はじめに
「プログラミング」学習初手『ゼロから作るDeep Learning』民のための実装攻略ノートです。『ゼロつく1』学習の補助となるように適宜解説を加えています。本と一緒に読んでください。
関数やクラスとして実装される処理の塊を細かく分解して、1つずつ処理を確認しながらゆっくりと組んでいきます。
この記事は、6.1.5項「AdaGrad」の内容になります。AdaGradを説明し、Pythonで実装します。またその学習過程を確認します。
【前節の内容】
【他の節の内容】
【この節の内容】
6.1.5 AdaGrad
SGDでは、学習率を全ての要素に対して等しく与えました。AdaGradとは、各要素に適応した学習率を用いることを考えた手法です。
・更新式の確認
重みパラメータを$\mathbf{W}$、損失関数を$L$、$\mathbf{W}$に関する損失関数の勾配を$\frac{\partial L}{\partial \mathbf{W}}$とすると、AdaGradは次の式になります。
ここで$\mathbf{h}$は過去の勾配を2乗和として保持する項です(後で確認します)。また$\odot$は行列の要素ごとの掛け算を表します。
勾配によって更新した$\mathbf{h}$を用いてパラメータを更新します。
$\frac{1}{\sqrt{\mathbf{h}}}$によって、過去の勾配の情報を用いてパラメータの各要素に適合した学習率に調整します。
式(6.5),(6.6)について、$j,k$要素に注目すると次の式になります。
ちなみに$\leftarrow$は、右辺の計算によって左辺の変数に更新することを表しています。不気味であれば右肩に括弧付きの数字で更新回数を示すことで、次のように等式でも表せます。
これは$t$回目の更新によって現在の値($t-1$回目の更新値)$h_{jk}^{(t-1)},\ w_{jk}^{(t-1)}$を更新することを表しています。右肩の記号が恐ろしければ矢印の方で理解しましょう。
プログラミングっぽく$w_{jk} = w_{jk} - \eta \frac{1}{\sqrt{h_{jk}^{(t)}}} \frac{\partial L}{\partial w_{jk}^{(t-1)}}$と書くと、$\eta \frac{1}{\sqrt{h_{jk}^{(t)}}} \frac{\partial L}{\partial w_{jk}^{(t-1)}}$が0でないと式が成立しないことになるという不都合があるだけのことです。
式(6.5),(6.6)についてもう少し考えてみましょう。
式(6.3)の初回の更新式は、$h_{jk}^{(1)} = h_{jk}^{(0)} + \Bigl( \frac{\partial L}{\partial w_{jk}^{(0)}} \Bigr)^2$と表せます。(このことを今から確認するのですが、$\mathbf{h}$は過去の勾配の情報であるため初回は過去の情報がないことから)$h_{jk}$の初期値$h_{jk}^{(0)}$を0とすると、この式は
になります。
次に2回目の更新を考えます。式は$h_{jk}^{(2)} = h_{jk}^{(1)} + \Bigl( \frac{\partial L}{\partial w_{jk}^{(1)}} \Bigr)^2$ですね。この式に1回目の更新値(上の式)を代入すると
となります。
では$T$回更新を繰り返すと
となります。
これを用いると$w_{jk}$の$T$回目の更新値は
で計算できることが分かります。
つまりAdaGradでは、これまでの全ての勾配の2乗和を$\mathbf{h}$として保存します。そしてその情報を$\frac{1}{\sqrt{\mathbf{h}}}$として勾配$\frac{\partial L}{\partial \mathbf{W}}$に掛けます。$\eta$は、全ての要素の学習幅を同じ比率で調整します。これに対して$\frac{1}{\sqrt{\mathbf{h}}}$は、要素ごとに学習幅を調整します。$j,k$要素に注目すると、パラメータ$w_{jk}$に関する過去の勾配の2乗和である$\frac{1}{\sqrt{h_{jk}}}$に従って、パラメータ$w_{jk}$の学習幅を個別に調整します。
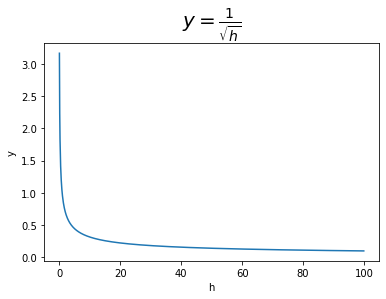
下のグラフからも分かる通り、$h_{jk}$が大きくなるほど$\frac{1}{\sqrt{h_{jk}}}$は小さくなります。また$\mathbf{h}$はどの要素も更新を繰り返す度に勾配の2乗(必ず正の値になる)を加算するため、徐々に(勾配が0ならそのままか)大きくなります。つまり更新が進むと$\frac{1}{\sqrt{\mathbf{h}}}$が小さくなり、その地点の勾配の値を大きく割り引き学習幅が狭くなります。これは、次の2つの働きがあります。
1つ目は、始めの頃は最小値から遠いため大幅に値を更新し、更新が進んだ最小値付近では最小値を飛び越えてしまわないように繊細に探索する必要があることに対応するためです。始めの頃は$\mathbf{h}$が小さい($\frac{1}{\sqrt{\mathbf{h}}}$が大きい)ため、大幅に学習を進めます。更新値を繰り返すに従って$\mathbf{h}$が大きく($\frac{1}{\sqrt{\mathbf{h}}}$が小さく)なるため、少しずつ学習を進めるようになります。ただし無限に更新を繰り返すと、更新幅が0になってしまうことを意味します。
2つ目は、勾配が大きい要素については何度も学習機会があると捉えられることから細かく何度も更新し、逆に勾配が小さいあるいは観測されにくく勾配が0となることが多い要素については僅かな学習機会を活かすことに対応するためです。勾配が大きい要素は$\frac{1}{\sqrt{\mathbf{h}}}$が小さくなるため学習率が小さくなり、勾配が小さい要素は$\frac{1}{\sqrt{\mathbf{h}}}$が大きいままなので学習率が大きくなります。
ただし実装上は0除算とならないように、$\epsilon = 10^{-7}$のような微小な値を加えて$\frac{1}{\sqrt{\mathbf{h}} + \epsilon}$とします。
# ルートhのイメージ h = np.arange(0.1, 100, 0.1) plt.plot(h, 1 / np.sqrt(h)) plt.xlabel("h") plt.ylabel("y") plt.title("$y = \\frac{1}{\\sqrt{h}}$", fontsize=20) plt.show()
・実装
更新式の確認ができたので、AdaGradを実装します。
# この項で利用するライブラリを読み込む import numpy as np import matplotlib.pyplot as plt
学習率$\eta$は、インスタンスの作成時に引数lrとして指定し、インスタンス変数として値を保持します。デフォルト値として、よく用いられる値を設定しておきます。
$\mathbf{h}$はパラメータ$\mathbf{W}$と同じ形状にする必要があるため、インスタンス作成時はNoneを定義してインスタンス変数だけ作成しておきます。更新メソッドの使用時に渡されるパラメータ(とパラメータごとの勾配)と同じ形状で全ての要素が0の変数を作成し、ディクショナリ型のインスタンス変数hに格納します。
# AdaGradの実装 class AdaGrad: # インスタンス変数を定義 def __init__(self, lr=0.01): self.lr = lr # 学習率 self.h = None # 過去の勾配の2乗和 # パラメータの更新メソッドを定義 def update(self, params, grads): # hの初期化 if self.h is None: # 初回のみ self.h = {} for key, val in params.items(): self.h[key] = np.zeros_like(val) # 全ての要素が0 # パラメータごとに値を更新 for key in params.keys(): self.h[key] += grads[key] * grads[key] # 式(6.5) params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7) # 式(6.6)
更新式に従いパラメータごとに値を更新します。ただし0除算にならないように、分母に1e-7を加算しておきます。パラメータと勾配はどちらもディクショナリ変数として更新メソッド.update()の使用時に引数に指定します。
・アルゴリズムの確認
AdaGradにより関数
の最小値となる$x,\ y$を探索します。またこの関数の勾配(偏微分)は
になります。
まずは関数(6.2)とその勾配をそれぞれ関数として定義しておきます。
# 式(6.2) def f(x, y): return x ** 2 / 20.0 + y ** 2 # 式(6.2)の勾配(偏微分) def df(x, y): # 偏微分 dx = x / 10.0 # df / dx dy = 2.0 * y # df / dy return dx, dy # (値を2つ出力!)
元の関数は作図に、勾配はもちろんパラメータの更新に利用します。
ちなみにこの関数を等高線図にすると次のようになります。
# 等高線用の値 x = np.arange(-10, 10, 0.01) # x軸の値 y = np.arange(-5, 5, 0.01) # y軸の値 X, Y = np.meshgrid(x, y) # 格子状の点に変換 Z = f(X, Y) # 作図 plt.contour(X, Y, Z) # 等高線 plt.plot(0, 0, '+') # 最小値の点 plt.xlim(-10, 10) # x軸の範囲 plt.ylim(-10, 10) # y軸の範囲 plt.xlabel("x") # x軸ラベル plt.ylabel("y") # y軸ラベル plt.title("$f(x, y) = \\frac{1}{20} x^2 + y^2$", fontsize=20) # タイトル plt.show()

原点がこの関数の最小値になります。また原点付近が横に広くなだらかに(勾配が小さく)なっていることが確認できます。
初期値は点$(-7, 2)$とします。これまでと同様に、パラメータ(変数)params、パラメータごとの勾配gradsのディクショナリ変数を作成して、パラメータ名をキーとして値を格納します。
学習率を指定して、AdaGradクラスのインスタンスを作成します。
# パラメータの初期値を指定 params = {} params['x'] = -7.0 params['y'] = 2.0 # 勾配の初期値を指定 grads = {} grads['x'] = 0 grads['y'] = 0 # 学習率を指定 lr = 1.5 # インスタンスを作成 optimizer = AdaGrad(lr=lr)
試行回数を指定して、学習を行います。また、パラメータの更新値を記録するためのリスト型の変数を用意しておきます。値の追加は.append()を使います。
# 試行回数を指定 iter_num = 30 # 更新値の記録用リストを初期化 x_history = [] y_history = [] # 初期値を保存 x_history.append(params['x']) y_history.append(params['y']) # 関数の最小値を探索 for _ in range(iter_num): # 勾配を計算 grads['x'], grads['y'] = df(params['x'], params['y']) # パラメータを更新 optimizer.update(params, grads) # パラメータを記録 x_history.append(params['x']) y_history.append(params['y'])
勾配を計算し、gradsに格納している値をそれぞれ上書きします。そしてAdaGradクラスの更新メソッド.update()にparamsとgradsを指定して、パラメータを更新します。
更新値の推移を先ほどの等高線グラフに重ねて確認しましょう。
# 作図 plt.plot(x_history, y_history, 'o-') # パラメータの推移 plt.contour(X, Y, Z) # 等高線 plt.plot(0, 0, '+') # 最小値の点 plt.xlim(-10, 10) # x軸の範囲 plt.ylim(-10, 10) # y軸の範囲 plt.xlabel("x") # x軸ラベル plt.ylabel("y") # y軸ラベル plt.title("AdaGrad", fontsize=20) # タイトル plt.text(6, 7.5, "$\\eta=$" + str(lr) + "\niteration:" + str(iter_num)) # メモ plt.show()
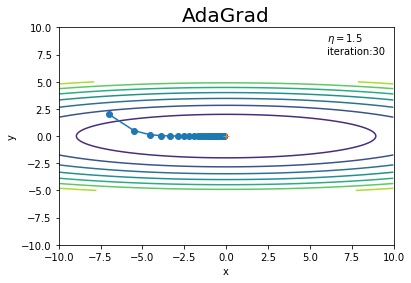
SGDよりも、最小値の点に向かって効率的な経路を辿っています(図6-6)。
学習率や試行回数を変更して試してみましょう!

ハイパーパラメータをSGDのときと同じの値にすると、最小値まで辿り着けませんでした。勿論対象となる関数によって結果は変わります。

SGDでは学習率が大きいと発散してしまいましたが、AdaGradでは$\frac{1}{\sqrt{\mathbf{h}}}$の調整機能によって発散せずに最小値に辿り着いています。
以上で、各要素の学習係数を適応的に調整して学習を行うAdaGradを実装できました。次は、AdaGradの問題点である学習を無限に繰り返すと更新量が0になってしまうことに対応したPMSPropを説明します。
参考文献
- 斎藤康毅『ゼロから作るDeep Learning』オライリー・ジャパン,2016年.
おわりに
次は本で名前だけ出てきたRSMPropをやります。この手法を知っておいた方が、Adamを理解しやすいためです。あと実はマスターデータの方にはRSMPropの実装例があります。これがなければ流石に飛ばしました。
【次節の内容】