はじめに
『完全独習 統計学入門』の学習ノートです。本に載っている計算や表、グラフをR言語で再現します。本とあわせて読んでください。
この記事では、株の平均収益率(平均値)とボラティリティ(標準偏差)をグラフで確認します。
【前の節の内容】
【他の節の内容】
【この節の内容】
第5講 標準偏差(S.D.)は、株のリスクの指標(ボラティリティ)として活用できる
前講では、標準偏差の役割を確認しました。この講では、標準偏差をボラティリティとして株の収益率を比較します。
利用するパッケージを読み込みます。
# 利用パッケージ library(tidyverse) library(magick)
この記事では、基本的にパッケージ名::関数名()の記法を使うので、パッケージを読み込む必要はありません。ただし、作図コードがごちゃごちゃしないようにパッケージ名を省略しているためggplot2を読み込む必要があります。
また、ネイティブパイプ演算子|>を使っています。magrittrパッケージのパイプ演算子%>%に置き換えても処理できますが、その場合はmagrittrも読み込む必要があります。
5-2 平均収益率だけでは、優良な投資かどうかは判断できない
まずは、データを読み込んで、グラフで確認します。
図表5-3のデータセットをデータフレームとして作成します。
# データを作成:(図表5-3) revenue_df_wide <- tibble::tibble( month = 1:12, year_1980 = c(9.2, 2.3, -6.5, 9, 5.3, -4.3, -3.7, 7, 7.6, 1.4, -3.4, 0.7), year_1981 = c(2.8, -1.4, 17.6, 17.8, 5.5, -1.9, 1.9, 9, -10.3, -10.3, -7.7, 6.5), year_1982 = c(-0.6, -11.8, 3.5, 1.9, -5.5, -9.1, -5.7, 2.3, -4.9, -0.8, 8, 6.7), year_1983 = c(-2.8, 9.3, 11.4, 3, -7.5, 2.5, -0.6, 1.8, 5.1, -2.3, -6, 10.6), year_1984 = c(0, -5.7, 10.6, -0.6, -11.2, -3.8, -5.2, 6.2, -4.2, 2.1, 0.6, 4.7) ) revenue_df_wide
## # A tibble: 12 × 6 ## month year_1980 year_1981 year_1982 year_1983 year_1984 ## <int> <dbl> <dbl> <dbl> <dbl> <dbl> ## 1 1 9.2 2.8 -0.6 -2.8 0 ## 2 2 2.3 -1.4 -11.8 9.3 -5.7 ## 3 3 -6.5 17.6 3.5 11.4 10.6 ## 4 4 9 17.8 1.9 3 -0.6 ## 5 5 5.3 5.5 -5.5 -7.5 -11.2 ## 6 6 -4.3 -1.9 -9.1 2.5 -3.8 ## 7 7 -3.7 1.9 -5.7 -0.6 -5.2 ## 8 8 7 9 2.3 1.8 6.2 ## 9 9 7.6 -10.3 -4.9 5.1 -4.2 ## 10 10 1.4 -10.3 -0.8 -2.3 2.1 ## 11 11 -3.4 -7.7 8 -6 0.6 ## 12 12 0.7 6.5 6.7 10.6 4.7
5年分の株の月次収益率です。
作図用に、各年の収益率のデータ(列)を1列にまとめます。
# 縦型のデータフレームに変換 revenue_df <- revenue_df_wide |> tidyr::pivot_longer( cols = !month, names_to = "year", names_prefix = "year_", names_ptypes = list(year = factor()), values_to = "revenue_rate" ) revenue_df
## # A tibble: 60 × 3 ## month year revenue_rate ## <int> <fct> <dbl> ## 1 1 1980 9.2 ## 2 1 1981 2.8 ## 3 1 1982 -0.6 ## 4 1 1983 -2.8 ## 5 1 1984 0 ## 6 2 1980 2.3 ## 7 2 1981 -1.4 ## 8 2 1982 -11.8 ## 9 2 1983 9.3 ## 10 2 1984 -5.7 ## # … with 50 more rows
pivot_longer()で横型のデータフレームを縦型に変換します。cols引数に変換する列(変換しない列を指定する場合は頭に!を付けます)、names_to引数に「現在の列名」を格納する新たな列の名前、values_to引数に「現在の各列の値」を格納する新たな列の名前を指定します。また、names_prefix引数に現列名の頭から取り除く文字列、names_ptypes(またはnames_transform)引数で格納後の型を指定できます。
年ごとに収益率の推移のグラフを作成します。
# 月次収益率を作図 ggplot() + geom_line(data = revenue_df, mapping = aes(x = month, y = revenue_rate, color = year), size = 1) + # 収益率 scale_x_continuous(breaks = 1:12) + # x軸目盛 labs(title = "monthly revenue rate", x = "month", y = "revenue rate")
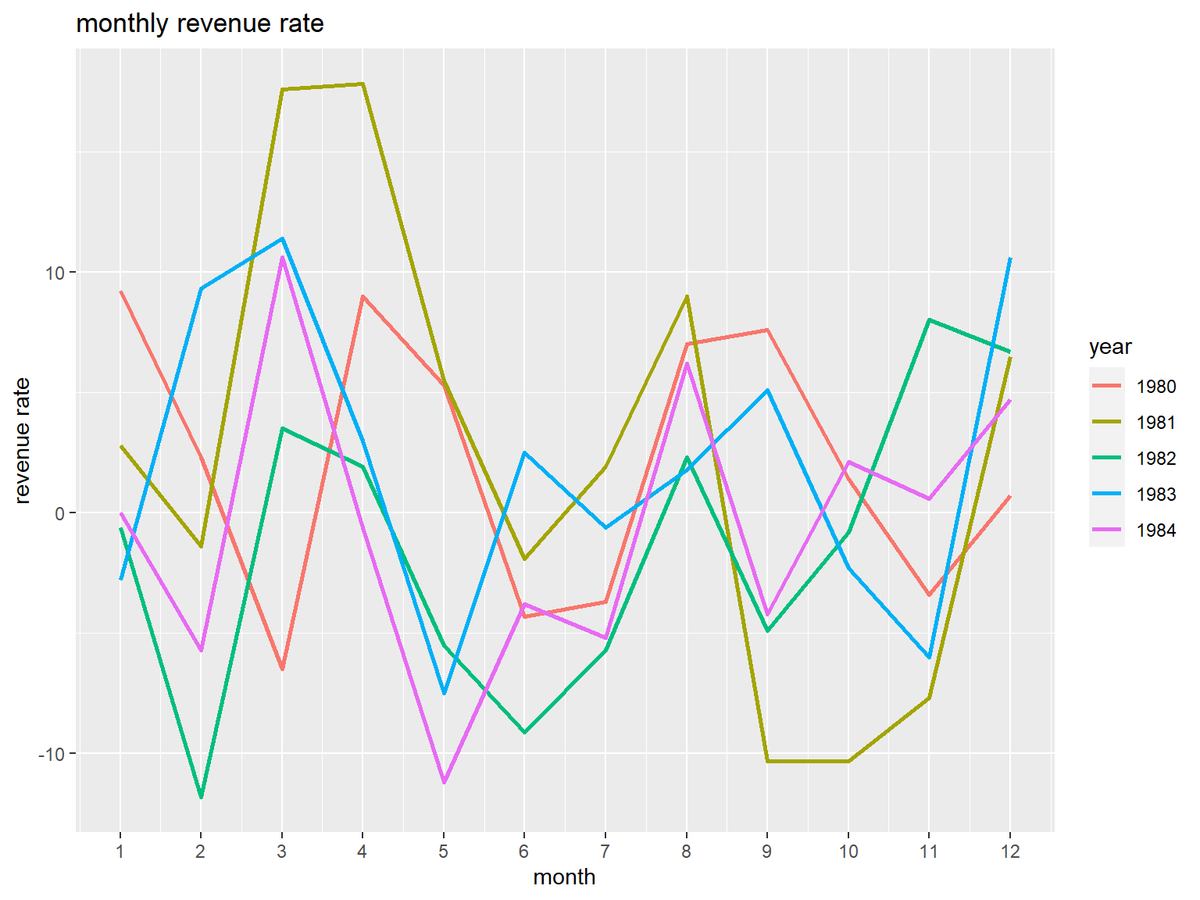
color引数にyear列を指定して、年ごとに折れ線グラフを描画します。
5-3 ボラティリティが意味するところ
次に、平均値と標準偏差を計算して、ボラティリティのグラフを作成します。
年ごとに平均収益率を計算します。
# 年ごとの平均値を計算 mean_df <- revenue_df |> dplyr::group_by(year) |> # 年ごとの計算用 dplyr::summarise( mean = mean(revenue_rate), .groups = "drop" ) mean_df
## # A tibble: 5 × 2 ## year mean ## <fct> <dbl> ## 1 1980 2.05 ## 2 1981 2.46 ## 3 1982 -1.33 ## 4 1983 2.04 ## 5 1984 -0.542
年ごとに(year列で)グループ化して、summarise()を使って標本平均を計算します。summarise()を使って計算すると、計算に利用した行が集約されます(行数が変化します)。
平均収益率を重ねてグラフを作成します。
# タイトル用の文字列を作成 stat_label <- paste0( "mean==", round(mean(mean_df[["mean"]]), digits = 3) ) # 月次収益率と平均値を作図 ggplot() + geom_line(data = revenue_df, mapping = aes(x = month, y = revenue_rate, color = year), size = 1) + # 収益率 geom_hline(data = mean_df, mapping = aes(yintercept = mean, color = year), size = 1, linetype ="dashed") + # 平均値 scale_x_continuous(breaks = 1:12) + # x軸目盛 labs(title = "average revenue rate", subtitle = parse(text = stat_label), x = "month", y = "revenue rate")

各年の平均収益率をgeom_hline()で水平線として描画します。
破線の位置が高いほど、収益率が高いことを表します。ただし、あくまで年間を通した値であり、月ごとの変動を表しません。
そこで、年ごとに標準偏差を計算します。
# 年ごとの標準偏差を計算 sd_df <- revenue_df |> dplyr::group_by(year) |> # 年ごとの計算用 dplyr::mutate( mean = mean(revenue_rate), sd = sd(revenue_rate) * sqrt(12-1) / sqrt(12) ) sd_df
## # A tibble: 60 × 5 ## # Groups: year [5] ## month year revenue_rate mean sd ## <int> <fct> <dbl> <dbl> <dbl> ## 1 1 1980 9.2 2.05 5.35 ## 2 1 1981 2.8 2.46 9.11 ## 3 1 1982 -0.6 -1.33 5.91 ## 4 1 1983 -2.8 2.04 5.98 ## 5 1 1984 0 -0.542 5.71 ## 6 2 1980 2.3 2.05 5.35 ## 7 2 1981 -1.4 2.46 9.11 ## 8 2 1982 -11.8 -1.33 5.91 ## 9 2 1983 9.3 2.04 5.98 ## 10 2 1984 -5.7 -0.542 5.71 ## # … with 50 more rows
mutate()を使って標本平均と標本標準偏差を計算します。mutate()を使って計算すると、計算に利用した行が集約されません(行数が変化しません)。
年ごとの標準偏差を取り出します。
# 標準偏差を抽出 sd_vec <- sd_df |> dplyr::distinct(year, sd) |> # 重複を削除 dplyr::pull(sd) # 列を抽出 sd_vec
## [1] 5.352492 9.110750 5.905553 5.979334 5.712188
sd_dfの平均値と標準偏差の値は、12か月分に複製されています。そこで、distinct()で重複を除去してから、pull()で標準偏差の列を取り出します。
平均収益率の平均値を中心に標準偏差1個分の範囲を重ねてグラフを作成します。
# タイトル用の文字列を作成 stat_label <- paste0( "list(", "mean==", round(mean(mean_df[["mean"]]), digits = 3), ", sd==", round(mean(sd_vec), digits = 3), ")" ) # 月次収益率とボラティリティを作図 ggplot() + geom_line(data = revenue_df, mapping = aes(x = month, y = revenue_rate, color = year), size = 1) + # 収益率 geom_hline(data = mean_df, mapping = aes(yintercept = mean, color = year), size = 1, linetype ="dashed") + # 平均値 geom_ribbon(data = sd_df, mapping = aes(x = month, ymin = mean-sd, ymax = mean+sd, color = year, fill = year), alpha = 0.1, linetype = "dotted") + # 標準偏差の範囲 scale_x_continuous(breaks = 1:12) + # x軸目盛 facet_wrap(year~.) + # グラフを分割 theme(legend.position = "none") + # 凡例の非表示 labs(title = "volatility", subtitle = parse(text = stat_label), x = "month", y = "revenue rate")
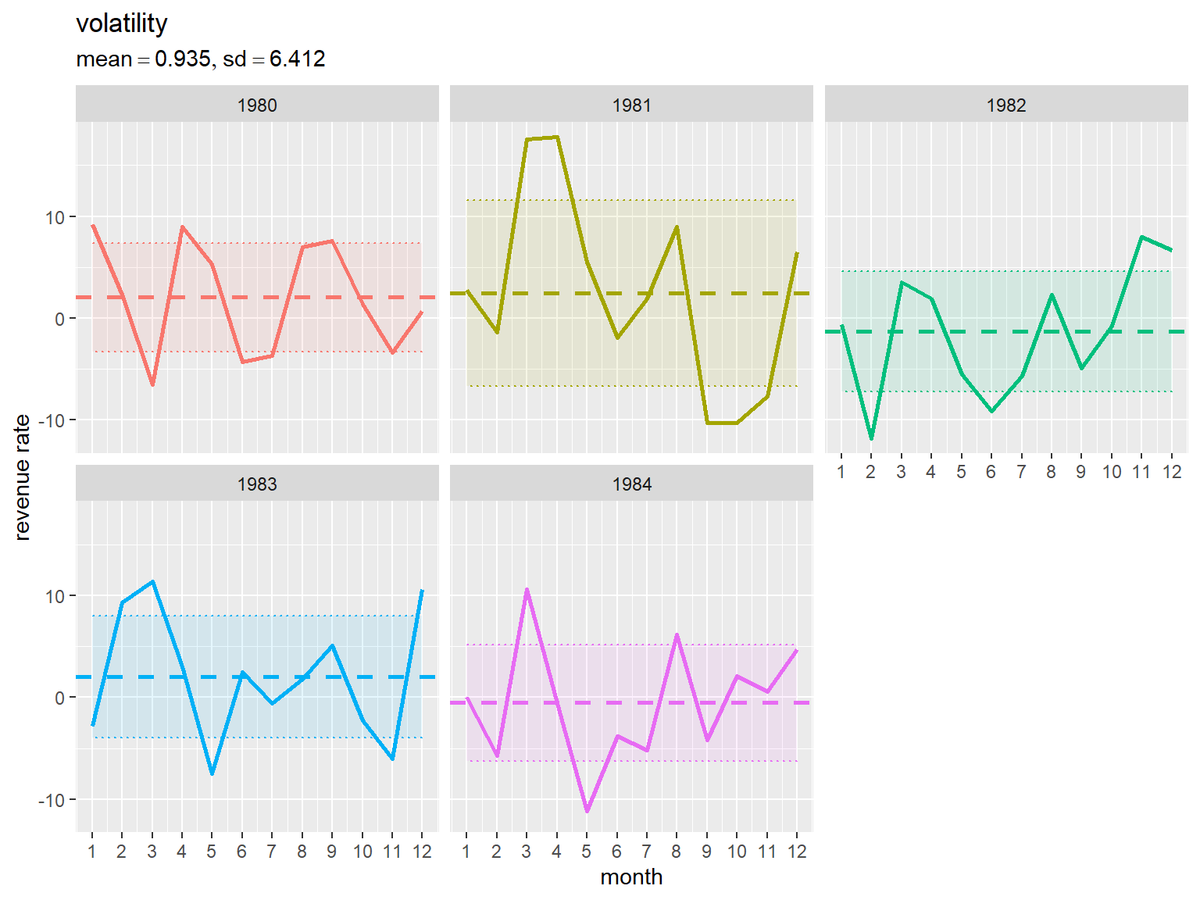
geom_ribbon()で平均値から標準偏差1個分を引いた値と足した値の範囲を描画します。
各年のグラフが重なると分かりにくくなるので、facet_wrap()で年ごとに分割します。
塗りつぶしの範囲が広いほど、変動が大きいことを表します。
(標準偏差の平均の値が合いませんでした。そもそも標準偏差の平均ってなんですか?)
この講では、標準偏差を利用してボラティリティを比較しました。次講では、シャープレシオを比較します。
参考書籍
- 小島寛之『完全独習 統計学入門』ダイヤモンド社,2006年.
おわりに
昨年末に1日1記事ペースで書いてたのですが、geom_histogram()の仕様にハマってしまい、修正に手間取って1か月ほど空いてしまいました。ようやく修正が終わって、そのままのテンションでこの記事を書きました。半日もかからずサクっと書けたので気分が良いです。
修正が面倒になってうっかり別のシリーズを書き始めてしましましたが、こっちのシリーズもやっていきます(希望的観測)。
唐突に金融の話になりましたが、この本ってそういう本なんですかね?確かに経済学部の講義用として買った本なんですが。
収益率などの訳語が分からない、、
2023年1月19日は、アンジュルムの伊勢鈴蘭さんの19歳のお誕生日です!
気付けば上から数えた方が早い先輩メンなんだな、フィーチャー曲をくださいお願いします。
【次の節の内容】