はじめに
「プログラミング」学習初手『ゼロから作るDeep Learning』民のための実装攻略ノートです。『ゼロつく1』学習の補助となるように適宜解説を加えています。本と一緒に読んでください。
関数やクラスとして実装される処理の塊を細かく分解して、1つずつ処理を確認しながらゆっくりと組んでいきます。
この記事は、6.4.3項「Dropout」の内容になります。ランダムにニューロンを消去するDropoutを説明し、Pythonで実装します。
【前節の内容】
【他の節の内容】
【この節の内容】
6.4.3 Dropout
Dropoutとは、ランダムにニューロンを消去しながら学習を行う手法です。ニューロンを消去することで一部の信号が伝播しなくり、表現力を一時的に落とすことで過学習を抑制できます。
・実装
np.random.randint()で、ランダムに整数を生成します。第1引数以上第2引数未満の整数を、第3引数に指定した形状で出力します。
# バッチサイズを指定 batch_size = 5 # ニューロン数を指定 node_num = 5 # (処理のイメージ用に)ランダムに整数を生成 x = np.random.randint(0, 10, (batch_size, node_num)) print(x)
[[6 3 6 1 2]
[0 4 7 0 6]
[5 5 4 0 9]
[5 5 4 0 3]
[3 1 6 0 5]]
(処理をイメージしやすいように整数にしているだけで、この値に意味はありません。)
何度も使ってきた通り、.shapeとすると各次元の要素数を格納した(タプル型の)オブジェクト返します。頭に*(アスタリスク)を付けることで、それぞれ要素を別々に返します。
print(x.shape) print(*x.shape)
(5, 5)
5 5
要は、x.shape[0], x.shape[1]と同じ結果となります。
この機能を使って、xの要素数をそれぞれnp.random.rand()の第1引数と第2引数に指定できます。つまりxと同じ形状の出力を得られます。np.random.rand()は、0から1までの値を(標準正規分布ではなく)一様な確率に従いランダムに生成します。
またその出力に対して、比較演算子を使って指定したレートより大きい要素のインデックスを取得します。
# Dropout ratioを指定 dropout_ratio = 0.5 # ランダムに0から1の値を生成 random_data = np.random.rand(*x.shape) print(np.round(random_data, 3)) # 一定の値以上の要素を検索 mask = random_data > dropout_ratio print(mask)
[[0.128 0.714 0.617 0.077 0.285]
[0.011 0.719 0.275 0.317 0.31 ]
[0.884 0.796 0.782 0.356 0.575]
[0.317 0.873 0.245 0.231 0.423]
[0.221 0.101 0.699 0.68 0.423]]
[[False True True False False]
[False True False False False]
[ True True True False True]
[False True False False False]
[False False True True False]]
Trueは1、Falseは0として計算できるので、データxに掛けることで、指定したレートに従いランダムにノードを消去するのと同じ効果を得られます。
# ノードを消去 print(x * mask)
[[0 3 6 0 0]
[0 4 0 0 0]
[5 5 4 0 9]
[0 5 0 0 0]
[0 0 6 0 0]]
0になった要素は、伝播しなかったことを意味します。
処理の確認ができたので、Dropoutをクラスとして実装します。
Dropoutは訓練時にのみ行う処理です。引数のtrain_flgによって条件分岐します。
# Dropoutの実装 class Dropout: # インスタンスの定義 def __init__(self, dropout_ratio=0.5): self.dropout_ratio = dropout_ratio self.mask = None # 順伝播メソッドの定義 def forward(self, x, train_flg=True): # ランダムにニューロンを消去 if train_flg: # 訓練時 self.mask = np.random.rand(*x.shape) > self.dropout_ratio return x * self.mask else: # テスト時 return x * (1.0 - self.dropout_ratio) # 逆伝播メソッドの定義 def backward(self, dout): return dout * self.mask
続いてDropoutによる過学習の抑制効果を確認しましょう。
・過学習を抑制効果を確認
MNISTデータセットを使ってDropoutの効果を見ます。「6.4.1-2:Weight decay【ゼロつく1のノート(実装)】 - からっぽのしょこ」と同様に過学習が起きやすい設定で実験してみます。
Dropout対応版多層ニューラルネットワークMultiLayerNetExtendのインスタンスを作成します。
この例では7層のニューラルネットワークとするため、中間層のニューロン数の引数hidden_size_listに6つの値をリスト型変数で指定します(詳しくは実装時に説明します)。任意の値を指定できますが、この例では全て100とします。MNISTデータセットを用いる場合は、入力サイズinput_sizeがピクセル数の784、出力サイズoutput_sizeが数字の数10になります。(ちなみに、入出力層を含めた8つの層の間の数が7になります。)
活性化レイヤにReLU関数を用いるためactivation引数にrelu、重みの初期値をHeの初期値とするためweight_init_std引数に'he'を指定します。
また最適化手法を確率的勾配降下法(SGD)とします。6.1節で実装した他の手法も使えます。
# データ読み込み用ライブラリを読み込む import sys, os # ファイルパスを指定 sys.path.append('C:\\Users\\「ユーザー名」\\Documents\\・・・\\deep-learning-from-scratch-master') # MNISTデータセット読み込み関数 from dataset.mnist import load_mnist # 各種レイヤのクラス from common.layers import * # Dropout対応版多層ニューラルネットワーククラスを読み込む from common.multi_layer_net_extend import MultiLayerNetExtend # 画像データを読み込む (x_train, t_train), (x_test, t_test) = load_mnist(normalize = True, one_hot_label=True) print(x_train.shape) print(t_train.shape)
(60000, 784)
(60000, 10)
ここから300データだけを取り出します。また更に1回の試行に使用するデータ数を指定し、batch_sizeとします。
# 学習データを削減 x_train = x_train[:300] t_train = t_train[:300] # 訓練データ数 train_size = x_train.shape[0] # バッチサイズを指定 batch_size = 100
まずはDropoutを行わない場合の結果を見るため、use_dropout引数にFalseを指定します。またニューロンを消去する割合dropout_ratioを(一応)0とします(後で変更しやすいように変数は作っておきます)。
Dropout対応版多層ニューラルネットワークMultiLayerNetExtendのインスタンスを作成します。
この例では7層のニューラルネットワークとするため、中間層のニューロン数の引数hidden_size_listに6つの値をリスト型変数で指定します(詳しくは実装時に説明します)。任意の値を指定できますが、この例では全て100とします。MNISTデータセットを用いる場合は、入力サイズinput_sizeがピクセル数の784、出力サイズoutput_sizeが数字の数10になります。(ちなみに、入出力層を含めた8つの層の間の数が7になります。)
活性化レイヤにReLU関数を用いるためactivation引数にrelu、重みの初期値をHeの初期値とするためweight_init_std引数に'he'を指定します。
また最適化手法を確率的勾配降下法(SGD)とします。6.1節で実装した他の手法も使えます。
# 消去するニューロンの割合を指定 dropout_ratio = 0.0 # 7層のニューラルネットワークのインスタンスを作成 network = MultiLayerNetExtend( input_size=784, hidden_size_list=[100, 100, 100, 100, 100, 100], output_size=10, activation='relu', # 活性化関数 weight_init_std='he', # 重みの初期値の標準偏差 use_dropout=False, # Dropoutの設定 dropout_ration=dropout_ratio # ニューロンを消去する割合 ) # 最適化手法を指定 optimizer = SGD(lr=0.01)
試行回数を指定して実行します。
これまではfor文のrange()等に試行回数を指定していましたが、この例では次のようにして操作します。ミニバッチデータごとに(試行する度に)epoch_cntに1を加えることで試行回数を記録します。このカウントが指定した回数max_epochsに達すると、breakによってループ処理を終了します。この操作の前にforループが終わらないようにするため、range()には大きな値を与えています。値自体に特別な意味はありません。
# エポック当たりの試行回数を指定 max_epochs = 301 # 全データ数に対するバッチデータ数の割合(エポック数判定用) iter_per_epoch = max(train_size / batch_size, 1) # 試行回数のカウントを初期化 epoch_cnt = 0 # 認識精度の受け皿を初期化 train_acc_list = [] test_acc_list = [] for i in range(1000000000): # ランダムにバッチデータ抽出 batch_mask = np.random.choice(train_size, batch_size) x_batch = x_train[batch_mask] t_batch = t_train[batch_mask] # 勾配を計算 grads = network.gradient(x_batch, t_batch) # パラメータを更新 optimizer.update(network.params, grads) # 1エポックごとに認識精度を測定 if i % iter_per_epoch == 0: # 認識精度を測定 train_acc = network.accuracy(x_train, t_train) test_acc = network.accuracy(x_test, t_test) # 値を記録 train_acc_list.append(train_acc) test_acc_list.append(test_acc) # (動作確認も兼ねて)10エポックごとに認識精度を表示 if epoch_cnt % 10 == 0: print( "===========" + "epoch:" + str(epoch_cnt) + "===========" + "\ntrain acc:" + str(np.round(train_acc, 3)) + "\ntest acc :" + str(np.round(test_acc, 3)) ) # エポック数をカウント epoch_cnt += 1 # 最大エポック数に達すると終了 if epoch_cnt >= max_epochs: break
===========epoch:0===========
train acc:0.11
test acc :0.093
===========epoch:10===========
train acc:0.307
test acc :0.25
===========epoch:20===========
(省略)
===========epoch:290===========
train acc:1.0
test acc :0.768
===========epoch:300===========
train acc:1.0
test acc :0.769
訓練データとテストデータに対する認識精度の推移をグラフ化して確認しましょう。
# 作図用のx軸の値 epoch_vec = np.arange(max_epochs) # 作図 plt.plot(epoch_vec, train_acc_list, label='train') # 訓練データ plt.plot(epoch_vec, test_acc_list, label='test') # テストデータ #plt.ylim(0, 1) # y軸の範囲 plt.xlabel("epochs") # x軸ラベル plt.ylabel("accuracy") # y軸ラベル plt.title("Accuracy", fontsize=20) # タイトル plt.legend() # 凡例 plt.show()
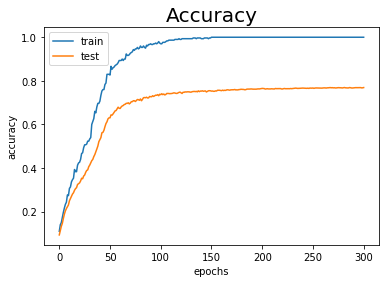
訓練データの認識率が100%になっていますが、テストデータに対しては75%とその差が開いていることから、過学習をしていることが分かります(図6-23左)。(まぁ6.4.1項と全く同じことをしましたから。)
今度はDropoutを行います。use_dropout引数をTrueとし、dropout_ratio引数に指定する割合を設定します。
# 消去するニューロンの割合を指定 dropout_ratio = 0.15 # 7層のニューラルネットワークのインスタンスを作成 network = MultiLayerNetExtend( input_size=784, hidden_size_list=[100, 100, 100, 100, 100, 100], output_size=10, activation='relu', # 活性化関数 weight_init_std='he', # 重みの初期値の標準偏差 use_dropout=True, # Dropoutの設定 dropout_ration=dropout_ratio # ニューロンを消去する割合 )
その他のコードは同じなので省略します。
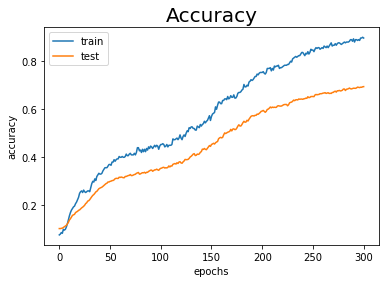
訓練データとテストデータに対しての認識精度の差が小さくなりました(図6-23右)。
以上で過学習を抑制するための手法を確認できました。次はハイパーパラメータの更新について考えます。
参考文献
- 斎藤康毅『ゼロから作るDeep Learning』オライリー・ジャパン,2016年.
おわりに
ドロップアウトせずにここまで来られた!
1つ前の手法も含めて、確かに過学習は抑制できているようですが、それによってテストデータに対する認識精度が上がるわけではないんですね。
【次節の内容】