はじめに
「Python」初学者のための『ゼロから作るDeep Learning』攻略ノートです。『ゼロつくシリーズ』学習の補助となるように適宜解説を加えています。本と一緒に読んでください。
本を進めるにあたって必要となるPython文法や利用する関数について、その機能や使い方、補足情報を確認していきます。
この記事では、「ファイルパスの解説」「MNISTデータセットの確認」「load_mist()の読み込み方と機能の解説」を行います。
【関連する記事】
【他の記事一覧】
【この節の内容】
- はじめに
- 3.6.1 MNISTデータセットの読み込み
- ・load_mnist関数の読み込み
- ・MNISTデータセットの確認
- ・load_mnist関数の引数
- ・おまけ:手書き数字をアニメーションで表示
- 参考文献
- おわりに
3.6.1 MNISTデータセットの読み込み
GitHubからダウンロードした「deep-learning-from-scratch-master」フォルダ内にある「dataset」フォルダの「mnist.py」に実装されている「MNISTデータセットの読み込み関数load_mnist()」を利用して、MNIST(手書き数字)データセットを読み込みます。
この記事では、ファイルパスの設定、load_mnist()自体を読み込む方法、初回実行時の処理、取得できるMNISTデータセット、load_mnist()の引数について解説します。
・ファイルのインポートのための設定
まずは、ファイルパスについて説明します。実装済みの関数やクラスを読み込むには、実装されているファイルの場所を指定する必要があります。そのファイルの位置を示すものをファイルパスと言います。
ファイルパスの設定には、sysとosのライブラリを利用します。
# ファイル読み込み用ライブラリの読み込み import sys import os
2つのライブラリを1行で同時に読み込むこともできます。
# ファイル読み込み用ライブラリの読み込み import sys, os
少しだけ言葉の確認をしておきます。
ファイルを保存するフォルダのことをディレクトリとも呼びます。(データを保存している場所は、ハード的にいうと保存している領域(directory)だからです。)
フォルダの中にフォルダを作って管理しますよね。この中の中というのを階層と言います。(ある領域の更に下の領域というイメージです。)階層になっているディレクトリにおいて、1つ上を親ディレクトリ(parent directory)、1つ下を子ディレクトリ(child directory)と呼びます。
現在使用している領域(おそらく今開いているnotebookやスクリプトを保存しているフォルダ)のことをカレントディレクトリ(current directory:現行ディレクトリ)と言います。または、今作業している領域としてワーキングディレクトリ(working directory:作業ディレクトリ)とも言います(作業フォルダなら聞いたことがあるかもしれません)。
言葉の確認ができたので、この記事では親フォルダや作業フォルダと書くことにします。
さて、その現在作業しているフォルダ(ディレクトリ)を調べる関数がos.getcwd()です。(get current working directoryの頭文字ですね。)引数を指定せずにそのまま実行します。
# 作業フォルダを取得 print(os.getcwd())
C:\Users\ユーザー名\Documents\JupyterLab_Working\DL_from_Scratch1\notebook
Windowsでは、\(半角バックスラッシュあるいは半角円マーク)が階層の区切りを意味します。それぞれがフォルダ名で、右に行くほど階層が下がり(フォルダの中の中となり)ます。
Macだと、\ではなく/(スラッシュ)で表します。
つまり、この実行結果は「Cドライブ」の中の「ユーザーフォルダ」の中の・・・「notebook」フォルダで作業を行っているということです。JupyterLabを利用しているのであれば、今書いているスクリプトを保存している場所になっていると思います。
このようにファイルの位置を示すものをファイルパスと言います。
では、load_mnist()が実装されている「mnist.py」のファイルパスについて考えます。
サポートページ「GitHub - oreilly-japan/deep-learning-from-scratch: 『ゼロから作る Deep Learning』(O'Reilly Japan, 2016)」からダウンロードした「deep-learning-from-scratch-master」フォルダは、次のフォルダ構成です。サポートページの右上にある緑色の「Code」を開いて「Download ZIP」からダウンロードできます。
deep-learning-from-scratch-master
├ ch01
├ ch02
├ ch03
│ ├ mnist_show.py
│ ┆
│ └ step_function.py
┆
├ ch09
├ common
└ dataset
├ __init__.py
┆
└ mnist.py
「mnist.py」は「dataset」に保存されています。
「dataset」や「ch03」から見ると「deep-learning-from-scratch-master」は親フォルダです。逆に、「deep-learning-from-scratch-master」から見ると「ch03」は子フォルダです。
os.pardirは、作業フォルダの親フォルダの代名詞として働きます。(parent directoryの略ですね。)
・想定されているフォルダ構成
本としては、3章を読んでいるのであれば、「03ch」に「3章のコードのファイル」を保存した状態を想定しています。つまり、次のようなフォルダ構成になります。(一応書いておきますが、3章のコード.ipynbというファイル名は分かりやすいようにあえて付けたものです。フォルダ名やファイル名は、アルファベットと数字と_(アンダースコア)だけにしましょう。日本語や記号、スペースを入れるのはエラーの元です。)
deep-learning-from-scratch-master
├ ch01
├ ch02
├ ch03
│ ├ mnist_show.py
│ ┆
│ ├ step_function.py
│ └ 3章のコード.ipynbまたは3章のコード.py
┆
├ ch09
├ common
└ dataset
├ __init__.py
┆
└ mnist.py
この場合、作業フォルダは「ch03」であり、os.getcwd()の結果は(省略)\deep-learning-from-scratch-master\ch03となります。
また、os.pardirが「deep-learning-from-scratch-master」の代わりになるので、本のように指定できます。
# 親フォルダを指定
sys.path.append(os.pardir)
これで「learning-from-scratch-master」内のファイルからインポートできます。
・自己流のフォルダ構成
例えば、私は次のようなフォルダ構成にしています。(単なる我流なのでマネしないで。)
DL_from_Scratch1
├ notebook
│ ├ 1章のコード.ipynb
│ ├ 2章のコード.ipynb
│ └ 3章のコード.ipynb
└ deep-learning-from-scratch-master
├ ch01
┆
├ ch09
├ common
└ dataset
├ __init__.py
┆
└ mnist.py
この場合は、作業フォルダは「notebook」であり、親フォルダは「DL_from_scratch1」です。つまり、親フォルダの中に「deep-learning-from-scratch-master」があります。
os.pardirの代わりに、..でも親フォルダを表せます。つまり、親フォルダ(..)の中(/)の「deep-learning-from-scratch-master」なので、次のように指定できます。
# 親フォルダ内のフォルダを指定 #sys.path.append('..\\deep-learning-from-scratch-master') # Win sys.path.append('../deep-learning-from-scratch-master') # WinとMac
同様に、「親フォルダ」の更に「親フォルダ」に「deep-learning-from-scratch-master」がある場合
親の親フォルダ
├ 親フォルダ
│ └ 作業フォルダ
│ └ 3章のコード.ipynb
└ deep-learning-from-scratch-master
は、'../../deep-learning-from-scratch-master'となります。
また、「親フォルダ」の中の「別のフォルダ」の更に中に「deep-learning-from-scratch-master」がある場合
親フォルダ
├ 作業フォルダ
│ └ 3章のコード.ipynb
└ 別のフォルダ
└ deep-learning-from-scratch-master
は、'../別のフォルダ/deep-learning-from-scratch-master'となります。
・絶対パスを使う
フォルダの親子関係を考えず、「deep-learning-from-scratch-master」のファイルパスを直接指定することもできます。
Windowsの場合は、「deep-learning-from-scratch-master」内のファイルを(どれでもいいので)右クリックしてプロパティを開くと、「場所」のところに(表示上は円マークになっていると思いますが)'C:\Users\ユーザー名\Documents\省略\deep-learning-from-scratch-master'のようにファイルパスが書かれているので、それをコピペします。ただし、「バックスラッシュ\」を「2つにする\\」か「スラッシュ/」に変える必要があります。
Macの場合は、(どうやって取得するのかは知りませんが)スラッシュ/になっているので、そのままコピペします。
# 絶対パスで指定 #sys.path.append('C:\\Users\\ユーザー名\\Documents\\・・・\\deep-learning-from-scratch-master') # Win sys.path.append('C:/Users/ユーザー名/Documents/・・・/deep-learning-from-scratch-master') # WinとMac
以上の3つの方法によって、importする際にファイルを検索するディレクトリ一覧に「deep-learning-from-scratch-master」を追加することができました。これで、load_mnist()を読み込む準備が整いました。
話は脱線しますが、なぜ\\とするのかについて少しだけ解説します。
\は、エスケープ文字と呼ばれ特殊な機能を持ちます。例えば、\nで改行を表します。2つ重ねる\\とこの機能が打ち消されます。
# \nで改行 print('Hello!\nProject') # \をエスケープ print('Hello!\\nProject')
Hello!
Project
Hello!\nProject
上の処理は、\nが改行として機能しています。
下の処理は、\\nが\nと表示されています。1つ目の\が2つ目の\の機能を打ち消したためです。なので、2つ目の\とnがただの文字として処理され、\nが文字列として表示されています。詳しくは、エスケープ文字や正規表現で調べてください。
・load_mnist関数の読み込み
「deep-learning-from-scratch-masterフォルダ」にある「datasetフォルダ」内の「mnist.py」に実装されいる「load_mnist()関数」を読み込んで、実行します。
sys.path.append()に「deep-learning-from-scratch-master」のパスを指定して、load_mnist()を読み込みます。
# パスの指定に利用するライブラリ import sys # ファイルパスを指定 sys.path.append('../deep-learning-from-scratch-master') #sys.path.append('C:\\Users\\ユーザー名\\Documents\\・・・\\deep-learning-from-scratch-master') # Win #sys.path.append('C:/Users/ユーザー名/Documents/・・・//deep-learning-from-scratch-master') # WinとMac # 関数を読み込む from dataset.mnist import load_mnist
importによるライブラリの読み込みは1章で確認しました。fromを使って、ライブラリに含まれるクラスや関数を指定して読み込めます。
from dataset.mnistで「dataset」フォルダ内の「mnist.py」にアクセスします。そして、import load_mnistで「mnist.py」に関数定義されているload_mnist()を読み込んでいます。
読み込めない場合は、上で説明したファイルパスを確認してください。
ちなみに、73ページのコード中に登場する\は、コードを改行しても続いてることをPythonに認識させるための記号です。横に長いと視認性が悪くなるため(本的には紙面からはみ出るため)改行することがあります。
・初回の実行時の処理
load_mnist()を初めて実行すると、MNISTデータセットのダウンロードが行われます。「訓練用の画像データ」「訓練用のラベルデータ」「テスト用の画像データ」「テスト用のラベルデータ」をダウンロードして、Pythonで扱いやすいように変換する処理が行われます。
load_mnist()を読み込めたら、とりあえず実行してみます。
# load_mnist関数を実行
(x_train, t_train), (x_test, t_test) = load_mnist()
load_mnist()を実行すると
Downloading train-images-idx3-ubyte.gz ...
と表示されて、ダウンロードが始まります。
Downloading train-images-idx3-ubyte.gz ... Done Downloading train-labels-idx1-ubyte.gz ... Done Downloading t10k-images-idx3-ubyte.gz ... Done Downloading t10k-labels-idx1-ubyte.gz ... Done
と表示されれば、ファイルのダウンロードが完了しました。datasetフォルダに、4つのgzファイルが保存されています(***.gzの***の部分がファイル名です。特に確認する必要はありません)。
続いて、ダウンロードしたファイルがそれぞれNumPy配列に変換されます。
Converting train-images-idx3-ubyte.gz to NumPy Array ... Done Converting train-labels-idx1-ubyte.gz to NumPy Array ... Done Converting t10k-images-idx3-ubyte.gz to NumPy Array ... Done Converting t10k-labels-idx1-ubyte.gz to NumPy Array ... Done
と表示されれば、変換が完了しました。
最後に、NumPy配列に変換したデータをまとめてpickleとして保存されます。
Creating pickle file ...
Done!
と表示されれば、初回時の処理は完了です。datasetフォルダに、mnist.pklが保存されています(特に確認する必要はありません)。
以降は、load_mnist()を実行するとmnist.pklが読み込まれます。
・エラーになる場合
load_minit()の初回実行時に、次のエラーが起きてダウンロードできない場合があります。
HTTP Error 503: Service Unavailable
これはファイルのダウンロード元サイト(サーバー)にアクセスできないことを示すエラーメッセージです。
いくつか対応策があります。ただし、自己責任で行ってください。
・時間を空ける
しばらく待っていると、サイトにアクセスできるようになってダウンロードできることがあります。
・自分でファイルをダウンロードする
データセットを自分(手動)でダウンロードすることで対応します。
ダウンロード元サイトhttp://yann.lecun.com/exdb/mnist/を開きます。
Four files are available on this site:
のところから、「train-images-idx3-ubyte.gz」「train-labels-idx1-ubyte.gz」「t10k-images-idx3-ubyte.gz」「t10k-labels-idx1-ubyte.gz」の4つのファイルをダウンロードします。
この方法でもアクセス(ダウンロード)できない(そもそもPython上からアクセスできない時は、ブラウザ上からもアクセスできない?)場合は、ミラーサイトからダウンロードすることもできます。
ミラーサイトhttps://github.com/cvdfoundation/mnistを開きます。
Download
のところにある「Training images」「Training labels」「Testing images」「Testing labels」の4つのリンクから、それぞれgzファイルをダウンロードします。詳しくは、ミラーサイトを読んでください。
どちらの方法でもいいので、ダウンロードした4つのgzファイルをdatasetフォルダに保存します。
保存した後にload_mnist()を実行すると、「NumPy配列に変換」と「pickleとして保存」する処理が行われます。
・ダウンロード元を変更する
ファイルのダウンロードをミラーサイトから行うように変更します。
load_mnist()は、datasetフォルダ内のmnist.pyに実装されています。
mnist.pyを開くとソースコードを見られます。その中に(現在だと13行目に)、ダウンロード元のURLを指定する記述があります。
url_base = 'http://yann.lecun.com/exdb/mnist/'
これを次のようにミラーサイトのURLに変更します。
#url_base = 'http://yann.lecun.com/exdb/mnist/' url_base = 'https://storage.googleapis.com/cvdf-datasets/mnist/' # ミラーサイト
mnist.pyを上書き保存して、Python?(カーネル?)を再起動?(リスタート?)して、再度load_mnist()の読み込みから実行すると「ファイルのダウンロード」「NumPy配列に変換」「pickleとして保存」する処理が行われます。
一応私の環境では3つとも実行できましたが、どんな問題があるのか把握できていないので、くれぐれも自己判断で行ってください。(そして、この方法に何か問題があれば教えて下さい。)
・データの取得に関しての補足
load_mnist()で出力されるデータセットに関して、変則的な受け取り方をしますね。この処理を簡単に確認します。
load_mnist()の出力を確認します。
# load_mnit()の出力を確認 obj = load_mnist(normalize=False, flatten=True) print(obj) print(type(obj)) # オブジェクト全体 print(type(obj[0])) # 中のオブジェクト print(type(obj[0][0])) # 中のオブジェクトの更に中
((array([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]], dtype=uint8), array([5, 0, 4, ..., 5, 6, 8], dtype=uint8)), (array([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]], dtype=uint8), array([7, 2, 1, ..., 4, 5, 6], dtype=uint8)))
<class 'tuple'>
<class 'tuple'>
<class 'numpy.ndarray'>
出力されるオブジェクトは、((配列, 配列), (配列, 配列))という構造をしています。タプルの中に2つのタプルがあり、またその2つのタプルそれぞれに2つのNumPy配列があります。4つのNumPy配列がそれぞれ、訓練用の画像データ・ラベルデータ、評価用の画像データ・ラベルデータです。
「入れ子になって出力されるオブジェクト」の構造に「受け取る側のオブジェクト」を合わせることで、オブジェクト内のオブジェクトを代入できます。
もう少し詳しく知りたい場合は、次のように簡易的に試してみましょう。
・省略(クリックで展開)
複数のオブジェクトに同時に代入することができます。
# 2つの変数に代入 a, b = 1, 2 print(a) print(b)
1
2
また、タプル内の要素を代入することができます。
# 1つの変数に代入 x = (1, 2) print(x) # 2つの変数に代入 a, b = (1, 2) print(a) print(b)
(1, 2)
1
2
さらに、タプル内にタプルを持つ(タプル, タプル)ような場合も、受け取る側のオブジェクトを構造に合わせることで代入できます。(タプルの機能なわけではなく、リストでも行えます。)
# 1つの変数に代入 x = ((1, 2), (3, 4)) print(x) # 2つの変数に代入 y, z = ((1, 2), (3, 4)) print(y) print(z) # 疑似再現 (a, b), (c, d) = ((1, 2), (3, 4)) print(a) print(b) print(c) print(d)
((1, 2), (3, 4))
(1, 2)
(3, 4)
1
2
3
4
最後の処理が、load_mnist()の受け取り方に対応しています。
・MNISTデータセットの確認
次は、MNISTデータセット(手書き数字)を確認します。
次のライブラリを利用します。
# 利用するライブラリ import numpy as np import matplotlib.pyplot as plt
normalize=Falseとflatten=Falseを指定して、データセットを出力します。引数については次で説明します。
# データセットを取得 (x_train, t_train), (x_test, t_test) = load_mnist(normalize=False, flatten=False) # 訓練用のデータの形状を確認 print(x_train.shape) print(t_train.shape) # テスト用のデータの形状を確認 print(x_test.shape) print(t_test.shape)
(60000, 1, 28, 28)
(60000,)
(10000, 1, 28, 28)
(10000,)
「訓練用の画像データx_train」と「テスト用の画像データx_test」は4次元配列で、各次元(軸)はデータ数・チャンネル数・縦方向のピクセル数・横方向のピクセル数です。MNISTデータセットは、グレースケールなのでチャンネルが1で、縦28ピクセル・横28ピクセルの画像データです。(例えばRGBデータだと赤・緑・青の3チャンネルになります。)
画像データは、ニューラルネットワークに入力するデータなので、入力データとも呼びます。
「訓練用のラベルデータt_train」と「テスト用のラベルデータt_test」の形状については、one_hot_label引数のところで説明します。
ラベルデータは、対応する画像データに書かれている数字を示します。また、ニューラルネットワークの出力(推論結果)の正誤を判定するのに用いるので、教師データや正解ラベルとも呼びます。
訓練用のデータが6万枚、テスト用のデータが1万枚用意されています。
1つのデータを取り出して、表示してみます。
# 出力の折り返し設定を変更:(資料作成用) np.set_printoptions(linewidth=150) # 表示するデータ番号を指定 n = 0 # n番目の画像データを表示 print(x_train[n, 0]) # n番目のラベルデータを表示 print(t_train[n]) # 出力の折り返し設定を戻す:(資料作成用) np.set_printoptions(linewidth=75)
[[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 3 18 18 18 126 136 175 26 166 255 247 127 0 0 0 0]
[ 0 0 0 0 0 0 0 0 30 36 94 154 170 253 253 253 253 253 225 172 253 242 195 64 0 0 0 0]
[ 0 0 0 0 0 0 0 49 238 253 253 253 253 253 253 253 253 251 93 82 82 56 39 0 0 0 0 0]
[ 0 0 0 0 0 0 0 18 219 253 253 253 253 253 198 182 247 241 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 80 156 107 253 253 205 11 0 43 154 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 14 1 154 253 90 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 139 253 190 2 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 11 190 253 70 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 35 241 225 160 108 1 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 81 240 253 253 119 25 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 45 186 253 253 150 27 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 16 93 252 253 187 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 249 253 249 64 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 46 130 183 253 253 207 2 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 39 148 229 253 253 253 250 182 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 24 114 221 253 253 253 253 201 78 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 23 66 213 253 253 253 253 198 81 2 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 18 171 219 253 253 253 253 195 80 9 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 55 172 226 253 253 253 253 244 133 11 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 136 253 253 253 212 135 132 16 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]]
5
画像データx_train, x_testの各要素は、0から255の整数値をとります。0なら真っ黒、255は真っ白を表し、256段階で書かれ方を示しています。
ラベルデータt_train, t_testは、画像データに書かれている数字を要素として持ちます。
この状態でも「5」が書かれているのが分かりますね。
続いて、画像として表示してみます。
# 表示するデータ番号を指定 n = 0 # 手書き文字を作図 plt.imshow(x_train[n].reshape((28, 28)), cmap='gray') # 手書き文字 plt.title('label:' + str(t_train[n])) # ラベル plt.show()
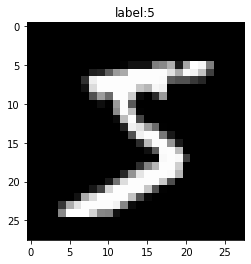
この手書き数字のデータをニューラルネットワークに入力して、書かれている数字を予測(推論)するのが目標です。
・load_mnist関数の引数
最後に、load_mnist()の3つの引数の機能を紹介します。必要になったタイミングで確認してください。
・normalize引数
normalizeは、画像データ(入力データ)の値に関する設定をします。Trueを指定すると、各要素(ピクセル)の値が0から1の値に正規化されます。Falseを指定すると、0から255の整数値のまま出力されます。デフォルト値はTrueです。
normalize=Falseを指定して、データセットを出力します。
# データを取得 (x_train, _), (x_test, _) = load_mnist(normalize=False, flatten=False, one_hot_label=False)
ラベルデータは使わないので、変数名を_として使わないことを明示しておきます。
入力データの形状を確認します。
# 配列の形状を確認 print(x_train.shape) print(x_test.shape)
(60000, 1, 28, 28)
(10000, 1, 28, 28)
normalize引数は形状に影響しません。
入力データを確認します。隅の要素は0ばかりなので、5行目と6行目を表示することにします。
# 0番目の入力データの一部を確認 print(x_train[0, 0, 5:7])
[[ 0 0 0 0 0 0 0 0 0 0 0 0 3 18 18 18 126 136
175 26 166 255 247 127 0 0 0 0]
[ 0 0 0 0 0 0 0 0 30 36 94 154 170 253 253 253 253 253
225 172 253 242 195 64 0 0 0 0]]
先ほど確認した通り、Falseを指定すると各要素は0から255の値をとります。
続いて、normalize=Trueを指定して、データセットを出力します。
# データを取得 (x_train, _), (x_test, _) = load_mnist(normalize=True, flatten=False, one_hot_label=False)
入力データの形状を確認します。
# 配列の形状を確認 print(x_train.shape) print(x_test.shape)
(60000, 1, 28, 28)
(10000, 1, 28, 28)
形状には影響しません。
入力データを確認します。
# 0番目の入力データの一部を確認 print(x_train[0, 0, 5:7])
[[0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0.01176471 0.07058824 0.07058824 0.07058824 0.49411765 0.53333336
0.6862745 0.10196079 0.6509804 1. 0.96862745 0.49803922
0. 0. 0. 0. ]
[0. 0. 0. 0. 0. 0.
0. 0. 0.11764706 0.14117648 0.36862746 0.6039216
0.6666667 0.99215686 0.99215686 0.99215686 0.99215686 0.99215686
0.88235295 0.6745098 0.99215686 0.9490196 0.7647059 0.2509804
0. 0. 0. 0. ]]
Trueを指定すると、各要素を最大値の255で割った値が出力されます。最大値で割ることで、各要素が0から1の値になります。全ての要素を同じ値で割っているので、要素間の大小関係などは変わりません。
この本では、正規化したものを入力データとして利用します。
正規化した場合の画像を見てみましょう。
# 表示するデータ番号を指定 n = 0 # 手書き文字を作図 plt.imshow(x_train[n].reshape((28, 28)), cmap='gray') # 手書き文字 plt.title('label:' + str(t_train[n])) # ラベル plt.show()
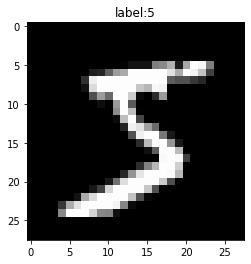
0が真っ黒、1が真っ白に対応します。
全ての要素に255を掛けることで元の値に戻せます。
# 元の値に戻す print((x_train[0, 0, 5:7] * 255).astype('int'))
[[ 0 0 0 0 0 0 0 0 0 0 0 0 3 18 18 18 126 136
175 26 166 255 247 127 0 0 0 0]
[ 0 0 0 0 0 0 0 0 30 36 94 154 170 253 253 253 253 253
225 172 253 242 195 64 0 0 0 0]]
astype()メソッドを使って、float型からint型に変換しています。元の値に戻っているのを確認できます。
・flatten引数
flattenは、入力データの形状を設定します。Trueを指定すると、各データを0行目の次に1行目その次に2行目と並び替えて、1次元配列で出力されます。Falseを指定すると、縦28・横28の2次元配列(と1チャンネルを含めた3次元配列)で出力されます。デフォルト値はTrueです。
flatten=Falseを指定して、データセットを出力します。
# データを取得 (x_train, _), (x_test, _) = load_mnist(normalize=False, flatten=False, one_hot_label=False)
入力データの形状を確認します。
# 配列の形状を確認 print(x_train.shape) print(x_test.shape)
(60000, 1, 28, 28)
(10000, 1, 28, 28)
Falseを指定すると、データ数・チャンネル数・縦のピクセル数・横のピクセル数の4次元配列として出力されます。各画像データは、$28 \times 28$の形状なので、縦につながるピクセルの情報を維持しています。
入力データを確認します。
# 0番目の入力データの一部を確認 print(x_train[0, 0, 5:7])
[[ 0 0 0 0 0 0 0 0 0 0 0 0 3 18 18 18 126 136
175 26 166 255 247 127 0 0 0 0]
[ 0 0 0 0 0 0 0 0 30 36 94 154 170 253 253 253 253 253
225 172 253 242 195 64 0 0 0 0]]
flatten引数は値に影響しません。
7章の畳み込みニューラルネットワーク(CNN)では、この状態の画像データを入力します。
続いて、flatten=Trueを指定して、データセットを出力します。
# データを取得 (x_train, _), (x_test, _) = load_mnist(normalize=False, flatten=True, one_hot_label=False)
入力データの形状を確認します。
# 配列の形状を確認 print(x_train.shape) print(x_test.shape)
(60000, 784)
(10000, 784)
Trueを指定すると、各画像データは$28^2 = 784$個の要素を持つ1次元配列として出力されます。
入力データを確認します。元の形状で5・6行目の要素を取り出します。
# 0番目の入力データの一部を確認 print(x_train[0, 5*28:7*28])
[ 0 0 0 0 0 0 0 0 0 0 0 0 3 18 18 18 126 136
175 26 166 255 247 127 0 0 0 0 0 0 0 0 0 0 0 0
30 36 94 154 170 253 253 253 253 253 225 172 253 242 195 64 0 0
0 0]
値には影響しません。
一応、画像にしてみます。
# 表示するデータ番号を指定 n = 0 # 手書き文字を作図 plt.imshow(x_train[n].reshape((1, 28**2)), cmap='gray') # 手書き文字 plt.title('label:' + str(t_train[n])) # ラベル plt.axis('off') # 軸ラベル plt.show()

横に並べ替えたので、縦に並ぶピクセルの関係が分からなくなっています。
6章までのニューラルネットワーク(NN)では、この状態の画像データを入力します。この状態では、人間にとっては何の数字なのか判別できませんが、NNはこの状態でパターンを認識します。
・one_hot_label引数
one_hot_labelは、ラベルデータ(教師データ)の値の持ち方を設定します。Trueを指定すると、書かれている数字をone-hot表現(one-hotベクトル)で示します。Falseを指定すると、1つの数値(スカラ)で示します。デフォルト値はFalseです。
one_hot_label=Falseを指定して、データセットを出力します。
# データを取得 (_, t_train), (_, t_test) = load_mnist(normalize=False, flatten=False, one_hot_label=False)
画像データは使わないので、_としておきます。
ラベルデータの形状を確認します。
# 配列の形状を確認 print(t_train.shape) print(t_test.shape)
(60000,)
(10000,)
画像データごとに「1つの要素」が対応しているので、それぞれデータ数と同じ要素数の1次元配列になっています。
ラベルデータを確認します。
# ラベルデータを確認 print(t_train[:5])
[5 0 4 1 9]
Falseを指定すると、1つの画像データに1つの値(ラベル)が対応します。それぞれ0から9の整数値をとり、画像に書かれている数字を示します。
続いて、one_hot_label=Trueを指定して、データを出力します。
# データを取得 (_, t_train), (_, t_test) = load_mnist(normalize=False, flatten=False, one_hot_label=True)
ラベルデータの形状を確認します。
# 配列の形状を確認 print(t_train.shape) print(t_test.shape)
(60000, 10)
(10000, 10)
画像データごとに「10個の要素を持つ1次元配列」が対応しています。
ラベルデータを確認します。
# ラベルデータを確認 print(t_train[:5])
[[0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
[1. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]]
Trueを指定すると、10個の要素の内、1つの要素のみ1で他の要素は全て0です。値が1のインデックス(要素番号)が画像データに書かれている数字を示しています。このような表現をone-hot表現と呼びます。
np.argmax()を使って、正解ラベルを取り出せます。
# 正解ラベルを抽出 print(np.argmax(t_train[:5], axis=1))
[5 0 4 1 9]
one_hot_label=Falseを指定したときの配列を得られました。
最終的には、どちらの状態で入力しても処理できるようにニューラルネットワークを実装します。
以上で、MNISTデータセットの取得方法を確認できました。この手書き数字とは最後までお付き合いすることになります。
・おまけ:手書き数字をアニメーションで表示
手書き数字がどんなものなのか確認します。
・コード(クリックで展開)
# 追加ライブラリ from matplotlib.animation import FuncAnimation
# データを取得 (x_train, t_train), (_, _) = load_mnist(normalize=True, flatten=False, one_hot_label=False)
データセットを順番に表示します。
# 画像サイズを指定 fig = plt.figure(figsize=(5, 5)) # 作図処理を関数として定義 def update(n): # 前フレームのグラフを初期化 plt.cla() # n番目の数字を作図 plt.imshow(x_train[n, 0], cmap='gray') # 手書き数字 plt.title('number:' + str(n) + ', label:' + str(t_train[n]), fontsize=15) # ラベルデータ plt.axis('off') # 軸目盛 # gif画像を作成 mnist_anime = FuncAnimation(fig, update, frames=100, interval=1000) # gif画像を保存 mnist_anime.save('ch3_6_2_mnist.gif')
指定した数字のみを表示します。
# 表示する数字を指定 k = 0 # 指定した数字に関するデータを抽出 x = x_train[t_train == k] t = t_train[t_train == k] idx = np.arange(len(t_train))[t_train == k] # 画像サイズを指定 fig = plt.figure(figsize=(5, 5)) # 作図処理を関数として定義 def update(n): # 前フレームのグラフを初期化 plt.cla() # n番目の数字を作図 plt.imshow(x[n, 0], cmap='gray') # 手書き数字 plt.title('number:' + str(idx[n]) + ', label:' + str(t[n]), fontsize=15) # ラベルデータ plt.axis('off') # 軸目盛 # gif画像を作成 mnist_anime = FuncAnimation(fig, update, frames=100, interval=1000) # gif画像を保存 mnist_anime.save('ch3_6_2_mnist_' + str(k) + '.gif')





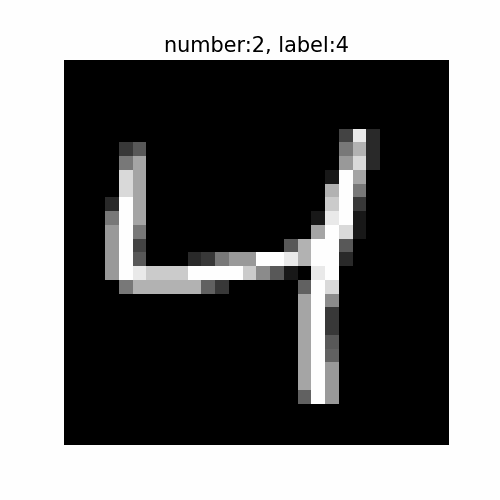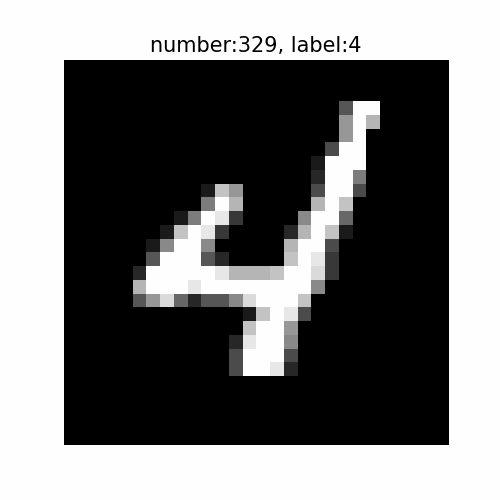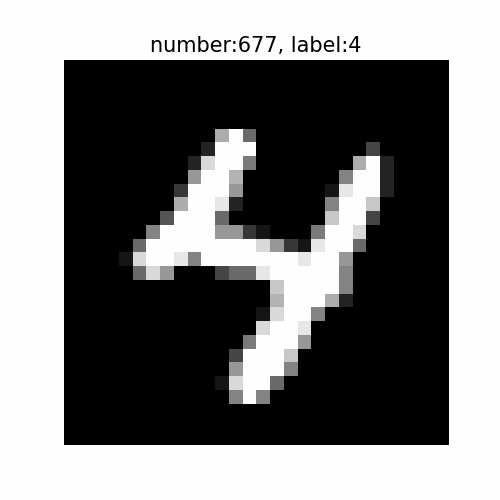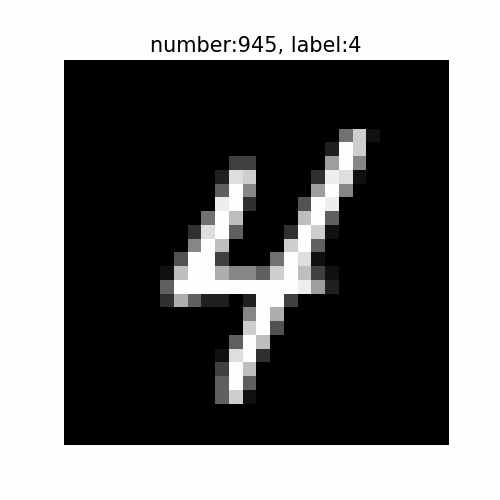





思っているより難しそう(字が汚い)ですね。
参考文献
- 斎藤康毅『ゼロから作るDeep Learning』オライリー・ジャパン,2016年.
おわりに
読み返す度に付け足したいことが増えていく。良いこと?良くない?
自分が最初に躓いたのがこの内容ですね。思い出深い、、まだ先月のことだけど。
引数について書きましたが、それぞれどんな利用例があるのか追加したいですねぇ。
- 2021.07.15:加筆修正しました。
MNISTデータセットで検索した人がこの記事に辿り着いているっぽかったので、早く書き直したかった。一応ゼロつく目的でない人にも意味のあることを書き足せたと思います。この長文からぱっと見でその部分を見つけられるかは別問題だけど。
そしてあれもこれも詰込み過ぎてしまいました。文字数で言うと2.5倍になりました。情報が増えた分、欲しい情報を見付けられなくなったら本末転倒なんですけど。
【関連する記事】
などなど