はじめに
『パターン認識と機械学習』の独学時のまとめです。一連の記事は「数式の行間埋め」または「R・Pythonでのスクラッチ実装」からアルゴリズムの理解を補助することを目的としています。本とあわせて読んでください。
また、機械学習で登場する確率分布について色々な角度から理解したいシリーズです。
この記事では、R言語で固有ベクトルによるガウス分布(正規分布)の回転を可視化します。
【前の内容】
【数式読解編】
【他の記事一覧】
【この記事の内容】
分散共分散行列の固有ベクトルによる分布の回転の可視化
分散共分散行列(Variance–Covariance Matrix)の固有ベクトル(Eigenvector)により回転した多次元ガウス分布(Maltivariate Gaussian Distribution)・多変量正規分布(Maltivariate Normal Distribution)を計算します。
利用するパッケージを読み込みます。
# 利用パッケージ library(tidyverse) library(mvnfast) library(patchwork)
この記事では、基本的にパッケージ名::関数名()の記法を使うので、パッケージを読み込む必要はありません。ただし、作図コードがごちゃごちゃしないようにパッケージ名を省略しているため、ggplot2は読み込む必要があります。
また、patchworkパッケージの演算子を使うため、patchworkも読み込む必要があります。
magrittrパッケージのパイプ演算子%>%ではなく、ベースパイプ(ネイティブパイプ)演算子|>を使っています。%>%に置き換えても処理できます。
分布の変化をアニメーション(gif画像)で確認するのにgganimateパッケージを利用します。不要であれば省略してください。
ガウス分布の設定
まずは、2次元ガウス分布を設定してグラフを作成します。ガウス分布の乱数を使いますが、固有ベクトルによる回転を理解するためのもので、回転自体には不要です。軸の計算やグラフ作成については「【R】2次元ガウス分布の作図 - からっぽのしょこ」、乱数生成については「多次元ガウス分布の乱数生成」を参照してください。
ガウス分布のパラメータ$\boldsymbol{\mu}, \boldsymbol{\Sigma}$とサンプルサイズ$N$を設定します。この例では、2次元のグラフで可視化するため、次元数を$D = 2$とします。分布の回転の計算自体は次元数に関わらず行えます。
# 次元数を指定 D <- 2 # 平均ベクトルを指定 mu_d <- c(-4, 2) # 分散共分散行列を指定 sigma_dd <- matrix(c(2, -0.6, -0.6, 1.5), nrow = D, ncol = D) # データ数(サンプルサイズ)を指定 N <- 10
平均ベクトル$\boldsymbol{\mu} = (\mu_1, \mu_2)^{\top}$、分散共分散行列$\boldsymbol{\Sigma} = (\sigma_1^2, \sigma_{2,1}, \sigma_{1,2}, \sigma_2^2)$とデータ数(サンプルサイズ)$N$を指定します。
平均$\mu_d$は実数、分散$\sigma_d^2$は正の実数、共分散$\sigma_{i,j} = \sigma_{j,i}$は実数、また$\boldsymbol{\Sigma}$は正定値行列を満たす必要があります。
分散共分散行列の固有値と固有ベクトルを計算します。
# 固有値と固有ベクトルを計算 res_eigen <- eigen(sigma_dd) # 固有値を取得 lambda_d <- res_eigen[["values"]] # 固有ベクトルを取得 u_dd <- res_eigen[["vectors"]] |> t() lambda_d; u_dd
## [1] 2.4 1.1 ## [,1] [,2] ## [1,] -0.8320503 0.5547002 ## [2,] -0.5547002 -0.8320503
$i = 1, 2$の固有値$\lambda_i$と固有ベクトル$\mathbf{u}_i = (u_{i,1}, u_{i,2})^{\top}$をeigen()で計算します。2個の固有値をまとめたベクトルと、2個の固有ベクトルをそれぞれ列とするマトリクスを格納したリストが出力されます。
"values"で固有値(をまとめたベクトル)、"vectors"で固有ベクトル(をまとめたマトリクス)を取り出して、数式での成分$\mathbf{U} = (u_{1,1}, u_{2,1}, u_{1,2}, u_{2,2})$と合わせるために転置しておきます。
設定したパラメータに応じて、ガウス分布の確率変数の値$\mathbf{x}$を作成して、確率密度を計算します。
# xの値を作成 x_1_vals <- seq( from = mu_d[1] - sqrt(sigma_dd[1, 1]) * 3, to = mu_d[1] + sqrt(sigma_dd[1, 1]) * 3, length.out = 100 ) x_2_vals <- seq( from = mu_d[2] - sqrt(sigma_dd[2, 2]) * 3, to = mu_d[2] + sqrt(sigma_dd[2, 2]) * 3, length.out = 100 ) # xの点を作成 x_mat <- tidyr::expand_grid( x_1 = x_1_vals, x_2 = x_2_vals ) |> # 格子点を作成 as.matrix() # マトリクスに変換 # 多次元ガウス分布を計算 dens_x_df <- tibble::tibble( x_1 = x_mat[, 1], # x軸の値 x_2 = x_mat[, 2], # y軸の値 density = mvnfast::dmvn(X = x_mat, mu = mu_d, sigma = sigma_dd) # 確率密度 ) dens_x_df
## # A tibble: 10,000 × 3 ## x_1 x_2 density ## <dbl> <dbl> <dbl> ## 1 -8.24 -1.67 0.000000103 ## 2 -8.24 -1.60 0.000000135 ## 3 -8.24 -1.53 0.000000177 ## 4 -8.24 -1.45 0.000000232 ## 5 -8.24 -1.38 0.000000302 ## 6 -8.24 -1.30 0.000000391 ## 7 -8.24 -1.23 0.000000505 ## 8 -8.24 -1.15 0.000000649 ## 9 -8.24 -1.08 0.000000830 ## 10 -8.24 -1.01 0.00000106 ## # … with 9,990 more rows
$x_1$(x軸)の値をx_1_vals、$x_2$(y軸)の値をx_2_valsとします。この例では、それぞれ平均を中心に標準偏差の3倍を範囲とします。
x_1_valsとx_2_valsの要素の全ての組み合わせ(格子状の点)をexpand_grid()で作成します。データフレームが出力されるので、as.matrix()でマトリクスに変換してx_matとします。x_matの各行が点$\mathbf{x} = (x_1, x_2)^{\top}$に対応します。
多次元ガウス分布の確率密度は、mvnfastパッケージのdmvn()で計算できます。確率変数の引数Xにx_mat、平均の引数muにmu_d、共分散の引数sigmaにsigma_ddを指定します。
ガウス分布の乱数を生成します。
# 多次元ガウス分布に従う乱数を生成 x_nd <- mvnfast::rmvn(n = N, mu = mu_d, sigma = sigma_dd) # サンプルを格納 data_x_df <- tibble::tibble( n = factor(1:N), # データ番号 x_1 = x_nd[, 1], # x軸の値 x_2 = x_nd[, 2] # y軸の値 ) data_x_df
## # A tibble: 10 × 3 ## n x_1 x_2 ## <fct> <dbl> <dbl> ## 1 1 -6.05 1.47 ## 2 2 -5.01 3.68 ## 3 3 -3.97 1.63 ## 4 4 -4.39 2.00 ## 5 5 -0.953 1.48 ## 6 6 -4.09 0.877 ## 7 7 -4.34 1.52 ## 8 8 -3.80 0.739 ## 9 9 -5.28 2.73 ## 10 10 -7.72 2.27
多次元ガウス分布の乱数は、rmvn()で生成できます。データ数の引数nにN、平均の引数muにmu_d、分散共分散行列の引数sigmaにsigma_ddを指定します。
生成した値x_ndの各行を$n = 1, 2, \dots, N$の$N$個のサンプル$\mathbf{x}_n = (x_{n,1}, x_{n,2})^{\top}$とします。
ガウス分布の断面図(楕円)の軸を計算します。
# 断面図の軸を計算 axis_x_df <- tibble::tibble( xstart = mu_d[1] - u_dd[, 1] * sqrt(lambda_d), ystart = mu_d[2] - u_dd[, 2] * sqrt(lambda_d), xend = mu_d[1] + u_dd[, 1] * sqrt(lambda_d), yend = mu_d[2] + u_dd[, 2] * sqrt(lambda_d) ) axis_x_df
## # A tibble: 2 × 4 ## xstart ystart xend yend ## <dbl> <dbl> <dbl> <dbl> ## 1 -2.71 1.14 -5.29 2.86 ## 2 -3.42 2.87 -4.58 1.13
軸番号を$i$、次元を$j$として、始点は$\mu_i - u_{j,i} \sqrt{\lambda_j}$、終点は$\mu_i + u_{j,i} \sqrt{\lambda_j}$で計算できます。$i = 1$がx軸、$i = 2$がy軸に対応します。
ガウス分布のグラフを作成します。
# パラメータラベルを作成:(数式表記用) param_x_text <- paste0( "list(", "mu==group('(', list(", paste0(mu_d, collapse = ", "), "), ')')", ", Sigma==group('(', list(", paste0(sigma_dd, collapse = ", "), "), ')')", ")" ) # 確率密度の最大値を計算 max_dens <- mvnfast::dmvn(X = mu_d, mu = mu_d, sigma = sigma_dd) # 2次元ガウス分布のグラフを作成 dens_x_graph <- ggplot() + geom_contour_filled(data = dens_x_df, mapping = aes(x = x_1, y = x_2, z = density, fill = ..level..), alpha = 0.8) + # 分布 geom_contour(data = dens_x_df, mapping = aes(x = x_1, y = x_2, z = density), breaks = max_dens*exp(-0.5), color = "red", size = 1, linetype = "dashed") + # 分布の断面図 geom_segment(data = axis_x_df, mapping = aes(x = xstart, y = ystart, xend = xend, yend = yend), color = "blue", size = 1, arrow = arrow(length = unit(10, "pt"))) + # 断面図の軸 geom_point(data = data_x_df, mapping = aes(x = x_1, y = x_2, color = n), alpha = 0.8, size = 5, show.legend = FALSE) + # サンプル coord_fixed(ratio = 1) + # アスペクト比 labs(title ="Maltivariate Gaussian Distribution", subtitle = parse(text = param_x_text), fill = "density", x = expression(x[1]), y = expression(x[2])) dens_x_graph
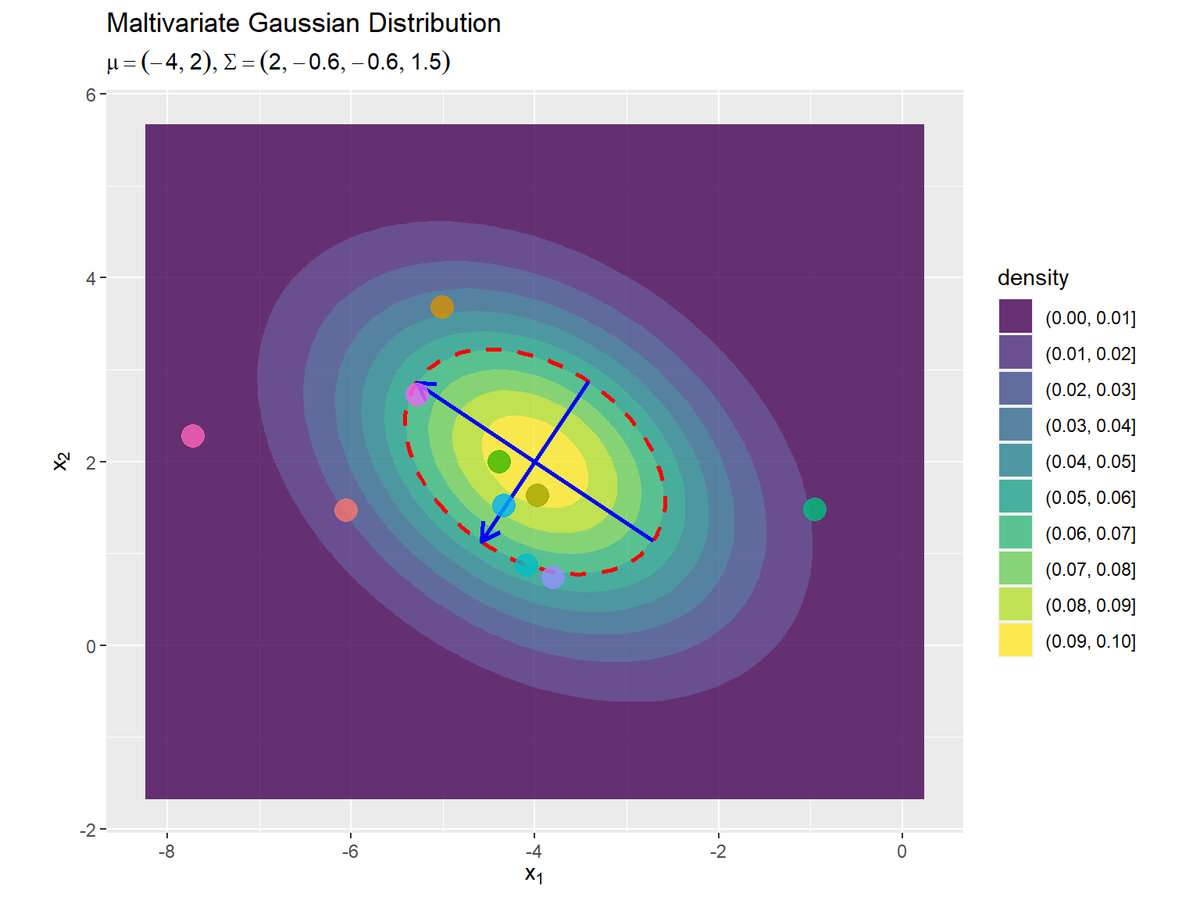
geom_contour()のbreaks引数に値を指定すると、その値で等高線を引きます。この例では、確率密度の最大値の$\exp(-\frac{1}{2})$倍を指定します。z軸(確率密度)がこの値の面で切断すると断面図(等高線)が軸の先端になります。
geom_segment()で断面図の軸を描画します。
この分布の断面図の2つの軸が、それぞれx軸とy軸になるように分布とサンプルを回転します。
回転後の分布を計算
平均値が0になるように並行移動し、分散共分散行列の固有ベクトルを用いて回転したガウス分布を計算します。固有ベクトルについては「2.3.0:分散共分散行列と固有値・固有ベクトルの関係の導出【PRMLのノート】 - からっぽのしょこ」、固有ベクトルによる回転については「2.3.0:分散共分散行列の固有ベクトルによる分布の回転の導出 - からっぽのしょこ」を参照してください。
回転後のガウス分布のパラメータを計算します。
# 平均ベクトルを作成 mu_y_d <- rep(0, times = D) # 分散共分散行列を計算 lambda_dd <- diag(lambda_d) lambda_dd
## [,1] [,2] ## [1,] 2.4 0.0 ## [2,] 0.0 1.1
全ての次元(軸)の平均が0になるように並行移動するため、平均ベクトルの全ての要素が0になります。
分散共分散行列は固有値を対角成分とする対角行列になります。diag()にベクトルを渡すと、ベクトルの要素を対角成分とする対角行列を作成します。
回転後のガウス分布の確率変数の値$\mathbf{y}$を作成して、確率密度を計算します。
# yの値を作成 y_1_vals <- seq( from = -sqrt(lambda_dd[1, 1]) * 3, to = sqrt(lambda_dd[1, 1]) * 3, length.out = 100 ) y_2_vals <- seq( from = -sqrt(lambda_dd[2, 2]) * 3, to = sqrt(lambda_dd[2, 2]) * 3, length.out = 100 ) # yの点を作成 y_mat <- tidyr::expand_grid( y_1 = y_1_vals, y_2 = y_2_vals ) |> # 格子点を作成 as.matrix() # マトリクスに変換 # 多次元ガウス分布を計算 dens_y_df <- tibble::tibble( y_1 = y_mat[, 1], # x軸の値 y_2 = y_mat[, 2], # y軸の値 density = mvnfast::dmvn(X = y_mat, mu = mu_y_d, sigma = lambda_dd) # 確率密度 ) dens_y_df
## # A tibble: 10,000 × 3 ## y_1 y_2 density ## <dbl> <dbl> <dbl> ## 1 -4.65 -3.15 0.0000121 ## 2 -4.65 -3.08 0.0000145 ## 3 -4.65 -3.02 0.0000173 ## 4 -4.65 -2.96 0.0000205 ## 5 -4.65 -2.89 0.0000243 ## 6 -4.65 -2.83 0.0000287 ## 7 -4.65 -2.77 0.0000337 ## 8 -4.65 -2.70 0.0000394 ## 9 -4.65 -2.64 0.0000460 ## 10 -4.65 -2.57 0.0000535 ## # … with 9,990 more rows
元の分布のときと同様に、$y_1$(x軸)の値と$y_2$(y軸)の値を作成して、格子状の点y_matを作成します。y_matの各行が点$\mathbf{y} = (y_1, y_2)^{\top}$に対応します。
dmvn()のX引数にy_mat、mu引数にmu_y_d、sigma引数にlambda_ddを指定して、各点の確率密度を計算します。
サンプルを並行移動して回転します。
# サンプルを回転 y_nd <- t(t(x_nd) - mu_d) %*% t(u_dd) # 回転したサンプルを格納 data_y_df <- tibble::tibble( n = factor(1:N), y_1 = y_nd[, 1], y_2 = y_nd[, 2] ) data_y_df
## # A tibble: 10 × 3 ## n y_1 y_2 ## <fct> <dbl> <dbl> ## 1 1 1.41 1.58 ## 2 2 1.77 -0.843 ## 3 3 -0.232 0.293 ## 4 4 0.321 0.216 ## 5 5 -2.82 -1.26 ## 6 6 -0.547 0.984 ## 7 7 0.0162 0.583 ## 8 8 -0.863 0.940 ## 9 9 1.47 0.108 ## 10 10 3.25 1.84
各サンプル$\mathbf{x}_n$から平均値$\boldsymbol{\mu}$を引いて、x軸方向に$-\mu_1$、y軸方向に$-\mu_2$移動します。座標を並行移動した値$(x_1 - \mu_1, x_2 - \mu_2)$に$\mathbf{U}^{\top}$を掛けて回転します。x_ndの各行からmu_dを引くために、適宜転置して計算します。
回転後の分布の軸を計算するために、固有ベクトルを回転します。
# 固有ベクトルを回転 u_y_dd <- u_dd %*% t(u_dd) u_y_dd
## [,1] [,2] ## [1,] 1 0 ## [2,] 0 1
$\mathbf{U}$に$\mathbf{U}^{\top}$を掛けて回転します。$\mathbf{U} \mathbf{U}^{\top}$は単位行列$\mathbf{I}$になります。
回転した固有ベクトルを使って、回転後の分布の断面図の軸を計算します。
# 断面図の軸を計算 axis_y_df <- tibble::tibble( xstart = - u_y_dd[, 1] * sqrt(lambda_d), ystart = - u_y_dd[, 2] * sqrt(lambda_d), xend = u_y_dd[, 1] * sqrt(lambda_d), yend = u_y_dd[, 2] * sqrt(lambda_d) ) axis_y_df
## # A tibble: 2 × 4 ## xstart ystart xend yend ## <dbl> <dbl> <dbl> <dbl> ## 1 -1.55 0 1.55 0 ## 2 0 -1.05 0 1.05
回転後の分布の平均は全ての次元で0なので、始点は$- u_{j,i} \sqrt{\lambda_j}$、終点は$u_{j,i} \sqrt{\lambda_j}$で計算できます。ただし、$u_{j,i}$は回転後の値です。
回転後のガウス分布のグラフを作成します。
# パラメータラベルを作成:(数式表記用) param_y_text <- paste0( "list(", "mu[y]==group('(', list(", paste0(round(mu_y_d, 2), collapse = ", "), "), ')')", ", Lambda[y]==group('(', list(", paste0(round(lambda_dd, 2), collapse = ", "), "), ')')", ")" ) # 回転後の2次元ガウス分布のグラフを作成 dens_y_graph <- ggplot() + geom_contour_filled(data = dens_y_df, mapping = aes(x = y_1, y = y_2, z = density, fill = ..level..), alpha = 0.8) + # 塗りつぶし等高線 geom_contour(data = dens_y_df, mapping = aes(x = y_1, y = y_2, z = density), breaks = max_dens*exp(-0.5), color = "red", size = 1, linetype = "dashed") + # 分布の断面図 geom_segment(data = axis_y_df, mapping = aes(x = xstart, y = ystart, xend = xend, yend = yend), color = "blue", size = 1, arrow = arrow(length = unit(10, "pt"))) + # 断面図の軸 geom_point(data = data_y_df, mapping = aes(x = y_1, y = y_2, color = n), alpha = 0.8, size = 5, show.legend = FALSE) + coord_fixed(ratio = 1) + # アスペクト比 labs(title ="Maltivariate Gaussian Distribution", subtitle = parse(text = param_y_text), fill = "density", x = expression(y[1]), y = expression(y[2])) dens_y_graph
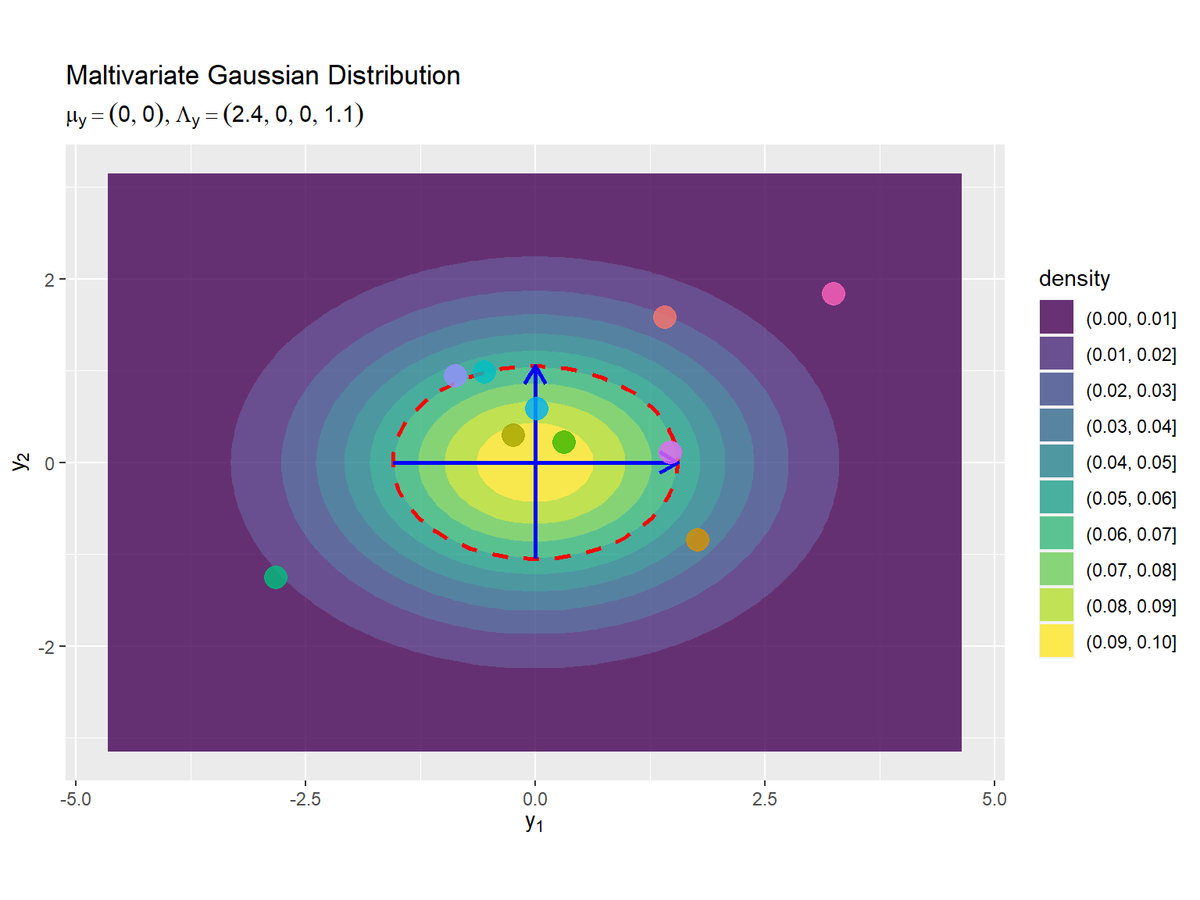
元の分布のときと同様にして作図します。
回転前の分布と回転後の分布を並べて描画します。
# グラフを並べて描画 dens_x_graph + dens_y_graph
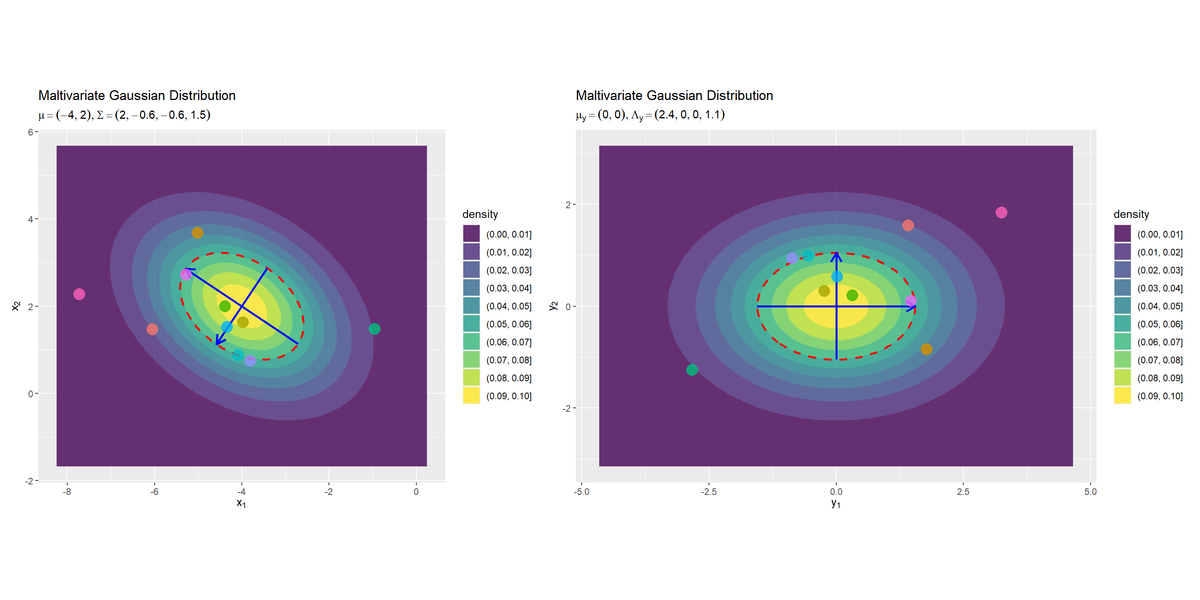
patchworkパッケージの+演算子を使うと左右に並べて描画できます。
元の分布$\mathcal{N}(\mathbf{y} | \boldsymbol{\mu}, \boldsymbol{\Sigma})$の軸が回転後の分布$\mathcal{N}(\mathbf{y} | \mathbf{0}, \boldsymbol{\Lambda})$の軸と対応しており、回転後の軸がx軸($y_1$軸)とy軸($y_2$軸)と並行なのが分かります。また、元の分布のサンプルも軸に対応するように回転しているのが分かります。
固有ベクトルによる分布の回転
次は、回転後の分布を直接計算するのではなく、元の分布に固有ベクトルの行列を掛けて回転します。
元の分布の計算・作図用の点$\mathbf{x}$を並行移動して回転します。
# xの点を回転 x_to_y_mat <- t(t(x_mat) - mu_d) %*% t(u_dd) head(x_to_y_mat)
## [,1] [,2] ## [1,] 1.491992 5.410542 ## [2,] 1.533165 5.348781 ## [3,] 1.574339 5.287020 ## [4,] 1.615513 5.225260 ## [5,] 1.656687 5.163499 ## [6,] 1.697860 5.101739
サンプルの回転のときと同様に、$\mathbf{x}$から$\boldsymbol{\mu}$を引き、各次元の平均が0になるように並行移動して、$\mathbf{U}^{\top}$を掛けて回転します。
回転後の分布の作図用の点$\mathbf{y}$を作成します。
# yの値を作成 y_1_vals <- seq(from = min(x_to_y_mat[, 1]), to = max(x_to_y_mat[, 1]), length.out = 100) y_2_vals <- seq(from = min(x_to_y_mat[, 2]), to = max(x_to_y_mat[, 2]), length.out = 100) # yの点を作成 y_mat <- tidyr::expand_grid( y_1 = y_1_vals, y_2 = y_2_vals ) |> # 格子点を作成 as.matrix() # マトリクスに変換 head(y_mat)
## y_1 y_2 ## [1,] -5.568189 -5.410542 ## [2,] -5.568189 -5.301238 ## [3,] -5.568189 -5.191934 ## [4,] -5.568189 -5.082630 ## [5,] -5.568189 -4.973326 ## [6,] -5.568189 -4.864022
等高線の作図には、格子点を用意する必要があります。そこで、x_matを回転したx_to_y_matの最小値と最大値を使って、回転後の座標の点$\mathbf{y} = (y_1, y_2)^{\top}$を作成します。
回転後の分布の計算用の点を作成します。
# yの点を回転 y_to_x_mat = y_mat %*% solve(t(u_dd)) head(y_to_x_mat)
回転前の分布のパラメータで確率密度を計算するため、$\mathbf{y}$に対応する回転前の座標の点を用意する必要があります。そこで、$\mathbf{y}$に$\mathbf{U}^{\top}$の逆行列を掛けて、元の座標の点に回転し(戻し)ます。ちなみに、$\mathbf{U}$は直交行列なので$(\mathbf{U}^{\top})^{-1} = \mathbf{U}$です。
回転後の分布を計算します。
# 多次元ガウス分布を計算 dens_y_df <- tibble::tibble( y_1 = y_mat[, 1], # x軸の値 y_2 = y_mat[, 2], # y軸の値 density = mvnfast::dmvn(X = y_to_x_mat, mu = rep(0,2), sigma = sigma_dd) # 確率密度 ) dens_y_df
## [,1] [,2] ## [1,] 7.634242 1.4131672 ## [2,] 7.573611 1.3222208 ## [3,] 7.512980 1.2312745 ## [4,] 7.452349 1.1403282 ## [5,] 7.391718 1.0493819 ## [6,] 7.331087 0.9584356
回転後の座標($y_1, y_2$軸座標)の値で作図するために、データフレームにy_matの値を格納します。そして、元の座標($x_1, x_2$軸座標)の値で計算するために、dmvn()のX引数にy_to_x_matを指定して確率密度を計算します。
サンプルを並行移動して回転します。
# サンプルを回転 y_nd <- t(t(x_nd) - mu_d) %*% t(u_dd) # 回転したサンプルを格納 data_y_df <- tibble::tibble( n = factor(1:N), y_1 = y_nd[, 1], y_2 = y_nd[, 2] ) data_y_df
## # A tibble: 10,000 × 3 ## y_1 y_2 density ## <dbl> <dbl> <dbl> ## 1 -5.57 -5.41 2.55e-10 ## 2 -5.57 -5.30 4.35e-10 ## 3 -5.57 -5.19 7.32e-10 ## 4 -5.57 -5.08 1.22e- 9 ## 5 -5.57 -4.97 2.01e- 9 ## 6 -5.57 -4.86 3.28e- 9 ## 7 -5.57 -4.75 5.28e- 9 ## 8 -5.57 -4.65 8.43e- 9 ## 9 -5.57 -4.54 1.33e- 8 ## 10 -5.57 -4.43 2.08e- 8 ## # … with 9,990 more rows
「回転後の分布の計算」のときと同じ処理です。
元の分布の軸を並行移動して回転します。
# 軸を計算 axis_y_df <- dplyr::bind_cols( value_1 = c(axis_x_df[["xstart"]], axis_x_df[["xend"]]) - mu_d[1], value_2 = c(axis_x_df[["ystart"]], axis_x_df[["yend"]]) - mu_d[2] ) |> as.matrix() |> (\(.){. %*% t(u_dd)})() |> as.vector() |> tibble::as_tibble() |> tibble::add_column( name = paste0(rep(c("x", "y"), each = 4), rep(c("start", "end"), each = 2, times = 2)), axis = rep(c("y_1", "y_2"), times = 4) ) |> tidyr::pivot_wider( id_cols = axis, names_from = name, values_from = value ) # 軸の視点・終点の列を分割 axis_y_df
## # A tibble: 10 × 3 ## n y_1 y_2 ## <fct> <dbl> <dbl> ## 1 1 1.41 1.58 ## 2 2 1.77 -0.843 ## 3 3 -0.232 0.293 ## 4 4 0.321 0.216 ## 5 5 -2.82 -1.26 ## 6 6 -0.547 0.984 ## 7 7 0.0162 0.583 ## 8 8 -0.863 0.940 ## 9 9 1.47 0.108 ## 10 10 3.25 1.84
2つの軸の始点と終点の8つの値を並行移動して回転します。
axis_x_dfのxstar, xend列が$x_1$軸(x軸)の値なのでmu_d[1]を引き、ystar, yend列が$x_2$軸(y軸)の値なのでmu_d[2]を引きます。
並行移動した値をas.matrix()で8行2列のマトリクスに変換して、t(u_dd)を掛けて回転したり、展開後の列名を作成したり、上手いこと処理します(誰かもっと上手く処理してください…)。
求めた値をpivot_wider()で列名と対応付けて分割します。
「回転後の分布の計算」の作図コードで、回転後の分布のグラフを作成します。
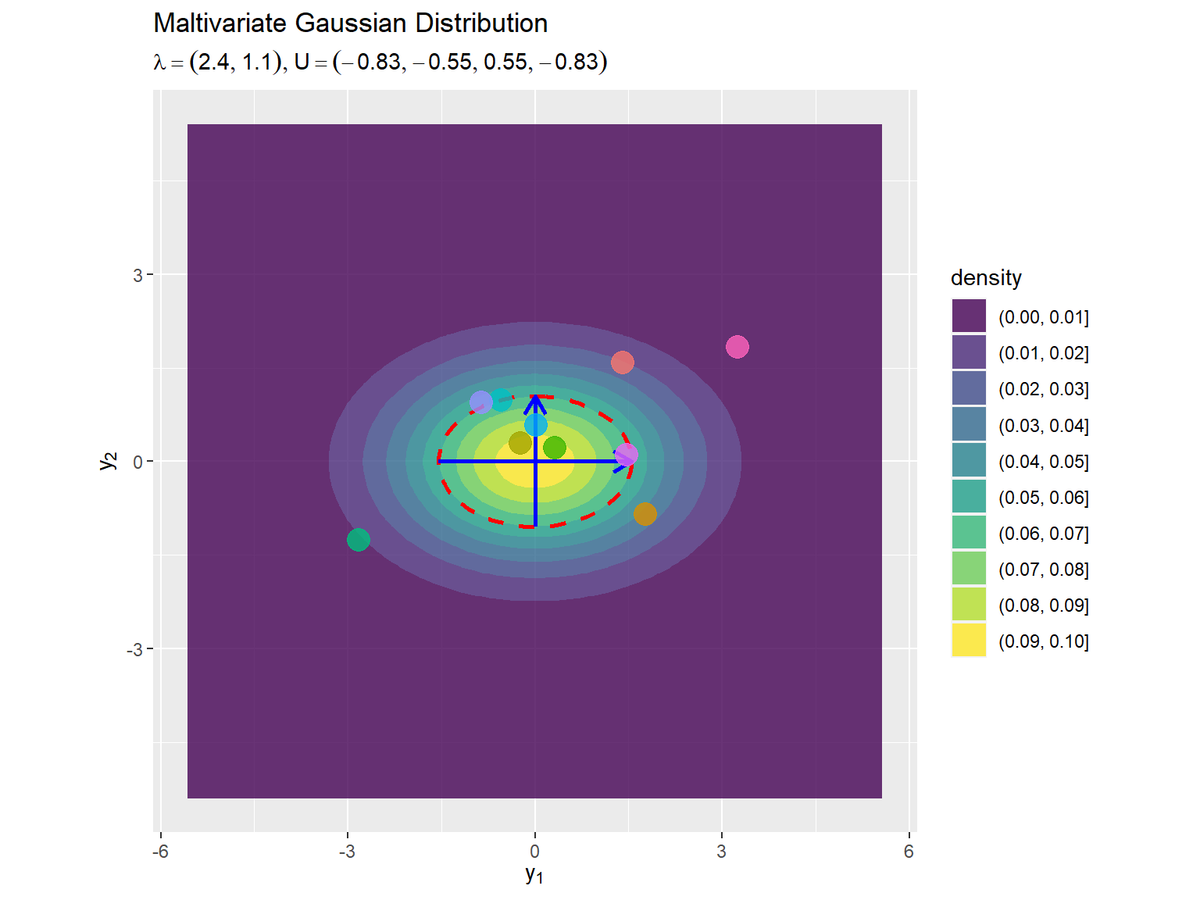
回転前の分布と回転後の分布を並べて描画します。
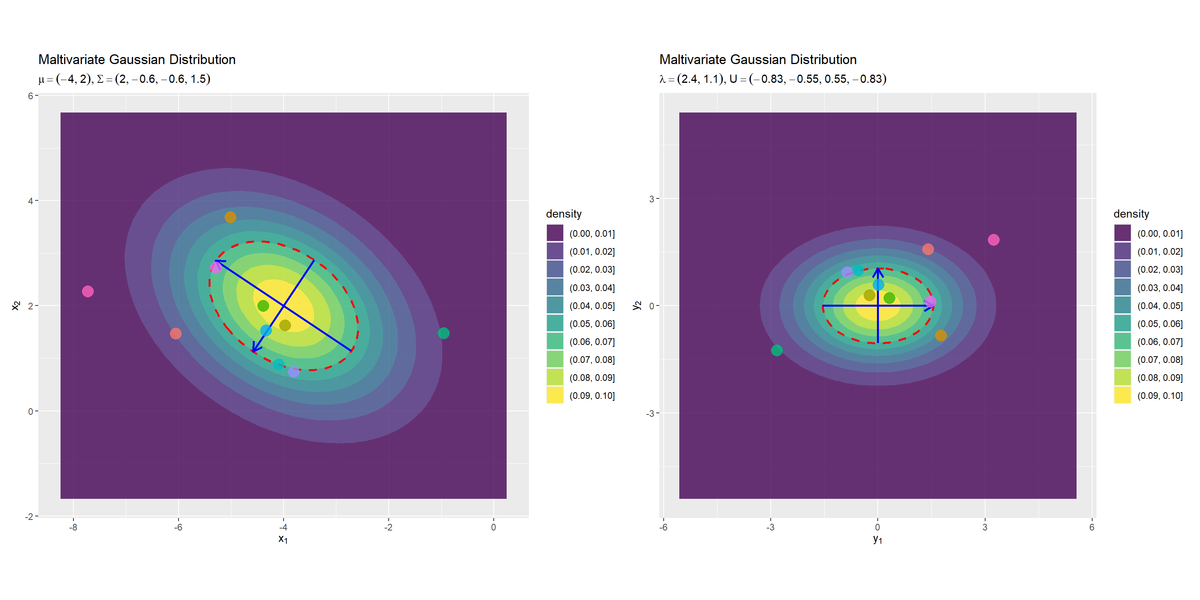
(描画範囲は異なりますが、)直接求めた回転後の分布と同じグラフになりました。
この記事では、分散共分散行列の固有ベクトルによる分布の回転を確認しました。
参考文献
- C.M.ビショップ著,元田 浩・他訳『パターン認識と機械学習 上』,丸善出版,2012年.
おわりに
数式を解いた後すぐに組んだのが面倒くさい方の処理で、何だか面倒だなと思って本を読み返してなるほどとなって組み直したのが直接的な方の処理です。もったいないので両方載せとくかと解説を書いてると、回転している感があった方が分かりやすいだろうし両方載せるのが正解だなと思いました。先に直接的な方を組んでたら面倒な方もやっただろうか。
ところで、回転って表現でいいんですよね?座標変換とは別物ですか?
固有ベクトルを勉強してたら線形代数やらなきゃからやりたいに気持ちが変わってきました。
【次の内容】