はじめに
『ゼロから作るDeep Learning 4 ――強化学習編』の独学時のまとめノートです。初学者の補助となるようにゼロつくシリーズの4巻の内容に解説を加えていきます。本と一緒に読んでください。
この記事は、8.2節の内容です。DQNを実装して、カートポールを学習します。
【前節の内容】
【他の記事一覧】
【この記事の内容】
8.2 DQNのコア技術
DQNを実装します。
利用するライブラリを読み込みます。
# ライブラリを読み込み import gym import numpy as np import random from collections import deque import copy from dezero import Model from dezero import optimizers import dezero.functions as F import dezero.layers as L # 追加ライブラリ import matplotlib.pyplot as plt from matplotlib.animation import FuncAnimation
gymライブラリやカートポールの利用・作図については「8.1:OpenAI Gym:Classic Control【ゼロつく4のノート】 - からっぽのしょこ」を参照してください。
学習の推移をアニメーションで確認するのにmatplotlibのanimationモジュールのFuncAnimation関数を利用します。不要であれば省略してください。
8.2.2 経験再生の実装
DQNでは、各時刻(ステップ)で得られるサンプルデータ(経験データ)「状態・行動・報酬・次の状態(・終了フラグ)」を保存しておき、行動価値関数(Q関数)の更新時にランダムに取り出して利用します。経験データからミニバッチデータを作成する処理を経験再生と呼びます。経験再生の必要性については本を参照してください。
この項では、経験再生の処理を実装します。
処理の確認
ReplayBufferクラスの内部で行う処理を確認します。deque()については「6.2:SARSA【ゼロつく4のノート】 - からっぽのしょこ」も参照してください。
サンプルデータの一時保存用に、最大要素数を指定したリストを作成します。
# サンプルデータの保存数を指定 buffer_size = 10 # サンプルデータの一時保存用リストを初期化 buffer = deque(maxlen=buffer_size) print(buffer)
deque([], maxlen=10)
保存するデータ数buffer_sizeを指定して、deque()でリストを作成します。
ダミーのサンプルデータを繰り返し格納します。
# (ダミーの)サンプルデータを格納 for i in range(15): # (ダミーの)現在の状態・行動・報酬・次の状態・終了フラグを作成 state = (i, i, i, i) action = i reward = i next_state = (i, i, i, i) done = False # サンプルデータをタプルに格納 data = (state, action, reward, next_state, done) # サンプルデータを保存 buffer.append(data) # サンプルデータ数を表示 print(len(buffer))
1
2
3
4
5
6
7
8
9
10
10
10
10
10
10
リストの要素数がbuffer_sizeを超えないのが分かります。
サンプルデータをランダムに取り出します。
# ミニバッチのデータ数を指定 batch_size = 5 # ランダムにサンプルデータを抽出 data = random.sample(buffer, k=batch_size) print(data) print(len(data))
[((10, 10, 10, 10), 10, 10, (10, 10, 10, 10), False), ((14, 14, 14, 14), 14, 14, (14, 14, 14, 14), False), ((13, 13, 13, 13), 13, 13, (13, 13, 13, 13), False), ((5, 5, 5, 5), 5, 5, (5, 5, 5, 5), False), ((7, 7, 7, 7), 7, 7, (7, 7, 7, 7), False)]
5
randomモジュールのsample()でリスト内の要素を重複を許さずランダムに取り出します。
dataにはbatch_size個のタプルが格納されます。
サンプリング時刻ごとにまとまっているサンプルデータを、状態・行動・報酬・次の状態・終了フラグごとに分割します。
# 状態・行動・報酬・次の状態を抽出 state = np.stack([x[0] for x in data]) action = np.array([x[1] for x in data]) reward = np.array([x[2] for x in data]) next_state = np.stack([x[3] for x in data]) done = np.array([x[4] for x in data]).astype(np.int32) # 因子型から整数型に変換 print(state.shape) print(action.shape) print(reward.shape) print(next_state.shape) print(done.shape)
(5, 4)
(5,)
(5,)
(5, 4)
(5,)
リスト内包表記を使って、dataからそれぞれのデータを取り出してまとめます。xは、ある時刻における状態・行動・報酬・次の状態・終了フラグを格納したタプルです。それぞれ対応するインデックスを指定してリストに格納します。
状態は配列なので、リストに格納してnp.stack()で行方向に結合します。行動・報酬・終了フラグはスカラなので、リストに格納してnp.array()で配列に変換します。
また、フラグに関しては、np.astype(np.int32)で因子型から整数型に変換しておきます。
データ番号(サンプリング時刻)ごとに、各データを確認します。
# ミニバッチデータを確認 for n in range(batch_size): print('state : ' + str(state[n])) print('action : ' + str(action[n])) print('reward : ' + str(reward[n])) print('next state : ' + str(next_state[n])) print('done : ' + str(done[n]))
state : [10 10 10 10]
action : 10
reward : 10
next state : [10 10 10 10]
done : 0
state : [14 14 14 14]
action : 14
reward : 14
next state : [14 14 14 14]
done : 0
state : [13 13 13 13]
action : 13
reward : 13
next state : [13 13 13 13]
done : 0
state : [5 5 5 5]
action : 5
reward : 5
next state : [5 5 5 5]
done : 0
state : [7 7 7 7]
action : 7
reward : 7
next state : [7 7 7 7]
done : 0
因子型から整数型への変換を確認します。
# 因子型を格納 bool_arr = np.array([False, True]) # 整数型に変換 int_arr = bool_arr.astype(np.int32) print(bool_arr) print(int_arr)
[False True]
[0 1]
Falseは0、Trueは1になります。
整数にすることで、条件分岐を行わずにTDターゲットを計算できます。詳しくは7.4.3項の「更新メソッド」を参照してください。
以上が、経験再生の処理です。
実装
処理の確認ができたので、経験再生をクラスとして実装します。
# 経験再生の実装 class ReplayBuffer: # 初期化メソッドの定義 def __init__(self, buffer_size, batch_size): # サンプルデータの一時保存用リストを初期化 self.buffer = deque(maxlen=buffer_size) # ミニバッチのデータ数を設定 self.batch_size = batch_size # 追加メソッドの定義 def add(self, state, action, reward, next_state, done): # サンプルデータをタプルに格納 data = (state, action, reward, next_state, done) # サンプルデータを保存 self.buffer.append(data) # データ数メソッドの定義 def __len__(self): # サンプルデータ数を出力 return len(self.buffer) # ミニバッチデータの出力メソッドの定義 def get_batch(self): # サンプルデータをランダムに抽出 data = random.sample(self.buffer, self.batch_size) # 状態・行動・報酬・次の状態・終了フラグを抽出 state = np.stack([x[0] for x in data]) action = np.array([x[1] for x in data]) reward = np.array([x[2] for x in data]) next_state = np.stack([x[3] for x in data]) done = np.array([x[4] for x in data]).astype(np.int32) # 因子型から整数型に変換 return state, action, reward, next_state, done
実装したクラスを試してみましょう。
環境(カートポール)とエージェントのインスタンスを作成して、複数回のエピソードでサンプリングを繰り返します。ここでは、サンプリングが目的なので、学習は行いません。
実装できているかと次項での処理の確認のため、buffer_sizeとbatch_size以上のサンプルデータを格納しておきます。
# サンプルデータの保存数を指定 buffer_size = 100 # ミニバッチのデータ数を指定 batch_size = 32 # インスタンスを作成 env = gym.make('CartPole-v1') replay_buffer = ReplayBuffer(buffer_size, batch_size) # エピソード数を指定 episodes = 10 # 繰り返しシミュレーション for episode in range(episodes): # 状態を初期化 state, info = env.reset() done = False # 時刻を初期化 t = 0 # 1エピソードのシミュレーション while not done: # 時刻をカウント t += 1 # ランダムに行動を決定 action = np.random.choice([0, 1]) # 状態を遷移 next_state, reward, done, truncated, info = env.step(action) # サンプルデータを保存 replay_buffer.add(state, action, reward, next_state, done) # 状態を更新 state = next_state # サンプルデータ数を表示 print( 'episode ' + str(episode+1) + ', T=' + str(t) + ', buffer size:' + str(len(replay_buffer)) )
episode 1, T=11, buffer size:11
episode 2, T=34, buffer size:45
episode 3, T=29, buffer size:74
episode 4, T=13, buffer size:87
episode 5, T=23, buffer size:100
episode 6, T=30, buffer size:100
episode 7, T=14, buffer size:100
episode 8, T=19, buffer size:100
episode 9, T=18, buffer size:100
episode 10, T=20, buffer size:100
最初の状態からランダムに行動して、カートまたはポールが閾値を超えると(doneがTrueになると)エピソードが終了です。エピソードごとに、envのreset()で状態(カートとポール)を初期化し、終了フラグdoneをFalseに設定します。
時刻(ステップ)ごとに、envのstep()で状態を遷移し、得られたサンプルデータ(現在の状態・行動・報酬・次の状態。終了フラグ)をreplay_bufferのadd()で保存します。
各データのミニバッチデータを作成します。
# 現在の状態・行動・報酬・次の状態・終了フラグのミニバッチデータを取得 state, action, reward, next_state, done = replay_buffer.get_batch() print(state[:5].round(3)) print(state.shape) print(action[:5]) print(action.shape) print(reward[:5]) print(reward.shape) print(next_state[:5].round(3)) print(next_state.shape) print(done[:5]) print(done.shape)
[[ 0.019 -0.414 -0.04 0.556]
[-0.018 -0.414 0.099 0.736]
[ 0.012 -0.408 0.05 0.598]
[-0.085 -0.425 0.058 0.636]
[-0.044 -0.031 0.005 -0.014]]
(32, 4)
[0 0 1 0 1]
(32,)
[1. 1. 1. 1. 1.]
(32,)
[[ 0.01 -0.609 -0.029 0.836]
[-0.026 -0.61 0.114 1.058]
[ 0.004 -0.214 0.062 0.322]
[-0.094 -0.62 0.071 0.947]
[-0.044 0.164 0.005 -0.305]]
(32, 4)
[0 0 0 0 0]
(32,)
状態は2次元配列、行動・報酬・終了フラグは1次元配列になります。
この項では、DQNで利用する経験再生を実装しました。次項では、ターゲットネットワークを実装します。
8.2.4 ターゲットネットワークの実装
DQNでは、正解ラベル(TDターゲット)を一定期間固定するために、Q関数の計算を行うネットワークとは別に、TDターゲットの計算を行うためのターゲットネットワークを用います。ターゲットネットワークの必要性については本を参照してください。
この項では、3層のニューラルネットワークと、経験再生とターゲットネットワークの機能を持つエージェントを実装します。
実装:ニューラルネットワーク
まずは、Q関数やターゲットネットワークとして利用する3層のニューラルネットワークをクラスとして実装します。ニューラルネットワークの実装については「7.4:Q学習とニューラルネットワーク【ゼロつく4のノート】 - からっぽのしょこ」を参照してください。
# NNを用いたQ関数の実装 class QNet(Model): # 初期化メソッドの定義 def __init__(self, action_size): # 親クラスのメソッドを継承 super().__init__() # レイヤのインスタンスを作成 self.l1 = L.Linear(128) # 入力層 self.l2 = L.Linear(128) # 中間層 self.l3 = L.Linear(action_size) # 出力層 # 順伝播メソッドの定義 def forward(self, x): # NNを計算 x = F.relu(self.l1(x)) # 入力層 x = F.relu(self.l2(x)) # 中間層 x = self.l3(x) # 出力層 return x
中間層(隠れ層)のサイズ(ニューロン数)は、任意の整数を指定できます。出力層のサイズは、左右の2つの行動に対応するので2です。
活性化関数としてReLU関数を使います。
処理の確認:エージェント
次は、DQNAgentクラスのupdateメソッドの内部で行う処理を確認します。get_actionメソッドについては「7.4:Q学習とニューラルネットワーク【ゼロつく4のノート】 - からっぽのしょこ」を参照してください。
Q関数とターゲットネットワークのそれぞれとして利用するニューラルネットワークのインスタンスを作成します。
# 行動の種類数を設定 action_size = 2 # Q関数用のNNのインスタンスを作成 qnet = QNet(action_size) # ターゲットネットワーク用のNNのインスタンスを作成 qnet_target = QNet(action_size)
カートポールは2種類(左右に押す)の行動を取るので、QNetクラスのインスタンス作成時の引数に2を指定します。
最適化手法のインスタンスを作成して、Q関数用のニューラルネットワークのインスタンスを設定します。
# 勾配降下法用の学習率を指定 lr = 0.0005 # 最適化手法のインスタンスを作成 optimizer = optimizers.Adam(lr) # モデルを設定 optimizer.setup(qnet)
<dezero.optimizers.Adam at 0x1ea66ccbc70>
この例では、オプティマイザとしてAdamを利用します。
学習に利用するミニバッチデータを作成します。
# ミニバッチデータを取得 state, action, reward, next_state, done = replay_buffer.get_batch() print(state.shape) print(action.shape) print(reward.shape) print(next_state.shape) print(done.shape)
(32, 4)
(32,)
(32,)
(32, 4)
(32,)
8.2.2項の最後に作成したReplayBufferクラスのインスタンスreplay_bufferを利用します。batch_size以上のサンプルデータが格納されている必要があります。
ミニバッチデータとして取り出された状態ごとに、行動価値を計算します。
# 状態のサンプルごとに行動価値(Q関数NNの順伝播)を計算 qs = qnet(state) # 全ての行動 print(qs.data[:5].round(3)) print(qs.shape)
[[-0.116 -0.062]
[ 0.002 -0.174]
[-0.051 0.043]
[ 0.016 -0.023]
[-0.083 -0.009]]
(32, 2)
サンプリング時点の状態stateをQ関数のニューラルネットワークqnetに入力して順伝播を計算し、各状態における全ての行動価値qsを求めます。
batch_size行action_size列の2次元配列が出力されます。各行がデータ、各列が行動に対応します。
行動のミニバッチデータに対応する行動価値を取り出します。
# 行動番号を確認 print(action[:5]) # 行動のサンプルに応じた行動価値を抽出 q = qs[np.arange(batch_size), action] print(q.data[:5].round(3)) print(q.shape)
[1 0 0 1 0]
[-0.062 0.002 -0.051 -0.023 -0.083]
(32,)
actionをインデックスとして使って、qsの行(データ)ごとにサンプリングされた行動に対応する列を抽出します。
同様に、ターゲットネットワークを用いて、次の状態における全ての行動価値を計算します。
# 次の状態の状態ごとに行動価値(ターゲットNNの順伝播)を計算 next_qs = qnet_target(next_state) # 全ての行動 print(next_qs.data[:5].round(3)) print(next_qs.shape)
[[ 0.107 0.061]
[-0.19 0.109]
[-0.036 -0.046]
[ 0.031 0.018]
[ 0.013 0.007]]
(32, 2)
サンプリング時点の次の状態next_stateをターゲットネットワークqnet_targetに入力して順伝播を計算します。
データごとに行動価値の最大値を取り出します。
# 行動価値の最大値を抽出 next_q = next_qs.max(axis=1) print(next_q.data[:5].round(3)) print(next_q.shape) # 勾配の計算から除外 next_q.unchain()
[ 0.107 0.109 -0.036 0.031 0.013]
(32,)
np.max()で行(データ)ごとに最大値を抽出します。
TDターゲット(正解ラベル)を計算します。
# 収益の計算用の割引率 gamma = 0.98 # ターゲット(正解ラベル)を計算 target = reward + (1 - done) * gamma * next_q print(target.data.round(3)[:5]) print(target.shape)
[1.105 1.107 0.965 1.031 1.013]
(32,)
次の状態がエピソードの終了条件の場合は、行動価値が0なのでした。また、終了フラグdoneを整数型に変換して(1 - done)を掛けることで、条件分岐せずにTDターゲットを計算できるのでした(7.4.3項)。
正解ラベルtargetと行動価値の推定値qを使って、損失関数(損失レイヤの順伝播)として平均2乗誤差を計算します。
# 損失関数(損失レイヤの順伝播)を計算 loss = F.mean_squared_error(q, target) print(loss.data)
1.2232366530750893
(ちなみに、平均2乗誤差の計算において、差を2乗するので$(t - q)2 = (q - t)2$です。よって、target, qを引数に指定する順番は計算結果に影響しません。)
ここまでが順伝播の計算です。
2つのネットワークのパラメータを確認しておきます。
# Q関数NNとターゲットNNのパラメータを確認 print(qnet.l1.W.data[:5, :5].round(5)) print(qnet_target.l1.W.data[:5, :5].round(5))
[[-1.03818 -0.35128 -0.93529 0.29857 -0.01896]
[-0.15855 0.33951 0.26128 -0.22662 0.38711]
[-0.52156 -0.56969 0.21413 -0.60592 -0.66908]
[ 0.86168 -0.4002 0.09893 0.06456 -0.46271]]
[[-0.72459 -0.07635 -0.37949 -0.61383 -0.38521]
[-0.34167 0.28834 0.75089 0.10324 -0.43549]
[-0.48761 0.03648 -0.15202 -0.52449 -0.73869]
[ 0.21465 0.62343 -0.25167 -0.07325 0.0035 ]]
順伝播の計算しか行っていないので、どちらもランダムな初期値(正確にはXavierの初期値)です。
各レイヤのパラメータの勾配を計算して、パラメータを更新します。
# 勾配を初期化 qnet.cleargrads() # パラメータの勾配(逆伝播)を計算 loss.backward() # 勾配降下法によりQ関数NNのパラメータを更新 optimizer.update()
qnetの逆伝播メソッドbackward()で、各パラメータの勾配を計算します。
さらに、オプティマイザの更新メソッドupdate()で、各パラメータを更新します。
更新後のパラメータを確認します。
# Q関数NNとターゲットNNのパラメータを確認 print(qnet.l1.W.data[:5, :5].round(5)) print(qnet_target.l1.W.data[:5, :5].round(5))
[[-1.03768 -0.35178 -0.9348 0.29807 -0.01846]
[-0.15805 0.33901 0.26178 -0.22712 0.38761]
[-0.52206 -0.56919 0.21363 -0.60542 -0.66958]
[ 0.86118 -0.3997 0.09843 0.06506 -0.46321]]
[[-0.72459 -0.07635 -0.37949 -0.61383 -0.38521]
[-0.34167 0.28834 0.75089 0.10324 -0.43549]
[-0.48761 0.03648 -0.15202 -0.52449 -0.73869]
[ 0.21465 0.62343 -0.25167 -0.07325 0.0035 ]]
qnetのパラメータが少し変化しているのが分かります。qnet_targetのパラメータは更新されません。
Q関数のネットワークでターゲットネットワークを上書きします。
# Q関数NNとターゲットNNを同期 qnet_target = copy.deepcopy(qnet) # ターゲットNNのパラメータを確認 print(qnet_target.l1.W.data[:5, :5].round(5))
[[-1.03768 -0.35178 -0.9348 0.29807 -0.01846]
[-0.15805 0.33901 0.26178 -0.22712 0.38761]
[-0.52206 -0.56919 0.21363 -0.60542 -0.66958]
[ 0.86118 -0.3997 0.09843 0.06506 -0.46321]]
2つのニューラルネットワークのパラメータが一致しました。
以上が、DQNにおけるエージェントの処理です。
実装:エージェント
処理の確認ができたので、DQNにおけるエージェントをクラスとして実装します。
# DQNのエージェントの実装 class DQNAgent: # 初期化メソッドの定義 def __init__(self): # ハイパーパラメータを指定 self.gamma = 0.98 # 収益の計算用の割引率 self.lr = 0.0005 # 勾配降下法用の学習率 self.epsilon = 0.1 # ランダムに行動する確率 self.buffer_size = 10000 # サンプルデータの保存数 self.batch_size = 32 # ミニバッチのデータ数 self.action_size = 2 # 行動の種類数 # インスタンスを作成 self.replay_buffer = ReplayBuffer(self.buffer_size, self.batch_size) # サンプルデータの保存用リスト self.qnet = QNet(self.action_size) # Q関数(3層のNN) self.qnet_target = QNet(self.action_size) # ターゲットネットワーク(3層のNN) self.optimizer = optimizers.Adam(self.lr) # 最適化手法 self.optimizer.setup(self.qnet) # モデルを設定 # 同期メソッド def sync_qnet(self): # Q関数NNとターゲットNNを同期 self.qnet_target = copy.deepcopy(self.qnet) # 行動メソッドの定義 def get_action(self, state): # ε-greedy法により行動を決定:式(6.11) if np.random.rand() < self.epsilon: # ランダムに行動を出力 return np.random.choice(self.action_size) else: # 2次元配列に変換 state = state[np.newaxis, :] # 現在の状態における行動価値(Q関数NNの順伝播)を計算 qs = self.qnet(state) # 行動価値が最大の行動を出力 return qs.data.argmax() # 更新メソッドの定義 def update(self, state, action, reward, next_state, done): # サンプルデータを保存 self.replay_buffer.add(state, action, reward, next_state, done) # サンプルデータが足りない場合は更新しない if len(self.replay_buffer) < self.batch_size: return None # ミニバッチデータを取得 state, action, reward, next_state, done = self.replay_buffer.get_batch() # サンプルごとに現在の状態・行動の行動価値(Q関数NNの順伝播)を計算 qs = self.qnet(state) # 全ての行動 q = qs[np.arange(self.batch_size), action] # 各行動 # サンプルごとに次の状態の行動価値(ターゲットNNの順伝播)の最大値を計算 next_qs = self.qnet_target(next_state) # 全ての行動 next_q = next_qs.max(axis=1) # 最大値の行動 # 勾配の計算から除外 next_q.unchain() # ターゲット(正解ラベル)を計算 target = reward + (1 - done) * self.gamma * next_q # 損失関数(損失レイヤの順伝播)を計算 loss = F.mean_squared_error(q, target) # 勾配を初期化 self.qnet.cleargrads() # パラメータの勾配(逆伝播)を計算 loss.backward() # 勾配降下法によりQ関数NNのパラメータを更新 self.optimizer.update() # 損失を出力 return loss.data
推移の確認用に損失を出力するように変更しました。
実装したクラスを試してみましょう。
環境(カートポール)とエージェントのインスタンスを作成して、batch_sizeよりも多い総時刻(ステップ数)の処理を行います。
# 環境とエージェントのインスタンスを作成 env = gym.make('CartPole-v1') agent = DQNAgent() # 行動の表示用のリストを作成 arrows = ['←', '→'] # 最初の状態を設定 state, info = env.reset() done = False # 総時刻(ステップ数) T = 100 # 計算用のオブジェクトを初期化 total_loss = 0.0 total_reward = 0.0 # 推移の可視化用のリストを初期化 trace_loss = [] trace_reward = [] # 繰り返し試行 for t in range(T): # ε-greedy法により行動を決定 action = agent.get_action(state) # サンプルデータを取得 next_state, reward, done, truncated, info = env.step(action) # Q関数(NNのパラメータ)を更新 loss = agent.update(state, action, reward, next_state, done) # 合計損失・合計報酬を計算 if not len(agent.replay_buffer) < agent.batch_size: # サンプルデータが足りない場合は計算しない total_loss += loss total_reward += reward # サンプルデータを表示 print( 't=' + str(t) + ', S_t=' + str(state.round(3)) + ', A_t=' + arrows[action] + ', S_t+1=' + str(next_state.round(3)) + ', R_t=' + str(reward) + ', average loss=' + str(np.round(total_loss/(t+1), 3)) ) # 状態を更新 state = next_state # 平均損失・合計報酬を記録 trace_loss.append(total_loss / (t+1)) trace_reward.append(total_reward)
t=0, S_t=[-0.005 0.033 0.007 0.038], A_t=←, S_t+1=[-0.004 -0.162 0.008 0.333], R_t=1.0, average loss=0.0
t=1, S_t=[-0.004 -0.162 0.008 0.333], A_t=←, S_t+1=[-0.008 -0.357 0.015 0.628], R_t=1.0, average loss=0.0
t=2, S_t=[-0.008 -0.357 0.015 0.628], A_t=→, S_t+1=[-0.015 -0.162 0.027 0.34 ], R_t=1.0, average loss=0.0
t=3, S_t=[-0.015 -0.162 0.027 0.34 ], A_t=←, S_t+1=[-0.018 -0.358 0.034 0.641], R_t=1.0, average loss=0.0
t=4, S_t=[-0.018 -0.358 0.034 0.641], A_t=←, S_t+1=[-0.025 -0.553 0.047 0.944], R_t=1.0, average loss=0.0
(省略)
t=95, S_t=[-7.739 -5.923 2.347 -9.258], A_t=←, S_t+1=[-7.858 -6.047 2.162 -9.178], R_t=0.0, average loss=0.289
t=96, S_t=[-7.858 -6.047 2.162 -9.178], A_t=←, S_t+1=[-7.979 -6.161 1.978 -9.029], R_t=0.0, average loss=0.289
t=97, S_t=[-7.979 -6.161 1.978 -9.029], A_t=←, S_t+1=[-8.102 -6.271 1.798 -8.825], R_t=0.0, average loss=0.288
t=98, S_t=[-8.102 -6.271 1.798 -8.825], A_t=→, S_t+1=[-8.227 -6.017 1.621 -8.452], R_t=0.0, average loss=0.286
t=99, S_t=[-8.227 -6.017 1.621 -8.452], A_t=→, S_t+1=[-8.348 -5.769 1.452 -8.14 ], R_t=0.0, average loss=0.285
ここでは簡単に確認するために、回数を指定して(エピソードが終了しても)サンプリングを行います(警告メッセージが出ます)。
Q関数のネットワークとターゲットネットワークのパラメータを確認します。
# Q関数NNとターゲットNNのパラメータを確認 print(agent.qnet.l1.W.data[0, :5].round(3)) print(agent.qnet_target.l1.W.data[0, :5].round(3))
[ 0.597 -0.475 -0.935 0.736 -0.807]
[ 0.641 1.352 0.124 -0.024 1.066]
パラメータを同期します。
# Q関数NNとターゲットNNを同期 agent.sync_qnet() # Q関数NNとターゲットNNのパラメータを確認 print(agent.qnet.l1.W.data[0, :5].round(3)) print(agent.qnet_target.l1.W.data[0, :5].round(3))
[ 0.597 -0.475 -0.935 0.736 -0.807]
[ 0.597 -0.475 -0.935 0.736 -0.807]
この項では、DQNのエージェントを実装しました。次項では、DQNの学習を行います。
8.2.5 DQNを動かす
DQNを用いてカートポールの問題を解きます。
DQNの学習
カートポールに対するDQNの学習を実装します。ニューラルネットワークを用いたQ学習については「7.4:Q学習とニューラルネットワーク【ゼロつく4のノート】 - からっぽのしょこ」を参照してください。
DQNによりQ関数を繰り返し更新します。
# 環境とエージェントのインスタンスを作成 env = gym.make('CartPole-v1') agent = DQNAgent() # エピソード数を指定 episodes = 300 # ターゲットネットワークの同期タイミングを指定 sync_interval = 20 # 推移の確認用のリストを初期化 trace_loss = [] trace_reward = [] # 繰り返しシミュレーション for episode in range(episodes): # 状態を初期化 state, info = env.reset() done = False # 時刻を初期化 t = 0 # 計算用のオブジェクトを初期化 total_loss = 0.0 total_reward = 0.0 # 1エピソードのシミュレーション while not done: # 時刻をカウント t += 1 # ε-greedy法により行動を決定 action = agent.get_action(state) # サンプルデータを取得 next_state, reward, done, truncated, info = env.step(action) # Q関数(NNのパラメータ)を更新 loss = agent.update(state, action, reward, next_state, done) # 状態を更新 state = next_state # 合計損失・合計報酬を計算 if not len(agent.replay_buffer) < agent.batch_size: # サンプルデータが足りない場合は計算しない total_loss += loss total_reward += reward # Q関数NNとターゲットNNを同期 if episode % sync_interval == 0: agent.sync_qnet() # 平均損失・合計報酬を記録 trace_loss.append(total_loss / t) trace_reward.append(total_reward) # 一定回数ごとに結果を表示 if (episode+1) % 20 == 0: print( 'episode ' + str(episode+1) + ', T=' + str(t) + ', average loss=' + str(np.round(total_loss/t, 3)) + ', total reward=' + str(total_reward) )
episode 20, T=11, average loss=1.535, total reward=11.0
episode 40, T=9, average loss=1.386, total reward=9.0
episode 60, T=9, average loss=1.219, total reward=9.0
episode 80, T=9, average loss=0.238, total reward=9.0
episode 100, T=9, average loss=0.133, total reward=9.0
episode 120, T=36, average loss=1.417, total reward=36.0
episode 140, T=60, average loss=0.932, total reward=60.0
episode 160, T=13, average loss=0.838, total reward=13.0
episode 180, T=386, average loss=0.161, total reward=386.0
episode 200, T=258, average loss=0.251, total reward=258.0
episode 220, T=232, average loss=1.976, total reward=232.0
episode 240, T=219, average loss=1.059, total reward=219.0
episode 260, T=216, average loss=0.669, total reward=216.0
episode 280, T=225, average loss=0.433, total reward=225.0
episode 300, T=165, average loss=0.273, total reward=165.0
最初の状態からε-greedy法により行動し、カートまたはポールが閾値を超えるまでを1エピソードとします。エピソードごとに、envのreset()で状態(カートとポール)を初期化し、終了フラグdoneをFalseに設定します。
episodesに指定した回数のシミュレーションを行い、時刻ごとに繰り返しagentのupdate()でニューラルネットワークのパラメータを勾配降下法(Adam)により更新します。ただし、replay_bufferに保存された経験データ(サンプルデータ)数がbatch_size以上になるまでは更新されません。
sync_intervalに指定したエピソード数ごとに、Q関数のネットワークとターゲットネットワークのパラメータを同期します。
カートポールでは、総時刻(ステップ数)と合計報酬は一致します。
平均損失と総報酬の推移をそれぞれグラフで確認します。
# 最適化手法名を取得 optm_name = agent.optimizer.__class__.__name__ # 学習率名を指定 lr_name = 'alpha' # 学習率を取得 lr = getattr(agent.optimizer, lr_name)
# 平均損失の推移を作図 plt.figure(figsize=(8, 6), facecolor='white') plt.plot(np.arange(1, episodes+1), trace_loss) plt.xlabel('episode') plt.ylabel('average loss') plt.suptitle('DQN', fontsize=20) plt.title(optm_name+': '+lr_name+'='+str(lr), loc='left') plt.grid() plt.show()
# 総報酬の推移を作図 plt.figure(figsize=(8, 6), facecolor='white') plt.plot(np.arange(1, episodes+1), trace_reward) plt.xlabel('episode') plt.ylabel('total reward') plt.suptitle('DQN', fontsize=20) plt.title(optm_name+': '+lr_name+'='+str(lr), loc='left') plt.grid() plt.show()
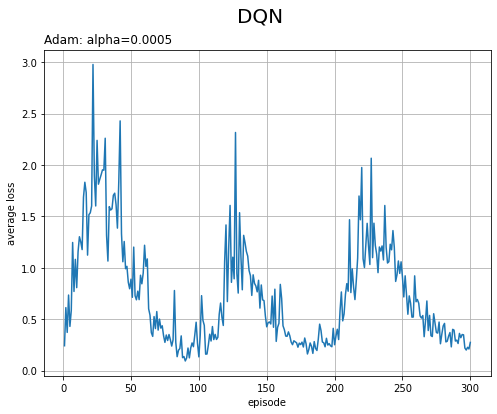
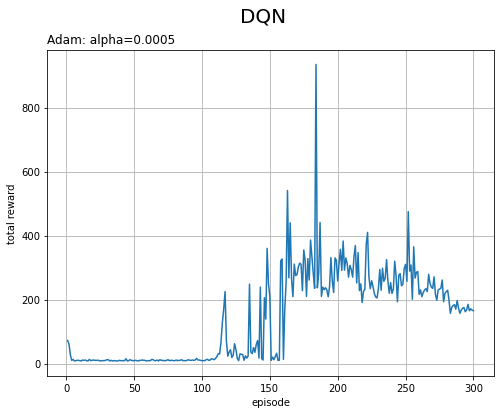
結果の解釈については本を参照してください。
以上で、DQNの学習を行えました。次からは、学習の状況を確認します。
学習済みエージェントによるプレイ
学習済みのQ関数(ニューラルネットワーク)を使って、カートポールをプレイします。
greedyに行動するように設定変更してシミュレーションを行います。
# 環境のインスタンスを作成 env = gym.make('CartPole-v1', render_mode='rgb_array') # greedy法に設定を変更 agent.epsilon = 0.0 # 最初の状態を取得 state, info = env.reset() # 終了フラグを設定 done = False # 時刻を初期化 t = 0 # 状態の記録用リストを初期化 state_data = [] render_data = [env.render()] # 最初の状態 # 1エピソードのシミュレーション while not done: # 時刻をカウント t += 1 # greedy法により行動を決定 action = agent.get_action(state) # 状態を遷移 next_state, reward, done, truncated, info = env.step(action) # 状態を保存 state_data.append((state, action, reward, done)) # 現在 render_data.append(env.render()) # 次 # フラグを表示 print('t='+str(t) + ': '+str(done)) # 状態を更新 state = next_state # 最後の状態を保存 state_data.append((state, None, None, None))
t=1: False
t=2: False
t=3: False
(省略)
t=163: False
t=164: False
t=165: True
DQNAgentクラスのインスタンス変数epsilonの値を0にして、1エピソードの処理を行います。
推移の確認用に、各時刻におけるカートポールの描画用の配列をリストに格納していきます。
カートポールのアニメーションを作成します。
・作図コード(クリックで展開)
# フレーム数を設定 frame_num = len(render_data) # 図を初期化 fig = plt.figure(figsize=(9, 7), facecolor='white') fig.suptitle('DQN', fontsize=20) # 行動の表示用のリストを作成 arrows = ['←', '→'] # 作図処理を関数として定義 def update(t): # 時刻tの状態を取得 state, action, reward, terminated = state_data[t] rgb_data = render_data[t] # 状態ラベルを作成 state_text = 't=' + str(t) + '\n' state_text += f'cart position={state[0]:5.2f}, ' state_text += f'cart velocity={state[1]:6.3f}\n' state_text += f'pole angle ={state[2]:5.2f}, ' state_text += f'pole velocity={state[3]:6.3f}\n' if (t+1) < frame_num: state_text += 'action=' + arrows[action] + ', ' state_text += 'reward=' + str(reward) + ', ' state_text += 'terminated:' + str(terminated) else: # 最後の状態の場合 state_text += 'action=' + str(action) + ', ' state_text += 'reward=' + str(reward) + ', ' state_text += 'terminated:' + str(terminated) # カートポールを描画 plt.imshow(rgb_data) plt.xticks(ticks=[]) plt.yticks(ticks=[]) plt.title(state_text, loc='left') # gif画像を作成 anime = FuncAnimation(fig=fig, func=update, frames=frame_num, interval=50) # gif画像を保存 anime.save('CatePole_DQN.gif')
時刻(ステップ)ごとの作図処理を関数update()として定義して、FuncAnimation()でアニメーション(gif画像)を作成します。各フレームの図はimshow()で描画します。

ポールを倒さないように制御できています。
学習推移の可視化
DQNの学習では、確率的な処理を含み、一回の実験結果の変動が大きくなります。そこで、同じ設定で複数回の実験を行い、推移の平均を確認します。
先ほどの学習処理を繰り返し行います。
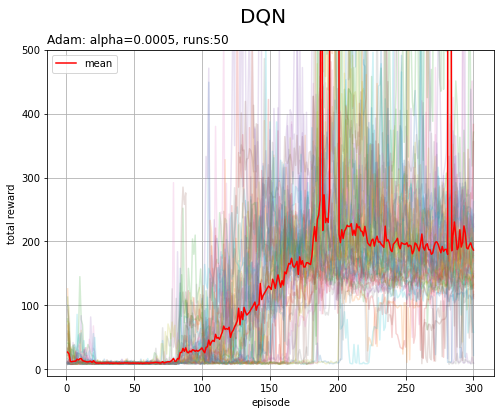
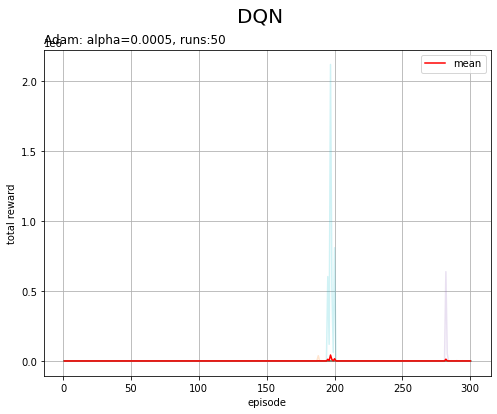
# 環境のインスタンスを作成 env = gym.make('CartPole-v1') # 実験回数を指定 runs = 50 # エピソード数を指定 episodes = 300 # ターゲットネットワークの同期タイミングを指定 sync_interval = 20 # 推移の確認用のリストを初期化 trace_all_loss = [] trace_all_reward = [] # 繰り返し実験 for run in range(runs): # 実験回数を表示 print('----- run ' + str(run+1) + ' -----') # エージェントのインスタンスを初期化 agent = DQNAgent() # 推移の確認用のリストを初期化 trace_loss = [] trace_reward = [] # 繰り返しシミュレーション for episode in range(episodes): # 状態を初期化 state, info = env.reset() done = False truncated = False # 時刻を初期化 t = 0 # 計算用のオブジェクトを初期化 total_reward = 0.0 total_loss = 0.0 # 1エピソードのシミュレーション while not done: # カートかポールが閾値を超えると終了 #while not done and not truncated: # 500ステップで打ち切り #while not done and t < 200: # 打ち切り回数を指定 # 時刻をカウント t += 1 # ε-greedy法により行動を決定 action = agent.get_action(state) # サンプルデータを取得 next_state, reward, done, truncated, info = env.step(action) # Q関数(NNのパラメータ)を更新 loss = agent.update(state, action, reward, next_state, done) # 状態を更新 state = next_state # Q関数NNとターゲットNNを同期 if episode % sync_interval == 0: agent.sync_qnet() # 合計損失・合計報酬を計算 if not len(agent.replay_buffer) < agent.batch_size: # サンプルデータが足りない場合は計算しない total_loss += loss total_reward += reward # 平均損失・合計報酬を記録 trace_loss.append(total_loss/t) trace_reward.append(total_reward) # 一定回数ごとに結果を表示 if (episode+1) % 100 == 0: print( 'episode ' + str(episode+1) + ', T=' + str(t) + ', average loss=' + str(np.round(total_loss/t, 3)) ) # 平均損失・合計報酬の推移を記録 trace_all_loss.append(trace_loss) trace_all_reward.append(trace_reward) # 最大ステップ数を表示 print('max T:' + str(int(np.max(trace_all_reward))))
----- run 1 -----
episode 100, T=22, average loss=0.299
episode 200, T=10, average loss=4.306
episode 300, T=227, average loss=0.64
max T:1080
----- run 2 -----
episode 100, T=35, average loss=0.196
episode 200, T=832, average loss=2.341
episode 300, T=114, average loss=13.086
max T:37766
----- run 3 -----
episode 100, T=9, average loss=1.542
episode 200, T=562, average loss=5.319
episode 300, T=865, average loss=0.375
max T:37766
(省略)
----- run 49 -----
episode 100, T=31, average loss=4.454
episode 200, T=173, average loss=3.784
episode 300, T=190, average loss=1.128
max T:2119332
----- run 50 -----
episode 100, T=27, average loss=0.313
episode 200, T=175, average loss=6.156
episode 300, T=166, average loss=0.052
max T:2119332
「DQNの学習」の処理をrunsに指定した回数繰り返して、平均損失と総報酬の推移をtrace_all_***に格納していきます。
while文の条件にtruncatedも含めると、500ステップでエピソードを終了します。
(いや200万ステップって、、3万ステップ越えの時点でひいてたのに、これは外れ値ですか?バグですか?分かりません。)図8-9は、ライブラリの仕様変更前のもので、時刻の上限が200(200ステップでエピソード打ち切り)の場合だと思われます。
平均損失と総報酬について、それぞれ実験ごとの推移と、全ての実験での推移の平均をグラフで確認します。
# 最適化手法名を取得 optm_name = agent.optimizer.__class__.__name__ # 学習率名を指定 lr_name = 'alpha' # 学習率を取得 lr = getattr(agent.optimizer, lr_name)
# 配列に変換 loss_arr = np.array(trace_all_loss) print(loss_arr.shape) # 平均損失の推移を作図 plt.figure(figsize=(8, 6), facecolor='white') for run in range(runs): plt.plot(np.arange(1, episodes+1), loss_arr[run], alpha=0.2) # 実験ごとの推移 plt.plot(np.arange(1, episodes+1), np.mean(loss_arr, axis=0), color='red', label='mean') # 推移の平均 plt.xlabel('episode') plt.ylabel('average loss') plt.suptitle('DQN', fontsize=20) plt.title(optm_name+': '+lr_name+'='+str(lr) + ', runs:'+str(runs), loc='left') plt.grid() plt.legend() plt.ylim(-5, 50) plt.show()
# 配列に変換 reward_arr = np.array(trace_all_reward) print(reward_arr.shape) # 総報酬の推移を作図 plt.figure(figsize=(8, 6), facecolor='white') for run in range(runs): plt.plot(np.arange(1, episodes+1), reward_arr[run], alpha=0.2) # 実験ごとの推移 plt.plot(np.arange(1, episodes+1), np.mean(reward_arr, axis=0), color='red', label='mean') # 推移の平均 plt.xlabel('episode') plt.ylabel('total reward') plt.suptitle('DQN', fontsize=20) plt.title(optm_name+': '+lr_name+'='+str(lr) + ', runs:'+str(runs), loc='left') plt.grid() plt.legend() plt.ylim(-10, 500) plt.show()
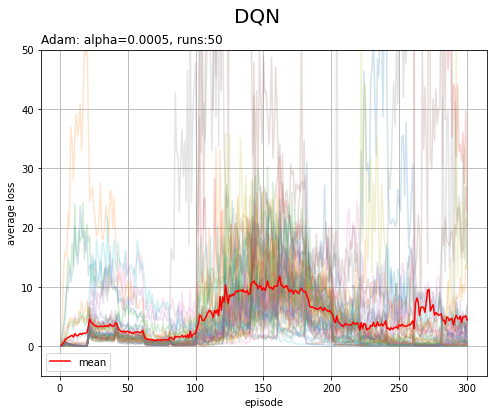
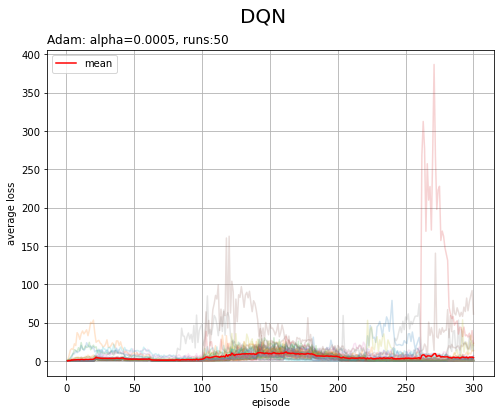
(マシンスペック的に100回はキツい…)
この節では、基本的なDQNを実装して学習を行いました。次節からは、DQNを拡張する手法を扱いますが実装はしないようです(残念)。
参考文献
- 斎藤康毅『ゼロから作るDeep Learning 4 ――強化学習編』オライリー・ジャパン,2022年.
- サポートページ:GitHub - oreilly-japan/deep-learning-from-scratch-4
おわりに
サンプルデータをサンプリングし始めて表現に悩みました。経験データのサンプルと呼べばいいのでしょうが、これまでの記事と呼び方が揺れるのが嫌でして、なんとかうまくやったつもりです。読みにくければ、、、頑張って読んでください。
8章の後半は実装例が載ってないんですね、残念です。しかし、無いなら作る!ということでちょっと考えてみます。というわけで続きは少し空くと思います。他にも年内に書いておきたいこともありますし。
えっとそして、この記事がこのブログの500記事目なようです。目次用のページや日記も含めてカウントされているので、気持ち的にはもう十数記事は書いてから達成って感じですが、きっちり数えるようなことでもないので、ぜひ褒めてください。
それと、来週でブログ開設4周年です。特に今回に限らずいつでも褒めてもらえると喜びます!今後もよろしくお願いします。
最後に!先ほど公開された歌唱動画をぜひ聴きましょう。
卒業目前にまーでぃーを観られるとはありがたい限りです。良いコンビ!
【次節の内容】
つづく