はじめに
『ゼロから作るDeep Learning 2――自然言語処理編』の初学者向け【実装】攻略ノートです。『ゼロつく2』学習の補助となるように適宜解説を加えています。本と一緒に読んでください。
本の内容を1つずつ確認しながらゆっくりと組んでいきます。
この記事は、6.4節「LSTMを使った言語モデル」の内容です。LSTMレイヤを用いたRNNLMを解説して、Pythonで実装します。また実装したモデルを使って学習を行います。
【前節の内容】
【他の節の内容】
【この節の内容】
6.4.1 LSTMを使った言語モデルの実装
LSTMレイヤを用いた言語モデルを実装します。「5.5節」で実装したSimpleRnnlmのRNNレイヤをLSTMレイヤに置き替えたものです。
# Rnnlmクラスの実装で利用するライブラリ import numpy as np import pickle
PTBデータセットを読み込むためのモジュールptbを読み込みます。
# 読み込み用の設定 import sys sys.path.append('C://Users//「ユーザー名」//Documents//・・・//deep-learning-from-scratch-2-master') # データセットの読み込み関数 from dataset import ptb
・データの作成
まずはPTBデータセットを読み込み、学習に用いるデータを作成します。
## データの作成 # データセットを読み込む corpus, word_to_id, id_to_word = ptb.load_data('train') # 訓練データ corpus_test, _, _ = ptb.load_data('test') # テストデータ print(corpus.shape) print(corpus_test.shape) # 語彙数を取得 vocab_size = len(word_to_id) print(vocab_size)
(929589,)
(82430,)
10000
訓練データは約93万語、テストデータは約8万語で構成されています。
RNNでは、単語を順番に入力していき、入力した次の単語を予測するのでした。なのでcorpusから、最後の単語を除いたものが入力データ$\mathbf{xs}$、最初の単語を除いたものが教師ラベル$\mathbf{ts}$となります。
# 入力データとして用いる(最後以外)データを取得 data_x = corpus[:-1] # 教師ラベルとして用いる(最初以外)データを取得 data_t = corpus[1:] # データ数を取得 data_size = len(data_x) print(data_size)
929588
この段階ではまだ$\mathbf{xs},\ \mathbf{ts}$ではありません。またdata_sizeも$N$のことではありません。
RNNMLに入力するミニバッチを抽出します。ミニバッチを取得する方法については、5.5.3項を参照してください。
# バッチサイズを指定 batch_size = 20 # 時間サイズを指定 time_size = 35 # ミニバッチの開始位置を計算 jump = data_size // batch_size # 間隔 offsets = [n * jump for n in range(batch_size)] # インデックス # ミニバッチを初期化 batch_x = np.empty((batch_size, time_size), dtype='i') batch_t = np.empty((batch_size, time_size), dtype='i') # ミニバッチを取得 time_idx = 0 # カウントを初期化 for t in range(time_size): for n, offset in enumerate(offsets): batch_x[n, t] = data_x[(offset + time_idx) % data_size] batch_t[n, t] = data_t[(offset + time_idx) % data_size] # カウントを更新 time_idx += 1 print(batch_x[batch_size-1]) print(batch_x.shape) print(batch_t[batch_size-1]) print(batch_t.shape)
[4210 467 1496 1047 360 1338 108 32 2836 42 32 26 1486 9054
24 563 2425 42 9852 134 668 9415 119 159 212 4307 64 4147
32 1367 753 24 78 119 176]
(20, 35)
[ 467 1496 1047 360 1338 108 32 2836 42 32 26 1486 9054 24
563 2425 42 9852 134 668 9415 119 159 212 4307 64 4147 32
1367 753 24 78 119 176 2111]
(20, 35)
このミニバッチがTime Embedレイヤの入力データ$\mathbf{xs} = (\mathbf{x}_0, \cdots, \mathbf{x}_{T-1})$、Lossレイヤで使用する教師ラベル$\mathbf{ts} = (\mathbf{t}_0, \cdots, \mathbf{t}_{T-1})$です。
実際の学習では、1試行ごとにミニバッチを変更します。
・モデルの構築
続いて、各レイヤのパラメータを生成します。np.random.randn()を使って標準正規分布(平均0、標準正規1の正規分布)に従う乱数を生成し、標準偏差を調整します。Embedレイヤの重みは0.01、LSTMレイヤとAffineレイヤの重みはXavierの初期値を使います。Xavierの初期値とは、その重みの前の層のニューロン数(その重みの行数)を$n$としたとき、標準偏差が$\frac{1}{\sqrt{n}}$である初期値のことです。標準偏差が1の乱数に対して、任意の値を掛けることで標準偏差をその値に変更できます。詳しくは1巻の6.2節を参照してください。
また、Time LSTMレイヤのパラメータは、4つのパラメータを結合したものです(6.3.0項)。
# 中間層のニューロン数を指定 wordvec_size = 100 hidden_size = 100 # Time Embedレイヤのパラメータを生成 embed_W = (np.random.randn(vocab_size, wordvec_size) / 100) # Time LSTMレイヤのパラメータを生成 lstm_Wx = (np.random.randn(wordvec_size, 4 * hidden_size) / np.sqrt(wordvec_size)) lstm_Wh = (np.random.randn(hidden_size, 4 * hidden_size) / np.sqrt(hidden_size)) lstm_b = np.zeros(4 * hidden_size) # Time Affineレイヤのパラメータを生成 affine_W = (np.random.randn(hidden_size, vocab_size) / np.sqrt(vocab_size)) affine_b = np.zeros(vocab_size)
これで学習に用いる変数を作成できました。
次は、各レイヤのインスタンスを作成して、layersに格納ます。ただしTime Sofmax with Lossレイヤに関しては、他のレイヤと処理が異なるため分けておきます。
# RNNレイヤのインスタンスを格納 layers = [ TimeEmbedding(embed_W), TimeLSTM(lstm_Wx, lstm_Wh, lstm_b), TimeAffine(affine_W, affine_b) ] # lossレイヤのインスタンスを作成 loss_layer = TimeSoftmaxWithLoss()
各レイヤが持つパラメータと勾配をコピーして、それぞれリストに格納しておきます。
# 全てのパラメータと勾配をリストに格納 params = [] # パラメータ grads = [] # 勾配 for layer in layers: params += layer.params grads += layer.grads print(len(params)) print(len(grads))
6
6
これでモデルの用意が整いました。
・順伝播の処理
モデルを構築できたので、推論処理を行います。各レイヤの順伝播メソッドを順番に実行して、スコアを計算します。
# ミニバッチを取得 xs = batch_x # スコアの計算 for layer in layers: xs = layer.forward(xs) print(np.round(xs[:, 0, :], 3)) print(xs.shape)
[[-0. -0. 0. ... 0. 0. 0. ]
[-0. -0. -0.001 ... 0. -0. 0. ]
[-0. 0. 0. ... -0. -0. -0. ]
...
[-0. 0. -0. ... 0. -0. -0. ]
[ 0. 0. -0. ... -0. -0. -0. ]
[-0. 0. 0. ... 0. -0. -0. ]]
(20, 35, 10000)
スコアとは、Time Affineレイヤの出力データです。それぞれ3次元方向に並ぶ要素の内、最大値のインデックスが予測単語のIDなのでした。ここまでが推論処理です。
推論結果を確認してみましょう。softmax()を使って値を正規化してみます。
# 正規化 print(np.round(softmax(xs[:, 0, :]), 5))
[[0.0001 0.0001 0.0001 ... 0.0001 0.0001 0.0001]
[0.0001 0.0001 0.0001 ... 0.0001 0.0001 0.0001]
[0.0001 0.0001 0.0001 ... 0.0001 0.0001 0.0001]
...
[0.0001 0.0001 0.0001 ... 0.0001 0.0001 0.0001]
[0.0001 0.0001 0.0001 ... 0.0001 0.0001 0.0001]
[0.0001 0.0001 0.0001 ... 0.0001 0.0001 0.0001]]
1万種類の単語に対して、次の単語である確率を割り当てているので、多くの要素の値が0に近くなっています。
正規化(確率に変換)しなくてもスコアが最大の要素が予測結果なのでした。np.argmax()を使って、スコアが最大の要素のインデックスを抽出します。
# 予測結果を確認 print(np.argmax(xs[:, 0, :], axis=1)) # 単語ID print([id_to_word[id] for id in np.argmax(xs[:, 0, :], axis=1)]) # 単語
[ 122 467 3077 3790 1284 2004 6332 7653 8191 1050 7836 9968 7099 2295
3790 3077 5568 173 1968 5562]
['medicine', 'or', 'witnesses', 'programming', 'negotiators', 'suspect', 'alert', 'inflows', 'skeptics', 'september', 'quist', 'fossett', "o'kicki", 'stockholm', 'programming', 'witnesses', 'threatens', 'harvard', 'change', 'blue-chip']
学習を行っていないので、重みの初期値に依存したでたらめな結果です。
では話戻って、Time Sofmax with Lossレイヤの順伝播メソッド実行して、損失(交差エントロピー誤差)を計算します。
# ミニバッチを取得 ts = batch_t # 損失を計算 loss = loss_layer.forward(xs, ts) print(np.round(loss, 2))
9.21
RNNLMの出力(損失)が求まりました。ここでは学習を行っていないので、損失は高い値をとります。ここまでが順伝播の処理です。
・逆伝播の処理
最後に、パラメータの更新に用いる各パラメータの勾配を求めます。逆伝播の入力は、$\frac{\partial L}{\partial L} = 1$です。layersに格納されている各レイヤのインスタンスを逆順に取り出して、逆伝播メソッドを実行します。
# 逆伝播の入力 dout = 1 # 後のレイヤから逆伝播を実行 dout = loss_layer.backward(dout) for layer in reversed(layers): dout = layer.backward(dout) print(dout)
None
Time Embedレイヤではそれ以降に伝播しないので、Time Embedクラスの逆伝播メソッドは値を返しません。よって最終的なdoutの中身はNoneになります。
各レイヤのパラメータと勾配は、そのレイヤのインスタンスのメンバ変数に保存されています。また参照コピーしているparamsとgradsからもアクセスできます。
# 確認 for i in range(len(params)): print(params[i].shape) print(grads[i].shape)
(10000, 100)
(10000, 100)
(100, 400)
(100, 400)
(100, 400)
(100, 400)
(400,)
(400,)
(100, 10000)
(100, 10000)
(10000,)
(10000,)
ここまでが逆伝播の処理です。学習時には、得られた各パラメータの勾配を用いて勾配法によりパラメータを更新します。
・実装
処理の確認ができたので、LSTMレイヤを用いた言語モデルをクラスとして実装します。
# RNNLMの実装 class Rnnlm: # 初期化メソッドの定義 def __init__(self, vocab_size=10000, wordvec_size=100, hidden_size=100): # 形状に関する値を取得 V, D, H = vocab_size, wordvec_size, hidden_size # パラメータを初期化 embed_W = (np.random.randn(V, D) / 100).astype('f') lstm_Wx = (np.random.randn(D, 4 * H) / np.sqrt(D)).astype('f') lstm_Wh = (np.random.randn(H, 4 * H) / np.sqrt(H)).astype('f') lstm_b = np.zeros(4 * H).astype('f') affine_W = (np.random.randn(H, V) / np.sqrt(H)).astype('f') affine_b = np.zeros(V).astype('f') # レイヤを作成 self.layers = [ TimeEmbedding(embed_W), TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True), TimeAffine(affine_W, affine_b) ] self.loss_layer = TimeSoftmaxWithLoss() self.lstm_layer = self.layers[1] # パラメータと勾配を書くの self.params = [] # パラメータ self.grads = [] # 勾配 for layer in self.layers: self.params += layer.params self.grads += layer.grads # 推論メソッドの定義 def predict(self, xs): # 各レイヤの順伝播を計算 for layer in self.layers: xs = layer.forward(xs) return xs # 順伝播メソッドの定義 def forward(self, xs, ts): # スコアを計算 score = self.predict(xs) # 損失を計算 loss = self.loss_layer.forward(score, ts) return loss # 逆伝播メソッドの定義 def backward(self, dout=1): # 後のレイヤから逆伝播を計算 dout = self.loss_layer.backward(dout) for layer in reversed(self.layers): dout = layer.backward(dout) return dout # ネットワークの継続メソッドの定義 def reset_state(self): self.lstm_layer.reset_state() # 学習済みパラメータの保存メソッドの定義 def save_params(self, file_name='Rnnlm.pkl'): with open(file_name, 'rb') as f: # パラメータを保存 pickle.dump(self.params, f) # 学習済みパラメータの読み込みメソッドの定義 def load_params(self, file_name='Rnnlm.pkl'): with open(file_name, 'rb') as f: # パラメータを読み込む self.params = pickle.load(f)
実装したクラスを試してみましょう。RNNLMのインスタンスを作成して、推論メソッドを実行します。
# RNNLMのインスタンスを作成 model = Rnnlm(vocab_size, wordvec_size, hidden_size) # 推論 ss = model.predict(batch_x) print(np.round(ss[:, t, :], 3)) print(ss.shape)
[[ 0.005 0.003 0.001 ... 0.001 -0.001 0.001]
[-0.004 -0.004 0.007 ... -0.001 -0.003 0.008]
[ 0.003 -0.002 -0.005 ... 0.004 0.002 -0.004]
...
[-0.001 -0.005 -0.002 ... -0. 0.003 0.003]
[ 0.002 -0.004 0.001 ... 0.002 -0. -0.003]
[-0.003 0.001 -0.001 ... 0. -0.001 0.001]]
(20, 35, 10000)
スコアが出力されました。
予測結果を確認しましょう。スコアが最大のインデックスと正解ラベルを表示します。
# 予測した単語IDを表示 print(np.argmax(ss[batch_size-1], axis=1)) print(ts[batch_size-1])
[5802 1067 1260 1228 516 310 6548 3214 6678 1388 3214 3214 7531 7228
8445 8483 1601 8097 7690 1088 1931 1241 7528 6193 8494 3341 9952 2220
4749 6402 5002 2275 8445 7936 4245]
[ 467 1496 1047 360 1338 108 32 2836 42 32 26 1486 9054 24
563 2425 42 9852 134 668 9415 119 159 212 4307 64 4147 32
1367 753 24 78 119 176 2111]
学習を行っていないので、正解の単語を予測できていません。
続いて、順伝播メソッドを実行して損失を求めましょう。
# 順伝播(損失)を計算 loss = model.forward(batch_x, batch_t) print(loss)
9.210388532366071
当然交差エントロピー誤差も高くなります。
最後に、逆伝播を計算します。
# 逆伝播を計算 dout = model.backward() for grad in model.grads: print(grad.shape)
(10000, 100)
(100, 400)
(100, 400)
(400,)
(100, 10000)
(10000,)
以上でLSTMレイヤを用いたRNNLMを実装できました。次項では、このモデルを使って学習を行います。
6.4.2 LSTMを使った言語モデルの学習
前項で実装したLSTMレイヤを用いたRNNLMを使って学習を行います。ミニバッチの取得など「5.5.3項」も参照してください。
# 6.4節で利用するライブラリ import numpy as np import matplotlib.pyplot as plt
この例では、パラメータの更新にSGDを使います。
# 読み込み用の設定 import sys sys.path.append('C://Users//「ユーザー名」//Documents//・・・//deep-learning-from-scratch-2-master') # 実装済みのクラスと関数 from common.optimizer import SGD from ch06.rnnlm import Rnnlm
・データの作成
まずはPTBデータセットを読み込み、学習に用いるデータを作成します。
## データの作成 # データセットの読み込み関数 from dataset import ptb # データセットを読み込む corpus, word_to_id, id_to_word = ptb.load_data('train') # 訓練データ corpus_test, _, _ = ptb.load_data('test') # テストデータ # 使用するデータ数を指定 corpus_size = 5000 # データを削減 corpus = corpus[:corpus_size] # 語彙数を取得 vocab_size = int(max(corpus) + 1) print(vocab_size)
1326
(私のマシンスペックの問題でこの例ではデータ数を減らします、、)
RNNでは、単語を順番に入力していき、入力した次の単語を予測するのでした。なのでcorpusから、最後の単語を除いたものが入力データ$\mathbf{xs}$、最初の単語を除いたものが教師ラベル$\mathbf{ts}$となります。
# 入力データとして用いる(最後以外)データを取得 data_x = corpus[:-1] # 教師ラベルとして用いる(最初以外)データを取得 data_t = corpus[1:] # データ数を取得 data_size = len(data_x) print(data_size)
4999
バッチサイズと時間サイズを指定します。また1エポックにおけるミニバッチあたりの試行回数を計算します。
# 入力データのサイズを指定 batch_size = 20 time_size = 35 # ミニバッチあたりの試行回数を計算 max_iters = data_size // (batch_size * time_size) print(max_iters)
7
(学習中は1エポックごとにパープレキシティを表示するので、この値が大きいと何も表示されない不安な時間が長くなります。)
以上で入力データを作成できました。続いて学習を行います。
・学習処理
LSTMレイヤを用いたRNNLMのインスタンスを作成します。
# 中間層のニューロン数を指定 wordvec_size = 100 hidden_size = 100 # モデルのインスタンスを作成 model = Rnnlm(vocab_size, wordvec_size, hidden_size)
学習率を指定して、最適化手法のインスタンスを作成します。この例では、SGDを用います。
# 学習率 lr = 0.1 # 最適化手法のインスタンスを作成 optimizer = SGD(lr)
エポックあたりの試行回数を指定して、学習を行います。学習処理については、5.5.3項のときと同じです。
## 学習 max_epoch = 1000 # 学習処理に用いる変数を初期化 time_idx = 0 total_loss = 0 loss_count = 0 ppl_list = [] # エポックごとに学習 for epoch in range(max_epoch): for iter in range(max_iters): # ミニバッチを取得 batch_x = np.empty((batch_size, time_size), dtype='i') batch_t = np.empty((batch_size, time_size), dtype='i') for t in range(time_size): for i, offset in enumerate(offsets): batch_x[i, t] = data_x[(offset + time_idx) % data_size] batch_t[i, t] = data_t[(offset + time_idx) % data_size] time_idx += 1 # カウント # 損失を計算 loss = model.forward(batch_x, batch_t) # 勾配を計算 model.backward() # パラメータを更新 optimizer.update(model.params, model.grads) # 平均損失計算用に加算 total_loss += loss loss_count += 1 # パープレキシティを計算 ppl = np.exp(total_loss / loss_count) print( '| eploch ' + str(epoch + 1) + ' | perplexity: ' + str(np.round(ppl, 2)) ) ppl_list.append(float(ppl)) # 結果を記録 total_loss, loss_count = 0, 0 # カウントを初期化
| eploch 1 | perplexity: 1319.24
| eploch 2 | perplexity: 1304.09
| eploch 3 | perplexity: 1288.8
| eploch 4 | perplexity: 1274.68
| eploch 5 | perplexity: 1259.5
(省略)
| eploch 996 | perplexity: 143.2
| eploch 997 | perplexity: 141.6
| eploch 998 | perplexity: 141.58
| eploch 999 | perplexity: 136.79
| eploch 1000 | perplexity: 148.0
perplexityが徐々に下がっているのが数値から確認できます。
結果をグラフでも確認しましょう。
# 作図 plt.plot(np.arange(1, len(ppl_list) + 1), ppl_list) plt.title('Simple RNNLM', fontsize=20) plt.xlabel('epoch') plt.ylabel('perplexity') plt.show()
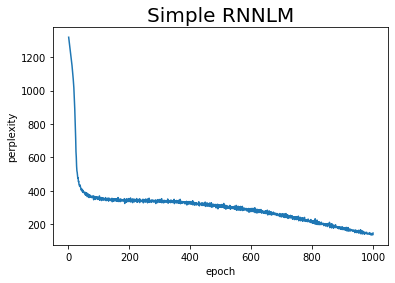
以上でLSTMレイヤを用いたRNNLMの学習を行えました。RnnlmTrainerクラスを用いた学習処理については、5.5.4項と同じなので省略します。次節では、さらに精度を高めるための手法を説明します。
参考文献

おわりに
これで6章のメインの話は完了です。次でもう1段階踏み込むための内容をさらっと確認しますが、まぁおまけみたいなものです。
あ、PTBデータを2回読み込んでるのは、記事を分けるつもりだったからです。ところでテストデータはいつ使うんでしょうね?
【次節の内容】