はじめに
『ゼロから作るDeep Learning 2――自然言語処理編』の初学者向け【実装】攻略ノートです。『ゼロつく2』学習の補助となるように適宜解説を加えています。本と一緒に読んでください。
本の内容を1つずつ確認しながらゆっくりと組んでいきます。
この記事は、7.3.3項「Seq2seqクラス」の内容です。seq2seqの処理を解説して、Pythonで実装します。
【前節の内容】
【他の節の内容】
【この節の内容】
7.2.4 足し算データセット
7章で実装するseq2seqの学習では、時系列データとして足し算データセットを利用します。足し算データセットの読み込みには、実装済みのモジュールsequenceを使います。sequenceは、「dataset」フォルダの「sequence.py」に実装されています。
# 7.2.4節で利用するライブラリ import numpy as np # 実装済みクラスの読み込み用の設定 import sys sys.path.append('C://Users//「ユーザー名」//Documents//・・・//deep-learning-from-scratch-2-master') # 足し算データセットの読み込み用クラス from dataset import sequence
sequenceクラスのload_data()で足し算データセットを、get_vocab()で文字と文字IDの変換用のディクショナリ変数を読み込めます。
# 足し算データセットを読み込み (x_train, t_train), (x_test, t_test) = sequence.load_data('addition.txt', seed=1984) print(x_train.shape) print(t_train.shape) print(x_test.shape) print(t_test.shape) # 文字と文字IDの変換用ディクショナリ変数を読み込み char_to_id, id_to_char = sequence.get_vocab() print(char_to_id) print(id_to_char)
(45000, 7)
(45000, 5)
(5000, 7)
(5000, 5)
{'1': 0, '6': 1, '+': 2, '7': 3, '5': 4, ' ': 5, '_': 6, '9': 7, '2': 8, '0': 9, '3': 10, '8': 11, '4': 12}
{0: '1', 1: '6', 2: '+', 3: '7', 4: '5', 5: ' ', 6: '_', 7: '9', 8: '2', 9: '0', 10: '3', 11: '8', 12: '4'}
訓練データが4万5千個、テストデータは5千個用意されています。(文字と文字IDの対応関係のルールが謎??)
入力データと教師データを確認しておきます。
# 入力データを確認 print(x_train[:5]) # 教師データを確認 print(t_train[:5])
[[ 3 0 2 0 0 11 5]
[ 4 0 9 2 8 8 10]
[ 1 1 2 3 9 0 5]
[11 11 4 2 9 5 5]
[11 9 2 10 9 9 5]]
[[ 6 0 11 7 5]
[ 6 3 10 10 5]
[ 6 3 1 3 5]
[ 6 11 11 4 5]
[ 6 10 11 9 5]]
入力データは7個、教師データは5個の要素で構成されています。
入力・教師データを人が見て分かる形式(文字列)に変換します。
# 入力データを変換 print(x_train[0]) # 0番目のデータ print([id_to_char[c] for c in x_train[0]]) # 文字IDを文字に変換 print(''.join([id_to_char[c] for c in x_train[0]])) # 文字を結合 # 教師データを変換 print(t_train[0]) # 0番目のデータ print([id_to_char[c] for c in t_train[0]]) # 文字IDを文字に変換 print(''.join([id_to_char[c] for c in t_train[0]])) # 文字を結合
[ 3 0 2 0 0 11 5]
['7', '1', '+', '1', '1', '8', ' ']
71+118
[ 6 0 11 7 5]
['_', '1', '8', '9', ' ']
_189
入力データが足し算の式$71+118$、教師データが足し算の答$189$となっているのを確認できました。教師データの_は、区切り文字です。
この項では、足し算データセットを確認しました。7.3-4節では、時系列データ(足し算の式)を入力して、時系列データ(足し算の答)に変換することを目指します。つまり、数値データとして式を計算するのではなく、あくまで文字列として式を渡して答を導き出します。
足し算データセット自体は、7.3.3項以降で利用します。
7.3.3 Seq2seqクラス
7.3.1-2項で実装した2つのRNN(EncoderとDecoder)を組み合わせてseq2seqを実装します。seq2seqは、文章などの時系列データを別の時系列データに変換します。
# 7.3.3項で利用するライブラリ import numpy as np
seq2seqの実装には、7.3節で実装したEncoder・Decoderと5.4.2.3項で実装したTime Softmax with Lossレイヤを利用します。そのため、クラス定義を再実行するか、次の方法で実装済みのクラスを読み込む必要があります。EncoderとDecoderは、「ch07」フォルダ内の「seq2seq.py」ファイルに実装されています。RNNで用いるレイヤのクラスは、「common」フォルダ内の「time_layers.py」ファイルに実装されています。
# 実装済みクラスの読み込み用の設定 import sys sys.path.append('C://Users//「ユーザー名」//Documents//・・・//deep-learning-from-scratch-2-master') # 実装済みのレイヤを読み込み from ch07.seq2seq import Encoder # 7.3.1項 from ch07.seq2seq import Decoder # 7.3.2項 from common.time_layers import TimeSoftmaxWithLoss # 5.4.2.3項
「deep-learning-from-scratch-2-master」フォルダにパスを設定しておく必要があります。
・処理の確認
図7-14・7-17・7-18を参考にして、seq2seqで行う処理を確認していきます。
ここからは、7.2.4項で確認した足し算データセットを利用します。そのため単語・単語IDではなく文字・文字IDと呼ぶことにします。
・モデルの設定
まずは、RNNを構築します。
データとパラメータの形状に関する値を設定します。
# データとパラメータの形状に関する値を指定 N = 6 # バッチサイズ V = len(char_to_id) # 文字の種類数 D = 15 # 単語ベクトル(Embedレイヤの中間層)のサイズ H = 10 # 隠れ状態(LSTMレイヤの中間層)のサイズ print(V)
13
時系列サイズ$T$は、EncoderとDecoderで異なるため値を設定せず、それぞれの入力データから自動で判別されるように各レイヤが実装されています。
Encoderには、足し算の式データx_train(訓練用)またはx_test(テスト用)を入力します。学習時には、ここからバッチサイズ分を取り出したものをEncoderの入力データ$\mathbf{xs}^{(\mathrm{Encoder})} = (x_{0,0}^{(\mathrm{Encoder})}, \cdots, x_{N-1,T-1}^{(\mathrm{Encoder})})$とします。この時系列サイズは$T = 7$です。
# Encoderの入力データを取得 encoder_xs = x_train[:N] print(encoder_xs) print(encoder_xs.shape)
[[ 3 0 2 0 0 11 5]
[ 4 0 9 2 8 8 10]
[ 1 1 2 3 9 0 5]
[11 11 4 2 9 5 5]
[11 9 2 10 9 9 5]
[ 1 2 0 1 3 5 5]]
(6, 7)
各要素の値は文字IDを示しています。
Decoderには、足し算の答データt_train(訓練用)とt_test(テスト用)を入力します。RNNでは、時系列サイズ$T$のデータ(文字列)を1時刻(1文字)ずつ入力していき、それぞれ次の時刻のデータ(文字)を予測するのでした。そのため、t_train・t_testの最後の文字には予測すべき次の文字がないので入力データには含めません。逆に、最初の文字には1つ前の文字がないので教師データには含めないのでした。
こちらも学習時には、(行方向に)バッチサイズ分のデータを取り出します。取り出したデータから更に、最後の列を除いたものをDecoderの入力データ$\mathbf{xs}^{(\mathrm{Decoder})} = (x_{0,0}^{(\mathrm{Decoder})}, \cdots, x_{N-1,T-1}^{(\mathrm{Decoder})})$、最初の列を除いたものを教師データ$\mathbf{ts} = (t_{0,0}, \cdots, t_{N-1,T-1})$とします。この時系列サイズは$T = 4$です。
# Decoderの入力データを取得 decoder_xs = t_train[:N, :-1] # 最後を除く print(decoder_xs) print(decoder_xs.shape) # Decoderの教師ラベルを取得 decoder_ts = t_train[:N, 1:] # 最初を除く print(decoder_ts) print(decoder_ts.shape)
[[ 6 0 11 7]
[ 6 3 10 10]
[ 6 3 1 3]
[ 6 11 11 4]
[ 6 10 11 9]
[ 6 0 3 10]]
(6, 4)
[[ 0 11 7 5]
[ 3 10 10 5]
[ 3 1 3 5]
[11 11 4 5]
[10 11 9 5]
[ 0 3 10 5]]
(6, 4)
こちらも各要素の値は文字IDを示しています。また、文字ID6は区切り文字_、5は空白を示します。
それぞれのインスタンスを作成します。
# Encoderのインスタンスを作成 encoder = Encoder(V, D, H) # Decoderのインスタンスを作成 decoder = Decoder(V, D, H) # Time Softmax with Lossレイヤのインスタンスを作成 softmax_layer = TimeSoftmaxWithLoss()
これでseq2seqを構築できました。次は順伝播の処理の確認をします。
・順伝播の計算
encoder_xsをEncoderに入力して、順伝播を計算します。
# Encoderの順伝播を計算 h = encoder.forward(encoder_xs) print(np.round(h, 3)) print(h.shape)
[[ 0.003 0.003 -0.009 -0.009 0. -0.002 -0.009 0.002 0.001 -0.007]
[ 0.002 0.003 -0.003 -0.004 0.002 -0.005 -0.008 -0.001 -0.003 -0.001]
[ 0.002 0.003 -0.009 -0.003 0.001 -0.003 -0.004 0.003 0.003 -0.006]
[-0. 0.005 -0.006 0.002 -0.003 -0.007 0. 0.001 0.005 -0.009]
[-0.001 0.004 -0.004 0.002 -0.004 -0.006 0. 0.002 0.004 -0.009]
[ 0.001 0.006 -0.009 -0. -0.001 -0.007 -0.001 0. 0.005 -0.009]]
(6, 10)
入力データ$\mathbf{xs}^{(\mathrm{Encoder})}$が、パラメータによって重み付けされ隠れ状態$\mathbf{h}_{T-1}^{(\mathrm{Encoder})} = (h_{0,T-1,0}^{(\mathrm{Encoder})}, \cdots, h_{N-1,T-1,H-1}^{(\mathrm{Encoder})})$にエンコードされました。
decoder_xsとEncoderの出力hをDecoderに入力して、順伝播を計算します。
# Decoderの順伝播を計算 score = decoder.forward(decoder_xs, h) print(np.round(score[0, 0, :], 3)) print(score.shape)
[ 0.001 0.001 0.001 -0. -0. 0.002 -0.002 0.001 -0.002 -0.
-0.003 0.001 0. ]
(6, 4, 13)
Time Affineレイヤの出力であるスコア$\mathbf{ys} = (y_{0,0,0}, \cdots, y_{N-1,T-1,V-1})$が求まりました。
スコアscoreと教師データdecoder_tsをTime Softmax with Lossレイヤに入力して、順伝播を計算します。
# Time Softmax with Lossレイヤの順伝播を計算 loss = softmax_layer.forward(score, decoder_ts) print(loss)
2.5643650690714517
損失$L$が求まりました。
以上が順伝播の処理です。続いて、逆伝播の処理を確認します。
・逆伝播の計算
Time Softmax with Lossレイヤの逆伝播の入力は$\frac{\partial L}{\partial L} = 1$です。これを入力して、逆伝播を計算します。
# 逆伝播の入力 dL = 1 # Time Softmax with Lossレイヤの逆伝播を計算 dscore = softmax_layer.backward(dL) print(np.round(dscore[0, 0, :], 3)) print(dscore.shape)
[-0.038 0.003 0.003 0.003 0.003 0.003 0.003 0.003 0.003 0.003
0.003 0.003 0.003]
(6, 4, 13)
スコアの勾配$\frac{\partial L}{\partial \mathbf{ys}} = \Bigl( \frac{\partial L}{\partial y_{0,0,0}}, \cdots, \frac{\partial L}{\partial y_{N-1,T-1,V-1}} \Bigr)$が求まりました。$\frac{\partial L}{\partial \mathbf{ys}}$をDecoderに入力します。
dscoreをDecoderに入力して、逆伝播を計算します。
# Decoderの逆伝播を計算 dh = decoder.backward(dscore) print(np.round(dh, 3)) print(dh.shape)
[[-0.003 0.002 -0.001 0.005 0.001 0.003 -0.004 0.008 -0.002 -0. ]
[-0.002 -0.004 0. -0.002 -0.003 -0.007 -0.005 -0.007 0.004 -0.012]
[ 0. -0.003 0.004 -0.001 0.002 -0.008 -0.005 -0.004 0.003 -0.006]
[ 0.002 -0.004 0.001 0.002 0.001 0.002 0. 0.012 0.001 -0.004]
[ 0.001 -0.002 -0.003 -0. -0.004 -0.002 0.001 0.005 0.003 -0.006]
[-0.004 0.001 -0.001 0.003 -0.001 -0.002 -0.007 -0.002 0. -0.005]]
(6, 10)
Encoderの$T-1$番目の隠れ状態$\mathbf{h}_{T-1}$の勾配$\frac{\partial L}{\partial \mathbf{h}_{T-1}^{(\mathrm{Encoder})}} = \Bigl( \frac{\partial L}{\partial h_{0,T-1,0}^{(\mathrm{Encoder})}}, \cdots, \frac{\partial L}{\partial h_{N-1,T-1,H-1}^{(\mathrm{Encoder})}} \Bigr)$が求まりました。$\frac{\partial L}{\partial \mathbf{h}_{T-1}^{(\mathrm{Encoder})}}$をEncoderに入力します。
Decoderの出力dhをEncoderに入力して、逆伝播を計算します。
# Encoderの逆伝播を計算 dxs = encoder.backward(dh) print(dxs)
None
Encoderは勾配を出力しません(Noneを返します)。
・文章の生成
学習を行ってはいませんが、テストデータを使って予測(解答の生成)をしてみましょう。
x_testから足し算の式データを1つ取り出てquestionします。questionをEncoderに入力して、順伝播の計算をします。
# 足し算の式を取得 question = x_test[[0]] print(question) print(question.shape) # 足し算の式をエンコード h = encoder.forward(question) print(np.round(h, 3)) print(h.shape)
[[ 3 3 2 11 4 5 5]]
(1, 7)
[[ 0.002 0.005 -0.007 0.001 -0.003 -0.007 -0.003 0. 0.004 -0.01 ]]
(1, 10)
足し算の式がエンコードされh(隠れ状態)として出力されました。
t_testからも足し算の答データを1つ取り出します。RNNに入力するのは最初の文字(区切り文字)のIDだけです。これをstart_idとします。最初の文字以外が式の答なのでcorrectとして、生成した解答が正しいか判定するのに使います。
# 区切り文字のIDを取得 start_id = t_test[0, 0] print(start_id) # 足し算の答を取得 correct = t_test[0, 1:] print(correct) print(correct.shape) # 解答すべき文字数を取得 sample_size = len(correct) print(sample_size)
6
[0 1 8 5]
(4,)
4
サンプリングする文字数は正答の文字数から取得しますが、足し算の答の桁は空白で埋められているため正答の桁数が分かるわけではありません。
hと区切り文字のIDstart_idをDecoderに入力して、解答を生成します。
# 解答を生成 guess = decoder.generate(h, start_id, sample_size) print(guess) # 正誤を判定 print(guess == list(correct))
[5, 0, 4, 5]
False
generate()の返り値はリストです。そこで、NumPy配列である正答correctをリストに変換してから解答guessと比較しています。
Decoderにはhとstart_idを入力しますが、最初の文字は区切り文字なので答に関する情報を持ちません。つまり、エンコードされた式の情報のみから解答を生成しています。
以上がseq2seqで行う処理です。
・実装
処理の確認ができたので、seq2seqをクラスとして実装します。
# seq2seqの実装 class Seq2seq: # 初期化メソッド def __init__(self, vocab_size, wordvec_size, hidden_size): # 変数の形状に関する値を取得 V, D, H = vocab_size, wordvec_size, hidden_size # インスタンスを作成 self.encoder = Encoder(V, D, H) self.decoder = Decoder(V, D, H) self.softmax = TimeSoftmaxWithLoss() # パラメータと勾配をリストに格納 self.params = self.encoder.params + self.decoder.params # パラメータ self.grads = self.encoder.grads + self.decoder.grads # 勾配 # 順伝播メソッド def forward(self, xs, ts): # Decoder用のデータを作成 decoder_xs = ts[:, :-1] # 入力データ:(最後を除く) decoder_ts = ts[:, 1:] # 教師データ:(最初を除く) # 各レイヤの順伝播を計算 h = self.encoder.forward(xs) score = self.decoder.forward(decoder_xs, h) loss = self.softmax.forward(score, decoder_ts) return loss # 逆伝播メソッド def backward(self, dout=1): # 各レイヤの逆伝播を逆順に計算 dout = self.softmax.backward(dout) dh = self.decoder.backward(dout) dout = self.encoder.backward(dh) return dout # 文章生成メソッド def generate(self, xs, start_id, sample_size): # 足し算の式をエンコード h = self.encoder.forward(xs) # 解答を生成 sampled = self.decoder.generate(h, start_id, sample_size) return sampled
この実装ではしませんでしたが本の実装例のようにBaseModelクラスを継承すると、学習済みのパラメータの保存メソッドsave_params()と読込メソッドload_params()が継承されます。
実装したクラスを試してみましょう。
インスタンスを作成します。
# seq2seqのインスタンスを作成
model = Seq2seq(V, D, H)
訓練データからバッチサイズのデータを取り出します。
# バッチデータを取得 batch_x = x_train[:N] batch_t = t_train[:N] print(batch_x) print(batch_x.shape) print(batch_t) print(batch_t.shape)
[[ 3 0 2 0 0 11 5]
[ 4 0 9 2 8 8 10]
[ 1 1 2 3 9 0 5]
[11 11 4 2 9 5 5]
[11 9 2 10 9 9 5]
[ 1 2 0 1 3 5 5]]
(6, 7)
[[ 6 0 11 7 5]
[ 6 3 10 10 5]
[ 6 3 1 3 5]
[ 6 11 11 4 5]
[ 6 10 11 9 5]
[ 6 0 3 10 5]]
(6, 5)
batch_xはEncoderに、batch_tは入力データと教師データに分割されてそれぞれDecoderとTime Softmax with Lossレイヤに入力されます。
順伝播を計算します。
# 順伝播を計算 loss = model.forward(batch_x, batch_t) print(loss)
2.565293629964193
損失$L$が求まりました。
逆伝播を計算します。
# 逆伝播を計算 dx = model.backward(dout=1) print(dx)
None
インスタンス内に各レイヤのパラメータの勾配が保存されます。確率的勾配降下法により、それぞれ勾配を用いてパラメータを更新します。
テストデータを入力データ用に加工して、解答を生成します。
# 足し算の式を取得 question = x_test[[0]] print(question) print(''.join([id_to_char[c_id] for c_id in question.flatten()])) # 区切り文字のIDを取得 start_id = t_test[0, 0] # 解答すべき文字数を取得 sample_size = len(correct) # 解答を生成 guess = model.generate(question, start_id, sample_size) print(guess) print(''.join([id_to_char[c_id] for c_id in guess]))
[[ 3 3 2 11 4 5 5]]
77+85
[2, 0, 8, 4]
+125
足し算の式(時系列データ)を足し算の答(時系列データ)に変換できました。テストデータではなく訓練データでも行えます。
解答が正しい答になっているか調べましょう。
# 足し算の答を取得 correct = t_test[0, 1:] print(correct) print(''.join([id_to_char[c_id] for c_id in correct])) # 正誤を判定 print(guess == list(correct))
[0 1 8 5]
162
False
学習を行っていないので、解答はデタラメです。
以上でseq2seqを実装できました。次項では、seq2seqの学習を行います。
7.3.4 seq2seqの評価
足し算データセットを用いて、seq2seqの学習を行います。
# 7.3.4項で利用するライブラリ import numpy as np import matplotlib.pyplot as plt
この例では、最適化手法にAdamを使います。また学習処理には、1.4.4項で実装したTrainerを使います。そのため、クラス定義を再実行するか、次の方法で実装済みのクラスを読み込む必要があります。それぞれ「common」フォルダ内の「optimizer.py」ファイルと「trainer.py」ファイルに実装されています。Adamについては、1巻の6.1.6項を参照してください。
# 実装済みクラスの読み込み用の設定 import sys sys.path.append('C://Users//「ユーザー名」//Documents//・・・//deep-learning-from-scratch-2-master') # 実装済みのクラスを読み込み from common.optimizer import Adam # 最適化手法 from common.trainer import Trainer # 学習処理:1.4.4項
「deep-learning-from-scratch-2-master」フォルダにパスを設定しておく必要があります。
ハイパーパラメータを設定します。
# 単語の種類数(EmbedレイヤとAffineレイヤのニューロン数)を取得 vocab_size = len(char_to_id) # 単語ベクトルのサイズ(Embedレイヤのニューロン数)を指定 wordvec_size = 16 # 隠れ状態のサイズ(LSTMレイヤのニューロン数)を指定 hidden_size = 128 # バッチサイズを指定 batch_size = 128 # エポック当たりの試行回数を指定 max_epoch = 25 # 勾配の閾値を指定 max_grad = 5.0
それぞれインスタンスを作成します。
# seq2seqのインスタンスを作成 model = Seq2seq(vocab_size, wordvec_size, hidden_size) # 最適化手法のインスタンスを作成 optimizer = Adam() # 学習処理用のインスタンスを作成 trainer = Trainer(model, optimizer)
学習処理はTrainerクラスの学習メソッドfit()で行います。バッチデータの切り分けやパラメータの更新も行われます。詳しくは1.4.4項を参照してください。
1エポックごとにテストデータに対する正解率を測ります。結果をacc_listに記録します。
# 正解率の記録用のリストを初期化 acc_list = [] # 繰り返し試行 for epoch in range(max_epoch): # 学習 trainer.fit(x_train, t_train, max_epoch=1, batch_size=batch_size, max_grad=max_grad) # 正解数を初期化 correct_num = 0 # 精度を測定 for n in range(len(x_test)): # データを取得 question = x_test[[n]] # Encoderの入力データ(足し算の式) start_id = t_test[n, 0] # Decoderの入力データの最初の文字(区切り文字) correct = t_test[n, 1:] # 教師データ(足し算の答) # 解答を生成 guess = model.generate(question, start_id, len(correct)) # 正解数をカウント if guess == list(correct): # 解答と正答が一致したら correct_num += 1 # 正解率を計算 acc = float(correct_num) / len(x_test) acc_list.append(acc) # 途中経過を表示 print('val acc:' + str(acc * 100))
| epoch 1 | iter 1 / 351 | time 0[s] | loss 2.57
| epoch 1 | iter 21 / 351 | time 0[s] | loss 2.53
| epoch 1 | iter 41 / 351 | time 1[s] | loss 2.17
| epoch 1 | iter 61 / 351 | time 1[s] | loss 1.94
| epoch 1 | iter 81 / 351 | time 2[s] | loss 1.90
| epoch 1 | iter 101 / 351 | time 3[s] | loss 1.87
| epoch 1 | iter 121 / 351 | time 3[s] | loss 1.86
| epoch 1 | iter 141 / 351 | time 4[s] | loss 1.85
| epoch 1 | iter 161 / 351 | time 5[s] | loss 1.83
| epoch 1 | iter 181 / 351 | time 5[s] | loss 1.79
| epoch 1 | iter 201 / 351 | time 6[s] | loss 1.77
| epoch 1 | iter 221 / 351 | time 7[s] | loss 1.78
| epoch 1 | iter 241 / 351 | time 7[s] | loss 1.76
| epoch 1 | iter 261 / 351 | time 8[s] | loss 1.76
| epoch 1 | iter 281 / 351 | time 9[s] | loss 1.75
| epoch 1 | iter 301 / 351 | time 9[s] | loss 1.74
| epoch 1 | iter 321 / 351 | time 10[s] | loss 1.74
| epoch 1 | iter 341 / 351 | time 11[s] | loss 1.73
val acc:0.16
(省略)
| epoch 25 | iter 261 / 351 | time 9[s] | loss 0.73
| epoch 25 | iter 281 / 351 | time 9[s] | loss 0.74
| epoch 25 | iter 301 / 351 | time 10[s] | loss 0.75
| epoch 25 | iter 321 / 351 | time 11[s] | loss 0.74
| epoch 25 | iter 341 / 351 | time 12[s] | loss 0.79
val acc:7.5600000000000005
eval_seq2seq()を使うと、どのような解答を行っているのかを表示してくれます。
記録した正解率の推移をグラフにします。
# 正解率の推移をグラフ化 plt.figure(figsize=(9, 6)) plt.plot(1 + np.arange(len(acc_list)), acc_list, marker='o') plt.xlabel('epoch') plt.ylabel('accuracy') plt.title('seq2seq', fontsize=20) plt.ylim(0, 1) # y軸の表示範囲 plt.grid() # グリッド線 plt.show()
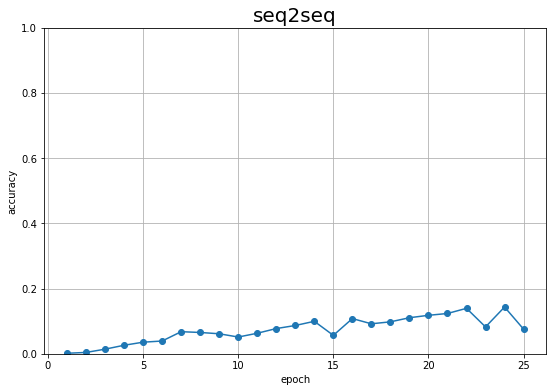
正解率が上がっていません。つまり、うまく学習できていないか、あるいは更に学習時間がかかります。
この節では、seq2seqを実装しました。しかしうまく学習できませんでした。そこで次節では、入力データに対する工夫と、seq2seq自体の改良を行います。
参考文献
- 斎藤康毅『ゼロから作るDeep Learning 2――自然言語処理編』オライリー・ジャパン,2018年.
おわりに
時系列サイズの扱いとかうまいこと組まれてるんだなぁ。色々と分からないままだったことが解決できて、綺麗に伏線が回収されたような心地です。
2021年3月16日は、ハロープロジェクトの末っ子グループBEYOOOOONDSの高瀬くるみさん22歳のお誕生日!
とりあえずビヨ曲を聴いて!
【次節の内容】