"]] |> max() |> # 最大値を取得 lubridate::ceiling_date(unit = "year"), # 年単位で切り上げ by = "year" ) head(date_vec)
## [1] "1997-01-01" "1998-01-01" "1999-01-01" "2000-01-01" "2001-01-01" ## [6] "2002-01-01"
グループの活動期間(date列)の最小値の年から最大値の年までの値を作成します。
フレームに関する値を設定します。
# 1秒間に表示する月数を指定:(値が大きいと意図した通りにならない) mps <- 6 # 最後のグラフでの停止フレーム数を指定 ep <- 30 # フレーム数を取得 n <- length(unique(anime_df[["date"]])) n
## [1] 298
1秒当たりのフレーム数をmpsとして、整数を指定します。ただし、値が大きいと値の通りになりません。
最後のフレーム(グラフ)で一時停止(同じグラフを表示)するフレーム数をepとして、整数を指定します。
基本となるフレーム数(月数)をnとします。
タイムラインのアニメーション(gif画像)を作成します。
# タイムラインのアニメーションを作成:デフォルトの配色 anim <- ggplot(data = anime_df, mapping = aes(x = date, y = member_id, color = factor(member_id))) + geom_vline(mapping = aes(xintercept = date), color = "gray56", size = 1, linetype = "dashed") + # 時間経過の垂線 geom_label(data = member_n_df, mapping = aes(x = date, y = 0, label = label), vjust = 0, color = "gray56") + # 在籍数ラベル geom_line(size = 2) + # 活動期間ライン geom_point(size = 4) + # 活動期間終点 geom_text(mapping = aes(label = paste(" ", label)), hjust = 0) + # メンバーラベル gganimate::transition_reveal(date) + # フレーム scale_x_date(breaks = date_vec, date_labels = "%Y", expand = c(0, 0)) + # x軸目盛 scale_y_reverse(breaks = seq(0, max(anime_df[["member_id"]]), by = 10)) + # y軸を反転 coord_cartesian(clip = "off") + # 表示範囲 theme( plot.title = element_text(color = "black", face = "bold", size = 20, hjust = 0.5), # 全体のタイトル plot.subtitle = element_text(color = "black", size = 15, hjust = 0.5), # 全体のサブタイトル plot.margin = margin(t = 10, r = 200, b = 20, l = 40, unit = "pt"), # 全体の余白 legend.position = "none" # 凡例の表示位置 ) + # 図の体裁 labs( title = paste0(group_name, "歴代メンバーの活動期間"), subtitle = paste0("{format(frame_along, format = '%Y年%m月')}01日時点"), x = "年", y = "メンバー", caption = "データ:「https://github.com/xxgentaroxx/HP_DB」" ) # ラベル
transition_reveal()にフレームの順序(各グラフに利用するデータ)を示す列を指定します。
線や文字色をメンバーカラーにします。
# タイムラインを作成:メンバーカラーで配色(color_list.Rを参照) anim <- ggplot(data = anime_df, mapping = aes(x = date, y = member_id, color = memberName)) + geom_vline(mapping = aes(xintercept = date), color = "gray56", size = 1, linetype = "dashed") + # 時間経過の垂線 geom_label(data = member_n_df, mapping = aes(x = date, y = 0, label = label), vjust = 0, color = "gray56") + # 在籍数ラベル geom_label(mapping = aes(label = paste(" ", label)), hjust = 0, fill = "gray92", label.size = 0, label.padding = unit(0.1, units = "lines")) + # メンバーラベル geom_line(size = 2) + # 活動期間ライン geom_point(size = 4) + # 活動期間終点 gganimate::transition_reveal(date) + # フレーム scale_color_manual(breaks = color_df[["member_name"]], values = color_df[["color_code"]]) + # 線の色 scale_x_date(breaks = date_vec, date_labels = "%Y", guide = guide_axis(angle = 0), expand = c(0, 0)) + # x軸目盛 scale_y_reverse(breaks = seq(0, max(anime_df[["member_id"]]), by = 10)) + # y軸を反転 coord_cartesian(clip = "off") + # 表示範囲 theme( plot.title = element_text(color = "black", face = "bold", size = 20, hjust = 0.5), # 全体のタイトル plot.subtitle = element_text(color = "black", size = 15, hjust = 0.5), # 全体のサブタイトル plot.margin = margin(t = 10, r = 200, b = 20, l = 40, unit = "pt"), # 全体の余白 legend.position = "none" # 凡例の表示位置 ) + # 図の体裁 labs( title = paste0(group_name, "歴代メンバーの活動期間"), subtitle = paste0("{format(lubridate::as_date(frame_along)+3, format = '%Y年%m月')}01日時点"), x = "年", y = "メンバー", caption = "データ:「https://github.com/xxgentaroxx/HP_DB」" ) # ラベル
scale_color_manual()のbreaks引数にcolor引数に指定した値(文字列など)、values引数に色(色名やカラーコード)を指定します。
animate()でgif画像を作成します。
# gif画像を作成 g <- gganimate::animate( anim, nframes = n+ep, end_pause = ep, fps = mps, width = 1200, height = 900 ) g

plot引数にグラフ、nframes引数にフレーム数、end_pause引数に最終グラフの表示フレーム数、fps引数に1秒当たりのフレーム数を指定します。
モーニング娘。の例は下に貼っています。他のグループだと次のようになります。


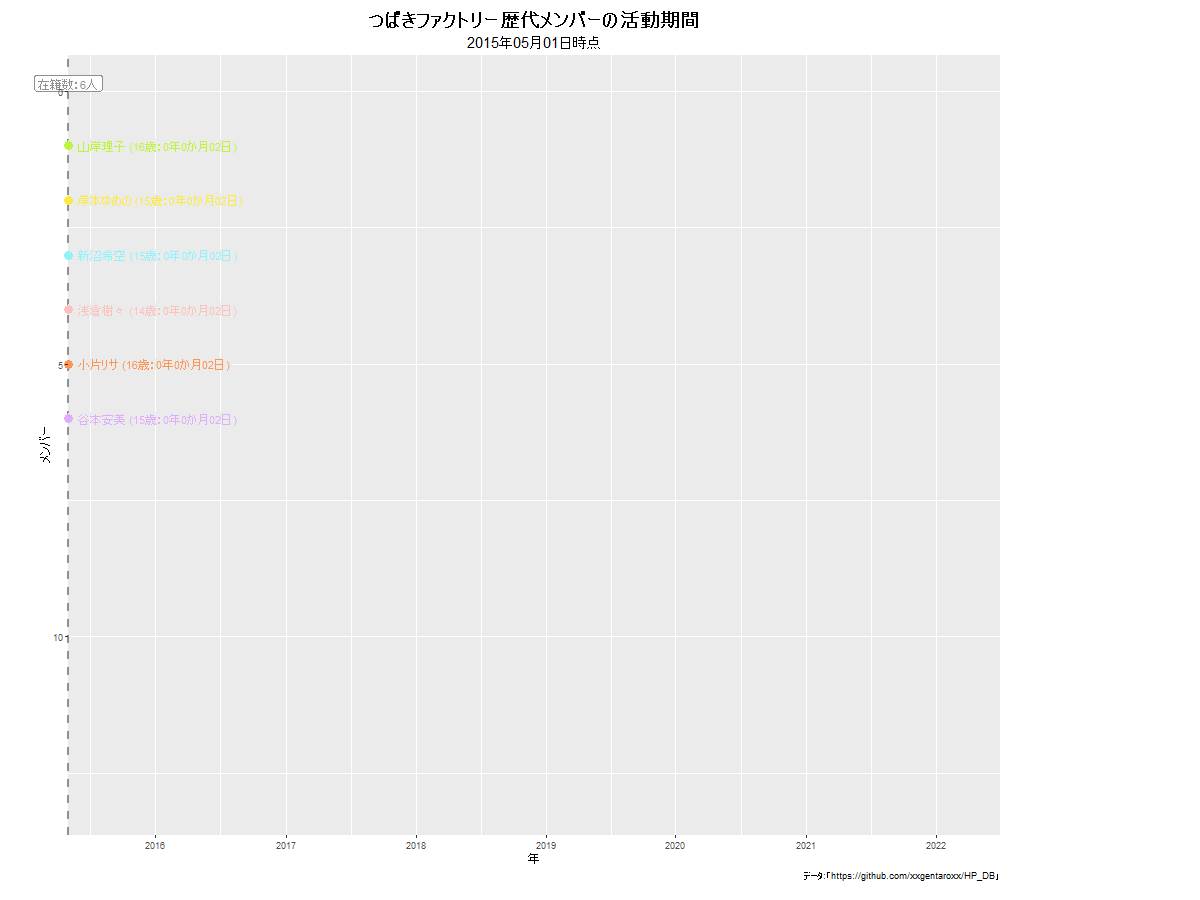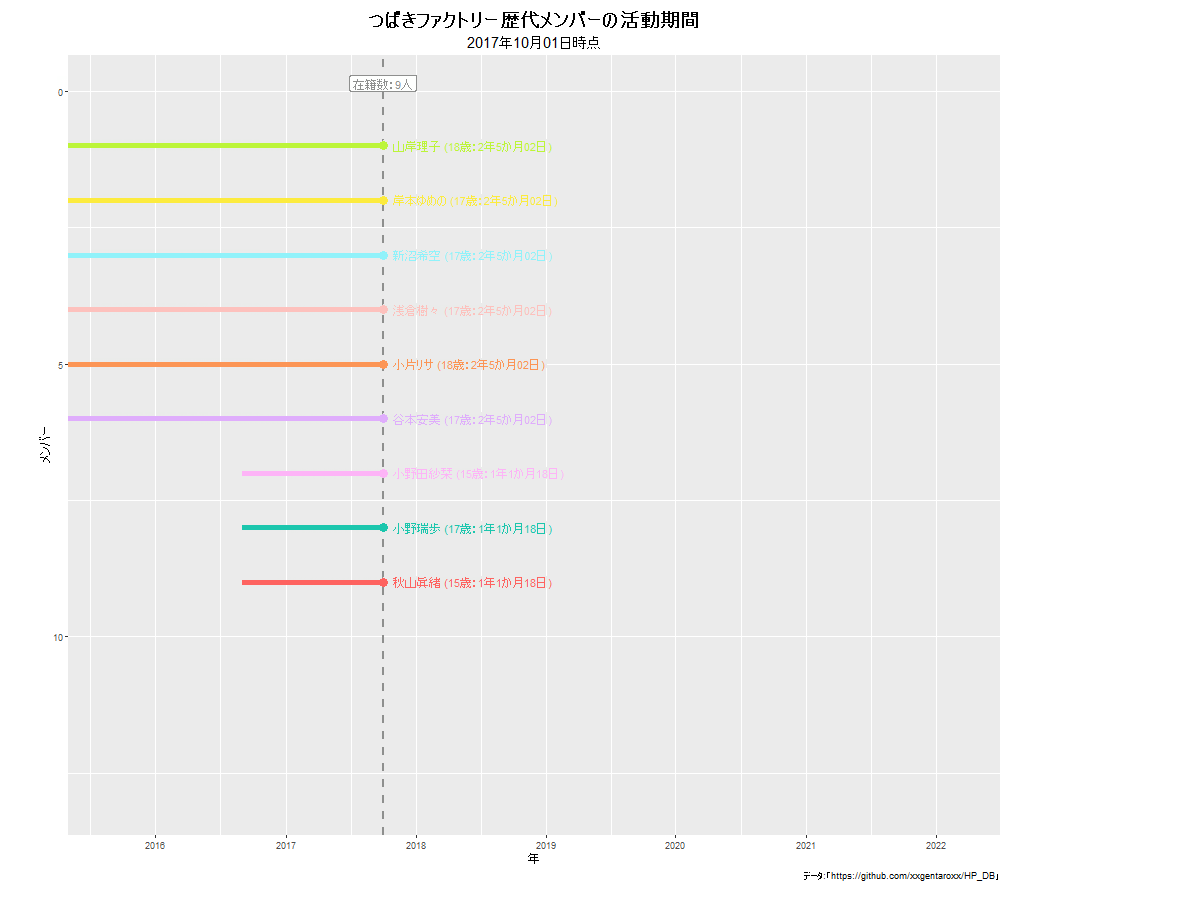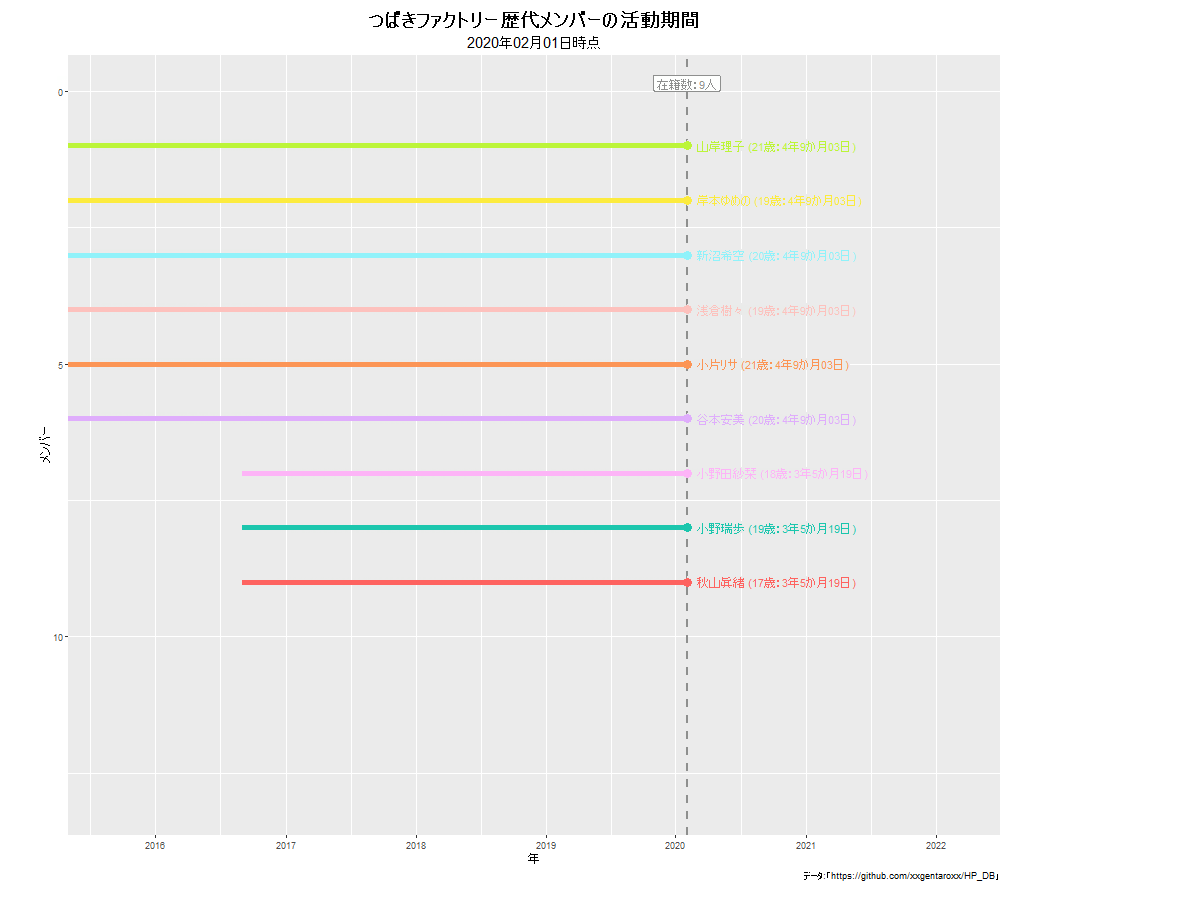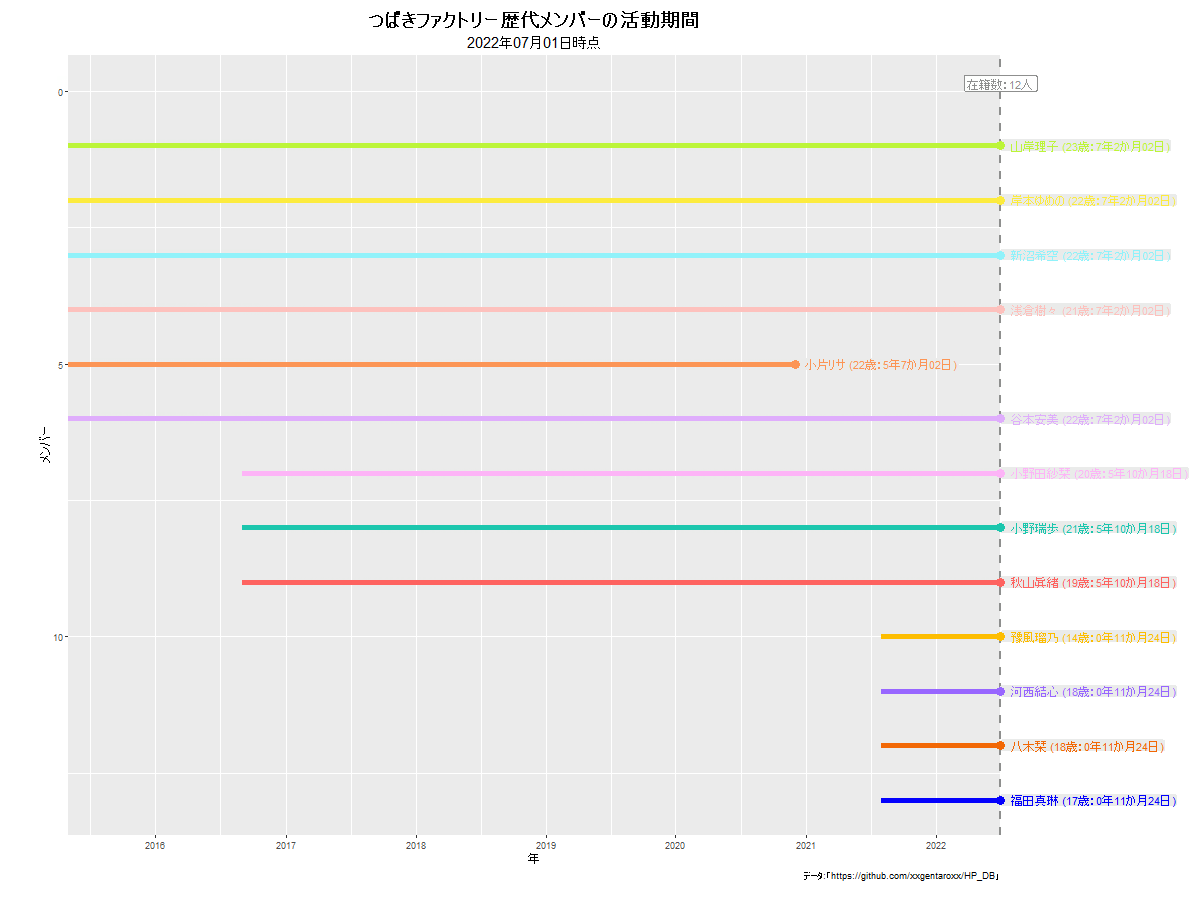

anim_save()でgif画像を保存します。
# gif画像を保存 gganimate::anim_save(filename = "output/ActivePeriod.gif", animation = g)
filename引数にファイルパス("(保存する)フォルダ名/(作成する)ファイル名.gif")、animation引数に作成したgif画像を指定します。
動画を作成する場合は、renderer引数を指定します。
# 動画を作成と保存 m <- gganimate::animate( plot = anim, nframes = n+ep, end_pause = ep, fps = mps, width = 1200, height = 900, renderer = gganimate::av_renderer(file = "output/ActivePeriod.mp4") )
renderer引数に、レンダリング方法に応じた関数を指定します。この例では、av_renderer()を使います。
av_renderer()のfile引数に保存先のファイルパス("(保存する)フォルダ名/(作成する)ファイル名.mp4")を指定します。
動画は貼れない(gifもなぜか貼れなかった)のでこれで代用します。
モーニング娘。歴代メンバーの活動期間一覧です🧋 pic.twitter.com/BS73SKhF2R
— しょこ📚 (@anemptyarchive) 2022年7月11日
おわりに
これまではバーチャートレースを作ってたのですが、ネタ切れ感もあって別の可視化をしてみました。このてのグラフに動きを付けても情報が増えないしなぁと思ってたのですが、意外とよくできたので気に入っています。他のグループでもできるので、ぜひ試してみてください。
メンバーカラーの変更に対応して線の色を変えることもできるとは思うのですが、ちょっと面倒そうなので今回は見送りました。いつか実装したいと思ってます。
ところで、このグラフって本当にタイムラインって呼ぶんですか?
2022年7月13日はOCHA NORMAのメジャーデビュー日です!!!!
めでたい!!!祭りだ!!!