はじめに
『Rが生産性を高める 〜データ分析ワークフロー効率化の実践』(R登山本)の内容を実際にやってみた記録や気になったことのメモです。
この記事は、6章を読んでやってみた内容です。本とあわせて読んでください。
【前の内容】
【この記事の内容】
記事テキストのスクレイピング
前回は、はてなブログにおける記事のURLを収集しました。今回は、記事URLを使って、記事のテキストを収集します。
次のパッケージを利用します。
# 利用パッケージ library(rvest) library(polite) library(magrittr)
rvestとpoliteは、スクレイピングに関するパッケージです。詳しくは、本の6-2節と6-7節を参照してください。
この記事では、パッケージ名::関数名()の記法を使うので、パッケージを読み込む必要はありません。
ただし、パイプ演算子%>%を使うため、magrittrパッケージは読み込む必要があります。
記事テキストの収集
「Chapter 6:ブログの投稿数をヒートマップで可視化してみた【R登山本】 - からっぽのしょこ」で取得した記事URLのベクトルから、テキストを取得する記事のURLを取り出します。
対象とする年と月を指定します。
# 年月を指定 year <- 2022 month <- 4
はてなブログの記事URLは、(デフォルトでは)ブログURLの後に投稿時間が付いてブログURL/entry/yyyy/mm/dd/hhmmssとなります。
そこで、検索用の文字列yyyy/mmを作成します。
# 年月の文字列を作成 year_month <- paste0(year, "/", stringr::str_pad(month, width = 2, pad = 0)) year_month
## [1] "2022/04"
月の値をstr_pad()で2桁表示にします。この例だと、4が"04"になります。
指定した月に投稿された記事URLのインデックスを抽出します。
# 期間内の記事URLのインデックスを抽出 target_idx <- stringr::str_which(url_vec, pattern = year_month) target_idx[1:5]
## [1] 369 370 371 372 373
str_which()は、該当する文字列を含む要素のインデックスを返しします。
このインデックスを使って、記事URLを取り出せます。
# 記事URLを取り出し url_vec[target_idx][1:5]
## [1] "https://www.anarchive-beta.com/entry/2022/04/01/123000" ## [2] "https://www.anarchive-beta.com/entry/2022/04/02/123000" ## [3] "https://www.anarchive-beta.com/entry/2022/04/03/123000" ## [4] "https://www.anarchive-beta.com/entry/2022/04/04/180000" ## [5] "https://www.anarchive-beta.com/entry/2022/04/08/190000"
1記事ずつ取り出して使います。
スクレイピングのルールを確認しておきます。
# 記事URLを取り出し entry_url <- url_vec[target_idx[1]] # スクレイピングルールの確認 session <- polite::bow(url = entry_url) session
## <polite session> https://www.anarchive-beta.com/entry/2022/04/01/123000 ## User-agent: polite R package - https://github.com/dmi3kno/polite ## robots.txt: 5 rules are defined for 2 bots ## Crawl delay: 5 sec ## The path is scrapable for this user-agent
politeパッケージのbow()で確認できます。詳しくは6-7節を参照してください。
抽出した記事URLを1つずつ使って、記事のテキストを取得します。
# 記事ごとにテキストをスクレイピング entry_text_vec <- c() for(idx in target_idx) { # 記事URLを取り出し entry_url <- url_vec[idx] print(entry_url) # 記事HTMLを取得 entry_html <- rvest::read_html(entry_url) #session <- polite::nod(bow = session, path = entry_url) #entry_html <- polite::scrape(bow = session) # politeパッケージの場合 # 記事テキストを抽出 entry_text <- entry_html %>% rvest::html_elements(".entry-content") %>% # 記事の内容 rvest::html_text() # テキストを取得 # 同じ月のテキストを結合 entry_text_vec <- c(entry_text_vec, entry_text) # 処理を一時停止 Sys.sleep(20) #sleep_bar(20) } # 書き出し用のパスを作成 file_path <- paste0("フォルダ名/", stringr::str_replace(year_month, pattern = "/", replacement = "_"), ".txt") # テキストを書き出し write(paste0(entry_text_vec, collapse = "\n"), file = file_path)
rvestパッケージのread_html()またはpoliteパッケージのscrape()で、記事のHTMLを取得します。
記事ページにはヘッダーやサイドバーなども含まれます。記事の内容は<div class="entry-content">~</div>の部分なので、html_elements(".entry-content")で抜き出します。
さらに、html_text()でテキストを抜き出します。
各記事のテキストをentry_textとして、全ての記事テキストをentry_text_vecに追加していきます。
指定した月の記事のテキストが得られたら、write()でテキストファイルとして書き出します。file引数に保存するファイルパス("(保存する)フォルダ名/(作成する)ファイル名.txt")を指定します。この例では、ファイル名をyyyy_mm.txtとします。
sleep_bar()については「Chapter 6:ブログの投稿数をヒートマップで可視化してみた【R登山本】 - からっぽのしょこ」を参照してください。
複数年をループ処理する場合は、次のように行います。
# 年を切り替え for(year in year_from:year_to) { # 月を切り替え for(month in 1:12) { # 記事インデックスを作成:(処理は省略) target_idx # 記事が無ければ次の月に進む if(length(target_idx) == 0) next # 記事ごとにテキストをスクレイピング:(処理は省略) for(idx in target_idx) { entry_text_vec } # テキストを書き出し:(処理は省略) write() } }
投稿がない月の場合はtarget_idxが要素を持たないので、if()とnextを使って次の月に進みます。
棒グラフによる頻出語の可視化
ブログによく登場する単語を棒グラフで可視化します。
次のパッケージを利用します。
# 利用パッケージ library(RMeCab) library(tidyverse)
RMeCabは、RからMeCabを利用するためのパッケージです。形態素解析器MeCabがインストールされている必要があります。
この記事では、基本的にパッケージ名::関数名()の記法を使うので、パッケージを読み込む必要はありません。
ただし、パイプ演算子%>%を使うためmagrittrと、作図コードがごちゃごちゃしないようにパッケージ名を省略するためggplot2は読み込む必要があります。
形態素解析
まずは、形態素解析を行い、文章を単語(形態素)に分解します。
テキストファイルのパスを指定します。
# 年月を指定 year <- 2022 month <- 3 # テキストのファイルパスを作成 file_name <- paste0(year, "_", stringr::str_pad(month, width = 2, pad = 0), ".txt") file_path <- paste0("フォルダ名/", file_name) file_path
## [1] "フォルダ名/2022_03.txt"
前回と次回の内容との対応からこのように処理しています。テキストファイルを棒グラフにするのであれば、ファイルパスをそのまま文字列で指定してください。
形態素解析を行います。
# MeCabによる形態素解析 mecab_df <- RMeCab::docDF(target = file_path, type = 1) %>% tibble::as_tibble() head(mecab_df)
## # A tibble: 6 x 4 ## TERM POS1 POS2 `2022_03.txt` ## <chr> <chr> <chr> <int> ## 1 "!" 名詞 サ変接続 3 ## 2 "!$" 名詞 サ変接続 1 ## 3 "\"" 名詞 サ変接続 348 ## 4 "\"\"" 名詞 サ変接続 2 ## 5 "\")" 名詞 サ変接続 70 ## 6 "\")\")," 名詞 サ変接続 13
RMeCabパッケージのdocDF()で、形態素解析を行います。target(第1引数)にテキストのファイルパス、type引数に1を指定します。
TERM列は単語、POS1列は品詞大分類、POS2列は品詞小分類です。4列目は各単語の頻度で、テキストファイル名が列名になります。
以上で、文章を単語に分かち書きできました。
単語の集計
次に、記事の内容を反映する単語を抽出します。
記号類や意味を持たない単語などを取り除く設定をします。
# 単語数を指定 term_size <- 100 # 利用する品詞を指定 pos1_vec <- c("名詞", "動詞", "形容詞") pos2_vec <- c("一般", "固有名詞", "サ変接続", "形容動詞語幹", "ナイ形容詞語幹", "自立") # 削除する単語を指定 stopword_symbol_vec <- c("\\(", "\\)", "\\{", "\\}", "\\[", "]", "「", "」", ",", "_", "--", "!", "#", "\\.", "\\$", "\\\\") stopword_term_vec <- c("る", "ある", "する", "せる", "できる", "なる", "やる", "れる", "いい", "ない")
利用する品詞大分類をpos1_vec、品詞小分類をpos2_vecとして指定します。
削除する記号と単語をstopword_***_vecに指定します。正規表現に使われる記号の場合は、エスケープ文字\\を付ける必要があります。
それぞれ結果を見ながら指定してください。
利用する単語を抽出して、出現頻度を再集計し、出現頻度の上位単語を抽出します。
# 頻出語を抽出 freq_df <- mecab_df %>% dplyr::filter(POS1 %in% pos1_vec) %>% # 指定した品詞大分類を抽出 dplyr::filter(POS2 %in% pos2_vec) %>% # 指定した品詞小分類を抽出 dplyr::filter(!stringr::str_detect(TERM, pattern = paste0(stopword_symbol_vec, collapse = "|"))) %>% # 指定した記号を削除 dplyr::filter(!stringr::str_detect(TERM, pattern = paste0(stopword_term_vec, collapse = "|"))) %>% # 指定した単語を削除 dplyr::select(term = TERM, frequency = file_name) %>% # 単語と頻度の列を取り出し dplyr::group_by(term) %>% # 単語でグループ化 dplyr::summarise(frequency = sum(frequency), .groups = "drop") %>% # 同一単語の頻度を合計 dplyr::arrange(dplyr::desc(frequency)) %>% # 降順に並び替え head(term_size) # 頻出語を抽出 head(freq_df)
## # A tibble: 6 x 2 ## term frequency ## <chr> <int> ## 1 "=" 1575 ## 2 "x" 696 ## 3 "+" 413 ## 4 "\"" 348 ## 5 "関数" 328 ## 6 "y" 315
filter()で単語を抽出して、summarise()で重複語の頻度を合計して、arrange()とhead()で頻度が多い単語を抽出します。
処理の塊ごとに確認していきます。
・処理の確認(クリックで展開)
利用する品詞を抽出して、不要な単語を削除します。
# 不要な単語を削除 tmp1_df <- mecab_df %>% dplyr::filter(POS1 %in% pos1_vec) %>% # 指定した品詞大分類を抽出 dplyr::filter(POS2 %in% pos2_vec) %>% # 指定した品詞小分類を抽出 dplyr::filter(!stringr::str_detect(TERM, pattern = paste0(stopword_symbol_vec, collapse = "|"))) %>% # 指定した記号を削除 dplyr::filter(!stringr::str_detect(TERM, pattern = paste0(stopword_term_vec, collapse = "|"))) tmp1_df
## # A tibble: 1,373 x 4 ## TERM POS1 POS2 `2022_03.txt` ## <chr> <chr> <chr> <int> ## 1 "\"" 名詞 サ変接続 348 ## 2 "\"\"" 名詞 サ変接続 2 ## 3 "%>%" 名詞 サ変接続 62 ## 4 "&" 名詞 サ変接続 12 ## 5 "&=" 名詞 サ変接続 12 ## 6 "'" 名詞 サ変接続 23 ## 7 "*" 名詞 サ変接続 33 ## 8 "+" 名詞 サ変接続 413 ## 9 "+=" 名詞 サ変接続 1 ## 10 "-" 名詞 サ変接続 270 ## # ... with 1,363 more rows
filter()で利用する単語を抽出します。抽出する際の条件に、次の2つの方法を使います。
%in%演算子を使って、利用する品詞の行を抽出します。
# 要素を含むか検索 "a" %in% c("a", "b", "c") "d" %in% c("a", "b", "c")
## [1] TRUE ## [1] FALSE
%in%の左側の要素が、右側の要素に含まれていればTRUE、含まなければFALSEになります。
str_detect()を使って、利用しない単語の行を削除します。
# 文字列を含むか検索 stringr::str_detect("a", pattern = "a|b|c") stringr::str_detect("d", pattern = "a|b|c")
## [1] TRUE ## [1] FALSE
第1引数の要素に、pattern引数に指定した文字列が含まれていればTRUE、含まなければFALSEを返します。|は、「または」を表す記号です。
条件に合う単語を削除したいので、!を付けてTRUEとFALSEを反転させます。
# 結果を反転 !stringr::str_detect("a", pattern = "a|b|c") !stringr::str_detect("d", pattern = "a|b|c")
## [1] FALSE ## [1] TRUE
単語の頻度を再集計します。
# 頻度を再集計 tmp2_df <- tmp1_df %>% # 指定した単語を削除 dplyr::select(term = TERM, frequency = file_name) %>% # 単語と頻度の列を取り出し dplyr::group_by(term) %>% # 単語でグループ化 dplyr::summarise(frequency = sum(frequency), .groups = "drop") # 同一単語の頻度を合計 tmp2_df
## # A tibble: 1,170 x 2 ## term frequency ## <chr> <int> ## 1 "'" 23 ## 2 "-" 270 ## 3 "-=" 3 ## 4 "\"" 348 ## 5 "\"\"" 2 ## 6 "%>%" 62 ## 7 "&" 12 ## 8 "&=" 12 ## 9 "*" 33 ## 10 "/" 91 ## # ... with 1,160 more rows
select()で、単語列と頻度列を取り出して、扱いやすいように列名を変更します。
品詞の情報を落とすので、品詞の異なる同一単語が重複して存在することになります。
そこで、group_by()で単語をグループ化して、summarise()とsum()で頻度を合算します。
出現頻度の上位単語を抽出します。
# 頻度上位単語を抽出 tmp3_df <- tmp2_df %>% dplyr::arrange(dplyr::desc(frequency)) %>% # 降順に並び替え head(n = term_size) # 頻出語を抽出 tmp3_df
## # A tibble: 100 x 2 ## term frequency ## <chr> <int> ## 1 "=" 1575 ## 2 "x" 696 ## 3 "+" 413 ## 4 "\"" 348 ## 5 "関数" 328 ## 6 "y" 315 ## 7 "-" 270 ## 8 "<" 253 ## 9 "作成" 222 ## 10 ">" 218 ## # ... with 90 more rows
arrange()とdesc()で頻度が多い順に並び替えて、head()で指定した単語数の上位単語を抽出します。
品詞の異なる同一単語について簡単に補足します。
例えば、「モーニング娘。の歌」の「歌」は「名詞-一般」で、「ドラマの主題歌」の「歌」は「名詞-接尾」になります。「主題歌」で1つの単語ですが、「主題」と「歌」に分割されます。後者のように、単語をさらに分解したものは形態素と呼ばれます。形態素は意味を持つ最小の単位のことで、前者の「歌」は単語であり形態素でもあります。形態素を更に分割した単位は文字です。
形態素解析は、文章を(単語ではなく)形態素の単位に分解します。なので、単語ではなく形態素と呼ぶべきですが、この記事では分かりやすさを優先して単語と呼ぶことにします。
以上で、前処理ができました。
棒グラフによる可視化
最後に、単語の出現頻度を棒グラフで可視化します。
出現頻度の棒グラフを作成します。
# 棒グラフを作成 graph <- ggplot(freq_df, aes(x = reorder(term, frequency), y = frequency)) + geom_bar(stat = "identity", fill = "hotpink", color = "white") + # 棒グラフ theme(axis.text.y = element_text(size = 15)) + # x軸目盛ラベル coord_flip(expand = FALSE) + # 軸の入れ替え labs(title = paste0(year, "年", month, "月の頻出語"), x = "単語", y = "頻度") graph
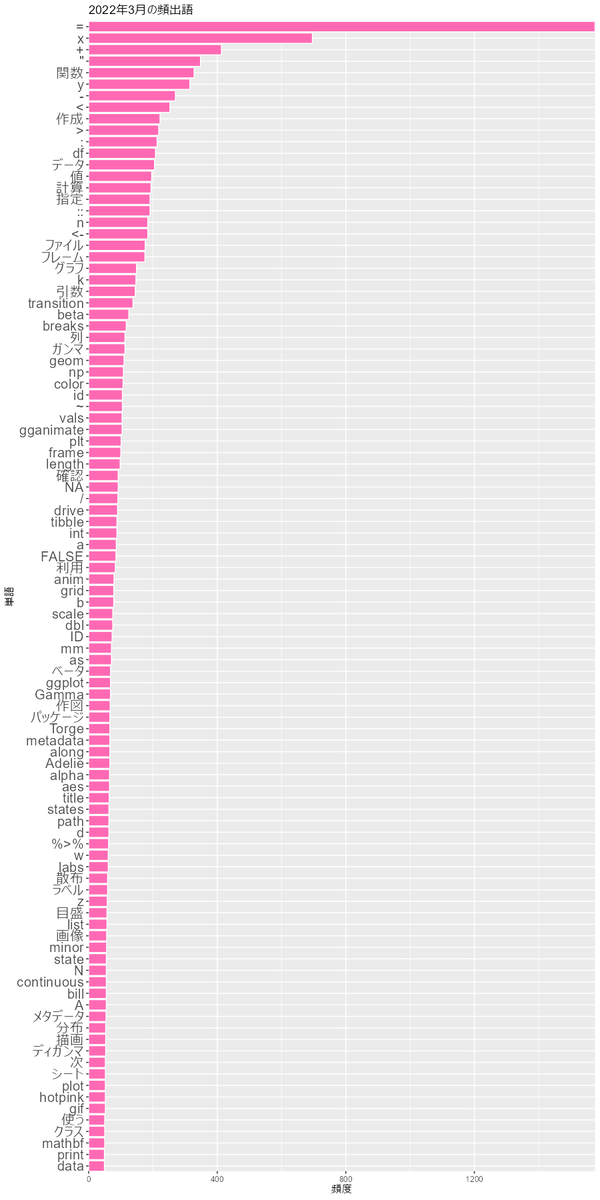
coord_filp()でx軸とy軸を入れ替えます。expand = FALSEを指定すると、グラフ領域の余白をなくし、バーと軸が接する図になります。
作成したグラフは、ggsave()で保存できます。
# グラフを保存 ggplot2::ggsave( filename = paste0("フォルダ名/", year, "_", month, ".png"), plot = graph, dpi = 100, width = 9, height = 18 )
plot引数にグラフ、filename引数に保存するファイルパスを指定します。"(保存する)フォルダ名/(作成する)ファイル名.png"でファイルを作成できます。
以上で、ブログ記事を可視化できました。
2018年から2022年の12月のグラフを見てみます。
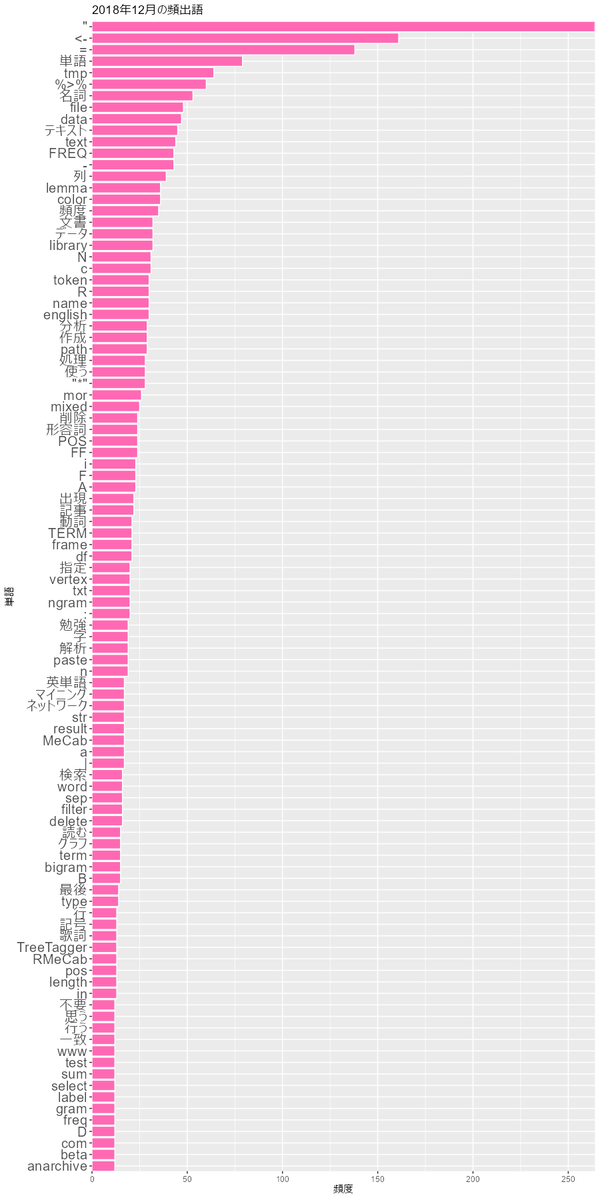
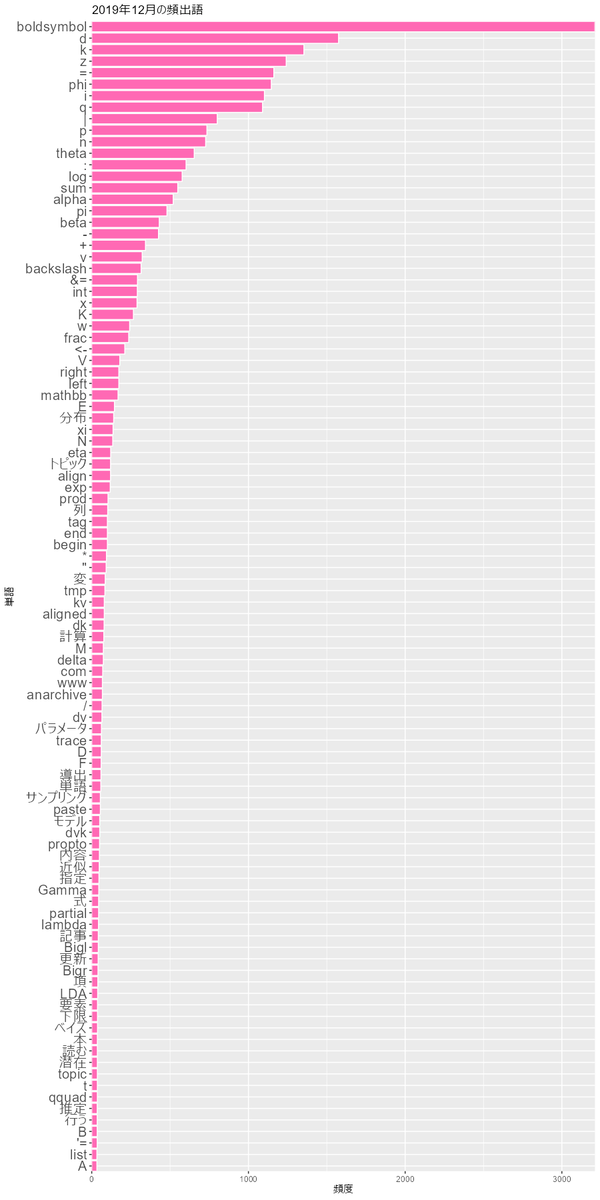
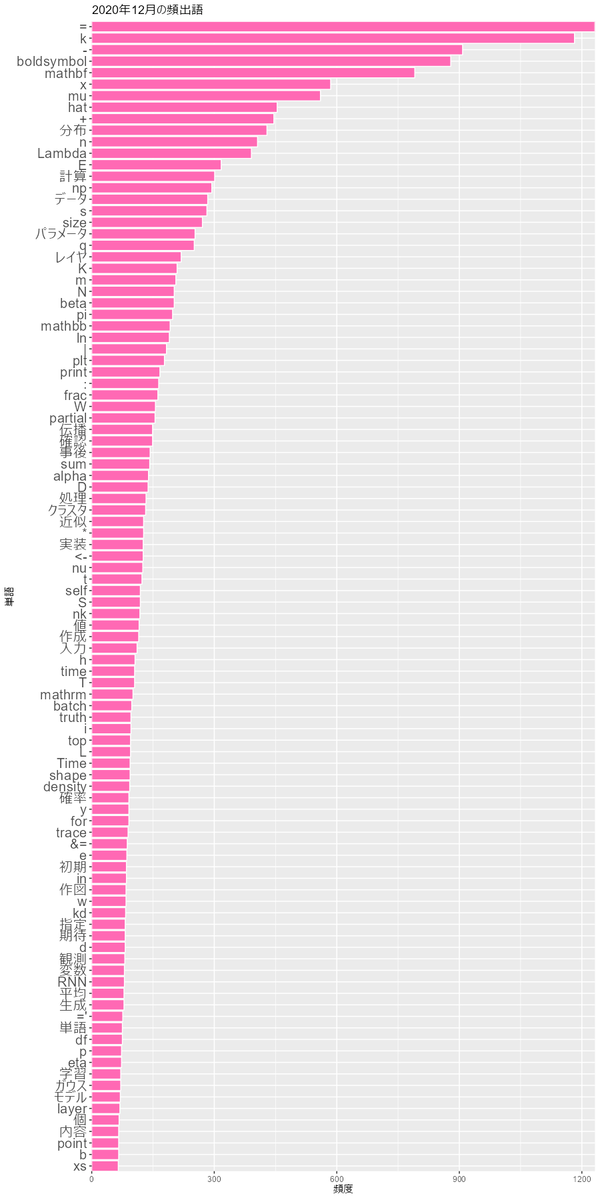
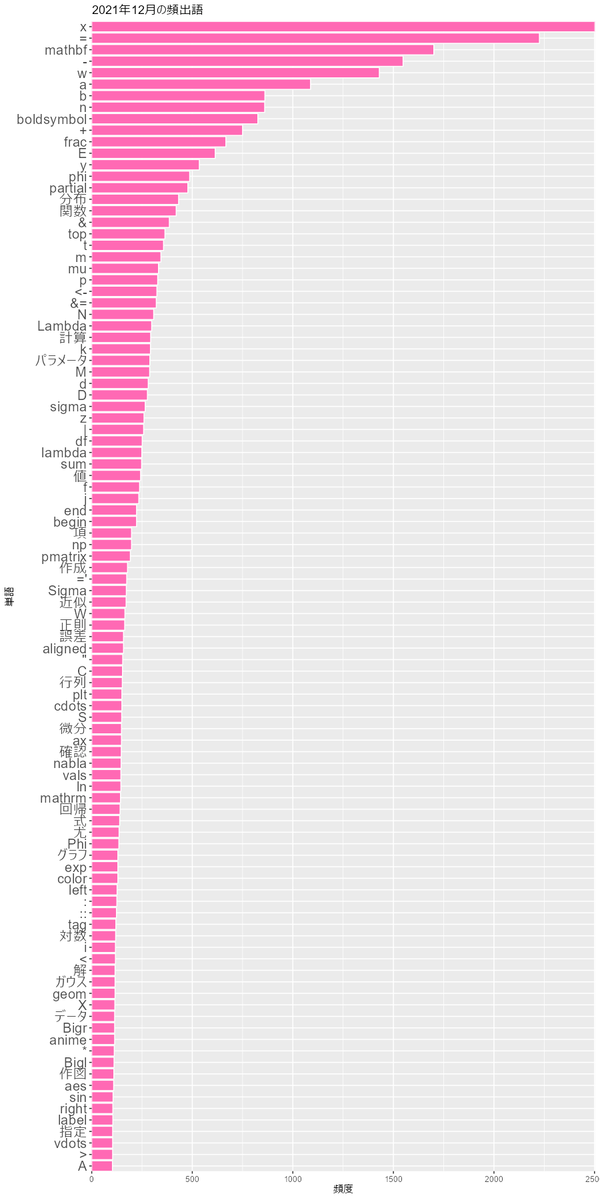
書いた本人としては、<-や%>%があるとRでnpやpltがあるとPythonとか、boldsymbol(ギリシャ文字の太字に使います)が多いとベイズネタで
mathbf(アルファベットの太字に使います)が多いと深層学習ネタとかが分かって面白いです。
他にも、なら観測変数か確率変数で
なら潜在変数あるいは
ならとか、添字が
か
かとかが面白かったのでアルファベット類も残しました。必要に応じて正規表現などを駆使して対応してください。
参考書籍
- 「Rが生産性を高める 〜データ分析ワークフロー効率化の実践」igjit・atusy・hanaori 著,技術評論社,2022年.
おわりに
前処理なる作業を久々にやりました。面倒くさい。そうだった、それで徐々に理論寄りのネタをトイデータで再現する記事ばっかりになっていったのだった。これを機に増やしていこうか。
【次の内容】