はじめに
ハロー!プロジェクトの歴史を可視化しようシリーズ(仮)です。
この記事では、各アーティストのシングルリリース数の推移をバーチャートレースにします。
【他の記事】
【目次】
シングルリリース数の推移の可視化
ハロー!プロジェクトのアーティストのシングルリリース数の推移をバーチャートレースで可視化します。
次のパッケージを利用します。
# 利用パッケージ library(tidyverse) library(lubridate) library(gganimate)
この記事では、基本的にパッケージ名::関数名()の記法を使うので、パッケージを読み込む必要はありません。
ただし、パイプ演算子%>%を使うためmagrittrと、作図コードがごちゃごちゃしないようにパッケージ名を省略するためggplot2は読み込む必要があります。
データの読込
次のページのデータを利用します。
GitHub上のcsvデータをRから読み込めたらよかったのですがやり方が分からなかったので、ダウンロードしてローカルフォルダに保存しておきます。
保存先のフォルダパスを指定します。
# フォルダパスを指定 dir_path <- "data/HP_DB-main/"
ファイルの読み込み時にファイル名を結合する(ファイルパスにする)ので、末尾を/にしておきます。
シングルの情報を読み込みます。
# シングル一覧を読み込み single_df <- readr::read_csv( file = paste0(dir_path, "single.csv"), col_types = readr::cols( singleID = "i", singleName = "c", releaseDate = readr::col_date(format = "%Y/%m/%d"), singleCategory = "c", artistName = "c" ) ) %>% dplyr::arrange(releaseDate, singleID) # 昇順に並び替え single_df
## # A tibble: 569 x 5 ## singleID singleName releaseDate singleCategory artistName ## <int> <chr> <date> <chr> <chr> ## 1 1 愛の種 1997-11-03 インディーズシング~ モーニン~ ## 2 2 GET 1997-11-05 シングル 平家みちよ ## 3 3 モーニングコーヒー 1998-01-28 シングル モーニン~ ## 4 4 卒業 ~TOP OF THE WORLD~ 1998-02-15 シングル 平家みちよ ## 5 5 サマーナイトタウン 1998-05-27 シングル モーニン~ ## 6 6 ダイキライ 1998-07-01 シングル 平家みちよ ## 7 7 カラスの女房 1998-08-05 シングル 中澤裕子 ## 8 8 抱いてHOLD ON ME! 1998-09-09 シングル モーニン~ ## 9 9 だけど 愛しすぎて 1998-10-25 シングル 平家みちよ ## 10 10 ラストキッス 1998-11-18 シングル タンポポ ## # ... with 559 more rows
single.csvは、シングルID・シングル名・リリース日・シングルカテゴリ・アーティスト名の5列のcsvファイルです。
このデータを利用して、各アーティストのシングルリリース数を集計します。
集計用の設定
集計に関する設定を行います。
期間の設定
アニメーションとしてグラフ化する(リリース数を集計する)期間を指定します。
# 期間を指定 date_from <- "1997-10-01" date_to <- "2022-04-15" #date_to <- lubridate::today() %>% # as.character()
開始日をdate_from、終了日をdate_toとして期間を指定します。文字列でyyyy-mm-ddやyyyy/mm/dd、yyyymmddなどと指定できます。現在の日付を使う場合は、today()で設定します。ただし、次の処理でベクトルにする際にdate_from, date_toが同じ型である必要があるので、as.character()で文字列にしておきます。
開始日と終了日をベクトルにまとめます。
# 値をまとめる date_vals <- c(date_from, date_to) %>% lubridate::as_date() %>% # Date型に変換 lubridate::floor_date(unit = "mon") # 月単位に切り捨て date_vals
## [1] "1997-10-01" "2022-04-01"
文字列型で指定した開始日と終了日を、as_date()でDate型に変換し、さらにfloor_date()のunit引数に"mon"を指定して月初の日付にして(日にちを切り捨てて)おきます。
シングルカテゴリの設定
シングルのカテゴリを確認します。
# シングルの種類を確認 unique(single_df[["singleCategory"]])
## [1] "インディーズシングル" "シングル" "配信限定シングル" ## [4] "DVDシングル" "サウンドトラック"
5種類のシングルがあるのが分かります。
集計に利用するカテゴリを指定します。
# シングルの種類を指定 single_category <- c("インディーズシングル", "シングル")
この例では、インディーズシングル・シングルのリリース数を集計します。
連名作品の編集
続いて、アーティスト名を確認します。
# アーティスト名を確認 unique(single_df[["artistName"]])[1:10]
## [1] "モーニング娘。" "平家みちよ" "中澤裕子" ## [4] "タンポポ" "中澤ゆうこ&高山厳" "太陽とシスコムーン" ## [7] "中澤ゆうこ" "ココナッツ娘" "カントリー娘。" ## [10] "三佳千夏"
「Berryz工房×℃-ute」のような複数アーティストの連名作品や、「中澤ゆうこ&高山厳」のようにハロプロ以外のアーティスト名を含む作品、「カントリー娘。に石川梨華(モーニング娘。)」のようにグループ名を含む名義、「中澤ゆうこ」「モーニング娘。'14」「アンジュルム」のような名義変更や改名に対応する必要があります。
連名作品についてはここで対応します。名義の修正は集計時に行います。
連名作品のデータを分割(複製)する際に利用するベクトルを作成します(目視で確認しながら頑張って指定します)。
# 連名作品の名義を指定 pattern_vec <- c( "7AIR/SALT5/11WATER", "セクシーオトナジャン/エレジーズ/プリプリピンク", "ガーディアンズ4/しゅごキャラエッグ!", "Berryz工房×℃-ute", "ピーベリー/ハーベスト", "DIY♡/GREEN FIELDS", "ハロプロ研修生 feat. Juice=Juice", "ダイヤレディー/メロウクアッド/HI-FIN", "さとのあかり/トリプレット/ODATOMO", "カントリー・ガールズ/つばきファクトリー", "つばきファクトリー/ハロプロ研修生", "こぶしファクトリー&つばきファクトリー" ) # 分割後のアーティスト名を指定 replace_vec <- c( "7AIR", "SALT5", "11WATER", "セクシーオトナジャン", "エレジーズ", "プリプリピンク", "ガーディアンズ4", "しゅごキャラエッグ!", "ガーディアンズ4", "しゅごキャラエッグ!", "Berryz工房", "℃-ute", "Berryz工房", "℃-ute", "ピーベリー", "ハーベスト", "DIY♡", "GREEN FIELDS", "ハロプロ研修生", "Juice=Juice", "ダイヤレディー", "メロウクアッド", "HI-FIN", "さとのあかり", "トリプレット", "ODATOMO", "カントリー・ガールズ", "つばきファクトリー", "つばきファクトリー", "ハロプロ研修生", "こぶしファクトリー", "つばきファクトリー" ) # 分割する数を指定 n_vec <- c( 3, 3, 2, 2, 2, 2, 2, 2, 2, 3, 3, 2, 2, 2 )
分割する必要のあるアーティスト名をpattern_vecに指定します。
分割後に設定するアーティスト名をreplace_vecに指定します。
分割(複製)するデータ(行)数をn_vecに指定します。
例えば、アーティスト名が「Berryz工房×℃-ute」のデータを「Berryz工房」と「℃-ute」の2行に分割する場合は、pattern_vecを"Berryz工房×℃-ute"・replace_vecをc("Berryz工房", "℃-ute"")・n_vecを2と指定します。
replace_vecの要素数とsum(n_vec)が一致します。
連名作品のデータを取り出して分割します。
# 連名作品を分割 split_df <- single_df %>% dplyr::filter(artistName %in% pattern_vec) %>% # 連名の作品を抽出 tibble::add_column(n = n_vec) %>% # 複製数を追加 tidyr::uncount(n) %>% # 作品を複製 dplyr::mutate(artistName = replace_vec) # 個々のアーティスト名を再設定 split_df
## # A tibble: 32 x 5 ## singleID singleName releaseDate singleCategory artistName ## <int> <chr> <date> <chr> <chr> ## 1 134 壊れない愛がほしいの/GET UP!~ 2003-07-09 シングル 7AIR ## 2 134 壊れない愛がほしいの/GET UP!~ 2003-07-09 シングル SALT5 ## 3 134 壊れない愛がほしいの/GET UP!~ 2003-07-09 シングル 11WATER ## 4 201 オンナ、哀しい、オトナ/印象派~ 2005-06-22 シングル セクシー~ ## 5 201 オンナ、哀しい、オトナ/印象派~ 2005-06-22 シングル エレジーズ ## 6 201 オンナ、哀しい、オトナ/印象派~ 2005-06-22 シングル プリプリ~ ## 7 338 PARTY TIME/わたしのたまご 2009-11-18 シングル ガーディ~ ## 8 338 PARTY TIME/わたしのたまご 2009-11-18 シングル しゅごキ~ ## 9 343 Going On! 2010-01-20 シングル ガーディ~ ## 10 343 Going On! 2010-01-20 シングル しゅごキ~ ## # ... with 22 more rows
pattern_vecに含まれるアーティストの行をfilter()と%in%演算子で抽出します。
複製する行数n_vecをadd_column()でn列として追加して、uncount()で行を複製します。
アーティスト名をreplace_vecに指定した文字列に置き換えます。
集計時に、分割前の連名作品のデータをこのデータに置き換えます。
リリース数の集計と順位付け
シングルのリリース数を集計してランキングを付けます。
リリース数の集計
アーティスト名の編集を行い、アーティストごとにリリース数を集計します。
# アーティスト名を編集してリリース数を集計 release_n_df <- single_df %>% dplyr::filter(!(artistName %in% pattern_vec)) %>% # 連名作品を削除 dplyr::bind_rows(split_df) %>% # 分割した連名作品を追加 dplyr::filter(singleCategory %in% single_category) %>% # 指定したカテゴリを抽出 dplyr::filter(releaseDate >= date_vals[1], releaseDate <= date_vals[2]) %>% # 指定した期間内の作品を抽出 dplyr::arrange(releaseDate, singleID) %>% # IDの割り当て用に昇順に並び替え dplyr::mutate( release_date = lubridate::floor_date(releaseDate, unit = "mon"), # 月単位に切り捨て artist_name = artistName %>% # グラフ表示名を追加 #stringr::str_replace(pattern = "℃-ute", replacement = "C-ute") %>% # 作図時に豆腐化するので代用 stringr::str_replace(pattern = "中澤ゆうこ&高山厳", replacement = "中澤ゆうこ") %>% # 不要な文字列を削除 stringr::str_replace(pattern = "カントリー娘。に石川梨華(モーニング娘。)", replacement = "カントリー娘。に石川梨華") %>% # グループ名を削除 stringr::str_replace(pattern = "カントリー娘。に紺野と藤本(モーニング娘。)", replacement = "カントリー娘。に紺野と藤本") %>% # グループ名を削除 stringr::str_replace(pattern = "ミニハムず/プリンちゃん", replacement = "ミニハムず") %>% # 不要な文字列を削除 stringr::str_replace(pattern = "バカ殿様とミニモニ姫。", replacement = "ミニモニ。") %>% # 企画名義を元の名前に変更 stringr::str_replace(pattern = "ミニモニ。と高橋愛+4KIDS", replacement = "ミニモニ。") %>% # ゲスト名を削除 stringr::str_replace(pattern = "おけいさんと安倍なつみ", replacement = "安倍なつみ") %>% # 不要な文字列を削除 stringr::str_replace(pattern = "あややム with エコハムず", replacement = "松浦亜弥") %>% # 企画名義を元の名前に変更 stringr::str_replace(pattern = "DEF.DIVAと楽天イーグルス応援隊", replacement = "DEF.DIVA") %>% # 不要な文字列を削除 stringr::str_replace(pattern = "月島きらり.*", replacement = "月島きらり(久住小春)") %>% # 長いので省略 stringr::str_replace(pattern = "THE ポッシボー.*", replacement = "THE ポッシボー") %>% # メンバー名を削除 stringr::str_replace(pattern = "里田まい with 藤岡藤巻", replacement = "里田まい") %>% # 不要な文字列を削除 stringr::str_replace(pattern = "ジンギスカン×Berryz工房", replacement = "Berryz工房") %>% # 不要な文字列を削除 stringr::str_replace(pattern = "矢口真里/エアバンド", replacement = "矢口真里") %>% # 不要な文字列を削除 stringr::str_replace(pattern = "北神未海(CV 小川真奈)with MM学園 合唱部/氷室衣舞(声:菅谷梨沙子/Berryz工房)", replacement = "氷室衣舞(菅谷梨沙子)") %>% # 不要な文字列を削除 stringr::str_replace(pattern = "むてん娘。", replacement = "モーニング娘。") %>% # 企画名義を元の名前に変更 stringr::str_replace(pattern = "おはガールメープル with スマイレージ", replacement = "スマイレージ") %>% # 不要な文字列を削除 stringr::str_replace(pattern = "NEXT YOU/Juice=Juice", replacement = "Juice=Juice") %>% # 企画名義を元の名前に変更 stringr::str_remove(pattern = "\\(モーニング娘。'17\\)") %>% # グループ名を削除 stringr::str_remove(pattern = "\\(アンジュルム\\)") %>% # グループ名を削除 stringr::str_remove(pattern = "\\(Juice=Juice\\)") %>% # グループ名を削除 stringr::str_remove(pattern = "\\(こぶしファクトリー\\)") %>% # グループ名を削除 stringr::str_remove(pattern = "\\(つばきファクトリー\\)") %>% # グループ名を削除 stringr::str_remove(pattern = "\\(ハロプロ研修生\\)") %>% # グループ名を削除 stringr::str_remove(pattern = "\\(アンジュルム/カントリー・ガールズ\\)") %>% # グループ名を削除 stringr::str_remove(pattern = "\\(LoVendoЯ\\)"), # グループ名を削除 artist_idname = artist_name %>% # IDの割り当て用に編集 stringr::str_replace(pattern = "^モーニング娘。.*", replacement = "モーニング娘。") %>% # ナンバリングを削除 stringr::str_replace(pattern = "中澤ゆうこ", replacement = "中澤裕子") %>% # ソロ用名義を名前に統一 stringr::str_replace(pattern = "T&Cボンバー", replacement = "太陽とシスコムーン") %>% # 改名前に統一 stringr::str_replace(pattern = "カントリー娘。.*", replacement = "カントリー娘。") %>% # ゲスト名を削除 stringr::str_replace(pattern = "ミニハムず", replacement = "ミニモニ。") %>% # 企画名義を元の名前に変更 stringr::str_replace(pattern = "S/mileage", replacement = "スマイレージ") %>% # 改名後に統一 stringr::str_replace(pattern = "アンジュルム", replacement = "スマイレージ") %>% # 改名前に統一 stringr::str_replace(pattern = "ハロプロ研修生北海道 feat.稲場愛香", replacement = "ハロプロ研修生北海道"), # ゲスト名を削除 artist_idname = factor(artist_idname, levels = unique(artist_idname)), # レベル設定のため因子型に変換 artist_id = dplyr::dense_rank(artist_idname) # アーティストIDを追加 ) %>% # アーティスト名を編集 dplyr::group_by(release_date, artist_id) %>% # カウント用にグループ化 dplyr::mutate(release_n = dplyr::row_number()) %>% # リリース数をカウント:(count()で処理できるならしたい) dplyr::filter(release_n == max(release_n)) %>% # 同じ月に複数リリースしていると重複するので遅い方を採用 dplyr::group_by(artist_id) %>% # 累積和の計算用にグループ化 dplyr::mutate(release_n = cumsum(release_n)) %>% # リリース数の累積和を計算 dplyr::arrange(release_date, artist_id) %>% # 複製数の追加用に並べ替え dplyr::group_by(artist_id) %>% # 複製数の追加用にグループ化 dplyr::mutate( next_release_date = release_date %>% dplyr::lead(n = 1) %>% # 1行前に値をズラす tidyr::replace_na( replace = lubridate::today() %>% lubridate::rollforward(roll_to_first = TRUE) ), # 最後の行を現在の翌月にする n = lubridate::interval(start = release_date, end = next_release_date) %>% lubridate::time_length(unit = "mon") # リリース数がない期間の月数を追加 ) %>% tidyr::uncount(n) %>% # 月数に応じて行を複製 dplyr::group_by(release_date, artist_id) %>% # 行番号用にグループ化 dplyr::mutate(idx = dplyr::row_number()) %>% # 行番号を割り当て dplyr::group_by(release_date, artist_id, idx) %>% # 1か月刻みの値の作成用にグループ化 dplyr::mutate(date = seq(from = release_date, to = next_release_date, by = "mon")[idx]) %>% # 複製した行を1か月刻みの値に変更 dplyr::ungroup() %>% # グループ化を解除 dplyr::select(date, artist_id, artist_name, release_n) %>% # 利用する列を選択 dplyr::arrange(date, artist_id) # 昇順に並べ替え release_n_df
## # A tibble: 16,209 x 4 ## date artist_id artist_name release_n ## <date> <int> <chr> <int> ## 1 1997-11-01 1 モーニング娘。 1 ## 2 1997-11-01 2 平家みちよ 1 ## 3 1997-12-01 1 モーニング娘。 1 ## 4 1997-12-01 2 平家みちよ 1 ## 5 1998-01-01 1 モーニング娘。 2 ## 6 1998-01-01 2 平家みちよ 1 ## 7 1998-02-01 1 モーニング娘。 2 ## 8 1998-02-01 2 平家みちよ 2 ## 9 1998-03-01 1 モーニング娘。 2 ## 10 1998-03-01 2 平家みちよ 2 ## # ... with 16,199 more rows
先ほどは、pattern_vecに指定したアーティストをfilter()と%in%演算子で抽出しました。ここでは、!でTRUEとFALSEを入れ替えて、pattern_vecに含まれないアーティストのデータを抽出します。
連名作品を除去したので、分割した連名作品split_dfをbind_rows()で結合します。
集計期間date_valsに発売されたデータを抽出します。
「グラフに表示する用のアーティスト名列artist_name」と「集計用(ID割り当て用)のアーティスト名列artist_idname」を作成します。
表示名では、例えば「月島きらり starring 久住小春(モーニング娘。)」を「月島きらり(久住小春)」のように書き換えます。
集計用名では、例えば「モーニング娘。'14」を「モーニング娘。」、「アンジュルム」を「スマイレージ」のように書き換えて、同一アーティストの名前を統一します。
各集計用名に対してdense_rank()で通し番号を割り当てて、アーティストID列artist_idとします。
IDの割り当て前に、artist_idname列を因子型に変換してレベルを設定しておくと、IDの割り当て順を指定できます。この例では、1枚目の発売が早い順(同月ならシングルIDが小さい順)になります。因子型にしない場合は、文字列の基準で昇順になります。
「発売月・ID」が同じ行ごとにrow_number()で通し番号を割り当てて、release_n列とします。release_n列が最大の行を抽出することでリリース数列とします。(IDが同じで名義が異なる行を、同じグループとしてカウントしたかったけど、count()で処理できなかった?のでこんな感じになりました。)
さらに、cumsum()で累積和を計算して、各月までの合計リリース数を求めます。
ここまでで、発売された月のデータを用意できました。続いて、発売のなかった月のデータを作成します。
処理がややこしいので、下の簡単な例を使って解説します。
3か月間隔の日付を作成して、i行目とi+1行目の月数を調べます。
df1 <- tibble::tibble( date = seq( from = lubridate::as_date("2020-04-01"), to = lubridate::as_date("2022-03-01"), by = "3 months" ) ) %>% dplyr::mutate( next_date = date %>% dplyr::lead(n = 1) %>% # 1行前にズラす tidyr::replace_na( replace = lubridate::today() %>% lubridate::rollforward(roll_to_first = TRUE) ), # 最後の行を翌月にする n = lubridate::interval(start = date, end = next_date) %>% lubridate::time_length(unit = "month") # i行目とi+1行目の月数を追加 ) df1
## # A tibble: 8 x 3 ## date next_date n ## <date> <date> <dbl> ## 1 2020-04-01 2020-07-01 3 ## 2 2020-07-01 2020-10-01 3 ## 3 2020-10-01 2021-01-01 3 ## 4 2021-01-01 2021-04-01 3 ## 5 2021-04-01 2021-07-01 3 ## 6 2021-07-01 2021-10-01 3 ## 7 2021-10-01 2022-01-01 3 ## 8 2022-01-01 2022-06-01 5
seq()のby引数に"3 months"を指定して3か月間隔の日付を作成して、発売月の代わりの列dateとします。
date列を1行前にズラした列をlead()で作成して、next_dateとします。最後の行が欠損値になるので、replace_na()で置き換えます。today()とrollfoward()で現在の日付の翌月にします。
dateからnext_dateまでの月数をinterval()とtime_lenght()で調べて、n列とします。
行を複製して、1か月間隔となるように日付を再設定します。
df2 <- df1 %>% tidyr::uncount(n) %>% # 月数に応じて行を複製 dplyr::group_by(date) %>% # 行番号用にグループ化 dplyr::mutate(idx = dplyr::row_number()) %>% # 行番号を割り当て dplyr::group_by(date, idx) %>% # 1か月刻みの値の作成用にグループ化 dplyr::mutate(new_date = seq(from = date, to = next_date, by = "month")[idx]) %>% # 複製した行を1か月刻みの値に変更 dplyr::ungroup() # グループ化を解除 df2
## # A tibble: 26 x 4 ## date next_date idx new_date ## <date> <date> <int> <date> ## 1 2020-04-01 2020-07-01 1 2020-04-01 ## 2 2020-04-01 2020-07-01 2 2020-05-01 ## 3 2020-04-01 2020-07-01 3 2020-06-01 ## 4 2020-07-01 2020-10-01 1 2020-07-01 ## 5 2020-07-01 2020-10-01 2 2020-08-01 ## 6 2020-07-01 2020-10-01 3 2020-09-01 ## 7 2020-10-01 2021-01-01 1 2020-10-01 ## 8 2020-10-01 2021-01-01 2 2020-11-01 ## 9 2020-10-01 2021-01-01 3 2020-12-01 ## 10 2021-01-01 2021-04-01 1 2021-01-01 ## # ... with 16 more rows
各行をuncount()でn行に複製します。
複製した行ごとにグループ化して、row_number()で行番号を割り当てます。
dateからnext_dateの月ベクトルを作成して、行番号に応じて値を取り出します。
ここでは分かりやすいように、作成した月列をnew_dateとしました。実際には、date列を上書きします。
以上で、月ごとに、各アーティストの合計リリース数のデータが得られました。
(ところで、私は2017年くらいからしか知らないのですが、解釈違いとか生じてないでしょうか?例えば、ミニモニ。とミニハムずって一緒にしていいの?、モーニング娘。おとめ組とさくら組は?)
演出用の処理
バーの変化(アニメーション)を強調するために、期間内における1枚目の発売1か月前のデータ(リリース数が0のデータ)を作成します。
各アーティストの「1枚目の発売1か月前」のデータフレームを作成します。
# 1枚目のリリース前月のデータを作成 release_0_df <- release_n_df %>% dplyr::group_by(artist_id) %>% # 1枚目の抽出用にグループ化 dplyr::filter(date == min(date)) %>% # 1枚目を抽出 dplyr::ungroup() %>% # グループ化を解除 dplyr::mutate( date = date %>% lubridate::rollback() %>% lubridate::floor_date(unit = "mon"), artist_name = " ", release_n = 0 ) %>% # 1か月前のデータに書き換え dplyr::filter(date >= date_vals[1], date <= date_vals[2]) # 指定した期間内のデータを抽出 release_0_df
## # A tibble: 85 x 4 ## date artist_id artist_name release_n ## <date> <int> <chr> <dbl> ## 1 1997-10-01 1 " " 0 ## 2 1997-10-01 2 " " 0 ## 3 1998-07-01 3 " " 0 ## 4 1998-10-01 4 " " 0 ## 5 1999-03-01 5 " " 0 ## 6 1999-06-01 6 " " 0 ## 7 1999-06-01 7 " " 0 ## 8 1999-07-01 8 " " 0 ## 9 1999-10-01 9 " " 0 ## 10 2000-01-01 10 " " 0 ## # ... with 75 more rows
編集と集計を行ったデータrelease_n_dfから、アーティストごとに、日付列dateが最小の行をfilter()で抽出します。
date列が1枚目の発売月になるので、rollback()とfloor_date()で1か月前の日付にします。
発売前のデータとして、アーティスト名を半角スペース" "、リリース数を0にします。
集計期間date_vals内のデータをfilter()で抽出します。
リリース数の順位付け
各月における「リリース数」と「順位」のデータフレームを作成します。
# 描画する順位を指定 max_rank <- 50 # リリース数で順位付け rank_df <- dplyr::bind_rows(release_0_df, release_n_df) %>% # 発売前月のデータを追加:(小細工する場合) dplyr::arrange(date, artist_id) %>% # 昇順に並び替え dplyr::group_by(date) %>% # 月でグループ化 dplyr::mutate( artist_id = factor(artist_id), # 作図用に因子型に変換 ranking = dplyr::row_number(-release_n) # ランキング列を追加 ) %>% dplyr::ungroup() %>% # グループ化を解除 dplyr::filter(ranking <= max_rank) %>% # ランク上位グループを抽出 dplyr::arrange(date, ranking) # 昇順に並べ替え rank_df
## # A tibble: 11,957 x 5 ## date artist_id artist_name release_n ranking ## <date> <fct> <chr> <dbl> <int> ## 1 1997-10-01 1 " " 0 1 ## 2 1997-10-01 2 " " 0 2 ## 3 1997-11-01 1 "モーニング娘。" 1 1 ## 4 1997-11-01 2 "平家みちよ" 1 2 ## 5 1997-12-01 1 "モーニング娘。" 1 1 ## 6 1997-12-01 2 "平家みちよ" 1 2 ## 7 1998-01-01 1 "モーニング娘。" 2 1 ## 8 1998-01-01 2 "平家みちよ" 1 2 ## 9 1998-02-01 1 "モーニング娘。" 2 1 ## 10 1998-02-01 2 "平家みちよ" 2 2 ## # ... with 11,947 more rows
リリース前のデータrelease_0_dfとリリース数のデータrelease_n_dfをbind_rows()で結合します。
バーの色分け用に、アーティストIDを因子型に変換します。
row_number()でリリース数に応じて順位を付けて、ranking列とします。指定した列を昇順にして通し番号が割り当てられるので、-を付けて大小関係を反転させます。
描画する順位を指定しておき、上位のデータをfilter()で抽出します。
以上で、必要なデータを得られました。次は、作図を行います。
推移の可視化
リリース数と順位を棒グラフで可視化します。
バーチャートレースの作成
シングルリリース数の推移をバーチャートレースで可視化します。バーチャートレースの作図については「【R】バーチャートレースのアニメーションの作図【gganimate】 - からっぽのしょこ」を参照してください。
フレームに関する値を指定します。
# 遷移フレーム数を指定 t <- 8 # 一時停止フレーム数を指定 s <- 2 # 1秒間に表示する月数を指定:(値が大きいと意図した通りにならない) mps <- 3 # フレーム数を取得 n <- length(unique(rank_df[["date"]])) n
## [1] 296
現月と次月のグラフを繋ぐアニメーションのフレーム数をtとして、整数を指定します。
各月のグラフで一時停止するフレーム数をsとして、整数を指定します。
基本となるフレーム数(月の数)をnとします。
バーチャートレースを作成します。
# バーチャートレースを作成:(y軸可変) anim <- ggplot(rank_df, aes(x = ranking, y = release_n, fill = artist_id, color = artist_id)) + geom_bar(stat = "identity", width = 0.9, alpha = 0.8) + # リリース数のバー geom_text(aes(y = 0, label = paste(artist_name, " ")), hjust = 1) + # アーティスト名のラベル geom_text(aes(label = paste(" ", round(release_n, 0), "枚")), hjust = 0) + # リリース数のラベル gganimate::transition_states(states = date, transition_length = t, state_length = s, wrap = FALSE) + # フレーム gganimate::ease_aes("cubic-in-out") + # アニメーションの緩急 theme( axis.title.x = element_blank(), # x軸のラベル axis.title.y = element_blank(), # y軸のラベル axis.text.x = element_blank(), # x軸の目盛ラベル axis.text.y = element_blank(), # y軸の目盛ラベル axis.ticks.x = element_blank(), # x軸の目盛指示線 axis.ticks.y = element_blank(), # y軸の目盛指示線 #panel.grid.major.x = element_line(color = "grey", size = 0.1), # x軸の主目盛線 panel.grid.major.y = element_blank(), # y軸の主目盛線 #panel.grid.minor.x = element_blank(), # x軸の補助目盛線 panel.grid.minor.y = element_blank(), # y軸の補助目盛線 panel.border = element_blank(), # グラフ領域の枠線 #panel.background = element_blank(), # グラフ領域の背景 plot.title = element_text(color = "black", face = "bold", size = 20, hjust = 0.5), # 全体のタイトル plot.subtitle = element_text(color = "black", size = 15, hjust = 0.5), # 全体のサブタイトル plot.margin = margin(t = 10, r = 50, b = 10, l = 150, unit = "pt"), # 全体の余白 legend.position = "none" # 凡例の表示位置 ) + # 図の体裁 coord_flip(clip = "off", expand = FALSE) + # 軸の入れ変え scale_x_reverse() + # x軸を反転 gganimate::view_follow(fixed_x = TRUE) + # 表示範囲の調整 labs( title = "ハロプロアーティストのシングルリリース数の推移", subtitle = paste0( "カテゴリ:[", paste0(single_category, collapse = ", "), "]\n", lubridate::year(date_from), "年", lubridate::month(date_from), "月~", "{lubridate::year(closest_state)}年{lubridate::month(closest_state)}月" ), caption = "データ:「https://github.com/xxgentaroxx/HP_DB」" ) # ラベル
y軸を最大値で固定して描画します。
animate()でgif画像を作成します。
# gif画像を作成 g <- gganimate::animate( plot = anim, nframes = n*(t+s), fps = (t+s)*mps, width = 900, height = 800 ) g
plot引数にグラフ、nframes引数にフレーム数、fps引数に1秒当たりのフレーム数を指定します。
(ファイルサイズの上限は越えてないんだけどアップロードできなかったので完成例は省略します。)
anim_save()でgif画像を保存します。
# gif画像を保存 gganimate::anim_save(filename = "output/SingleNum.gif", animation = g)
filename引数にファイルパス("(保存する)フォルダ名/(作成する)ファイル名.gif")、animation引数に作成したgif画像を指定します。
動画を作成する場合は、renderer引数を指定します。
# 動画を作成と保存 m <- gganimate::animate( plot = anim, nframes = n*(t+s), fps = (t+s)*mps, width = 900, height = 800, renderer = gganimate::av_renderer(file = "output/SingleNum.mp4") )
renderer引数に、レンダリング方法に応じた関数を指定します。この例では、av_renderer()を使います。
av_renderer()のfile引数に保存先のファイルパス("(保存する)フォルダ名/(作成する)ファイル名.mp4")を指定します。
ハロプロアーティストのシングルリリース数の推移です!📊 #ハロプロ pic.twitter.com/iWWJoXALEO
— しょこ📚 (@anemptyarchive) 2022年4月26日
インディーズを含めずスマイレージを含めてカウントもできる(おはガールコラボと演劇女子部が含まれてさんじゅルムにはならなかった) pic.twitter.com/npbWvoci37
— しょこ📚 (@anemptyarchive) 2022年5月24日
(記事に動画を貼れないのでこれで代用します。)
上の図は、全ての期間でカウントしたもので、全てのアーティストのデビュー作から集計しています。ただし、この時からタイトル部分の処理を変えました。
下の図は、2010年1月以降に発売された(インディーズを含めない)シングルを集計したものです。この記事の作図コードだと、こっちのようになります。
月を指定して作図
最後に、指定した月のリリース数のグラフを作成します。
# 月を指定 date_val <- "2021-05-01" # 棒グラフを作成 graph <- rank_df %>% dplyr::filter(date == lubridate::as_date(date_val)) %>% ggplot(aes(x = ranking, y = release_n, fill = artist_id, color = artist_id)) + geom_bar(stat = "identity", width = 0.9, alpha = 0.8) + # リリース数のバー geom_text(aes(y = 0, label = paste(artist_name, " ")), hjust = 1) + # グループ名のラベル geom_text(aes(y = 0, label = paste(" ", release_n, "枚")), hjust = 0, color = "white") + # リリース数のラベル theme( axis.title.y = element_blank(), # y軸のラベル axis.text.y = element_blank(), # y軸の目盛ラベル #panel.grid.major.x = element_line(color = "grey", size = 0.1), # x軸の主目盛線 panel.grid.major.y = element_blank(), # y軸の主目盛線 panel.grid.minor.x = element_blank(), # x軸の補助目盛線 panel.grid.minor.y = element_blank(), # y軸の補助目盛線 panel.border = element_blank(), # グラフ領域の枠線 #panel.background = element_blank(), # グラフ領域の背景 plot.title = element_text(color = "black", face = "bold", size = 20, hjust = 0.5), # 全体のタイトル plot.subtitle = element_text(color = "black", size = 15, hjust = 0.5), # 全体のサブタイトル plot.margin = margin(t = 10, r = 20, b = 10, l = 125, unit = "pt"), # 全体の余白 legend.position = "none" # 凡例の表示位置 ) + # 図の体裁 coord_flip(clip = "off", expand = FALSE) + # 軸の入れ変え scale_x_reverse(breaks = 1:max(rank_df[["ranking"]])) + # x軸を反転 labs( title = "ハロプロアーティストのシングルリリース数", subtitle = paste0( "カテゴリ:[", paste0(single_category, collapse = ", "), "]\n", lubridate::year(date_from), "年", lubridate::month(date_from), "月~", lubridate::year(date_val), "年", lubridate::month(date_val), "月" ), y = "リリース数", caption = "データ:「https://github.com/xxgentaroxx/HP_DB」" ) # ラベル
ggsave()で画像を保存できます。
# 画像を保存 ggplot2::ggsave( filename = paste0("output/SingleNum_", date_val, ".png"), plot = graph, width = 24, height = 24, units = "cm", dpi = 100 )
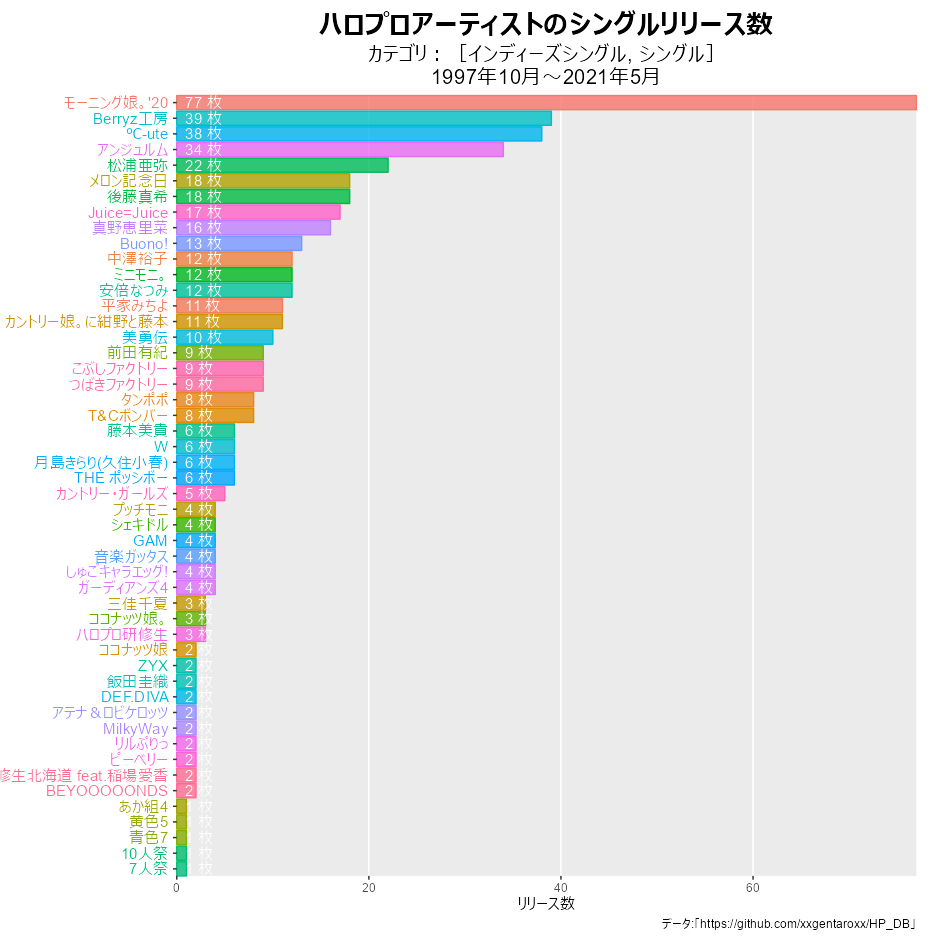
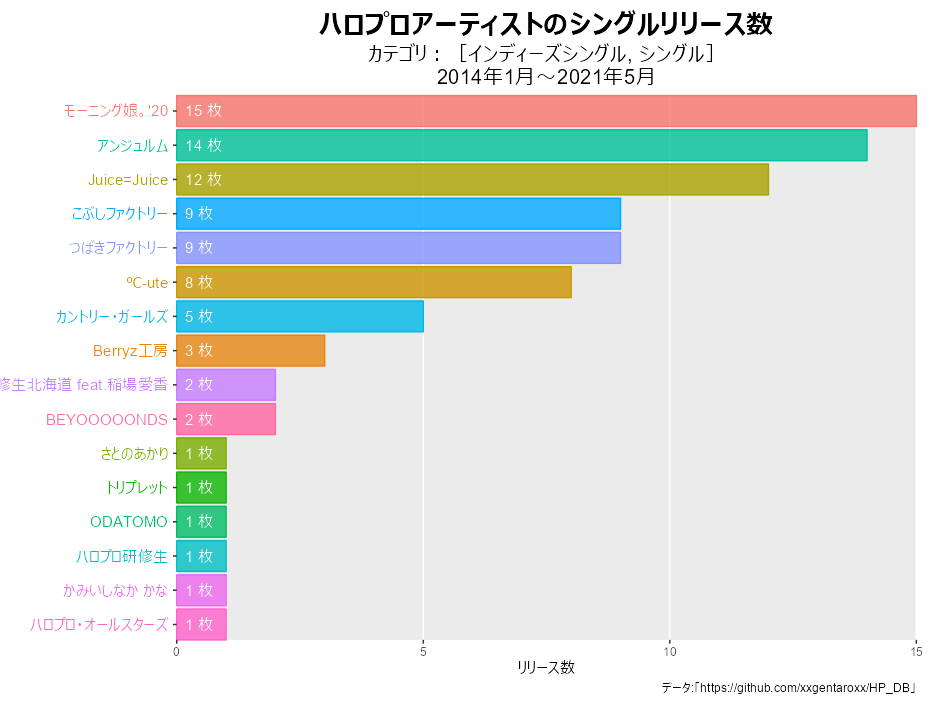
以上で、シングルリリース数の推移を可視化できました。
おわりに
解釈違いがあったときは各々の解釈で作り直してみてください。そしてR使いオタクになりましょう。普通に間違ってる場合はぜひ教えてください。