はじめに
「機械学習・深層学習」初学者のための『ゼロから作るDeep Learning』の攻略ノートです。『ゼロつくシリーズ』学習の補助となるように適宜解説を加えています。本と一緒に読んでください。
ニューラルネットワーク内部の計算について、数学的背景の解説や計算式の導出を行い、また実際の計算結果やグラフで確認していきます。
この記事は、4.4.1項「勾配法」の内容です。勾配降下法の定義を説明して、数値微分による計算をPythonで実装します。
【前節の内容】
【他の記事一覧】
【この記事の内容】
4.4.1 勾配法
勾配を用いて関数の最小値または最大値を探索する手法を勾配法と言います。最小値を探索する場合は、勾配降下法と言います。
ニューラルネットワークの学習においては、勾配降下法を用いて損失関数を最小化するパラメータとなるように繰り返し更新します。
利用するライブラリを読み込みます。
# 4.4.1項で利用するライブラリ import numpy as np import matplotlib.pyplot as plt
・1変数の場合
勾配法の簡単な例として、変数が1つの場合を考えます。微分については「4.3.1-2:数値微分【ゼロつく1のノート(数学)】 - からっぽのしょこ」を参照してください。
・グラフで確認
まずは、「関数$f(x)$の最小値」と「$f(x)$上の点における微分」のとの関係をグラフで確認します。
2乗の関数$f(x) = x^2$を例とします。$x^2$の計算を行う関数を作成します。
# 2乗の関数を作成 def f(x): return x**2
作図用の$x$の値を作成します。
# x軸の値を作成 x_vals = np.arange(-20.0, 20.0, 0.1)
x_valsがx軸の値です。y軸の値はf(x_vals)で計算できます。
$f(x)$をグラフで確認しましょう。
# 2乗のグラフを作成 plt.figure(figsize=(8, 6)) # 図の設定 plt.plot(x_vals, f(x_vals), label='$y = x^2$') # 折れ線グラフ plt.xlabel('x') # x軸ラベル plt.ylabel('f(x)') # y軸ラベル plt.title('$f(x) = x^2$', fontsize=20) # タイトル plt.grid() # グリッド線 plt.show()

何度も見たグラフですね。この関数$f(x)$が最小となる変数$x$の値を機械的に見付けたいわけです。勿論グラフにしてしまえば、$x = 0$のとき$f(x) = f(0) = 0$が最小値だとすぐに分かります。ただしそれは、表示した範囲にたまたま最小値が含まれていた場合に限ります。また、ニューラルネットワークのような複雑な関数であれば、次元が大きくグラフ化できないもしくはグラフ化するための計算に非現実的な時間がかかってしまいます。グラフにして人の目で最小値を見付けられるのは、特別な場合に限ります。
そこで、勾配降下法を用いて機械的に最小値を探索します。勾配降下法では、ある点における勾配を計算して、関数の値を少しだけ減らします。関数上のごく狭い範囲のみに注目(計算)し、繰り返し更新を行うことで最小値を目指します。
「4.3.1-2:数値微分【ゼロつく1のノート(数学)】 - からっぽのしょこ」で実装した数値微分numerical_diff()を使って、$f(x)$上の点$(x, f(x))$における微分(接線の傾き)$\frac{d f(x)}{d x}$を計算します。また、切片も求めます。
# 接点を指定 x = 10.0 # 微分(傾き)を計算 dx = numerical_diff(f, x) print(dx) # 切片を計算 b = f(x) - dx * x print(b)
19.99999999995339
-99.99999999953388
この例では、$x = 10$とします。接点$(x, f(x)) = (10, 100)$における傾き$\frac{d f(x)}{d x} = 20$が求まりました。
接線をグラフで確認しましょう。
# 接線を作図 plt.figure(figsize=(8, 6)) # 図の設定 plt.plot(x_vals, f(x_vals), label='f(x)') # 対象の関数 plt.plot(x_vals, dx * x_vals + b, label="f '(x)") # 接線 plt.scatter(x, f(x)) # 接点 plt.scatter(0.0, 0.0, color='red', s=100, marker='x') # 最小値 plt.xlabel('x') # x軸ラベル plt.ylabel('f(x)') # y軸ラベル plt.suptitle('$f(x) = x^2$', fontsize=20) # 全体のタイトル plt.title('(x, f(x))=(' + str(x) + ', ' + str(np.round(f(x), 2)) + ')' + ', dx=' + str(np.round(dx, 2)), loc='left') # 微分(傾き) plt.legend() # 凡例 plt.grid() # グリッド線 plt.ylim(-50, 400) # y軸の表示範囲 plt.show()
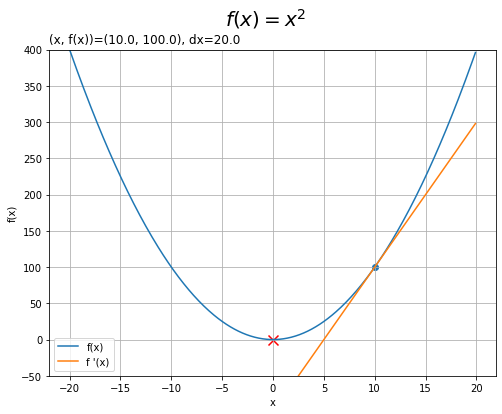
$\frac{d f(x)}{d x}$が正の値のときは、$x$をマイナス方向に動かすことで$f(x)$が小さくなるのが分かります。
同様に、$x = -5$のときも見てみましょう。
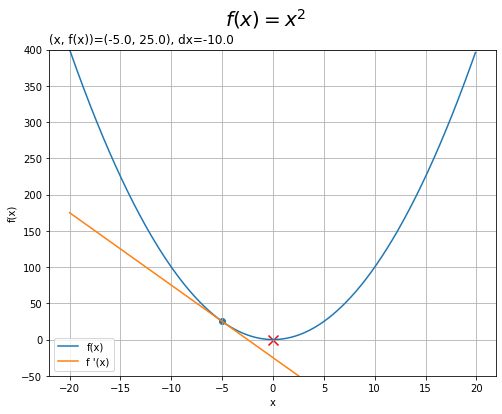
$\frac{d f(x)}{d x}$が負の値のときは、$x$を今よりプラス方向に動かすと$f(x)$が小さくなるのが分かります。
「微分$\frac{d f(x)}{d x}$」と「関数$f(x)$を小さくする方向」との関係が分かりました。また、最小値に近付くにつれて勾配が小さくなる傾向が見えます。次は、このことから勾配降下法を考えます。
・数式の確認
$\frac{d f(x)}{d x}$の符号と逆方向に$x$を変更することで、元の$x$よりも$f(x)$を小さくする(可能性のある)ことが分かりました。
そこで、$x$から$\frac{d f(x)}{d x}$を引いた値を更新値$x^{(\mathrm{new})}$とすることにします。
この式に従うと、$\frac{d f(x)}{d x}$が正の値のときは$x$をマイナス方向に変化させ、負の値のときはプラス方向に変化させることができます。また、$\frac{d f(x)}{d x}$が大きいほど大きく変化し、小さいほど小さく変化します。
しかし、$x$を動かしすぎると、$f(x)$を最小とする値を飛び越える可能性があります。この例だと、$x = -5$のとき$\frac{d f(x)}{d x} = -10$を引いた値は5なので、$f(-5) = f(5) = 25$となり変化しません。さらに、$x = 5$のとき$\frac{d f(x)}{d x} = 10$なので、$x = -5$に戻ってしまいます。
そこで、変化量を調整する項を導入します。学習幅の調整項を学習率と言い、$\eta$で表します。
この式が、1変数の場合の勾配降下法の定義式です。$\frac{d f(x)}{d x}$の$\eta$倍$x$が変化します。
ただし、この方法によって必ず最小値に辿り着けるわけではありません。次のような窪みが複数ある関数だと、最小値ではな極小値で$\frac{d f(x)}{d x} = 0$になり、それ以上更新できなくなってしまうことがあります。
# 関数を作成 def f(x): return (x + 4) * (x + 1) * (x - 1) * (x - 3) # 接点を指定 x = 2.222 # 微分(傾き)を計算 dx = numerical_diff(f, x) # 切片を計算 b = f(x) - dx * x # x軸の値を生成 x_vals = np.arange(-5.0, 4.0, 0.1) # 接線を作図 plt.figure(figsize=(8, 6)) # 図の設定 plt.plot(x_vals, f(x_vals), label='$y = x^2$') # 対象の関数 plt.scatter(x, f(x)) # 接点 plt.plot(x_vals, dx * x_vals + b) # 接線 plt.xlabel('x') # x軸ラベル plt.ylabel('f(x)') # y軸ラベル plt.title('dx=' + str(np.round(dx, 3)), loc='left') # 微分(傾き) plt.grid() # グリッド線 plt.show()

局所的最小値において傾きがほとんど0になっています。これでは値が更新されません。初期値や学習率などの設定によっては、最小値に辿り着けません。
1変数の場合の更新の様子(更新値の推移)については「ステップ29:勾配降下法とニュートン法の比較【ゼロつく3のノート(数学)】 - からっぽのしょこ」を参照してください。
ここまでは、変数が1つの場合を考えました。変数が複数になっても考え方は同じです。
・多変数の場合
多変数の場合の勾配降下法を考えます。偏微分(多変数の微分)については「4.3.3:偏微分【ゼロつく1のノート(数学)】 - からっぽのしょこ」、勾配については「4.4.0:勾配【ゼロつく1のノート(数学)】 - からっぽのしょこ」を参照してください。
・数式の確認
まずは、勾配降下法の定義式を確認します。
$n$個の変数$\mathbf{x} = (x_1, x_2, \cdots, x_n)$の関数$f(\mathbf{x})$の勾配を$\frac{\partial f(\mathbf{x})}{\partial \mathbf{x}} = (\frac{\partial f(\mathbf{x})}{\partial x_1}, \frac{\partial f(\mathbf{x})}{\partial x_2}, \cdots, \frac{\partial f(\mathbf{x})}{\partial x_n})$で表します。
このとき、$\mathbf{x}$を次の式で更新します(勾配降下法は次の式で定義されます)。
$\eta$は学習率、$\mathbf{x}^{(\mathrm{new})}$更新値です。
$\mathbf{x}$の$n$番目の項$x_n$に注目すると、更新式は次の式で表せます。
1変数の勾配降下法と同じ式の形です。
$\mathbf{x}$の更新式について、$t$回目の更新値を$x_n^{(t)}$、前回の更新値(現在の値)を$x_n^{(t-1)}$で表し、次の式で表すこともあります。
また、右辺の計算によって値を更新することを$\leftarrow$で表し、次の式で表すこともあります。
3つの式は表記が異なるだけで、同じ意味です。
・処理の確認
次に、勾配降下法で行う処理を確認します。
2乗和の関数$f(\mathbf{x}) = x_0^2 + x_1^2$を例とします。2乗和の計算を行う関数を作成します。
# 2乗和の関数を作成 def f(x): return np.sum(x**2)
変数$x$の初期値をinit_x、学習率をlr、試行回数をstep_numとして値を指定します。
# xの初期値を指定 init_x = np.array([-3.0, 4.0, 1.5]) # 学習率を指定 lr = 0.1 # 試行回数を指定 step_num = 100
この例では、初期値を$\mathbf{x} = (x_0, x_1, x_2) = (-3, 4, 1.5)$とします。Pythonのインデックスに合わせて添字を0から割り当てています。
「4.4.0:勾配【ゼロつく1のノート(数学)】 - からっぽのしょこ」で実装した数値微分による勾配numerical_gradient()を使って、$\mathbf{x}$の勾配$\frac{\partial f(\mathbf{x})}{\partial \mathbf{x}}$を計算します。
# 勾配を計算 grad = numerical_gradient(f, init_x) print(grad)
[-6. 8. 3.]
$\frac{\partial f(\mathbf{x})}{\partial \mathbf{x}} = (\frac{\partial f(\mathbf{x})}{\partial x_0}, \frac{\partial f(\mathbf{x})}{\partial x_1}, \frac{\partial f(\mathbf{x})}{\partial x_2}) = (-6, 8, 3)$が求まりました。
「初期値$\mathbf{x}$」から「学習率$\eta$で割り引いた勾配$\frac{\partial f(\mathbf{x})}{\partial \mathbf{x}}$」を引いて$\mathbf{x}$を更新します。
# 勾配降下法により値を更新:式(4.7) x = init_x - lr * grad print(x)
[-2.4 3.2 1.2]
最小値$f(\mathbf{x}) = 0$となる$\mathbf{x} = (0, 0, 0)$に近付いています。
初期値と更新値の$f(\mathbf{x})$の値を確認します。
# 関数の計算 print(f(init_x)) print(f(x))
27.25
17.440000000000428
値を更新したことで$f(\mathbf{x})$が下がりました。
以上が1回目の更新で行う処理です。for文を使って、この処理を指定した回数繰り返します。
・実装
処理の内容を確認できたので、数値微分による勾配降下法を関数として実装します。
# 勾配降下法の実装 def gradient_descent(f, init_x, lr=0.01, step_num=10): # xの初期値を設定 x = init_x # 繰り返し試行 for i in range(step_num): # 勾配を計算 grad = numerical_gradient(f, x) # 勾配降下法により値を更新:式(4.7) x -= lr * grad return x
引数として指定した初期値init_xをxに置き換えます。それにより式(4.7)の計算をx -= lr * gradと書くことができます(このような方法を代入演算と言います)。
実装した関数を試してみましょう。
# xの初期値を指定 init_x = np.array([-3.0, 4.0, 1.5]) print(f(init_x)) # 勾配降下法を計算 x = gradient_descent(f, init_x=init_x, lr=0.1, step_num=1) print(x) print(f(x))
27.25
[-2.4 3.2 1.2]
17.440000000000428
同じ設定で100回更新してみましょう。
# xの初期値を指定 init_x = np.array([-3.0, 4.0, 1.5]) print(f(init_x)) # 勾配降下法を計算 x = gradient_descent(f, init_x=init_x, lr=0.1, step_num=100) print(np.round(x, 2)) print(np.round(f(x), 2))
27.25
[-0. 0. 0.]
0.0
最小値$f(\mathbf{x}) = 0$となる$\mathbf{x} = (0, 0, 0)$を求められました。
・グラフで確認
最後に、勾配降下法による更新値の推移をグラフで確認します。2次元のグラフで可視化できるように2変数の場合を考えます。
更新値をプロットするために、更新する度に値をリストx_histryに保存し、最終的なxとともに出力するように変更しておきます。
# 勾配降下法を定義 def gradient_descent_histry(f, init_x, lr=0.01, step_num=10): # xの初期値を設定 x = init_x # 推移の確認用の受け皿を初期化 x_histry = [x.copy()] # 初期値を追加 # 繰り返し試行 for i in range(step_num): # 勾配を計算 grad = numerical_gradient(f, x) # 勾配降下法により値を更新:式(4.7) x -= lr * grad # i回目の更新値を追加 x_histry.append(x.copy()) # NumPy配列に変換して出力 return x, np.array(x_histry)
copy()でxの値を取り出して、append()でx_histryに追加します。最後に、np.array()でリストからNumPy配列に変換して出力します。
作図用の$\mathbf{x} = (x_0, x_1)$の値を作成して、2乗和を計算します。
# 作図用の値を生成 x0 = np.arange(-4.5, 4.5, 0.1) x1 = np.arange(-4.5, 4.5, 0.1) # 格子状の点に変換 X0, X1 = np.meshgrid(x0, x1) # 2乗和を計算 Z = X0**2 + X1**2
$f(\mathbf{x})$を等高線グラフで確認しましょう。
# 2乗和のグラフを作成 plt.figure(figsize=(8, 6)) # 図の設定 plt.scatter(0.0, 0.0, c='red', s=100, marker='x') # 最小値 plt.contour(X0, X1, Z) # 等高線 plt.xlabel('$x_0$') # x軸ラベル plt.ylabel('$x_1$') # y軸ラベル plt.title('$f(x) = x_0^2 + x_1^2$', fontsize=20) # タイトル plt.colorbar() # カラーバー plt.grid() # グリッド線 plt.axis('square') # アスペクト比 plt.show()
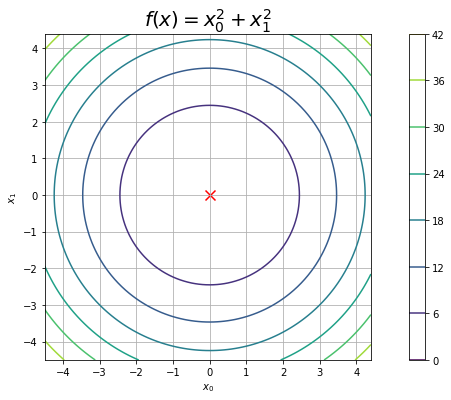
真の最小値は原点$\mathbf{x} = (0, 0)$です。
$\mathbf{x}$の初期値をinit_xとして値を指定します。
また、学習率lrと試行回数step_numを指定して、勾配降下法により$f(\mathbf{x})$を最小化する$\mathbf{x}$を探索します。
# xの初期値を指定 init_x = np.array([-3.0, 4.0]) # 学習率を指定 lr = 0.1 # 試行回数を指定 step_num = 100 # 勾配降下法による更新 x, x_histry = gradient_descent_histry(f, init_x, lr, step_num) print(x_histry[0:5]) print(x)
[[-3. 4. ]
[-2.4 3.2 ]
[-1.92 2.56 ]
[-1.536 2.048 ]
[-1.2288 1.6384]]
[-6.11110793e-10 8.14814391e-10]
初期値の点$(-3, 4)$から最小値の点$(0, 0)$に近付いているのが分かります。
xの推移を等高線グラフに重ねて表示します。
# 2乗和のグラフを作成 plt.figure(figsize=(8, 8)) # 図の設定 plt.contour(X0, X1, Z) # 等高線 plt.plot(x_histry[:, 0], x_histry[:, 1], marker='o') # 更新値の推移 plt.scatter(0.0, 0.0, c='red', s=100, marker='x') # 最小値 plt.xlabel('$x_0$') # x軸ラベル plt.ylabel('$x_1$') # y軸ラベル plt.suptitle('Gradient Method', fontsize=20) # 全体のタイトル plt.title('iter:' + str(step_num) + ', lr=' + str(lr), loc='left') # ハイパーパラメータ plt.grid() # グリッド線 plt.show()
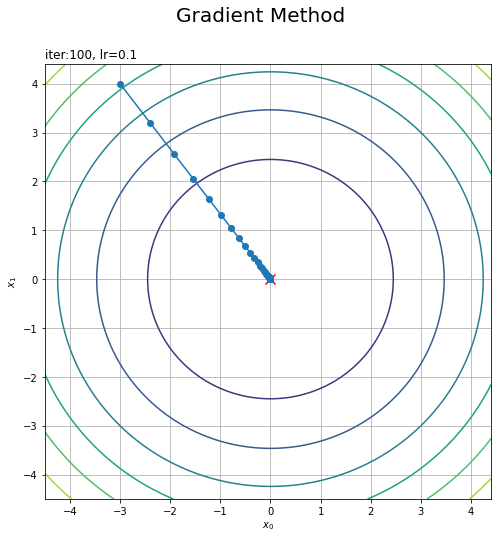
$x_0,\ x_1$の更新を繰り返すことで、$f(\mathbf{x})$が最小となる点に近付いていくのが分かります。
学習率を大きくして更新値の推移を見てみましょう。
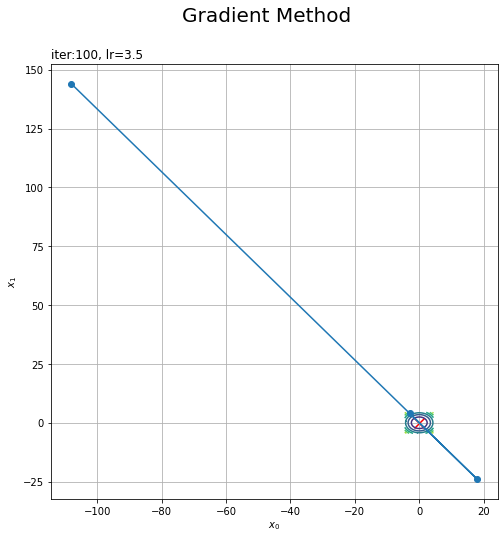
右下に小さく表示されているのが先ほどまで図いっぱいに表示されていた等高線です(空白部分は作図用に生成した値の範囲外なので描画できていないだけで、2乗和のグラフはどこまでも続いています)。
先ほどの例と同様に、1回目の更新によって最小値(原点)の方向に点が移動しています。ただし、原点を大きく飛び越えてしまっています。更新後の方が$f(\mathbf{x})$の値も大きくなっています。
2乗和の関数は、原点から離れるほど勾配も大きくなります。そのため2回目の更新では、原点に向かっていますが、更に大きく飛び越えてしまっています。
以降も同様に更新されるので、この設定では行ったり来たりを繰り返しながら発散してしまいます。
次は、学習率を小さくした場合を見てみましょう。

学習率を小さくしたことで、更新幅も小さくなりました。そのため、試行回数を増やしても初期値からほとんど変化していません。
このように、学習率が大きいと最小値を飛び越えてしまい、逆に小さいと探索に時間がかかったり辿り着けなかったりします。学習率や試行回数といったハイパーパラメータは適切に指定する必要があります。ハイパーパラメータの設定については6.5節で扱います。
また複雑な関数では、最小値ではない極小値に掴ってしまうことで正しく学習できないことがあります。より複雑な関数の場合に興味があれば「ステップ28:ローゼンブロック関数の可視化【ゼロつく3のノート(メモ)】 - からっぽのしょこ」を参照してください。
この項では、勾配降下法を実装しました。次項では、損失関数を最小にするニューラルネットワークの重みの値を勾配法を使って求めます。またこの項では、基本的な勾配降下法を解説しました。より発展させたアルゴリズムを6.1節で解説します。
参考文献

おわりに
加筆修正の際に記事を分割しました。
【次節の内容】