はじめに
『ゼロから作るDeep Learning 3』の初学者向け攻略ノートです。『ゼロつく3』の学習の補助となるように適宜解説を加えていきます。本と一緒に読んでください。
本で省略されているクラスや関数の内部の処理を1つずつ解説していきます。
この記事は、主にステップ57と58の間を補足する内容です。
簡単なCNNを実装してMNISTの学習を行います。
【前ステップの内容】
【他の記事一覧】
【この記事の内容】
・CNNによるMNISTの学習
畳み込みニューラルネットワーク(CNN)を用いて、MNISTデータセットの学習を行います。
次のライブラリを利用します。
# 利用するライブラリ import matplotlib.pyplot as plt
また、これまでに実装済したクラスを利用します。dezeroフォルダの親フォルダまでのパスをsys.path.append()に指定します。
# 実装済みライブラリのパスを指定 import sys sys.path.append('..') #sys.path.append('../deep-learning-from-scratch-3-master') # 実装済みモジュールを読み込み import dezero from dezero import Model, DataLoader, optimizers from dezero.transforms import Compose, ToFloat, Normalize import dezero.functions as F import dezero.layers as L
・簡単なCNNの実装
まずは、ゼロつく1巻の5.7節「7.5:CNNの実装【ゼロつく1のノート(実装)】 - からっぽのしょこ」を参考にして、簡単な畳み込みニューラルネットワークを実装します。
入力層を「畳み込み層-ReLU関数-Pooling層」、中間層を「全結合層-ReLU関数」、出力層を「全結合層」とするCNNを実装します。実装には、Modelクラスを継承します。
畳み込み層は、出力サイズ(チャンネル数)を30、フィルタのサイズを縦横共に5、ストライド幅を1とします。Pooling層は、フィルタのサイズを縦横共に2、ストライド幅も2とします。どちらもパディングは行いません。
中間層と出力層の全結合層は、出力サイズ(ニューロン数)をそれぞれ100と10とします。10は、手書き数字の種類数に対応しています。
# 簡単なCNNを実装 class SimpleConvNet(Model): # 初期化メソッド def __init__(self): # 初期化メソッドに処理を追加 super().__init__() # レイヤを作成 self.conv0 = L.Conv2d(out_channels=30, kernel_size=5, stride=1, pad=0) # 入力層 self.fc1 = L.Linear(out_size=100) # 中間層 self.fc2 = L.Linear(out_size=10) # 出力層 # 順伝播メソッド def forward(self, x): # 入力層を計算 x = F.relu(self.conv0(x)) x = F.pooling(x, kernel_size=2, stride=2, pad=0) # 各データを1次元配列に変形 x = F.reshape(x, (x.shape[0], -1)) # 中間層を計算 x = F.relu(self.fc1(x)) # 出力層を計算 x = self.fc2(x) return x
MLPのようにフィルタ数やニューロン数、活性化関数を引数に指定できるように実装してもよいのですが、ここだけで利用するものなのでシンプルに実装しました。
また、重みの初期値の標準偏差を指定できない仕様なので、その点が1巻の例と異なっています。
・MNISTの学習
次に、実装したSimpleConvNetを用いて学習を行います。
MNISTデータセットの読み込みについて簡単に確認します。詳しくは、「ステップ51:MNISTデータセットの学習【ゼロつく3のノート(実装)】 - からっぽのしょこ」を参照してください。
# データセットを設定 train_set = dezero.datasets.MNIST(train=True, transform=Compose([ToFloat(), Normalize(0.0, 255.0)])) # 0番目のデータを取得 x, t = train_set[0] # 入力データを確認 print(type(x)) print(x[0, 10, 5:15]) print(x.shape) # 教師データを確認 print(type(t)) print(t)
<class 'numpy.ndarray'>
[0. 0. 0. 0. 0.05490196 0.00392157
0.6039216 0.99215686 0.3529412 0. ]
(1, 28, 28)
<class 'numpy.uint8'>
5
多層ニューラルネットワーク(MLP)のときは、1つの画像データを1次元配列に並べ替えて扱いました。畳み込みニューラルネットワークでは、2次元配列のまま入力します。
そこで、前処理の内容(transform引数の設定)が少し変わります。
デフォルトでは、Composeを使って、Flattenで2次元配列から1次元配列に変形して、ToFloatでintからnp.float32に変更して、Normalizeで「0から255の値」を「0から1の値」に変換します。詳しくは、functions_conv.pyとtransforms.pyを参照してください。
ここでは、Flattenの処理を行いません。
入力する手書き数字は次のようなデータです。
# 手書き文字を表示 plt.imshow(x[0], cmap='gray') # 入力データ plt.title('label:' + str(t)) # 教師データ(正解ラベル) plt.axis('off') # 軸ラベル plt.show()
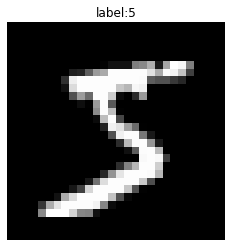
ステップ51とは異なりこの例では、縦方向に並ぶピクセルの情報も維持したまま入力されます。
基本的な処理はNNのとき(ステップ51)と同じです。
# エポック当たりの試行回数を指定 max_epoch = 10 # バッチサイズを指定 batch_size = 100 # データセットを設定 train_set = dezero.datasets.MNIST(train=True, transform=Compose([ToFloat(), Normalize(0.0, 255.0)])) test_set = dezero.datasets.MNIST(train=False, transform=Compose([ToFloat(), Normalize(0.0, 255.0)])) train_loader = DataLoader(train_set, batch_size) test_loader = DataLoader(test_set, batch_size, shuffle=False) # ニューラルネットのインスタンスを作成 model = SimpleConvNet() # 最適化手法のインスタンスを作成 optimizer = optimizers.Adam(alpha=0.001).setup(model) # 推移の確認用のリストを初期化 trace_loss_train, trace_loss_test = [], [] trace_acc_train, trace_acc_test = [], [] # ミニバッチ学習 for epoch in range(max_epoch): # 損失・精度の合計値を初期化 sum_loss, sum_acc = 0, 0 # ミニバッチに対する処理 for x, t in train_loader: # ミニバッチ(訓練データ)を抽出 # ニューラルネットワークの出力を計算(推論) y = model(x) # ミニバッチにおける損失・精度を計算 loss = F.softmax_cross_entropy(y, t) acc = F.accuracy(y, t) # 勾配を計算 model.cleargrads() loss.backward() # パラメータを更新(学習) optimizer.update() # 合計損失・正解数を加算 sum_loss += float(loss.data) * len(t) sum_acc += float(acc.data) * len(t) # 全データにおける損失・精度を計算 avg_loss = sum_loss / len(train_set) avg_acc = sum_acc / len(train_set) # 値を記録 trace_loss_train.append(avg_loss) trace_acc_train.append(avg_acc) # 訓練データに対する結果を表示 print('epoch: {}'.format(epoch + 1)) print('train loss: {:.4f}, accurary: {:.4f}'.format(avg_loss, avg_acc)) # 損失・精度の合計値を初期化 sum_loss, sum_acc = 0, 0 # ミニバッチに対する処理 with dezero.no_grad(): for x, t in test_loader: # ミニバッチ(テストデータ)を抽出 # ニューラルネットワークの出力を計算(推論) y = model(x) # ミニバッチにおける損失・精度を計算 loss = F.softmax_cross_entropy(y, t) acc = F.accuracy(y, t) # 合計損失・正解数を加算 sum_loss += float(loss.data) * len(t) sum_acc += float(acc.data) * len(t) # 全データにおける損失・精度を計算 avg_loss = sum_loss / len(test_set) avg_acc = sum_acc / len(test_set) # 値を記録 trace_loss_test.append(avg_loss) trace_acc_test.append(avg_acc) # テストデータに対する結果を表示 print('test loss: {:.4f}, accurary: {:.4f}'.format(avg_loss, avg_acc))
epoch: 1
train loss: 0.1674, accurary: 0.9507
test loss: 0.0594, accurary: 0.9805
epoch: 2
train loss: 0.0541, accurary: 0.9839
test loss: 0.0482, accurary: 0.9842
(省略)
epoch: 9
train loss: 0.0084, accurary: 0.9971
test loss: 0.0402, accurary: 0.9881
epoch: 10
train loss: 0.0063, accurary: 0.9980
test loss: 0.0367, accurary: 0.9895
学習を繰り返すごとに、平均損失が下がり、認識精度が上がっているのが分かります。
・学習結果の確認
最後に、学習の推移を確認します。
訓練データとテストデータに対する損失(交差エントロピー誤差)の推移を確認します。
# 損失の推移を作図 plt.figure(figsize=(8, 6)) plt.plot(range(1, max_epoch + 1), trace_loss_train, label='train') # 訓練データ plt.plot(range(1, max_epoch + 1), trace_loss_test, label='test') # テストデータ plt.xlabel('epoch') # x軸ラベル plt.ylabel('loss') # y軸ラベル plt.title('layer:' + str(len(model.__dict__['_params'])) + ', hidden size:' + str(model.__dict__['fc1'].__dict__['out_size']) + ', activation:' + str('relu') + ', optimizer:' + str(optimizer.__class__.__name__) + ', lr:' + str(optimizer.__dict__['alpha'])) # 設定 plt.legend() # 凡例 plt.grid() # グリッド線 #plt.ylim(0.0, 0.2) # y軸の表示範囲 plt.show()
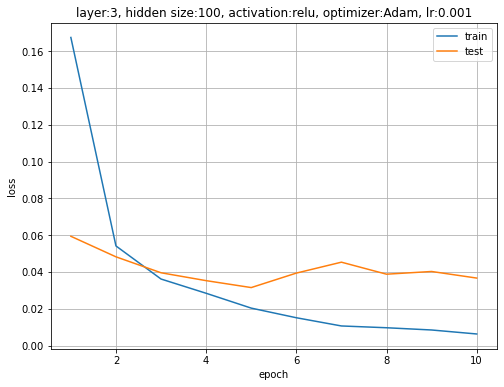
訓練データとテストデータどちらに対しても交差エントロピー誤差が下がっていることから、過学習が起きていないのが分かります。ただし、訓練データのミニバッチを1エポック分学習してからテストデータを使って評価しているので、始めの方はテストデータに対する損失の推移の方が小さくなっています。
同様に、認識精度の推移を確認します。
# 精度の推移を作図 plt.figure(figsize=(8, 6)) plt.plot(range(1, max_epoch + 1), trace_acc_train, label='train') # 訓練データ plt.plot(range(1, max_epoch + 1), trace_acc_test, label='test') # テストデータ plt.xlabel('epoch') # x軸ラベル plt.ylabel('accuracy') # y軸ラベル plt.title('layer:' + str(len(model.__dict__['_params'])) + ', hidden size:' + str(model.__dict__['fc1'].__dict__['out_size']) + ', activation:' + str('relu') + ', optimizer:' + str(optimizer.__class__.__name__) + ', lr:' + str(optimizer.__dict__['alpha'])) # 設定 plt.legend() # 凡例 plt.grid() # グリッド線 #plt.ylim(0.0, 1.0) # y軸の表示範囲 plt.show()
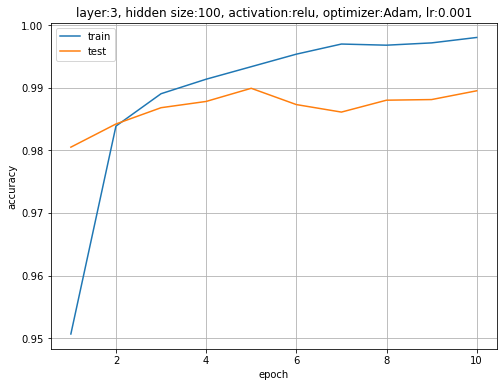
NNのときよりも更に精度が上がりました。
以上でCNNを実装できました。縦横(奥)の関係を維持したまま扱うことで、認識精度が上がりました。次からは、時系列データを扱うことを考えます。
参考文献
- 斎藤康毅『ゼロから作るDeep Learning 3 ――フレームワーク編』オライリー・ジャパン,2020年.
おわりに
DeZeroのCNNを使ったMNISTの学習が載っていなかったので、ここでやっておきましょう。理論面は1巻でじっくりやっているので、重複するのを避けたのかな。処理的にもステップ51と被りますしね。
CNNに関しては、1巻を読んでいないのであればこの本の先でも後でも1周することをおすすめします。理論面だけでなく実装面でも3巻よりも丁寧(3巻の実装方法で容易に理解できるのであれば冗長かもしれませんが)です。NNに関しても同様です。ただ、理論をしっかりと言うとどうしても数学が登場するわけですが、 「ここは理解しておこう」 「ここは理解できなくても最後の部分だけ知っておこう」「ここは興味のある人だけでいいよ」の線引きがうまくされているのでなんとかなると思います。なんとかならなそうであれば、このブログを参考にしていただいてなんとかなったらいーな。
さて2021年7月7日は、モーニング娘。'21のサブリーダー生田衣梨奈さん24歳のお誕生日です!
(アプフロさん加入10年が経って未だセンター曲がないです…ので)新曲をば。
さらに、アンジュルムのサブリーダー川村文乃さん22歳のお誕生日でもあります!!
最初に映る方です。
さらにさらに、Juice=Juiceの松永里愛さん16歳のお誕生です!!!
サムネの左の方です。今日(昨日?)が新メンバー最後の日だったわけか。月日が経つのがホントに早くなったよ。
そしてとどめに先ほどJuice=Juiceとつばきファクトリーの新メンバーが発表されましたー
めでたい日でした。みんな若い、希望しかないな。
【次ステップの内容】