はじめに
機械学習でも登場する情報理論におけるエントロピーを1つずつ確認していくシリーズです。
この記事では、エントロピーを扱います。
【前の内容】
【今回の内容】
平均情報量(エントロピー)の定義
自己情報量(self-information)の期待値である平均情報量(average information)を数式とグラフで確認します。平均情報量はエントロピー(entropy)とも呼ばれます。
自己情報量については「自己情報量の定義 - からっぽのしょこ」を参照してください。
定義
まずは、平均情報量の定義を数式で確認します。
確率分布における自己情報量の期待値を考えます。
排反な 個の事象
からなる事象系
の確率分布を
とします。
は、各事象
の確率
が非負の値で、総和が1の値で定義されます。
1つの事象の自己情報量 は、生起確率の負の対数で定義されるのでした。定数の底は
(またはネイピア数
)とします。
のとき
、
のとき
となり、
の範囲で単調減少する値をとります。
の平均情報量
は、各事象
の「自己情報量」の期待値で定義されます。
「各事象の確率」と「自己情報量(確率の負の対数)」の積和で計算できます。
1つの事象の確率が1で他の事象の確率が0のとき、つまり1つの事象しか発生しない状態のとき、自己情報量が なので、最小値の
になります。ただし生起確率が0の事象に関して、自己情報量が
なので、0と無限大の積を
として扱います。
全ての事象で等確率 のとき、つまり全ての事象が偏りなく発生する状態のとき、最大値の
になります。
平均情報量の最大値については「平均情報量の最大値の導出」を参照してください。
可視化
次は、2次元と3次元の確率分布における平均情報量をグラフで確認します。
利用するパッケージを読み込みます。
# 利用パッケージ library(tidyverse)
この記事では、基本的にパッケージ名::関数名()の記法を使うので、パッケージを読み込む必要はありません。ただし、作図コードがごちゃごちゃしないようにパッケージ名を省略しているため、ggplot2を読み込む必要があります。
また、ネイティブパイプ演算子|>を使っています。magrittrパッケージのパイプ演算子%>%に置き換えても処理できますが、その場合はmagrittrも読み込む必要があります。
2次元の場合
2つの事象からなる確率分布に関する平均情報量を可視化します。
2事象における平均情報量を計算します。
# 平均情報量を計算 entropy_2d_df <- tibble::tibble( p_x1 = seq(from = 0, to = 1, by = 0.01), # x1の確率 p_x2 = 1 - p_x1, # x2の確率 I_x1 = - log2(p_x1), # x1の自己情報量 I_x2 = - log2(p_x2), # x2の自己情報量 H_x = p_x1 * I_x1 + p_x2 * I_x2 # xの平均情報量 ) |> dplyr::mutate( H_x = dplyr::if_else(condition = is.nan(H_x), true = 0, false = H_x) # 確率が1の場合のNaNを0に置換 ) entropy_2d_df
## # A tibble: 101 × 5 ## p_x1 p_x2 I_x1 I_x2 H_x ## <dbl> <dbl> <dbl> <dbl> <dbl> ## 1 0 1 Inf 0 0 ## 2 0.01 0.99 6.64 0.0145 0.0808 ## 3 0.02 0.98 5.64 0.0291 0.141 ## 4 0.03 0.97 5.06 0.0439 0.194 ## 5 0.04 0.96 4.64 0.0589 0.242 ## 6 0.05 0.95 4.32 0.0740 0.286 ## 7 0.06 0.94 4.06 0.0893 0.327 ## 8 0.07 0.93 3.84 0.105 0.366 ## 9 0.08 0.92 3.64 0.120 0.402 ## 10 0.09 0.91 3.47 0.136 0.436 ## # … with 91 more rows
事象 の確率
として
0から1の値を作成して、事象 の確率
を計算します。
それぞれの自己情報量
を計算して、平均情報量
を計算します。
確率列が0のとき自己情報量列がInfになるため、平均情報量列が非数NaNになります。事象が2つの場合、一方の確率列が0のときもう一方の確率列が1であり、この場合のみ平均情報量列がNaNになります。そこで、H_x列がNaNのとき自己情報量を最小値の0に置き換えます。
2事象における平均情報量のグラフを作成します。
# 平均情報量を作図 ggplot() + geom_tile(data = entropy_2d_df, mapping = aes(x = p_x1, y = p_x2, fill = H_x)) + coord_fixed(ratio = 1) + # アスペクト比 labs(title = "average information", subtitle = expression(list(n == 2, H(x) == - sum(p(x[i]) ~ log[2]*p(x[i]), i==1, n))), fill = expression(H(x)), x = expression(p(x[1])), y = expression(p(x[2])))

事象 の確率をx軸の値、事象
の確率をy軸の値、平均情報量をz軸の値(グラデーション用の値)として、
geom_tile()でヒートマップを描画します。
の組み合わせ(座標)のみなので、xy平面で見ると直線状になります。
1つの軸に注目してグラフを作成します。
# 平均情報量を作図 ggplot() + geom_line(data = entropy_2d_df, mapping = aes(x = p_x1, y = H_x)) + # , color = H_x labs(title = "average information", subtitle = expression(list(n == 2, H(x) == - sum(p(x[i]) ~ log[2]*p(x[i]), i==1, n))), #color = expression(H(x)), x = expression(p(x[i])), y = expression(H(x)))
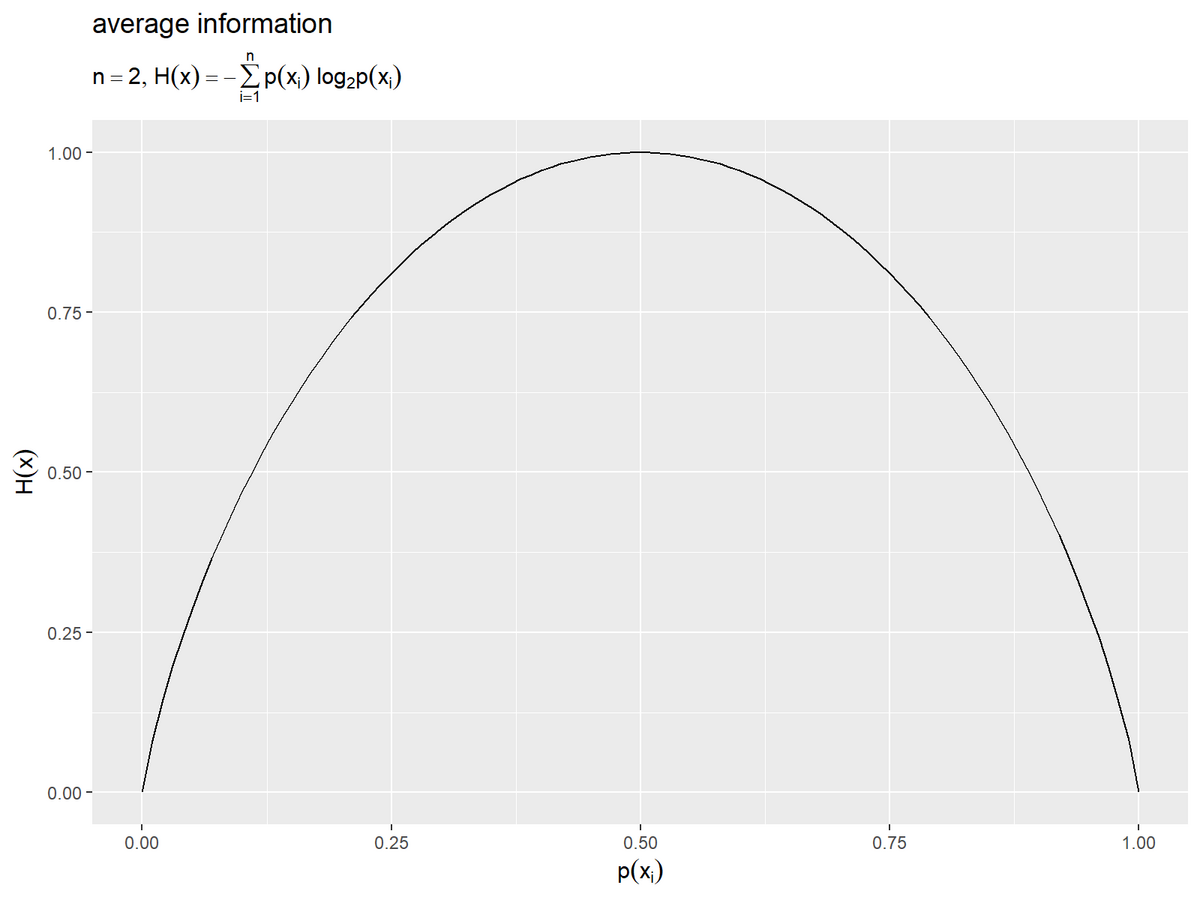
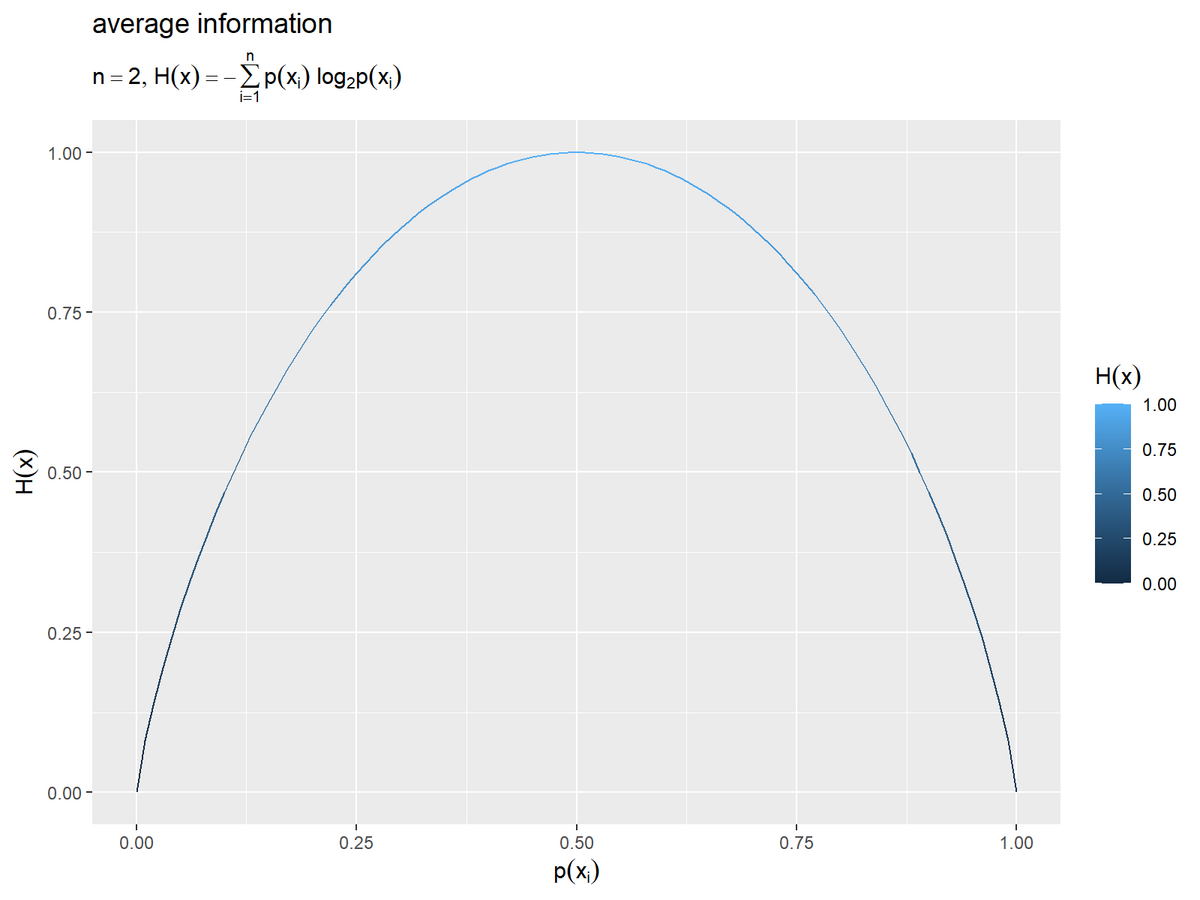
事象 または
の確率をx軸の値、平均情報量をy軸の値として、
geom_line()で折れ線グラフを描画します。
先ほどのヒートマップを3次元の図として、x軸( 軸)またはy軸(
軸)側から見た図に対応します。
一方の事象の確率が1で他方の事象の確率が0のとき(直線や曲線の両端の座標の)平均情報量が最小値の0、2つの事象の確率が同じとき(中点の座標の)平均情報量が最大値なのが分かります。
3次元の場合
3つの事象からなる確率分布に関する平均情報量を可視化します。三角図の作成については「ggplot2で三角グラフの等高線を作図したい - からっぽのしょこ」を参照してください。
・三角座標の作図用のコード(クリックで展開)
三角座標を描画するためのデータフレームを作成します。
# 軸目盛の位置を指定 axis_vals <- seq(from = 0, to = 1, by = 0.1) # 枠線用の値を作成 ternary_axis_df <- tibble::tibble( y1_start = c(0.5, 0, 1), # 始点のx軸の値 y2_start = c(0.5*sqrt(3), 0, 0), # 始点のy軸の値 y1_end = c(0, 1, 0.5), # 終点のx軸の値 y2_end = c(0, 0, 0.5*sqrt(3)), # 終点のy軸の値 axis = c("p_x1", "p_x2", "p_x3") # 元の軸 ) # グリッド線用の値を作成 ternary_grid_df <- tibble::tibble( y1_start = c( 0.5 * axis_vals, axis_vals, 0.5 * axis_vals + 0.5 ), # 始点のx軸の値 y2_start = c( sqrt(3) * 0.5 * axis_vals, rep(0, times = length(axis_vals)), sqrt(3) * 0.5 * (1 - axis_vals) ), # 始点のy軸の値 y1_end = c( axis_vals, 0.5 * axis_vals + 0.5, 0.5 * rev(axis_vals) ), # 終点のx軸の値 y2_end = c( rep(0, times = length(axis_vals)), sqrt(3) * 0.5 * (1 - axis_vals), sqrt(3) * 0.5 * rev(axis_vals) ), # 終点のy軸の値 axis = c("p_x1", "p_x2", "p_x3") |> rep(each = length(axis_vals)) # 元の軸 ) # 軸ラベル用の値を作成 ternary_axislabel_df <- tibble::tibble( y1 = c(0.25, 0.5, 0.75), # x軸の値 y2 = c(0.25*sqrt(3), 0, 0.25*sqrt(3)), # y軸の値 label = c("p(x[1])", "p(x[2])", "p(x[3])"), # 軸ラベル h = c(2, 0.5, -1), # 水平方向の調整用の値 v = c(0.5, 2.5, 0.5), # 垂直方向の調整用の値 axis = c("p_x1", "p_x2", "p_x3") # 元の軸 ) # 軸目盛ラベル用の値を作成 ternary_ticklabel_df <- tibble::tibble( y1 = c( 0.5 * axis_vals, axis_vals, 0.5 * axis_vals + 0.5 ), # x軸の値 y2 = c( sqrt(3) * 0.5 * axis_vals, rep(0, times = length(axis_vals)), sqrt(3) * 0.5 * (1 - axis_vals) ), # y軸の値 label = c( rev(axis_vals), axis_vals, rev(axis_vals) ), # 軸目盛ラベル h = c( rep(1.5, times = length(axis_vals)), rep(1.5, times = length(axis_vals)), rep(-0.5, times = length(axis_vals)) ), # 水平方向の調整用の値 v = c( rep(0.5, times = length(axis_vals)), rep(0.5, times = length(axis_vals)), rep(0.5, times = length(axis_vals)) ), # 垂直方向の調整用の値 angle = c( rep(-60, times = length(axis_vals)), rep(60, times = length(axis_vals)), rep(0, times = length(axis_vals)) ), # ラベルの表示角度 axis = c("p_x1", "p_x2", "p_x3") |> rep(each = length(axis_vals)) # 元の軸 )
三角座標上にヒートマップや等高線を描画するためのマトリクスを作成します。
# 格子点を作成 y_mat <- tidyr::expand_grid( y1 = seq(from = 0, to = 1, length.out = 101), # x軸の値 y2 = seq(from = 0, to = 0.5*sqrt(3), length.out = 100) # y軸の値 ) |> # 格子点を作成 as.matrix() # マトリクスに変換 # 3次元変数に変換 p_x_mat <- tibble::tibble( p_x2 = y_mat[, 1] - y_mat[, 2] / sqrt(3), p_x3 = 2 * y_mat[, 2] / sqrt(3) ) |> # 元の座標に変換 dplyr::mutate( p_x2 = dplyr::if_else(p_x2 >= 0 & p_x2 <= 1, true = p_x2, false = NA_real_), p_x3 = dplyr::if_else(p_x3 >= 0 & p_x3 <= 1 & !is.na(p_x2), true = p_x3, false = NA_real_), p_x1 = 1 - p_x2 - p_x3, p_x1 = dplyr::if_else(p_x1 >= 0 & p_x1 <= 1, true = p_x1, false = NA_real_) ) |> # 範囲外の値をNAに置換 dplyr::select(p_x1, p_x2, p_x3) |> # 順番を変更 as.matrix() # マトリクスに変換 head(p_x_mat); head(y_mat)
## p_x1 p_x2 p_x3 ## [1,] 1 0 0 ## [2,] NA NA NA ## [3,] NA NA NA ## [4,] NA NA NA ## [5,] NA NA NA ## [6,] NA NA NA ## y1 y2 ## [1,] 0 0.000000000 ## [2,] 0 0.008747731 ## [3,] 0 0.017495463 ## [4,] 0 0.026243194 ## [5,] 0 0.034990925 ## [6,] 0 0.043738657
3次元の確率分布の値(行ごとの和が1になる非負(1にならない場合は欠損値)の3次元の値)をp_x_mat、p_x_matを三角座標系に変換した際の2次元座標の値をy_matとします。p_x_matを計算、y_matを作図に使います。
3事象における平均情報量を計算します。
# 平均情報量を計算 entropy_3d_df <- tibble::tibble( y1 = y_mat[, 1], # x軸の値 y2 = y_mat[, 2], # y軸の値 p_x1 = p_x_mat[, 1], # x1の確率 p_x2 = p_x_mat[, 2], # x2の確率 p_x3 = p_x_mat[, 3], # x3の確率 I_x1 = - log2(p_x1), # x1の自己情報量 I_x2 = - log2(p_x2), # x2の自己情報量 I_x3 = - log2(p_x3), # x3の自己情報量 H_x = - rowSums(p_x_mat * log2(p_x_mat), na.rm = TRUE), # xの平均情報量 ) |> dplyr::filter(!is.na(rowSums(p_x_mat))) # 三角座標の範囲外(総和が1でない組み合わせ)を除去 entropy_3d_df
## # A tibble: 5,002 × 9 ## y1 y2 p_x1 p_x2 p_x3 I_x1 I_x2 I_x3 H_x ## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> ## 1 0 0 1 0 0 0 Inf Inf 0 ## 2 0.01 0 0.99 0.01 0 0.0145 6.64 Inf 0.0808 ## 3 0.01 0.00875 0.985 0.00495 0.0101 0.0219 7.66 6.63 0.126 ## 4 0.02 0 0.98 0.02 0 0.0291 5.64 Inf 0.141 ## 5 0.02 0.00875 0.975 0.0149 0.0101 0.0366 6.06 6.63 0.193 ## 6 0.02 0.0175 0.970 0.00990 0.0202 0.0441 6.66 5.63 0.222 ## 7 0.02 0.0262 0.965 0.00485 0.0303 0.0516 7.69 5.04 0.240 ## 8 0.03 0 0.97 0.03 0 0.0439 5.06 Inf 0.194 ## 9 0.03 0.00875 0.965 0.0249 0.0101 0.0515 5.32 6.63 0.249 ## 10 0.03 0.0175 0.960 0.0199 0.0202 0.0590 5.65 5.63 0.283 ## # … with 4,992 more rows
2次元座標上のx軸の値y_mat[, 1]とy軸の値y_mat[, 2]をデータフレームに格納します。
三角座標上の3つの軸の値p_x_matを用いて、rowSums()で行ごとに平均情報量を計算します。na.rm引数をTRUEにすると、欠損値を無視して計算するので、自己情報量がInfになる(確率が0の)場合も計算できます。
3事象における平均情報量のグラフを作成します。
# 平均情報量を作図 ggplot() + geom_contour_filled(data = entropy_3d_df, mapping = aes(x = y1, y = y2, z = H_x)) + # 等高線図 # geom_tile(data = entropy_3d_df, # mapping = aes(x = y1, y = y2, fill = H_x)) + # ヒートマップ # scale_fill_viridis_c() + # グラデーション:(ヒートマップ用) geom_segment(data = ternary_grid_df, mapping = aes(x = y1_start, y = y2_start, xend = y1_end, yend = y2_end), color = "gray50", linetype = "dashed") + # 三角図のグリッド線 geom_segment(data = ternary_axis_df, mapping = aes(x = y1_start, y = y2_start, xend = y1_end, yend = y2_end), color = "gray50") + # 三角図の枠線 geom_text(data = ternary_ticklabel_df, mapping = aes(x = y1, y = y2, label = label, hjust = h, vjust = v, angle = angle)) + # 三角図の軸目盛ラベル geom_text(data = ternary_axislabel_df, mapping = aes(x = y1, y = y2, label = label, hjust = h, vjust = v), parse = TRUE, size = 5) + # 三角図の軸ラベル scale_x_continuous(breaks = c(0, 0.5, 1), labels = NULL) + # x軸目盛 scale_y_continuous(breaks = c(0, 0.25*sqrt(3), 0.5*sqrt(3)), labels = NULL) + # y軸目盛 coord_fixed(ratio = 1, clip = "off") + # アスペクト比 theme(axis.ticks = element_blank(), panel.grid.minor = element_blank()) + # 図の体裁 labs(title = "average information", subtitle = expression(list(n == 3, H(x) == - sum(p(x[i]) ~ log[2]*p(x[i]), i==1, n))), fill = expression(H(x)), x = "", y = "")
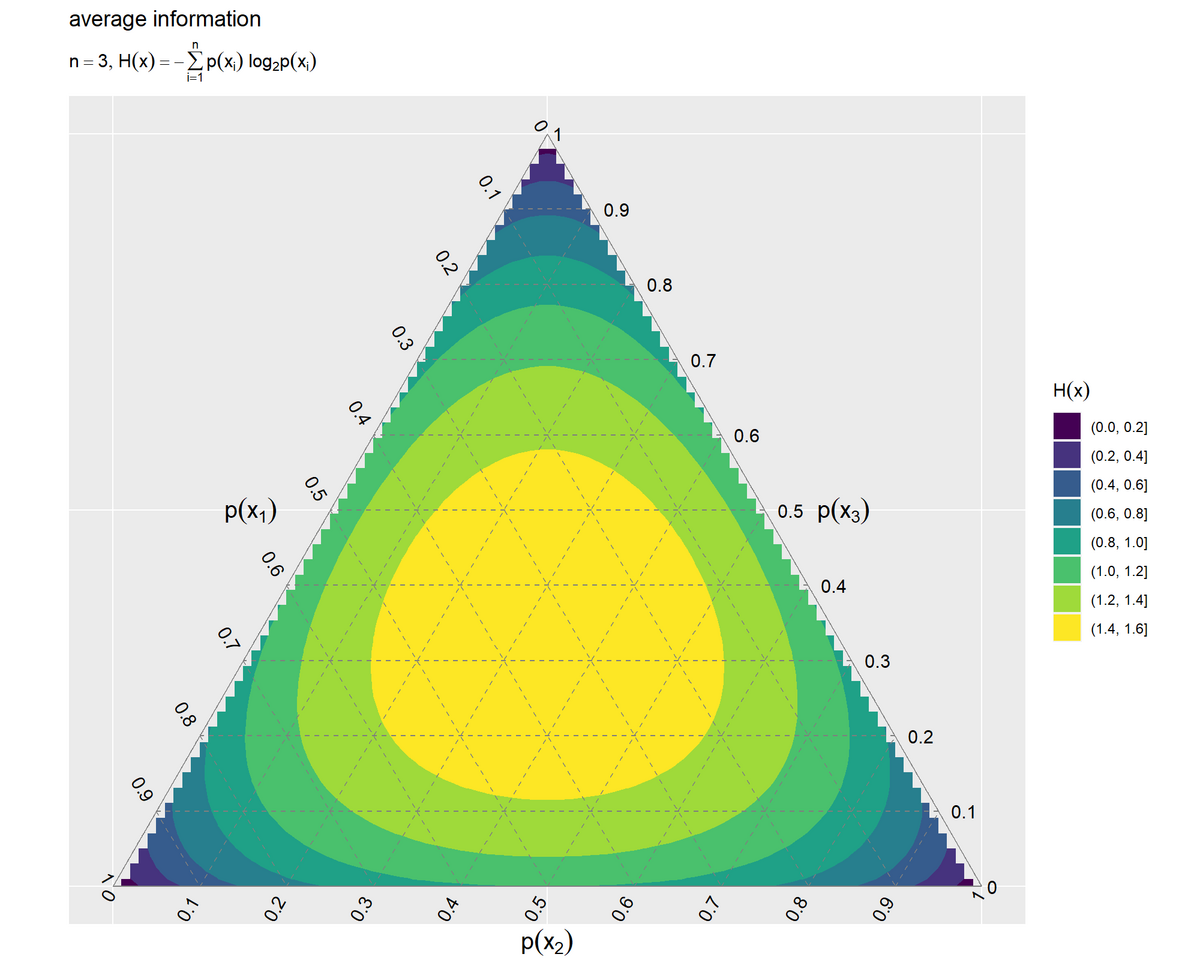
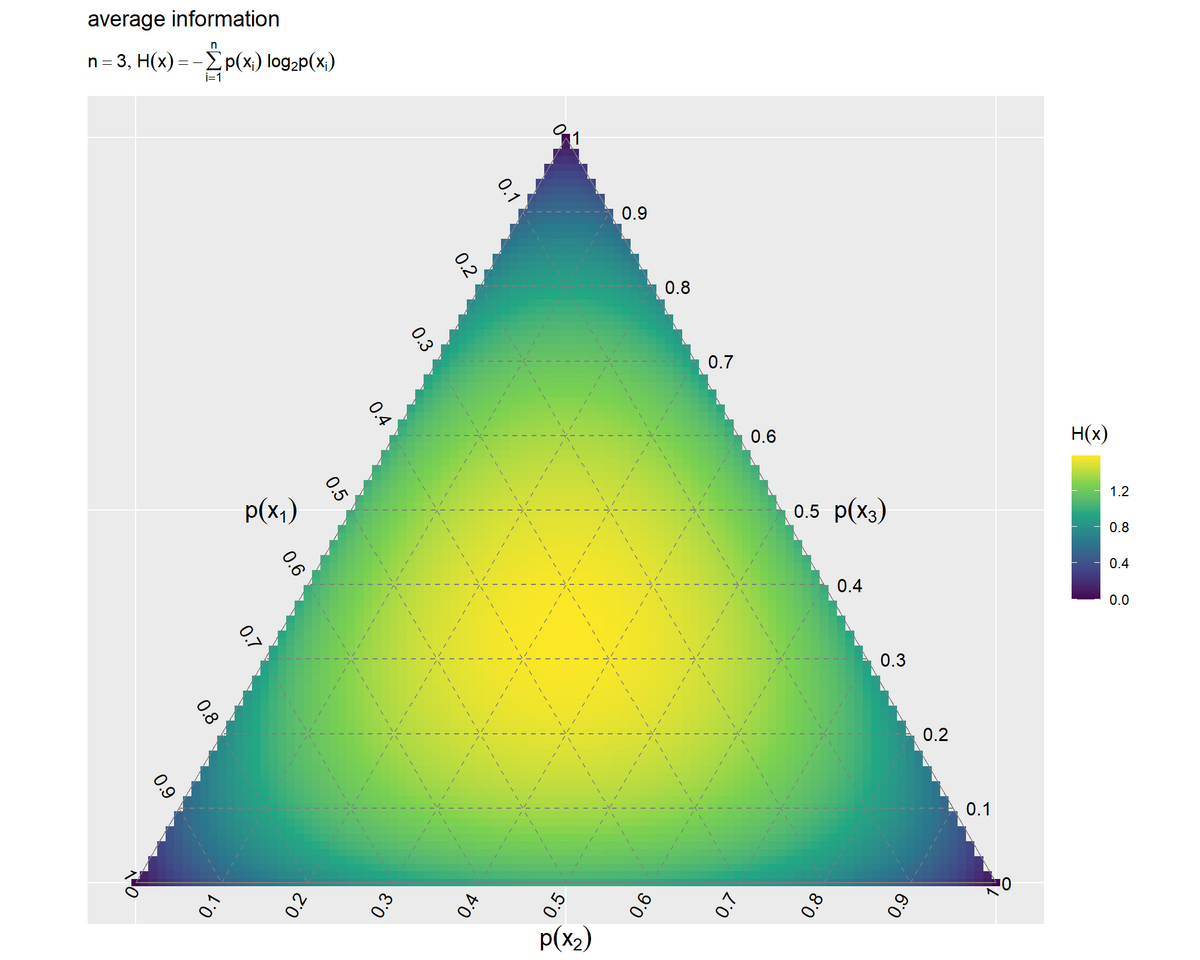
2次元座標列y1, y2をx軸・y軸の値、平均情報量をz軸の値(グラデーション用の値)として、geom_contour_filled()で等高線図またはgeom_tile()でヒートマップを描画します。
事象 の確率が
軸の値、事象
の確率が
軸の値、事象
の確率が
軸の値となるように描画されます。
1つの事象の確率が1で他の事象の確率が0のとき(正三角形の頂点の座標の)平均情報量が最小値の0、3つの事象の確率が同じとき(中心の座標の)平均情報量が最大値なのが分かります。
この記事では、平均情報量を確認しました。次の記事では、平均情報量の最大値を導出します。
参考文献
- 『わかりやすい ディジタル情報理論』(改訂2版)塩野 充・蜷川 繁,オーム社,2021年.
おわりに
ここまでは目新しさというかオリジナリティというかが足りないよなと思いながら書いてたのですが、この記事は三次元版の図を描けたので一応満足です。
平均情報量と呼ぶかエントロピーと呼ぶか都度判断しながら書いているのでこの先表記が揺れます。
【次の内容】