はじめに
『ゼロから作るDeep Learning 4 ――強化学習編』の独学時のまとめノートです。初学者の補助となるようにゼロつくシリーズの4巻の内容に解説を加えていきます。本と一緒に読んでください。
この記事は、1.2節の内容です。スロットマシンの価値(期待値)を計算します。
【他の記事一覧】
【この記事の内容】
1.2 バンディット問題
「真の期待値」と「期待値の推定値」を計算してグラフで確認します。
利用するライブラリを読み込みます。
# 利用するライブラリ import numpy as np import matplotlib.pyplot as plt
1.2.2 よいスロットマシンとは
報酬と各報酬の確率(確率分布)を指定します。
# 報酬を指定 reward = np.array([0, 1, 5, 10]) # 確率を指定 rate_a = np.array([0.7, 0.15, 0.12, 0.03]) # マシンa rate_b = np.array([0.5, 0.4, 0.09, 0.01]) # マシンb
図1-7に従って、スロットマシンa・bの確率を設定しました。
2つのスロットマシンの確率を棒グラフで確認します。
# x軸目盛の位置を作成 x_ticks = np.arange(1, len(reward)+1) # 報酬と確率の棒グラフを作成 plt.figure(figsize=(8, 6)) plt.bar(x_ticks, rate_a, align='edge', width=-0.4, label='a') # マシンaの確率 plt.bar(x_ticks, rate_b, align='edge', width=0.4, label='b') # マシンbの確率 plt.xlabel('reward') plt.ylabel('rate') plt.xticks(ticks=x_ticks, labels=reward) # 報酬ラベル plt.title('reward=' + str(reward), loc='left') # 報酬の値 plt.suptitle('Slot machine : a, b', fontsize=20) plt.grid() plt.ylim(0, 1) plt.legend() plt.show()

グラフ(や表)だけではどちらのマシンの価値が高いのかを判断しかねます。
そこで、期待値を計算します。
# 期待値(真の価値)を計算 E_a = np.sum(reward * rate_a) E_b = np.sum(reward * rate_b) print(E_a) print(E_b)
1.05
0.95
aのマシンの方が期待値(価値)が高いのが分かりました。
しかし、実際にはマシンごとの確率は分からないので、真の期待値を計算できません。
そのため、マシンをプレイした結果から期待値を推定します。
# 試行回数を指定 N = 1000 # スロットマシンをプレイ reward_a_n = np.random.choice(reward, size=N, replace=True, p=rate_a) reward_b_n = np.random.choice(reward, size=N, replace=True, p=rate_b) print(reward_a_n[:10]) print(reward_b_n[:10])
[0 0 5 0 0 0 5 0 0 5]
[0 0 1 1 1 1 0 0 0 0]
np.random.choice()を使って、マシンa・bをプレイした結果が得られます。
試行ごとに標本平均(期待値の推定値)を計算します。
# 期待値を計算 E_a_n = np.cumsum(reward_a_n) / np.arange(1, N+1) E_b_n = np.cumsum(reward_b_n) / np.arange(1, N+1) print(np.round(E_a_n[:10], 3)) print(np.round(E_b_n[:10], 3))
[0. 0. 1.667 1.25 1. 0.833 1.429 1.25 1.111 1.5 ]
[0. 0. 0.333 0.5 0.6 0.667 0.571 0.5 0.444 0.4 ]
np.cumsum()で累積和を計算します。累積和とは、要素ごとに0番目の要素(1回目の結果)からn番目の要素(n+1回目の結果)の和を計算します。(Pythonではインデックスを0から数えるので値がズレます。)
累積和をそれぞれの試行回数(1からNの値)で割ることで、各試行の標本平均が求まります。
期待値の推定値の推移をグラフで確認します。
# マシンaの推定期待値のグラフを作成 plt.figure(figsize=(8, 6)) plt.plot(np.arange(1, N+1), E_a_n, label='Q(a)') # 推定期待値の推移 plt.hlines(y=E_a, xmin=0, xmax=N, color='red', linestyle='--', label='q(a)') # 真の期待値 plt.xlabel('n') plt.ylabel('E') plt.title('q(a)=' + str(E_a), loc='left') # 真の期待値 plt.suptitle('Slot machine : a', fontsize=20) plt.grid() plt.legend() plt.show() # マシンbの推定期待値のグラフを作成 plt.figure(figsize=(8, 6)) plt.plot(np.arange(1, N+1), E_a_n, label='Q(b)') # 推定期待値の推移 plt.hlines(y=E_b, xmin=0, xmax=N, color='red', linestyle='--', label='q(b)') # 真の期待値 plt.xlabel('n') plt.ylabel('E') plt.title('q(b)=' + str(E_b), loc='left') # 真の期待値 plt.suptitle('Slot machine : b', fontsize=20) plt.grid() plt.legend() plt.show()
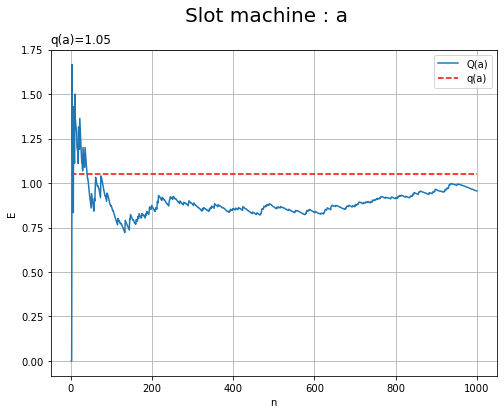
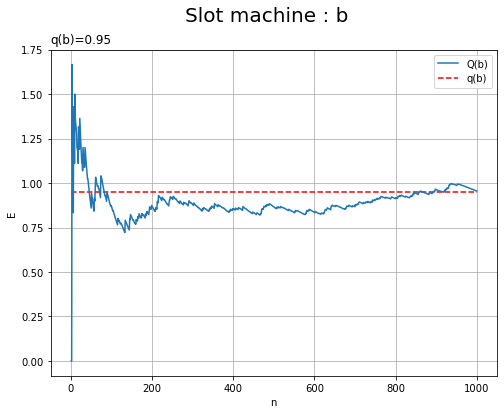
試行回数が増えるに従って、推定期待値(青色の曲線)が真の期待値(赤色の破線)に近付いていくのが分かります。
同じ処理を複数回行います。
# 実験回数を指定 S = 10 # 試行回数を指定 N = 1000 # スロットマシンをプレイ reward_a_sn = np.random.choice(reward, size=(S, N), replace=True, p=rate_a) reward_b_sn = np.random.choice(reward, size=(S, N), replace=True, p=rate_b) print(reward_a_sn[:3, :10]) print(reward_b_sn[:3, :10]) # 期待値を計算 E_a_sn = np.cumsum(reward_a_sn, axis=1) / np.arange(1, N+1) E_b_sn = np.cumsum(reward_b_sn, axis=1) / np.arange(1, N+1) print(np.round(E_a_sn[:3, :10], 3)) print(np.round(E_b_sn[:3, :10], 3))
[[ 5 5 5 0 0 5 0 0 0 1]
[ 5 0 1 1 0 0 10 0 5 0]
[ 5 1 0 0 1 1 10 0 0 0]]
[[0 1 1 1 0 0 1 1 0 1]
[1 1 0 1 1 1 1 0 5 0]
[0 0 1 0 0 1 0 1 5 5]]
[[5. 5. 5. 3.75 3. 3.333 2.857 2.5 2.222 2.1 ]
[5. 2.5 2. 1.75 1.4 1.167 2.429 2.125 2.444 2.2 ]
[5. 3. 2. 1.5 1.4 1.333 2.571 2.25 2. 1.8 ]]
[[0. 0.5 0.667 0.75 0.6 0.5 0.571 0.625 0.556 0.6 ]
[1. 1. 0.667 0.75 0.8 0.833 0.857 0.75 1.222 1.1 ]
[0. 0. 0.333 0.25 0.2 0.333 0.286 0.375 0.889 1.3 ]]
各実験結果をグラフで確認します。
# マシンaの実験結果を作図 plt.figure(figsize=(8, 6)) for s in range(S): plt.plot(np.arange(1, N+1), E_a_sn[s], alpha=0.5) # 推定期待値の推移 plt.hlines(y=E_a, xmin=0, xmax=N, color='red', linestyle='--', label='q(a)') # 真の期待値 plt.xlabel('n') plt.ylabel('E') plt.title('q(a)=' + str(E_a), loc='left') # 真の期待値 plt.suptitle('Slot machine : a', fontsize=20) plt.grid() plt.legend() plt.show() # 実験結果を作図 plt.figure(figsize=(8, 6)) for s in range(S): plt.plot(np.arange(1, N+1), E_b_sn[s], alpha=0.5) # 推定期待値の推移 plt.hlines(y=E_b, xmin=0, xmax=N, color='red', linestyle='--', label='q(b)') # 真の期待値 plt.xlabel('n') plt.ylabel('E') plt.title('q(b)=' + str(E_b), loc='left') # 真の期待値 plt.suptitle('Slot machine : b', fontsize=20) plt.grid() plt.legend() plt.show()
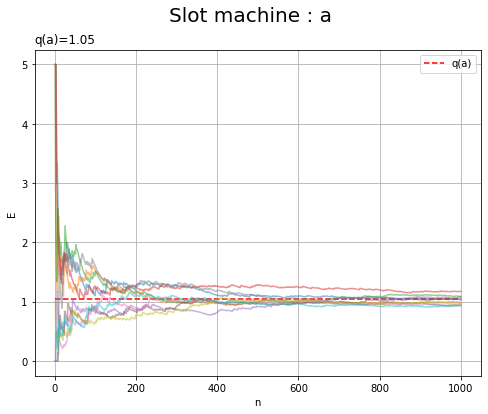
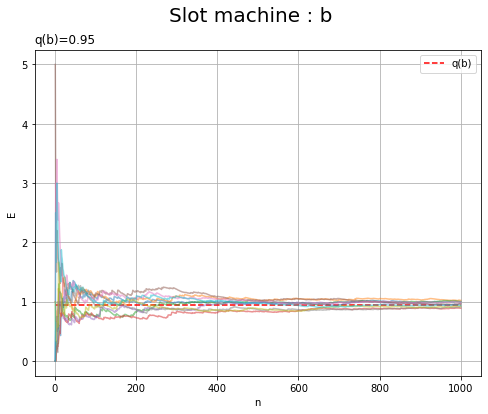
実験結果を増やしても、真の期待値に近付くのを確認できます。
実際には、両方を1000回ずつプレイして良いマシンを選ぶわけにはいきません。良いマシンはできるだけ多く、悪いマシンはできるだけ少なくプレイすることで、できるだけ多くの報酬を得ることを目指します。
どの実験結果も真の期待値に収束しているのが分かります。
1.2.3 数式を使って表す
どっちのマシンを選ぶなどのエージェントの行動を$A$、報酬を$R$とします。
行動$A$によって得られる報酬$R$の期待値を、次の式で表します。
これを行動価値と呼びます。推定値の場合は、$Q(A)$で表します。
参考文献
- 斎藤康毅『ゼロから作るDeep Learning 4 ――強化学習編』オライリー・ジャパン,2022年.
- サポートページ:GitHub - oreilly-japan/deep-learning-from-scratch-4
おわりに
4巻もこれまで通りノートを作りながら寄り道回り道しながらやっていきます。
先日公開されたMVを聴いて楽しくやっていきましょう。
And you?
【次節の内容】