はじめに
機械学習で登場する確率分布について色々な角度から理解したいシリーズです。
この記事では、ggplot2パッケージを利用して、正規分布の確率密度関数・累積分布関数・分位関数のグラフを作成します。
【前の内容】
【他の記事一覧】
【この記事の内容】
1次元ガウス分布の確率密度関数と累積分布関数の関係の可視化
1次元の正規分布(Normal distribution)・ガウス分布(Gaussian distribution)の確率密度関数(probability density function)・累積分布関数(cumulative distribution function)・分位関数(quantile function)のグラフを作成します。
ガウス分布については「1次元ガウス分布の定義式 - からっぽのしょこ」を参照してください。
利用するパッケージを読み込みます。
# 利用パッケージ library(tidyverse)
この記事では、基本的に パッケージ名::関数名() の記法を使うので、パッケージの読み込みは不要です。ただし、作図コードについてはパッケージ名を省略するので、ggplot2 を読み込む必要があります。
また、ネイティブパイプ演算子 |> を使います。magrittr パッケージのパイプ演算子 %>% に置き換えられますが、その場合は magrittr を読み込む必要があります。
グラフの作成
まずは、正規分布の3つの関数(確率密度関数・累積分布関数・分位関数)のグラフを作成します。
正規分布のパラメータを指定して、正規分布の関数を計算します。
# 正規分布のパラメータを指定 mu <- 0 sigma <- 1 # 確率変数の範囲を指定 x_vec <- seq(from = -4, to = 4, length.out = 1001) # 正規分布の値を作成 norm_df <- tibble::tibble( x = x_vec, # 確率変数(クォンタイル) d = dnorm(x = x, mean = mu, sd = sigma), # 確率変数 → 確率密度 p = pnorm(q = x, mean = mu, sd = sigma), # クォンタイル → パーセンタイル q = qnorm(p = p, mean = mu, sd = sigma) # パーセンタイル → クォンタイル ) norm_df
# A tibble: 1,001 × 4
x d p q
<dbl> <dbl> <dbl> <dbl>
1 -4 0.000134 0.0000317 -4
2 -3.99 0.000138 0.0000328 -3.99
3 -3.98 0.000143 0.0000339 -3.98
4 -3.98 0.000147 0.0000350 -3.98
5 -3.97 0.000152 0.0000362 -3.97
6 -3.96 0.000157 0.0000375 -3.96
7 -3.95 0.000162 0.0000388 -3.95
8 -3.94 0.000167 0.0000401 -3.94
9 -3.94 0.000173 0.0000414 -3.94
10 -3.93 0.000178 0.0000428 -3.93
# ℹ 991 more rows
平均パラメータ(実数) 、標準偏差パラメータ(正の実数)
を指定します。
確率変数がとり得る値(実数) を作成して、
dnorm() で確率変数(クォンタイル)から確率密度、pnorm() でクォンタイルからパーセンタイル(累積確率)、qnorm() でパーセンタイルからクォンタイルを計算します。
分位数を指定して、分布点ごとに正規分布の関数を計算します。
# 分位数を指定 n <- 10 # 分位点の値を作成 quan_df <- tibble::tibble( i = 1:n, # 分位番号 p = (i - 0.5) / n, # 分位番号 → パーセンタイル:(両端は0.5) #p = i / (n + 1), # 分位番号 → パーセンタイル:(両端も1) q = qnorm(p = p, mean = mu, sd = sigma), # パーセンタイル → クォンタイル d = dnorm(x = q, mean = mu, sd = sigma) # クォンタイル → 確率密度 ) quan_df
# A tibble: 10 × 4
i p q d
<int> <dbl> <dbl> <dbl>
1 1 0.05 -1.64 0.103
2 2 0.15 -1.04 0.233
3 3 0.25 -0.674 0.318
4 4 0.35 -0.385 0.370
5 5 0.45 -0.126 0.396
6 6 0.55 0.126 0.396
7 7 0.65 0.385 0.370
8 8 0.75 0.674 0.318
9 9 0.85 1.04 0.233
10 10 0.95 1.64 0.103
分位数 を指定して、分位番号
を作成します。
パーセンタイルを または
で計算して、クォンタイルと確率密度を計算します。
正規分布の確率密度関数のグラフを作成します。
# ラベル用の文字列を作成 param_label <- paste0( "list(", "mu == ", round(mu, digits = 2), ", ", "sigma == ", round(sigma, digits = 2), ", ", "sigma^2 == ", round(sigma^2, digits = 2), ")" ) # 確率密度関数を作図 ggplot() + geom_vline(data = quan_df, mapping = aes(xintercept = q), linetype = "dotted") + # 分位点のy軸目盛線 geom_vline(xintercept = mu, color = "red", linewidth = 1, linetype = "dashed") + # 平均 geom_segment(mapping = aes(x = mu-sigma, y = -Inf, xend = mu+sigma, yend = -Inf), arrow = arrow(length = unit(10, units = "pt"), ends = "both"), color = "red", linewidth = 1, linetype = "dashed") + # 標準偏差の範囲 geom_text(mapping = aes(x = c(mu-sigma, mu, mu+sigma), y = -Inf, label = c("mu-sigma", "mu", "mu+sigma")), parse = TRUE, vjust = -0.5, size = 6) + # パラメータラベル geom_line(data = norm_df, mapping = aes(x = x, y = d), linewidth = 1) + # 確率密度 scale_x_continuous(sec.axis = sec_axis(trans = ~., breaks = quan_df[["q"]], labels = round(quan_df[["p"]], digits = 3), name = "cumulative probability")) + # 累積確率軸 coord_cartesian(clip = "off") + #theme(axis.text.x.top = element_text(angle = 45, hjust = 0)) + labs(title = "Normal distribution: probability density function", subtitle = parse(text = param_label), x = "variable, quantile", y = "density")

横軸は確率変数(クォンタイル)、縦軸は確率密度です。
平均を赤色の破線の垂直線、平均を中心とした標準偏差の範囲を水平線で示します。また、分位点ごとの左側確率(累積確率)を点線の水平線と横軸の第2軸で示します。
正規分布の累積分布関数のグラフを作成します。
# 累積分布関数を作図 ggplot() + geom_hline(data = quan_df, mapping = aes(yintercept = p), linetype = "dotted") + # 分位点のy軸目盛線 geom_vline(xintercept = mu, color = "red", linewidth = 1, linetype = "dashed") + # 平均 geom_segment(mapping = aes(x = mu-sigma, y = -Inf, xend = mu+sigma, yend = -Inf), arrow = arrow(length = unit(10, units = "pt"), ends = "both"), color = "red", linewidth = 1, linetype = "dashed") + # 標準偏差の範囲 geom_text(mapping = aes(x = c(mu-sigma, mu, mu+sigma), y = -Inf, label = c("mu-sigma", "mu", "mu+sigma")), parse = TRUE, vjust = -0.5, size = 6) + # パラメータラベル geom_line(data = norm_df, mapping = aes(x = x, y = p), linewidth = 1) + # 累積確率 scale_y_continuous(sec.axis = sec_axis(trans = ~., breaks = quan_df[["p"]], labels = round(quan_df[["p"]], digits = 3))) + # 確率軸 coord_cartesian(clip = "off") + labs(title = "Normal distribution: cumulative distribution function", subtitle = parse(text = param_label), x = "variable, quantile", y = "probability, percentile")

横軸は確率変数(クォンタイル)、縦軸は確率(パーセンタイル)です。
こちらも平均の位置と標準偏差の範囲を赤色の破線で示します。また、分位点ごとの累積確率を点線の水平線と縦軸の第2軸で示します。
正規分布の分位関数のグラフを作成します。
# 分位関数を作図 ggplot() + geom_vline(data = quan_df, mapping = aes(xintercept = p), linetype = "dotted") + # 分位点のy軸目盛線 geom_hline(mapping = aes(yintercept = mu), color = "red", linewidth = 1, linetype = "dashed") + # 平均 geom_segment(mapping = aes(x = -Inf, y = mu-sigma, xend = -Inf, yend = mu+sigma), arrow = arrow(length = unit(10, units = "pt"), ends = "both"), color = "red", linewidth = 1, linetype = "dashed") + # 標準偏差の範囲 geom_text(mapping = aes(x = 0, y = c(mu-sigma, mu, mu+sigma), label = c("mu-sigma", "mu", "mu+sigma")), parse = TRUE, hjust = 0.5, size = 6) + # パラメータラベル geom_line(data = norm_df, mapping = aes(x = p, y = q), linewidth = 1) + # 確率変数 scale_x_continuous(sec.axis = sec_axis(trans = ~., breaks = quan_df[["p"]], labels = round(quan_df[["p"]], digits = 3))) + # 確率軸 coord_cartesian(clip = "off") + labs(title = "Normal distribution: quantile function", subtitle = parse(text = param_label), x = "probability, percentile", y = "variable, quantile")

横軸は確率(パーセンタイル)、縦軸は確率変数の値(クォンタイル)です。
累積分布関数のグラフの横軸と縦軸を入れ替えたグラフです。
関数の関係
次は、正規分布の3つの関数の関係をグラフで確認します。
作図コードについては「GitHub - anemptyarchive/Probability-Distribution/.../gaussian_fnc.R
」を参照してください。
確率密度関数と累積分布関数の関係
確率密度関数と累積分布関数の関係を確認します。
確率密度と累積確率の関係のアニメーションを作成します。
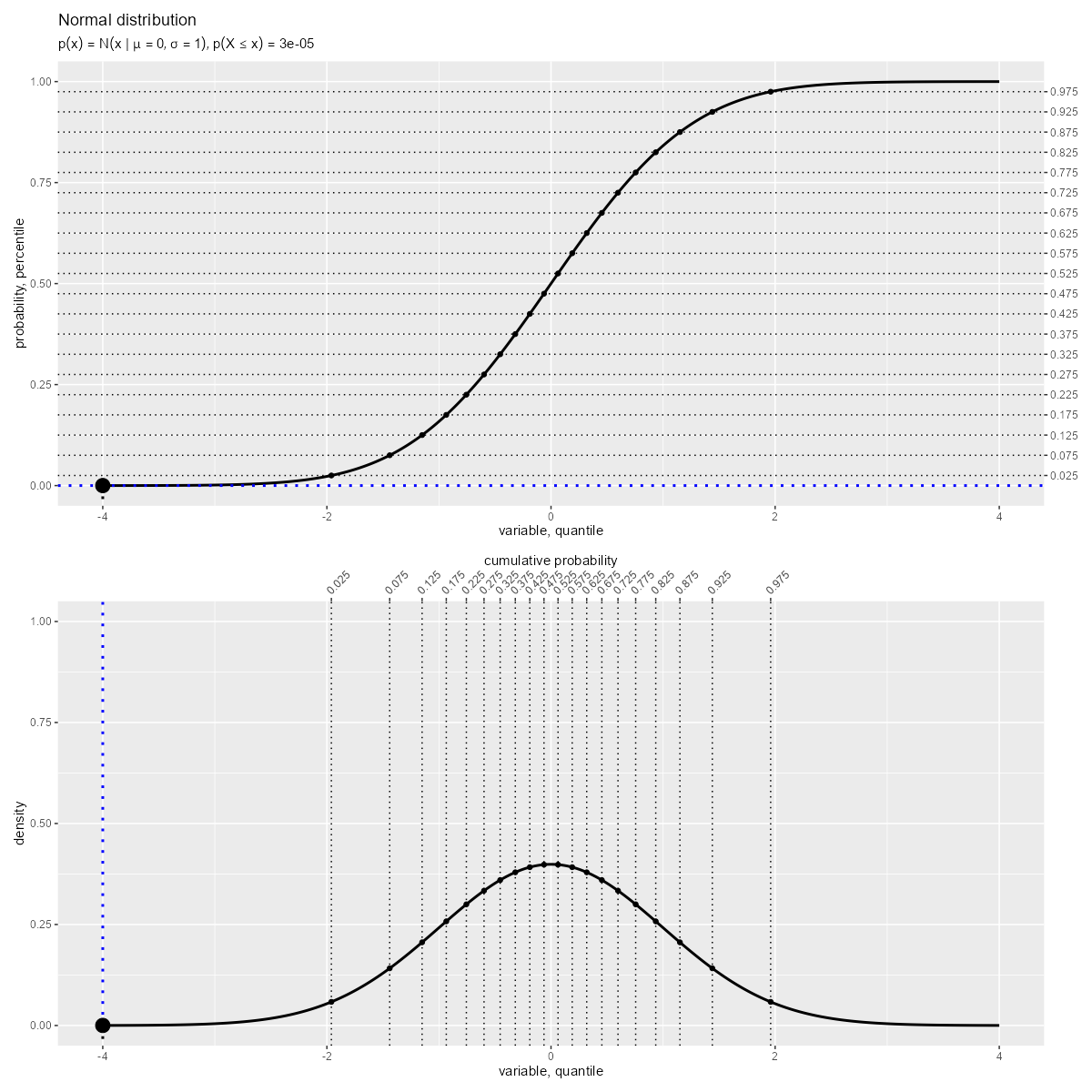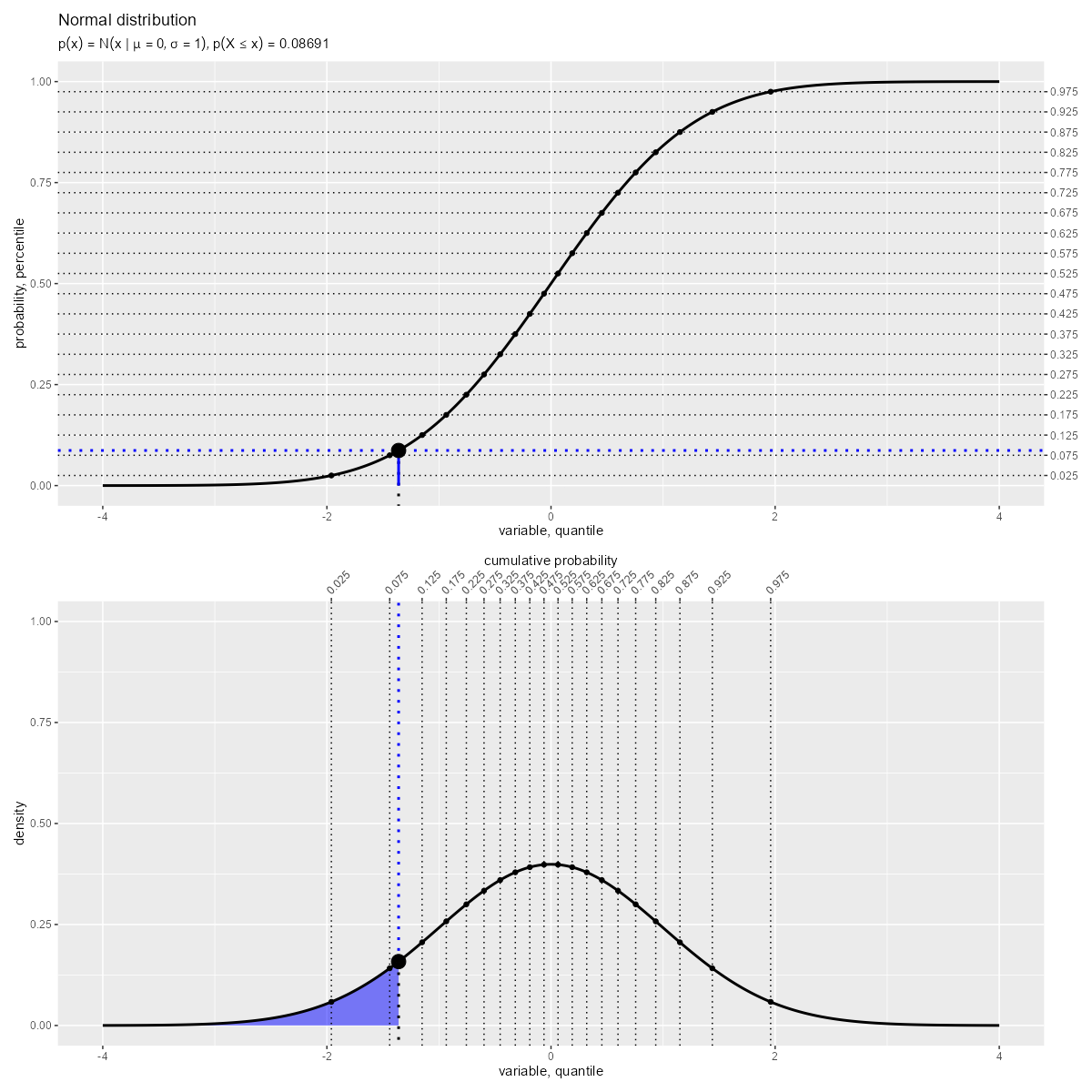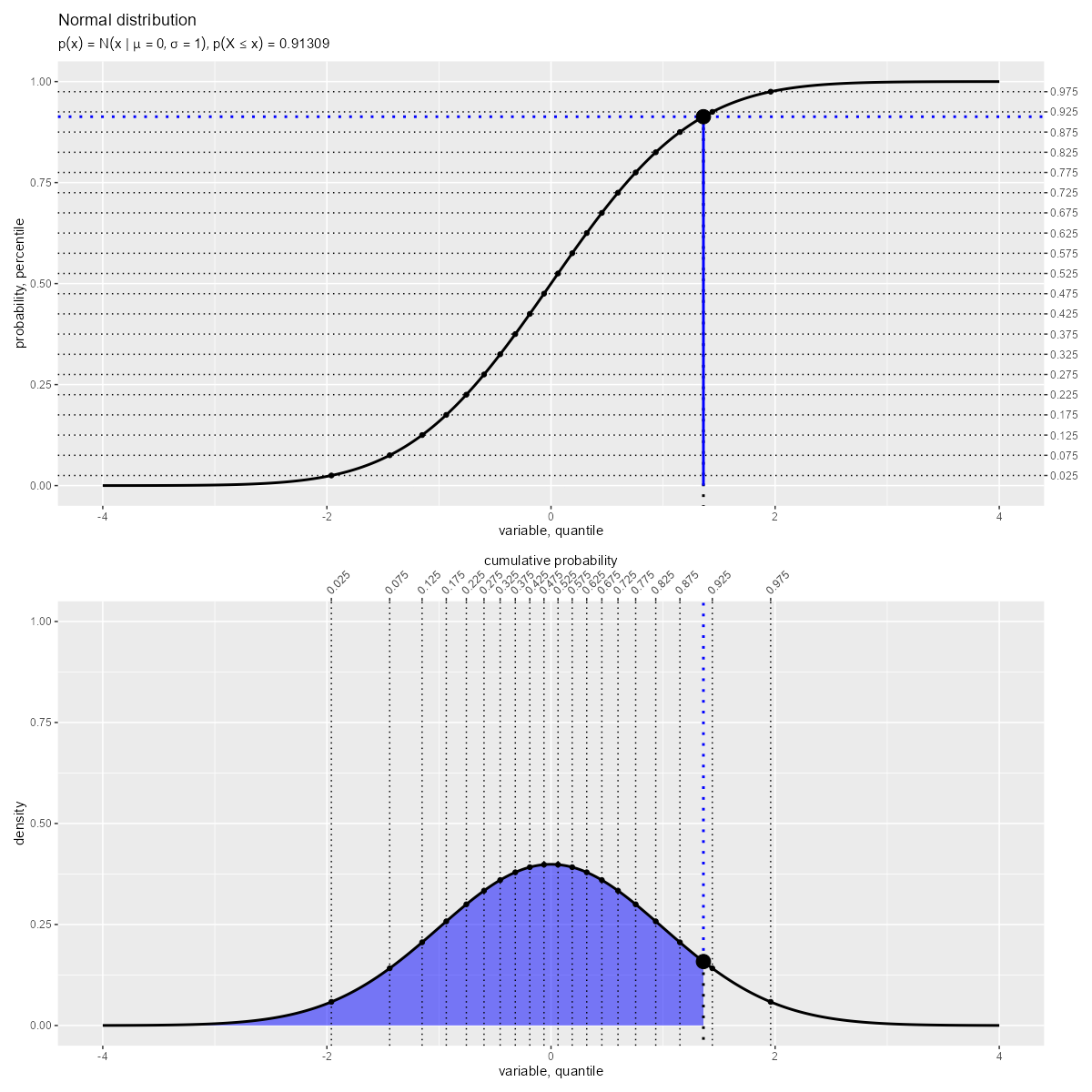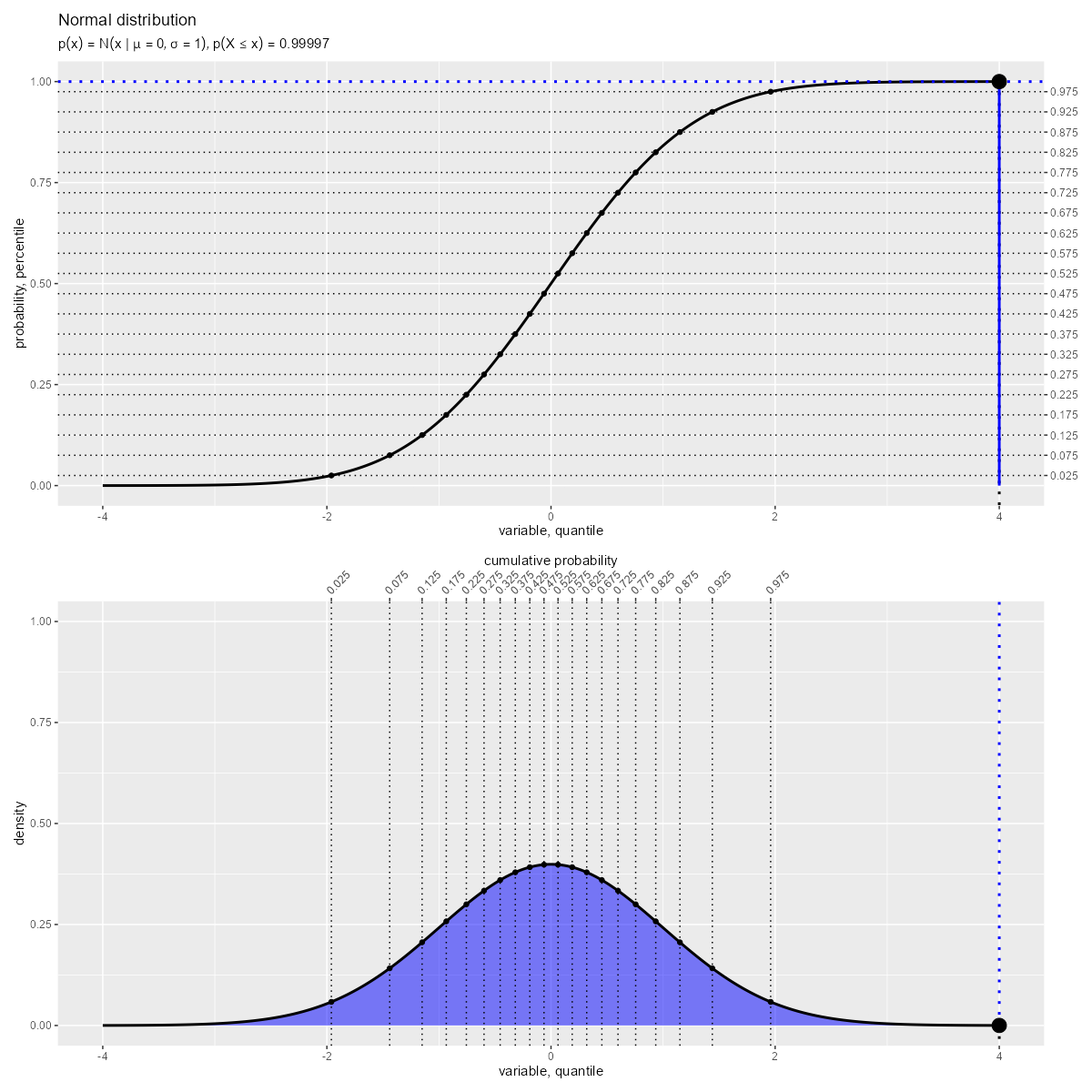
「確率密度関数(曲線)の左側の面積」が「累積分布関数(曲線)の高さ」に対応します。
累積分布関数 は、確率密度関数
の積分で定義され、累積確率を表します。
累積分布関数と確率密度関数の関係
累積分布関数と確率密度関数の関係を確認します。
接線と確率密度の関係のアニメーションを作成します。
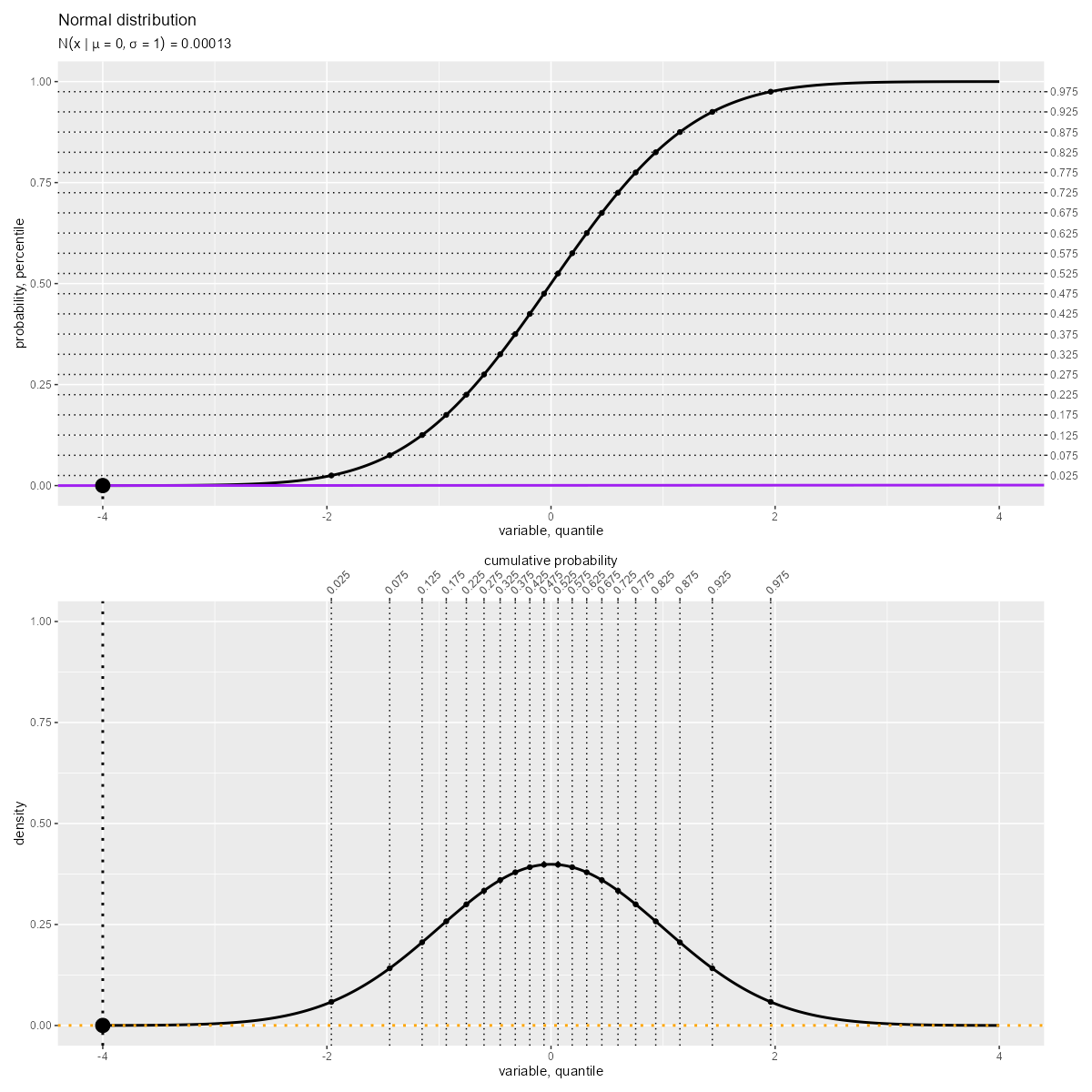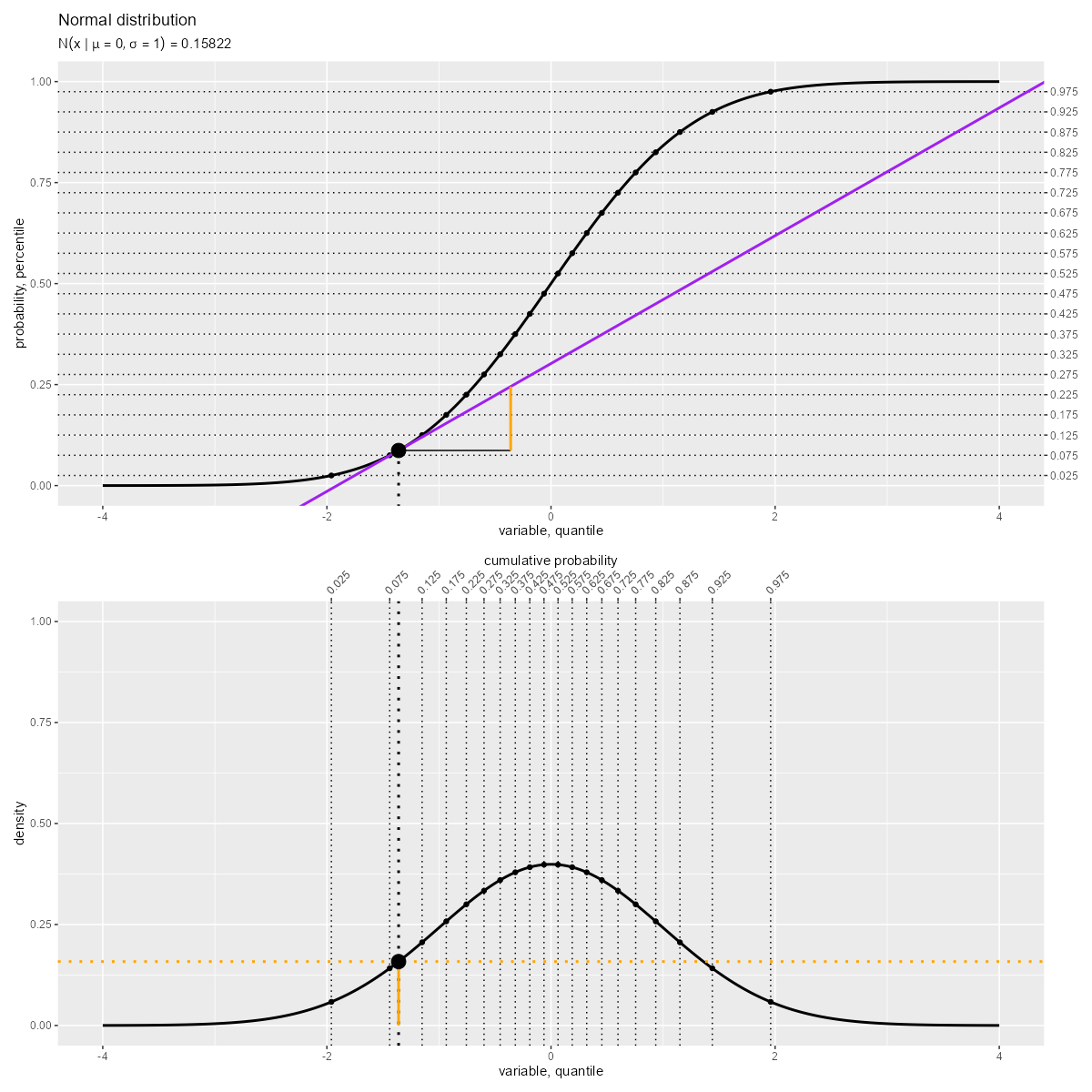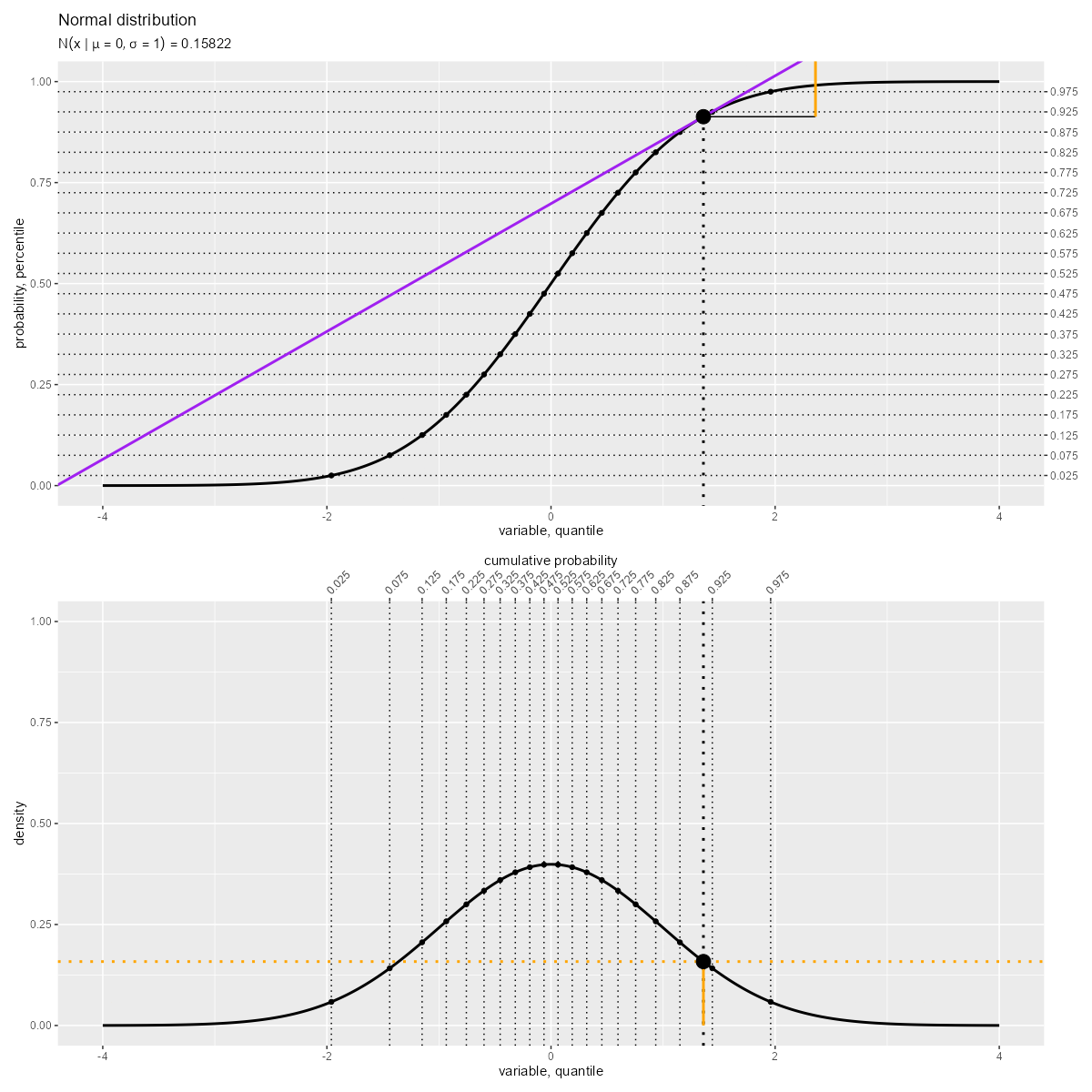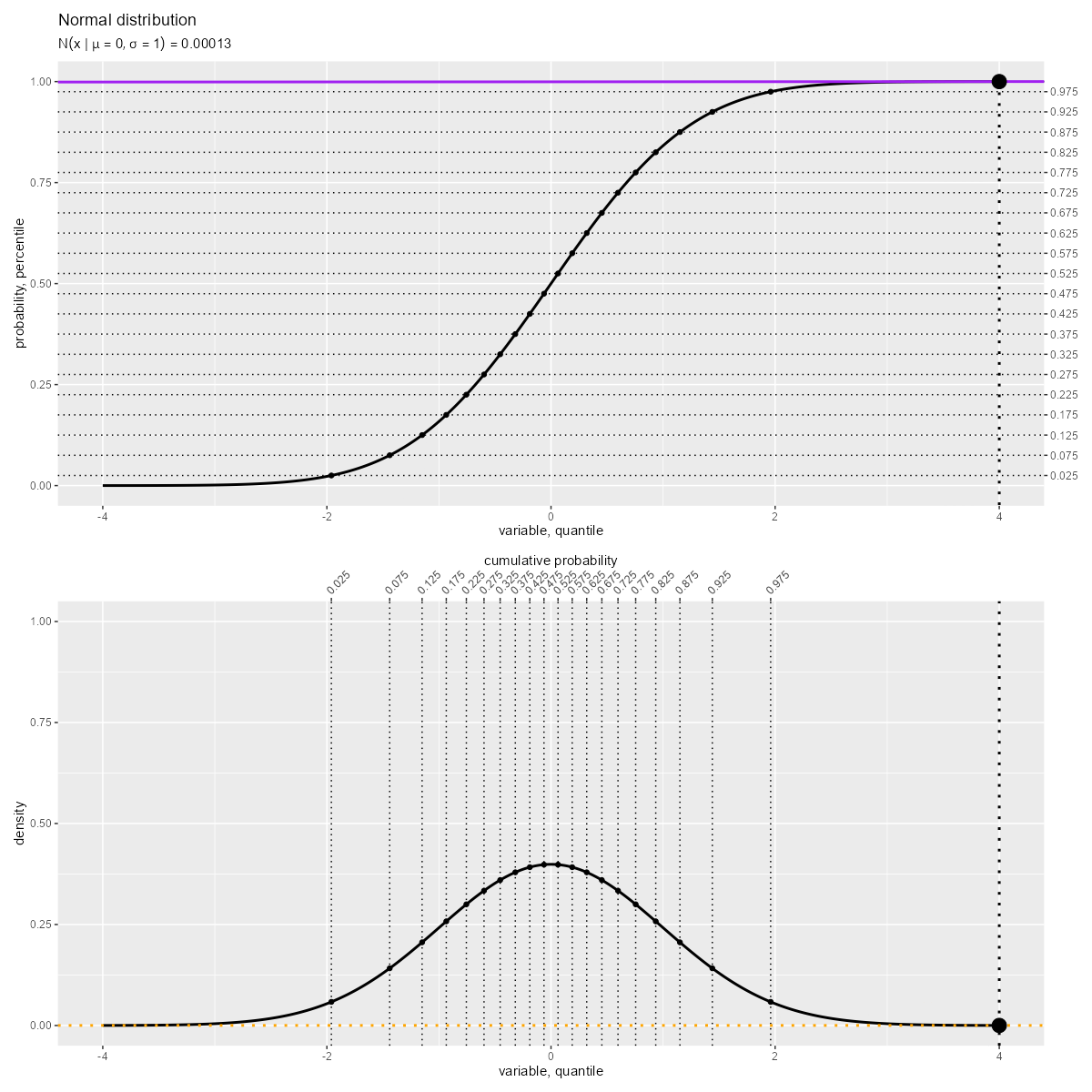
「累積分布関数(曲線)の接線の傾き」が「確率密度関数(曲線)の高さ」に対応します。
確率密度関数 は、累積分布関数
の微分です。
累積分布関数と分位関数の関係
累積分布関数と分位関数の関係を確認します。
パーセンタイルとクォンタイルの関係のアニメーションを作成します。
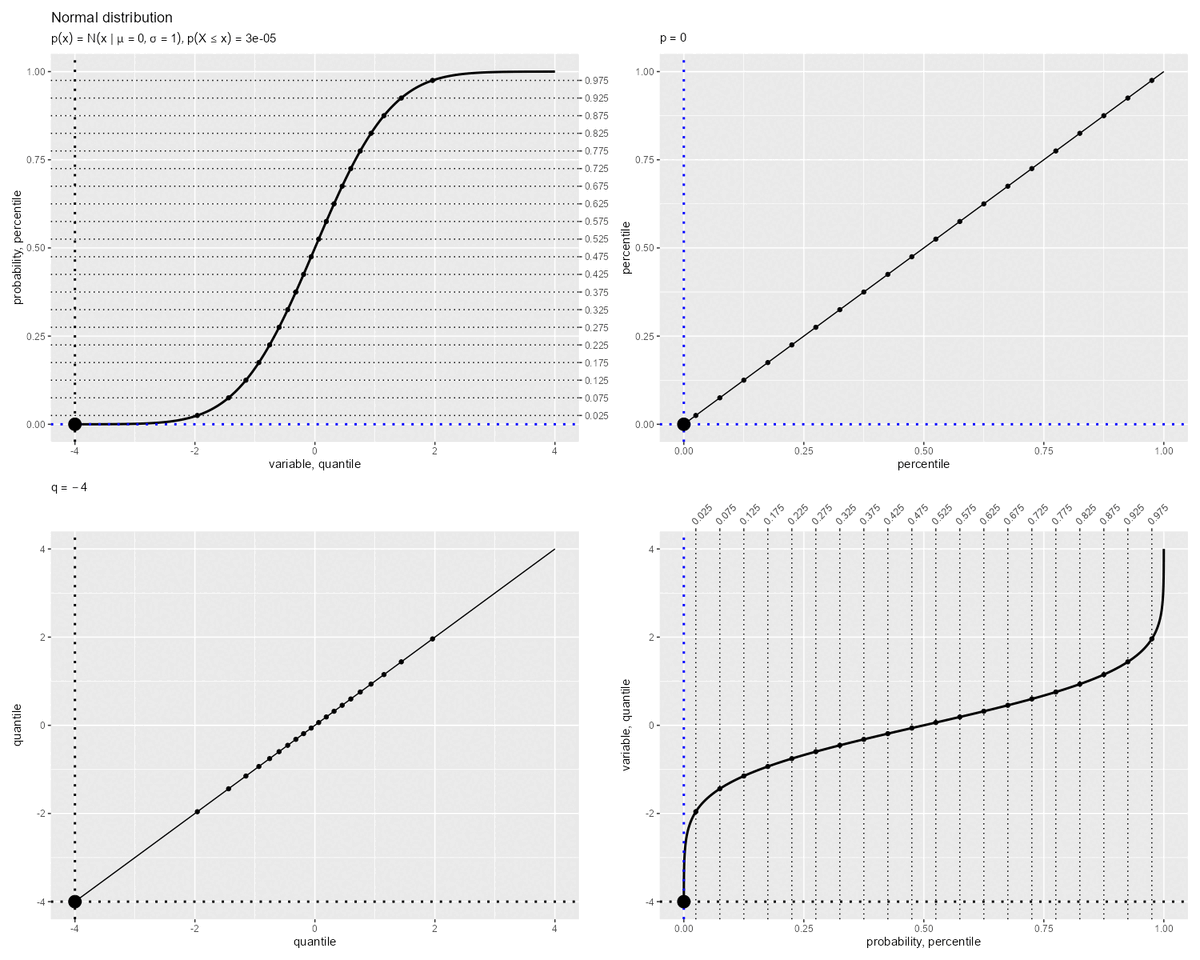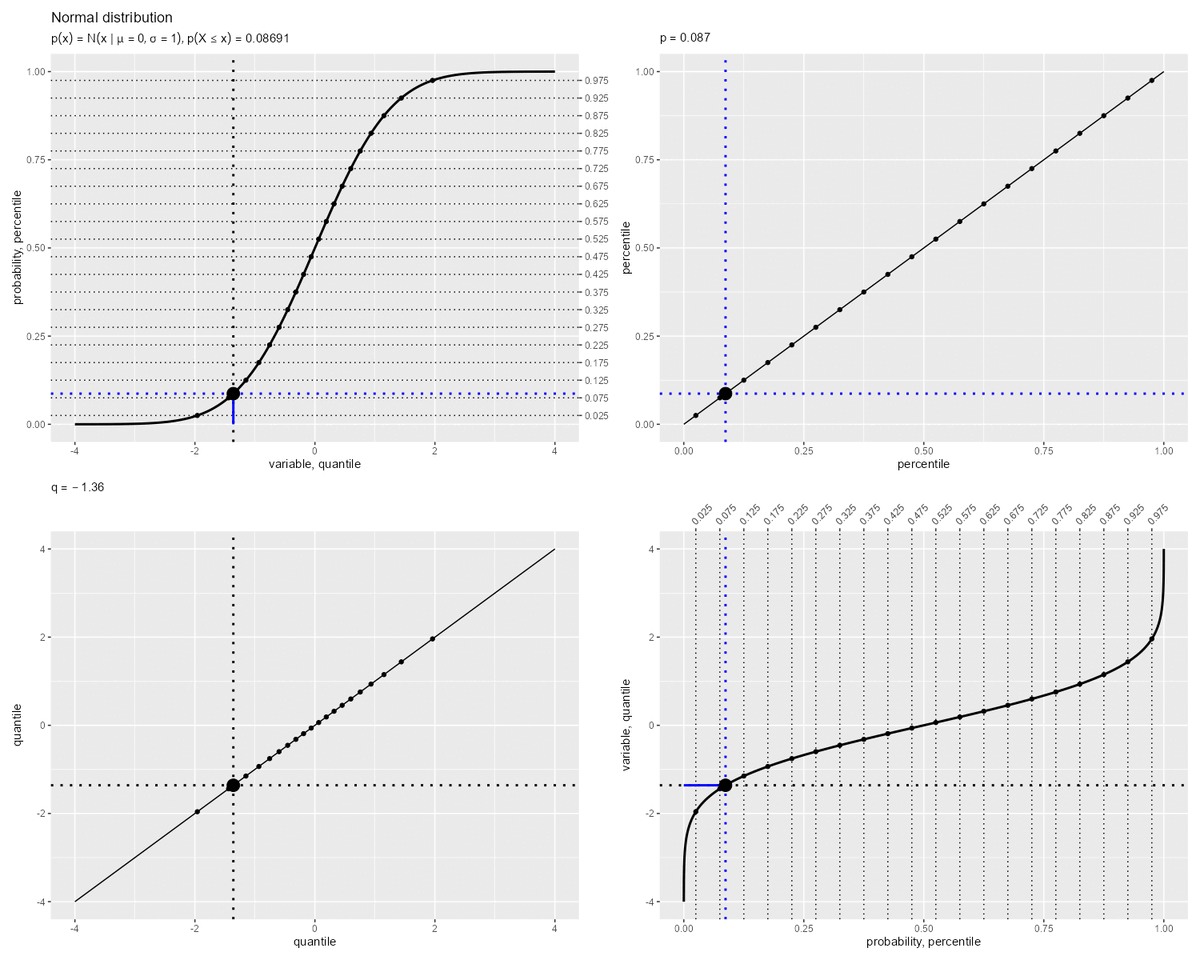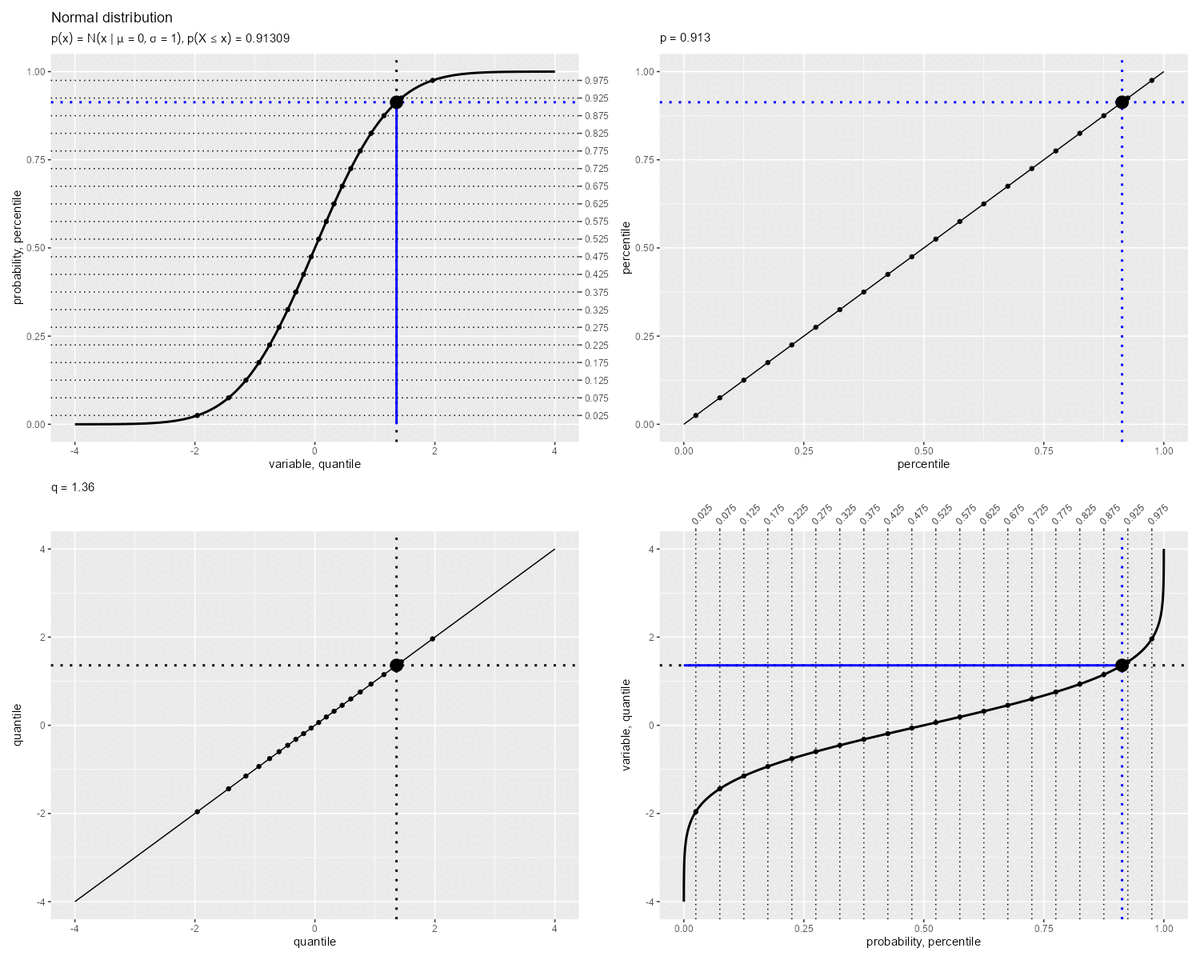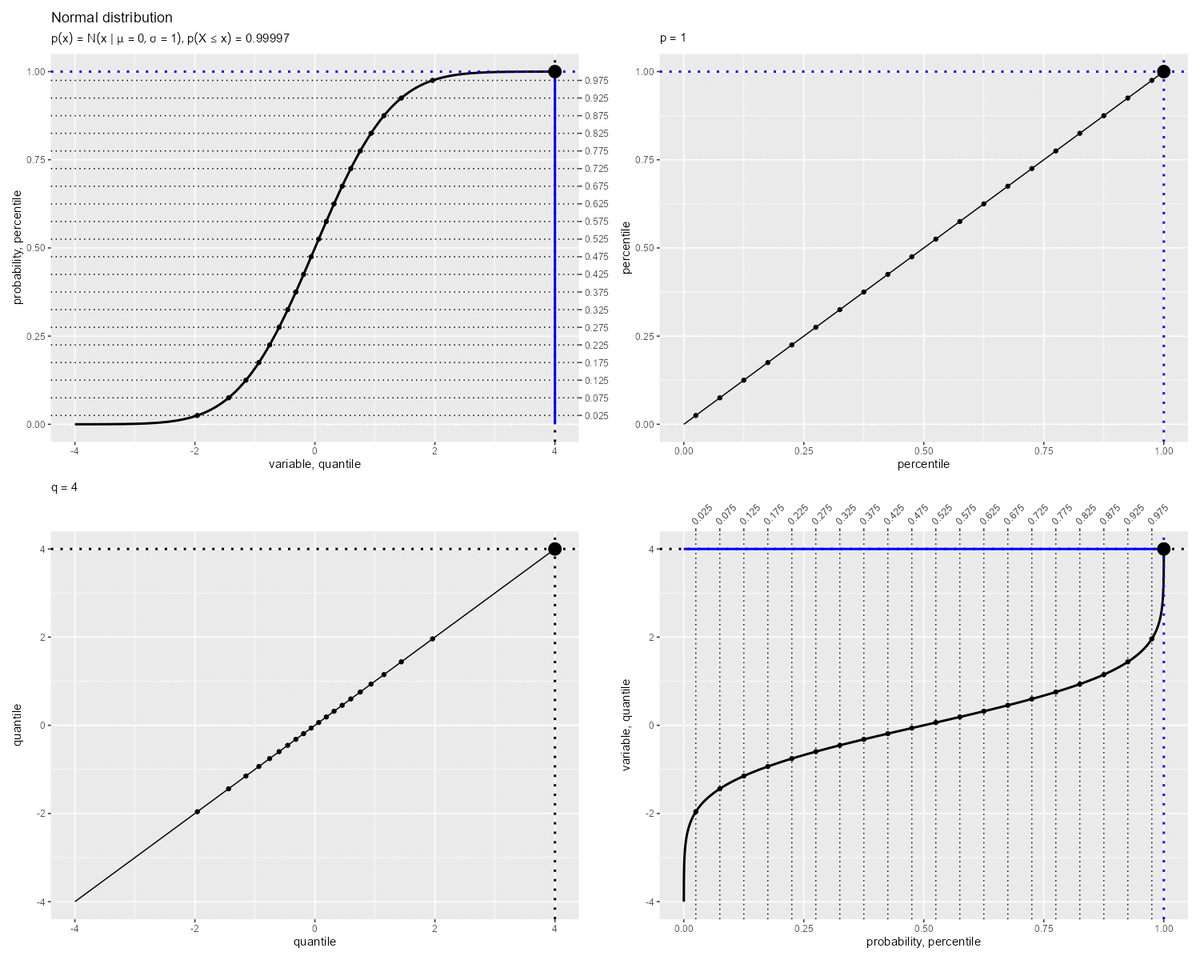
「累積分布関数(曲線)の縦軸・横軸」が「分位関数(曲線)の横軸・縦軸」に対応します。つまり、曲線の軸(関数の入力・出力)を入れ替えた関係です。
累積分布関数 と分位関数
は逆関数で定義されます。
この記事では、正規分布の関数について確認しました。
参考文献

おわりに
これまでは確率密度関数や確率質量関数しか必要にならなかったので、いわゆる確率分布の数式やグラフしか扱いませんでした。勉強すること数年、遂に必要になってしまったので他の形式の定義式やグラフを扱ってみました。と思ったのですが、モーメント母関数や特性関数を扱ったことがあるのを今思い出しました。
扱う範囲が広がると、何となくあった記事タイトルの命名規則(「○○分布の□□の可視化」みたいな感じ)が崩壊しつつあって困ります。
確率分布に限らずですが、用語がなんとも分かりにくいです。さすがに確率と確率密度の違いは分かったつもりですが、確率や左側確率・累積確率・パーセンタイルなどなど場面場面で適切な用語はどれなのか判断できません。そういや確率密度関数のグラフの横軸が変数なのか確率変数なのかなんなのかはっきりしないままここまできてしまいましたが、クォンタイルなるものまで登場して、はぁ。分位数の意味は分かるのですが、用語の扱い方が謎です。あぁ独学つら、ついでにもう年末つら。
しか~し2023年12月27日は、カントリー・ガールズとJuice=Juiceの元メンバーの稲場愛香さんの26歳のお誕生日です!
あぁ可愛い。そろそろソロデビューやソロライブを期待してもいいでしょうか。万能型のアイドルでマルチに活躍できるのは間違いないので、1日でも早く世間に見つかってほしいです。
来年もがんばりまなかん♪
【次の内容】
続きというわけではないですが、Q-Qプロットを理解するためにこの記事を書くことになったので。