はじめに
『ゼロから作るDeep Learning 2――自然言語処理編』の初学者向け【実装】攻略ノートです。『ゼロつく2』学習の補助となるように適宜解説を加えています。本と一緒に読んでください。
本の内容を1つずつ確認しながらゆっくりと組んでいきます。
この記事は、6.1.3項「勾配消失もしくは勾配爆発の原因」と6.1.4項「勾配爆発への対策」の内容です。勾配消失・勾配爆発の原因を確認した後、勾配爆発の対策として用いる勾配クリッピングを解説して、Pythonで実装します。
【前節の内容】
【他の節の内容】
【この節の内容】
6.1.3 勾配消失もしくは勾配爆発の原因
入力データ・重みパラメータの値と勾配の値との関係を簡単に確認します。
# 6.1.3項で利用するライブラリ import numpy as np import matplotlib.pyplot as plt
・tanh関数の場合
まずはtanh関数に関して、入力と出力、微分との関係を見ましょう。
tanh関数(の順伝播での計算)は、入力を$h$、出力を$y$とすると次の式でした。
またtanh関数の微分(逆伝播での計算)は、次の式でした。
実際に計算してみましょう。tanh関数の計算は、np.tanh()で行えます。
# 入力データの範囲(x軸の描画範囲)を指定 h = np.arange(-5.0, 5.0, 0.1) print(np.round(h, 2)) # tanh関数を計算 y = np.tanh(h) print(np.round(y, 2)) # tanh関数の微分を計算 dy = 1 - y**2 print(np.round(dy, 2))
[-5. -4.9 -4.8 -4.7 -4.6 -4.5 -4.4 -4.3 -4.2 -4.1 -4. -3.9 -3.8 -3.7
-3.6 -3.5 -3.4 -3.3 -3.2 -3.1 -3. -2.9 -2.8 -2.7 -2.6 -2.5 -2.4 -2.3
-2.2 -2.1 -2. -1.9 -1.8 -1.7 -1.6 -1.5 -1.4 -1.3 -1.2 -1.1 -1. -0.9
-0.8 -0.7 -0.6 -0.5 -0.4 -0.3 -0.2 -0.1 -0. 0.1 0.2 0.3 0.4 0.5
0.6 0.7 0.8 0.9 1. 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9
2. 2.1 2.2 2.3 2.4 2.5 2.6 2.7 2.8 2.9 3. 3.1 3.2 3.3
3.4 3.5 3.6 3.7 3.8 3.9 4. 4.1 4.2 4.3 4.4 4.5 4.6 4.7
4.8 4.9]
[-1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1. -1. -1. -1. -0.99 -0.99 -0.99
-0.99 -0.99 -0.98 -0.98 -0.98 -0.97 -0.96 -0.96 -0.95 -0.94 -0.92 -0.91
-0.89 -0.86 -0.83 -0.8 -0.76 -0.72 -0.66 -0.6 -0.54 -0.46 -0.38 -0.29
-0.2 -0.1 -0. 0.1 0.2 0.29 0.38 0.46 0.54 0.6 0.66 0.72
0.76 0.8 0.83 0.86 0.89 0.91 0.92 0.94 0.95 0.96 0.96 0.97
0.98 0.98 0.98 0.99 0.99 0.99 0.99 0.99 1. 1. 1. 1.
1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.
1. 1. 1. 1. ]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0.01 0.01 0.01 0.01 0.01 0.01 0.02 0.02 0.03 0.03 0.04
0.05 0.06 0.07 0.09 0.1 0.13 0.15 0.18 0.22 0.26 0.31 0.36 0.42 0.49
0.56 0.63 0.71 0.79 0.86 0.92 0.96 0.99 1. 0.99 0.96 0.92 0.86 0.79
0.71 0.63 0.56 0.49 0.42 0.36 0.31 0.26 0.22 0.18 0.15 0.13 0.1 0.09
0.07 0.06 0.05 0.04 0.03 0.03 0.02 0.02 0.01 0.01 0.01 0.01 0.01 0.01
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. ]
これをグラフで確認してみましょう。
# 作図 plt.plot(h, y, label='tanh(h)') plt.plot(h, dy, linestyle='--', label='dy/dh') plt.xlabel('h') plt.ylabel('y') plt.legend() plt.show()
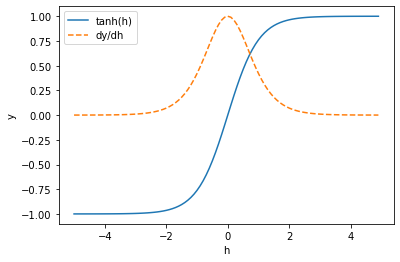
微分は、元の関数の傾きを表すのでした(1巻の4.3節)。0付近の入力に対する出力(青の実線)は大きく変化する(傾きが大きい)ため、微分(オレンジの破線)も0から1の値をとります。しかし0付近の外の入力に対する出力は変化(傾き)が小さいため、微分の値もほとんど0になります。
勾配の値が0というのは、学習する(損失を下げる)ための情報を持っていないということです。
・MatMulレイヤの場合
次にTime RNNレイヤにおける行列の積(MatMulノード)に関して、重みパラメータと勾配との関係を確認しましょう。
これまでと同様に、RNNレイヤ(内のMatMulノード)の順伝播における入力データを$\mathbf{h}_t$として、$\mathbf{h}_t$に対応する重みを$\mathbf{W}_{\mathbf{h}}$、$\mathbf{h}_t$に関する勾配を$\frac{\partial L}{\partial \mathbf{h}_t}$とします。この$\mathbf{h}_t$は、Time RNNレイヤの順伝播の出力データ$\mathbf{hs} = (\mathbf{h}_0, \cdots, \mathbf{h}_{T-1})$内の1つの要素のことです。$\frac{\partial L}{\partial \mathbf{h}_t}$は、Time RNNレイヤの逆伝播の入力データ$\frac{\partial L}{\partial \mathbf{hs}} = (\frac{\partial L}{\partial \mathbf{h}_0}, \cdots, \frac{\partial L}{\partial \mathbf{h}_{T-1}})$内の1つの要素です。ただしTime RNNレイヤの順伝播の出力・逆伝播の入力時にtanh関数を通ります。$\mathbf{W}_{\mathbf{h}}$は、$T$個のRNNレイヤで共有されるパラメータです。Time RNNレイヤについては、「5.3節」を参照してください。
$\frac{\partial L}{\partial \mathbf{h}_t}$と$\mathbf{W}_{\mathbf{h}}$を作成します。
# バッチサイズ N = 2 # 重み付き和の次元数 H = 3 # (簡易的に)逆伝播の入力データを作成 dh = np.ones((N, H)) # RNNレイヤの重みを生成 np.random.seed(3) # 乱数を固定 Wh = np.random.randn(H, H) print(np.round(Wh, 2))
[[ 1.79 0.44 0.1 ]
[-1.86 -0.28 -0.35]
[-0.08 -0.63 -0.04]]
$t$番目のRNNレイヤにおける逆伝播の出力データ$\frac{\partial L}{\partial \mathbf{h}_{t-1}}$は、次の式で計算するのでした(5.3.1項)。
ここでは$T-1$番目のRNNレイヤで計算(出力)された勾配(情報)が、$0$番目のRNNレイヤを出力するまでの$T$回の計算によってどのように変化するのかを見ます。よって、本来は各RNNレイヤの出力$\mathbf{h}_t$は分岐して伝播するため2つの勾配の和をとる必要がありますが、ここでは行いません 。
各RNNレイヤを出力する度に、次の式で平均L2ノルムを計算して記録しておきます。L2ノルムについては、2.3.5項で少しだけ確認しました。
平方根の計算は、np.sqrt()で行います。
# 時間サイズ T = 20 # L2ノルムの受け皿を初期化 norm_list = [] # 時刻ごとに処理 for t in range(T): # 勾配を計算(更新) dh = np.dot(dh, Wh.T) # 平均L2ノルムを計算 norm = np.sqrt(np.sum(dh**2)) / N # 結果をリストに格納 norm_list.append(norm) print(np.round(norm_list, 2))
[ 2.47 3.34 4.78 6.28 8.08 10.25 12.94 16.28 20.45 25.69
32.25 40.49 50.82 63.8 80.08 100.51 126.16 158.36 198.77 249.5 ]
RNNレイヤを伝播するごとに勾配が大きくなっていることが分かります。
グラフでも確認しましょう。
# 作図 plt.plot(np.arange(1, len(norm_list) + 1), norm_list) plt.xlabel('time step') plt.ylabel('norm') plt.title('Exploding Gradients', fontsize=20) plt.show()
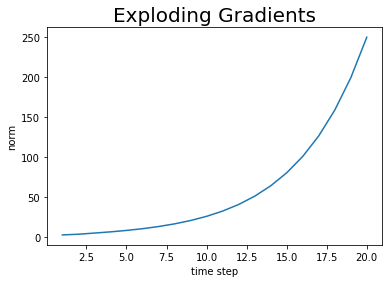
このまま大きくなり続けると値を保持できなくなってしまいます。これを勾配爆発と呼びます。
続いて勾配消失する場合を確認しましょう。重みの初期化時に全ての要素に0.5を掛けて値を小さくします。これ操作によって、標準偏差を1から0.5に変更しています。
# (簡易的に)逆伝播の入力データを作成 dh = np.ones((N, H)) # RNNレイヤの重みを生成 np.random.seed(3) Wh = np.random.randn(H, H) * 0.5 print(np.round(Wh, 2)) # 時刻ごとのノルムを計算 norm_list = [] # 初期化 for t in range(T): # 逆伝播の入力を更新 dh = np.dot(dh, Wh.T) # 平均L2ノルムを計算 norm = np.sqrt(np.sum(dh**2)) / N norm_list.append(norm) # 格納 print(np.round(norm_list, 2))
[[ 0.89 0.22 0.05]
[-0.93 -0.14 -0.18]
[-0.04 -0.31 -0.02]]
[1.23 0.83 0.6 0.39 0.25 0.16 0.1 0.06 0.04 0.03 0.02 0.01 0.01 0.
0. 0. 0. 0. 0. 0. ]
先ほどとは逆に、計算する度に値が小さくなっています。
# 作図 plt.plot(np.arange(1, len(norm_list) + 1), norm_list) plt.xlabel('time step') plt.ylabel('norm') plt.title('Vanishing Gradients', fontsize=20) plt.show()
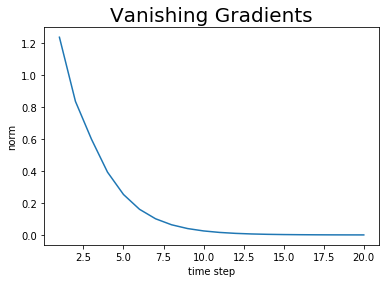
最終的に勾配がほとんど0になっているが分かります。値が0ということは勾配情報がなくなっていることを意味し、これを勾配消失と呼びます。
この項では、勾配消失と勾配爆発について確認しました。次項では、勾配爆発への対策を考えます。
6.1.4 勾配爆発への対策
勾配爆発の回避策として用いられる勾配クリッピングを実装します。勾配クリッピングでは、全ての勾配を用いたL2ノルムが閾値を越えないように勾配の値を調整します。
# 6.1.4項で利用するライブラリ import numpy as np import matplotlib.pyplot as plt
・処理の確認
簡単な例として、重みパラメータが2つの場合を考えます。
この例では、0から1の値をとる一様乱数np.random.rand()を使って簡易的に大きな値を持つ勾配を作成します。大きな値となるように、生成した全ての要素に10を掛けます。
生成した勾配をリストにまとめておきます。
# (簡易的に大きい値を持つ)重みパラメータの勾配を生成 dW1 = np.random.rand(3, 3) * 10 dW2 = np.random.rand(3, 3) * 10 # 全ての勾配を格納 grads = [dW1, dW2] print(np.round(grads, 2))
[[[6.49 2.78 6.76]
[5.91 0.24 5.59]
[2.59 4.15 2.84]]
[[6.93 4.4 1.57]
[5.45 7.8 3.06]
[2.22 3.88 9.36]]]
全てのパラメータに関する勾配のL2ノルム$|\hat{\mathbf{g}}|$を、次の式で計算します。
ここで$\hat{\mathbf{g}}$は全ての勾配、$|\cdot|$はL2ノルムを表します。
記号も式も仰々しいですが、処理はこれまでと似たようなものです。リストに格納した各勾配を取り出して、np.sum(grad**2)で2乗和の計算をします。計算結果をtotal_normに加算していき、最後にnp.sqrt()で平方根を計算します。
## L2ノルムの計算 # 受け皿を初期化 total_norm = 0 # 勾配の2乗和を計算 for grad in grads: total_norm += np.sum(grad**2) # 平方根を計算 total_norm = np.sqrt(total_norm) print(np.round(total_norm, 2))
21.71
閾値$threshold$をmax_normとして値を指定します。
その閾値をL2ノルムで割ることで、大小関係を計算します。計算結果をrateとします。
# 閾値を指定 max_norm = 5.0 # 大小関係を計算 rate = max_norm / total_norm print(np.round(rate, 2))
0.23
勾配のL2ノルム$|\hat{\mathbf{g}}|$を閾値$threshold$と比較して、大きいとき0から1未満、等しいとき1、小さいとき1より大きい値になります。
条件式$|\hat{\mathbf{g}}| \geq threshold$に従い、勾配の値を調整します。ただし実装上は、条件式の両辺を$|\hat{\mathbf{g}}|$で割り、$1 \geq \frac{threshold}{|\hat{\mathbf{g}}|}$とします。$\frac{threshold}{|\hat{\mathbf{g}}|}$が先ほど求めたrateです。rateを使って、次の計算式で各勾配を調整します。これを勾配クリッピングと呼びます。
# 勾配クリッピング if rate < 1: # L2ノルムが閾値より大きいとき # 各パラメータを調整 for grad in grads: grad *= rate print(np.round(grads, 2))
[[[1.5 0.64 1.56]
[1.36 0.06 1.29]
[0.6 0.96 0.65]]
[[1.6 1.01 0.36]
[1.25 1.8 0.71]
[0.51 0.89 2.16]]]
条件式を厳密に実装するならrate =< 1ですが、rateが1の場合は勾配の値に変化はありませんね。なので処理効率の面から、rate == 1の場合は計算しません。
勾配クリッピングによって各勾配の要素の値が小さくなりました。
調整した勾配を用いてL2ノルムを計算してみましょう。
# L2ノルムを計算 total_norm = 0 # 初期化 for grad in grads: total_norm += np.sum(grad**2) total_norm = np.sqrt(total_norm) print(np.round(total_norm, 2))
5.0
L2ノルムが、閾値として指定した値になります。
・実装
処理の確認ができたので、勾配クリッピングを関数として実装します。
# 勾配クリッピング def clip_grads(grads, max_norm): # L2ノルムを計算 total_norm = 0 # 初期化 for grad in grads: total_norm += np.sum(grad**2) total_norm = np.sqrt(total_norm) # 勾配クリッピング rate = max_norm / (total_norm + 1e-6) if rate < 1: # L2ノルムが閾値より大きいとき for grad in grads: grad *= rate
$\frac{threshold}{|\hat{\mathbf{g}}|}$(rate)の計算において、0除算とならないように分母に微小な値1e-6を加算してから計算しています。
この関数はreturnを指定していないので、何も返しません。引数に渡したgradsの値が直接更新されます。
実装した関数を試してみましょう。全ての勾配gradsの値が更新されているので、再度勾配を作成してgradsに格納します。
# (簡易的に大きい値を持つ)重みパラメータの勾配を生成 dW1 = np.random.rand(3, 3) * 10 dW2 = np.random.rand(3, 3) * 10 dW3 = np.random.rand(3, 3) * 10 # 全ての勾配を格納 grads = [dW1, dW2, dW3] print(np.round(grads, 2))
[[[9.76 6.72 9.03]
[8.46 3.78 0.92]
[6.53 5.58 3.62]]
[[2.25 4.07 4.69]
[2.69 2.92 4.58]
[8.61 5.86 2.83]]
[[2.78 4.55 2.05]
[2.01 5.14 0.87]
[4.84 3.62 7.08]]]
clip_grads()で勾配クリッピングを行います。
# 勾配クリッピング clip_grads(grads, max_norm) print(np.round(grads, 2)) print(np.round( np.sqrt(np.sum([np.sum(grad**2) for grad in grads])) , 2))
[[[1.79 1.23 1.66]
[1.55 0.69 0.17]
[1.2 1.02 0.66]]
[[0.41 0.75 0.86]
[0.49 0.54 0.84]
[1.58 1.08 0.52]]
[[0.51 0.83 0.38]
[0.37 0.94 0.16]
[0.89 0.66 1.3 ]]]
5.0
gradsの値が更新されました。L2ノルムの計算については、リスト内包表記を用いて処理しています。
以上で勾配爆発への対策である勾配クリッピングを実装できました。次節では、勾配消失の対策を考えます。
参考文献
- 斎藤康毅『ゼロから作るDeep Learning 2――自然言語処理編』オライリー・ジャパン,2018年.
おわりに
6章1つ目の記事です。LSTMは、RNNを少し複雑にしたものです。難しさは変わりませんが、ややこしくなりますね。このブログでは、そのややこしいに踏み込んでいくのが目的です。とはいえ本で省略されているのにはそれなりの理由(ややこしい)があるので、わざわざこのブログを読まずに本の載っている内容を理解して進めてもいいと思いますよ。
2021年1月7日は、モーニング娘。'21のサブリーダー石田亜佑美さんの24歳のお誕生日です!
おめでとうございます!10年目の今年、踊ってる姿を観たいんだよおおお。
【次節の内容】