はじめに
機械学習で登場する確率分布について色々な角度から理解したいシリーズです。
ポアソン分布のグラフをR言語で作成します。
【前の内容】
【他の記事一覧】
【この記事の内容】
ポアソン分布の作図
ポアソン分布(Poisson Distribution)のグラフを作成します。ポアソン分布については「ポアソン分布の定義式の確認 - からっぽのしょこ」を参照してください。
利用するパッケージを読み込みます。
# 利用パッケージ library(tidyverse) library(gganimate)
この記事では、基本的にパッケージ名::関数名()の記法を使うので、パッケージを読み込む必要はありません。ただし、作図コードがごちゃごちゃしないようにパッケージ名を省略しているため、ggplot2は読み込む必要があります。
magrittrパッケージのパイプ演算子%>%ではなく、ベースパイプ(ネイティブパイプ)演算子|>を使っています。%>%に置き換えても処理できます。
分布の変化をアニメーション(gif画像)で確認するのにgganimateパッケージを利用します。不要であれば省略してください。
定義式の確認
まずは、ポアソン分布の定義式を確認します。
ポアソン分布は、次の式で定義されます。
ここで、$x$は単位時間における事象の発生回数、$\lambda$は発生回数の期待値です。
確率変数の実現値$x$は0以上の整数となります。パラメータ$\lambda$は、$\lambda > 0$を満たす必要があります。
ポアソン分布の期待値と分散は、どちらもパラメータ$\lambda$になります。
最頻値は、$\lambda$未満の最大の整数です。
ポアソン分布の歪度と尖度は、次の式で計算できます。
これらの計算を行いグラフを作成します。
グラフの作成
ggplot2パッケージを利用して、ポアソン分布のグラフを作成します。ポアソン分布の確率や統計量の計算については「【R】ポアソン分布の計算 - からっぽのしょこ」を参照してください。
ポアソン分布のパラメータ$\lambda$を設定します。
# パラメータを指定 lambda <- 4.5
発生回数の期待値$\lambda > 0$を指定します。
ポアソン分布の確率変数がとり得る値$x$を作成します。
# xの値を作成 x_vals <- seq(from = 0, to = ceiling(lambda) * 3) head(x_vals)
## [1] 0 1 2 3 4 5
非負の整数$x$を作成してx_valsとします。この例では、0からlambdaの4倍を範囲とします。ただし、非負の整数とするため、ceiling()で値を切り上げて使います。
$x$の値ごとに確率を計算します。
# ポアソン分布を計算 prob_df <- tidyr::tibble( x = x_vals, # 確率変数 probability = dpois(x = x_vals, lambda = lambda) # 確率 ) prob_df
## # A tibble: 16 × 2 ## x probability ## <int> <dbl> ## 1 0 0.0111 ## 2 1 0.0500 ## 3 2 0.112 ## 4 3 0.169 ## 5 4 0.190 ## 6 5 0.171 ## 7 6 0.128 ## 8 7 0.0824 ## 9 8 0.0463 ## 10 9 0.0232 ## 11 10 0.0104 ## 12 11 0.00426 ## 13 12 0.00160 ## 14 13 0.000554 ## 15 14 0.000178 ## 16 15 0.0000534
ポアソン分布の確率は、dpois()で計算できます。確率変数の引数xにx_vals、パラメータの引数lambdaにlambdaを指定します。
x_valsと、x_valsの各要素に対応する確率をデータフレームに格納します。
ポアソン分布のグラフを作成します。
# ポアソン分布のグラフを作成 ggplot(data = prob_df, mapping = aes(x = x, y = probability)) + # データ geom_bar(stat = "identity", fill = "#00A968") + # 棒グラフ scale_x_continuous(breaks = x_vals, minor_breaks = FALSE) + # x軸目盛 labs(title = "Poisson Distribution", subtitle = paste0("lambda=", lambda), # (文字列表記用) #subtitle = parse(text = paste0("lambda==", lambda)), # (数式表記用) x = "x", y = "probability") # ラベル
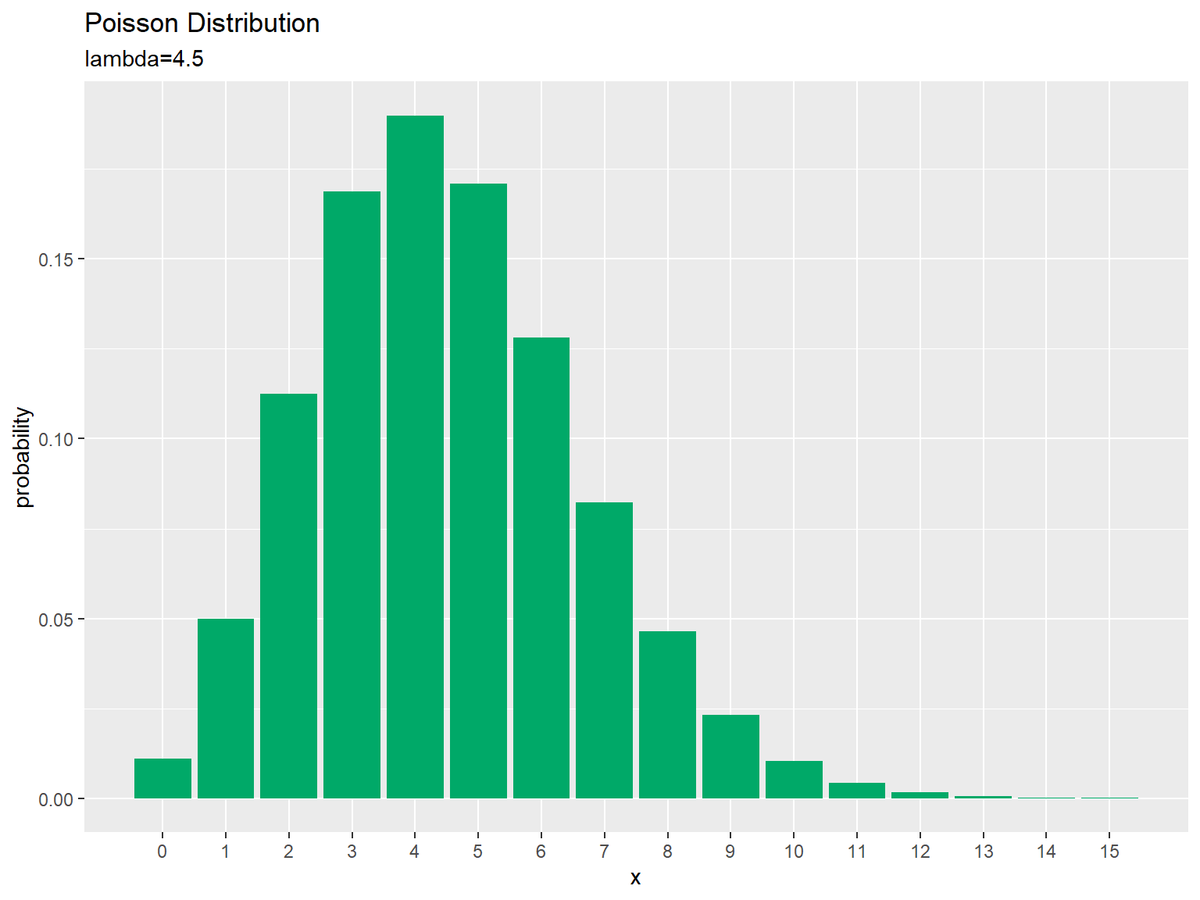
ギリシャ文字などの記号を使った数式を表示する場合は、expression()の記法を使います。等号は"=="、複数の(数式上の)変数を並べるには"list(変数1, 変数2)"とします。(プログラム上の)変数の値を使う場合は、parse()のtext引数に指定します。
この分布に統計量の情報を重ねて表示します。
# 補助線用の統計量の計算 E_x <- lambda s_x <- sqrt(lambda) mode_x <- floor(lambda) # 統計量を重ねたポアソン分布を作図:線のみ ggplot(data = prob_df, mapping = aes(x = x, y = probability)) + # データ geom_bar(stat = "identity", fill = "#00A968") + # 分布 geom_vline(xintercept = E_x, color = "blue", size = 1, linetype = "dashed") + # 期待値 geom_vline(xintercept = E_x-s_x, color = "orange", size = 1, linetype = "dotted") + # 期待値 - 標準偏差 geom_vline(xintercept = E_x+s_x, color = "orange", size = 1, linetype = "dotted") + # 期待値 + 標準偏差 geom_vline(xintercept = mode_x, color = "chocolate", size = 1, linetype = "dashed") + # 最頻値 scale_x_continuous(breaks = x_vals, minor_breaks = FALSE) + # x軸目盛 labs(title = "Poisson Distribution", subtitle = parse(text = paste0("lambda==", lambda)), x = "x", y = "probability") # ラベル
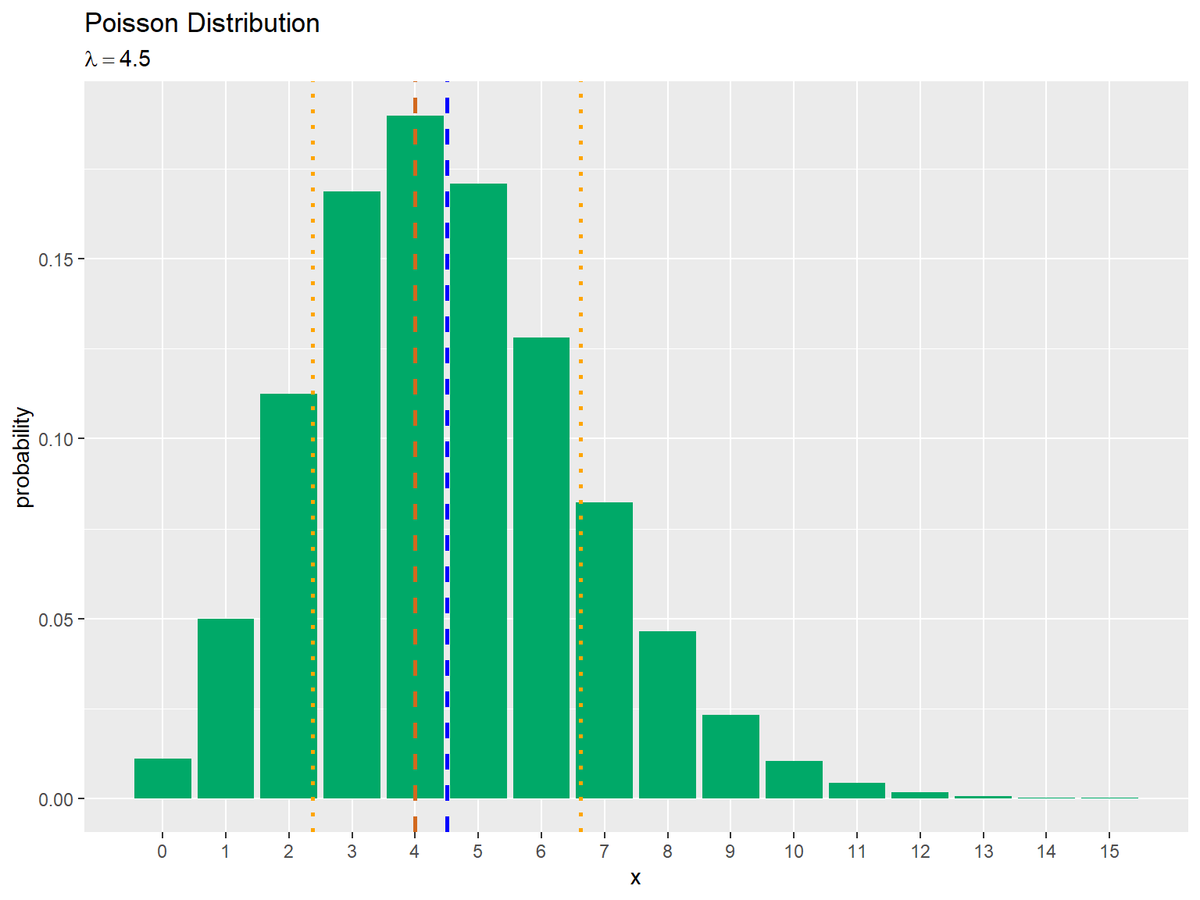
期待値・標準偏差(分散の平方根)・最頻値を計算して、それぞれgeom_vline()で垂直線を引きます。標準偏差については期待値から足し引きした値を使います。
凡例を表示する場合は、垂直線を引く値をデータフレームにまとめます。
# 統計量を格納 stat_df <- tibble::tibble( statistic = c(E_x, E_x-s_x, E_x+s_x, mode_x), # 統計量 type = c("mean", "sd", "sd", "mode") # 色分け用ラベル ) stat_df
## # A tibble: 4 × 2 ## statistic type ## <dbl> <chr> ## 1 4.5 mean ## 2 2.38 sd ## 3 6.62 sd ## 4 4 mode
各統計量を区別するための文字列とデータフレームに格納します。期待値と標準偏差の差・和は同じタイプとします。
線の色や種類、凡例テキストを指定する場合は、設定用の名前付きベクトルを作成します。
# 凡例用の設定を作成:(数式表示用) color_vec <- c(mean = "blue", sd = "orange", mode = "chocolate") linetype_vec <- c(mean = "dashed", sd = "dotted", mode = "dashed") label_vec <- c(mean = expression(E(x)), sd = expression(E(x) %+-% sqrt(V(x))), mode = expression(mode(x)))
各要素(設定)の名前をtype列の文字列と対応させて、設定(線の色・種類と数式用のテキスト)を指定します。
凡例付きのグラフを作成します。
# 統計量を重ねたポアソン分布のグラフを作成:凡例付き ggplot() + # データ geom_bar(data = prob_df, mapping = aes(x = x, y = probability), stat = "identity", position = "dodge", fill = "#00A968") + # 分布 geom_vline(data = stat_df, mapping = aes(xintercept = statistic, color = type, linetype = type), size = 1) + # 統計量 scale_x_continuous(breaks = x_vals, minor_breaks = FALSE) + # x軸目盛 scale_color_manual(values = color_vec, labels = label_vec, name = "statistic") + # 線の色:(色指定と数式表示用) scale_linetype_manual(values = linetype_vec, labels = label_vec, name = "statistic") + # 線の種類:(線指定と数式表示用) theme(legend.text.align = 0) + # 図の体裁:凡例 labs(title = "Poisson Distribution", subtitle = parse(text = paste0("lambda==", lambda)), x = "x", y = "probability") # ラベル

scale_color_manual()のvalues引数に線の色、scale_linetype_manual()のvalues引数に線の種類を指定します。凡例テキストを指定する場合は、それぞれのlabels引数に指定します。names引数は凡例ラベルです。
凡例テキストは、theme()のlegend.text.align引数に0を指定すると左寄せ、デフォルト(1)だと右寄せになります。
期待値(青色の破線)以下の最大の整数となる確率が最大であり、最頻値(茶色の破線)と一致するのを確認できます。また、平均を中心に標準偏差の範囲をオレンジ色の点線で示しています。非対称な形状なのが分かります。
ポアソン分布のグラフを描画できました。以降は、ここまでの作図処理を用いて、パラメータの影響を確認していきます。
パラメータと分布の関係を並べて比較
次は、複数のパラメータのグラフを比較することで、パラメータの値と分布の形状の関係を確認します。
・作図コード(クリックで展開)
複数の$\lambda$を指定して、それぞれ分布を計算します。
# パラメータとして利用する値を指定 lambda_vals <- c(1, 5.5, 10, 15.7) # xの値を作成 x_vals <- seq(from = 0, to = ceiling(max(lambda_vals)) * 2) # パラメータごとにポアソン分布を計算 res_prob_df <- tidyr::expand_grid( x = x_vals, lambda = lambda_vals ) |> # 全ての組み合わせを作成 dplyr::arrange(lambda, x) |> # パラメータごとに並べ替え dplyr::mutate( probability = dpois(x = x, lambda = lambda), parameter = paste0("lambda=", lambda) |> factor(levels = paste0("lambda=", sort(lambda_vals))) # 色分け用ラベル ) # 確率を計算 res_prob_df
## # A tibble: 132 × 4 ## x lambda probability parameter ## <int> <dbl> <dbl> <fct> ## 1 0 1 0.368 lambda=1 ## 2 1 1 0.368 lambda=1 ## 3 2 1 0.184 lambda=1 ## 4 3 1 0.0613 lambda=1 ## 5 4 1 0.0153 lambda=1 ## 6 5 1 0.00307 lambda=1 ## 7 6 1 0.000511 lambda=1 ## 8 7 1 0.0000730 lambda=1 ## 9 8 1 0.00000912 lambda=1 ## 10 9 1 0.00000101 lambda=1 ## # … with 122 more rows
確率変数x_valsとパラメータlambda_valsそれぞれの要素の全ての組み合わせをexpand_grid()で作成します。
組み合わせごとに確率を計算して、パラメータごとにラベルを作成します。ラベルは、グラフの設定や凡例テキストとして使います。文字列型だと文字列の基準で順序が決まるので、因子型にしてパラメータに応じたレベル(順序)を設定します。
凡例を数式で表示する場合は、expression()に対応した記法に変換します。
# 凡例用のラベルを作成:(数式表示用) label_vec <- res_prob_df[["parameter"]] |> stringr::str_replace_all(pattern = "=", replacement = "==") |> # 等号表示用の記法に変換 (\(.){paste0("list(", ., ")")})() |> # カンマ表示用の記法に変換 unique() |> # 重複を除去 parse(text = _) # expression関数化 names(label_vec) <- unique(res_prob_df[["parameter"]]) # ggplotに指定する文字列に対応する名前付きベクトルに変換 label_vec[1]
## expression(`lambda=1` = list(lambda == 1))
変換後の文字列のベクトルに対してnames()を使って、元の文字列を各要素の名前として設定します。
3行目の処理では、無名関数function()の省略記法\()を使って、(\(x){引数xを使った具体的な処理})()としています。直前のパイプ演算子を%>%にすると、行全体(\(引数){処理})()を{}の中の処理に置き換えられます(置き換えられるように引数名を.にしています)。
res_prob_dfのparameter列の要素lambda=1と、変換後の文字列list(lambda == 1)が対応しています。
パラメータごとにポアソン分布を作図します。
# パラメータごとにポアソン分布のグラフを作成:棒グラフ ggplot(data = res_prob_df, mapping = aes(x = x, y = probability, fill = parameter, color = parameter)) + # データ geom_bar(stat = "identity", position = "dodge") + # 棒グラフ #scale_x_continuous(breaks = x_vals, minor_breaks = FALSE) + # x軸目盛 scale_color_hue(labels = label_vec) + # 線の色:(数式表示用) scale_fill_hue(labels = label_vec) + # 塗りつぶしの色:(数式表示用) theme(legend.text.align = 0) + # 図の体裁:凡例 labs(title = "Poisson Distribution", fill = "parameter", color = "parameter", x = "x", y = "probability") # タイトル
棒グラフを並べると分かりにくい場合は、散布図と折れ線グラフを重ねて可視化します。
# パラメータごとにポアソン分布のグラフを作成:点グラフ ggplot(data = res_prob_df, mapping = aes(x = x, y = probability, fill = parameter, color = parameter)) + # データ geom_point(size = 3) + # 散布図 geom_line(size = 1) + # 折れ線グラフ #scale_x_continuous(breaks = x_vals, minor_breaks = FALSE) + # x軸目盛 scale_color_hue(labels = label_vec) + # 線の色:(数式表示用) scale_fill_hue(labels = label_vec) + # 塗りつぶしの色:(数式表示用) theme(legend.text.align = 0) + # 図の体裁:凡例 labs(title = "Poisson Distribution", fill = "parameter", color = "parameter", x = "x", y = "probability") # タイトル

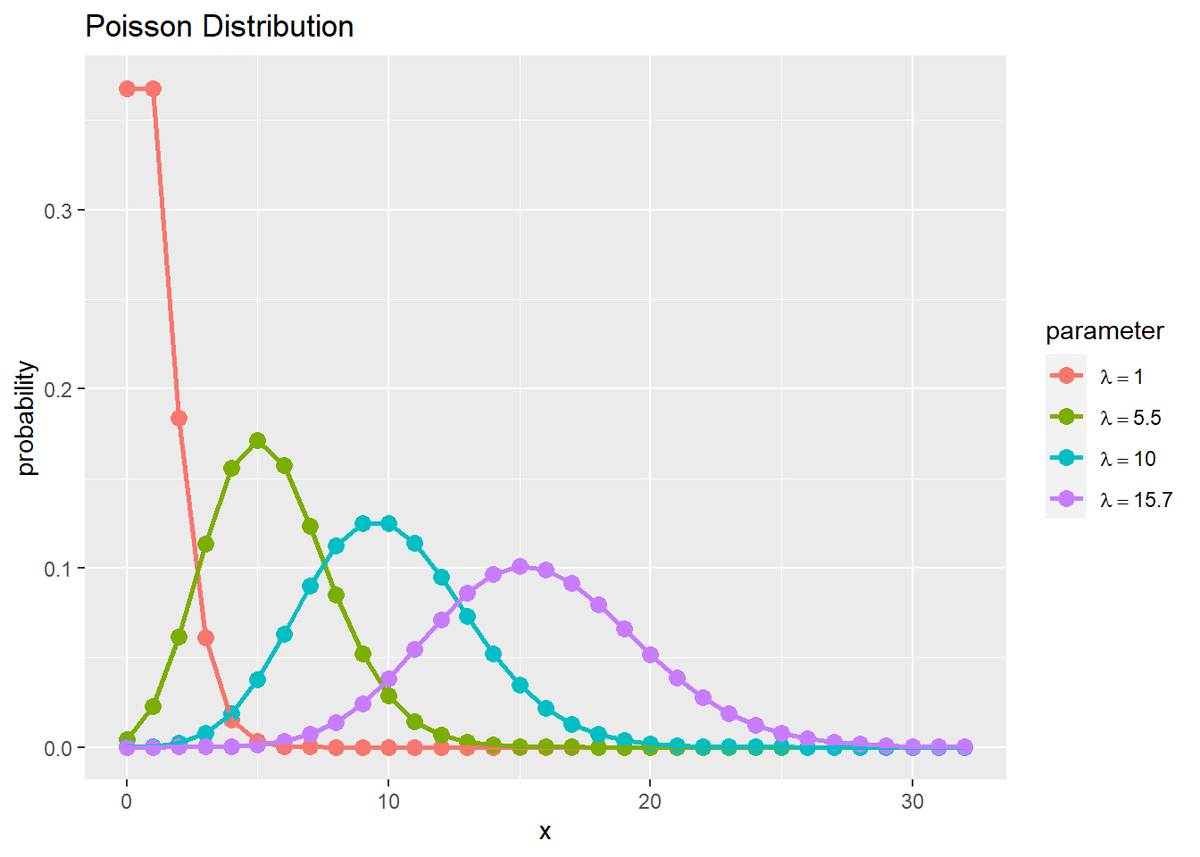
発生回数の期待値$\lambda$が大きいと、発生回数$x$が大きいほど確率が高くなる(山が右に位置する)のが分かります。このことは、平均の計算式からも分かります。
また分散の計算式からも分かるように、$\lambda$が大きいほど分布の裾が広く確率の最大値が小さく(なだらかな山に)なります。
パラメータと分布の関係をアニメーションで可視化
前節では、複数のパラメータのグラフを並べて比較しました。次は、パラメータの値を少しずつ変化させて、分布の形状の変化をアニメーションで確認します。
・作図コード(クリックで展開)
$\lambda$の値を変化させ、それぞれ分布を計算します。
# パラメータとして利用する値を指定 lambda_vals <- seq(from = 0, to = 10, by = 0.1) #length(lambda_vals) # フレーム数 # xの値を作成 x_vals <- seq(from = 0, to = ceiling(max(lambda_vals)) * 2) # パラメータごとにポアソン分布を計算 anime_prob_df <- tidyr::expand_grid( x = x_vals, lambda = lambda_vals ) |> # 全ての組み合わせを作成 dplyr::arrange(lambda, x) |> # パラメータごとに並べ替え dplyr::mutate( probability = dpois(x = x, lambda = lambda), parameter = paste0("lambda=", lambda) |> factor(levels = paste0("lambda=", sort(lambda_vals))) # フレーム切替用ラベル ) # 確率を計算 anime_prob_df
## # A tibble: 2,121 × 4 ## x lambda probability parameter ## <int> <dbl> <dbl> <fct> ## 1 0 0 1 lambda=0 ## 2 1 0 0 lambda=0 ## 3 2 0 0 lambda=0 ## 4 3 0 0 lambda=0 ## 5 4 0 0 lambda=0 ## 6 5 0 0 lambda=0 ## 7 6 0 0 lambda=0 ## 8 7 0 0 lambda=0 ## 9 8 0 0 lambda=0 ## 10 9 0 0 lambda=0 ## # … with 2,111 more rows
値の間隔が一定になるようにlambda_valsを作成します。パラメータごとにフレームを切り替えるので、lambda_valsの要素数がアニメーションのフレーム数になります。
データフレームの変数名以外は「並べて比較」のときと同じ処理です。アニメーションの作図では、parameter列をフレーム切替用のラベルとして使います。
ポアソン分布のアニメーション(gif画像)を作成します。
# ポアソン分布にアニメーションを作図 anime_prob_graph <- ggplot(data = anime_prob_df, mapping = aes(x = x, y = probability)) + # データ geom_bar(stat = "identity", fill = "#00A968") + # 棒グラフ gganimate::transition_manual(parameter) + # フレーム scale_x_continuous(breaks = x_vals, minor_breaks = FALSE) + # x軸目盛 coord_cartesian(ylim = c(0, 0.5)) + # 軸の表示範囲 labs(title = "Poisson Distribution", subtitle = "{current_frame}", x = "x", y = "probability") # ラベル # gif画像を作成 gganimate::animate(anime_prob_graph, nframes = length(lambda_vals), fps = 10, width = 800, height = 600)
transition_manual()にフレームの順序を表す列を指定します。この例では、因子型のラベルのレベルの順に描画されます。
animate()のフレーム数の引数nframesにパラメータ数、フレームレートの引数fpsに1秒当たりのフレーム数を指定します。fps引数の値が大きいほどフレームが早く切り替わります。ただし、値が大きいと指定した通りに動作しません。
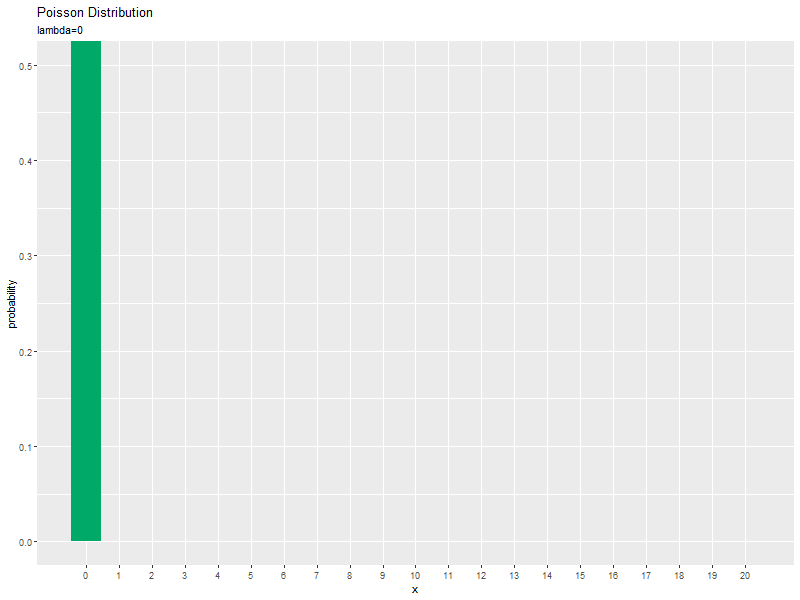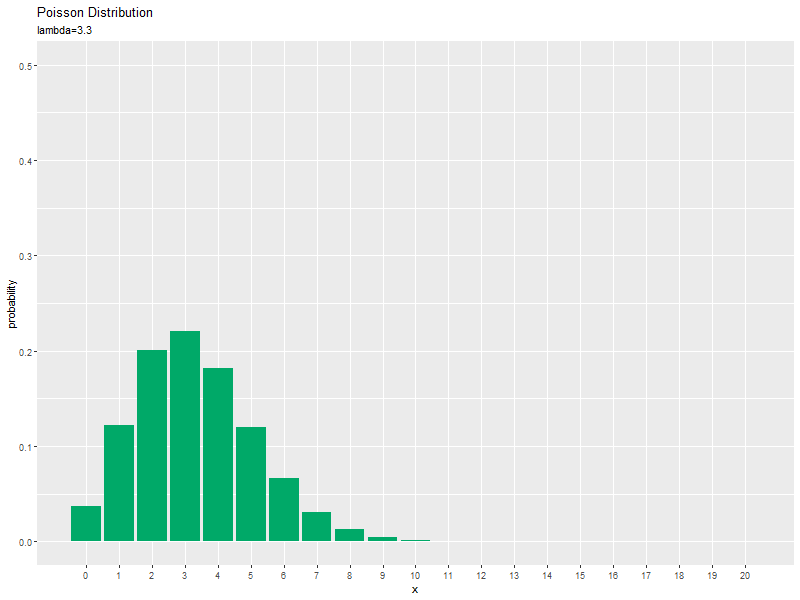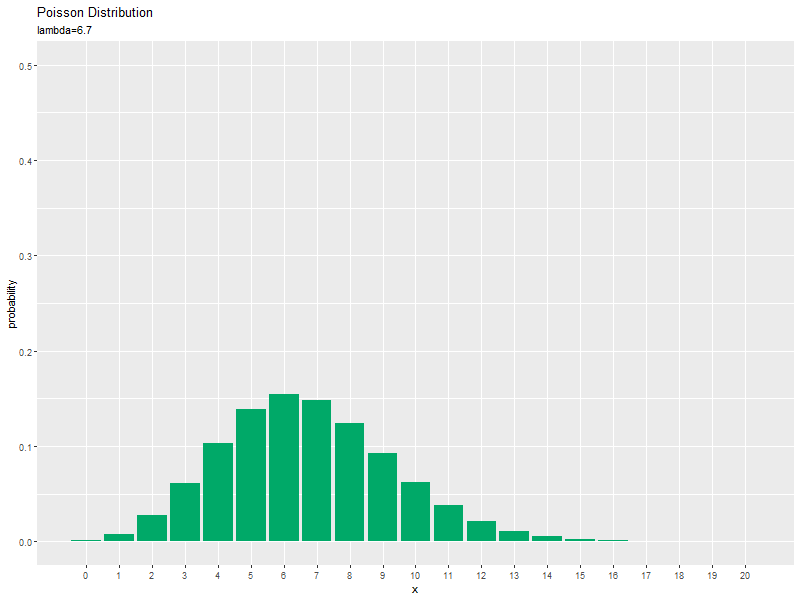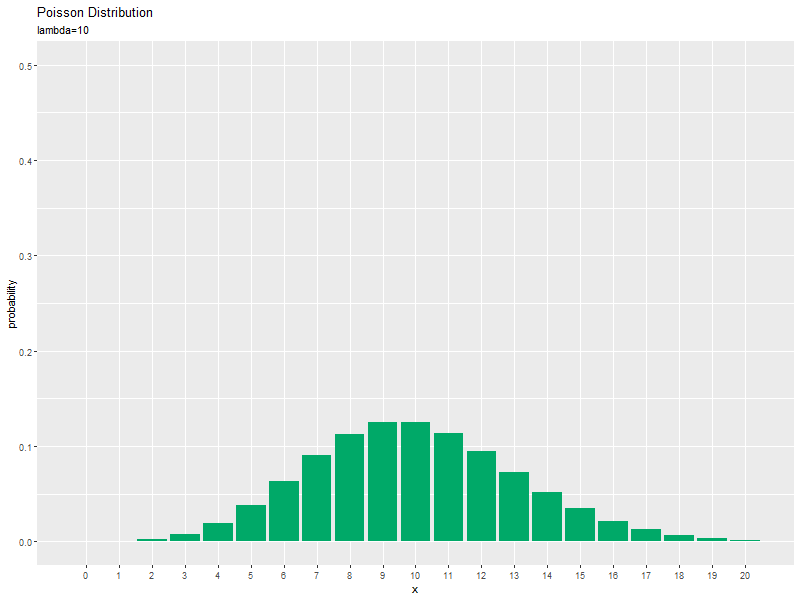
$\lambda$が大きくなるに従って、$x$が大きいほど確率が高くなる(山が右に移動する)のを確認できます。
パラメータと統計量の関係をアニメーションで可視化
ここまでは、パラメータと分布の関係を確認しました。次は、パラメータと統計量と歪度・尖度の関係をアニメーションで確認します。
・作図コード(クリックで展開)
$\phi$の値を変化させ、試行回数$M$を固定して、それぞれ歪度と尖度を計算し、フレーム切替用のラベルを作成します。
# パラメータとして利用する値を指定 lambda_vals <- seq(from = 0, to = 10, by = 0.1) #length(lambda_vals) # フレーム数 # xの値を作成 x_vals <- seq(from = 0, to = ceiling(max(lambda_vals)) * 2) # 歪度を計算 skewness_vec <- 1 / sqrt(lambda_vals) # 尖度を計算 kurtosis_vec <- 1 / lambda_vals # ラベル用のテキストを作成 label_vec <- paste0( "lambda=", lambda_vals, ", skewness=", round(skewness_vec, 3), ", kurtosis=", round(kurtosis_vec, 3) ) head(label_vec)
## [1] "lambda=0, skewness=Inf, kurtosis=Inf" ## [2] "lambda=0.1, skewness=3.162, kurtosis=10" ## [3] "lambda=0.2, skewness=2.236, kurtosis=5" ## [4] "lambda=0.3, skewness=1.826, kurtosis=3.333" ## [5] "lambda=0.4, skewness=1.581, kurtosis=2.5" ## [6] "lambda=0.5, skewness=1.414, kurtosis=2"
パラメータごとに歪度と尖度を計算して、フレーム切替用のラベルとして利用します。
パラメータごとに分布を計算します。
# パラメータごとにポアソン分布を計算 anime_prob_df <- tidyr::expand_grid( x = x_vals, lambda = lambda_vals ) |> # 全ての組み合わせを作成 dplyr::arrange(lambda, x) |> # パラメータごとに並べ替え dplyr::mutate( probability = dpois(x = x, lambda = lambda), parameter = rep(label_vec, each = length(x_vals)) |> factor(levels = label_vec) # フレーム切替用ラベル ) # 確率を計算 anime_prob_df
## # A tibble: 2,121 × 4 ## x lambda probability parameter ## <int> <dbl> <dbl> <fct> ## 1 0 0 1 lambda=0, skewness=Inf, kurtosis=Inf ## 2 1 0 0 lambda=0, skewness=Inf, kurtosis=Inf ## 3 2 0 0 lambda=0, skewness=Inf, kurtosis=Inf ## 4 3 0 0 lambda=0, skewness=Inf, kurtosis=Inf ## 5 4 0 0 lambda=0, skewness=Inf, kurtosis=Inf ## 6 5 0 0 lambda=0, skewness=Inf, kurtosis=Inf ## 7 6 0 0 lambda=0, skewness=Inf, kurtosis=Inf ## 8 7 0 0 lambda=0, skewness=Inf, kurtosis=Inf ## 9 8 0 0 lambda=0, skewness=Inf, kurtosis=Inf ## 10 9 0 0 lambda=0, skewness=Inf, kurtosis=Inf ## # … with 2,111 more rows
これまでと同様に処理します。フレーム切替用のラベル(parameter列)の値にはlabel_vecを使います。
パラメータごとに統計量を計算します。
# パラメータごとに統計量を計算 anime_stat_df <- tibble::tibble( mean = lambda_vals, # 期待値 sd = sqrt(lambda_vals), # 標準偏差 mode = floor(lambda_vals), # 最頻値 parameter = factor(label_vec, levels = label_vec) # フレーム切替用のラベル ) |> # 統計量を計算 dplyr::mutate( sd_minus = mean - sd, sd_plus = mean + sd ) |> # 期待値±標準偏差を計算 dplyr::select(!sd) |> # 不要な列を削除 tidyr::pivot_longer( cols = !parameter, names_to = "type", values_to = "statistic" ) |> # 統計量の列をまとめる dplyr::mutate( type = stringr::str_replace(type, pattern = "sd_.*", replacement = "sd")) # 期待値±標準偏差のカテゴリを統一 anime_stat_df
## # A tibble: 404 × 3 ## parameter type statistic ## <fct> <chr> <dbl> ## 1 lambda=0, skewness=Inf, kurtosis=Inf mean 0 ## 2 lambda=0, skewness=Inf, kurtosis=Inf mode 0 ## 3 lambda=0, skewness=Inf, kurtosis=Inf sd 0 ## 4 lambda=0, skewness=Inf, kurtosis=Inf sd 0 ## 5 lambda=0.1, skewness=3.162, kurtosis=10 mean 0.1 ## 6 lambda=0.1, skewness=3.162, kurtosis=10 mode 0 ## 7 lambda=0.1, skewness=3.162, kurtosis=10 sd -0.216 ## 8 lambda=0.1, skewness=3.162, kurtosis=10 sd 0.416 ## 9 lambda=0.2, skewness=2.236, kurtosis=5 mean 0.2 ## 10 lambda=0.2, skewness=2.236, kurtosis=5 mode 0 ## # … with 394 more rows
期待値・標準偏差・最頻値を計算して、さらに期待値から標準偏差を引いた値と足した値を求めます。
期待値・標準偏差の和と差・最頻値の4つの列をpivot_longer()でまとめます。列名がラベルになるので、標準偏差の和と差のラベルを統一します。
折れ線と凡例テキストの設定用の名前付きベクトルを作成します。
# 凡例用の設定を作成:(数式表示用) color_vec <- c(mean = "blue", sd = "orange", mode = "chocolate") linetype_vec <- c(mean = "dashed", sd = "dotted", mode = "dashed") label_vec <- c(mean = expression(E(x)), sd = expression(E(x) %+-% sqrt(V(x))), mode = expression(mode(x)))
「グラフの作成」のときと同じ処理です。
統計量の情報を重ねたポアソン分布のアニメーション(gif画像)を作成します。
# 統計量を重ねたポアソン分布のアニメーションを作図 anime_prob_graph <- ggplot() + geom_bar(data = anime_prob_df, mapping = aes(x = x, y = probability), stat = "identity", fill = "#00A968", color = "#00A968") + # 分布 geom_vline(data = anime_stat_df, mapping = aes(xintercept = statistic, color = type, linetype = type), size = 1) + # 統計量 gganimate::transition_manual(parameter) + # フレーム scale_x_continuous(breaks = x_vals, minor_breaks = FALSE) + # x軸目盛 scale_linetype_manual(values = linetype_vec, labels = label_vec, name = "statistic") + # 線の種類:(線指定と数式表示用) scale_color_manual(values = color_vec, labels = label_vec, name = "statistic") + # 線の色:(色指定と数式表示用) coord_cartesian(ylim = c(0, 0.5)) + # 軸の表示範囲 theme(legend.text.align = 0) + # 図の体裁:凡例 labs(title = "Poisson Distribution", subtitle = "{current_frame}", x = "x", y = "probability") # ラベル # gif画像を作成 gganimate::animate(anime_prob_graph, nframes = length(lambda_vals), fps = 10, width = 800, height = 600)
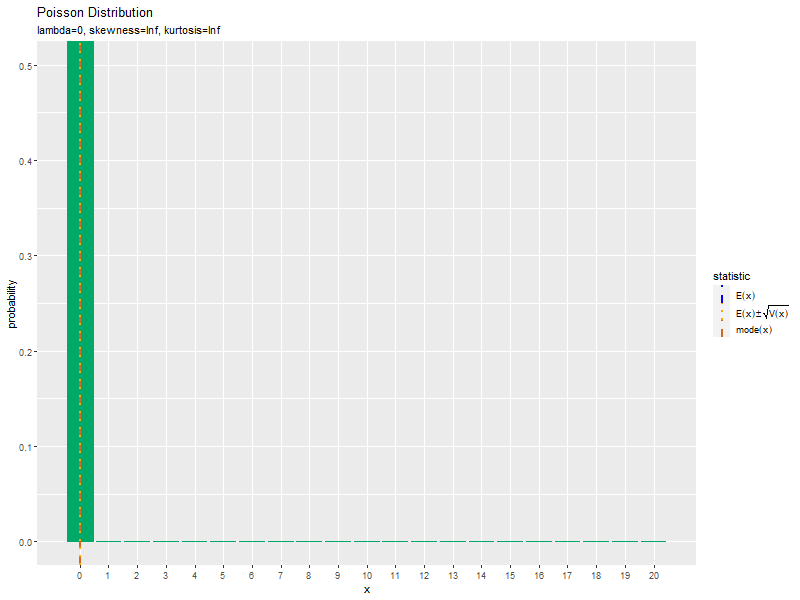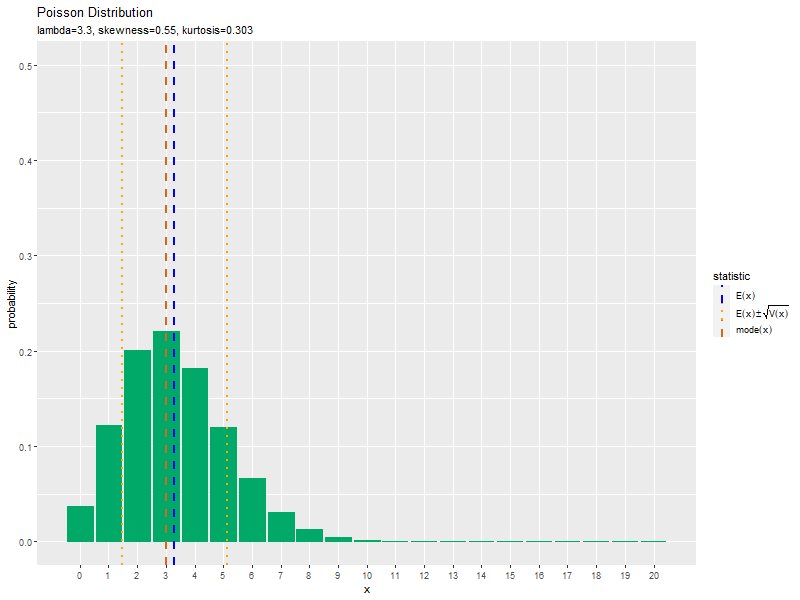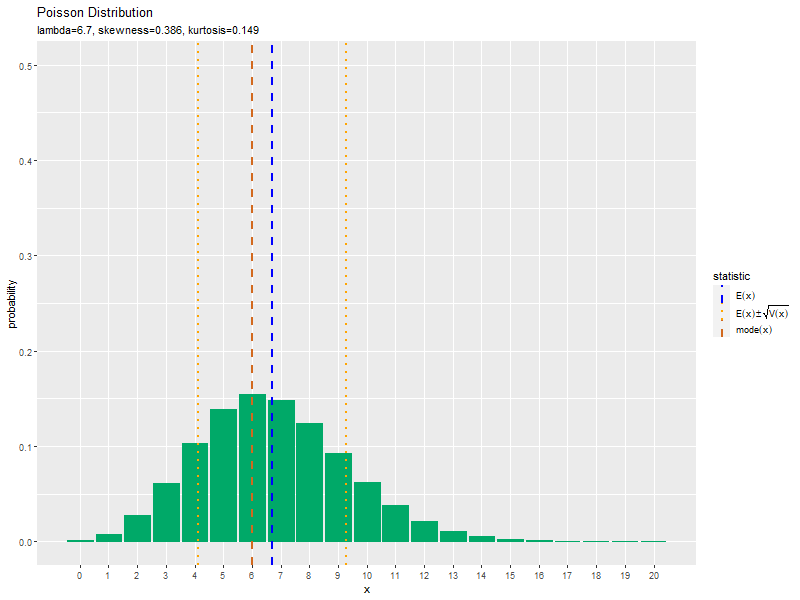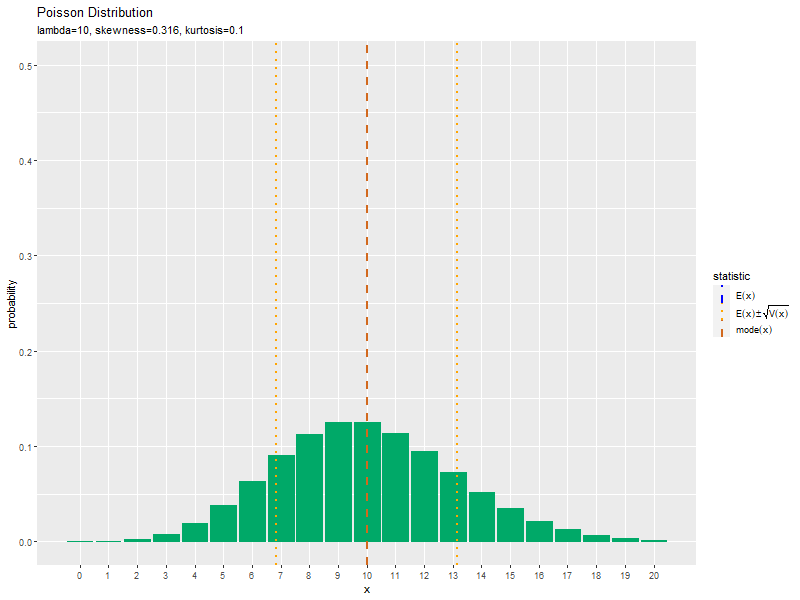
この記事では、ポアソン分布の作図を確認しました。次は、乱数を生成します。
参考文献
- 須山敦志『ベイズ推論による機械学習入門』(機械学習スタートアップシリーズ)杉山将監修,講談社,2017年.
おわりに
青トピに続けて緑と黄色のベイズ本で登場する分布をやっていきます。
- 2022.02.21:追記して、記事を分割しました。
- 2022.07.19:加筆修正しました。
【次の内容】