はじめに
『Rが生産性を高める 〜データ分析ワークフロー効率化の実践』(R登山本)の内容を実際にやってみた記録や気になったことのメモです。
この記事は、6章を読んでやってみた内容です。本とあわせて読んでください。
【前の内容】
【この記事の内容】
処理の一時停止用の関数の実装
スクレイピングでは、サイトに負荷がかかりすぎないように処理を一時停止する必要があります。そこで、停止時の待ち時間を表示する関数を作成しておきます。
# 一時停止のカウントダウンバー sleep_bar <- function(s = 10) { # プログレスバーを表示 message("\r", "[", rep("#", times = s), "] ", s, "s", appendLF = FALSE) for(i in 1:s) { # 処理を一時停止 Sys.sleep(1) # 前回のメッセージを初期化 message("\r", rep(" ", s + 10), appendLF = FALSE) # プログレスバーを表示 message( "\r", "[", rep("#", times = s - i), rep(" ", times = i), "] ", s - i, "s", appendLF = FALSE ) } # 改行 message("\r") }
この関数を利用すると次のように表示されます。
> sleep_bar() [###### ] 6s
1秒ごとに#が減っていきます。
待ち時間が気にならなければ、Sys.sleep()をそのまま使います。
記事URLのスクレイピング
はてなブログにおいて、投稿年ごとの記事一覧ページから記事のURLを収集します。
次のパッケージを利用します。
# 利用パッケージ library(rvest) library(polite) library(magrittr)
rvestとpoliteは、スクレイピングに関するパッケージです。詳しくは、本の6-2節と6-7節を参照してください。
この記事では、パッケージ名::関数名()の記法を使うので、パッケージを読み込む必要はありません。
ただし、パイプ演算子%>%を使うため、magrittrパッケージは読み込む必要があります。
記事URLの収集
ブログのURLを指定します。
# ブログのURLを指定 blog_url <- "https://www.anarchive-beta.com/"
この記事の内容は、はてなブログを対象としています。
スクレイピングのルールを確認しておきます。
# スクレイピングルールの確認 session <- polite::bow(url = blog_url) session
## <polite session> https://www.anarchive-beta.com/ ## User-agent: polite R package - https://github.com/dmi3kno/polite ## robots.txt: 5 rules are defined for 2 bots ## Crawl delay: 5 sec ## The path is scrapable for this user-agent
politeパッケージのbow()で確認できます。詳しくは6-7節を参照してください。
年ごとの記事一覧ページのURLは、ブログURLの後に検索対象の年を含めて、ブログURL/archive/年/?page=ページ番号です。2022年の2ページ目だと「https://www.anarchive-beta.com/archive/2022?page=2」となります。
for()を使って年yearとページ番号pageを変更して、一覧ページのURLtarget_urlを作成して、記事のURLを取得していきます。
# 期間(年)を指定 year_from <- 2018 year_to <- 2022 # 最大ページ数を指定:(念のため) max_page <- 10 # 年ごとに記事URLを収集 url_vec <- c() # 受け皿を作成 for(year in year_from:year_to) { # 一覧ページを切り替え url_year_vec <- c() # 初期化 for(page in 1:max_page) { # 一覧ページのURLを作成 target_url <- paste0(blog_url, "archive/", year, "?page=", page) print(target_url) # 一覧ページのHTMLを取得 #session <- polite::nod(bow = session, path = target_url) # politeパッケージの場合 target_html <- try( rvest::read_html(target_url), # rvestパッケージの場合 #polite::scrape(bow = session), # politeパッケージの場合 silent = TRUE ) # 記事が無ければ次の年に進む if(inherits(target_html, what = "try-error")) break # 記事のURLを取得 url_page_vec <- target_html %>% rvest::html_elements(".entry-title") %>% # 記事タイトル rvest::html_elements("a") %>% # 記事リンク rvest::html_attr("href") # 記事URL # 同じ年のURLを結合 url_year_vec <- c(rev(url_page_vec), url_year_vec) # 処理を一時停止 Sys.sleep(10) #sleep_bar(10) } # 全ての年のURLを結合 url_vec <- c(url_vec, url_year_vec) }
rvestパッケージのread_html()またはpoliteパッケージのscrape()で、一覧ページのHTMLを取得します。
ただし、記事がないときはエラーになります。そこで、if()を使って、エラーが起きると(記事がないと)その年のページ切り替えループを終了(break)して、次の年の処理に移ります。try()については、6-5節を参照してください。
(while()を使えばいいのですが、無限ループが怖かったのでmax_pageを指定してfor()ループしています。)
一覧ページにおける記事リンクの部分のHTMLは、次のようになっています。
<h1 class="entry-title"> <a class="entry-title-link" href="記事URL">記事タイトル</a> </h1>
html_elements(".entry-title")で、全ての記事の<h1 class="entry-title">~</h1>の部分を抜き出します。
さらに、html_elements("a")とhtml_attr("href")で、<a class="entry-title-link" href="記事URL">~</a>の記事URLを抜き出します。
一覧ページの全ての記事リンクを同時に取得できます。記事URLのベクトルをurl_page_vecとして、全ての記事URLをurl_vecに追加していきます。
収集した記事URLは、次のようになります。
# URLを確認 url_vec[1:5]
## [1] "https://www.anarchive-beta.com/entry/2018/12/01/164452" ## [2] "https://www.anarchive-beta.com/entry/2018/12/02/233840" ## [3] "https://www.anarchive-beta.com/entry/2018/12/03/234525" ## [4] "https://www.anarchive-beta.com/entry/2018/12/04/234831" ## [5] "https://www.anarchive-beta.com/entry/2018/12/05/234343"
はてなブログの記事のURLは、(デフォルトでは)ブログURLの後に記事の投稿日時が付いてブログURL/entry/yyyy/mm/dd/hhmmssとなります。
投稿数の可視化
はてなブログにおける記事の投稿数をヒートマップで可視化します。
次のパッケージを利用します。
# 利用パッケージ library(tidyverse) library(lubridate)
lubridateは、時間データに関するパッケージです。
この記事では、基本的にパッケージ名::関数名()の記法を使うので、パッケージを読み込む必要はありません。
ただし、パイプ演算子%>%を使うためmagrittrと、作図コードがごちゃごちゃしないようにパッケージ名を省略するためggplot2は読み込む必要があります。
集計と作図
記事の投稿数を日や月ごとに集計してヒートマップで可視化します。
日別
まずは、日ごとに投稿数を集計して可視化します。
対象とする期間を指定します。
# 期間(年月日)を指定 date_from <- "2018-12-01" date_to <- "2022-04-15" #date_to <- lubridate::today() # 現在の日付
開始日をdate_from、終了日をdate_toとして期間を指定します。文字列でyyyy-mm-ddやyyyy/mm/dd、yyyymmddなどと指定できます。現在の日付の場合は、lubridateパッケージのtoday()を使います。
期間内の全ての日付を持つデータフレームを作成します。
# 期間内の日付情報を作成 base_df <- seq( from = lubridate::as_date(date_from), to = lubridate::as_date(date_to), by = "day" ) %>% # 日付ベクトルを作成 tibble::tibble(date = .) # データフレームに変換 head(base_df)
## # A tibble: 6 x 1 ## date ## <date> ## 1 2018-12-01 ## 2 2018-12-02 ## 3 2018-12-03 ## 4 2018-12-04 ## 5 2018-12-05 ## 6 2018-12-06
seq()で、第1引数fromから第2引数toまでのベクトルを作成します。第3引数byに"day"を指定すると、1日刻みのベクトルを作成します。
文字列型で指定した日付date_***をas_date()でDate型に変換して使います。
作成した日付ベクトルを使って、tibble()でデータフレームを作成します。
記事URLから投稿日を抽出します。
# 記事URLを投稿日に変換 date_vec <- url_vec %>% stringr::str_remove(pattern = paste0(blog_url, "entry/")) %>% # 日時を示す文字列を抽出 lubridate::as_datetime(tz = "Asia/Tokyo") %>% # POSIXt型に変換 lubridate::as_date() %>% # Date型に変換 sort() # 昇順に並び替え date_vec[1:5]
## [1] "2018-12-01" "2018-12-02" "2018-12-03" "2018-12-04" "2018-12-05"
記事URLはブログURL/entry/yyyy/mm/dd/hhmmssなので、日付と無関係な部分をstr_remove()で削除します。
文字列型の日付をas_datetime()でPOSIXt型に変換して、さらにas_date()でDate型に変換します。(文字列処理の段階で/hhmmssを消しておけばas_datetime()は不要です。)
日ごとの投稿数を集計します。
# 日ごとに投稿数を集計 date_df <- tibble::tibble(date = date_vec) %>% dplyr::count(date, name = "post") # 投稿数をカウント head(date_df)
## # A tibble: 6 x 2 ## date post ## <date> <int> ## 1 2018-12-01 1 ## 2 2018-12-02 1 ## 3 2018-12-03 1 ## 4 2018-12-04 1 ## 5 2018-12-05 1 ## 6 2018-12-06 1
投稿日のベクトルをデータフレームにして、count()で同じ日付の数をカウントします。
投稿がなかった日はデータフレームに含まれません。
投稿がなかった日付を含めた作図用のデータフレームを作成します。
# 作図用のデータフレームを作成 post_df <- date_df %>% dplyr::right_join(base_df, by = "date") %>% # 日付情報に統合 dplyr::mutate( post = tidyr::replace_na(post, replace = 0), # 投稿なしを0に置換 year_month = format(date, "%Y-%m"), # 年月を抽出 day = format(date, "%d") # 日を抽出 ) head(post_df)
## # A tibble: 6 x 4 ## date post year_month day ## <date> <int> <chr> <chr> ## 1 2018-12-01 1 2018-12 01 ## 2 2018-12-02 1 2018-12 02 ## 3 2018-12-03 1 2018-12 03 ## 4 2018-12-04 1 2018-12 04 ## 5 2018-12-05 1 2018-12 05 ## 6 2018-12-06 1 2018-12 06
right_join()を使って全ての日付を持つbase_dfと結合することで、全ての日付を持つ投稿数のデータフレームになります。
ただし、投稿がない日は欠損値NAになるので、replace_na()で0に置換します。
グラフのx軸とy軸の値として、format()で年月と日の値を抽出します。
投稿数のヒートマップを作成します。
# ヒートマップを作成 graph <- ggplot(post_df, aes(x = year_month, y = day, fill = post)) + geom_tile() + # ヒートマップ #geom_text(mapping = aes(label = post), color = "white") + # 記事数ラベル scale_fill_gradient(low = "white", high = "hotpink") + # タイルの色 theme(axis.text.x = element_text(angle = 90, vjust = 0.5)) + # 軸目盛ラベル labs(title = paste0(blog_url, "の記事投稿数"), subtitle = paste("総記事数:", sum(post_df[["post"]])), x = "年-月", y = "日", fill = "記事数") graph
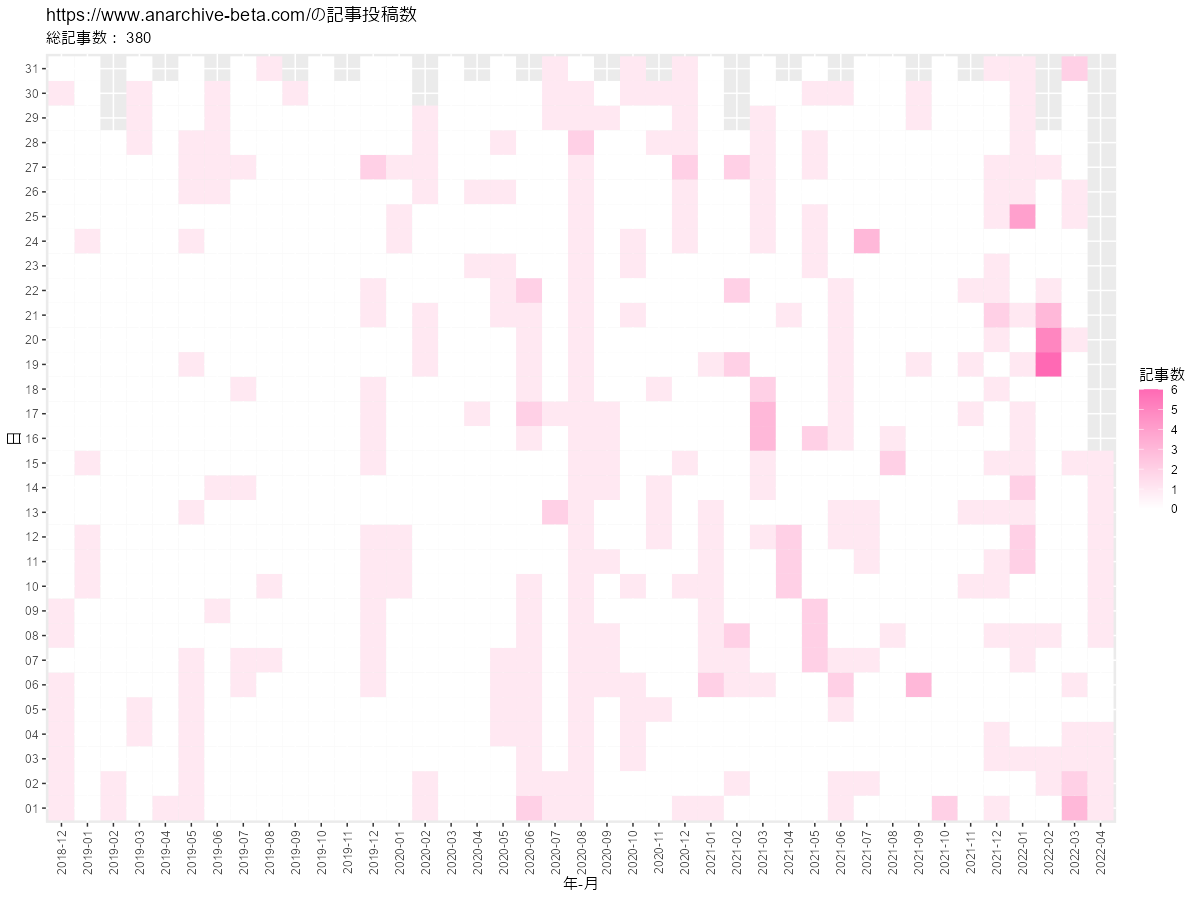
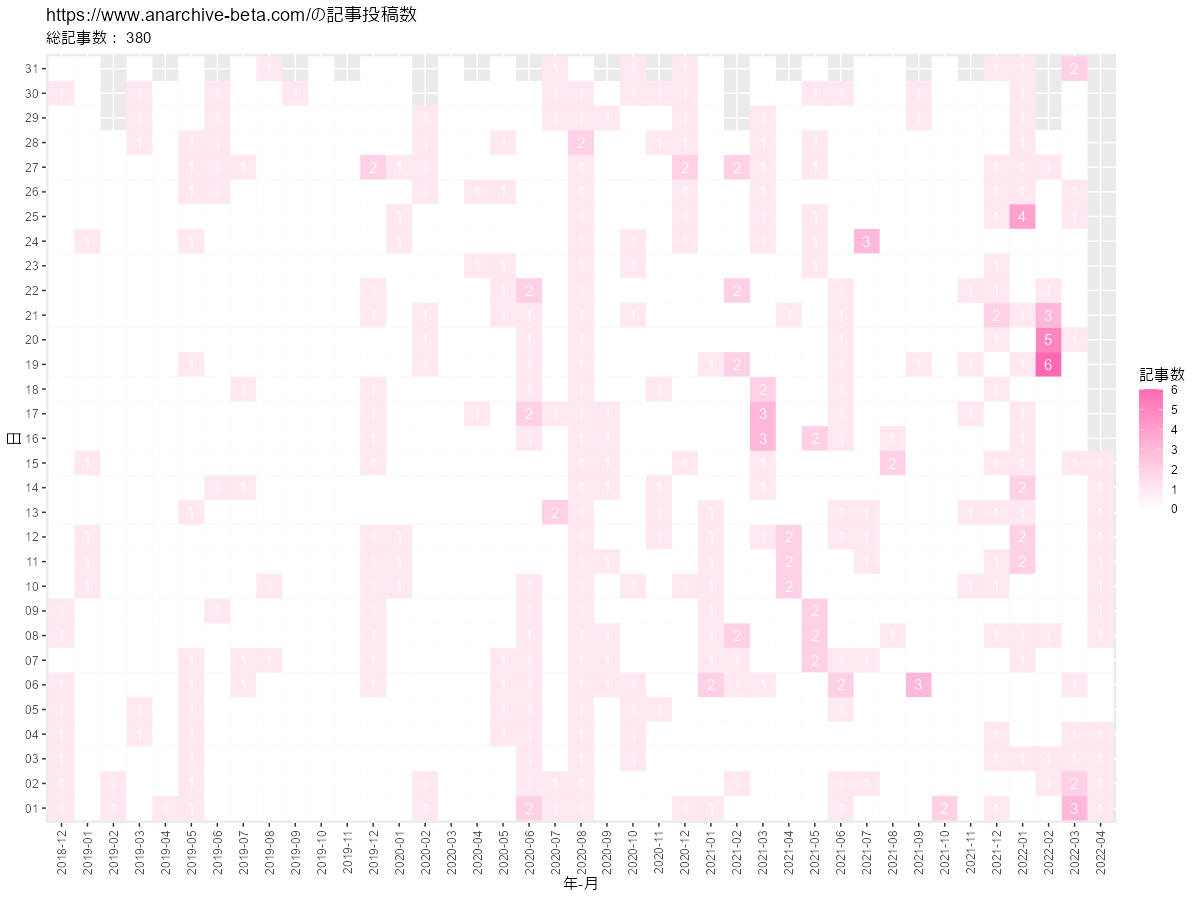
geom_tile()で、ヒートマップを描画します。
geom_text()で、投稿数を重ねて描画できます。
作成したグラフは、ggsave()で保存できます。
# グラフを保存 ggplot2::ggsave( filename = "フォルダ名/ファイル名.png", plot = graph, dpi = 100, width = 12, height = 9 )
plot引数にグラフ、filename引数に保存するファイルパス("(保存する)フォルダ名/(作成する)ファイル名.png")を指定します。
月別
次は、月ごとに投稿数を集計して可視化します。
指定した期間内の全ての月を持つデータフレームを作成します。
# 期間内の月情報を作成 base_df <- seq( from = date_from %>% lubridate::as_date() %>% lubridate::floor_date(unit = "mon"), to = date_to %>% lubridate::as_date() %>% lubridate::floor_date(unit = "mon"), by = "mon" ) %>% # 月ベクトルを作成 tibble::tibble(date = .) # データフレームに変換 head(base_df)
## # A tibble: 6 x 1 ## date ## <date> ## 1 2018-12-01 ## 2 2019-01-01 ## 3 2019-02-01 ## 4 2019-03-01 ## 5 2019-04-01 ## 6 2019-05-01
seq()の第3引数byに"mon"を指定すると、1か月刻みのベクトルを作成します。
指定した日付date_***をfloor_date()で月初の日付にして(日にちを切り捨てて)使います。こちらもunit引数に"mon"を指定します。
記事URLから投稿月を抽出します。
# 記事URLを投稿月に変換 date_vec <- url_vec %>% stringr::str_remove(pattern = paste0(blog_url, "entry/")) %>% # 日時を示す文字列を抽出 lubridate::as_datetime(tz = "Asia/Tokyo") %>% # POSIXt型に変換 lubridate::as_date() %>% # Date型に変換 lubridate::floor_date(unit = "mon") %>% # 月単位に切り捨て sort() # 昇順に並び替え date_vec[1:5]
## [1] "2018-12-01" "2018-12-01" "2018-12-01" "2018-12-01" "2018-12-01"
こちらも、floor_date()で月単位に切り捨てます。
月ごとの投稿数を集計します。
# 月ごとに投稿数を集計 date_df <- tibble::tibble(date = date_vec) %>% dplyr::count(date, name = "post") # 投稿数をカウント head(date_df)
## # A tibble: 6 x 2 ## date post ## <date> <int> ## 1 2018-12-01 9 ## 2 2019-01-01 5 ## 3 2019-02-01 2 ## 4 2019-03-01 5 ## 5 2019-04-01 1 ## 6 2019-05-01 13
日ごとのときと同じです。
投稿なしの月を含むデータフレームを作成します。
# 作図用のデータフレームを作成 post_df <- date_df %>% dplyr::right_join(base_df, by = "date") %>% # 月情報に統合 dplyr::mutate( post = tidyr::replace_na(post, replace = 0), # 投稿なしを0に置換 year = format(date, "%Y"), # 年を抽出 month = format(date, "%m") # 月を抽出 ) head(post_df)
## # A tibble: 6 x 4 ## date post year month ## <date> <int> <chr> <chr> ## 1 2018-12-01 9 2018 12 ## 2 2019-01-01 5 2019 01 ## 3 2019-02-01 2 2019 02 ## 4 2019-03-01 5 2019 03 ## 5 2019-04-01 1 2019 04 ## 6 2019-05-01 13 2019 05
x軸とy軸の値として、format()で年と月の値を抽出します。
投稿数のヒートマップを作成します。
# ヒートマップを作成 ggplot(post_df, aes(x = year, y = month, fill = post)) + geom_tile() + # ヒートマップ #geom_text(mapping = aes(label = post), color = "white") + # 記事数ラベル scale_fill_gradient(low = "white", high = "hotpink") + # タイルの色 labs(title = paste0(blog_url, "の記事投稿数"), subtitle = paste("総記事数:", sum(post_df[["post"]])), x = "年", y = "月", fill = "記事数")
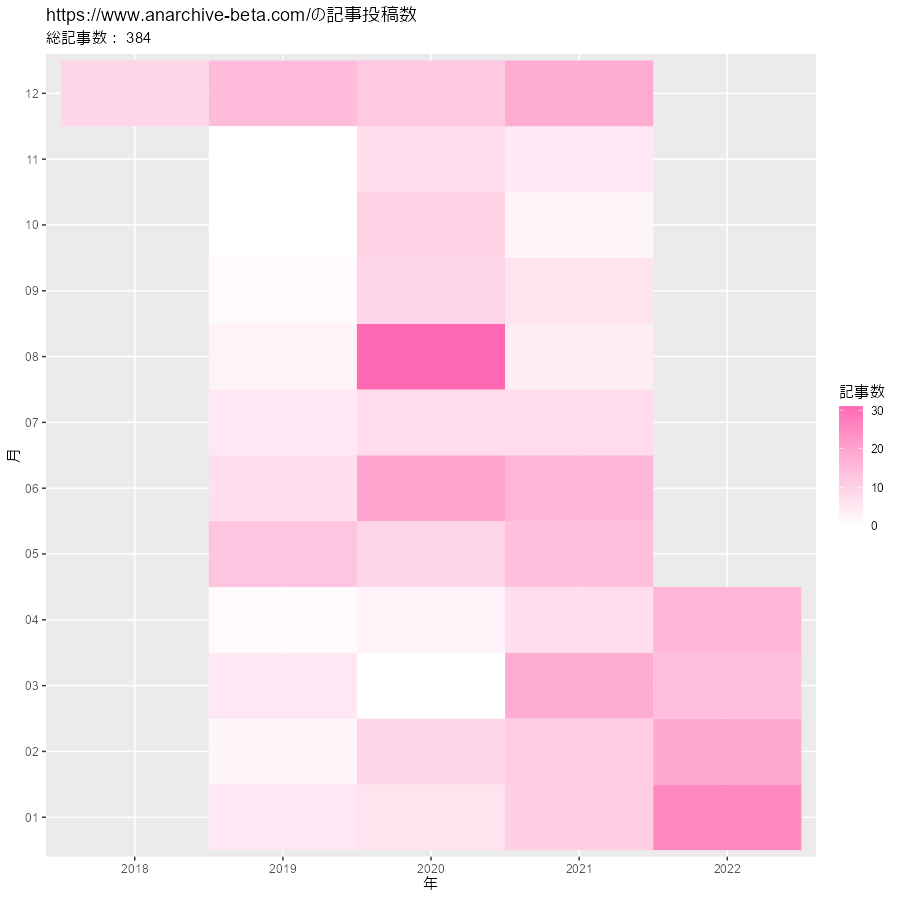
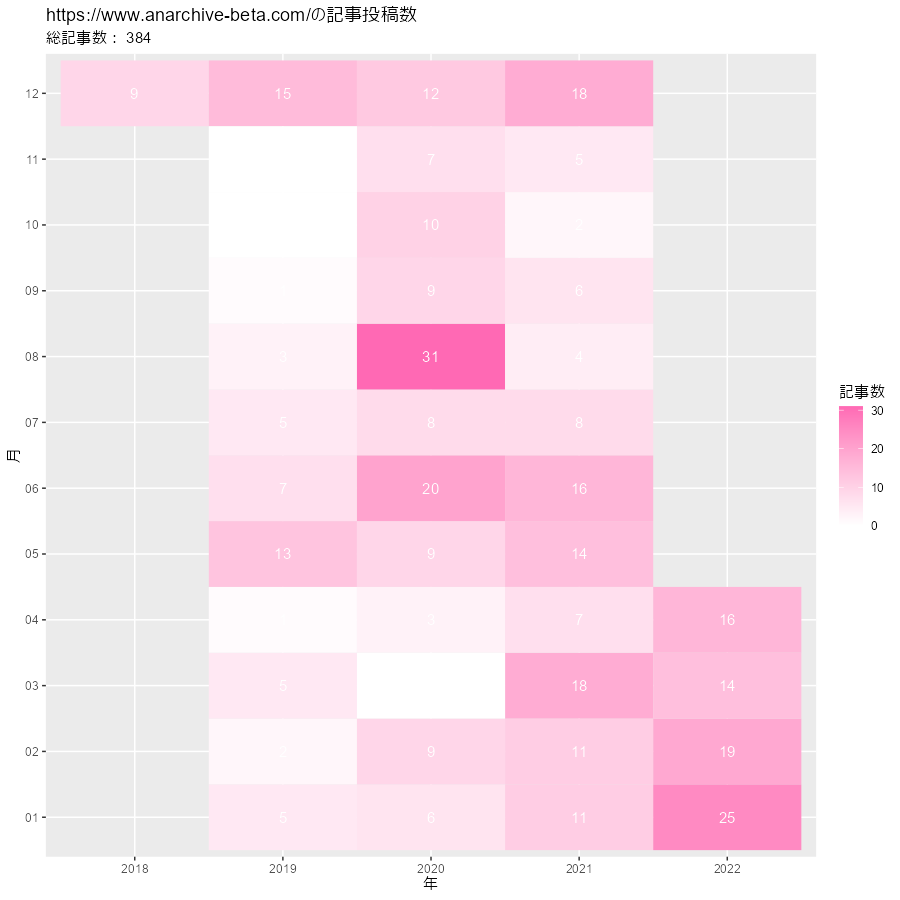
毎年、年末年始とゴールデンウイーク辺りで頑張る感じですかね。実際は、新しい記事を書いてるときと過去記事の加筆修正をしているときがあるので、投稿数だけではこのブログの活動を可視化できません!
時別
続いて、投稿日の情報は無視して、投稿時間に注目してみます。
全ての時刻(0から23の整数)を持つデータフレームを作成します。
# 期間内の時刻情報を作成 base_df <- tibble::tibble(hour = 0:23) head(base_df)
## # A tibble: 6 x 1 ## hour ## <int> ## 1 0 ## 2 1 ## 3 2 ## 4 3 ## 5 4 ## 6 5
記事URLから投稿時刻を抽出します。
# 記事URLを投稿日時に変換 datetime_vec <- url_vec %>% stringr::str_remove(pattern = paste0(blog_url, "entry/")) %>% # 日時を示す文字列を抽出 lubridate::as_datetime(tz = "Asia/Tokyo") %>% # POSIXt型に変換 sort() # 昇順に並び替え datetime_vec[1:5]
## [1] "2018-12-01 16:44:52 JST" "2018-12-02 23:38:40 JST" ## [3] "2018-12-03 23:45:25 JST" "2018-12-04 23:48:31 JST" ## [5] "2018-12-05 23:43:43 JST"
時刻ごとの投稿数を集計します。
# 時刻ごとに投稿数を集計 hour_df <- tibble::tibble( hour = lubridate::hour(datetime_vec) # 時刻を抽出 ) %>% # データフレームに変換 dplyr::count(hour, name = "post") # 投稿数をカウント head(hour_df)
## # A tibble: 6 x 2 ## hour post ## <int> <int> ## 1 0 4 ## 2 1 2 ## 3 2 4 ## 4 3 6 ## 5 4 3 ## 6 6 5
lubridateパッケージのhour()で時刻の値を抽出して、データフレームを作成します。
5時に投稿された記事(hour列が5の行)がないのが分かります。
投稿なしの時刻を含めたデータフレームを作成します。
# 作図用のデータフレームを作成 post_df <- hour_df %>% dplyr::right_join(base_df, by = "hour") %>% # 時刻情報に統合 dplyr::mutate(post = tidyr::replace_na(post, replace = 0)) %>% # 投稿なしを0に置換 dplyr::arrange(hour) head(post_df)
## # A tibble: 6 x 2 ## hour post ## <int> <int> ## 1 0 4 ## 2 1 2 ## 3 2 4 ## 4 3 6 ## 5 4 3 ## 6 5 0
5時の投稿数を示す行が追加されたのが分かります。
投稿数のヒートマップを作成します。
# ヒートマップを作成 ggplot(post_df, aes(x = 1, y = hour, fill = post)) + geom_tile() + # ヒートマップ geom_text(mapping = aes(label = post), color = "white") + # 記事数ラベル scale_fill_gradient(low = "white", high = "hotpink") + # タイルの色 scale_x_continuous(breaks = NULL) + # x軸目盛 scale_y_continuous(breaks = 0:23, minor_breaks = FALSE) + # y軸目盛 labs(title = paste0(blog_url, "の記事投稿数"), subtitle = paste("総記事数:", sum(post_df[["post"]])), x = "", y = "時", fill = "記事数")
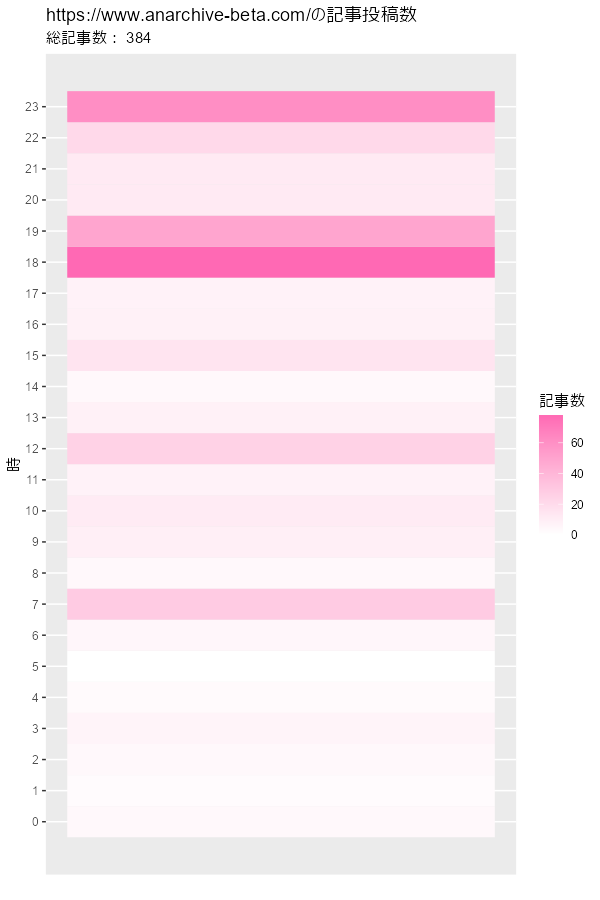
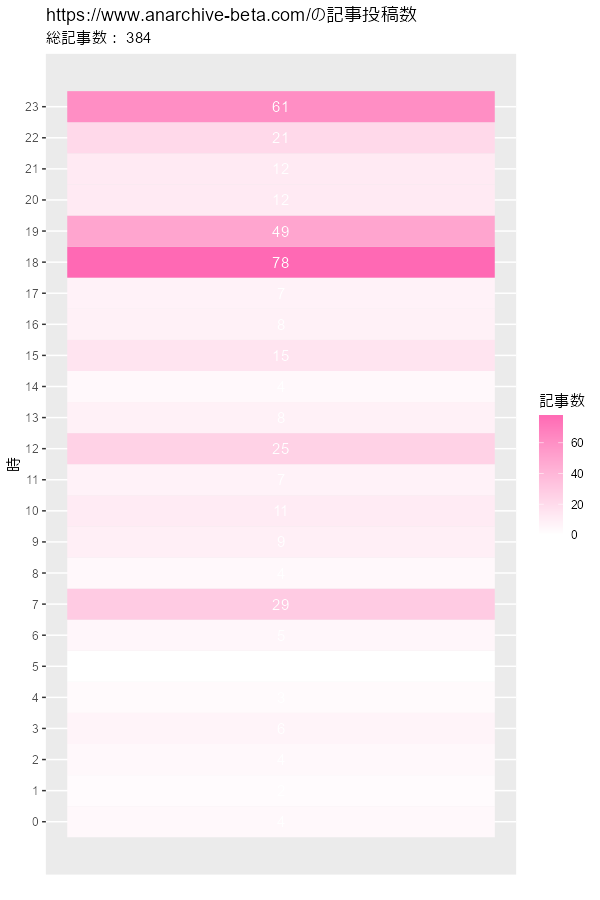
読まれやすそうな時間と日付が変わる間際が多いですね。
同じ値を棒グラフにしてみます。
# 棒グラフを作成 ggplot(post_df, aes(x = hour, y = post)) + geom_bar(stat = "identity", fill = "hotpink", color = "white") + # ヒートマップ geom_text(mapping = aes(label = post), color = "hotpink", vjust = -0.5) + # 記事数ラベル scale_x_continuous(breaks = 0:23, minor_breaks = FALSE) + # y軸目盛 labs(title = paste0(blog_url, "の記事投稿数"), subtitle = paste("総記事数:", sum(post_df[["post"]])), x = "時", y = "記事数")

軸が1つなら棒グラフの方が分かりやすいですね。
分別
最後に、時と分で投稿数を可視化します。
全ての時(0から23の整数)と10分間隔の分(0,10,...,50)の組み合わせを持つデータフレームを作成します。
# 時・分情報を作成 base_df <- tibble::tibble( hour = rep(0:23, each = 6), minute = rep(0:5*10, times = 24) ) head(base_df)
## # A tibble: 6 x 2 ## hour minute ## <int> <dbl> ## 1 0 0 ## 2 0 10 ## 3 0 20 ## 4 0 30 ## 5 0 40 ## 6 0 50
rep()で要素を複製します。each引数は要素ごとに複製、times引数はベクトルを繰り返して複製します。
記事URLから投稿時刻を抽出します
# 記事URLを投稿日時に変換 datetime_vec <- url_vec %>% stringr::str_remove(pattern = paste0(blog_url, "entry/")) %>% # 日時を示す文字列を抽出 lubridate::as_datetime(tz = "Asia/Tokyo") %>% # POSIXt型に変換 lubridate::floor_date(unit = "10minutes") %>% # 10分刻みに切り捨て sort() # 昇順に並び替え datetime_vec[1:5]
## [1] "2018-12-01 16:40:00 JST" "2018-12-02 23:30:00 JST" ## [3] "2018-12-03 23:40:00 JST" "2018-12-04 23:40:00 JST" ## [5] "2018-12-05 23:40:00 JST"
floor_date()のunit引数に"10minutes"を指定して、10分単位に切り捨てます。
時刻ごとの投稿数を集計します。
# 時・分ごとに投稿数を集計 datetime_df <- tibble::tibble( hour = lubridate::hour(datetime_vec), # 時を抽出 minute = lubridate::minute(datetime_vec) # 分を抽出 ) %>% dplyr::count(hour, minute, name = "post") # 投稿数をカウント head(datetime_df)
## # A tibble: 6 x 3 ## hour minute post ## <int> <int> <int> ## 1 0 10 1 ## 2 0 40 2 ## 3 0 50 1 ## 4 1 10 2 ## 5 2 20 1 ## 6 2 30 2
hour()で時間、minute()で分の値を抽出して、データフレームを作成します。
投稿なしの時刻を含めたデータフレームを作成します。
# 作図用のデータフレームを作成 post_df <- datetime_df %>% dplyr::right_join(base_df, by = c("hour", "minute")) %>% # 時・分情報に統合 dplyr::mutate(post = tidyr::replace_na(post, replace = 0)) %>% # 投稿なしを0に置換 dplyr::arrange(hour, minute) # 昇順に並び替え head(post_df)
## # A tibble: 6 x 3 ## hour minute post ## <int> <dbl> <int> ## 1 0 0 0 ## 2 0 10 1 ## 3 0 20 0 ## 4 0 30 0 ## 5 0 40 2 ## 6 0 50 1
right_join()のby引数に列名のベクトルを指定することで、複数の列でマッチして結合できます。
投稿数のヒートマップを作成します。
# ヒートマップを作成 ggplot(post_df, aes(x = hour, y = minute, fill = post)) + geom_tile() + # ヒートマップ #geom_text(mapping = aes(label = post), color = "white") + # 記事数ラベル scale_fill_gradient(low = "white", high = "hotpink") + # タイルの色 scale_x_continuous(breaks = 0:23, minor_breaks = FALSE) + # x軸目盛 scale_y_continuous(breaks = 0:5*10, minor_breaks = FALSE) + # y軸目盛 labs(title = paste0(blog_url, "の記事投稿数"), subtitle = paste("総記事数:", sum(post_df[["post"]])), x = "時", y = "分", fill = "記事数")
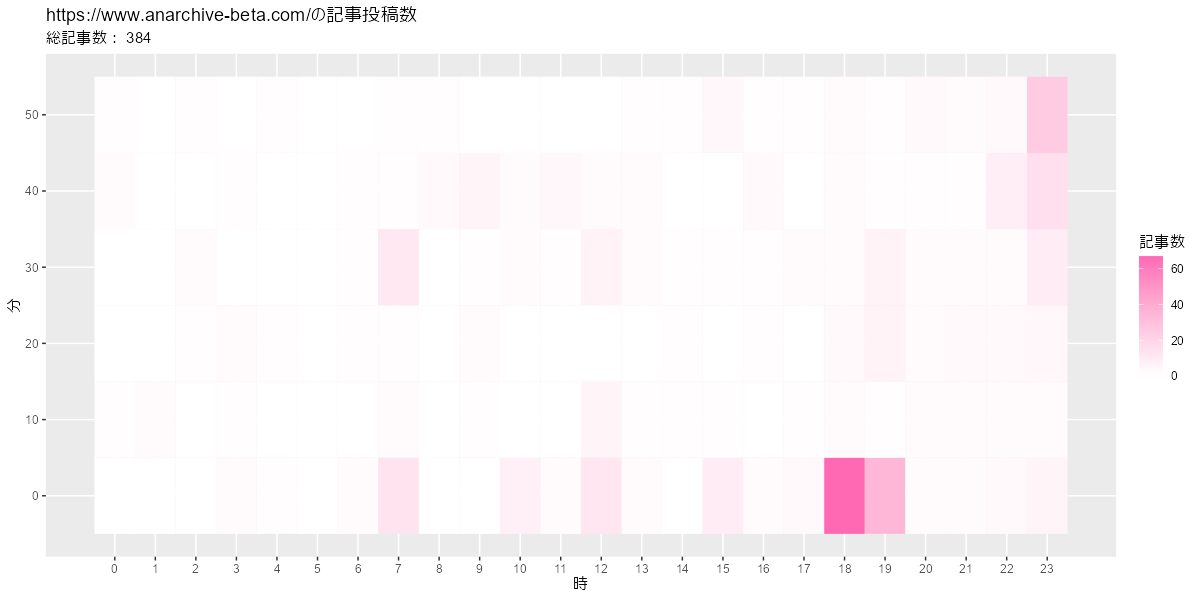
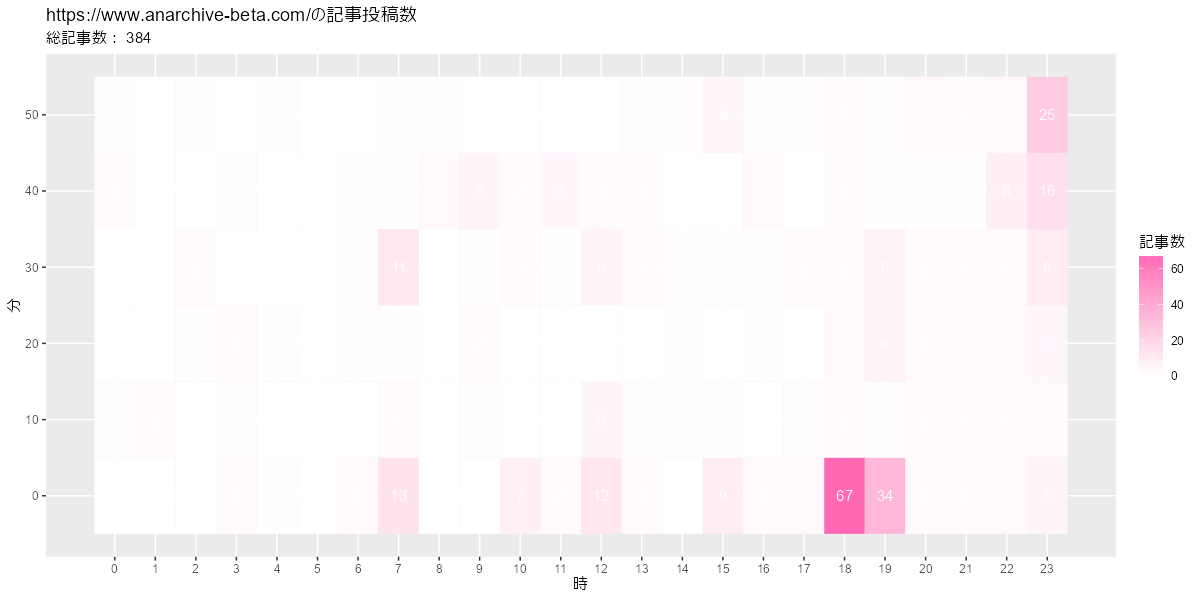
予約投稿のときは切りのよい00分や30分に設定するので、このようなグラフになります。後は、日付の変わるギリギリに投稿するのが見えます。
以上で、ブログの更新数をヒートマップで可視化できました。
正確な投稿日時の取得
ちなみに、正確な投稿日時は次のようにして得られます。
# 記事番号を指定 i <- 1 # 記事URLを取り出し entry_url <- url_vec[i] # 記事HTMLを取得 entry_html <- rvest::read_html(entry_url) # 記事テキストを抽出 entry_datetime <- entry_html %>% #rvest::html_elements("header") %>% # ヘッダー rvest::html_elements(".entry-date") %>% # 記事の日時データ rvest::html_elements("time") %>% # 投稿日時 rvest::html_attr("datetime") %>% # 日時データ lubridate::as_datetime(tz = "UTC") %>% # POLITXt型に変換 lubridate::as_datetime(tz = "Asia/Tokyo") # 日本標準時に変換 entry_url; entry_datetime
## [1] "https://www.anarchive-beta.com/entry/2018/12/01/164452" ## [1] "2018-12-01 16:44:52 JST"
ただし、このやり方だと1記事ずつアクセスする必要があります。
参考書籍
- 「Rが生産性を高める 〜データ分析ワークフロー効率化の実践」igjit・atusy・hanaori 著,技術評論社,2022年.
おわりに
本に載っているスクレイピングと文字列処理で何かできないかなと思いやってみました。文字列処理なのに数値データになってグラフになるのが個人的には面白かったです。次の記事ではもう少し文字列処理感のある内容をします。
ところで、例えば「6時10分」の「6」のことをなんと呼べばいいのか悩みました。表記が揺れてますが見逃してください。
【次の内容】