はじめに
『ゼロから作るDeep Learning 2――自然言語処理編』の初学者向け【実装】攻略ノートです。『ゼロつく2』学習の補助となるように適宜解説を加えています。本と一緒に読んでください。
本の内容を1つずつ確認しながらゆっくりと組んでいきます。
この記事は、5.5.3項「RNNLMの学習コード」と5.5.4項「RNNLMのTrainerクラス」の内容です。RNNLMによる学習処理を解説して、Pythonで実装します。
【前節の内容】
【他の節の内容】
【この節の内容】
5.5.3 RNNLMの学習コード
ここまでで実装したRNNLMを用いて、PTBデータセットに対する学習を行います。PTB(Penn Treebankコーパス)については2.4.4項を参照してください。
# 5.5.3項で利用するライブラリ import numpy as np import matplotlib.pyplot as plt
学習に利用する実装済みのクラスも読み込みます。ptbは、本で用意されているPTBを読み込むためのモジュールです。
# 実装済みのクラスと関数 from dataset import ptb from common.optimizer import SGD from simple_rnnlm import SimpleRnnlm
・データの読み込み
まずはPTBデータセットを読み込み、学習に用いるデータを作成します。
## データの作成 # データセットを読み込む corpus, word_to_id, id_to_word = ptb.load_data('train') print(corpus.shape) print(len(word_to_id))
(929589,)
10000
PTBは、1万種類の語彙を使った、約93万語で構成されているコーパス(データセット)です。
ここでは、一部のデータのみを扱うことにします。
# 使用するデータ数を指定 corpus_size = 1000 # データを削減 corpus = corpus[:corpus_size] # 語彙数を取得 vocab_size = int(max(corpus) + 1) print(vocab_size)
418
0番目から1000語取り出した所、418種類の語彙が含まれていることが分かりました。ここから入力データと教師ラベルを作成します。
RNNでは、単語を順番に入力していき、入力した次の単語を予測するのでした。なのでcorpusから、最後の単語を除いたものが入力データ$\mathbf{xs}$、最初の単語を除いたものが教師ラベル$\mathbf{ts}$です。
# 入力データ(最後以外)を取得 xs = corpus[:-1] # 教師ラベル(最初以外)を取得 ts = corpus[1:] # データ数を取得 data_size = len(xs) print(xs.shape)
(999,)
・ハイパーパラメータの設定
次に、ハイパーパラメータを指定します。
## ハイパーパラメータを指定 # バッチサイズ batch_size = 10 # 時間サイズ time_size = 5 # Embedレイヤの中間層のニューロン数 wordvec_size = 100 # Affineレイヤの中間層のニューロン数 hidden_size = 100 # 学習率 lr = 0.1 # エポックあたりの試行回数 max_epoch = 100
ミニバッチデータに切り分けるためのインデックスを準備をします。
# ミニバッチの開始位置を計算 jump = data_size // batch_size # 間隔 offsets = [i * jump for i in range(batch_size)] # インデックス print(jump) print(offsets)
99
[0, 99, 198, 297, 396, 495, 594, 693, 792, 891]
データ数data_sizeをバッチサイズbatch_sizeで割った値をjumpとします。この計算は、データ全体を等間隔でバッチサイズ個に区切ったときの、間隔(単語数)を求めています。インデックス用の値なので、//演算子で割り算の整数部分を計算します。
1からbatch_sizeまでの整数にjumpを掛けることで、ミニバッチデータを取り出す際の先頭のインデックスが得られます。
どのように処理されるのかを確認しておきましょう。分かりやすいように通し番号の要素を持つ(単語IDが通し番号)の入力データと教師ラベルを使います。
# 通し番号のデータを作成 simple_x = np.arange(data_size) simple_t = np.arange(data_size) + 1 # カウントを初期化 time_idx = 0 # ミニバッチを初期化 batch_x = np.empty((batch_size, time_size), dtype='i') batch_t = np.empty((batch_size, time_size), dtype='i') # ミニバッチを取得 for t in range(time_size): for i, offset in enumerate(offsets): batch_x[i, t] = simple_x[(offset + time_idx) % data_size] batch_t[i, t] = simple_t[(offset + time_idx) % data_size] # カウントを更新 time_idx += 1 print(batch_x) print(batch_t)
[[ 0 1 2 3 4]
[ 99 100 101 102 103]
[198 199 200 201 202]
[297 298 299 300 301]
[396 397 398 399 400]
[495 496 497 498 499]
[594 595 596 597 598]
[693 694 695 696 697]
[792 793 794 795 796]
[891 892 893 894 895]]
[[ 1 2 3 4 5]
[100 101 102 103 104]
[199 200 201 202 203]
[298 299 300 301 302]
[397 398 399 400 401]
[496 497 498 499 500]
[595 596 597 598 599]
[694 695 696 697 698]
[793 794 795 796 797]
[892 893 894 895 896]]
試行ごとに、全てのデータxsからbatch_size個の文章を取り出します。各文章の長さ(単語数)はtime_sizeです。つまり、ミニバッチデータの総単語数はbatch_size掛けるtime_size個です。取り出したミニバッチデータbatch_xを入力し、学習を行います。教師ラベルのミニバッチデータbatch_tについても同様です。
ミニバッチデータの各単語は、for文で1語ずつxsから取り出してbatch_xに格納していきます。enumerate()でoffsetsの各要素offsetと要素番号iを出力して、インデックスとして使います。iは文章番号を表します。batch_xのi行目がi番目の文書に対応します。
offsetから数えてtime_idx番目の単語を取り出して、batch_xのi行目に格納します。ただし、取り出す単語のインデックスoffset+time_idxが総単語数data_sizeを超えた場合は、0に戻って数えます。この計算は、%演算子で割り算の余りを求めることで行えます。
全て(batch_size個の)文書のt番目の単語(batch_xのt列)を処理したら、time_idxをカウントアップします。
この処理をtime_size回繰り返すことで、全ての単語を取得できます。よって、1回の試行でtime_idxの値はtime_size上がります。
試行(学習)の度にbatch_x, batch_tを更新します。次の試行では、time_sizeが加算されたtime_idxを使って処理します。よって、更新前のbatch_x, batch_tの続きの単語になります。
初期化の処理time_idx = 0を(コメントアウトなどで)行わずにfor文の処理を再度実行すると、次の試行におけるミニバッチデータを取得できます。
・学習処理
以上で準備が整いました。それでは学習を行います。パラメータの更新(勾配降下法)については、「1巻の4.4.節」または、「1巻の6.1節」を参照してください。
## 学習 # ミニバッチあたりの試行回数を計算 max_iters = data_size // (batch_size * time_size) # 学習処理に用いる変数を初期化 time_idx = 0 total_loss = 0 loss_count = 0 ppl_list = [] # インスタンスを作成 model = SimpleRnnlm(vocab_size, wordvec_size, hidden_size) # モデル optimizer = SGD(lr) # 最適化手法 # エポックごとに学習 for epoch in range(max_epoch): for iter in range(max_iters): # ミニバッチを取得 batch_x = np.empty((batch_size, time_size), dtype='i') batch_t = np.empty((batch_size, time_size), dtype='i') for t in range(time_size): for i, offset in enumerate(offsets): batch_x[i, t] = xs[(offset + time_idx) % data_size] batch_t[i, t] = ts[(offset + time_idx) % data_size] time_idx += 1 # カウント # 損失を計算 loss = model.forward(batch_x, batch_t) # 勾配を計算 model.backward() # パラメータを更新 optimizer.update(model.params, model.grads) # 平均損失計算用に加算 total_loss += loss loss_count += 1 # パープレキシティを計算 ppl = np.exp(total_loss / loss_count) print( '| eploch ' + str(epoch + 1) + ' | perplexity: ' + str(np.round(ppl, 2)) ) ppl_list.append(float(ppl)) # 結果を記録 total_loss, loss_count = 0, 0 # カウントを初期化
| eploch 1 | perplexity: 410.45
| eploch 2 | perplexity: 384.49
| eploch 3 | perplexity: 328.05
| eploch 4 | perplexity: 278.14
| eploch 5 | perplexity: 247.1
(省略)
| eploch 96 | perplexity: 58.41
| eploch 97 | perplexity: 56.4
| eploch 98 | perplexity: 54.93
| eploch 99 | perplexity: 53.4
| eploch 100 | perplexity: 52.21
perplexityが徐々に下がっているのが数値から確認できます。
結果をグラフでも確認しましょう。
# 作図 plt.plot(np.arange(1, len(ppl_list) + 1), ppl_list) plt.title('Simple RNNLM', fontsize=20) plt.xlabel('epoch') plt.ylabel('perplexity') plt.show()
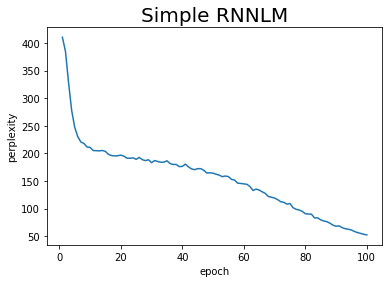
試行回数が増えるに従ってperplexityが下がっています。つまり学習が進んでいることが確認できます。
以上でRNNLMを用いた学習を行えました。次項では、この学習処理をクラスとして実装します。
5.5.4 RNNLMのTrainerクラス
前項で行ったRNNLMによる学習処理をクラスとして実装します。
# 5.5.4項で利用するライブラリ import numpy as np import matplotlib.pyplot as plt import time
timeは、時間データを扱うためのライブラリです。学習にかかる時間を計測するために利用します。
実装済みの関数をマスターデータから読み込む必要があります。
# 読み込み用の設定 import sys #sys.path.append('C://Users//「ユーザー名」//Documents/・・・/deep-learning-from-scratch-2-master') # 実装済みの関数 from common.util import clip_grads from common.trainer import remove_duplicate
この関数は、この資料内で実装していません。
・実装
学習処理は前項で確認しました。一連の処理をまとめてクラスとして実装します。
# RNNLMによる学習処理の実装 class RnnlmTrainer: # 初期化メソッドの定義 def __init__(self, model, optimizer): self.model = model # モデル self.optimizer = optimizer # 最適化手法 self.time_idx = None # バッチデータに関するカウント self.ppl_list = None # perplexityの記録用 self.eval_interval = None # 評価を行う感覚 self.current_epoch = 0 # エポックあたりの試行回数 # ミニバッチデータの作成メソッドを定義 def get_batch(self, x, t, batch_size, time_size): # データ数を取得 data_size = len(x) # ミニバッチの開始位置を計算 jump = data_size // batch_size # 間隔 offsets = [i * jump for i in range(batch_size)] # インデックス # ミニバッチを取得 batch_x = np.empty((batch_size, time_size), dtype='i') batch_t = np.empty((batch_size, time_size), dtype='i') for time in range(time_size): for i, offset in enumerate(offsets): batch_x[i, time] = x[(offset + self.time_idx) % data_size] batch_t[i, time] = t[(offset + self.time_idx) % data_size] self.time_idx += 1 # カウント return batch_x, batch_t # 学習メソッドの定義 def fit(self, xs, ts, max_epoch=10, batch_size=20, time_size=35, max_grad=None, eval_interval=20): # データ数を取得 data_size = len(xs) # ミニバッチあたりの試行回数を計算 max_iters = data_size // (batch_size * time_size) # 学習処理に用いる変数を初期化 self.time_idx = 0 self.ppl_list = [] self.eval_interval = eval_interval # インスタンスを取得 model, optimizer = self.model, self.optimizer # 平均損失用の変数を初期化 total_loss, loss_count = 0, 0 # 学習 start_time = time.time() # 学習開始時刻を記録 for epoch in range(max_epoch): for iters in range(max_iters): # ミニバッチを取得 batch_x, batch_t = self.get_batch(xs, ts, batch_size, time_size) # 損失を計算 loss = model.forward(batch_x, batch_t) # 勾配を計算 model.backward() # パラメータと勾配を取得 params, grads = remove_duplicate(model.params, model.grads) # 共有された重みを1つに集約 if max_grad is not None: clip_grads(grads, max_grad) # パラメータを更新 optimizer.update(params, grads) # 平均損失の計算用に加算 total_loss += loss loss_count += 1 # パープレキシティの評価 if (eval_interval is not None) and (iters % eval_interval) == 0: # 設定した試行回数のとき # 平均損失をもとにperplexityを計算 ppl = np.exp(total_loss / loss_count) # 結果を表示 elapsed_time = time.time() - start_time # 経過時間を計算 print( '| epoch ' + str(self.current_epoch + 1) + ' | iter ' + str(iters + 1) + ' / ' + str(max_iters) + ' | time ' + str(np.round(elapsed_time, 2)) + ' | perplexity: ' + str(np.round(ppl, 2)) ) self.ppl_list.append(float(ppl)) # 結果を記録 total_loss, loss_count = 0, 0 # カウントを初期化 # エポックあたりの試行回数を加算 self.current_epoch += 1 # 作図メソッドの定義 def plot(self, ylim=None): # x軸の値を生成 x = np.arange(1, len(self.ppl_list) + 1) # 作図 if ylim is not None: # y軸の描画範囲を指定した場合 plt.ylim(*ylim) plt.plot(x, self.ppl_list, label='train') plt.title('Simple RNNLM', fontsize=20) plt.xlabel('iterations (x' + str(self.eval_interval) + ')') plt.ylabel('perplexity') plt.show()
作図メソッドplot()のylimに値を指定することで描画範囲を調整できます。値はリストやタプル形式で[最小値, 最大値]の2値を渡します。
実装したクラスを試してみましょう。
# RNNLMのインスタンスを作成 model = SimpleRnnlm(vocab_size, wordvec_size, hidden_size) # 最適化手法のインスタンスを作成 optimizer = SGD(lr) # 学習用クラスのインスタンスを作成 trainer = RnnlmTrainer(model, optimizer) # 学習 trainer.fit(xs, ts, max_epoch, batch_size, time_size)
| epoch 1 | iter 1 / 19 | time 0.01 | perplexity: 418.78
| epoch 2 | iter 1 / 19 | time 0.11 | perplexity: 409.45
| epoch 3 | iter 1 / 19 | time 0.2 | perplexity: 386.78
| epoch 4 | iter 1 / 19 | time 0.26 | perplexity: 334.25
| epoch 5 | iter 1 / 19 | time 0.34 | perplexity: 274.73
(省略)
| epoch 96 | iter 1 / 19 | time 7.27 | perplexity: 56.96
| epoch 97 | iter 1 / 19 | time 7.35 | perplexity: 54.46
| epoch 98 | iter 1 / 19 | time 7.41 | perplexity: 53.74
| epoch 99 | iter 1 / 19 | time 7.48 | perplexity: 53.63
| epoch 100 | iter 1 / 19 | time 7.55 | perplexity: 50.03
perplexityが徐々に下がっているのが数値で確認できます。
plot()メソッドで可視化できます。
# 可視化
trainer.plot()
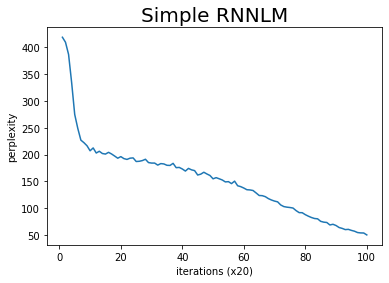
グラフでも確認できました。
以上で5章の内容は完了です。この章では、単純な言語モデルであるRNNLMを実装し、学習を行いました。しかしこのままではうまく学習できないケースが多くあります。そこで次章では、RNNLMを更に発展させたモデルを扱います。
参考文献

おわりに
5章完了です!お疲れ様でしたー。良いお年を~
【次節の内容】