はじめに
『パターン認識と機械学習』の独学時のまとめです。一連の記事は「数式の行間埋め」または「R・Pythonでのスクラッチ実装」からアルゴリズムの理解を補助することを目的としています。本とあわせて読んでください。
この記事は、4.4節の内容です。2次元の確率分布に対するラプラス近似をPythonで実装します。
【数式読解編】
【前節の内容】
【他の節一覧】
【この節の内容】
4.4.0 ラプラス近似の実装
2次元の確率分布に対するラプラス近似(ガウス分布による近似)を実装します。
利用するライブラリを読み込みます。
# 4.4.0項で利用するライブラリ import numpy as np from scipy import integrate from scipy.stats import multivariate_normal # 多変量ガウス分布 import matplotlib.pyplot as plt from matplotlib.animation import FuncAnimation
分布が近似される様子をアニメーションで確認するのにMatplotlibライブラリのanimationモジュールを利用します。不要であれば省略してください。
・真の分布の設定
まずは、この例で利用する分布の式を確認します。
この例では、$\mathbf{x} = (x_0, x_1)$として次の式を真の関数とします。
関数$f(\mathbf{x})$を用いた次の式を真の分布とします。
真の分布$p(\mathbf{x})$を得るためには、$f(\mathbf{x})$の積分を求める必要があります。しかし$f(\mathbf{x})$の積分が得られない場合に、$p(\mathbf{x})$の近似分布$q(\mathbf{x})$を求めることにします。
ラプラス近似では、ガウス分布を用いて近似します。つまりここでは、$p(\mathbf{x})$に近似するガウス分布$q(\mathbf{x})$(のパラメータ)を求めます。
勾配法・ニュートン-ラフソン法、ラプラス近似では、負の対数$E(\mathbf{x})$の勾配(1階微分)$\nabla E(\mathbf{x})$とヘッセ行列(2階微分)$\nabla \nabla E(\mathbf{x})$を用います。それぞれ導出しますが、必要な式は後でまとめるので、ここは飛ばしても問題ありません。
・計算式の導出(クリックで展開)
$f(\mathbf{x})$の対数をとり符号を反転させた(-1を掛けた)ものを、負の対数$E(\mathbf{x})$で表します。
$E(\mathbf{x})$を$x_0$で偏微分します。
対数関数の微分$\frac{d \ln x}{d x} = \frac{1}{x}$、三角関数の微分$\frac{d \sin x}{d x} = \cos x$、合成関数の微分$\frac{d g(f(x))}{d x} = \frac{d g(f(x))}{d f(x)} \frac{d f(x)}{d x}$を行いました。
同様に、$E(\mathbf{x})$を$x_1$で偏微分します。
三角関数の微分$\frac{d \cos x}{d x} = - \sin x$を行いました。
よって、$E(\mathbf{x})$の勾配ベクトルは
となります。
$\frac{\partial E(\mathbf{x})}{\partial x_0}$を更に$x_0$で偏微分します。
商の微分$\frac{d}{d x} \frac{f(x)}{g(x)} = (\frac{d f(x)}{d x} g(x) - f(x) \frac{d g(x)}{d x}) \frac{1}{(g(x))^2}$を行いました。
$\frac{\partial E(\mathbf{x})}{\partial x_0}$を更に$x_1$で偏微分します。
$\frac{\partial E(\mathbf{x})}{\partial x_1}$を更に$x_0$で偏微分します。
$x_0, x_1$のどちらから微分しても同じ結果になりました。
$\frac{\partial E(\mathbf{x})}{\partial x_1}$を更に$x_1$で偏微分します。
よって、$E(\mathbf{x})$のヘッセ行列は
となります。(三角関数をまともに勉強してないんで分からないですが、これってもっと整理できたりするんですか?)
・利用する関数の作成
次に、最急降下法・ニュートン-ラフソン法、ラプラス近似などの計算に利用する関数を作成します。
真の関数$f(\mathbf{x})$と真の分布$p(\mathbf{x})$を作成します。
# 真の関数を指定 def f(X0, X1): return 0.25 * np.sin(X0) - 0.2 * np.cos(X1) + 0.5 # 真の確率分布を指定 def p(X0, X1, f): # 正規化係数を計算 C = integrate.dblquad(f, np.min(X0), np.max(X0), lambda x: np.min(X1), lambda x: np.max(X1))[0] return f(X0, X1) / C
この例では、次の式を真の関数とします。
$f(\mathbf{x})$の積分
を正規化係数として、真の分布を次の式とします。
真の分布(の正規化係数)を解析的に得られない場合に近似分布を求めるのでした。ここで作成するp()は、真の分布のグラフを描いて近似できているかを確認するのに使います(近似には使いません)。そのため、scipyの積分用の関数integrate.dblquad()を使って簡易的に(グラフの描画範囲で)正規化係数を計算します。
$f(\mathbf{x})$の負の対数$E(\mathbf{x})$と、$E(\mathbf{x})$の1階微分$\nabla E(\mathbf{x})$、2階微分$\nabla \nabla E(\mathbf{x})$の計算を行う関数を作成します。
# 負の対数を作成 def E(X0, X1): return - np.log(f(X0, X1)) # 負の対数の勾配(階微分)を作成 def nabla_E(x0, x1): # 中間変数を計算 denom = - (5.0 * np.sin(x0) - 4.0 * np.sin(x1) + 10.0) vec = np.array([5.0 * np.cos(x0), 4.0 * np.sin(x1)]) return vec / denom # 負の対数のヘッセ行列(2階微分)を作成 def nabla2_E(x0, x1): # 中間変数を計算 denom = 5.0 * np.sin(x0) - 4.0 * np.cos(x1) + 10.0 mat = np.zeros((2, 2)) mat[0, 0] = 5.0 * np.sin(x0) * denom + 25.0 * np.cos(x0)**2 mat[0, 1] = 20.0 * np.cos(x0) * np.sin(x1) mat[1, 0] = 20.0 * np.cos(x0) * np.sin(x1) mat[1, 1] = - 4.0 * np.cos(x1) * denom + 16.0 * np.sin(x1)**2 return mat / denom**2
それぞれ次の式になります。
作図用の$\mathbf{x}$の点を作成します。
# 作図用のxの値を作成 x0_vals = np.arange(-3.0, 4.0, 0.1) x1_vals = np.arange(-6.0, 1.0, 0.1) # 作図用のxの点を作成 X0, X1 = np.meshgrid(x0_vals, x1_vals) x_dims = X0.shape x_point = np.stack([X0.flatten(), X1.flatten()], axis=1) print(x_dims) print(x_point.shape)
(70, 70)
(4900, 2)
真の関数$f(\mathbf{x})$と分布$p(\mathbf{x})$を作図します。
# 真の関数のグラフを作成 fig = plt.figure(figsize=(8, 8)) ax = fig.add_subplot(projection='3d') # 3D用の設定 ax.plot_surface(X0, X1, f(X0, X1), cmap='jet') # 真の関数:(3D) ax.contour(X0, X1, f(X0, X1), cmap='jet', offset=np.min(f(X0, X1))) # 真の関数:(等高線) ax.set_xlabel('$x_0$') ax.set_ylabel('$x_1$') ax.set_zlabel('$f(x)$') ax.set_title('$f(x) = \\frac{1}{4} \sin x_0 - \\frac{1}{5} \cos x_1 + 0.5$', fontsize=20) plt.show()
# 真の分布のグラフを作成 fig = plt.figure(figsize=(8, 8)) ax = fig.add_subplot(projection='3d') # 3D用の設定 ax.plot_surface(X0, X1, p(X0, X1, f), cmap='jet') # 真の分布:(3D) ax.contour(X0, X1, p(X0, X1, f), cmap='jet', offset=0.0) # 真の分布:(等高線) ax.set_xlabel('$x_0$') ax.set_ylabel('$x_1$') ax.set_zlabel('density') ax.set_title('$p(x) = \\frac{f(x)}{\int f(x) dx}$', fontsize=20) plt.show()

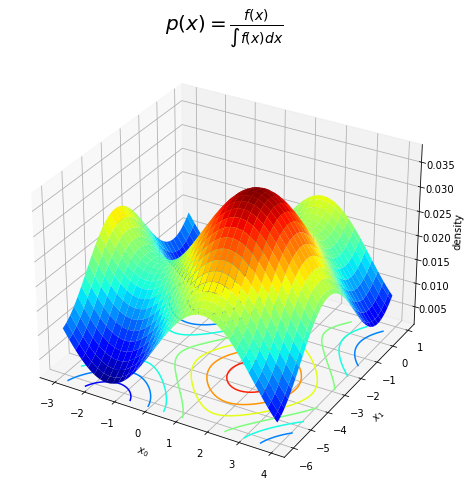
正規化したことで$f(\mathbf{x})$より$p(\mathbf{x})$の方がz軸の値が小さくなっていますが、同様の形状をしているのが分かります。
例えば、2つの点$\mathbf{x}_1, \mathbf{x}_2$について、$f(\mathbf{x}_1) < f(\mathbf{x}_2)$であれば$p(\mathbf{x}_1) < p(\mathbf{x}_2)$になります。この関係を、比例の記号$\propto$を使って$p(\mathbf{x}) \propto f(\mathbf{x})$で表しています。
$f(\mathbf{x})$の負の対数$E(\mathbf{x})$を作図します。
# 負の対数のグラフを作成 fig = plt.figure(figsize=(8, 8)) ax = fig.add_subplot(projection='3d') # 3D用の設定 ax.plot_surface(X0, X1, E(X0, X1), cmap='jet') # 負の対数:(3D) ax.contour(X0, X1, E(X0, X1), cmap='jet', offset=0.0) # 負の対数:(等高線) ax.set_xlabel('$x_0$') ax.set_ylabel('$x_1$') ax.set_zlabel('$E(x)$') ax.set_title('$E(x) = - \ln f(x)$', fontsize=20) plt.show()
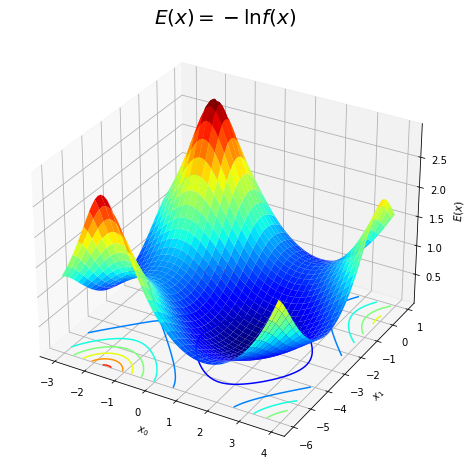
ラプラス近似では、真の分布$p(\mathbf{x})$を近似するのに、$p(\mathbf{x})$が最大となる値を求める必要があります。$p(\mathbf{x})$が最大になる値は、最頻値(モード)と言います。
しかし、真の分布は分からないので、真の関数$f(\mathbf{x})$のモードを求めます。また、「真の関数が最大となる値」は「負の対数が最小になる値」と同じです。
そこでこの例では、最急降下法またはニュートン-ラフソン法を用いて負の対数$E(\mathbf{x})$が最小となる値を求めます。
・最頻値の探索
では、近似分布を得るための処理を確認していきます。
最急降下法またはニュートン-ラフソン法により、負の対数が最小(真の分布の確率密度が最大)となる$\mathbf{x}$の値$\mathbf{x}_0$を求めます。
# 試行回数を指定 max_iter = 50 # 最急降下法の学習係数を指定 eta = 0.5 # xの初期値を指定 x_d = np.array([-1.0, -0.5]) # 最頻値を探索 trace_x = np.zeros((max_iter + 1, 2)) trace_x[0] = x_d.copy() for i in range(max_iter): # 負の対数の勾配(1階微分)を計算 grad = nabla_E(x_d[0], x_d[1]) # 負の対数のヘッセ行列(2階微分)を計算 H = nabla2_E(x_d[0], x_d[1]) # xを更新 x_d -= eta * grad # 最急降下法 #x_d -= np.dot(np.linalg.inv(H), grad.reshape(2, 1)).flatten() # ニュートン-ラフソン法 # 値を記録 trace_x[i+1] = x_d.copy() # 最頻値を記録(近似分布の平均を設定) x0_d = x_d.copy() print(x0_d)
[ 1.57079633 -3.14159265]
ニュートン-ラフソン法では、次の式で値を更新します。
最急降下法では、次の式で値を更新します。
$\eta$は、学習係数で、更新の幅を調整します。
収束した値を最頻値(モード)$\mathbf{x}_0$とします。
更新値の推移を確認します。
# 更新値の推移を作図 fig = plt.figure(figsize=(8, 8)) ax = fig.add_subplot(projection='3d') # 3D用の設定 ax.plot_surface(X0, X1, E(X0, X1), cmap='jet', alpha=0.5) # 負の対数:(3D) ax.contour(X0, X1, E(X0, X1), cmap='jet', linestyles=':', offset=0.0) # 負の対数:(等高線) ax.plot(trace_x[:, 0], trace_x[:, 1], E(trace_x[:, 0], trace_x[:, 1]), c='chocolate', marker='o', mfc='orange', mec='orange', label='$x^{(t)}$') # xの推移 ax.scatter(x_d[0], x_d[1], E(x_d[0], x_d[1]), color='red', marker='x', s=200, label='$x^{(' + str(max_iter) +')}$') # 推定した最頻値 ax.plot(trace_x[:, 0], trace_x[:, 1], 0, c='chocolate', linestyle='--') # xの推移:(平面) ax.set_xlabel('$x_0$') ax.set_ylabel('$x_1$') ax.set_zlabel('$E(x)$') ax.set_title('iter:' + str(max_iter) + ', x=(' + ', '.join(str(x) for x in np.round(x_d, 3)) + ')', loc='left') fig.suptitle('Gradient Descent, Newton-Raphson Method', fontsize=20) ax.legend() plt.show()
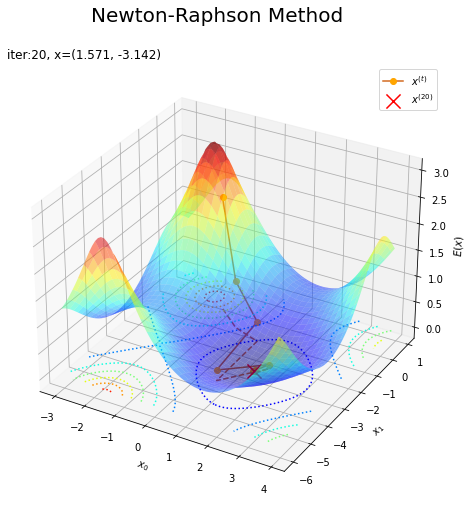
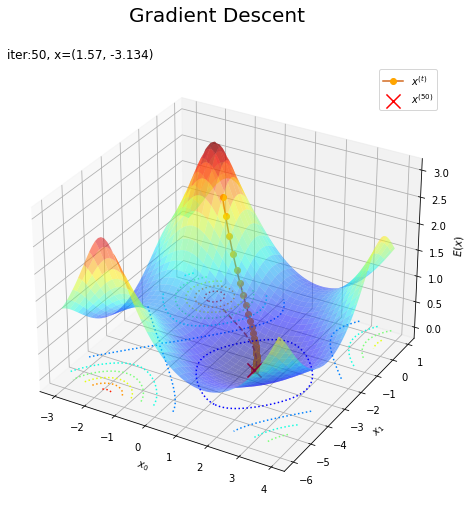
この例だと、ニュートン-ラフソン法の方が早く収束しました。初期値や学習係数の設定によって結果は変わります。初期値・学習係数によっては発散します。ここではこれ以上言及しません。詳しくは「ステップ29:勾配降下法とニュートン法の比較【ゼロつく3のノート(数学)】 - からっぽのしょこ」を参考にしてください。
以降は最急降下法による結果を用います。
・近似分布の計算
モードが得られたので、近似分布を計算します。
# 近似分布の平均を指定(手計算) #x0_d = np.array([0.0, 0.0]) # 近似分布の精度行列を計算 A_dd = nabla2_E(x0_d[0], x0_d[1]) print(A_dd) print(np.linalg.inv(A_dd)) # 近似分布の確率密度を計算 laplace_dens = multivariate_normal.pdf(x=x_point, mean=x0_d, cov=np.linalg.inv(A_dd))
[[ 2.63159397e-01 -3.91767259e-07]
[-3.91767259e-07 2.10524203e-01]]
[[3.79997831e+00 7.07142962e-06]
[7.07142962e-06 4.75004767e+00]]
ラプラス近似による近似分布は、平均$\mathbf{x}_0$・精度$\mathbf{A}$のガウス分布になります。
ヘッセ行列が精度行列二なります。
また精度行列は分散共分散行列の逆行列なので、分散共分散行列$\mathbf{A}^{-1}$です。
多変量ガウス分布の確率密度は、scipyのmultivariate_normal.pdf()で計算できます。平均の引数meanにx0_d、標準偏差の引数covに精度行列の逆行列np.linalg.inv(A_dd)を指定します。
真の分布$p(\mathbf{x})$と近似分布$q(\mathbf{x})$を重ねて作図します。
# 近似分布のグラフを作成 fig = plt.figure(figsize=(8, 8)) ax = fig.add_subplot(projection='3d') # 3D用の設定 ax.plot_wireframe(X0, X1, p(X0, X1, f), alpha=0.3) # 真の関数:(3D) ax.contour(X0, X1, p(X0, X1, f), cmap='jet', linestyles='--', offset=0) # 真の関数:(等高線) ax.plot_surface(X0, X1, laplace_dens.reshape(x_dims), cmap='jet', alpha=0.9) # 近似分布:(3D) ax.contour(X0, X1, laplace_dens.reshape(x_dims), cmap='jet', offset=0) # 近似分布:(等高線) ax.set_xlabel('$x_0$') ax.set_ylabel('$x_1$') ax.set_zlabel('density') ax.set_title('$iter:' + str(max_iter) + ', \mu=(' + ', '.join([str(x) for x in np.round(x0_d , 3)]) + ')' + ', \Sigma=[' + ', '.join([str(sgm) for sgm in np.round(A_dd, 3)]) + ')$', loc='left') fig.suptitle('Laplace Approximation', fontsize=20) #ax.view_init(elev=0, azim=300) # 表示アングル plt.show()
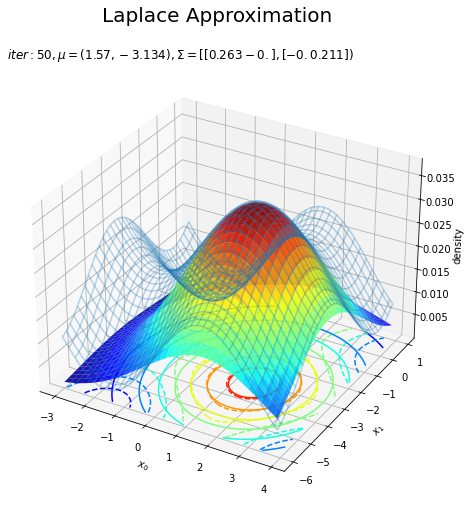
(グラフの重なり方に難がありますが、)近似できました。ただ、真の分布のx軸とy軸の範囲を変えると当て嵌まりが悪くなったりするので、実装をミスってるか何か勘違いしているかもしれません…。
以上で、ラプラス近似による近似分布を実装できました。
近似分布の推移をアニメーションで確認します。
・作図コード(クリックで展開)
ただし、分散(分散共分散行列の対角要素)が負の値になると確率密度を計算できません。更新値の始めの値は負の値になることがあるので、調べておきます(これって実装・計算ミスなのかも?)。
# 分散が負の値になると計算できないので問題ない試行番号をチェック for i in reversed(range(max_iter)): x_d = trace_x[i] A_dd = nabla2_E(x_d[0], x_d[1]) laplace_dens = multivariate_normal.pdf(x=x_point, mean=x0_d, cov=np.linalg.inv(A_dd)) print(i)
49
48
47
(省略)
9
8
7
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-13-a8a5b0343204> in <module>
3 x_d = trace_x[i]
4 A_dd = nabla2_E(x_d[0], x_d[1])
----> 5 laplace_dens = multivariate_normal.pdf(x=x_point, mean=x0_d, cov=np.linalg.inv(A_dd))
6 print(i)
(省略)
ValueError: the input matrix must be positive semidefinite
エラーになる前の値をnに設定すると、それ以降の結果を使ってアニメーションを作成します。
# 図を初期化 fig = plt.figure(figsize=(8, 8)) ax = fig.add_subplot(projection='3d') # 3D用の設定 fig.suptitle('Laplace Approximation', fontsize=20) # フレームを開始する試行番号を指定 n = 7 # 作図処理を関数として定義 def update(i): # 前フレームのグラフを初期化 plt.cla() # i回目のxの値を取得 x0_d = trace_x[i+n] # 近似分布の精度行列を計算 A_dd = nabla2_E(x0_d[0], x0_d[1]) # 近似分布の確率密度を計算 laplace_dens = multivariate_normal.pdf(x=x_point, mean=x0_d, cov=np.linalg.inv(A_dd)) # 条件付きガウス分布の3Dグラフを作成 ax.plot_wireframe(X0, X1, p(X0, X1, f), alpha=0.3) # 真の関数:(3D) ax.contour(X0, X1, p(X0, X1, f), cmap='jet', linestyles='--', offset=0) # 真の関数:(等高線) ax.plot_surface(X0, X1,laplace_dens.reshape(x_dims), cmap='jet', alpha=0.9) # 近似分布:(3D) ax.contour(X0, X1, laplace_dens.reshape(x_dims), cmap='jet', offset=0) # 近似分布:(等高線) ax.set_xlabel('$x_0$') ax.set_ylabel('$x_1$') ax.set_zlabel('density') ax.set_title('$iter:' + str(i+n) + ', \mu=(' + ', '.join([str(x) for x in np.round(x0_d , 3)]) + ')' + ', \Sigma=[' + ', '.join([str(sgm) for sgm in np.round(np.linalg.inv(A_dd), 3)]) + ')$', loc='left') # gif画像を作成 anime_laplace = FuncAnimation(fig, update, frames=(max_iter+1-n), interval=100) # gif画像を保存 anime_laplace.save('ch4_4_0_laplasApproximation2D.gif')
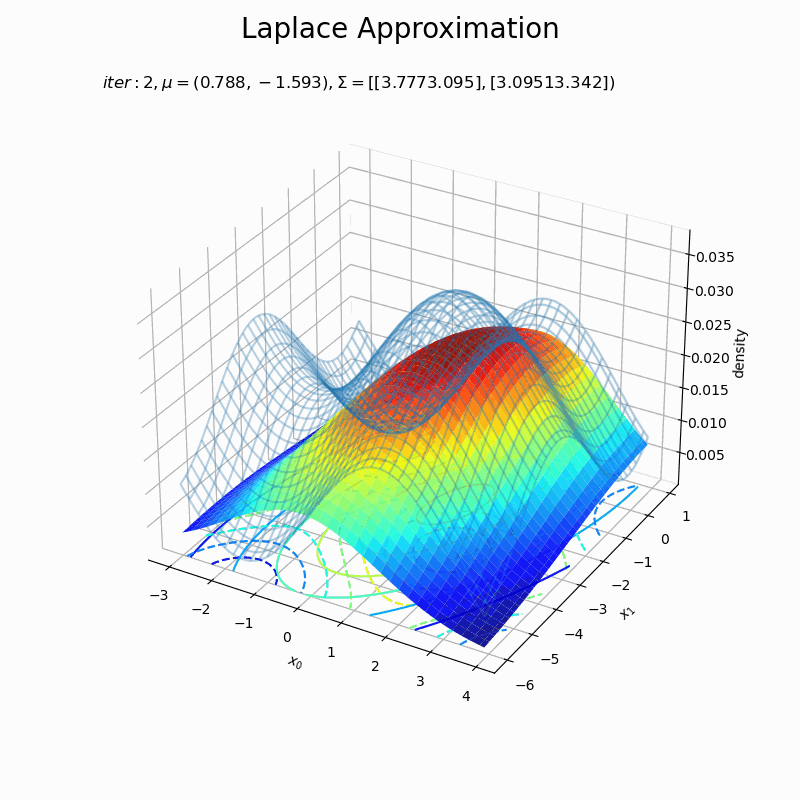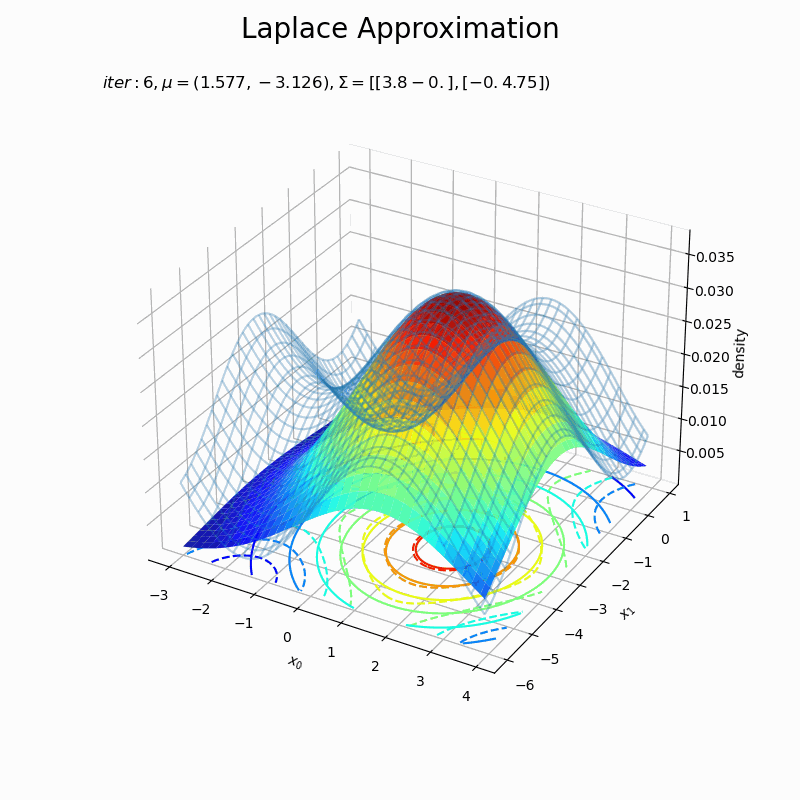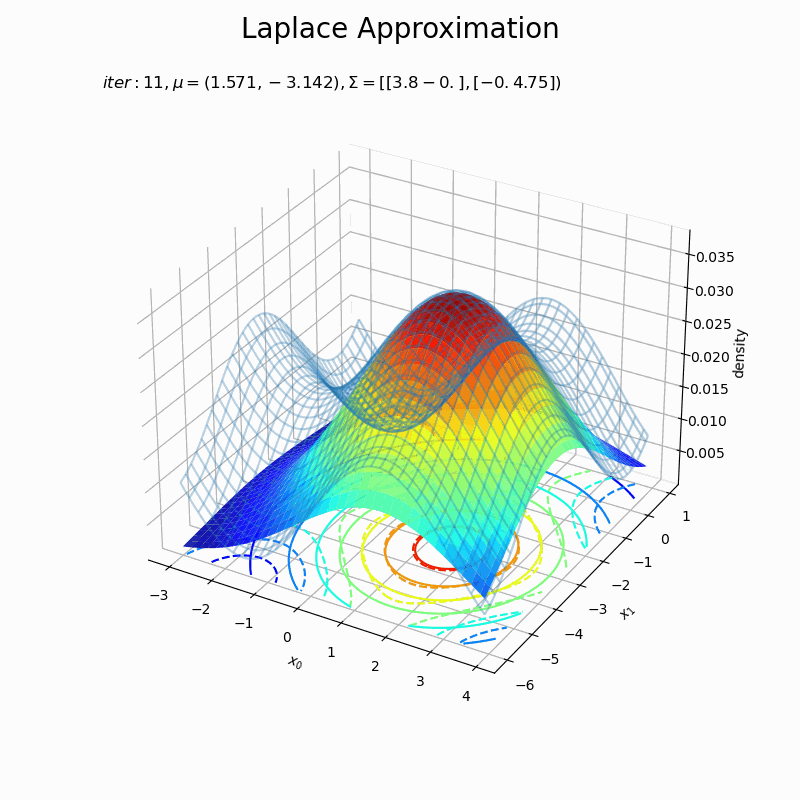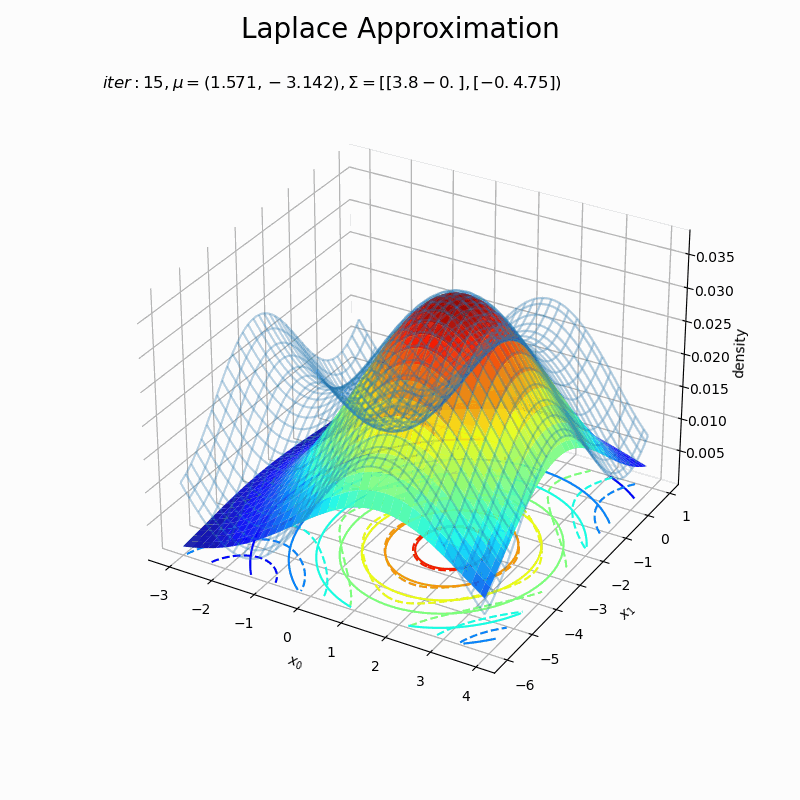
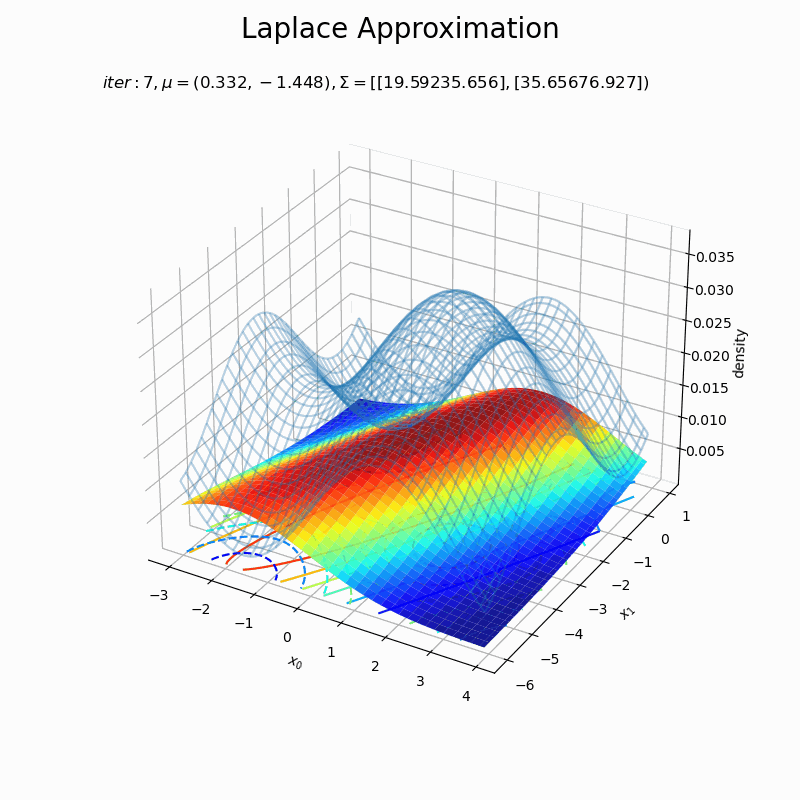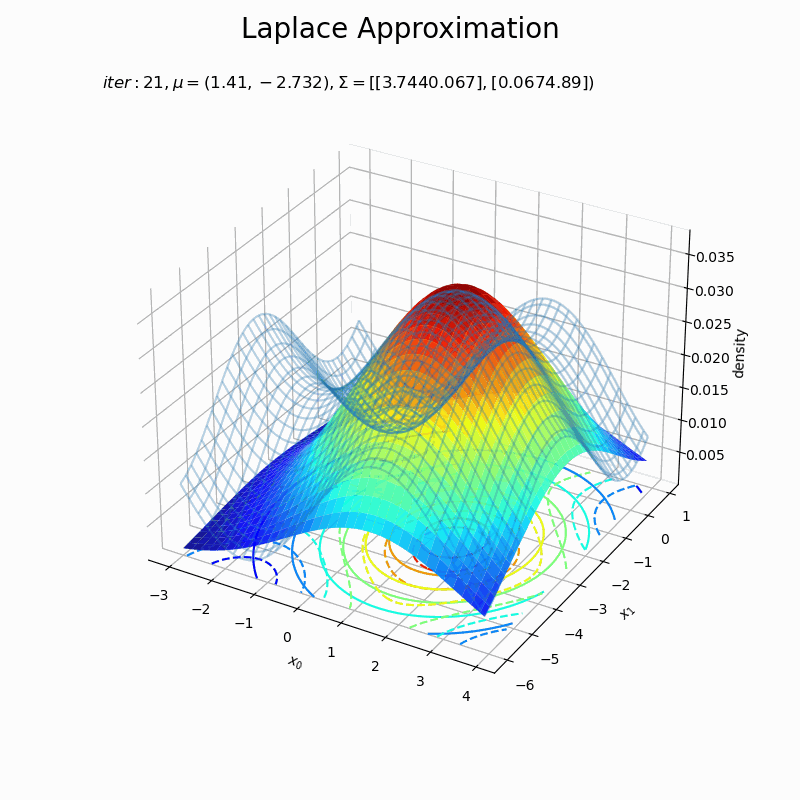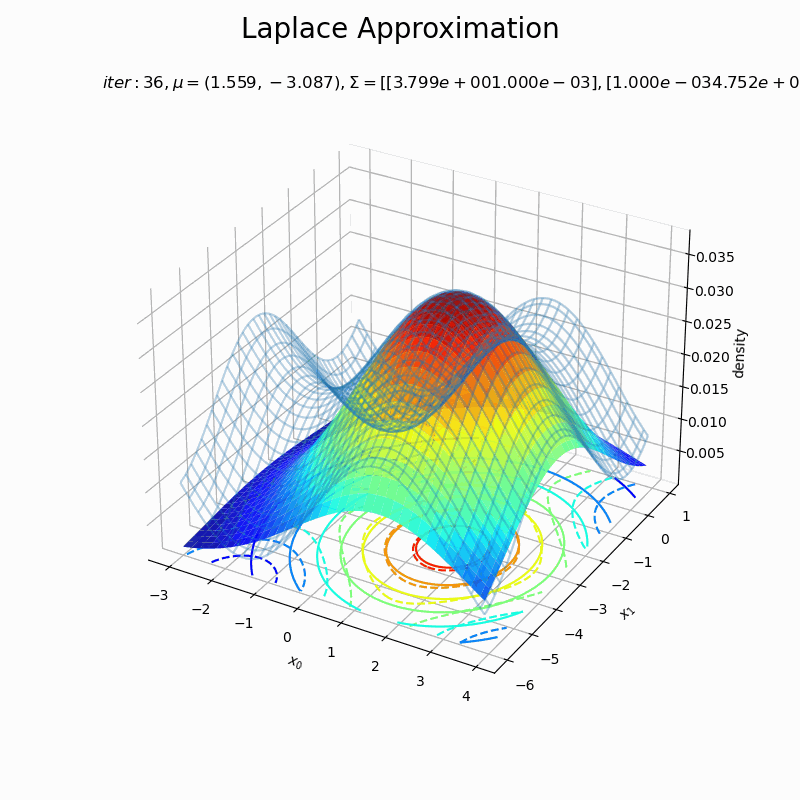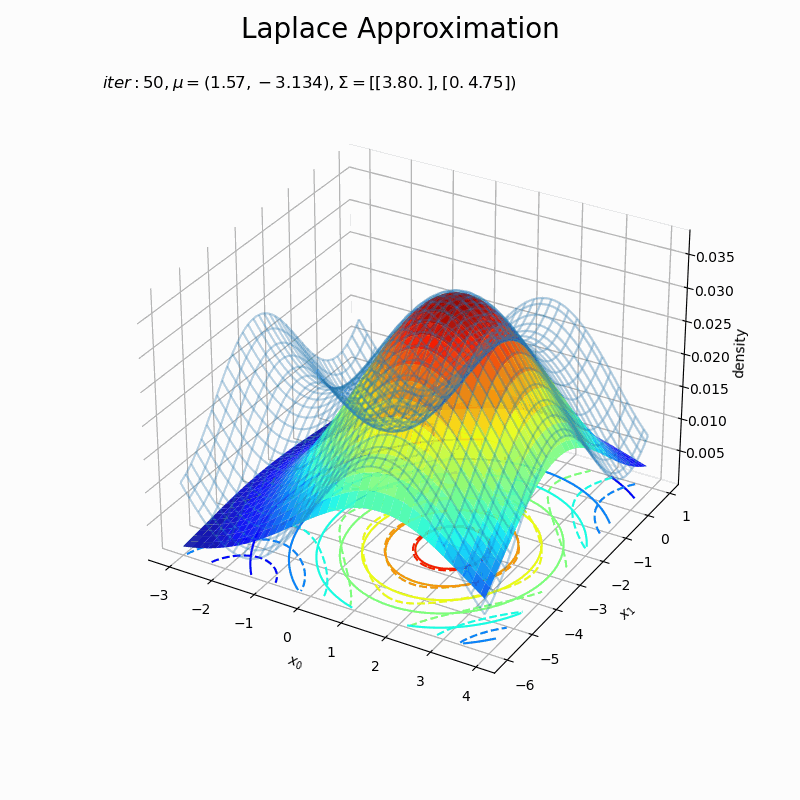
近似分布の平均は$\boldsymbol{\mu} = \mathbf{x}_0$なので、「最頻値の探索」でプロットした$\mathbf{x}$の更新値の推移(オレンジ色の点)に従って分布が移動しています。
近似分布の分散共分散行列は$\boldsymbol{\Sigma} = \mathbf{A}^{-1}$なので、上手いこと可視化したかったのですが力尽きました。1次元の方を参考にしてください。
参考文献
- C.M.ビショップ著,元田 浩・他訳『パターン認識と機械学習 上下』,丸善出版,2012年.
おわりに
できたと思うけどよく分からない。
よく分からないけどこれは準備運動で変分近似が本番なんだと思う。
前日に公開されたカバー動画をどうぞ♪
この企画最高でしょでしょ