はじめに
『ゼロから作るDeep Learning 3』の初学者向け攻略ノートです。『ゼロつく3』の学習の補助となるように適宜解説を加えていきます。本と一緒に読んでください。
本で省略されているクラスや関数の内部の処理を1つずつ解説していきます。
この記事は、主にステップ51「MNISTの学習」を補足する内容です。
ニューラルネットワークを用いて手書き文字認識(多クラス分類)を行います。
【前ステップの内容】
【他の記事一覧】
【この記事の内容】
ステップ51 MNISTの学習
機械学習のベンチマークとしてよく利用されるMNIST(手書き数字)データセットを用いて学習を行います。
次のライブラリを利用します。
# 利用するライブラリ import matplotlib.pyplot as plt
また、これまでに実装済したクラスを利用します。dezeroフォルダの親フォルダまでのパスをsys.path.append()に指定します。
# 実装済みモジュールの読み込み用設定 import sys #sys.path.append('..') sys.path.append('..//deep-learning-from-scratch-3-master') # 実装済みモジュールの読み込み import dezero from dezero import DataLoader, optimizers import dezero.functions as F from dezero.models import MLP
51.1 MNISTデータセット
まずは、MNISTデータセットを確認します。
datasets.pyに実装されているMNISTクラスを利用します。
MNISTクラスのインスタンス作成時に、train引数にTrueを指定すると訓練(学習)用のデータを、Falseだとテスト(評価)用のデータを持つインスタンスを作成します。デフォルト値はTrueです。作成されたインスタンスは、入力データと教師データを持ちます。
transformは、入力データの前処理(加工)に関する引数です。デフォルトでは、値を0から1に、形状を1次元配列に変換するように実装されています。
target_transform引数は、教師データの前処理に関する引数です。デフォルト値はNoneで、何も行いません。
ここでは、transform=Noneを指定して、未加工のデータを確認します。
# 訓練用データを取得 train_set = dezero.datasets.MNIST(train=True, transform=None) print(type(train_set)) print(len(train_set)) # テスト用データを取得 test_set = dezero.datasets.MNIST(train=False, transform=None) print(type(test_set)) print(len(test_set))
<class 'dezero.datasets.MNIST'>
60000
<class 'dezero.datasets.MNIST'>
10000
訓練データは6万枚、テストデータは1万枚です。
訓練データの入力データと教師データを1つ取り出して確認してみましょう。
# 取り出すデータ番号を指定 n = 0 # n番目のデータを取得 x, t = train_set[n] # 入力データを確認 print(type(x)) print(x.shape) # 教師データを確認 print(type(t)) print(t)
<class 'numpy.ndarray'>
(1, 28, 28)
<class 'numpy.uint8'>
5
入力データxは$(1 \times 28 \times 28)$の3次元配列です。3つの次元(軸)はそれぞれチャンネル数・縦方向のピクセル数・横方向のピクセル数を表します。
MNISTデータセットは、グレースケールなので1チャンネルの縦28ピクセル・横28ピクセルの画像データです。(例えばRGBデータだと赤・緑・青の3チャンネルになります。)
教師データtはスカラです。入力データの数字を表します。
入力データ(の左側)の配列を表示してみます。
# 入力データ(の一部)を確認 print(x[0, :, :18])
[[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 3 18 18 18 126 136]
[ 0 0 0 0 0 0 0 0 30 36 94 154 170 253 253 253 253 253]
[ 0 0 0 0 0 0 0 49 238 253 253 253 253 253 253 253 253 251]
[ 0 0 0 0 0 0 0 18 219 253 253 253 253 253 198 182 247 241]
[ 0 0 0 0 0 0 0 0 80 156 107 253 253 205 11 0 43 154]
[ 0 0 0 0 0 0 0 0 0 14 1 154 253 90 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 139 253 190 2 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 11 190 253 70 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 35 241 225 160 108 1]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 81 240 253 253 119]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 45 186 253 253]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 16 93 252]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 249]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 46 130 183 253]
[ 0 0 0 0 0 0 0 0 0 0 0 0 39 148 229 253 253 253]
[ 0 0 0 0 0 0 0 0 0 0 24 114 221 253 253 253 253 201]
[ 0 0 0 0 0 0 0 0 23 66 213 253 253 253 253 198 81 2]
[ 0 0 0 0 0 0 18 171 219 253 253 253 253 195 80 9 0 0]
[ 0 0 0 0 55 172 226 253 253 253 253 244 133 11 0 0 0 0]
[ 0 0 0 0 136 253 253 253 212 135 132 16 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]]
各要素は、0から255の整数です。0は真っ黒を255は真っ白を表し、256段階の値の大きさが色の濃さに対応します。(配列の全てを出力すると折り返して表示されるので一部だけ出力しています。)
教師データを確認します。
# 教師データを確認 print(t)
5
教師データは、0から9の整数です。入力データに書かれている数字を示します。DeZeroのモジュールでは、one-hotベクトルではなくスカラで正解の数字を表します。正解ラベルとも呼びます。
手書き数字を画像として表示します。
# 手書き文字を表示 plt.imshow(x.reshape(28, 28), cmap='gray') # 入力データ plt.title('label:' + str(t)) # 教師データ(正解ラベル) plt.axis('off') # 軸ラベル plt.show()


このデータ(または前処理を行ったデータ)をニューラルネットワークに入力して正解ラベルの値を出力することを目指します。
このステップでは、デフォルトの前処理を行ったデータセットを用います。
# 前処理を行った訓練データを取得 train_set = dezero.datasets.MNIST(train=True) x, t = train_set[n] print(type(x)) print(x.shape) print(x[25*5:28*6])
<class 'numpy.ndarray'>
(784,)
[0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0.01176471 0.07058824 0.07058824
0.07058824 0.49411765 0.53333336 0.6862745 0.10196079 0.6509804
1. 0.96862745 0.49803922 0. 0. 0.
0. ]
元のデータの各要素(ピクセル)は0から255の値でした。そこで、最大値の255で割ることで0から1の値をとるようになります。また、0行目の要素の後に1行目の要素と続くように並べて1次元配列にしています。(0が続くので、前処理を行っていないデータの(0から数えて)5行目に対応する要素を表示しています。)
3次元配列に変形して、255をかけて、整数型intにすることで、前処理を行っていないデータに戻せます。
# 入力データを加工前の状態に戻す print((x.reshape((1, 28, 28)) * 255).astype(int)[0, :, :18])
[[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 3 18 18 18 126 136]
[ 0 0 0 0 0 0 0 0 30 36 94 154 170 253 253 253 253 253]
[ 0 0 0 0 0 0 0 49 238 253 253 253 253 253 253 253 253 251]
[ 0 0 0 0 0 0 0 18 219 253 253 253 253 253 198 182 247 241]
[ 0 0 0 0 0 0 0 0 80 156 107 253 253 205 11 0 43 154]
[ 0 0 0 0 0 0 0 0 0 14 1 154 253 90 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 139 253 190 2 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 11 190 253 70 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 35 241 225 160 108 1]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 81 240 253 253 119]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 45 186 253 253]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 16 93 252]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 249]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 46 130 183 253]
[ 0 0 0 0 0 0 0 0 0 0 0 0 39 148 229 253 253 253]
[ 0 0 0 0 0 0 0 0 0 0 24 114 221 253 253 253 253 201]
[ 0 0 0 0 0 0 0 0 23 66 213 253 253 253 253 198 81 2]
[ 0 0 0 0 0 0 18 171 219 253 253 253 253 195 80 9 0 0]
[ 0 0 0 0 55 172 226 253 253 253 253 244 133 11 0 0 0 0]
[ 0 0 0 0 136 253 253 253 212 135 132 16 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]]
MNISTデータセットの確認ができたので、学習を行います。
51.2 MNISTの学習
次に、MNISTデータセットに対して学習と推論(予測)を行います。
基本的な処理はこれまでと同じです。学習の推移を確認するために、損失と認識精度をリストtrace_***に格納していきます。
# エポック当たりの試行回数を指定 max_epoch = 5 # バッチサイズを指定 batch_size = 100 # データセットを設定 train_set = dezero.datasets.MNIST(train=True) test_set = dezero.datasets.MNIST(train=False) train_loader = DataLoader(train_set, batch_size) test_loader = DataLoader(test_set, batch_size, shuffle=False) # 中間層の次元数を指定 hidden_size = 1000 # ニューラルネットのインスタンスを作成 model = MLP((hidden_size, 10)) #model = MLP((hidden_size, hidden_size, 10), activation=F.relu) # 学習係数を指定 lr = 0.01 #lr = 0.001 # 最適化手法のインスタンスを指定 optimizer = optimizers.SGD(lr).setup(model) #optimizer = optimizers.Adam(lr).setup(model) # 推移の確認用のリストを初期化 trace_loss_train, trace_loss_test = [], [] trace_acc_train, trace_acc_test = [], [] # ミニバッチ学習 for epoch in range(max_epoch): # 損失・精度の合計値を初期化 sum_loss, sum_acc = 0, 0 # ミニバッチを抽出 for x, t in train_loader: # ニューラルネットワークの出力を計算(手書き数字を認識) y = model(x) # ミニバッチにおける損失・精度を計算 loss = F.softmax_cross_entropy(y, t) acc = F.accuracy(y, t) # 勾配を計算 model.cleargrads() loss.backward() # パラメータを更新 optimizer.update() # 合計損失・正解数を加算 sum_loss += float(loss.data) * len(t) sum_acc += float(acc.data) * len(t) # 全データにおける損失・精度を計算 avg_loss = sum_loss / len(train_set) avg_acc = sum_acc / len(train_set) # 値を記録 trace_loss_train.append(avg_loss) trace_acc_train.append(avg_acc) # 訓練データに対する結果を表示 print('epoch: {}'.format(epoch + 1)) print('train loss: {:.4f}, accurary: {:.4f}'.format(avg_loss, avg_acc)) # 損失・精度の合計値を初期化 sum_loss, sum_acc = 0, 0 # ミニバッチを抽出 with dezero.no_grad(): for x, t in test_loader: # ニューラルネットワークの出力を計算(手書き数字を認識) y = model(x) # ミニバッチにおける損失・精度を計算 loss = F.softmax_cross_entropy(y, t) acc = F.accuracy(y, t) # 合計損失・正解数を加算 sum_loss += float(loss.data) * len(t) sum_acc += float(acc.data) * len(t) # 全データにおける損失・精度を計算 avg_loss = sum_loss / len(test_set) avg_acc = sum_acc / len(test_set) # 値を記録 trace_loss_test.append(avg_loss) trace_acc_test.append(avg_acc) # テストデータに対する結果を表示 print('test loss: {:.4f}, accurary: {:.4f}'.format(avg_loss, avg_acc))
epoch: 1
train loss: 1.9164, accurary: 0.5493
test loss: 1.5462, accurary: 0.7823
epoch: 2
train loss: 1.2886, accurary: 0.7636
test loss: 1.0535, accurary: 0.8056
epoch: 3
train loss: 0.9305, accurary: 0.8143
test loss: 0.8005, accurary: 0.8298
epoch: 4
train loss: 0.7455, accurary: 0.8373
test loss: 0.6695, accurary: 0.8512
epoch: 5
train loss: 0.6403, accurary: 0.8516
test loss: 0.5832, accurary: 0.8642
softmax_cross_entropy()の出力lossは、ミニバッチデータにおける平均損失と言えます。平均損失loss.dataにミニバッチサイズlen(t)を掛けることで、ミニバッチの損失の合計になります。また、ミニバッチの合計損失をsum_lossに加算していくことで、データセット全体の損失の合計を求めます。最後に、sum_lossを総データ数len(test_set)で割ることで、データセット全体における平均損失avg_lossを求めます。
同様に、accuracy()の出力accは、ミニバッチにおける正解率です。ミニバッチにおける正解数acc.data * len(t)をsum_accに加算していくことで、データセット全体における正解数を求めます。最後に、sum_accを総データ数len(test_set)で割ることで、データセット全体における正解率になります。これを認識精度とします。
表示される途中経過を見ると、学習を繰り返すごとに損失が下がり精度が上がっているのが確認できます。
学習の推移をグラフでも確認しましょう。
まずは、訓練データとテストデータに対する損失(交差エントロピー誤差)の推移を確認します。
# 損失の推移を作図 plt.figure(figsize=(8, 6)) plt.plot(range(1, max_epoch + 1), trace_loss_train, label='train') # 訓練データ plt.plot(range(1, max_epoch + 1), trace_loss_test, label='test') # テストデータ plt.xlabel('epoch') # x軸ラベル plt.ylabel('loss') # y軸ラベル plt.title('layer:' + str(len(model.__dict__['_params'])) + ', hidden size:' + str(hidden_size) + ', activation:' + str(model.__dict__['activation'].__name__) + ', optimizer:' + str(optimizer.__class__.__name__) + ', lr:' + str(lr)) # 設定 plt.legend() # 凡例 plt.grid() # グリッド線 #plt.ylim(0.0, 0.2) # y軸の表示範囲 plt.show()
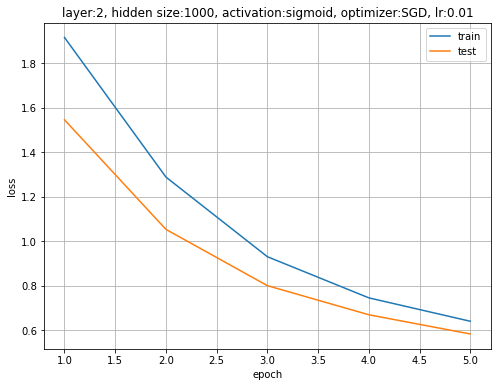
訓練データとテストデータどちらに対しても交差エントロピー誤差が下がっていることから、過学習が起きていないのが分かります。ただし、訓練データのミニバッチを1エポック分学習してからテストデータを使って評価しているので、テストデータに対する損失の推移の方が小さくなっています。
同様に、認識精度の推移を確認します。
# 精度の推移を作図 plt.figure(figsize=(8, 6)) plt.plot(range(1, max_epoch + 1), trace_acc_train, label='train') # 訓練データ plt.plot(range(1, max_epoch + 1), trace_acc_test, label='test') # テストデータ plt.xlabel('epoch') # x軸ラベル plt.ylabel('accuracy') # y軸ラベル plt.title('layer size:' + str(len(model.__dict__['_params'])) + ', hidden size:' + str(hidden_size) + ', activation:' + str(model.__dict__['activation'].__name__) + ', optimizer:' + str(optimizer.__class__.__name__) + ', lr:' + str(lr)) # 設定 plt.legend() # 凡例 plt.grid() # グリッド線 #plt.ylim(0.0, 1.0) # y軸の表示範囲 plt.show()
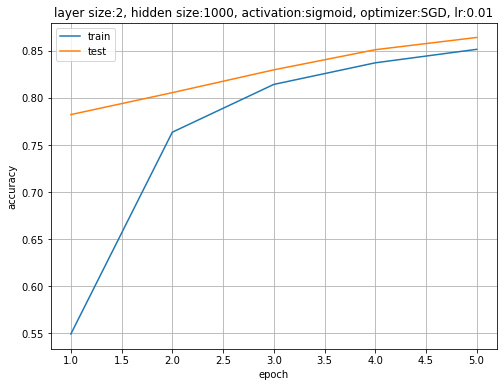
9割弱のデータで認識できているのが分かります。
(ところで、(dict['lr' or 'alpha']のような感じで)キーを2つ指定して値を1つ取り出したかったのですが、(if文を使わずに1行で行える)そういう方法はないでしょうか?dictは片方のキーしか持たない前提です。今回は諦めてオブジェクトlrを作成することにしました。hidden_sizeの値もインスタンスから取り出せるのですが、結構深いところにあるのでhidden_sizeをそのまま使いました。)
51.3 モデルの改良
活性化関数をReLU関数とした3層のニューラルネットワークを用いて、Adamによりパラメータを更新した場合は、次のような結果になります。
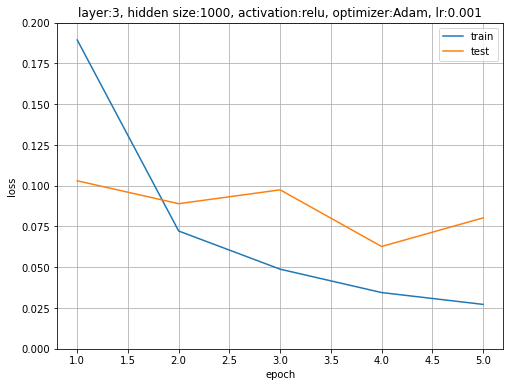
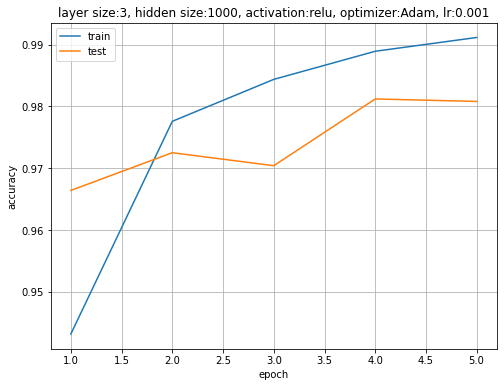
訓練データ対する結果の方が少しだけ精度が高くなっていますが、どちらも98%まで認識精度が上がっています。
以上で第3ステージの内容は完了です。このステップでは、画像データを1列に並べ替えて扱いました。次からは、配列の形状を保ったまま扱うことを考えます。縦横(奥)の関係を維持することで、隣り合うピクセルデータの情報も考慮して推論を行えます。
参考文献
- 斎藤康毅『ゼロから作るDeep Learning 3 ――フレームワーク編』オライリー・ジャパン,2020年.
おわりに
第4ステージ完了!以上でNNを実装して学習を行えましたーお疲れ様でしたーー。(正直面倒になってきたので、データセット周りの実装に関する解説は省略します。2週目の際には追加するかもしれません。)
ハロプロ楽曲で私的ベスト3に入る曲のカバー動画が先日公開されたのでぜひ♪
MVロケ地に巡礼するくらい好き。
【次ステップの内容】