はじめに
『ベイズ推論による機械学習入門』(MLSシリーズ)の独学時のノートです。各種のモデルやアルゴリズムについて「数式・プログラム・図」を用いて解説します。
本の補助として読んでください。
この記事では、多次元ガウス分布に対するベイズ推論で登場する数式の行間を埋めます。
【前節の内容】
【他の節の内容】
【この節の内容】
3.4.0 多次元ガウスモデルの生成モデルの導出
多次元ガウスモデル(multivariate Gaussian model)の定義(仮定)を確認する。多次元ガウスモデルでは、生成分布を多次元ガウス分布(Gaussian distribution・多変量正規分布・multivariate Normal distribution)、事前分布を3つのパターンに応じて多次元ガウス分布、ウィシャート分布(Wishart distribution)、ガウス・ウィシャート分布(Gaussian-Wishart distribution)とする。
多次元ガウス分布については「多次元ガウス分布の定義式 - からっぽのしょこ」、ウィシャート分布については「ウィシャート分布の定義式 - からっぽのしょこ」、ガウス・ウィシャート分布については「準備中」を参照のこと。
生成過程の設定
まずは、多次元ガウスモデルの生成過程(generative process)を数式で確認する。
観測データ数を 、データ番号(インデックス)を
とする。
データの次元数を 、次元番号を
とする。
各観測データ は、
次元ベクトル(
個の要素で1つのデータ)
であり、各要素 は、実数値をとる。
個の観測データをまとめて、観測データ集合
として扱う。
または、観測データ を、
行
列の行列として扱う。
各観測データ は、パラメータ
のガウス分布に従い独立に生成されるとする。
を生成分布のパラメータと呼ぶ。データの生成分布を観測モデルや尤度関数とも呼ぶ。
はガウス分布の平均パラメータ(
次元の平均ベクトル)、
は精度パラメータ(
行
列の精度行列・分散共分散行列
の逆行列)
なので、 は正定値行列であり、
の各要素
は実数値、
の各対角要素
は正の実数値、非対角要素
は実数値を満たす必要がある。
は共分散パラメータ(
行
列の分散共分散行列)
なので、 は正定値行列であり、各対角要素
は正の実数値、非対角要素
は実数値を満たす必要がある。
は
(次元
)の期待値、
は
の標準偏差、
は
の分散、
は
の共分散、
は
の精度を表す。
正の実数値を とも表記する。
事前分布に関しては、3つのパターン(平均が未知・精度が未知・平均と精度が未知)に応じて設定する。
平均が未知の場合
平均パラメータ が未知の場合、
は、パラメータ
のガウス分布に従い生成されるとする。
を生成分布の超パラメータと呼ぶ。パラメータのパラメータを超パラメータ(ハイパーパラメータ)と言う。下付き文字の
は、平均パラメータ
の為のパラメータであることを示しているだけで、数学的な意味はない。
は平均パラメータ(
次元の平均ベクトル)、
は精度パラメータ(
行
列の精度行列)
なので、 は正定値行列であり、
の各要素
は実数値、
の各対角要素
は正の実数値、非対角要素
は実数値を満たす必要がある。
ガウス分布の確率変数は、ガウス分布の平均パラメータの条件を満たす。
精度が未知の場合
精度パラメータ が未知の場合、
は、パラメータ
のウィシャート分布に従い生成されるとする。
は自由度パラメータ、
は尺度パラメータ(
行
列のスケール行列)
なので、 は
より大きい実数値、
は正定値行列を満たす必要がある。
ウィシャート分布の確率変数は、ガウス分布の精度パラメータの条件を満たす。
平均・精度が未知の場合
平均パラメータ と精度パラメータ
が未知の場合、
は、パラメータ
のガウス・ウィシャート分布に従い生成されるとする。
は平均パラメータ(
次元の平均ベクトル)、
は係数として用いて
を精度パラメータ(
行
列の精度行列)
とするので、 は実数値、
は正の実数値を満たす必要がある。
は自由度パラメータ、
は尺度パラメータ(
行
列のスケール行列)
なので、 は
より大きい実数値、
は正定値行列を満たす必要がある。
ガウス・ウィシャート分布の確率変数は、ガウス分布の平均パラメータと精度パラメータの条件を満たす。
以上で、ガウスモデルの生成過程(定義・仮定)を確認した。生成過程は、変数やパラメータ間の依存関係であり、生成モデルや推論アルゴリズムの導出でも用いる。
尤度関数の確認
次は、多次元ガウスモデルの尤度関数(likelihood function)を数式で確認する。パラメータが与えられたときのデータの生成確率(観測された全ての変数の同時確率)を尤度と呼ぶ。
パラメータ が与えられた(条件とする)下での観測データ
の生成確率は、生成過程(依存関係)に従い次のように変形できる。
途中式の途中式(クリックで展開)
個のデータは独立に生成されることから、観測データ集合
の生成確率は、各データ
の生成確率の積に分解できる。
生成分布(3.96)を用いた式が得られた。
生成モデルの導出
続いて、多次元ガウスモデルの生成モデル(generative model)を数式で確認する。観測・潜在変数やパラメータを全て確率変数とみなした結合分布(同時分布)を生成モデルと呼ぶ。
平均が未知の場合
平均パラメータ が未知の場合、観測変数
、パラメータ
、超パラメータ
をそれぞれ確率変数とする結合分布は、生成過程(依存関係)に従い次のように分解できる。
途中式の途中式(クリックで展開)
依存関係のない場合は独立性 、依存関係のある場合は乗法定理
により、式を変形していく。
- 1: 変数やパラメータごとの項に分割する。
依存関係のある変数、パラメータ、超パラメータの項を分割する。
と
は無関係なので条件から省ける。
さらに2つ目の項の、独立なパラメータ の項を分割する。
と
は無関係なので条件から省ける。
3つ目の項の、独立な超パラメータ の項を分割する。
- 2: 全データに関する
1データレベルに項を分解した。
精度が未知の場合
精度パラメータ が未知の場合、観測変数
、パラメータ
、超パラメータ
をそれぞれ確率変数とする結合分布は、生成過程(依存関係)に従い次のように分解できる。
途中式の途中式(クリックで展開)
- 1: 変数やパラメータごとの項に分割する。
依存関係のある変数、パラメータ、超パラメータの項を分割する。
と
は無関係なので条件から省ける。
さらに2つ目の項の、独立なパラメータ の項を分割する。
と
は無関係なので条件から省ける。
3つ目の項の、独立な超パラメータ の項を分割する。
- 2: 全データに関する
1データレベルに項を分解した。
平均・精度が未知の場合
平均パラメータ と精度パラメータ
が未知の場合、観測変数
、パラメータ
、超パラメータ
をそれぞれ確率変数とする結合分布は、生成過程(依存関係)に従い次のように分解できる。
途中式の途中式(クリックで展開)
- 1: 変数やパラメータごとの項に分割する。
依存関係のある変数、パラメータ、超パラメータの項を分割する。
と
は無関係なので条件から省ける。
さらに2つ目の項の、依存関係のあるパラメータ の項を分割する。
と
、
と
はそれぞれ無関係なので条件から省ける。
3つ目の項の、独立な超パラメータ の項を分割する。
- 2: 全データに関する
1データレベルに項を分解した。
それぞれの式自体が変数やパラメータ間の依存関係を表している。
グラフィカルモデルの確認
最後は、多次元ガウスモデルの生成モデルをグラフィカルモデル表現(graphical model representation)で確認する。グラフィカルモデルについては1.5節を参照のこと。
平均が未知の場合
平均パラメータ が未知で精度パラメータ
が既知の場合、多次元ガウスモデルの生成モデルは、次の式に分解できた。
この式をグラフィカルモデルにすると、次の図になる。
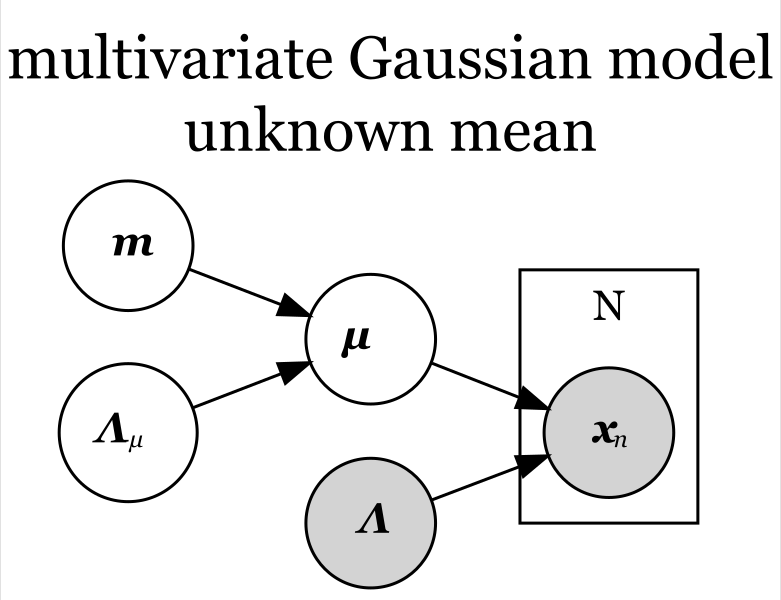
「 」と「
」が、生成分布の平均パラメータの事前分布
に対応し、事前分布(のパラメータ)に従ってパラメータ
が生成されることを示している。
「 」と「
」が、生成分布(のパラメータ)に従って各データ
が生成されることを示している。
「 」のプレートが、
に対応し、
個の観測データ
が繰り返し生成されることを示している。
「 」のノードの塗りつぶしが、精度パラメータが既知であることを示している。
精度が未知の場合
平均パラメータ が既知で精度パラメータ
が未知の場合、モデルの生成モデルは、次の式に分解できた。
この式をグラフィカルモデルにすると、次の図になる。
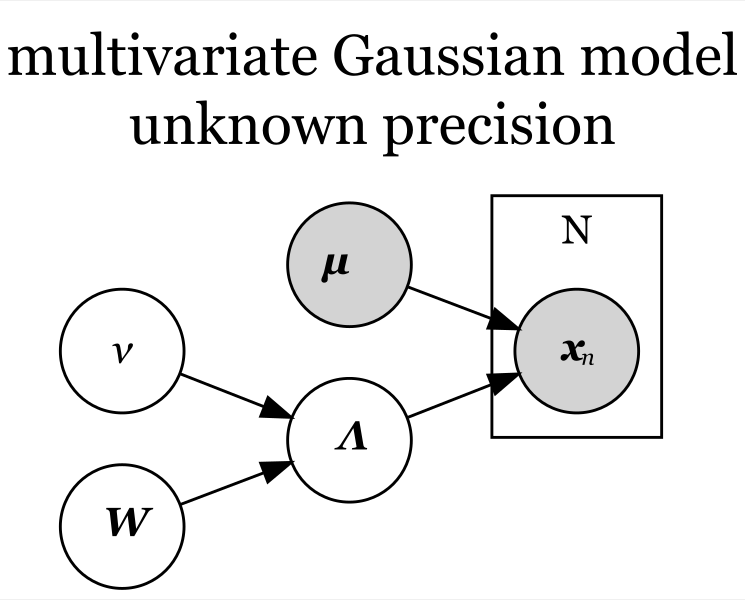
「 」と「
」が、生成分布の精度パラメータの事前分布
に対応し、事前分布(のパラメータ)に従ってパラメータ
が生成されることを示している。
「 」のノードの塗りつぶしが、平均パラメータが既知であることを示している。
平均・精度が未知の場合
平均パラメータ と精度パラメータ
が未知の場合、モデルの生成モデルは、次の式に分解できた。
この式をグラフィカルモデルにすると、次の図になる。
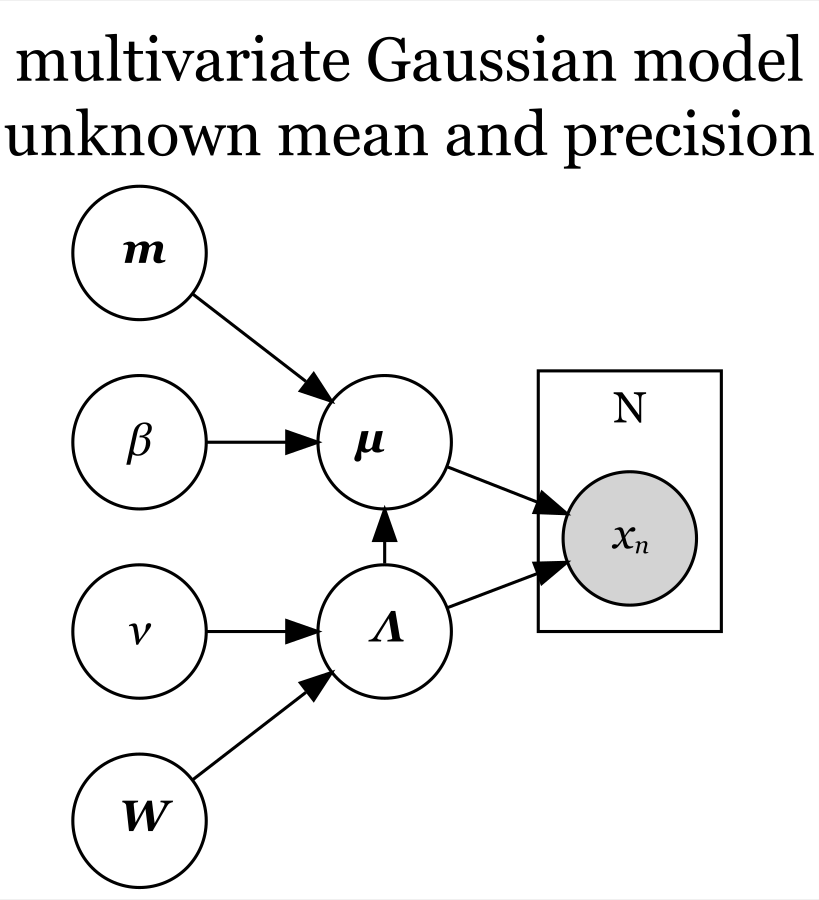
「 」と「
」に加えて「
」が、生成分布の平均パラメータの事前分布
に対応し、平均パラメータの事前分布(のパラメータ)と精度パラメータに従ってパラメータ
が生成されることを示している。
この記事では、多次元ガウスモデルで用いる記号や定義を確認した。次の記事では、多次元ガウスモデルに対するベイズ推論を導出する。
参考文献

おわりに
この記事の投稿日は、このブログの開設7周年の日でした。何かしら記事を投稿しようと思うも作業中のものがなかったので、急遽書いたのがこの記事です。
今日から8年目に突入です。さすがに褒めてほしいです。ついでに広めてほしいです(自分ではできないので)。あとそろそろいいかげんに収益化したいです(でも面倒臭い)、、万年赤字なんですこのブログ。。。
これからもよろしくお願いします。
そして!12月1日は、Juice=Juiceの元メンバーの宮本佳林さんのお誕生日です。先ほど公開されたライブ映像をどうぞ♪
おめでとうございます!ソロでも精力的に活動を続けてくれてありがとうございます。
この方の誕生日に合わせてこのブログを開設しました。そういう縁なので、皆さん1曲聴いていってください。
ちなみに、勉強のやる気はあるのですが、ブログ周りのアレコレの作業のやる気が不足しております。地道に頑張ります。
【次節の内容】
- 数式読解編
ガウスモデルに対するベイズ推論を数式で確認します。
- スクラッチ実装編
ガウスモデルの生成モデルをプログラムで確認します。
(Python版は準備中です)
本や記事の表記などとは対応していませんが、必要な内容は概ね上の記事で書いているので、参考にしてください。