はじめに
『問題解決力を鍛える! アルゴリズムとデータ構造』の学習ノートです。
本に掲載されているコードや図をR言語で再現します。本と一緒に読んでください。
この記事は、12.3節「ソート(1):挿入ソート」の内容です。
挿入ソートのアルゴリズムを確認します。
【他の節の内容】
【この節の内容】
12.3 挿入ソートの実装と可視化
挿入ソート(insertion sort)を実装します。また、ソートの推移のアニメーションを作成して、アルゴリズムを確認します。
利用するパッケージを読み込みます。
# 利用パッケージ library(tidyverse) library(gganimate)
この記事では、基本的に パッケージ名::関数名() の記法を使っているので、パッケージを読み込む必要はありません。ただし、作図コードについてはパッケージ名を省略しているので、ggplot2 を読み込む必要があります。
また、ネイティブパイプ演算子 |> を使っています。magrittrパッケージのパイプ演算子 %>% に置き換えても処理できますが、その場合は magrittr を読み込む必要があります。
「ソートの可視化」において、gganimateパッケージを利用してアニメーション(gif画像)を作成します。「ソートの実装」自体には使いません。
ソートの実装
まずは、挿入ソートのアルゴリズムを関数として実装します。
挿入ソートを実装します。
# 挿入ソートの実装 insertion_sort <- function(vec) { # 数列の要素数を取得 N <- length(vec) # 要素ごとに処理 for(i in 2:N) { # (1番目は不要) # i番目の値を取得 val <- vec[i] # i番目から逆順に挿入位置jを探索:(j ≤ i) for(j in (i-1):0) { # (i番目は不要・0番目は挿入処理との兼ね合い用) # j番目とi番目の値を大小比較 if(j <= 0) { # 全要素を比較したらループを終了 break } else if(vec[j] > val) { # j番目の値を1つ後に移動 vec[j+1] <- vec[j] } else { # i番目の値以下ならループを終了 break } } # i番目の値をj番目に挿入 vec[j+1] <- val } # 数列を出力 return(vec) }
数列を vec、数列の要素数を N とします。
vec の 1 番目から N 番目まで(を i として)の要素を順番に入れ替えていきます。ただしアルゴリズム上、1番目の要素は入れ替えが行われないので、処理を省略します。
vec の i 番目の要素 vec[i] の入れ替えでは、i 番目から 1 番目まで(を j として)の要素を順番に大小比較します。ただしアルゴリズム上、i番目の要素は入れ替えが行われないので、処理を省略します。
i 番目の要素 vec[i] を val としておき、val と j 番目の要素 vec[j] を比較します。
j 番目の値が大きければ、j 番目の値を j+1 番目の値に複製します。この操作が、j番目の要素を1つ後に移動するのに対応します。ただしこの時点では、j番目とj+1番目が同じ値です。
j 番目の値が小さければ、break でループ処理を終了して、j+1 番目の要素を val で上書きします。この操作が、値の挿入に対応します。j+1番目の値は、1つ前の試行においてj+2番目に移動(複製)されています。
全ての要素が大きかった場合は、j を 0 にしておき、j+1 (1)番目の要素を val で上書きします。
アルゴリズムの詳しい解説は、本のcode 12.1などを参照してください。
実装した関数を試してみます。
要素数を指定して、数列を作成します。
# 要素数を指定 N <- 50 # 数列を生成 a <- sample(x = 1:(2*N), size = N, replace = TRUE) a
## [1] 55 37 63 47 48 96 93 18 3 3 27 24 55 77 44 43 13 68 5 6 94 55 28 13 84 ## [26] 96 29 53 92 39 3 14 20 42 40 47 79 67 72 31 29 52 58 41 49 79 76 65 12 73
乱数生成関数 sample() などで数値ベクトルを生成します。
挿入ソートにより並べ替えます。
# ソート insertion_sort(a)
## [1] 3 3 3 5 6 12 13 13 14 18 20 24 27 28 29 29 31 37 39 40 41 42 43 44 47 ## [26] 47 48 49 52 53 55 55 55 58 63 65 67 68 72 73 76 77 79 79 84 92 93 94 96 96
目で確認するのはアレなので、組み込み関数のソート結果と比較して確認します。
# 確認 sum(!(insertion_sort(a) == sort(a)))
## [1] 0
! で TRUE, FALSE を反転させて sum() で合計することで、一致しない要素数を得られます。結果が 0 であれば全ての要素が一致したことが分かります。
ソートの可視化
次は、挿入ソートのアルゴリズムをグラフで確認します。
数列の初期値を作成して、グラフで確認します。
・作図コード(クリックで展開)
要素数を指定して、数列を作成します。
# 要素数を指定 N <- 20 # 数列を生成 a <- rnorm(n = N, mean = 0, sd = 1) |> round(digits = 1) table(a)
## a ## -2.3 -1.2 -1.1 -1 -0.8 0 0.1 0.2 0.5 0.6 0.8 1.1 1.2 1.4 1.6 2.2 ## 1 1 1 2 1 2 1 1 3 1 1 1 1 1 1 1
この例では、(負の値を含めるため)正規乱数生成関数 rnorm() で値を生成して、(重複を含めるため)丸め込み関数 round() で小数第一位にしておきます。
数列をデータフレームに格納します。
# 要素数を取得 N <- length(a) # 数列を格納 tmp_df <- tibble::tibble( iteration = 0, # 試行回数 id = 1:N, # 元のインデックス index = 1:N, # 各試行のインデックス value = a # 要素 ) tmp_df
## # A tibble: 20 × 4 ## iteration id index value ## <dbl> <int> <int> <dbl> ## 1 0 1 1 -0.8 ## 2 0 2 2 0.5 ## 3 0 3 3 -1.2 ## 4 0 4 4 0.2 ## 5 0 5 5 1.4 ## 6 0 6 6 0 ## 7 0 7 7 0.5 ## 8 0 8 8 2.2 ## 9 0 9 9 1.1 ## 10 0 10 10 0.1 ## 11 0 11 11 0.8 ## 12 0 12 12 -1 ## 13 0 13 13 0.6 ## 14 0 14 14 1.6 ## 15 0 15 15 0 ## 16 0 16 16 -1.1 ## 17 0 17 17 1.2 ## 18 0 18 18 0.5 ## 19 0 19 19 -2.3 ## 20 0 20 20 -1
作図用に、インデックスなどの値とあわせて数列を格納します。数列のみが与えられている場合は、要素数を N とします。
数列を棒グラフで確認します。
# 数列を作図 ggplot() + geom_bar(data = tmp_df, mapping = aes(x = index, y = value, fill = factor(value)), stat = "identity") + theme(panel.grid.minor.x = element_blank()) + # 図の体裁 labs(title = "numerical sequence", subtitle = paste0("iteration: ", unique(tmp_df[["iteration"]])), fill = "value", x = "index", y = "value")
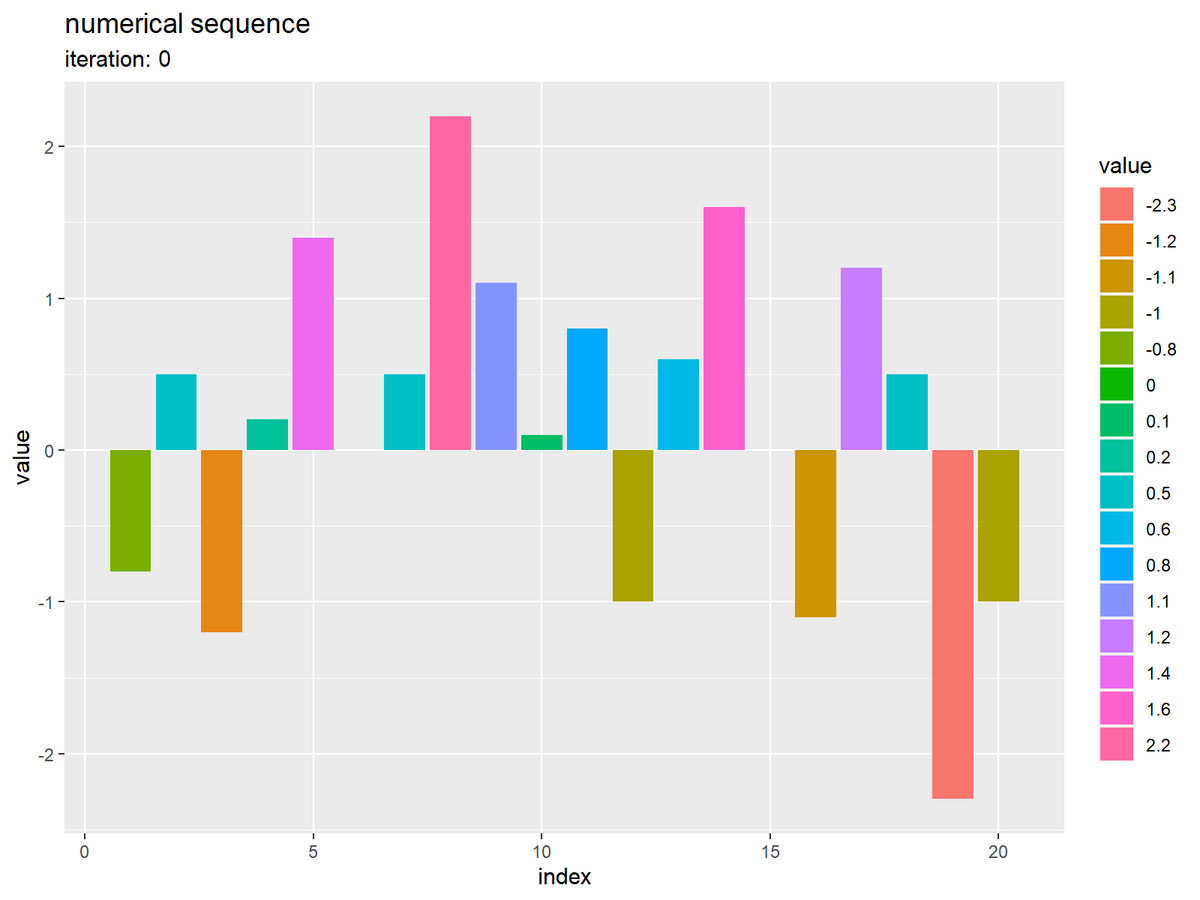
この要素(バー)を昇順に並べ替えます。
アルゴリズムに従いソートを行って、作図用のデータを作成します。
・作図コード(クリックで展開)
1データずつ入れ替え処理を行い、数列を記録します。
# 作図用のオブジェクトを初期化 id_vec <- 1:N trace_df <- tmp_df # 挿入ソート for(i in 1:N) { if(i > 1) { # (初回は不要) # i番目の値を取得 v <- a[i] # i番目から逆順に挿入位置jを探索:(j ≤ i) for(j in (i-1):0) { # (i番目は不要・0番目は挿入処理との兼ね合い用) # j番目とi番目の値を大小比較 if(j <= 0) { # 全要素を比較したらループを終了 break } else if(a[j] > v) { # j番目の値を1つ後に移動 a[j+1] <- a[j] id_vec[1:N] <- replace(x = id_vec, list = j+1, values = id_vec[j]) } else { # i番目の値以下ならループを終了 break } } # i番目の値をj番目に挿入 a[j+1] <- v id_vec[1:N] <- replace(x = id_vec, list = j+1, values = i) } # 数列を格納 tmp_df <- tibble::tibble( iteration = i, id = id_vec, index = 1:N, value = a ) # 数列を記録 trace_df <- dplyr::bind_rows(trace_df, tmp_df) # 途中経過を表示 print(paste0("--- iteration: ", i, " ---")) print(a) }
「ソートの実装」のときと同様にして、要素を入れ替えていきます。
数列 a の初期値のインデックス(1 から N の整数)を id_vec としておき、a の要素の入れ替えに対応するように id_vec の要素も入れ替えます。
試行ごとに、数列やインデックスをデータフレームに保存します。
初期値のときのコードで、ソートした数列をグラフで確認します。
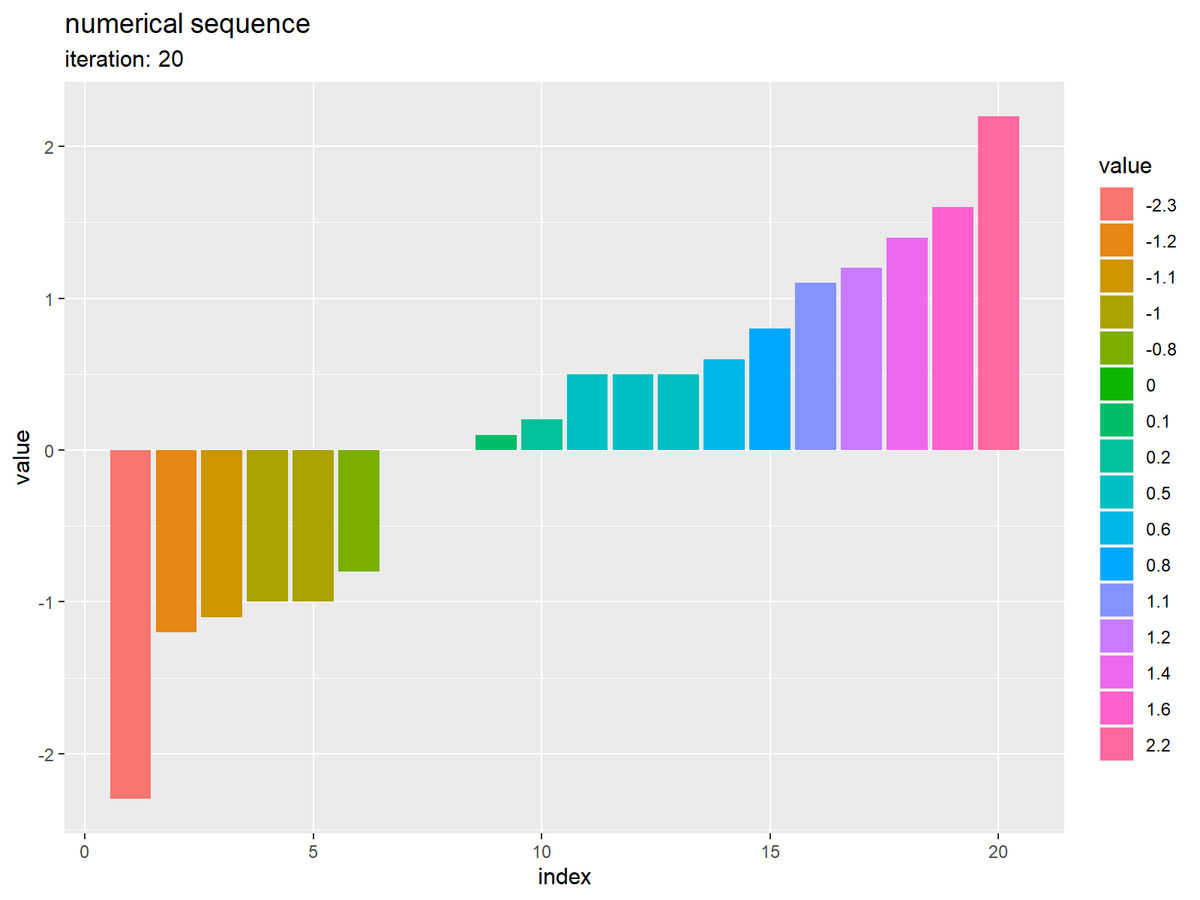
昇順に並んでいるのが分かります。
各試行の数列のグラフを並べて推移を確認します。
・作図コード(クリックで展開)
挿入データの描画用のデータフレームを作成します。
# 挿入データを作成 target_df <- trace_df |> dplyr::filter(iteration == id) # i番目の要素を抽出 target_df
## # A tibble: 20 × 4 ## iteration id index value ## <dbl> <int> <int> <dbl> ## 1 1 1 1 -0.8 ## 2 2 2 2 0.5 ## 3 3 3 1 -1.2 ## 4 4 4 3 0.2 ## 5 5 5 5 1.4 ## 6 6 6 3 0 ## 7 7 7 6 0.5 ## 8 8 8 8 2.2 ## 9 9 9 7 1.1 ## 10 10 10 4 0.1 ## 11 11 11 8 0.8 ## 12 12 12 2 -1 ## 13 13 13 9 0.6 ## 14 14 14 13 1.6 ## 15 15 15 5 0 ## 16 16 16 2 -1.1 ## 17 17 17 14 1.2 ## 18 18 18 11 0.5 ## 19 19 19 1 -2.3 ## 20 20 20 5 -1
試行回数(iteration 列)と元のインデックス(id 列)が一致するデータ(行)を抽出します。
試行ごとに数列のグラフを作成します。
# 全試行の数列を作図 ggplot() + geom_bar(data = trace_df, mapping = aes(x = index, y = value, fill = factor(value)), stat = "identity") + # 全ての要素 geom_bar(data = target_df, mapping = aes(x = id, y = value), stat = "identity", color = "red", alpha = 0, linewidth = 0.5, linetype = "dashed") + # 挿入前のi番目の要素 geom_bar(data = target_df, mapping = aes(x = index, y = value), stat = "identity", color = "red", alpha = 0, linewidth = 0.5, linetype = "dotted") + # 挿入後のi番目の要素 geom_segment(data = target_df, mapping = aes(x = id, y = value, xend = -Inf, yend = value, color = factor(value)), linewidth = 0.5, linetype = "dashed", show.legend = FALSE) + # 挿入データまでの上限値 facet_wrap(iteration ~ ., scales = "free_x", labeller = label_both) + # 試行ごとに分割 theme(panel.grid.minor.x = element_blank(), legend.position = "right") + labs(title = "insertion sort", fill = "value", x = "index", y = "value")
facet_wrap() で、試行(iteration 列)ごとに分割して棒グラフを描画します。
挿入前の要素(バー)の位置は元のインデックス(id 列)、挿入後の位置は iteration 回目時点のインデックス(index 列)を使います。
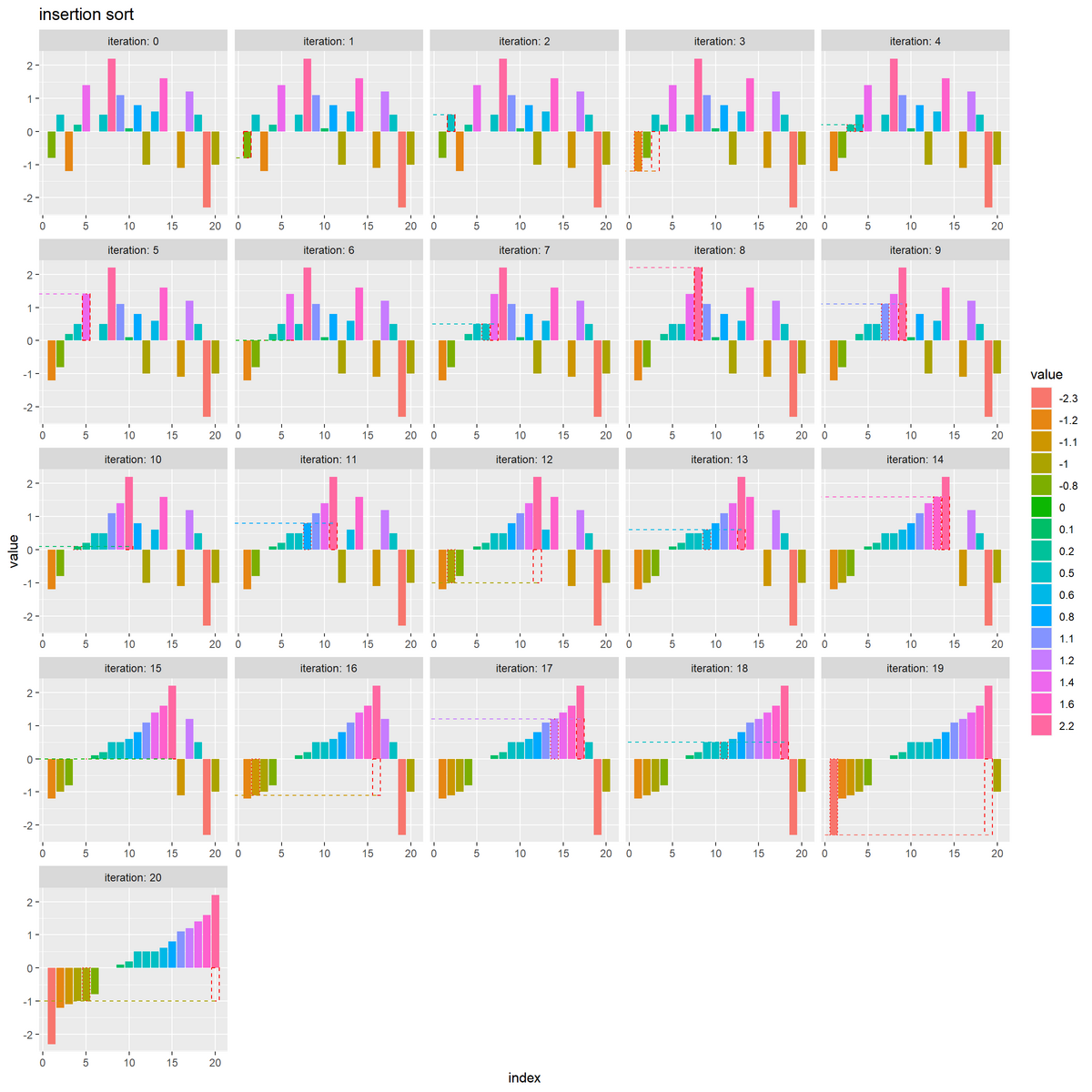
初期値を0回目として、N回目までの「入れ替え後の数列」をそれぞれ棒グラフ(バー)で表します。
i回目の試行(i+1枚目のグラフ)において、挿入した要素を赤色の枠線のバー、またその値を水平線で示します。破線のバーが挿入前の位置、点線のバーが挿入後の位置です。
挿入前の位置より左(小さいインデックス)の要素(バー)はソート済み、右(大きいインデックス)の要素(バー)は未処理のデータです。
挿入後の位置より左の要素は挿入した要素よりも値(高さ)が小さく、右の要素は値が大きいのが分かります。
各試行の数列のグラフを切り替えて推移を確認します。
・作図コード(クリックで展開)
同様に、挿入データの描画用のデータフレームを作成します。
# 挿入データを作成 target_df <- trace_df |> dplyr::filter((iteration + 1) == index) # i番目の要素を抽出 target_df
## # A tibble: 20 × 4 ## iteration id index value ## <dbl> <int> <int> <dbl> ## 1 0 1 1 -0.8 ## 2 1 2 2 0.5 ## 3 2 3 3 -1.2 ## 4 3 4 4 0.2 ## 5 4 5 5 1.4 ## 6 5 6 6 0 ## 7 6 7 7 0.5 ## 8 7 8 8 2.2 ## 9 8 9 9 1.1 ## 10 9 10 10 0.1 ## 11 10 11 11 0.8 ## 12 11 12 12 -1 ## 13 12 13 13 0.6 ## 14 13 14 14 1.6 ## 15 14 15 15 0 ## 16 15 16 16 -1.1 ## 17 16 17 17 1.2 ## 18 17 18 18 0.5 ## 19 18 19 19 -2.3 ## 20 19 20 20 -1
こちらは、試行回数(iteration 列)と元のインデックス(id 列)が一致する要素の1試行前のデータを抽出します。
重複ラベルの描画用のデータフレームを作成します。
# 重複ラベルを作成 dup_label_df <- trace_df |> dplyr::arrange(iteration, id) |> # IDの割当用 dplyr::group_by(iteration, value) |> # IDの割当用 dplyr::mutate( dup_id = dplyr::row_number(id), # 重複IDを割り当て dup_num = max(dup_id), # 重複の判定用 dup_label = dplyr::if_else( condition = dup_num > 1, true = paste0("(", dup_id, ")"), false = "" ) # 重複要素のみラベルを作成 ) |> dplyr::ungroup() |> dplyr::arrange(iteration, index) dup_label_df
## # A tibble: 420 × 7 ## iteration id index value dup_id dup_num dup_label ## <dbl> <int> <int> <dbl> <int> <int> <chr> ## 1 0 1 1 -0.8 1 1 "" ## 2 0 2 2 0.5 1 3 "(1)" ## 3 0 3 3 -1.2 1 1 "" ## 4 0 4 4 0.2 1 1 "" ## 5 0 5 5 1.4 1 1 "" ## 6 0 6 6 0 1 2 "(1)" ## 7 0 7 7 0.5 2 3 "(2)" ## 8 0 8 8 2.2 1 1 "" ## 9 0 9 9 1.1 1 1 "" ## 10 0 10 10 0.1 1 1 "" ## # ℹ 410 more rows
重複している値の要素にのみ、それぞれ通し番号のラベルを作成します。
推移のアニメーションを作成します。
# ソートのアニメーションを作図 graph <- ggplot() + geom_bar(data = trace_df, mapping = aes(x = index, y = value, fill = factor(value), group = factor(id)), stat = "identity") + # 全要素 geom_bar(data = target_df, mapping = aes(x = index, y = value, group = factor(id)), stat = "identity", color = "red", alpha = 0, linewidth = 1, linetype = "dashed") + # 挿入データ geom_segment(data = target_df, mapping = aes(x = index, y = value, xend = -2, yend = value, color = factor(value), group = factor(id)), linewidth = 1, linetype = "dashed", show.legend = FALSE) + # 挿入データまでの上限値 geom_text(data = trace_df, mapping = aes(x = index, y = 0, label = as.character(value), group = factor(id)), vjust = -0.5, size = 5) + # 要素ラベル geom_text(data = dup_label_df, mapping = aes(x = index, y = 0, label = dup_label, group = factor(id)), vjust = 1, size = 4) + # 重複ラベル gganimate::transition_states(states = iteration, transition_length = 9, state_length = 1, wrap = FALSE) + # フレーム遷移 gganimate::ease_aes("cubic-in-out") + # 遷移の緩急 coord_cartesian(xlim = c(0, N+1)) + # (上限値の線用) theme(panel.grid.minor.x = element_blank(), legend.position = "none") + labs(title = "insertion sort", subtitle = "iteration: {next_state}", fill = "value", x = "index", y = "value") # 1試行当たりのフレーム数を指定 s <- 20 # gif画像を作成 gganimate::animate( plot = graph, nframes = (N+1 + 2)*s, start_pause = s, end_pause = s, fps = 20, width = 800, height = 600, renderer = gganimate::gifski_renderer() )
transition_states() のフレーム制御の引数 states に試行回数列 iteration を指定して、これまでと同様に作図します。
animate() の plot 引数にグラフオブジェクト、nframes 引数にフレーム数を指定して、gif画像を作成します。
初期値を含むため試行回数は N+1 です。transition_states() でアニメーションを作成すると、フレーム間の値を補完して、状態の遷移を描画します。遷移のフレームを s として、試行回数の s 倍の値を nframes 引数に指定します。
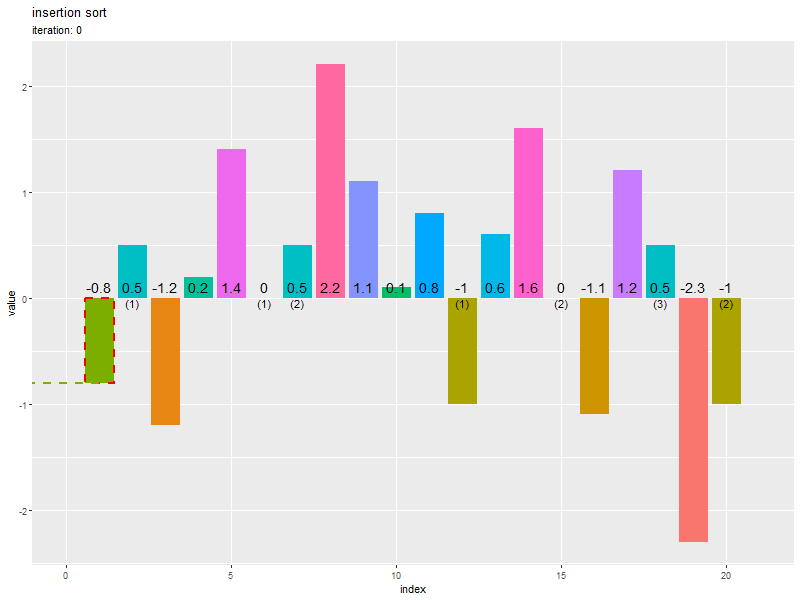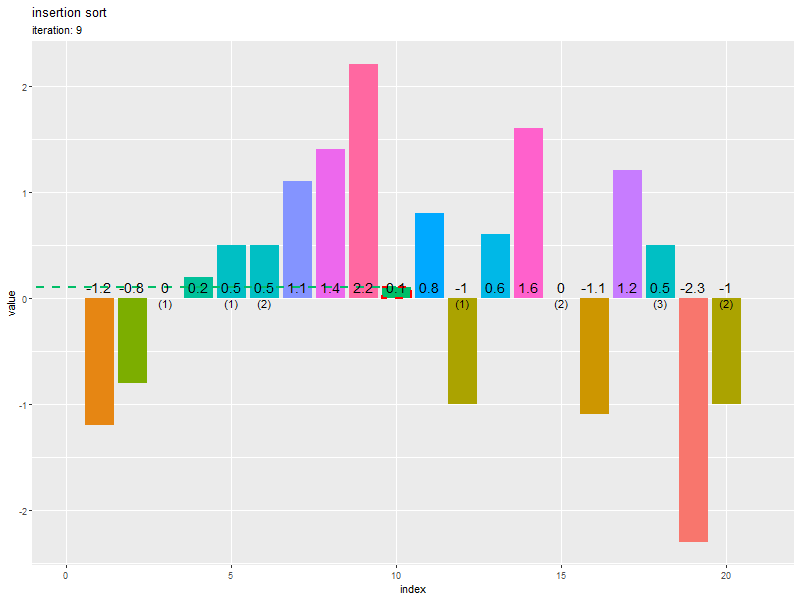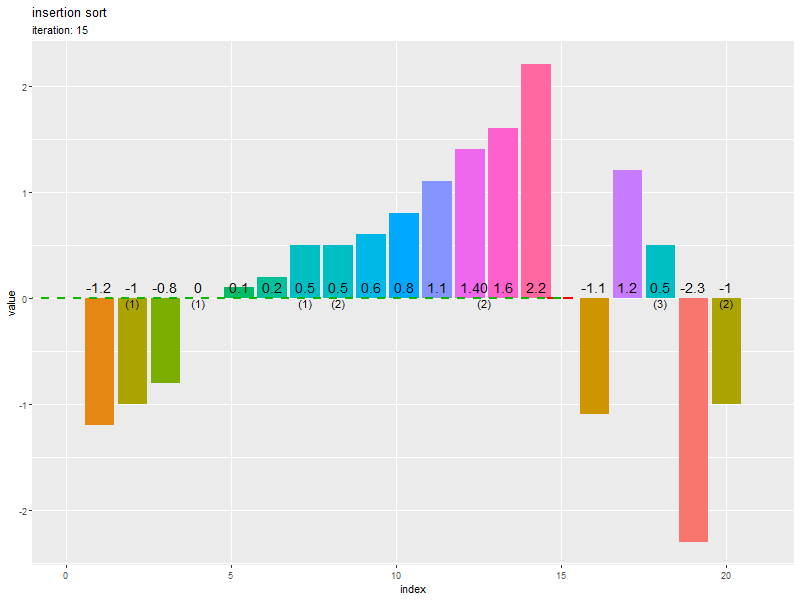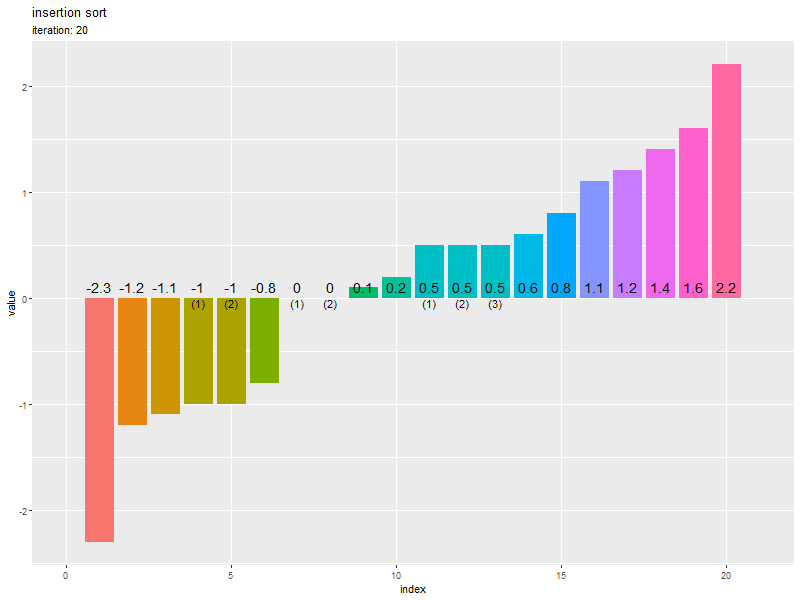
左(1番目)の要素から順番にソートされるのを確認できます。また、重複要素の順序が入れ替わらない(安定性・stable性)も確認できます。
ここでの試行回数(iterationの値)は、この可視化方法における試行番号(作図処理上の値)であり他の手法と対応していません。
この記事では、挿入ソートを実装しました。次の記事では、マージソートを実装します。
参考文献
- 大槻兼資(著), 秋葉拓哉(監修)『問題解決力を鍛える! アルゴリズムとデータ構造』講談社サイエンティク, 2021年.
おわりに
またまた電子版がセールだったのでポチりました。他に早く読み切りたい本が溜まっていて積むこと必至なのですが、せめて前々からやってみたかったソートアルゴリズムだけでもやっておきます。でも計算量とかの話はスルーします。
2023年8月16日は、BEYOOOOONDSとSeasoningSのメンバーの小林萌花さんの23歳のお誕生日です!
アイドルとして活動しつつ昨年音大を卒業されたピアニストでもあります。マンガ・アニメ調のイラストも上手で多才な方です。
ほのぴあのが最高なのでぜひぜひ聴いてください!
【次節の内容】