はじめに
「機械学習・深層学習」初学者のための『ゼロから作るDeep Learning』の攻略ノートです。『ゼロつくシリーズ』学習の補助となるように適宜解説を加えています。本と一緒に読んでください。
ニューラルネットワーク内部の計算について、数学的背景の解説や計算式の導出を行い、また実際の計算結果やグラフで確認していきます。
この記事は、4.4節「勾配」の前半の内容です。勾配の定義を説明してPythonで実装します。
【前節の内容】
【他の節の内容】
【この節の内容】
4.4.0 勾配
4.3.3項では、多変数関数の偏微分について学びました。この項では、各変数に関する偏微分をまとめた勾配について解説します。
利用するライブラリを読み込みます。
# 4.4.0項で利用するライブラリ import numpy as np import matplotlib.pyplot as plt
・数式の確認
まずは、勾配の数式上の表記を確認します。
$n$個の要素
を入力する関数を$f(\mathbf{x})$とします。
各要素$x_n$についての関数$f(\mathbf{x})$の偏微分$\frac{\partial f(\mathbf{x})}{\partial x_n}$を全ての変数分まとめたものを入力$\mathbf{x}$の勾配と言います。
入力$\mathbf{x}$と勾配$\frac{\partial f(\mathbf{x})}{\partial \mathbf{x}}$は同じ形状になります。
・処理の確認
次に、勾配の計算で行う処理を確認します。
ここでは、2乗和の関数を例とします。
2つの変数$x_0,\ x_1$をまとめて$\mathbf{x}$で表します。
このとき、入力$\mathbf{x}$の勾配を$\frac{\partial f(\mathbf{x})}{\partial \mathbf{x}}$で表します。
ただし、Pythonのインデックスに合わせて添字を0から割り当てています。
2乗和を計算する関数を作成します。
# 2乗和の関数を作成 def f(x): # 2乗和を計算 return np.sum(x**2)
入力$\mathbf{x}$をxとして値を指定します。また、xと同じ形状のオブジェクトgradを作成します。
# (仮の)入力を作成 x = np.array([3.0, 4.0]) print(x) # 勾配の受け皿を作成 grad = np.zeros_like(x) print(grad)
[3. 4.]
[0. 0.]
np.zeros_like()は、引数に指定した変数と同じ形状で、全ての値が0の配列を作成します。
各要素についての偏微分を計算して、gradに代入していきます。
$x_0$についての偏微分$\frac{\partial f(\mathbf{x})}{\partial x_0}$を次の式で計算していきます。
数値微分の計算に用いる微小な値hを作成します。
# 微小な値を設定 h = 1e-4 # 0.0001
この例では、$h = 0.0001$とします。
まずは、$x_0$の値x[0]を取り出してtmp_valとして保存しておきます。
# x0の値を取り出す tmp_val = x[0] print(tmp_val)
3.0
$x_0$の微小な変化に対する関数$f(\mathbf{x})$の変化量$f(x_0 + h, x_1)$を計算します。
# x0に微小な値を加える x[0] = tmp_val + h print(x) # f(x0+h, x1)を計算 fxh1 = f(x) print(fxh1)
[3.0001 4. ]
25.00060001
x[0]を、元の値tmp_valにhを加えた値に置き換えます。$\mathbf{x} = (x_0 + h, x_1)$に置き換わったxを用いて$f(\mathbf{x})$を計算します。
同様に、$x_0$のマイナス方向への微小な変化に対する変化量$f(x_0 - h, x_1)$を計算します。
# x0から微小な値を引く x[0] = tmp_val - h print(x) # f(x0-h, x1)を計算 fxh2 = f(x) print(fxh2)
[2.9999 4. ]
24.99940001
x[0]を、元の値tmp_valからhを引いた値に置き換えて、$f(\mathbf{x})$を計算します。
中心差分による数値微分を計算します。
# 中心差分による数値微分を計算 grad[0] = (fxh1 - fxh2) / (2 * h) print(grad)
[6. 0.]
$\frac{\partial f(\mathbf{x})}{\partial x_0} = 6$が求まりました。
最後に、変更された$x_0$の値x[0]を元に戻します。
# 元の値に戻す x[0] = tmp_val print(x)
[3. 4.]
同様に、$x_1$の偏微分$\frac{\partial f(\mathbf{x})}{\partial x_1}$を計算します。計算処理は、x[0]がx[1]、grad[0]がgrad[1]に換わります。
そこで、for文を使って要素数(x.size)回繰り返し同じ計算をします。これによって、入力xの要素数に関わらず勾配を計算できます。
# 勾配を計算 for idx in range(x.size): # 微分する変数の値を取り出す tmp_val = x[idx] # f(x+h)を計算 x[idx] = tmp_val + h fxh1 = f(x) # f(x-h)を計算 x[idx] = tmp_val - h fxh2 = f(x) # 数値微分(中心差分) grad[idx] = (fxh1 - fxh2) / (2 * h) # 元の値に戻す x[idx] = tmp_val print(grad)
[6. 8.]
が求まりました。
以上が勾配を求める処理です。
・実装
処理の確認ができたので、数値微分による勾配を関数として実装します。
# 勾配を計算する関数の実装 def numerical_gradient(f, x): # 微小な値を設定 h = 1e-4 # 0.0001 # 勾配を初期化(受け皿を作成) grad = np.zeros_like(x) # 勾配を計算 for idx in range(x.size): # 微分する変数の値を取り出す tmp_val = x[idx] # f(x+h)を計算 x[idx] = tmp_val + h fxh1 = f(x) # f(x-h)を計算 x[idx] = tmp_val - h fxh2 = f(x) # 数値微分を計算:(中心差分) grad[idx] = (fxh1 - fxh2) / (2 * h) # 元の値に戻す x[idx] = tmp_val return grad
対象となる関数(数式)の計算を行う関数(プログラム)の関数名を第1引数に受け取ります。
実装した関数を試してみましょう。
# (仮の)入力を作成 x = np.array([3.0, 4.0]) # 勾配を計算 grad = numerical_gradient(f, x) print(grad)
[6. 8.]
3変数の2乗和も計算できます。
# (仮の)入力を作成 x = np.array([3.0, 4.0, 5.0]) # 勾配を計算 grad = numerical_gradient(f, x) print(grad)
[ 6. 8. 10.]
ただし、多次元配列は処理できません。
・グラフで確認
最後に、関数と勾配(接平面)の関係をグラフで確認します。3Dプロットについては「3Dプロットの作図【ゼロつく1のノート(Python)】 - からっぽのしょこ」をご確認ください。
作図用の$x_0,\ x_1$の値を作成して、各要素の2乗和を計算します。
# 作図用の値を作成 x0_vals = np.arange(-3.0, 3.5, 0.5) x1_vals = np.arange(-3.0, 3.5, 0.5) # 格子状の点に変換 X0_vals, X1_vals = np.meshgrid(x0_vals, x1_vals) # 2乗和を計算 Z_vals = X0_vals**2 + X1_vals**2
X0_valsがx軸の値、X1_valsがy軸の値、Z_valsがz軸の値です。
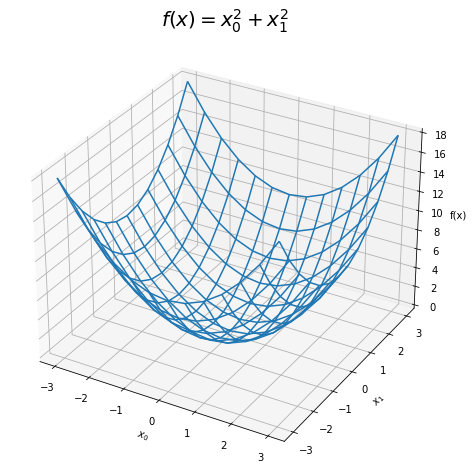
2乗和の関数$f(\mathbf{x})$のグラフを作成します。
# 2乗和のグラフを作成 fig = plt.figure(figsize=(8, 8)) # 図の設定 ax = fig.add_subplot(projection='3d') # 3D用の設定 ax.plot_wireframe(X0_vals, X1_vals, Z_vals) # ワイヤーフレーム図 ax.set_xlabel('$x_0$') # x軸ラベル ax.set_ylabel('$x_1$') # y軸ラベル ax.set_zlabel('f(x)') # z軸ラベル ax.set_title('$f(x) = x_0^2 + x_1^2$', fontsize=20) # タイトル plt.show()
・接平面
勾配として求めた偏微分を接線と接平面で可視化します。
関数$f(\mathbf{x})$上の点$(x_0, x_1, f(x_0, x_1))$を指定して、勾配$\frac{\partial f(\mathbf{x})}{\partial \mathbf{x}}$を計算します。
# (仮の)入力を指定 x = np.array([1.0, 2.0]) # 勾配を計算 grad = numerical_gradient(f, x) print(grad)
[2. 4.]
この例では、$\mathbf{x} = (1, 2)$とします。また、$\frac{\partial f(\mathbf{x})}{\partial \mathbf{x}} = (2, 4)$が求まりました。
扱いやすいように、$x_0,\ x_1$をx0, x1、$\frac{\partial f(\mathbf{x})}{\partial x_0},\ \frac{\partial f(\mathbf{x})}{\partial x_1}$をdx0, dx1として取り出します。
# 変数とその微分(傾き)値を取得 x0, x1 = x dx0, dx1 = grad print(x0, x1) print(dx0, dx1)
1.0 2.0
1.9999999999997797 4.000000000004
$x_0,\ x_1$それぞれの方向の接線を計算します。
# 切片を計算 b0 = f(x) - dx0 * x0 b1 = f(x) - dx1 * x1 print(b0) print(b1) # 接線を計算 tangent_line_0 = dx0 * x0_vals + b0 tangent_line_1 = dx1 * x1_vals + b1 print(np.round(tangent_line_0, 2)) print(np.round(tangent_line_1, 2))
3.0000000000002203
-3.0000000000080007
[-3. -2. -1. 0. 1. 2. 3. 4. 5. 6. 7. 8. 9.]
[-15. -13. -11. -9. -7. -5. -3. -1. 1. 3. 5. 7. 9.]
$f(\mathbf{x})$のグラフに2つの接線を重ねて描画します。
# 接線を作図 fig = plt.figure(figsize=(8, 8)) # 図の設定 ax = fig.add_subplot(projection='3d') # 3D用の設定 ax.plot_wireframe(X0_vals, X1_vals, Z_vals, label='$f(x)$') # 対象の関数 ax.plot(x0_vals, np.repeat(x1, len(x0_vals)), tangent_line_0, color='red', label='$f_{x_0}(x)$') # x0軸方向の接線 ax.plot(np.repeat(x0, len(x1_vals)), x1_vals, tangent_line_1, color='green', label='$f_{x_1}(x)$') # x1軸方向の接線 ax.scatter(x0, x1, f(x), s=50, c='black') # 接点 ax.set_xlabel('$x_0$') # x軸ラベル ax.set_ylabel('$x_1$') # y軸ラベル ax.set_zlabel('f(x)') # z軸ラベル ax.set_title('$(x_0, x_1, f(x))=(' + str(x0) + ', ' + str(x1) + ', ' + str(np.round(f(x), 1)) + ')' + ', (dx_0, dx_1)=(' + str(np.round(dx0, 2)) + ', ' + str(np.round(dx1, 2)) + ')$', loc='left') # 接点に関する値 fig.suptitle('$f(x) = x_0^2 + x_1^2$', fontsize=20) # 全体のタイトル ax.legend() # 凡例 plt.show()
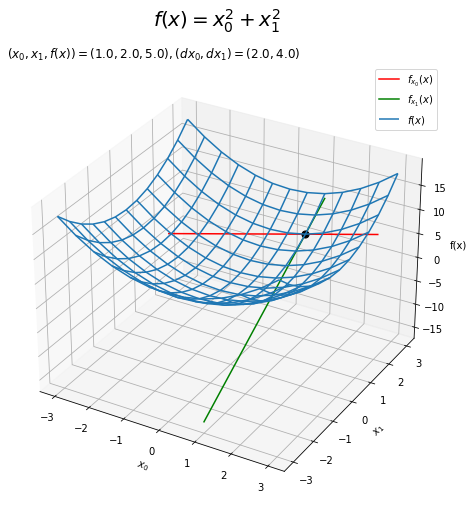
接点上を$x_0$軸方向と$x_1$軸方向に切断した断面図を確認します。
・コード(クリックで展開)
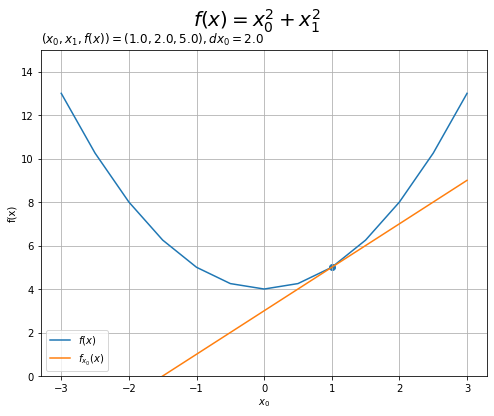
上の図を$x_1 = 2$で切断した断面図を確認します。
# x0軸方向の接線を作図 plt.figure(figsize=(8, 6)) # 図の設定 plt.plot(x0_vals, x0_vals**2 + x1**2, label='$f(x)$') # 対象の関数 plt.plot(x0_vals, tangent_line_0, label='$f_{x_0}(x)$') # x0軸方向の接線 plt.scatter(x0, f(x)) # 接点 plt.xlabel('$x_0$') # x軸ラベル plt.ylabel('f(x)') # y軸ラベル plt.suptitle('$f(x) = x_0^2 + x_1^2$', fontsize=20) # タイトル plt.title('$(x_0, x_1, f(x))=(' + str(x0) + ', ' + str(x1) + ', ' + str(np.round(f(x), 1)) + ')' + ', dx_0=' + str(np.round(dx0, 2)) + '$', loc='left') # 接点に関する値 plt.grid() # グリッド線 plt.legend() # 凡例 plt.ylim(0, 15) # y軸の表示範囲 plt.show()
同様に、$x_0 = 1$の断面図を確認します。
# をx1軸方向の接線を作図 plt.figure(figsize=(8, 6)) # 図の設定 plt.plot(x1_vals, x0**2 + x1_vals**2, label='$f(x)$') # 対象の関数 plt.plot(x1_vals, tangent_line_1, label='$f_{x_1}(x)$') # x1軸方向の接線 plt.scatter(x1, f(x)) # 接点 plt.xlabel('$x_1$') # x軸ラベル plt.ylabel('f(x)') # y軸ラベル plt.suptitle('$f(x) = x_0^2 + x_1^2$', fontsize=20) # タイトル plt.title('$(x_0, x_1, f(x))=(' + str(x0) + ', ' + str(x1) + ', ' + str(np.round(f(x), 1)) + ')' + ', dx_1=' + str(np.round(dx1, 2)) + '$', loc='left') # 接点に関する値 plt.grid() # グリッド線 plt.legend() # 凡例 plt.ylim(0, 15) # y軸の表示範囲 plt.show()
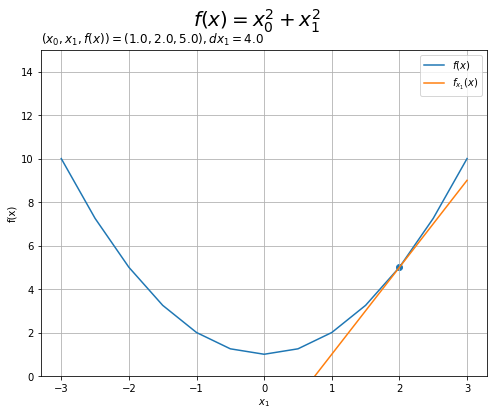
続いて、接平面を計算します。
# 接平面を計算 tangent_plane = dx0 * (X0_vals - x0) + dx1 * (X1_vals - x1) + f(x) print(np.round(tangent_plane, 2))
[[-23. -22. -21. -20. -19. -18. -17. -16. -15. -14. -13. -12. -11.]
[-21. -20. -19. -18. -17. -16. -15. -14. -13. -12. -11. -10. -9.]
[-19. -18. -17. -16. -15. -14. -13. -12. -11. -10. -9. -8. -7.]
[-17. -16. -15. -14. -13. -12. -11. -10. -9. -8. -7. -6. -5.]
[-15. -14. -13. -12. -11. -10. -9. -8. -7. -6. -5. -4. -3.]
[-13. -12. -11. -10. -9. -8. -7. -6. -5. -4. -3. -2. -1.]
[-11. -10. -9. -8. -7. -6. -5. -4. -3. -2. -1. -0. 1.]
[ -9. -8. -7. -6. -5. -4. -3. -2. -1. -0. 1. 2. 3.]
[ -7. -6. -5. -4. -3. -2. -1. -0. 1. 2. 3. 4. 5.]
[ -5. -4. -3. -2. -1. -0. 1. 2. 3. 4. 5. 6. 7.]
[ -3. -2. -1. 0. 1. 2. 3. 4. 5. 6. 7. 8. 9.]
[ -1. 0. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11.]
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13.]]
接点を$(x_p, y_p, z_p)$とすると、接平面は次の式で計算できます。
接平面を作図します。
# 接平面を作図 fig = plt.figure(figsize=(8, 8)) # 図の設定 ax = fig.add_subplot(projection='3d') # 3D用の設定 ax.plot_wireframe(X0_vals, X1_vals, tangent_plane, color='orange') # 接平面 ax.plot(x0_vals, np.repeat(x1, len(x0_vals)), tangent_line_0, color='red', linewidth=5, label='$f_{x_0}(x)$') # x0軸方向の接線 ax.plot(np.repeat(x0, len(x1_vals)), x1_vals, tangent_line_1, color='green', linewidth=5, label='$f_{x_1}(x)$') # x1軸方向の接線 ax.plot_wireframe(X0_vals, X1_vals, Z_vals, label='$f(x)$') # 対象の関数 ax.scatter(x0, x1, f(x), s=100, c='black') # 接点 ax.set_xlabel('$x_0$') # x軸ラベル ax.set_ylabel('$x_1$') # y軸ラベル ax.set_zlabel('f(x)') # z軸ラベル ax.set_title('$(x_0, x_1, f(x))=(' + str(x0) + ', ' + str(x1) + ', ' + str(np.round(f(x), 1)) + ')' + ', (dx_0, dx_1)=(' + str(np.round(dx0, 2)) + ', ' + str(np.round(dx1, 2)) + ')$', loc='left') # 接点に関する値 fig.suptitle('$f(x) = x_0^2 + x_1^2$', fontsize=20) # 全体のタイトル ax.legend() # 凡例 plt.show()
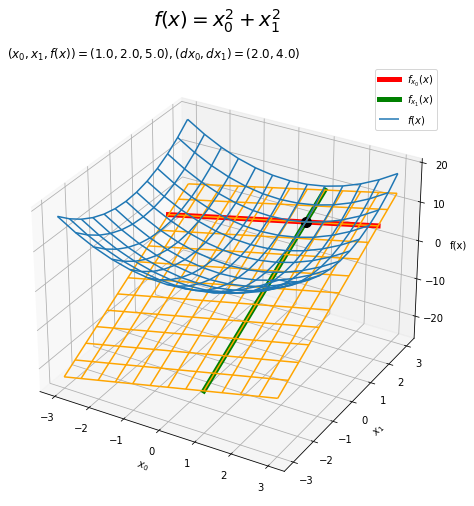
接平面は、2つの接線を並行移動した形になります。
・勾配ベクトル
続いて、勾配を矢印プロットで可視化します。矢印プロットの作図については「矢印プロットの作図【ゼロつく1のノート(Python)】 - からっぽのしょこ」を参照してください。
X0_vals, X1_valsの要素の組み合わせごとに勾配を計算します。
# 1組ずつ勾配を計算 grad_vals = np.array( [numerical_gradient(f, np.array([x0, x1])) for x0, x1 in zip(X0_vals.flatten(), X1_vals.flatten())] ) print(grad_vals[:5])
[[-6. -6.]
[-5. -6.]
[-4. -6.]
[-3. -6.]
[-2. -6.]]
X0とX1を.flatten()メソッドで1次元配列に並べ替えて、zip()でそれぞれの要素を順番に取り出しています。
今後は登場しない作図用の処理なので解説は省略しますが、これまでの処理で再現すると次のように行えます。
# 勾配の受け皿を作成 grad = np.zeros((X0_vals.size, 2)) # カウントを初期化 i = 0 # 1組ずつ勾配を計算 for x0, x1 in zip(X0_vals.flatten(), X1_vals.flatten()): # 配列にまとめる x = np.array([x0, x1]) # 勾配を計算 grad[i] = numerical_gradient(f, x) # カウント i += 1
各点における勾配が得られたので、2次元の矢印プロットで可視化します。
# 勾配を作図 plt.figure(figsize=(8, 8)) # 図の設定 plt.contourf(X0_vals, X1_vals, Z_vals, alpha=0.5) # 対象の関数 plt.quiver(X0_vals, X1_vals, -grad_vals[:, 0], -grad_vals[:, 1]) # 勾配 plt.xlabel('$x_0$') # x軸ラベル plt.ylabel('$x_1$') # y軸ラベル plt.grid() # グリッド線 plt.suptitle('Gradient', fontsize=20) # タイトル plt.title('$f(x) = x_0^2 + x_1^2$', fontsize=15) plt.show() # 表示
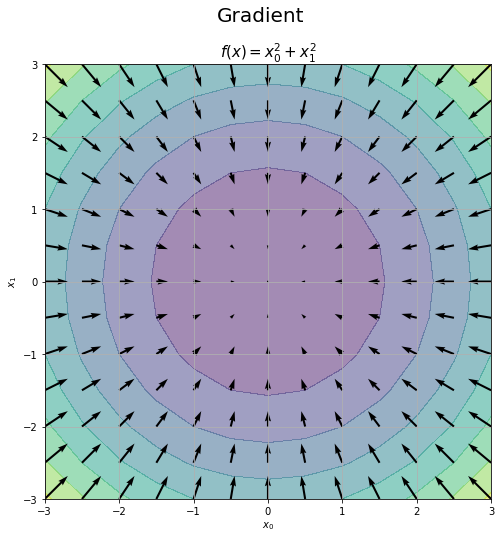
これは式(4.6)の3Dグラフを真上から見たときの勾配のイメージです。各点の勾配の値の大きさに応じて矢印が長くなります。
勾配(矢印)が示す方向が、各点において関数$f(\mathbf{x})$の値を最も減らす方向です。ただし窪みが1つとは限らないため、矢印の先が必ず関数の最小値になるというわけではありません。
続いて、3Dの矢印プロットでも可視化してみます。
z軸方向の変化量を計算します。(どういう計算なのか分かってないので解説は省略します。)
# 各次元の要素を取り出して配列を整形 dX0_vals = grad_vals[:, 0].reshape(X0_vals.shape) dX1_vals = grad_vals[:, 1].reshape(X1_vals.shape) # z軸方向の値を計算 W_vals = np.sqrt(dX0_vals**2 + dX1_vals**2) print(np.round(W_vals, 2))
[[8.49 7.81 7.21 6.71 6.32 6.08 6. 6.08 6.32 6.71 7.21 7.81 8.49]
[7.81 7.07 6.4 5.83 5.39 5.1 5. 5.1 5.39 5.83 6.4 7.07 7.81]
[7.21 6.4 5.66 5. 4.47 4.12 4. 4.12 4.47 5. 5.66 6.4 7.21]
[6.71 5.83 5. 4.24 3.61 3.16 3. 3.16 3.61 4.24 5. 5.83 6.71]
[6.32 5.39 4.47 3.61 2.83 2.24 2. 2.24 2.83 3.61 4.47 5.39 6.32]
[6.08 5.1 4.12 3.16 2.24 1.41 1. 1.41 2.24 3.16 4.12 5.1 6.08]
[6. 5. 4. 3. 2. 1. 0. 1. 2. 3. 4. 5. 6. ]
[6.08 5.1 4.12 3.16 2.24 1.41 1. 1.41 2.24 3.16 4.12 5.1 6.08]
[6.32 5.39 4.47 3.61 2.83 2.24 2. 2.24 2.83 3.61 4.47 5.39 6.32]
[6.71 5.83 5. 4.24 3.61 3.16 3. 3.16 3.61 4.24 5. 5.83 6.71]
[7.21 6.4 5.66 5. 4.47 4.12 4. 4.12 4.47 5. 5.66 6.4 7.21]
[7.81 7.07 6.4 5.83 5.39 5.1 5. 5.1 5.39 5.83 6.4 7.07 7.81]
[8.49 7.81 7.21 6.71 6.32 6.08 6. 6.08 6.32 6.71 7.21 7.81 8.49]]
grad_valsから$x_0$軸と$x_1$軸の要素をそれぞれ取り出してX0_vals, X1_valsと同じ形状に変換します。
3次元の矢印プロットを作成します。(dX0_vals, dX1_valsをそれぞれW_valsで割る必要があります。)
# 勾配を作図 fig = plt.figure(figsize=(8, 8)) # 図の設定 ax = fig.add_subplot(projection='3d') # 3D用の設定 ax.plot_wireframe(X0_vals, X1_vals, Z_vals, alpha=0.5, label='f(x)') # 対象の関数 ax.quiver(X0_vals, X1_vals, Z_vals, -dX0_vals/W_vals, -dX1_vals/W_vals, -W_vals, color='black', pivot='tail', arrow_length_ratio=0.1, length=0.5, label='grad') # 勾配 ax.set_xlabel('$x_0$') # x軸ラベル ax.set_ylabel('$x_1$') # y軸ラベル ax.set_zlabel('f(x)') # z軸ラベル ax.set_title('$f(x) = x_0^2 + x_1^2$', fontsize=15) # タイトル fig.suptitle('Gradient', fontsize=20) # 全体のタイトル ax.legend() # 凡例 #ax.view_init(elev=90, azim=270) # 表示アングル plt.show()
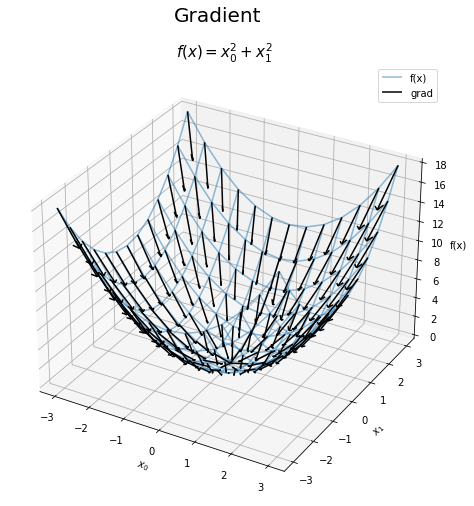
この図を真上から見た図が、2Dの矢印プロットです。ただし、矢印の長さを調整しているので一致しません。
以上で、勾配を確認できました。次は、バッチデータを処理できるようにnumerical_gradient()を改良します。
・バッチ版勾配の実装
4.4.0項で実装した勾配を計算する関数は、バッチデータ(多次元配列)は処理できませんでした。この項では、numerical_gradient()を2次元配列にも対応させます。
・処理の確認
まずは、バッチデータに対する勾配の計算で行う処理を確認します。
2つのfor文を使って、入力xの全ての要素にアクセスします。
# (仮の)入力を作成 x = np.array([[1.0, 2.0, 3.0, 4.0], [5.0, 6.0, 7.0, 8.0]]) print(x.shape) # 全てのインデックスにアクセス for i in range(x.shape[0]): for j in range(x.shape[1]): # インデックスを確認 print(i, j, ':', x[i, j])
(2, 4)
0 0 : 1.0
0 1 : 2.0
0 2 : 3.0
0 3 : 4.0
1 0 : 5.0
1 1 : 6.0
1 2 : 7.0
1 3 : 8.0
x[i, j]に対して数値微分を計算することで、勾配を計算できます。
・実装
処理の確認ができたので、勾配の計算を関数として実装します。
# (2次元配列対応版)勾配を定義 def numerical_gradient(f, x): # フラグをFalseに設定 reshape_flg = False # 2次元配列に変換 if x.ndim == 1: # 1次元配列の場合 x = x.reshape(1, x.size) reshape_flg = True # Trueに変更 # 微小な値を設定 h = 1e-4 # 0.0001 # 勾配を初期化(受け皿を作成) grad = np.zeros_like(x) # 勾配を計算 for i in range(x.shape[0]): # 行インデックス for j in range(x.shape[1]): # 列インデックス # 微分する変数の値を取り出す tmp_val = x[i, j] # f(x+h)を計算 x[i, j] = tmp_val + h fxh1 = f(x[i, :]) # f(x-h)を計算 x[i, j] = tmp_val - h fxh2 = f(x[i, :]) # 数値微分を計算:(中心差分) grad[i, j] = (fxh1 - fxh2) / (2 * h) # 元の値に戻す x[i, j] = tmp_val # 勾配を出力 if reshape_flg: # 形状を変更していた場合 # 元の形状に戻して出力 return grad.reshape(grad.size) else: return grad
commonフォルダのgradient.pyでは、2次元より大きい多次元配列にも対応するように実装されています。ただし、他では使わない関数や機能を使っているため、またこの関数は基本的に4章でしか使わないため、解説は省略します。
実装した関数を試してみましょう。
# 入力を作成 x = np.arange(4 * 5, dtype=np.float).reshape((4, 5)) print(x) print(x.shape) # 勾配を計算 grad = numerical_gradient(f, x) print(grad) print(grad.shape)
[[ 0. 1. 2. 3. 4.]
[ 5. 6. 7. 8. 9.]
[10. 11. 12. 13. 14.]
[15. 16. 17. 18. 19.]]
(4, 5)
[[ 0. 2. 4. 6. 8.]
[10. 12. 14. 16. 18.]
[20. 22. 24. 26. 28.]
[30. 32. 34. 36. 38.]]
(4, 5)
# (仮の)入力を作成 x = np.array([3.0, 4.0]) # 勾配を計算 grad = numerical_gradient(f, x) print(grad)
[6. 8.]
以上で、数値微分によって勾配を計算する関数を実装できました。次項では、勾配を用いてパラメータを更新する勾配降下法を解説します。また5章では、勾配を解析的に計算する方法を学びます。
参考文献

おわりに
相変わらず解説することと伏せることの線引きに悩みます。
- 2021.08.15:加筆修正しました。その際に記事を分割しました。
【次節の内容】