はじめに
『ゼロから作るDeep Learning 4 ――強化学習編』の独学時のまとめノートです。初学者の補助となるようにゼロつくシリーズの4巻の内容に解説を加えていきます。本と一緒に読んでください。
この記事は、1.4.3節と1.4.4節の内容です。多腕バンディット問題の学習を行います。
【前節の内容】
【他の記事一覧】
【この記事の内容】
1.4.3 動かしてみる
「1.4.1:スロットマシンの実装【ゼロつく4のノート】 - からっぽのしょこ」で実装したBanditクラスと「1.4.2:エージェントの実装【ゼロつく4のノート】 - からっぽのしょこ」で実装したAgentクラスを使って、多腕バンディット問題を解きます。
利用するライブラリを読み込みます。
# 利用するライブラリ import numpy as np import matplotlib.pyplot as plt
・バンディット問題の学習
BanditクラスとAgentクラスのインスタンスを作成して、繰り返しプレイし学習を行います。
# 試行回数を指定 steps = 1000 # ランダムにマシンを選ぶ確率を指定 epsilon = 0.1 # マシンの数を指定 action_size = 10 # インスタンスを作成 bandit = Bandit(action_size) agent = Agent(epsilon, action_size) # 総報酬を初期化 total_reward = 0 # 記録用のリストを初期化 total_rewards = [] rates = [] all_rates = np.zeros((action_size, steps+1)) # 初期値を記録 all_rates[:, 0] = agent.Qs # 繰り返し試行 for step in range(steps): # ε-greedy法によりプレイするマシン番号を決定 action = agent.get_action() # action番目のマシンをプレイ reward = bandit.play(action) # action番目のマシンの推定価値を更新 agent.update(action, reward) # 報酬を加算 total_reward += reward # 更新値を記録 total_rewards.append(total_reward) rates.append(total_reward / (step + 1)) all_rates[:, step+1] = agent.Qs # 最終結果を確認 print(total_reward) print(rates[steps-1])
947
0.947
Agentクラスのget_action()で、ε-greedy法によりプレイするマシンを決定します。各マシンの価値の推定値は、Agentクラスのインスタンス変数として保存され、プレイする度にupdate()で更新します。
各マシンの価値の推定値とは別に、プレーヤーが得た報酬をtotal_rewardに加えていきます。total_rewardはその試行までの総報酬であり、推移の確認用にtotal_rewardsに格納します。
また、total_rewardを試行回数で割って平均報酬を求めてratesに格納していきます。
この例では、スロットマシンが当たれば報酬が1、外れれば報酬が0です(1.4.2項)。よって、総報酬は当たりの数、平均報酬は当たりの割合を表します。
総報酬と平均報酬の推移をグラフで確認します。
# 総報酬の推移のグラフを作成 plt.figure(figsize=(8, 6)) plt.plot(total_rewards) # 総報酬 plt.xlabel('Steps') plt.ylabel('Total reward') plt.suptitle('Total reward', fontsize=20) plt.title('$\epsilon='+str(epsilon)+'$', loc='left') # ランダムに行動する確率 plt.grid() plt.show() # 平均報酬の推移のグラフを作成 plt.figure(figsize=(8, 6)) plt.plot(rates) # 平均報酬 plt.xlabel('Steps') plt.ylabel('Rates') plt.suptitle('Average reward', fontsize=20) plt.title('$\epsilon='+str(epsilon)+'$', loc='left') # ランダムに行動する確率 plt.grid() plt.ylim(0, 1) plt.show()
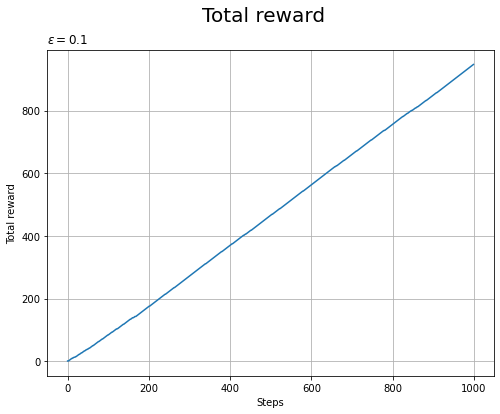
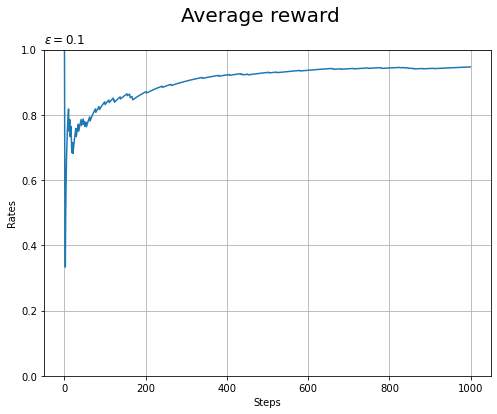
この例では、報酬が負の値にならないので、報酬の総和のグラフは増え続けます。
平均報酬のグラフを見ると、試行回数が増えるにつれて当たりの割合が高くなっていることから、学習が進んでいるのが分かります。ただし、初回が当たりになると当たりの割合が1になるので、学習後の割合の方が小さくなります。
最後に、各マシンの価値の推定値の推移をグラフで確認します。
# カラーマップを指定 cm = plt.get_cmap('hsv') # 各マシンの推定価値の推移のグラフを作成 plt.figure(figsize=(12, 9)) for arm in range(action_size): plt.plot(all_rates[arm], color=cm(arm/action_size), alpha=0.5) # 推定価値の推移 plt.hlines(y=bandit.rates[arm], xmin=0, xmax=steps, color=cm(arm/action_size), linestyle=':') # 真の価値 plt.xlabel('Steps') plt.ylabel('Rates') plt.suptitle('Bandit Algorithms', fontsize=20) plt.title('$\epsilon='+str(epsilon)+'$', loc='left') # ランダムに行動する確率 plt.grid() plt.show()
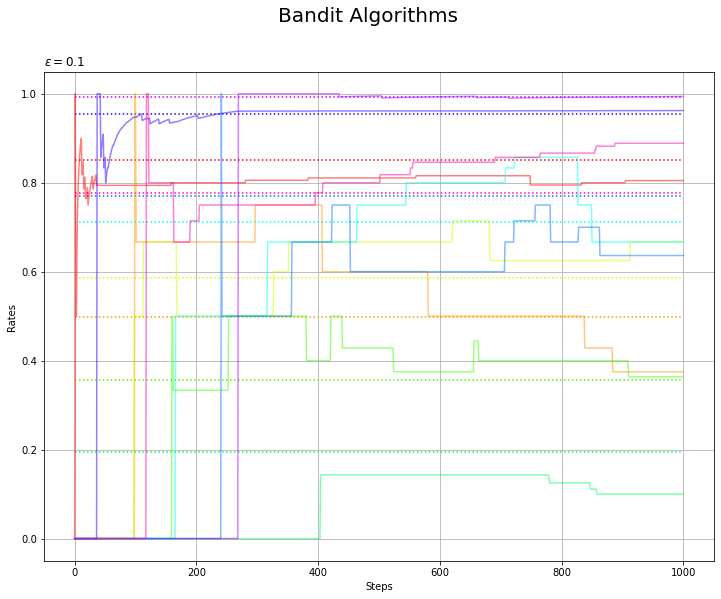
推定価値(実線)が真の価値(点線)に近付いていくことから、(概ね)推定できているのが分かります。このグラフについては「1.2:バンディット問題【ゼロつく4のノート】 - からっぽのしょこ」を参照してください。
最終的な結果も確認してみます。
真の価値(各マシンの確率)と推定価値(各マシンの報酬の標本平均)を確認します。
# 真の価値を確認 print(np.round(bandit.rates, 3)) # 推定価値を確認 print(np.round(agent.Qs, 3))
[0.851 0.498 0.587 0.355 0.195 0.711 0.77 0.955 0.992 0.777]
[0.805 0.375 0.667 0.364 0.1 0.667 0.636 0.962 0.994 0.889]
各マシンのプレイ回数を確認します。
# 各マシンのプレイ回数を確認 print(agent.ns) # ランダムにプレイする回数の期待値を計算 print(steps / action_size * epsilon)
[ 41. 8. 9. 11. 10. 9. 11. 213. 670. 18.]
10.0
真の価値が高いマシンを多く選ばれているのが分かります。また、真の価値が低いマシンもepsilonに応じて選ばれているのが分かります。
取り出して確認します。
# 真の価値が最大のマシン番号を確認 print(np.argmax(bandit.rates)) # プレイ回数が最大のマシン番号を確認 print(np.argmax(agent.ns))
8
8
真の価値の最大値と平均報酬を確認します。
# 真の価値の最大値を確認 print(np.max(bandit.rates)) # 平均報酬 print(rates[-1])
0.9917131187188237
0.947
以上で、推定される過程を確認できました。次節では、平均を求めます。
1.4.4 アルゴリズムの平均的な性質
前節では、学習を1回行いました。この節では、複数回行うことで、学習のランダム性を緩和します。
利用するライブラリを読み込みます。
# 利用するライブラリ import numpy as np import matplotlib.pyplot as plt
・実験結果の平均
前節と同じ処理を複数回行って、平均を求めます。
# 実験回数を指定 runs = 200 # 実験1回当たりの試行回数を指定 steps = 1000 # マシンの数を指定 action_size = 10 # ランダムにマシンを選ぶ確率を指定 epsilon = 0.1 # 記録用の配列を初期化 all_rates = np.zeros((runs, steps)) # 繰り返し実験 for run in range(runs): # インスタンスを作成(マシンの確率を初期化) bandit = Bandit(action_size) agent = Agent(epsilon, action_size) # 記録用のオブジェクトを初期化 total_reward = 0 rates = [] # 繰り返し試行 for step in range(steps): # マシンをプレイ action = agent.get_action() reward = bandit.play(action) # マシンの推定価値を更新 agent.update(action, reward) # 報酬を記録 total_reward += reward rates.append(total_reward / (step + 1)) # 実験結果を記録 all_rates[run] = rates # 試行ごとに平均を計算 avg_rates = np.average(all_rates, axis=0) print(avg_rates[steps-1])
0.8382350000000003
1回の実験における平均報酬の推移をratesに格納します。
また、全ての実験の平均報酬の推移をall_ratesに格納します。all_ratesの各行が各実験、各列が各試行に対応します。
最後に、all_ratesを試行ごとに(列ごとに)平均をとりavg_ratesとします。avg_ratesが推移の平均になります。
全ての実験の推移と平均推移をグラフで確認します。
# 実験結果を作図 plt.figure(figsize=(8, 6)) for run in range(runs): plt.plot(all_rates[run], alpha=0.1) # 実験ごとの平均報酬の推移 plt.plot(avg_rates, color='red', label='average') # 全ての実験で平均した平均報酬の推移 plt.xlabel('Steps') plt.ylabel('Rates') plt.title('$runs:'+str(runs) + ', \epsilon='+str(epsilon)+'$', loc='left') # 実験の設定 plt.suptitle('Average reward', fontsize=20) plt.grid() plt.legend() plt.ylim(0, 1) plt.show()
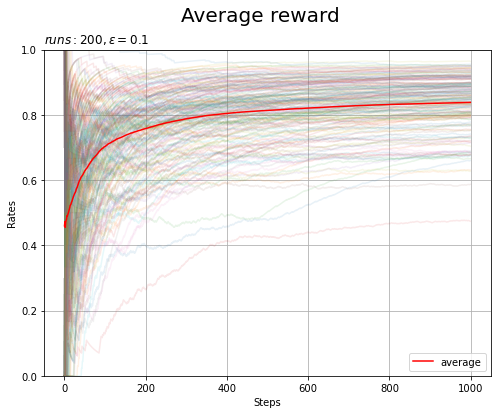
複数回実験した結果でも学習できているのが分かりました。
・ランダムに行動する確率の影響
先ほどは、$\epsilon = 0.1$として学習の推移を確認しました。今度は、$\epsilon$の値を変更して比較します。
# 実験回数を指定 runs = 200 # 実験1回当たりの試行回数を指定 steps = 10000 # ランダムにマシンを選ぶ確率を指定 epsilon_list = [0.01, 0.05, 0.1, 0.3, 0.5] # マシンの数を指定 action_size = 10 # 報酬の記録用の配列を初期化 all_rates = np.zeros((runs, steps)) all_avg_rates = np.zeros((len(epsilon_list), steps)) # 割引率を切り替え for i, epsilon in enumerate(epsilon_list): # 実験の設定を表示 print('epsilon =', epsilon) # 繰り返し実験 for run in range(runs): # インスタンスを作成:(マシンの確率を初期化) bandit = Bandit(action_size) agent = Agent(epsilon, action_size) # 記録用の配列を初期化 total_reward = 0 rates = [] # 繰り返し試行 for step in range(steps): # マシンを実行 action = agent.get_action() reward = bandit.play(action) # 値を更新 agent.update(action, reward) total_reward += reward rates.append(total_reward / (step + 1)) # 実験結果を記録 all_rates[run] = rates # 試行ごとの平均を計算 avg_rates = np.average(all_rates, axis=0) print(avg_rates[steps-1]) # epsilonごとの実験結果を記録 all_avg_rates[i] = avg_rates
epsilon = 0.01
0.8657140000000001
epsilon = 0.05
0.8815469999999997
epsilon = 0.1
0.8621785000000005
epsilon = 0.3
0.7735714999999999
epsilon = 0.5
0.7048394999999996
比較する$\epsilon$の値をepsilon_listに指定します。
for文を使って、epsilon_listの値を取り出して先ほどの実験を行います。
$\epsilon$ごとの実験結果の平均をグラフで確認します。
# 実験結果を作図 plt.figure(figsize=(8, 6)) for i, epsilon in enumerate(epsilon_list): plt.plot(all_avg_rates[i], label='$\epsilon='+str(epsilon)+'$') # 実験ごとの平均報酬 plt.xlabel('Steps') plt.ylabel('Rates') plt.title('runs:' + str(runs), loc='left') # 実験回数 plt.suptitle('Bandit Algorithms', fontsize=20) plt.grid() plt.legend() plt.ylim(0, 1) plt.show()
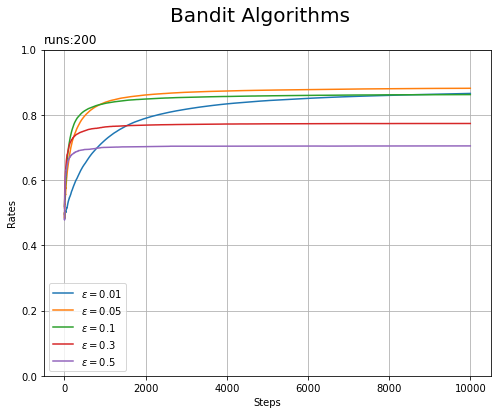
値が小さいと学習が遅くなり、値が大きいと学習が進まないのが分かります。
以上で、確率の設定が変わらないバンディット問題の学習を行なえました。次節からは、確率の設定が変わるバンディット問題を考えます。
参考文献
- 斎藤康毅『ゼロから作るDeep Learning 4 ――強化学習編』オライリー・ジャパン,2022年.
- サポートページ:GitHub - oreilly-japan/deep-learning-from-scratch-4
おわりに
初めて触れる分野なので用語の使い方に詰まります。
【次節の内容】