はじめに
『ゼロから作るDeep Learning 3』の初学者向け攻略ノートです。『ゼロつく3』の学習の補助となるように適宜解説を加えていきます。本と一緒に読んでください。
本で登場する数学的な内容をもう少し深堀りして解説していきます。
この記事は、主にステップ29「ニュートン法を用いた最適化(手計算)」を補足する内容です。
勾配降下法とニュートン法を比較します。
【前ステップの内容】
【他の記事一覧】
【この記事の内容】
・勾配降下法とニュートン法の比較
簡単な例を用いて、勾配降下法(最急降下法)とニュートン法を比較します。
次のライブラリを利用します。
# 利用するライブラリ import numpy as np import matplotlib.pyplot as plt
・関数の設定
簡単な問題として次の4次関数を用います。
この関数の1階微分$\frac{\partial f(x)}{\partial x}$と2階微分$\frac{\partial^2 f(x)}{\partial x^2}$は、次の式になります。
$\frac{\partial f(x)}{\partial x},\ \frac{\partial^2 f(x)}{\partial x^2}$の簡易的な表記が$f'(x),\ f''(x)$です。
それぞれ関数として定義しておきます。
# 元の関数を作成 def f(x): y = x**4 - 2 * x**2 return y # 1階微分を作成 def gx(x): return 4 * x**3 - 4 * x # 2階微分を作成 def gx2(x): return 12 * x**2 - 4
$f(x)$をグラフで確認しておきます。
# x軸の値を設定 x_line = np.linspace(-2.5, 2.5, num=500) # y軸の値を計算 y_line = f(x_line)
# グラフを作成 plt.figure(figsize=(8, 6)) plt.plot(x_line, y_line) plt.xlabel('x') # x軸ラベル plt.ylabel('f(x)') # y軸ラベル plt.title('$f(x) = x^4 - 2 x^2$', fontsize=20) # タイトル plt.grid() # グリッド線 plt.ylim(-2.0, 10.0) # y軸の表示範囲 plt.show()
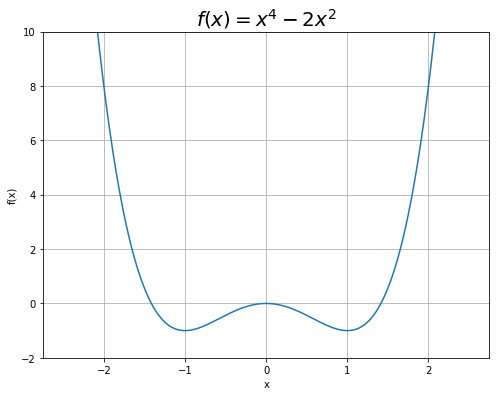
この関数の最小値は$x = -1, 1$のときの1です。
$f'(x)$と$f''(x)$も重ねてグラフにします。
# 関数と微分簿比較 plt.figure(figsize=(8, 6)) plt.plot(x_line, y_line, label='f(x)') # 元の関数 plt.plot(x_line, gx(x_line), label="f'(x)") # 1階微分 plt.plot(x_line, gx2(x_line), label="f''(x)") # 2階微分 plt.xlabel('x') # x軸ラベル plt.ylabel('f(x)') # y軸ラベル plt.title('$f(x) = x^4 - 2 x^2$', fontsize=20) # タイトル plt.legend() # 凡例 plt.grid() # グリッド線 plt.ylim(-5.0, 10.0) # y軸の表示範囲 plt.show()
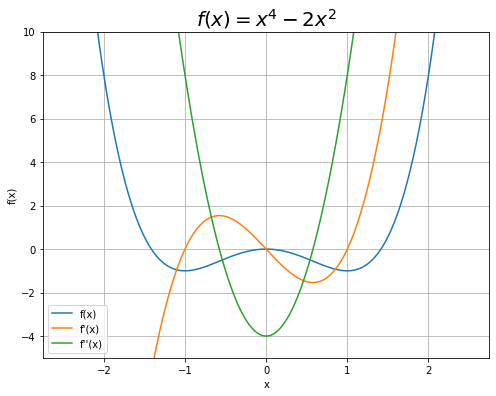
1階微分(オレンジ)$f'(x)$は元の関数(青)$f(x)$の傾き、2階微分(緑)$f''(x)$は1階微分(オレンジ)$f'(x)$の傾きを表します。
微分は傾きなので、$f(x)$の最小値・局所的最大値となる$x = -1, 0, 1$で$f'(x)$の値が0になり、$f'(x)$の局所的最小値・局所的最大値となるところ(ちなみに$x = -\frac{1}{\sqrt{3}}, \frac{1}{\sqrt{3}}$)で$f''(x)$が0になります。これは式からも分かります。
使用する関数を用意できたので、次からは勾配降下法とニュートン法による最適化を行います。
・勾配降下法による更新
勾配降下法を用いて$f(x)$の最小値を求めます。
勾配法では、学習率を$\alpha$として次の式の計算を繰り返すことで、$f(x)$が最小となる$x$に近付けていくのでした。詳しくは「4.4.1:勾配法【ゼロつく1のノート(数学)】 - からっぽのしょこ」または「6.1.2:SGD【ゼロつく1のノート(実装)】 - からっぽのしょこ」を参照してください
右辺の計算によって$x$を更新することを表しています。更新前を$x^{(\mathrm{old})}$、更新後を$x^{(\mathrm{new})}$で表すと次の式と同じことです。
早速やってみましょう。
# 試行回数を指定 iters = 20 # 学習率を指定 lr = 0.01 # 初期値を指定 x = 2.0 # 推移の確認用のリストを初期化 x_list_gdm = [x] # 勾配降下法 for i in range(iters): # 現在の値を表示 print('iter:' + str(i), x) # 値を更新 x -= lr * gx(x) # i回目の結果を記録 x_list_gdm.append(x) # 閾値未満まで近付けば終了 if abs(x - 1.0) < 1e-10: break
iter:0 2.0
iter:1 1.76
iter:2 1.61232896
iter:3 1.5091654023014192
iter:4 1.4320422081467723
iter:5 1.3718537670818505
iter:6 1.3234557123052246
iter:7 1.2836707795677516
iter:8 1.2504077544406735
iter:9 1.22222258571841
iter:10 1.1980798739184826
iter:11 1.177214336033959
iter:12 1.1590459825555366
iter:13 1.143125902304502
iter:14 1.129100349749648
iter:15 1.1166862256266712
iter:16 1.1056538960762419
iter:17 1.0958148793962101
iter:18 1.0870128450049137
iter:19 1.079116917392435
指定した回数では最小値まで辿り着かず(指定した値未満の誤差にならず)、最後まで処理を繰り返しています。1e-10は$\frac{1}{10^{10}}$です。
結果をグラフで確認します。
# 勾配降下法による更新値の推移を作図 plt.figure(figsize=(8, 6)) plt.plot(x_line, y_line, label='f(x)') # 元の関数 plt.scatter([-1.0, 1.0], [-1.0, -1.0], marker='*', c='black', s=100, label='minimum val') # 最小値 plt.plot(x_list_gdm, f(np.array(x_list_gdm)), marker='o', label='x') # 更新値 plt.xlabel('x') plt.ylabel('f(x)') plt.suptitle('Gradient Descent Method', fontsize=20) plt.title('iter:' + str(i + 1) + ', lr=' + str(lr) + ', x=' + str(np.round(x, 3)), loc='left') plt.legend() plt.grid() plt.ylim(-2.0, 10.0) plt.show()
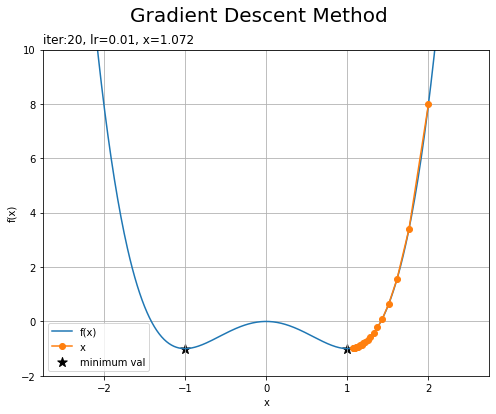
xの値の出力からも分かりますが、最小値付近で更新が停滞しているのが分かります。
他の値でも試してみましょう。
・「学習率が0.001で初期値が2」と「学習率が0.01で初期値が-2」の場合
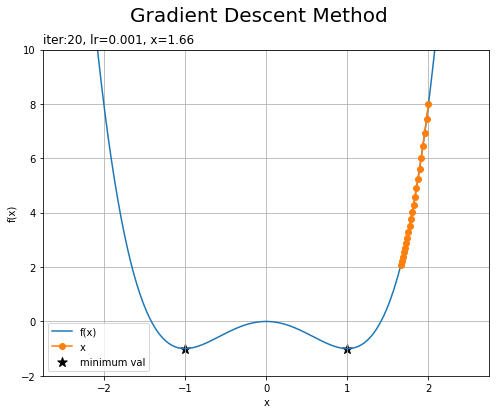
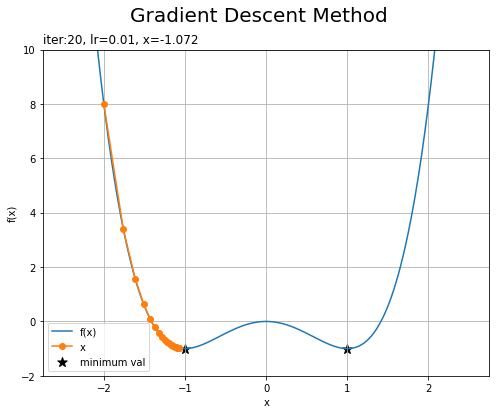
左の図は、学習率が小さすぎるため更新幅が割り引かれすぎて、全然更新が進んでいません。
右の図は、もう1つの最小値を目指しています。
・「学習率が0.15で初期値が-2」と「学習率が0.01で初期値が0」の場合
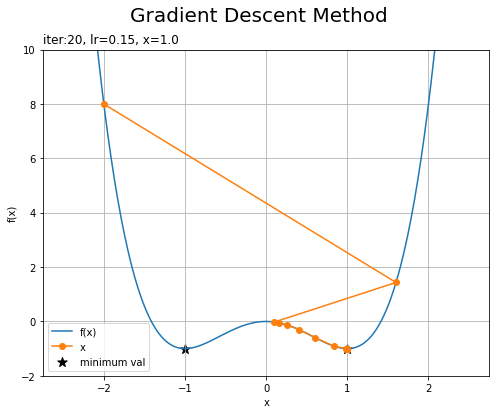
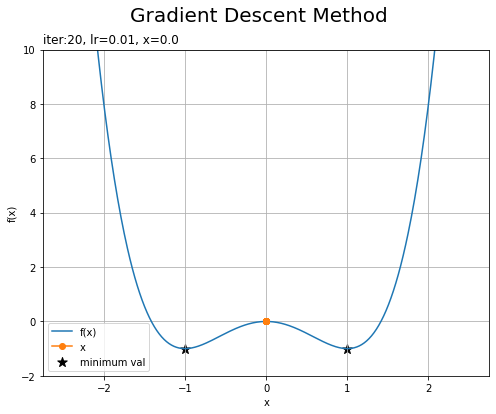
左の図は、学習率が大きいため更新幅も広くなり、近くの最小値を飛び越えて別の最小値に辿り着いています。ただし学習率が大きいと、最小値を何度も飛び越えていつまでも辿り着かないことや、大きく飛び越えて発散してしまうこともあります。
右の図は、初期値の勾配(傾き)が0のため、更新幅も0になり全く更新されません。
・ニュートン法による更新
続いて、ニュートン法を用いて$f(x)$の最小値を求めます。
ニュートン法とは、ある関数$f(x)$に関して$f(x) = 0$となる$x$を求める(近似する)手法です。次の計算を繰り返すことで$x$を解に近付けていきます。
ここでは、$f(x)$が(0ではなく)最小となる$x$を求めたいのでした。そこで、最小値$x$では$f(x)$の傾き$f'(x)$が0になることを利用します。つまり、「$f(x)$が最小となる$x$」は「$f'(x) = 0$となる$x$」と言い換えられます。
$f(x)$の1階微分$f'(x)$と2階微分$f''(x)$を用いて、ニュートン法の式に当てはめると式(29.5)が得られます。
勾配降下法のコードの更新式を置き換えるだけです。早速やってみましょう。
# 試行回数を指定 iters = 20 # 初期値を指定 x = 2.0 # 推移の確認用のリストを初期化 x_list_nm = [x] # ニュートン法 for i in range(iters): # 現在の値を表示 print('iter:' + str(i), x) # 値を更新 x -= gx(x) / gx2(x) # i回目の結果を記録 x_list_nm.append(x) # 閾値未満まで近付けば終了 if abs(x - 1.0) < 1e-10: break
iter:0 2.0
iter:1 1.4545454545454546
iter:2 1.1510467893775467
iter:3 1.0253259289766978
iter:4 1.0009084519430513
iter:5 1.0000012353089454
指定した回数の更新を行う前に、最小値に辿り着いています。
結果をグラフで確認します。
# ニュートン法による更新値の推移を作図 plt.figure(figsize=(8, 6)) plt.plot(x_line, y_line, label='f(x)') # 元の関数 plt.scatter([-1.0, 1.0], [-1.0, -1.0], marker='*', c='black', s=100, label='minimum val') # 最小値 plt.plot(x_list_nm, f(np.array(x_list_nm)), marker='o', label='x') # 更新値 plt.xlabel('x') plt.ylabel('f(x)') plt.suptitle("Newton's Method", fontsize=20) plt.title('iter:' + str(i + 1) + ', x=' + str(np.round(x, 3)), loc='left') plt.legend() plt.grid() plt.ylim(-2.0, 10.0) plt.show()
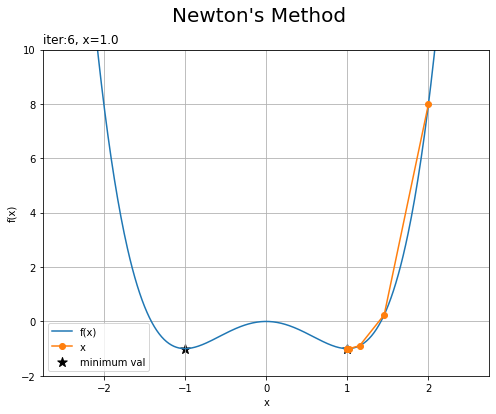
勾配降下法の結果と比較すると、1回の試行で更新される量が大きく、また最小値付近での停滞も少ないのが分かります。
他の値でも試してみましょう。
・「初期値が-2」と「初期値が0」の場合
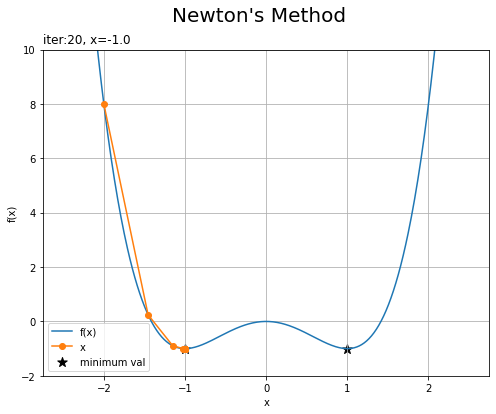
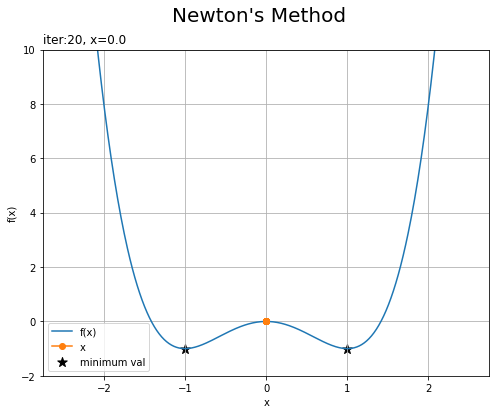
左の図は、勾配降下法のときと同じく、もう1つの最小値に辿り着いています。
右の図は、こちらも勾配降下法のときと同じく、初期値の勾配(傾き)が0のため全く更新されません。
・「初期値が0.4」と「初期値が0.55」の場合
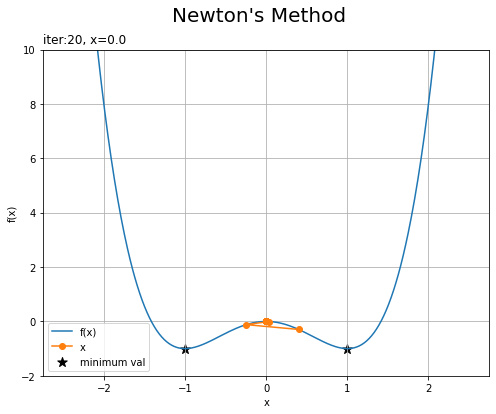
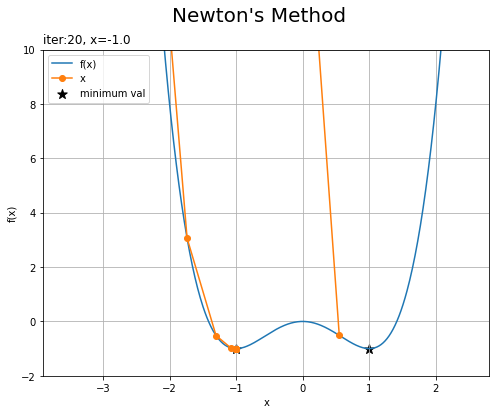
左の図は、$f(x)$の局所的最大値となる$x = 0$でも傾きが0になるので、そちらに向かっています。
右の図は、局所的最大値すらも大きく飛び越えて、最終的に遠い方の最小値に辿り着いていますね。初期値が0.4から0.8くらいの値だと直感に反する経路を辿るようです。
次は、なぜこうなるのかを(うまく示せなかったので)少しだけ見てみましょう。
・学習率の違い
勾配降下法とニュートン法の異なる点である学習率について少しだけ掘り下げます。
勾配降下法の更新式(29.4)とニュートン法の更新式(29.5)を(少し変形して)比較すると
ニュートン法では2階微分の逆数$\frac{1}{f''(x)}$が学習率に相当しているのが分かります。
$\alpha$は定数ですが、$f''(x)$は$x$によって変動します。これは、各試行における$x$の値に応じて学習率が自動で調整されると言えます。
勾配降下法とニュートン法による$x$の更新幅(更新量?変化量?)$\alpha f'(x)$と$\frac{f'(x)}{f''(x)}$を見てみましょう。
# 更新幅を比較 plt.figure(figsize=(8, 6)) plt.plot(x_line, y_line, linestyle='--', label='f(x)') # 元の関数 plt.plot(x_line, lr * gx(x_line), label="$\\alpha * f'(x)$") # 勾配降下法の更新幅 plt.plot(x_line, gx(x_line) / gx2(x_line), label="$f'(x) / f''(x)$") # ニュートン法の更新幅 plt.xlabel('x') plt.ylabel('update') plt.legend() plt.grid() plt.ylim(-1.0, 1.0) plt.show()
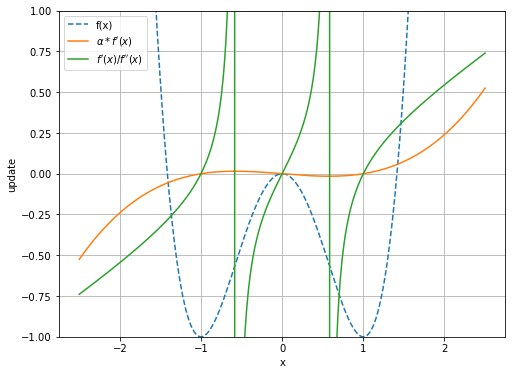
(ヘンな形をしている緑のグラフが気になるのをグッと堪えて)初期値が$x = 2$の場合(図29.5)で影響する「初期値$x = 2$から最小値となる$x = 1$まで」の範囲に注目してみましょう。
勾配降下法(オレンジ)よりもニュートン法(緑)の方がy軸の値が大きいですね。これは、1回の試行で更新する値が大きいことを意味します。また、勾配降下法では最小値の1に近付くにしたがって値が小さくなっています。このこと自体は最小値を飛び越えてしまわないためには良いことですが、最小値付近で更新が停滞するのはこのためです。これに対して、ニュートン法では最小値付近でも勾配降下法ほどは下がっていません。よって、ニュートン法の方が少ない回数で初期値に辿り着けます。
どちらの手法でもy軸の値を$x$から引くのでした。そのため、y軸の値がプラスであればx軸をマイナス方向に、マイナスであればプラス方向に移動します。なので勾配降下法では、常に局所的・大域的最小値に向かうのが分かります(グラフが判別しにくければ「関数の設定」のグラフを見てください)。しかしニュートン法では、(値が大き・小さすぎるのは置いておいて)最大値にも向かうのが分かります。
最後の例で起きた直感に反するような更新の理由は、緑のグラフが変わった形をしているからですね。$f''(x)$が0に近付くにしたがって$\frac{1}{f''(x)}$の影響が強くなっていきます(色々影響し合って0にはならないのかな?)。
最後に、元の関数や1階微分と2階微分の逆数との関係を見出したかったけど、何も考え付かなかったので諦めます。
# 学習率を比較 plt.figure(figsize=(8, 6)) plt.plot(x_line, y_line, linestyle=':', label='f(x)') # 元の関数 plt.plot(x_line, gx(x_line), label="f'(x)") # 1階微分 plt.plot(x_line, gx2(x_line), label="f''(x)") # 2階微分 plt.plot(x_line, 1.0 / gx2(x_line), label="1 / f''(x)") # 2階微分の逆数 plt.xlabel('x') plt.ylabel('update') plt.legend() plt.grid() plt.ylim(-5.0, 5.0) plt.show()
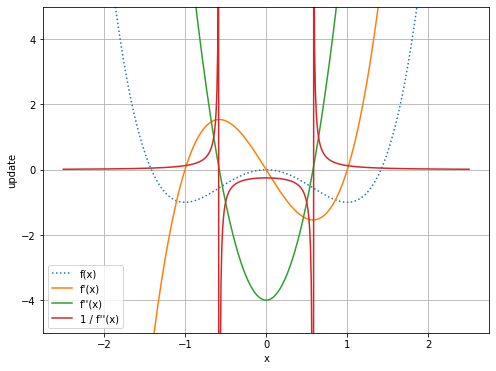
何が分かりますか?
勾配降下法とニュートン法を簡単な例を用いて比較しました。どちらの手法にも一長一短というよりも問題に対する向き不向きがあります。ニュートン法を用いて最適化を行うには2階微分が必要なので、次のステップでは、高階微分を行えるようにVariableクラスと各関数のクラスを実装し直します。
参考文献
- 斎藤康毅『ゼロから作るDeep Learning 3 ――フレームワーク編』オライリー・ジャパン,2020年.
おわりに
何だか締まらない終わり方に、、、それと、決してこの本が言葉足らずだなんて言いたいわけではなく(何よりこんなところまで掘り下げていたら話が進まないので。あと勾配降下法については1巻で詳しく取り上げられています。)、ただ図29.5を再現するついでに他の値でも試してみたら「なるほどなぁメモしとこ」となっただけです。
1・2巻のときもそうでしたが、本に書いてない事って結構激しい内容が多いんですよね。面白さやテンポと難易度が絶妙にコントロールされていると思います。その上で深掘りしたい人のためのヒントもちゃんと載っている最高の本です。
2021年6月7日は、BEYOOOOONDSの西田汐里さん18歳のお誕生日です。おめでとう!!
激幸🌶
【次ステップの内容】