はじめに
『ゼロから作るDeep Learning 3』の初学者向け攻略ノートです。『ゼロつく3』の学習の補助となるように適宜解説を加えていきます。本と一緒に読んでください。
本で省略されているクラスや関数の内部の処理を1つずつ解説していきます。
この記事は、主にステップ48「多値分類」を補足する内容です。
多クラスの非線形なデータセットに対する分類を行います。
【前ステップの内容】
【他の記事一覧】
【この記事の内容】
・スパイラル・データセットの学習
多クラスの非線形なデータセットの学習を行います。
次のライブラリを利用します。
# 利用するライブラリ import numpy as np import math import matplotlib.pyplot as plt from matplotlib.animation import FuncAnimation
予測の推移をアニメーション(gif画像)で確認するのにanimationモジュールのFuncAnimation()を使います。
また、これまでに実装済したクラスを利用します。dezeroフォルダの親フォルダまでのパスをsys.path.append()に指定します。
# 実装済みモジュールの読み込み用設定 import sys sys.path.append('..') # 実装済みモジュールの読み込み import dezero from dezero import optimizers import dezero.functions as F from dezero.models import MLP
dezeroフォルダ内にdeatasets.pyを作成して、スパイラル・データセットの生成関数get_spiral()を実装する必要があります。また、__init__.pyにimport dezero.datasetsを加えておきます。データの生成に関しての解説は省略します。
48.1 スパイラル・データセット
まずは、データセットを読み込んでグラフで確認します。
データセットを読み込みます。
# スパイラル・データセットを取得 x, t = dezero.datasets.get_spiral(train=True) print(x[:5]) print(x.shape) print(t[:5]) print(t.shape)
[[-0.13981389 -0.00721657]
[ 0.37049392 0.5820947 ]
[ 0.1374263 -0.17179643]
[ 0.3031688 0.06472 ]
[-0.20848857 0.53050214]]
(300, 2)
[1 1 2 0 1]
(300,)
データセットの散布図を作成します。
# 各クラスのマーカーを指定 markers = ['o', 'x', '^'] # 作図 plt.figure(figsize=(8, 8)) for i in range(3): plt.scatter(x[t == i, 0], x[t == i, 1], marker=markers[i], s=50, label='class ' + str(i)) # データセット plt.xlabel('$x_0$', fontsize=15) # x軸ラベル plt.ylabel('$x_1$', fontsize=15) # y軸ラベル plt.suptitle('Spiral Dataset', fontsize=20) # 図全体のタイトル plt.title('N=' + str(len(x)), loc='left') # タイトル plt.legend() # 凡例 plt.show()
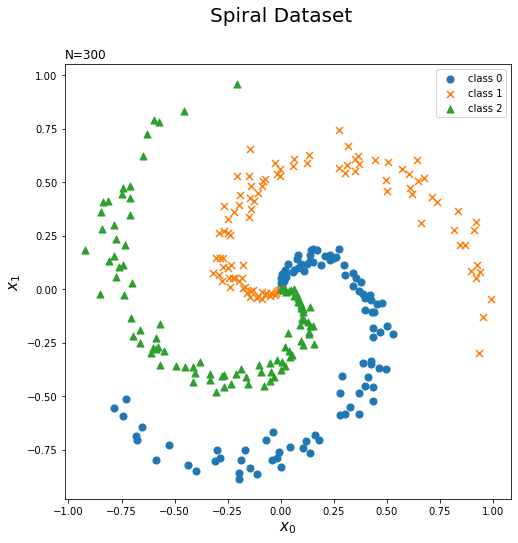
t == iによって、入力データxから各クラスのデータを取り出しています。
3クラスの非線形なデータであることを確認できます。(ところで、本の図とデータが違いますね?)
48.2 学習用のコード
次に、スパイラル・データセットに対して、2層のニューラルネットワークを用いて確率的勾配降下法によりがくしゅうを行います。
これまでとは異なり、一度の計算で全てのデータを用いるのではなく、ランダムに一部のデータを取り出して学習します。
# エポック当たりの試行回数を指定 max_epoch = 300 # バッチサイズを指定 batch_size = 30 # 中間層の次元数を指定 hidden_size = 10 # ニューラルネットのインスタンスを作成 model = MLP((hidden_size, 3)) # 学習係数を指定 lr = 1.0 # 最適化手法のインスタンスを指定 optimizer = optimizers.SGD(lr).setup(model) # データ数を取得 data_size = len(x) # バッチデータ当たりの試行回数を計算 max_iter = math.ceil(data_size / batch_size) # 推移の確認用のリストを初期化 trace_loss = [] trace_predict = [] # (アニメーションの作成用) # ミニバッチ学習 for epoch in range(max_epoch): # データセットのインデックスをシャッフル index = np.random.permutation(data_size) # 損失の合計値を初期化 sum_loss = 0 # ミニバッチに対する処理 for i in range(max_iter): # バッチデータを抽出 batch_index = index[i * batch_size:(i + 1) * batch_size] batch_x = x[batch_index] # 入力データ batch_t = t[batch_index] # 教師データ # ニューラルネットワークの出力(スコア)を計算 y = model(batch_x) # 損失(交差エントロピー誤差)を計算 loss = F.softmax_cross_entropy(y, batch_t) # 勾配を初期化 model.cleargrads() # 勾配を計算 loss.backward() # 値を更新 optimizer.update() # 損失を加算 sum_loss += float(loss.data) * len(batch_t) # 平均損失を計算 avg_loss = sum_loss / data_size # 値を記録 trace_loss.append(avg_loss) # 各地点のクラスを予測(分類)してリストに格納:(アニメーションの作成用) #trace_predict.append(np.argmax(model(x_point).data, axis=1)) # 結果を表示 print('epoch %d, loss %.2f' % (epoch + 1, avg_loss))
epoch 1, loss 1.13
epoch 2, loss 1.05
epoch 3, loss 0.95
epoch 4, loss 0.92
epoch 5, loss 0.87
(省略)
epoch 296, loss 0.13
epoch 297, loss 0.13
epoch 298, loss 0.12
epoch 299, loss 0.13
epoch 300, loss 0.13
model内のパラメータを更新した後に、アニメーションの作成用にニューラルネットの出力を計算して、trace_predictに格納しています。ただし計算には、この後に作成する作図用の点x_pointを使います。話の展開を考慮して前後しましたが、先にx_pointを作成しておく必要があります。
・推論結果の確認
続いて、推論結果を確認していきます。
まずは、交差エントロピー誤差の推移を確認します。
# 作図 plt.figure(figsize=(8, 6)) plt.plot(np.arange(len(trace_loss)), trace_loss, label='train') # 損失 plt.xlabel('iterations (epoch)') # x軸ラベル plt.ylabel('loss') # y軸ラベル plt.title('Cross Entropy Loss', fontsize=20) # タイトル plt.grid() # グリッド線 #plt.ylim(0, 0.2) # y軸の表示範囲 plt.show()
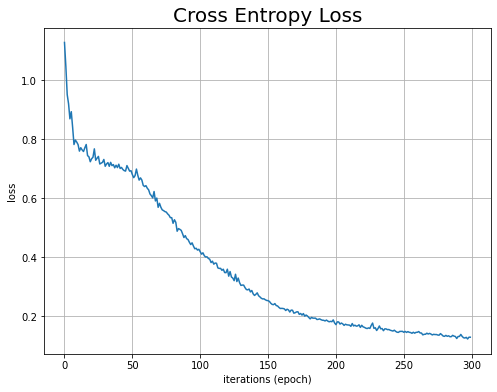
試行回数が増えるに従って0に近付いていることから学習が進んでいるのが分かります。
次は、データセットの周辺に対するクラスの予測を確認します。予測する範囲と間隔を設定します。
# x軸の値を生成 x0_line = np.arange(-1.1, 1.1, 0.005) print(x0_line[:5]) # y軸の値を生成 x1_line = np.arange(-1.1, 1.1, 0.005) print(x1_line[:5])
[-1.1 -1.095 -1.09 -1.085 -1.08 ]
[-1.1 -1.095 -1.09 -1.085 -1.08 ]
x軸とy軸の値を作成します。それぞれデータセットの最小値・最大値よりも少し広めに設定します(後で範囲を大幅に広くとった予測を見るのも面白いかもしれません)。第3引数の値が小さいほどクラスの境界線がなだらかに描画されます。ただし、計算・プロットする点の数も増えるので処理が重くなります。
2つの軸の値が直交する点(格子状の点)を作成します。
# 格子状の点を生成 x0_grid, x1_grid = np.meshgrid(x0_line, x1_line) print(x0_grid[:5, :5]) print(x0_grid.shape) print(x1_grid[:5, :5]) print(x1_grid.shape)
[[-1.1 -1.095 -1.09 -1.085 -1.08 ]
[-1.1 -1.095 -1.09 -1.085 -1.08 ]
[-1.1 -1.095 -1.09 -1.085 -1.08 ]
[-1.1 -1.095 -1.09 -1.085 -1.08 ]
[-1.1 -1.095 -1.09 -1.085 -1.08 ]]
(440, 440)
[[-1.1 -1.1 -1.1 -1.1 -1.1 ]
[-1.095 -1.095 -1.095 -1.095 -1.095]
[-1.09 -1.09 -1.09 -1.09 -1.09 ]
[-1.085 -1.085 -1.085 -1.085 -1.085]
[-1.08 -1.08 -1.08 -1.08 -1.08 ]]
(440, 440)
x0_lineを行方向に複製した配列x0_gridと、x1_lineを列方向に複製した配列x1_gridが出力されます。この2つの2次元配列を使って、等高線を作図します。
また、それぞれ1列に並べ替えて列方向に結合します。
# リストを結合 x_point = np.c_[x0_grid.ravel(), x1_grid.ravel()] print(x_point) print(x_point.shape)
[[-1.1 -1.1 ]
[-1.095 -1.1 ]
[-1.09 -1.1 ]
...
[ 1.085 1.095]
[ 1.09 1.095]
[ 1.095 1.095]]
(193600, 2)
この2次元配列を使って、クラスの予測を行います。
学習を行ったモデル(インスタンス)modelを利用して、x_pointの各点にクラスの予測します。
# スコアを計算 y = model(x_point) print(y.data)
[[ 7.61214498 -10.34869157 1.44873915]
[ 7.65262872 -10.38765155 1.45306557]
[ 7.69227217 -10.4269834 1.45845043]
...
[ -3.43287444 7.7718199 -5.7595969 ]
[ -3.41391503 7.71300667 -5.71845241]
[ -3.39512565 7.65478713 -5.6777348 ]]
x_pointをバッチデータとして、ニューラルネットの出力yを計算します。
x_pointの各点に対して予測された(確率が最大の)クラス番号を抽出します。
# 推論結果(各データのクラス)を抽出 predict_cls = np.argmax(y.data, axis=1) print(predict_cls)
[0 0 0 ... 1 1 1]
yの各行(データ)の最大値のインデックスを抽出します。ソフトマックス関数によって正規化を行っても(確率に変換しても)大小関係は変わらないのでした。つまり、yの最大の要素が、確率が最大の要素になります。
予測結果の配列predict_clsを作図用に整形します。
# 形状を調整 y_grid = predict_cls.reshape(x0_grid.shape) print(y_grid)
[[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
...
[2 2 2 ... 1 1 1]
[2 2 2 ... 1 1 1]
[2 2 2 ... 1 1 1]]
predict_clsは1次元配列で出力されるので、作図用にx0_grid, x1_gridと同じ形状に変換します。
近い点では同じクラスに分類されているのがこの時点でも分かります。
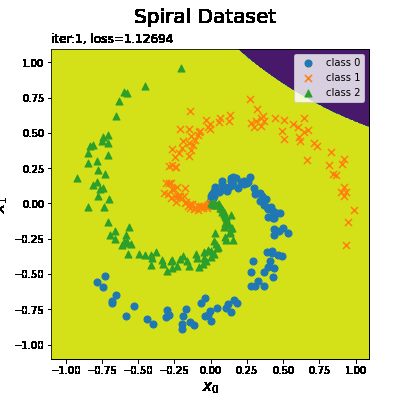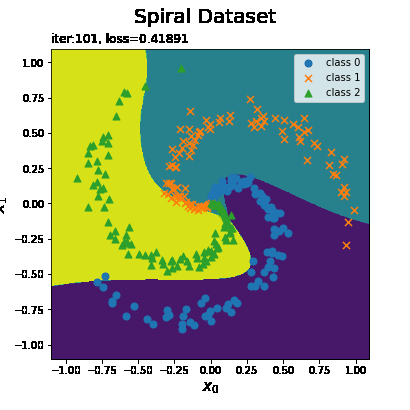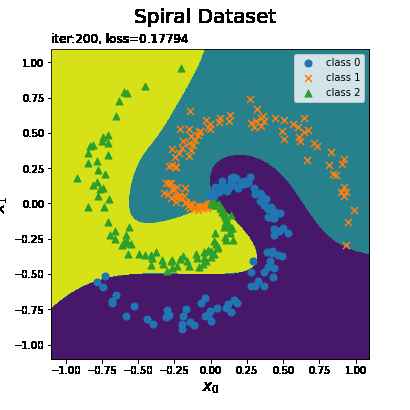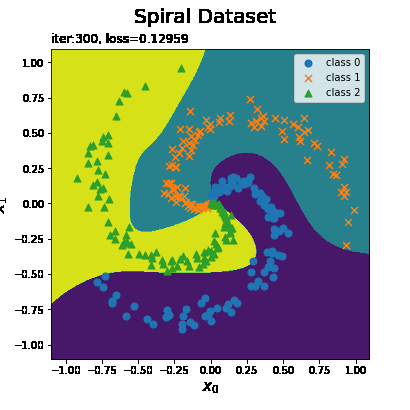
予測した各点のクラスを塗りつぶし等高線図として、データセットと重ねて描画します。
# 予測結果を作図 plt.figure(figsize=(8, 8)) plt.contourf(x0_grid, x1_grid, y_grid) # 予測クラス for i in range(3): plt.scatter(x[t == i, 0], x[t == i, 1], marker=markers[i], s=50, label='class ' + str(i)) # データセット plt.xlabel('$x_0$', fontsize=15) # x軸ラベル plt.ylabel('$x_1$', fontsize=15) # y軸ラベル plt.suptitle('Spiral Dataset', fontsize=20) # 図全体のタイトル plt.title('iter:' + str(max_epoch) + ', loss=' + str(np.round(loss.data, 5)) + ', N=' + str(len(x)), loc='left') # タイトル plt.legend() # 凡例 plt.show()

この図を満遍なく埋め尽くすようにx0_grid, x1_gridを作成しました。そのそれぞれに対してクラス分類を行い、色分けしてプロットしています。ただし、推論には、確率的な処理を含むため同じ結果にはなりません。
各クラスのデータに適合して境界線が表れていることから、うまく分類(予測)できているのがのが分かります。
最後におまけとして、クラスの境界線(各点における予測)の推移をアニメーション(gif画像)で確認します。
# 画像サイズを指定 fig = plt.figure(figsize=(8, 8)) # 作図処理を関数として定義 def update(i): # i回目の予測クラスを取得 y_grid = trace_predict[i].reshape(x0_grid.shape) # 前フレームのグラフを初期化 plt.cla() # i回目の試行のトレースプロットを作成 plt.contourf(x0_grid, x1_grid, y_grid) # 予測クラス for c in range(3): plt.scatter(x[t == c, 0], x[t == c, 1], marker=markers[c], s=50, label='class ' + str(c)) # データセット plt.xlabel('$x_0$', fontsize=15) # x軸ラベル plt.ylabel('$x_1$', fontsize=15) # y軸ラベル plt.suptitle('Spiral Dataset', fontsize=20) # 図全体のタイトル plt.title('iter:' + str(i + 1) + ', loss=' + str(np.round(trace_loss[i], 5)), loc='left') # タイトル plt.legend() # 凡例 # gif画像を作成 trace_anime = FuncAnimation(fig, update, frames=max_epoch, interval=100) # gif画像を保存 trace_anime.save('step48_spiral.gif')
試行回数が増えるに従って予測結果がデータに適合していくのが分かります。
参考文献
- 斎藤康毅『ゼロから作るDeep Learning 3 ――フレームワーク編』オライリー・ジャパン,2020年.
おわりに
この内容は2巻の1章の記事で代用するつもりだったんですが、読み返してみるとあんまりうまく処理できてなかったので、3巻用にも書くことにしました。2巻の記事を書き直したらほとんど同じ内容になるような気がします。
【次ステップの内容】