はじめに
「プログラミング」学習初手『ゼロから作るDeep Learning』民のための実装攻略ノートです。『ゼロつく1』学習の補助となるように適宜解説を加えています。本と一緒に読んでください。
関数やクラスとして実装される処理の塊を細かく分解して、1つずつ処理を確認しながらゆっくりと組んでいきます。
この記事は、6.1.5項「AdaGrad」と6.1.6項「Adam」を繋ぐための内容になります。RMSPropを説明し、Pythonで実装します。またその学習過程を確認します。
【前節の内容】
【他の節の内容】
【この節の内容】
6.1.x RMSProp
AdaGradの問題点を改善した手法であるRMSPropについて説明します。AdaGradと重複する内容は省略しているので、AdaGradの項も参考にしてください。
・更新式の確認
重みパラメータを$\mathbf{W}$、損失関数を$L$、重みによる損失関数の微分を$\frac{\partial L}{\partial \mathbf{W}}$とすると、PMSPropによる更新式は次の2つになります。
ここで$\beta$は0から1未満の値$0 \leq \beta < 1$をとり、過去の勾配の情報$\mathbf{h}$と現在の勾配の情報$\Bigl( \frac{\partial L}{\partial \mathbf{W}}\Bigr )^2$を調整するための項です。$\beta$が大きいほど過去の情報の影響を受け、逆に小さいほど$1 - \beta$が大きくなるため現在の勾配の影響を受けます。どちらの情報を重視するのかを設定できます。$\beta = 0$のとき、勾配の$\mathbf{h}$に記憶しないため、過去の情報を利用しません。また$\odot$は行列の要素ごとの掛け算を表します。
この$\mathbf{h}$を用いて、パラメータ$\mathbf{W}$を更新します。
ここで$\eta$は学習率で、勾配$\frac{\partial L}{\partial \mathbf{W}}$による学習幅を調整します。$\eta$は全ての要素に等しく影響するのに対して、$\frac{1}{\sqrt{\mathbf{h}} + \epsilon}$は各要素に対して過去の勾配の情報を基に個別に影響する項です。また$\epsilon$は0除算を防ぐための微小な値です。
式(1),(2)について、$j,k$要素に注目すると次の式になります。
ちなみに$\leftarrow$は、右辺の計算によって左辺の変数に更新することを表しています。不気味であれば右肩に括弧付きの数字で更新回数を示すことで、次のように等式でも表せます。
これは$t$回目の更新によって現在の値($t-1$回目の更新値)$h_{jk}^{(t-1)},\ w_{jk}^{(t-1)}$を更新することを表しています。右肩の記号が恐ろしければ矢印の方で理解しましょう。
プログラミングっぽく$w_{jk} = w_{jk} - \eta \frac{1}{\sqrt{h_{jk}^{(t)}}} \frac{\partial L}{\partial w_{jk}^{(t-1)}}$と書くと、$\eta \frac{1}{\sqrt{h_{jk}^{(t)}}} \frac{\partial L}{\partial w_{jk}^{(t-1)}}$が0でないと式が成立しないことになるという不都合があるだけのことです。
式(1),(2)についてもう少し考えてみましょう。
式(1)の初回の更新式は、$h_{jk}^{(1)} = \beta h_{jk}^{(0)} + (1 - \beta) \Bigl( \frac{\partial L}{\partial w_{jk}^{(0)}} \Bigr)^2$と表せます。$\mathbf{h}$は過去の勾配の情報であるため初回は過去の情報がないことから、$h_{jk}$の初期値$h_{jk}^{(0)}$を0とすると、この式は
になります。
次に2回目の更新を考えます。式は$h_{jk}^{(2)} = \beta h_{jk}^{(1)} + (1 - \beta) \Bigl( \frac{\partial L}{\partial w_{jk}^{(1)}} \Bigr)^2$ですね。この式に1回目の更新値(上の式)を代入すると
となります。
ではこれを3回目の更新式$h_{jk}^{(3)} = \beta h_{jk}^{(2)} + (1 - \beta) \Bigl( \frac{\partial L}{\partial w_{jk}^{(2)}} \Bigr)^2$に代入すると
となります。1つ目の項の$\beta^2$は$\beta$の2乗のことです。
ではでは$T$回更新を繰り返すと
となります。最後の2つの項について、$\beta^{T-(T-1)} = \beta$、$\beta^{T-T} = \beta^0 = 1$
これを用いると$w_{jk}$の$T$回目の更新値は
で計算できることが分かります。
AdaGradではこれまでの全ての勾配の情報を$\mathbf{h}$として用いていましたが、RMSPropでは下のグラフのように情報が古くなるにつれて減衰率$\beta$の指数的に減衰していきます。これにより直近の勾配に従うとともに、AdaGradのように更新を繰り返すことで学習率が0になることも防ぎます。
# beta^(T-t)による減衰イメージ t = np.arange(0, 100, 0.1) beta = 0.9 plt.plot(t, beta**t) plt.xlabel("x") plt.ylabel("y") plt.title("$y = \\beta^t,\\ \\beta=$" + str(beta), fontsize=20) plt.show()
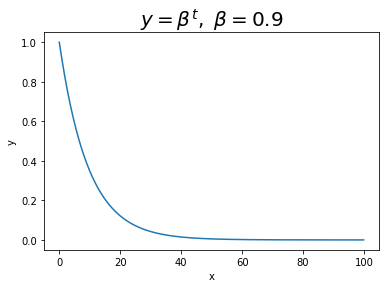
(x軸ラベルはtとすべきでした。)
・実装
更新式の確認ができたので、RMSPropを実装します。
# この項で利用するライブラリを読み込む import numpy as np import matplotlib.pyplot as plt
学習率$\eta$と減衰率$\beta$は、どちらもインスタンスの作成時にそれぞれ引数lr、decay_rateとして指定し、インスタンス変数として値を保持します。デフォルト値として、よく用いられる値を設定しておきます。
$\mathbf{h}$はパラメータ$\mathbf{W}$と同じ形状にする必要があるため、インスタンス作成時はNoneを定義してインスタンス変数だけ作成しておきます。更新メソッドの使用時に渡されるパラメータ(とパラメータごとの勾配)と同じ形状で全ての要素が0の変数を作成し、ディクショナリ型のインスタンス変数hに格納します。
# RMSPorpの実装 class RMSProp: # インスタンス変数を定義 def __init__(self, lr=0.01, decay_rate = 0.99): self.lr = lr # 学習率 self.decay_rate = decay_rate # 減衰率 self.h = None # 過去の勾配の2乗和 # パラメータの更新メソッドを定義 def update(self, params, grads): # hの初期化 if self.h is None: # 初回のみ self.h = {} for key, val in params.items(): self.h[key] = np.zeros_like(val) # 全ての要素が0 # パラメータの値を更新 for key in params.keys(): self.h[key] *= self.decay_rate # 式(1)の前の項 self.h[key] += (1 - self.decay_rate) * grads[key] * grads[key] # 式(1)の後の項 params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7) # 式(2)
更新式に従いパラメータごとに値を更新します。ただし式(1)については前の項と後の項の計算を2行に分けています(計算効率のため?可読性のため?)。また0除算にならないように、分母に1e-7を加算しておきます。パラメータと勾配はどちらもディクショナリ変数として更新メソッド.update()の使用時に引数に指定します。
・アルゴリズムの確認
RMSPropにより関数
の最小値となる$x,\ y$を探索します。またこの関数の勾配(偏微分)は
になります。
まずは関数(6.2)とその勾配をそれぞれ関数として定義しておきます。
# 式(6.2) def f(x, y): return x ** 2 / 20.0 + y ** 2 # 式(6.2)の勾配(偏微分) def df(x, y): # 偏微分 dx = x / 10.0 # df / dx dy = 2.0 * y # df / dy return dx, dy # (値を2つ出力!)
元の関数は作図に、勾配はもちろんパラメータの更新に利用します。
ちなみにこの関数を等高線図にすると次のようになります。
# 等高線用の値 x = np.arange(-10, 10, 0.01) # x軸の値 y = np.arange(-5, 5, 0.01) # y軸の値 X, Y = np.meshgrid(x, y) # 格子状の点に変換 Z = f(X, Y) # 作図 plt.contour(X, Y, Z) # 等高線 plt.plot(0, 0, '+') # 最小値の点 plt.xlim(-10, 10) # x軸の範囲 plt.ylim(-10, 10) # y軸の範囲 plt.xlabel("x") # x軸ラベル plt.ylabel("y") # y軸ラベル plt.title("$f(x, y) = \\frac{1}{20} x^2 + y^2$", fontsize=20) # タイトル plt.show()

原点がこの関数の最小値になります。また原点付近が横に広くなだらかに(勾配が小さく)なっていることが確認できます。
初期値は点$(-7, 2)$とします。これまでと同様に、パラメータ(変数)params、パラメータごとの勾配gradsのディクショナリ変数を作成して、パラメータ名をキーとして値を格納します。
学習率を指定して、RMSPropクラスのインスタンスを作成します。
# パラメータの初期値を指定 params = {} params['x'] = -7.0 params['y'] = 2.0 # 勾配の初期値を指定 grads = {} grads['x'] = 0 grads['y'] = 0 # 学習率を指定 lr = 0.1 # 減衰率 decay_rate = 0.99 # インスタンスを作成 optimizer = RMSProp(lr=lr, decay_rate=decay_rate)
試行回数を指定して、学習を行います。また、パラメータの更新値を記録するためのリスト型の変数を用意しておきます。値の追加は.append()を使います。
# 試行回数を指定 iter_num = 30 # 更新値の記録用リストを初期化 x_history = [] y_history = [] # 初期値を保存 x_history.append(params['x']) y_history.append(params['y']) # 関数の最小値を探索 for _ in range(iter_num): # 勾配を計算 grads['x'], grads['y'] = df(params['x'], params['y']) # パラメータを更新 optimizer.update(params, grads) # パラメータを記録 x_history.append(params['x']) y_history.append(params['y'])
勾配を計算し、gradsに格納している値をそれぞれ上書きします。そしてMRSPropクラスの更新メソッド.update()にparamsとgradsを指定して、パラメータを更新します。
更新値の推移を先ほどの等高線グラフに重ねて確認しましょう。
# 作図 plt.plot(x_history, y_history, 'o-') # パラメータの推移 plt.contour(X, Y, Z) # 等高線 plt.plot(0, 0, '+') # 最小値の点 plt.xlim(-10, 10) # x軸の範囲 plt.ylim(-10, 10) # y軸の範囲 plt.xlabel("x") # x軸ラベル plt.ylabel("y") # y軸ラベル plt.title("MRSProp", fontsize=20) # タイトル plt.text(6, 6, "$\\eta=$" + str(lr) + "\n$\\beta=$" + str(decay_rate) + "\niteration:" + str(iter_num)) # メモ plt.show()
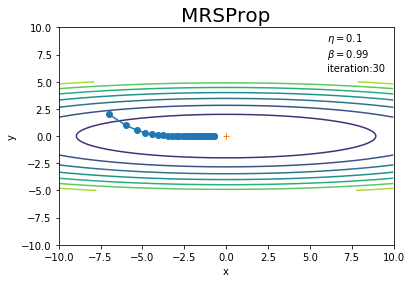
SGDよりも、最小値の点に向かって効率的な経路を辿っています。
学習率や試行回数を変更して試してみましょう!
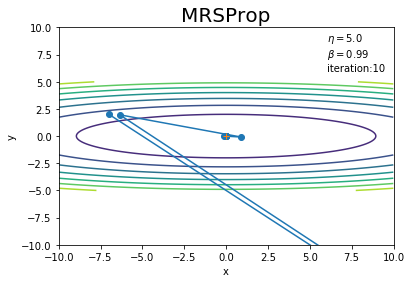
AdaGradのときと同様に、$\frac{1}{\sqrt{\mathbf{h}}}$の調整機能によって発散せずに最小値に辿り着いています。
以上で、AdaGradに減衰率を導入したPMSPropを実装できました。次は、Momentum SDGとPMSPropの2つのアイデアを導入したAdamを説明します。
参考文献
- 斎藤康毅『ゼロから作るDeep Learning』オライリー・ジャパン,2016年.
おわりに
ではAdamに進みましょう!
【次節の内容】