はじめに
機械学習で登場する確率分布について色々な角度から理解したいシリーズです。
この記事では、R言語で1次元ガウス分布(一変量正規分布)から1次元ガウス分布を生成します。
【前の内容】
【他の記事一覧】
【この記事の内容】
1次元ガウス分布から確率分布の生成
1次元ガウス分布(Gaussian Distribution)から1次元ガウス分布を生成します。ガウス分布については「1次元ガウス分布の定義式の確認 - からっぽのしょこ」を参照してください。
利用するパッケージを読み込みます。
# 利用パッケージ library(tidyverse) library(patchwork)
この記事では、基本的にパッケージ名::関数名()の記法を使うので、パッケージを読み込む必要はありません。ただし、作図コードがごちゃごちゃしないようにパッケージ名を省略しているため、ggplot2は読み込む必要があります。
magrittrパッケージのパイプ演算子%>%ではなく、ベースパイプ(ネイティブパイプ)演算子|>を使っています。%>%に置き換えても処理できます。
生成分布の設定
まずは、パラメータの生成分布としてガウス分布を設定して、ガウス分布の平均パラメータを生成(サンプリング)します。生成分布を$\mathcal{N}(\mu | \mu_{\mathrm{gen}}, \sigma_{\mathrm{gen}}^2)$、生成された分布を$\mathcal{N}(x | \mu, \sigma^2)$で表すことにします。
ガウス分布(生成分布)のパラメータ$\mu_{\mathrm{gen}}, \sigma_{\mathrm{gen}}$とサンプルサイズ$N$を設定します。
# パラメータを指定 mu_gen <- 2 sigma_gen <- 2.5 # 分布の数(サンプルサイズ)を指定 N <- 10
平均パラメータ(実数)$\mu_{\mathrm{gen}}$、精度パラメータ(正の実数)$\sigma_{\mathrm{gen}}$とデータ数(パラメータ数)$N$を指定します。
ガウス分布に従う乱数を生成します。
# ガウス分布の平均パラメータを生成 mu_n <- rnorm(n = N, mean = mu_gen, sd = sigma_gen) |> # ガウス分布の乱数を生成 sort() # 昇順に並べ替え # パラメータを格納 param_df <- tibble::tibble( mu = mu_n, parameter = round(mu_n, 3) |> factor() # 色分け用ラベル ) param_df
## # A tibble: 10 × 2 ## mu parameter ## <dbl> <fct> ## 1 -2.15 -2.145 ## 2 -1.71 -1.707 ## 3 -1.03 -1.034 ## 4 0.250 0.25 ## 5 0.422 0.422 ## 6 1.22 1.219 ## 7 1.97 1.97 ## 8 2.51 2.511 ## 9 4.11 4.112 ## 10 6.52 6.517
ガウス分布の乱数は、rnorm()で生成できます。データ数(サンプルサイズ)の引数nにN、平均の引数meanにmu_gen、標準偏差の引数sdにsigma_genを指定します。
生成した値をガウス分布の平均パラメータ$\mu$として使います。
ガウス分布を計算します。
# muの値を作成 mu_vals <- seq(from = mu_gen - sigma_gen*3, to = mu_gen + sigma_gen*3, length.out = 251) # 生成分布を計算 gaussian_gen_df <- tibble::tibble( mu = mu_vals, # 確率変数 density = dnorm(x = mu_vals, mean = mu_gen, sd = sigma_gen) # 確率密度 ) gaussian_gen_df
## # A tibble: 250 × 2 ## mu density ## <dbl> <dbl> ## 1 -5.5 0.00177 ## 2 -5.44 0.00191 ## 3 -5.38 0.00205 ## 4 -5.32 0.00220 ## 5 -5.26 0.00236 ## 6 -5.20 0.00253 ## 7 -5.14 0.00271 ## 8 -5.08 0.00290 ## 9 -5.02 0.00310 ## 10 -4.96 0.00332 ## # … with 240 more rows
ガウス分布(生成分布)の確率変数がとり得る値$\mu$を作成して、確率密度を計算します。
ガウス分布の確率密度は、dnorm()で計算できます。確率変数の引数xにx_vals、平均の引数meanにmu_gen、標準偏差の引数sdにsigma_genを指定します。
mu_valsと、mu_valsの各要素に対応する確率密度をデータフレームに格納します。
ガウス分布の期待値$\mathbb{E}[\mu]$を計算します。
# 平均パラメータの期待値を計算 E_mu <- mu_gen
サンプリングされたパラメータとその分布の基準を示すのに使います。
生成分布(ガウス分布)とパラメータのサンプルをプロットします。
# 生成分布とパラメータのサンプルを作図 gaussian_gen_graph <- ggplot() + # データ geom_vline(xintercept = E_mu, color = "red", size = 1, linetype = "dashed") + # パラメータの期待値 geom_line(data = gaussian_gen_df, mapping = aes(x = mu, y = density), color = "#00A968", size = 1) + # パラメータの生成分布 geom_point(data = param_df, mapping = aes(x = mu, y = 0, color = parameter), alpha = 0.8, size = 6, show.legend = FALSE) + # パラメータのサンプル guides(color = guide_legend(override.aes = list(size = 2, alpha = 1))) + # 凡例の体裁 labs( title = "Gaussian Distribution", subtitle = parse( text = paste0("list(mu[paste(g,e,n)]==", mu_gen, ", sigma[paste(g,e,n)]==", sigma_gen, ")"), ), color = expression(mu), x = expression(mu), y = "density" ) # ラベル gaussian_gen_graph
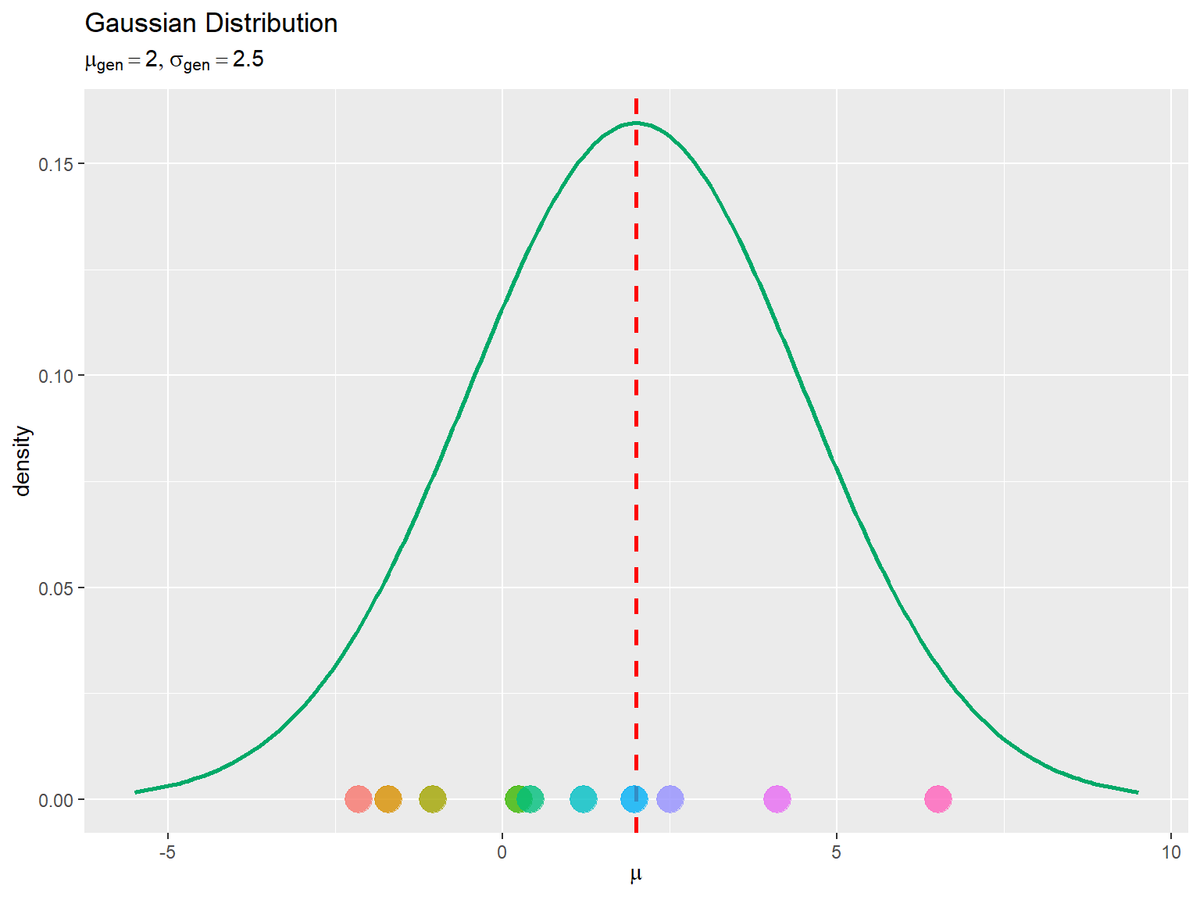
期待値を破線で示します。
以上で、生成分布を設定して、パラメータを生成しました。次は、パラメータのサンプルを用いて、ガウス分布を作図します。
分布の作図:ガウス分布
次に、生成した値をガウス分布の平均パラメータとして利用します。グラフ作成については「【R】1次元ガウス分布の作図 - からっぽのしょこ」を参照してください。
パラメータのサンプルごとにガウス分布を計算します。
# 標準偏差パラメータを指定 sigma <- 1 # xの値を作成 x_vals <- mu_vals # パラメータのサンプルごとにガウス分布を計算 res_gaussian_df <- tidyr::expand_grid( x = x_vals, mu = mu_n ) |> # 全ての組み合わせを作成 dplyr::arrange(mu, x) |> # パラメータごとに並べ替え dplyr::mutate( density = dnorm(x = x, mean = mu, sd = sigma), # 確率密度 parameter = round(mu, 3) |> factor() # 色分け用ラベル ) res_gaussian_df
## # A tibble: 2,500 × 4 ## x mu density parameter ## <dbl> <dbl> <dbl> <fct> ## 1 -5.5 -2.15 0.00144 -2.145 ## 2 -5.44 -2.15 0.00175 -2.145 ## 3 -5.38 -2.15 0.00214 -2.145 ## 4 -5.32 -2.15 0.00259 -2.145 ## 5 -5.26 -2.15 0.00313 -2.145 ## 6 -5.20 -2.15 0.00377 -2.145 ## 7 -5.14 -2.15 0.00452 -2.145 ## 8 -5.08 -2.15 0.00540 -2.145 ## 9 -5.02 -2.15 0.00644 -2.145 ## 10 -4.96 -2.15 0.00764 -2.145 ## # … with 2,490 more rows
ガウス分布(生成された分布)の確率変数がとり得る値$x$を作成してx_valsとします。この例では、作図時に対応関係が分かりやすいように、mu_valsの値を使います。
x_valsとmu_nそれぞれの要素の全ての組み合わせをexpand_grid()で作成して、組み合わせごとに確率を計算します。
ガウス分布の確率密度をdnorm()で計算します。確率変数の引数xにx_valsの値、平均の引数meanにmu_nの値、標準偏差の引数sdにsigmaを指定します。
ガウス分布(生成分布)の期待値(ガウス分布(生成された分布)の平均パラメータの期待値)を用いて、ガウス分布を計算します。
# パラメータの期待値によるガウス分布を計算 E_gaussian_df <- tidyr::tibble( x = x_vals, # 確率変数 density = dnorm(x = x_vals, mean = E_mu, sd = sigma) # 確率密度 ) E_gaussian_df
## # A tibble: 250 × 2 ## x density ## <dbl> <dbl> ## 1 -5.5 2.43e-13 ## 2 -5.44 3.82e-13 ## 3 -5.38 5.97e-13 ## 4 -5.32 9.29e-13 ## 5 -5.26 1.44e-12 ## 6 -5.20 2.23e-12 ## 7 -5.14 3.43e-12 ## 8 -5.08 5.26e-12 ## 9 -5.02 8.05e-12 ## 10 -4.96 1.23e-11 ## # … with 240 more rows
mean引数にE_muを指定します。
$N + 1$個のガウス分布を作図します。
# サンプルと期待値によるガウス分布を作図 gaussian_graph <- ggplot() + geom_line(data = E_gaussian_df, mapping = aes(x = x, y = density), color = "red", size = 1, linetype = "dashed") + # 期待値による分布 geom_line(data = res_gaussian_df, mapping = aes(x = x, y = density, color = parameter), alpha = 0.8, size = 1) + # サンプルによる分布 labs( title = "Gaussian Distribution", subtitle = parse(text = paste0("list(E(mu)==", E_mu, ", sigma==", sigma, ")"), ), color = expression(mu), x = "x", y = "density" ) # ラベル gaussian_graph
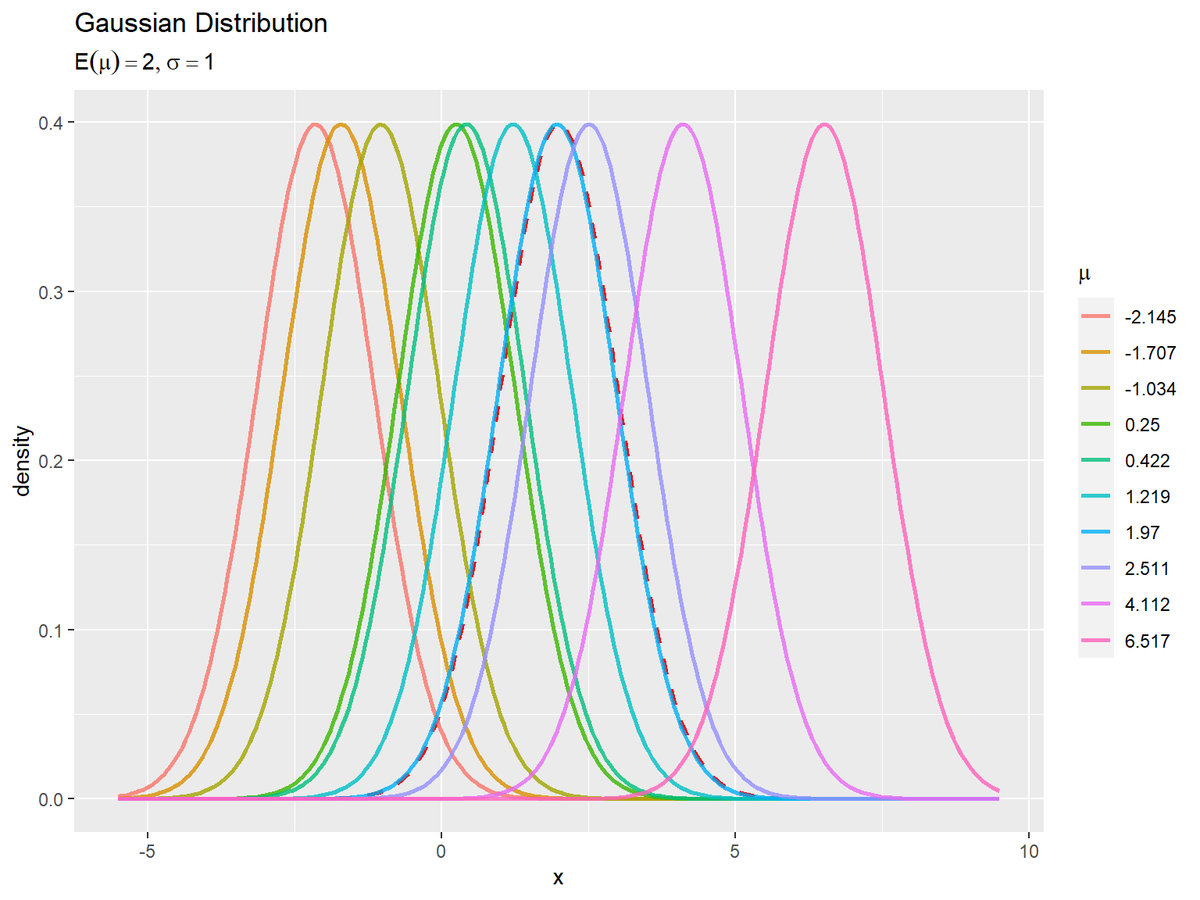
期待値による分布を破線で示します。
パラメータの生成分布(ガウス分布)と生成された分布(ガウス分布)を並べて描画します。
# グラフを並べて描画 gaussian_gen_graph / gaussian_graph + patchwork::plot_layout(guides = "collect")

patchworkパッケージの/演算子を使うと上下に並べて描画できます。
平均$\mu$が大きいほど、$x$が大きいほど確率密度が大きくなり、山が右に位置します。パラメータのサンプルの点と、分布のピークが対応しているのが分かります。
この記事では、1次元ガウス分布からの分布生成を確認しました。
参考文献
- 須山敦志『ベイズ推論による機械学習入門』(機械学習スタートアップシリーズ)杉山将監修,講談社,2017年.
おわりに
加筆修正の際に「ガウス分布の作図」から記事を分割しました。
投稿日に公開されたこの動画を観てください聴いてください。
9年ぶりのデュエット最高。お互いソロになってのこの曲ほんと泣ける。早く現場で聴きたい。
【次の内容】