はじめに
『ゼロから作るDeep Learning 4 ――強化学習編』の独学時のまとめノートです。初学者の補助となるようにゼロつくシリーズの4巻の内容に解説を加えていきます。本と一緒に読んでください。
この記事は、付録A節の内容です。方策オフ型のモンテカルロ法により行動価値関数を推定します。
【前節の内容】
【他の記事一覧】
【この記事の内容】
付録A 方策オフ型のモンテカルロ法
方策オフ型のモンテカルロ法により行動価値関数と方策を推定することを考えます。
A.1 方策オフ型のモンテカルロ法の理論
まずは、行動価値関数の計算を数式で確認します。
・数式の確認
行動価値関数の近似式を導出します。モンテカルロ法の近似計算については「5.2:モンテカルロ法による方策評価【ゼロつく4のノート】 - からっぽのしょこ」と「
5.4.1-2:モンテカルロ法による方策制御【ゼロつく4のノート】 - からっぽのしょこ]」、重点サンプリングについては「5.5:重点サンプリング【ゼロつく4のノート】 - からっぽのしょこ」を参照してください。
・行動価値関数の近似式
重点サンプリング(方策オフ型)の場合の行動価値関数の計算式を確認します。
行動価値関数は、現在の状態 𝑠 で行動 𝑎 を行った後の収益 𝐺 の期待値で定義されました(3.3.1項)。
また、方策オン型のモンテカルロ法では、サンプリングした収益$G^{(i)}$の標本平均を行動価値関数の推定値$Q_{\pi}(s, a)$とするのでした(5.4.1項)。
収益のサンプリングについて、簡易的に$G^{(i)} \sim \pi$で表しています。実際には、確率論的方策に従う行動のサンプリング$a \sim \pi(a | s)$と、状態遷移確率に従う遷移$s' \sim p(s' | s, a)$、報酬関数$r(s, a, s')$の影響を受けて収益のサンプル$G^{(i)}$が得られます(2.2節)。
方策オフ型のモンテカルロ法では、$\pi(a | s)$をターゲット方策として、挙動方策(サンプリング用の確率論的方策)$b(a | s)$からサンプリングを行います。
ここで、$\rho$はターゲット方策$\pi$と挙動方策$b$を対応付ける重みで、収益のサンプル$G^{(i)}$ごとに異なります。
・重みの計算式
続いて、重みの計算式を導出します。
モンテカルロ法ではゴールに辿り着くまでを1エピソードとするので、ゴールの状態を$S_T$とすると、時刻$t$の収益$G_t$は、次の式で定義されます(2.3.2項・3.1.2項)。
ここで、$T$は、1エピソードの総時刻を表し、エピソードごとに値が異なります。$\gamma$は割引率です。
つまり、収益$G_t$は、時刻$j = t, t+1, \cdots, T-1$の状態$S_j$、行動$A_j$、報酬$R_j$と最後(ゴール)の状態$S_T$により求まります。
よって、収益$G_t$(サンプルデータ$S_t, A_t, R_t, \cdots, S_T$)が得られる確率は、時刻$t$以降の状態と行動の同時確率で表せます。(報酬は、報酬関数により決定論的に得られると想定しているので、確率に影響しません。)
状態遷移確率$p(s' | s, a)$と混同しないように、収益が得られる確率を$\mathrm{Pr}(\cdot)$で表すことにします。また、ターゲット方策$\pi(a | s)$からサンプリングすることを、条件に$\pi$を書いて示します。
挙動方策$b(a | s)$から行動をサンプリングする場合は、条件を$b$として表します。
状態価値関数は共通するので条件には表記しないことにします。
重点サンプリングにおける重みは、サンプルがターゲット方策$\pi$から得られる確率と挙動方策$b$から得られる確率の比で定義されるので、次の式で計算できます(5.5.2項)。
各同時確率(分母分子)の計算式を考えます。
マルコフ過程を仮定しているので、各時刻の行動と状態はそれぞれ1つ前の状態や行動のみに依存します(それより前の影響を受けません)(2.1節)。
また、行動価値関数の計算において、時刻$t$の状態$S_t = s$と行動$A_t = a$は与えられて(決まって)おり、確率に影響しません。
よって、ターゲット方策から収益$G_t$が得られる確率は、時刻$t + 1$以降の状態遷移確率と確率論的方策の積に分解できます。
挙動方策の場合も同様です。
ターゲット方策による確率(A.3)と挙動方策による確率(A.2)は、状態遷移確率の項が共通しています。
重みの計算式にそれぞれ代入して、式を整理します。
状態遷移確率の項が分母分子で打ち消し合うので、重み$\rho$は、全ての時刻のターゲット方策と挙動方策の比$\frac{\pi(A_j | S_j)}{b(A_j | S_j)}$の積で計算できることが分かりました。(報酬が確率論的に得られる場合も、ここで打ち消されて同じ計算式になります。)
・重みの再帰計算
最後に、効率良く実装(処理)する方法(計算)を考えます。
時刻$t$の収益(のサンプル)$G_t$の重みを$\rho_t$とします。
次の時刻$t + 1$の収益$G_{t+1}$の重みも同様に求められるので
となります。
$G_t$の重み(A.4)は、$\rho_{t+1}$を使って計算できます。
この式により、全て($t$から$T - 1$)の時刻の重みは次の時刻の重みを使って再帰的に計算できます。
ただし、時刻$T$は、ゴールに辿り着いて(エピソードが終了して)いるので、報酬が存在せず収益が定義されません。
また、1つ前の時刻$T - 1$の収益$G_{T-1}$の計算において、状態$S_{T-1}$と行動$A_{T-1}$は与えられているので、$G_{T-1}$が得られる確率は
ターゲット方策と挙動方策の影響を受けず、1になります。
したがって、重みの初期値を$\rho = 1$としておき、後の時刻から順番にターゲット方策と挙動方策の比$\frac{\pi(A_j | S_j)}{b(A_j | S_j)}$を計算して$\rho$に掛けていくことで、効率的に処理できます。
「時刻$t$の収益のサンプル$G_t^{(n)}$」と「時刻$t$の状態$S_t$と行動$A_t$の行動価値$Q_n(S_t, A_t)$」の関係については「5.2:モンテカルロ法による方策評価【ゼロつく4のノート】 - からっぽのしょこ」を参照してください(状態価値関数$V_n(S_t)$との関係ですが、対応関係は同様です)。
A.2 方策オフ型のモンテカルロ法の実装
次は、方策オフ型のモンテカルロ法により行動価値関数の計算と方策の制御を行うエージェントを実装します。
利用するライブラリを読み込みます。
# ライブラリを読み込み import numpy as np from collections import defaultdict # 追加ライブラリ import matplotlib.pyplot as plt from matplotlib.colors import LinearSegmentedColormap from matplotlib.animation import FuncAnimation
推移をアニメーションで確認するのにanimationモジュールを利用します。不要であれば省略してください。
また、3×4マスのグリッドワールドのクラスGridWorldを読み込みます。
# 実装済みのクラスと関数を読み込み import sys sys.path.append('../deep-learning-from-scratch-4-master') from common.gridworld import GridWorld from common.utils import greedy_probs
実装済みクラスの読み込みについては「3.6.1:MNISTデータセットの読み込み【ゼロつく1のノート(Python)】 - からっぽのしょこ」、GridWorldクラスについては「4.2.1:GridWorldクラスの実装:評価と改善に関するメソッド【ゼロつく4のノート】 - からっぽのしょこ」「4.2.1:GridWorldクラスの実装:可視化に関するメソッド【ゼロつく4のノート】 - からっぽのしょこ」、greedy_probs関数については「5.4.3-5:モンテカルロ法による方策反復法の実装【ゼロつく4のノート】 - からっぽのしょこ」を参照してください。
・処理の確認
McOffPolycyAgentクラスのupdateメソッドの内部で行う処理を確認します。他のメソッドについては4.4.2項を参照してください。
全ての状態のターゲット方策と挙動方策、また行動価値を格納するディクショナリを作成します。
# 確率論的方策用の確率分布を指定 random_actions = {0: 0.25, 1: 0.25, 2: 0.25, 3: 0.25} # ターゲット方策を初期化 pi = defaultdict(lambda: random_actions) print(pi.items()) # 挙動方策を初期化 b = defaultdict(lambda: random_actions) print(b.items()) Q = defaultdict(lambda: 0.0) print(Q.items())
dict_items([])
dict_items([])
dict_items([])
各状態の確率論的方策の初期値をrandom_actionsとして、全ての状態の確率論的方策を格納するディクショナリを作成します。ターゲット方策をpi、挙動方策をbとします。
行動価値関数をVとして、全ての状態で初期値を0とします。
収益と重みのオブジェクトを作成します。
# 収益を初期化 G = 0.0 # 重みを初期化 rho = 1.0
収益Gの初期値を0として作成します。収益のサンプルを得る(取り出す)たびに、値を割り引いて報酬を加えていきます。
重みrhoの初期値を1として作成します。状態のサンプルを得る(取り出す)たびに、2つの方策の比を掛けていきます。
ダミーのサンプルデータを指定します。
# (仮の)状態・行動・報酬を指定 state = (1, 2) action = 2 reward = 1 # 行動価値関数用のキーを作成 key = (state, action) print(key)
((1, 2), 2)
環境(グリッドワールド)とのやり取りの中で、インスタンス変数(リスト)memoryに格納された1つのサンプルデータに対応します。
収益を計算(更新)して、行動価値関数を計算(更新)します。
# 割引率を指定 gamma = 0.1 alpha = 0.2 # 収益を計算 G = gamma * rho * G + reward print(G) # 行動価値関数を計算:図(5.16) Q[key] += (G - Q[key]) * alpha print(Q.keys()) print(Q.values())
1.0
dict_keys([((1, 2), 2)])
dict_values([0.2])
収益を計算します。計算式についてはA.1項を参照してください。
行動価値関数を計算します。計算式については5.4.4項を参照してください。
重みを計算(更新)します。更新した重みは、次の収益の計算に使います。
# 重みを計算 rho *= pi[state][action] / b[state][action] print(rho)
1.0
ターゲット方策と挙動方策それぞれの、状態stateで行動actionを取る確率の比を計算します。
全ての状態の方策を格納するディクショナリpi, bから状態stateの方策を取り出し、さらに取り出した方策(確率分布)のディクショナリpi[state], b[state]から行動actionの確率を取り出して計算します。
行動価値に応じて方策を更新します。
# ランダムに行動する確率を指定 epsilon = 0.1 # ターゲット方策をgreedy化:式(5.3) pi[state] = action_probs = greedy_probs(Q, state, epsilon=0.0) print(pi.keys()) print(pi.values()) # 挙動方策をε-greedy化:図(5.18) b[state] = action_probs = greedy_probs(Q, state, epsilon=epsilon) print(b.values())
dict_keys([(1, 2)])
dict_values([{0: 0.0, 1: 0.0, 2: 1.0, 3: 0.0}])
dict_values([{0: 0.025, 1: 0.025, 2: 0.925, 3: 0.025}])
ランダムに行動する確率epsilonを指定して、greedy_probs()で方策を更新します。ランダムな行動確率の引数epsilonに0を指定するとgreedy化、epsilonを指定するとε-greedy化します。
ターゲット方策piは、最適方策とするためgreedy化します。
挙動方策bは、探索を行うためε-greedy化します。
greedy_probs()の処理の中で、状態stateにおける全ての行動の価値を取り出されるので、初期値が格納されます。
# 行動価値を確認 print(Q.keys()) print(Q.values())
dict_keys([((1, 2), 2), ((1, 2), 0), ((1, 2), 1), ((1, 2), 3)])
dict_values([0.2, 0.0, 0.0, 0.0])
(ディクショナリに値が格納された順に並んでいるので、行動番号に対応していません。状態が遷移した場合も同様です。)
ここまでが、1つのサンプルデータに対する処理です。次のサンプルデータに対する処理として、もう一度同じ計算を行います。
# (仮の)状態・行動・報酬を指定 state = (1, 2) action = 0 reward = 10 # 行動価値関数用のキーを作成 key = (state, action) # 収益を計算 G = gamma * rho * G + reward print(G) # 行動価値関数を計算:図(5.16) Q[key] += (G - Q[key]) * alpha print(Q.keys()) print(Q.values()) # 重みを計算 rho *= pi[state][action] / b[state][action] print(rho) # ターゲット方策をgreedy化:式(5.3) pi[state] = action_probs = greedy_probs(Q, state, epsilon=0.0) print(pi.keys()) print(pi.values()) # 挙動方策をε-greedy化:図(5.18) b[state] = action_probs = greedy_probs(Q, state, epsilon=epsilon) print(b.values())
10.1
dict_keys([((1, 2), 2), ((1, 2), 0), ((1, 2), 1), ((1, 2), 3)])
dict_values([0.2, 2.02, 0.0, 0.0])
0.0
dict_keys([(1, 2)])
dict_values([{0: 1.0, 1: 0.0, 2: 0.0, 3: 0.0}])
dict_values([{0: 0.925, 1: 0.025, 2: 0.025, 3: 0.025}])
価値が最大となる行動が変わると、確率が最大の行動も変わります。ただし、greedy化またはε-greedy化するので、ランダムな行動確率などの値自体は変わりません。
実際の推定処理では、インスタンス変数memoryの後からサンプルデータ(状態・行動・報酬)を取り出して、これらの処理を繰り返します。後のサンプルから計算する理由については5.2節とA.1項を参照してください。
以上が、方策オフ型のモンテカルロ法による方策制御を行うエージェントの処理です。
・実装
処理の確認ができたので、方策オフ型のマルコフ法におけるエージェントの処理をクラスとして実装します。
# 方策オフ型のマルコフ法におけるエージェントの実装 class McOffPolycyAgent: # 初期化メソッドの定義 def __init__(self): # 値の設定 self.gamma = 0.9 # 収益の計算用の割引率 self.epsilon = 0.1 # ランダムに行動する確率 self.alpha = 0.2 # 行動価値の計算用の割引率 self.action_size = 4 # 行動の種類数 # オブジェクトの初期化 random_actions = {0: 0.25, 1: 0.25, 2: 0.25, 3: 0.25} # 確率論的方策用の確率分布 self.pi = defaultdict(lambda: random_actions) # ターゲット方策 self.b = defaultdict(lambda: random_actions) # 挙動方策 self.Q = defaultdict(lambda: 0) # 行動価値関数 self.memory = [] # サンプルデータ # 行動メソッドの定義 def get_action(self, state): # 現在の状態における挙動方策の確率分布を取得 action_probs = self.b[state] actions = list(action_probs.keys()) # 行動番号 probs = list(action_probs.values()) # 行動確率 # 確率論的方策による行動を出力 return np.random.choice(actions, p=probs) # 記録メソッドの定義 def add(self, state, action, reward): # 現在の時刻におけるサンプルデータをタプルに格納 data = (state, action, reward) # サンプルを格納 self.memory.append(data) # サンプルデータの初期化メソッドの定義 def reset(self): # 記録用のリストを初期化 self.memory.clear() # 方策の計算メソッドの定義 def update(self): # 行動価値関数を計算して、方策を作成 G = 0 rho = 1 for data in reversed(self.memory): # 各時刻におけるサンプルデータを取得 state, action, reward = data key = (state, action) # 収益を計算 G = self.gamma * rho * G + reward # 行動価値関数を計算:図(5.16) self.Q[key] += (G - self.Q[key]) * self.alpha # 重みを計算 rho *= self.pi[state][action] / self.b[state][action] # ターゲット方策をgreedy化:式(5.3) self.pi[state] = greedy_probs(self.Q, state, epsilon=0.0) # 挙動方策をε-greedy化:図(5.18) self.b[state] = greedy_probs(self.Q, state, epsilon=self.epsilon)
方策オン型のMcAgentクラスのget_actionメソッドでは、方策piに従う行動を出力しました。方策オフ型のMcOffPolycyAgentクラスでは、挙動方策bに従う行動を出力します。
実装したクラスを試してみましょう。
環境(グリッドワールド)とエージェントのインスタンスを作成します。
# 環境とエージェントのインスタンスを作成 env = GridWorld() agent = McOffPolycyAgent() # 最初の状態を取得 state = env.start_state print(state) # 1エピソードのシミュレーション while True: # 挙動方策に従い行動を決定 action = agent.get_action(state) # サンプルデータを取得 next_state, reward, done = env.step(action) # サンプルデータを格納 agent.add(state, action, reward) # ゴールに着いた場合 if done: # ループを終了 break # 状態を更新 state = next_state print(next_state)
(2, 0)
(0, 3)
agentのget_action()で方策に従い行動して、envのstep()で状態を遷移し報酬を出力します。現在の状態・行動・報酬をagentのadd()で記録します。
ゴールマスに着くとdoneがTrueになるので、breakでループ処理を終了します。
サンプルデータがmemoryに格納されているのを確認します。
# サンプルデータを確認 print(agent.memory[:5]) print(len(agent.memory))
[((2, 0), 2, 0), ((2, 0), 2, 0), ((2, 0), 3, 0), ((2, 1), 0, 0), ((2, 1), 3, 0)]
51
update()メソッドで行動価値関数と方策を計算します。
# (確認用に)状態を指定 state = (0, 2) # 行動価値関数と方策を確認 print(agent.Q.values()) print(agent.pi[state].values()) print(agent.b[state].values()) # 行動価値関数と方策を計算 agent.update() # 行動価値関数と方策を確認 print(np.round([agent.Q[(state, action)] for action in range(agent.action_size)], 4)) print(agent.pi[state].values()) print(agent.b[state].values())
dict_values([])
dict_values([0.25, 0.25, 0.25, 0.25])
dict_values([0.25, 0.25, 0.25, 0.25])
[0. 0. 0.162 0.2 ]
dict_values([0.0, 0.0, 0.0, 1.0])
dict_values([0.025, 0.025, 0.025, 0.925])
サンプルとして得られなかった状態はagent.Qに含まれません。
全ての行動で等しい確率に初期化されターゲット方策piと挙動方策bが、それぞれgreedy化・ε-greedy化されているのが分かります。
reset()でサンプルデータを削除します。
# サンプルデータを削除 agent.reset() print(agent.memory)
[]
この項では、方策オフ型のモンテカルロ法により行動価値関数を計算するエージェントを実装しました。次項では、行動価値関数と方策を推定します。
・方策オフ型のモンテカルロ法による方策反復法の実装
5.4.5項では、方策オン型のモンテカルロ法により行動価値関数と方策を求めました。この項では、方策オフ型のモンテカルロ法により推定します。
・推定
重点サンプリングを用いたマルコフ法により行動価値関数を推定してgreedyな方策を求めます(方策を制御します)。
# インスタンスを作成 env = GridWorld() agent = McOffPolycyAgent() # エピソード数を指定 episodes = 1000 # 推移の可視化用のリストを初期化 trace_Q = [{(state, action): agent.Q[(state, action)] for state in env.states() for action in env.action_space}] # 初期値を記録 # 繰り返しシミュレーション for episode in range(episodes): # 状態を初期化(エージェントの位置をスタートマスに設定) state = env.reset() # サンプルデータを初期化 agent.reset() # 試行回数(時刻)を初期化 t = 0 # 1エピソードのシミュレーション while True: # 試行回数をカウント t += 1 # ε-greedy法(挙動方策)により行動を決定 action = agent.get_action(state) # サンプルデータを取得 next_state, reward, done = env.step(action) # サンプルデータを格納 agent.add(state, action, reward) # ゴールに着いた場合 if done: # 行動価値関数を計算 agent.update() # 更新値を記録 trace_Q.append(agent.Q.copy()) # 試行回数を表示 print('episode '+str(episode+1) + ': T='+str(t)) # ループを終了して次のエピソードへ break # 状態を更新 state = next_state
episode 1: T=28
episode 2: T=187
episode 3: T=54
episode 4: T=95
episode 5: T=109
episode 6: T=10
(省略)
episode 996: T=5
episode 997: T=7
episode 998: T=5
episode 999: T=5
episode 1000: T=6
スタートマスからゴールマスに着くまでを1エピソードとします。エピソードごとに、GridWorldクラスのreset()メソッドで状態を初期化し(エージェントをスタートマスに戻し)、OffPolicyMcAgentクラスのreset()メソッドでサンプルデータを初期化(過去のデータを削除)します。
episodesに指定した回数のシミュレーションを行い、繰り返し行動価値関数と方策を更新します。
推移の確認用に、行動価値関数の更新値をtrace_Qに格納していきます。
推定した行動価値関数をヒートマップで、greedy化した方策を矢印のラベルで確認します。
# 行動価値関数のヒートマップと方策ラベルを作図
env.render_q(q=agent.Q)
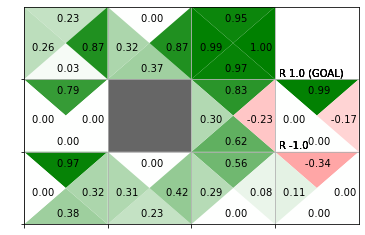
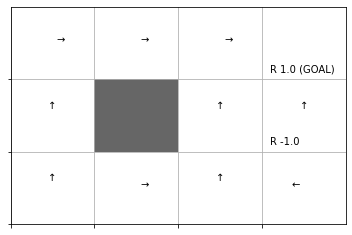
結果の解釈については本を参照してください。
・更新推移の可視化
ここまでで、繰り返しの更新処理を確認しました。続いて、途中経過をアニメーションで確認します。
行動価値関数のヒートマップのアニメーションを作成します。
・作図コード(クリックで展開)
# グリッドマップのサイズを取得 xs = env.width ys = env.height # 状態価値の最大値・最小値を取得 qmax = max([max(trace_Q[i].values()) for i in range(len(trace_Q))]) qmin = min([min(trace_Q[i].values()) for i in range(len(trace_Q))]) # 色付け用に最大値・最小値を再設定 qmax = max(qmax, abs(qmin)) qmin = -1 * qmax qmax = 1 if qmax < 1 else qmax qmin = -1 if qmin > -1 else qmin # カラーマップを設定 color_list = ['red', 'white', 'green'] cmap = LinearSegmentedColormap.from_list('colormap_name', color_list) # 図を初期化 fig = plt.figure(figsize=(12, 9), facecolor='white') # 図の設定 plt.suptitle('Off-policy Monte Carlo control', fontsize=20) # 全体のタイトル # 作図処理を関数として定義 def update(i): # 前フレームのグラフを初期化 plt.cla() # i回目の更新値を取得 Q = trace_Q[i] # マス(状態)ごとに処理 for state in env.states(): # 行動ごとに処理 for action in env.action_space: # インデックスを取得 y, x = state # 報酬を抽出 r = env.reward_map[y, x] # 報酬がある場合 if r != 0 and r is not None: # 報酬ラベル用の文字列を作成 txt = 'R ' + str(r) # ゴールの場合 if state == env.goal_state: # 報酬ラベルにゴールを追加 txt = txt + ' (GOAL)' # 報酬ラベルを描画 plt.text(x=x+0.1, y=ys-y-0.9, s=txt, ha='left', va='bottom', fontsize=15) # ゴールの場合 if state == env.goal_state: # 描画せず次の状態へ continue # 作図用のx軸・y軸の値を設定 tx, ty = x, ys-y-1 # 行動ごとの三角形の頂点を設定 action_map = { 0: ((0.5+tx, 0.5+ty), (1.0+tx, 1.0+ty), (tx, 1.0+ty)), # 上 1: ((tx, ty), (1.0+tx, ty), (0.5+tx, 0.5+ty)), # 下 2: ((tx, ty), (0.5+tx, 0.5+ty), (tx, 1.0+ty)), # 左 3: ((0.5+tx, 0.5+ty), (1.0+tx, ty), (1.0+tx, 1.0+ty)) # 右 } # 行動ごとの価値ラベルのプロット位置を設定 offset_map = { 0: (0.5, 0.75), # 上 1: (0.5, 0.25), # 下 2: (0.25, 0.5), # 左 3: (0.75, 0.5) # 右 } # 壁の場合 if state == env.wall_state: # 壁を描画 rect = plt.Rectangle(xy=(tx, ty), width=1, height=1, fc=(0.4, 0.4, 0.4, 1.0)) # 長方形を作成 plt.gca().add_patch(rect) # 重ねて描画 # (よく分からない) elif state in env.goal_state: plt.gca().add_patch(plt.Rectangle(xy=(tx, ty), width=1, height=1, fc=(0.0, 1.0, 0.0, 1.0))) # 壁以外の場合 else: # 行動価値を抽出 tq = Q[(state, action)] # 行動価値を0から1に正規化 color_scale = 0.5 + (tq / qmax) / 2 # 三角形を描画 poly = plt.Polygon(action_map[action],fc=cmap(color_scale)) # 三角形を作成 plt.gca().add_patch(poly) # 重ねて描画 # プロット位置の調整値を取得 offset = offset_map[action] # 行動価値ラベルを描画 plt.text(x=tx+offset[0], y=ty+offset[1], s=str(np.round(tq, 2)), ha='center', va='center', size=15) # 行動価値ラベル # グラフの設定 plt.xticks(ticks=np.arange(xs)) # x軸の目盛位置 plt.yticks(ticks=np.arange(ys), labels=ys-np.arange(ys)-1) # y軸の目盛位置 plt.xlim(xmin=0, xmax=xs) # x軸の範囲 plt.ylim(ymin=0, ymax=ys) # y軸の範囲 plt.tick_params(labelbottom=False, labelleft=False, labelright=False, labeltop=False) # 軸ラベル plt.grid() # グリッド線 plt.title('episode:'+str(i), loc='left') # タイトル # gif画像を作成 anime = FuncAnimation(fig=fig, func=update, frames=len(trace_Q), interval=50) # gif画像を保存 anime.save('ch5_A_2.gif')
各エピソードで更新した行動価値をtrace_Qから取り出してヒートマップを描画する処理を関数update()として定義して、FuncAnimation()でアニメーション(gif画像)を作成します。
行動価値関数の更新値の推移を折れ線グラフで確認します。
・作図コード(クリックで展開)
# 行動ラベルを指定 action_lt = ['Up', 'Down', 'Left', 'Right'] # 状態価値関数の推移を作図 plt.figure(figsize=(15, 10), facecolor='white') for state in env.states(): for action in range(agent.action_size): # 更新値を抽出 q_vals = [trace_Q[i][(state, action)] for i in range(episodes+1)] # 各状態の価値の推移を描画 plt.plot(np.arange(episodes+1), q_vals, label='$Q_i(L_{'+str(state[0])+','+str(state[1])+'},'+action_lt[action]+')$') plt.xlabel('episode') plt.ylabel('action-value') plt.suptitle('Monte Carlo Method', fontsize=20) plt.title('$\gamma='+str(agent.gamma) + ', \\alpha='+str(agent.alpha)+'$', loc='left') plt.grid() plt.legend(loc='upper left', bbox_to_anchor=(1, 1), ncol=2) plt.show()
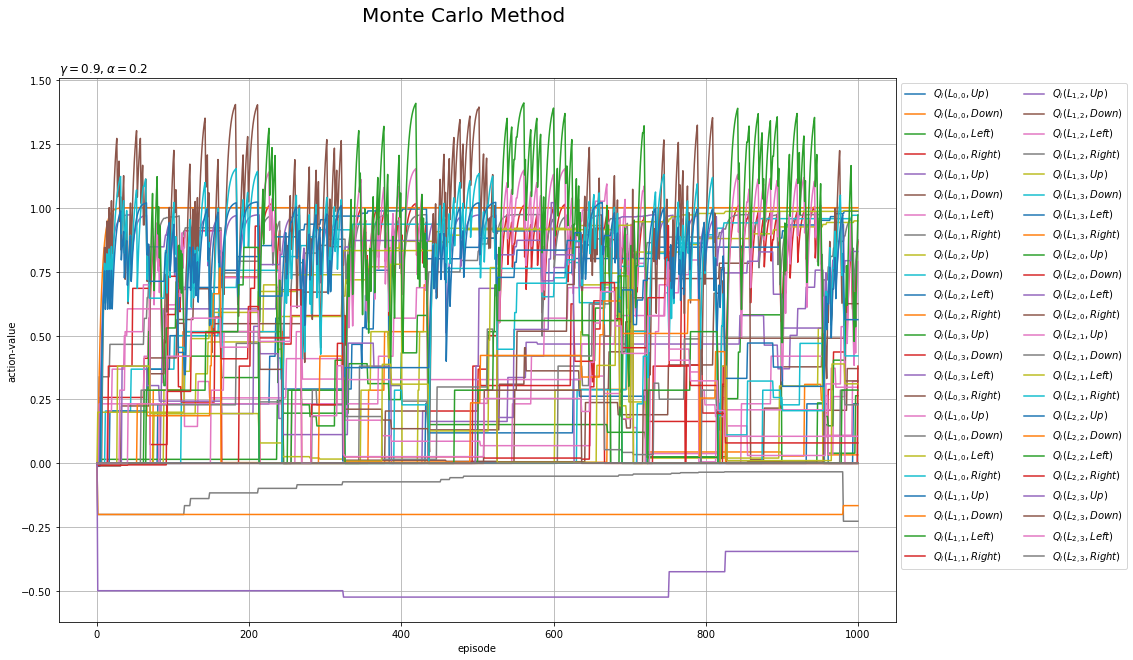
行番号を$h$、列番号を$w$として各マスを$L_{h,w}$で表します。また、$i$回目の状態(マス)$L_{h,w}$で行動$A$を取る価値を$Q_i(L_{h,w}, A)$で表します。マスのインデックスについては図4-9を参照してください。
各曲線の縦軸の値が、ヒートマップの色に対応します。
5章では、モンテカルロ法により行動価値関数を推定して、最適方策を求めました。
参考文献
- 斎藤康毅『ゼロから作るDeep Learning 4 ――強化学習編』オライリー・ジャパン,2022年.
- サポートページ:GitHub - oreilly-japan/deep-learning-from-scratch-4
おわりに
これで5章完了です!個人的には4章よりも進めやすくて良かったです。
【次節の内容】