はじめに
『問題解決力を鍛える! アルゴリズムとデータ構造』の学習ノートです。
本に掲載されているコードや図をR言語で再現します。本と一緒に読んでください。
この記事は、12.8節「ソート(5):バケットソート」の内容です。
ソートのアルゴリズムを確認します。
【前節の内容】
【他の節の内容】
【この節の内容】
12.8 バケットソートの実装と可視化
バケットソート(bucket sort)を実装します。また、ソートの推移のアニメーションを作成して、アルゴリズムを確認します。
利用するパッケージを読み込みます。
# 利用パッケージ library(tidyverse) library(patchwork) library(gganimate)
この記事では、基本的に パッケージ名::関数名() の記法を使っているので、パッケージを読み込む必要はありません。ただし、作図コードについてはパッケージ名を省略しているので、ggplot2 を読み込む必要があります。
また、ネイティブパイプ演算子 |> を使っています。magrittr パッケージのパイプ演算子 %>% に置き換えても処理できますが、その場合は magrittr を読み込む必要があります。
「ソートの可視化」において、patchwork パッケージを利用して複数のグラフを並べて描画、gganimate パッケージを利用してアニメーション(gif画像)を作成します。ソートの実装自体には使いません。
ソートの実装
まずは、バケットソートのアルゴリズムを関数として実装します。
バケットソートを実装します。
# バケットソートの実装 bucket_sort <- function(vec, max_val = NA) { # 数列の要素数を取得 N <- length(vec) # 最大値を設定 if(is.na(max_val)) { max_val <- max(vec) } # 集計用の中間変数を初期化 num_vec <- rep(x = 0, times = max_val) sum_vec <- rep(x = 0, times = max_val) val_vec <- rep(x = NA, times = N) # 要素ごとに処理 for(i in 1:N) { # (前から) # 重複数をカウント num_vec[vec[i]] <- num_vec[vec[i]] + 1 } # 値ごとに処理 for(v in 1:max_val) { # 累積要素数をカウント if(v == 1) { # (初回) sum_vec[v] <- num_vec[v] } else { sum_vec[v] <- sum_vec[v-1] + num_vec[v] } } # 要素ごとに処理 for(i in N:1) { # (後から) # 累積要素数番目に値を格納 val_vec[sum_vec[vec[i]]] <- vec[i] # 累積要素数をカウントダウン sum_vec[vec[i]] <- sum_vec[vec[i]] - 1 } # 数列を更新 vec <- val_vec # 数列を出力 return(vec) }
全ての要素が正の整数の数列を vec、数列の要素数を N とします。(本だと0以上の整数ですが、Rはインデックスが1からなので0より大きい整数とします。0を含める場合は、処理の前に数列全体に1を足しておきソート後の出力の前に1を引けばいいと思いますが、この例では扱いません。)
また、中間変数として扱う際の最大値を max_val として指定します。指定しない場合は、max() で実際の最大値を設定しますが、ソート前に最大値を得るのはおかしいのかもしれません。)
vec の各要素が正の整数であるのを利用して、vec に格納されている値(1 から max_val までの整数)ごとの要素数をカウントします。初期値が全て 0 のベクトル num_vec の vec[i] 番目(i は 1 から N までの整数)に 1 を足していくことで、要素数が得られます。
num_vec を用いて累積要素数をカウントします。整数 v-1 までの累積要素数 sum_vec[v-1] と整数 v の要素数 num_vec[v] を足すことで、vec に含まれる要素数の累積和(整数 v までの要素数)が得られます。
sum_vec を用いて昇順に要素を並べ換えます。i 番目の要素の値(整数) vec[i] の累積要素数 sum_vec[vec[i]] 番目に値 vec[i] を格納し、sum_vec[vec[i]] のカウントを1つ減らしていく(i は N から 1 までの(逆順の)整数)ことで、昇順に並んだベクトルを得られます。
アルゴリズムの詳しい解説は、本のcode 12.5などを参照してください。
実装した関数を試してみます。
要素数と最大値を指定して、数列を作成します。
# 要素数を指定 N <- 50 # 最大値を指定 max_val <- 100 # 数列を生成 a <- sample(x = 1:max_val, size = N, replace = TRUE) a
## [1] 16 17 77 67 97 8 32 56 90 39 6 45 53 81 70 96 40 43 99 ## [20] 17 63 17 47 15 58 25 86 81 85 48 62 29 48 72 100 94 37 96 ## [39] 39 79 18 60 77 9 14 21 10 87 50 64
乱数生成関数 sample() などで数値ベクトルを生成します。
バケットソートにより並べ替えます。
# ソート bucket_sort(a, max_val = max_val)
## [1] 6 8 9 10 14 15 16 17 17 17 18 21 25 29 32 37 39 39 40 ## [20] 43 45 47 48 48 50 53 56 58 60 62 63 64 67 70 72 77 77 79 ## [39] 81 81 85 86 87 90 94 96 96 97 99 100
目で確認するのはアレなので、組み込み関数のソート結果と比較して確認します。
# 確認 sum(!(bucket_sort(a, max_val) == sort(a)))
## [1] 0
! で TRUE, FALSE を反転させて sum() で合計することで、一致しない要素数を得られます。結果が 0 であれば全ての要素が一致したことが分かります。
ソートの可視化
次は、バケットソートのアルゴリズムをグラフで確認します。
数列の初期値を作成して、グラフで確認します。
・作図コード(クリックで展開)
要素数と最大値を指定して、数列を作成します。
# 要素数を指定 N <- 30 # 最大値を指定 max_val <- 20 # 数列を生成 a <- sample(x = 1:max_val, size = N, replace = TRUE) table(a)
## a ## 2 4 5 6 7 9 10 11 12 14 15 16 17 18 19 20 ## 1 2 2 1 3 1 2 4 3 1 1 2 1 1 1 4
「ソートの実装」のときのコードで数列を作成します。
数列をデータフレームに格納します。
# 要素数を取得 N <- length(a) # 数列を格納 seq_df <- tibble::tibble( index = 1:N, # 各試行のインデックス value = a # 要素 #value = bucket_sort(a) # 要素 ) seq_df
## # A tibble: 30 × 2 ## index value ## <int> <int> ## 1 1 11 ## 2 2 6 ## 3 3 10 ## 4 4 18 ## 5 5 5 ## 6 6 16 ## 7 7 12 ## 8 8 4 ## 9 9 2 ## 10 10 15 ## # ℹ 20 more rows
作図用に、インデックスとあわせて数列を格納します。数列のみが与えられている場合は、要素数を N とします。
数列を棒グラフで確認します。
# 数列を作図 ggplot() + geom_bar(data = seq_df, mapping = aes(x = index, y = value, fill = factor(value)), stat = "identity") + theme(panel.grid.minor.x = element_blank()) + # 図の体裁 labs(title = "numerical sequence", fill = "value", x = "index", y = "value")
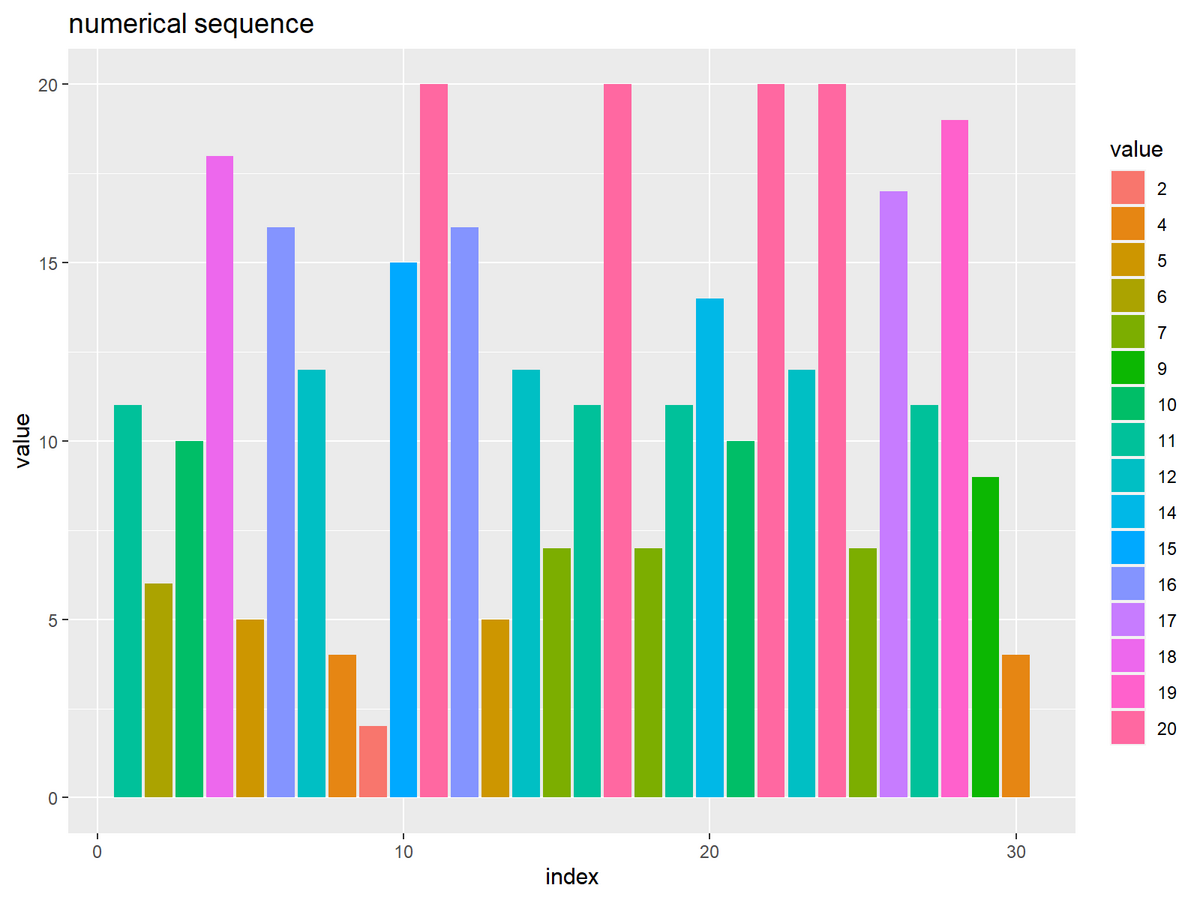
この要素(バー)を昇順に並べ替えます。
簡易版と詳細版の2つのアニメーションでアルゴリズムを確認します。
操作の確認
作図用に、アルゴリズムに従う途中経過のデータを作成します。
・作図コード(クリックで展開)
数列の初期値の描画用のデータフレームを作成します。
# 数列を格納 sequence_df <- tibble::tibble( iteration = 0, # フレーム番号 id = 1:N, # 要素ID # 数列用 index = 1:N, value = a, # タイル用 x = index, y = 0.5 * value, height = value, alpha = 1, linetype = "blank", # ラベル用 label_y = 0 ) |> dplyr::group_by(value) |> # IDの割当用 dplyr::mutate( # 重複ラベル用 dup_id = dplyr::row_number(id), # 重複IDを割り当て dup_num = max(dup_id), # 重複の判定用 dup_label = dplyr::if_else( condition = dup_num > 1, true = paste0("(", dup_id, ")"), false = "" ) # 重複要素のみラベルを作成 ) |> dplyr::ungroup() sequence_df |> dplyr::select(!c(height, alpha, linetype, dup_id, dup_num)) # 資料作成用に間引き
## # A tibble: 30 × 8 ## iteration id index value x y label_y dup_label ## <dbl> <int> <int> <int> <int> <dbl> <dbl> <chr> ## 1 0 1 1 11 1 5.5 0 "(1)" ## 2 0 2 2 6 2 3 0 "" ## 3 0 3 3 10 3 5 0 "(1)" ## 4 0 4 4 18 4 9 0 "" ## 5 0 5 5 5 5 2.5 0 "(1)" ## 6 0 6 6 16 6 8 0 "(1)" ## 7 0 7 7 12 7 6 0 "(1)" ## 8 0 8 8 4 8 2 0 "(1)" ## 9 0 9 9 2 9 1 0 "" ## 10 0 10 10 15 10 7.5 0 "" ## # ℹ 20 more rows
数列のインデックスと値を格納して、作図用の値(列)を作成します。
重複している値の要素にのみ、それぞれ通し番号のラベルを作成します。
アニメーション用のフレーム番号を 0 とし、以降は通し番号を指定します。
数列の初期値の棒グラフを作成します。
# 数列を作図 sequence_graph <- ggplot() + geom_tile(data = sequence_df, mapping = aes(x = x, y = y, width = 1, height = height, fill = factor(value))) + # 全要素 # geom_bar(data = sequence_df, # mapping = aes(x = x, y = value, fill = factor(value)), stat = "identity") + # 全要素 geom_text(data = sequence_df, mapping = aes(x = x, y = label_y, label = as.character(value)), vjust = -1.5, size = 5) + # 要素ラベル geom_text(data = sequence_df, mapping = aes(x = x, y = label_y, label = dup_label), vjust = -0.5, size = 4) + # 重複ラベル coord_equal(ratio = 1, xlim = c(1, N), ylim = c(0, max_val)) + # アスペクト比 theme(panel.grid.minor.x = element_blank(), legend.position = "none") + labs(title = "numerical sequence", subtitle = "initial value", fill = "value", x = "index", y = "value") sequence_graph
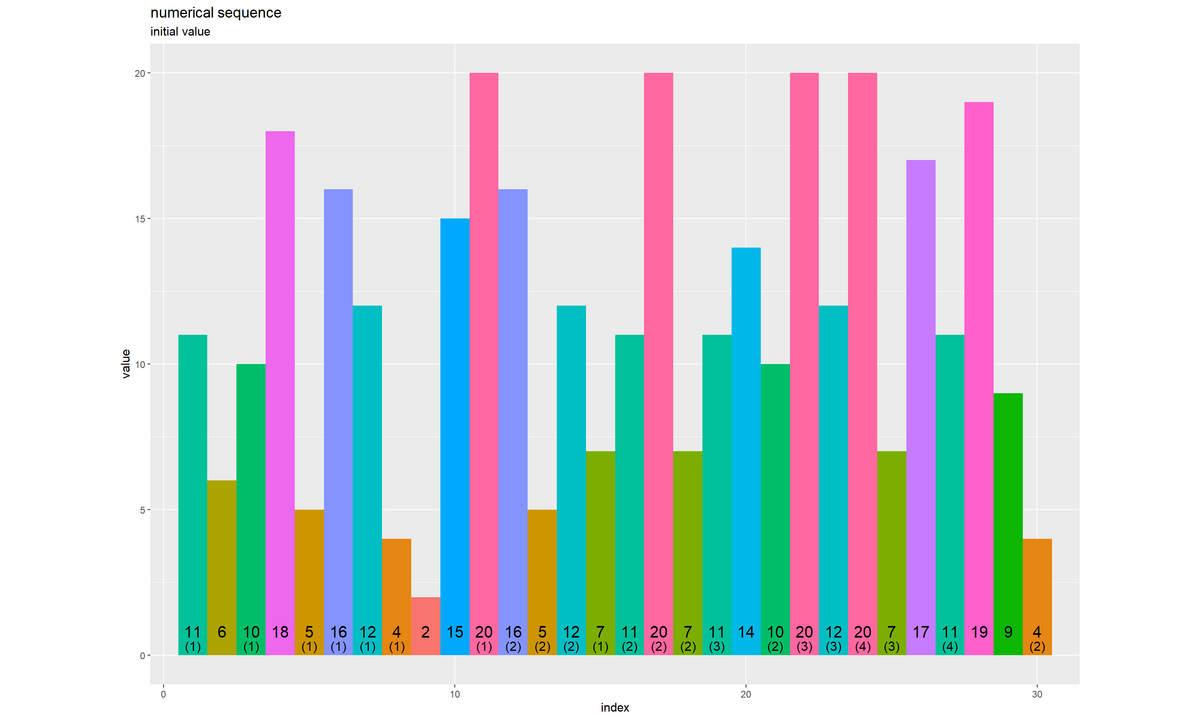
アニメーションの作図の確認として geom_tile() でバーを描画しています。x軸(x 引数)を数列のインデックス、y軸(y 引数)を数列の半分の値、高さ(height 引数)を数列の値にすると、数列に対応した棒グラフを描画できます。
geom_bar() でバーを描画する場合は、y 引数に value 列を指定します。
値ごとの要素数の描画用のデータフレームを作成します。
# 値ごとの要素数をカウント count_df <- tibble::tibble( iteration = 1, # フレーム番号 id = 1:N, # 要素ID # 数列用 value = a, # タイル用 x = value, height = 1, alpha = 0.1, linetype = "dashed" ) |> dplyr::group_by(value) |> # IDの割当・カウント用 dplyr::mutate( count = dplyr::row_number(id), # 値ごとの累積要素数 y = count - 0.5, # ラベル用 label_y = y - 0.5, # 重複ラベル用 dup_id = dplyr::row_number(id), # 重複IDを割り当て dup_num = max(dup_id), # 重複の判定用 dup_label = dplyr::if_else( condition = dup_num > 1, true = paste0("(", dup_id, ")"), false = "" ) # 重複要素のみラベルを作成 ) |> dplyr::ungroup() count_df |> dplyr::select(!c(height, alpha, linetype, dup_id, dup_num)) # 資料作成用に間引き
## # A tibble: 30 × 8 ## iteration id value x count y label_y dup_label ## <dbl> <int> <int> <int> <int> <dbl> <dbl> <chr> ## 1 1 1 11 11 1 0.5 0 "(1)" ## 2 1 2 6 6 1 0.5 0 "" ## 3 1 3 10 10 1 0.5 0 "(1)" ## 4 1 4 18 18 1 0.5 0 "" ## 5 1 5 5 5 1 0.5 0 "(1)" ## 6 1 6 16 16 1 0.5 0 "(1)" ## 7 1 7 12 12 1 0.5 0 "(1)" ## 8 1 8 4 4 1 0.5 0 "(1)" ## 9 1 9 2 2 1 0.5 0 "" ## 10 1 10 15 15 1 0.5 0 "" ## # ℹ 20 more rows
値ごとに(value 列でグループ化して)、row_number() を使って要素IDの小さい順に累積要素数を割り当てます(重複IDの割り当てと同じ処理です)。
数列に含まれる値ごとの要素数の積み上げ棒グラフを作成します。
# 最大値を取得 max_cnt <- max(count_df[["count"]]) + 1 # 値ごとの要素数を作図 count_graph <- ggplot() + geom_tile(data = count_df, mapping = aes(x = x, y = y, width = 1, height = height, fill = factor(value), color = factor(value)), alpha = 0.1, linewidth = 0.6, linetype = "dashed") + # 全要素 # geom_bar(data = count_df, # mapping = aes(x = x, y = 1, fill = factor(value), color = factor(value)), # stat = "identity", position = "stack", width = 1, # alpha = 0.1, linewidth = 0.6, linetype = "dashed") + # 全要素 geom_text(data = count_df, mapping = aes(x = x, y = label_y, label = as.character(value)), vjust = -1.5, size = 3) + # 要素ラベル geom_text(data = count_df, mapping = aes(x = x, y = label_y, label = dup_label), vjust = -0.5, size = 2) + # 重複ラベル coord_equal(ratio = 1, xlim = c(1, N), ylim = c(0, max_cnt)) + # アスペクト比 theme(panel.grid.minor.x = element_blank(), legend.position = "none") + labs(title = "count", fill = "value", x = "value", y = "count") count_graph
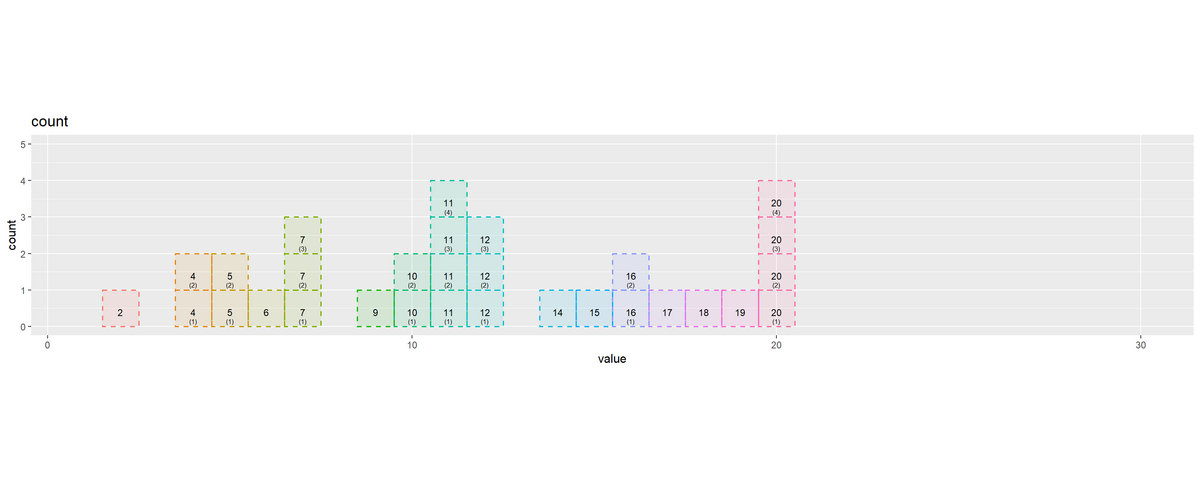
x軸(x 引数)を数列の値、y軸(y 引数)を値ごとの累積要素数から半タイル分ズラした(0.5 を引いた)値、高さ(height 引数)を 1 にすると、数列の要素数に対応した棒グラフを描画できます。
geom_bar() を使う場合は、y 引数に 1、position = "stack" (デフォルト)を指定して積み上げ棒グラフとして描画します。
累積要素数とインデックスの対応関係の描画用のデータフレームを作成します。
# 累積要素数をカウント reorder_df <- tibble::tibble( iteration = 2, # フレーム番号 id = 1:N, # 要素ID # 数列用 value = a, # タイル用 y = 0.5, height = 1, alpha = 0.1, linetype = "dashed", # ラベル用 label_y = y - 0.5 ) |> dplyr::arrange(value, id) |> # 累積カウント用 dplyr::mutate( x = dplyr::row_number() # 累積要素数 ) |> dplyr::arrange(id) |> dplyr::group_by(value) |> # IDの割当用 dplyr::mutate( # 重複ラベル用 dup_id = dplyr::row_number(id), # 重複IDを割り当て dup_num = max(dup_id), # 重複の判定用 dup_label = dplyr::if_else( condition = dup_num > 1, true = paste0("(", dup_id, ")"), false = "" ) # 重複要素のみラベルを作成 ) |> dplyr::ungroup() reorder_df |> dplyr::select(!c(height, alpha, linetype, dup_id, dup_num)) # 資料作成用に間引き
## # A tibble: 30 × 7 ## iteration id value y label_y x dup_label ## <dbl> <int> <int> <dbl> <dbl> <int> <chr> ## 1 2 1 11 0.5 0 13 "(1)" ## 2 2 2 6 0.5 0 6 "" ## 3 2 3 10 0.5 0 11 "(1)" ## 4 2 4 18 0.5 0 25 "" ## 5 2 5 5 0.5 0 4 "(1)" ## 6 2 6 16 0.5 0 22 "(1)" ## 7 2 7 12 0.5 0 17 "(1)" ## 8 2 8 4 0.5 0 2 "(1)" ## 9 2 9 2 0.5 0 1 "" ## 10 2 10 15 0.5 0 21 "" ## # ℹ 20 more rows
値と要素IDの小さい順に、row_number() を使って通し番号を割り当てます。
昇順の値ごとの累積要素数の棒グラフを作成します。
# 累積要素数を作図 reorder_graph <- ggplot() + geom_tile(data = reorder_df, mapping = aes(x = x, y = y, width = 1, height = height, fill = factor(value), color = factor(value)), alpha = 0.1, linewidth = 0.6, linetype = "dashed") + # 全要素 # geom_bar(data = reorder_df, # mapping = aes(x = x, y = 1, fill = factor(value), color = factor(value)), # stat = "identity", width = 1, # alpha = 0.1, linewidth = 0.6, linetype = "dashed") + # 全要素 geom_text(data = reorder_df, mapping = aes(x = x, y = label_y, label = as.character(value)), vjust = -1.5, size = 3) + # 要素ラベル geom_text(data = reorder_df, mapping = aes(x = x, y = label_y, label = dup_label), vjust = -0.5, size = 2) + # 重複ラベル coord_equal(ratio = 1, xlim = c(1, N), ylim = c(0, max_cnt)) + # アスペクト比 theme(panel.grid.minor.x = element_blank(), legend.position = "none") + labs(title = "cumulative sum", fill = "value", x = "value", y = "count") reorder_graph
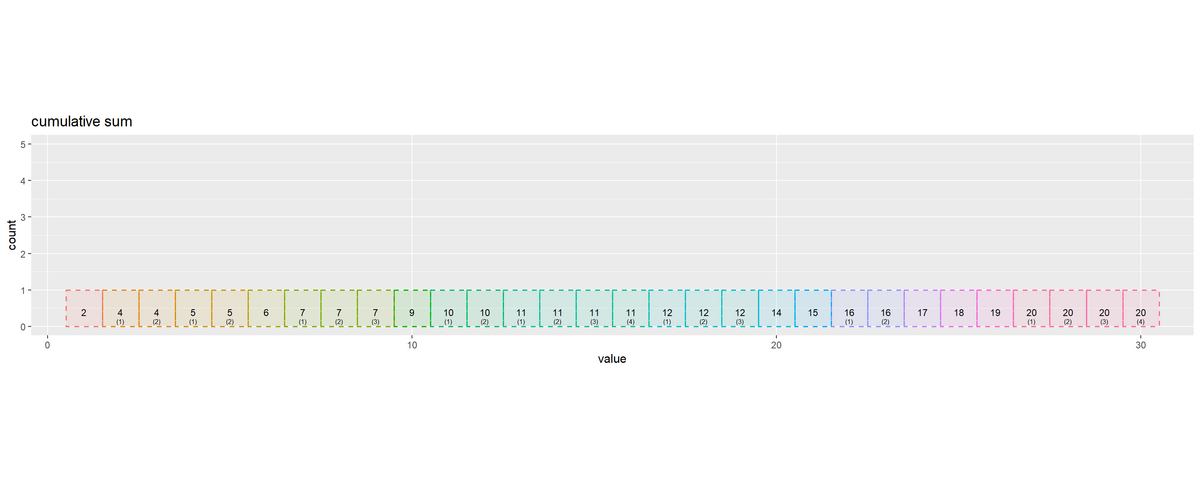
x軸(x 引数)を累積要素数(昇順の通し番号)、y軸(y 引数)を 0.5、高さ(height 引数)を 1 にすると、昇順のインデックスに対応した棒グラフを描画できます。
geom_bar() を使う場合は、y 引数に 1 を指定します。
昇順にソートした数列の描画用のデータフレームを作成します。
# 数列をソート swap_df <- tibble::tibble( iteration = 3, # フレーム番号 id = 1:N, # 要素ID # 数列用 value = a, # タイル用 y = 0.5 * value, height = value, alpha = 1, linetype = "blank", # ラベル用 label_y = 0 ) |> dplyr::arrange(value, id) |> # 入替用 dplyr::mutate( index = dplyr::row_number(), # 入替後のインデックス x = index ) |> dplyr::arrange(id) |> dplyr::group_by(value) |> # IDの割当用 dplyr::mutate( # 重複ラベル用 dup_id = dplyr::row_number(id), # 重複IDを割り当て dup_num = max(dup_id), # 重複の判定用 dup_label = dplyr::if_else( condition = dup_num > 1, true = paste0("(", dup_id, ")"), false = "" ) # 重複要素のみラベルを作成 ) |> dplyr::ungroup() swap_df |> dplyr::select(!c(height, alpha, linetype, dup_id, dup_num)) # 資料作成用に間引き
## # A tibble: 30 × 8 ## iteration id value y label_y index x dup_label ## <dbl> <int> <int> <dbl> <dbl> <int> <int> <chr> ## 1 3 1 11 5.5 0 13 13 "(1)" ## 2 3 2 6 3 0 6 6 "" ## 3 3 3 10 5 0 11 11 "(1)" ## 4 3 4 18 9 0 25 25 "" ## 5 3 5 5 2.5 0 4 4 "(1)" ## 6 3 6 16 8 0 22 22 "(1)" ## 7 3 7 12 6 0 17 17 "(1)" ## 8 3 8 4 2 0 2 2 "(1)" ## 9 3 9 2 1 0 1 1 "" ## 10 3 10 15 7.5 0 21 21 "" ## # ℹ 20 more rows
値と要素IDの小さい順に、row_number() を使ってインデックス(通し番号)を割り当てます。
昇順に並べ替えた数列の棒グラフを作成します。
# ソート済み数列を作図 swap_graph <- ggplot() + geom_tile(data = swap_df, mapping = aes(x = x, y = y, width = 1, height = height, fill = factor(value))) + # 全要素 # geom_bar(data = swap_df, # mapping = aes(x = x, y = value, fill = factor(value)), # stat = "identity") + # 全要素 geom_text(data = swap_df, mapping = aes(x = x, y = label_y, label = as.character(value)), vjust = -1.5, size = 5) + # 要素ラベル geom_text(data = swap_df, mapping = aes(x = x, y = label_y, label = dup_label), vjust = -0.5, size = 4) + # 重複ラベル coord_equal(ratio = 1, xlim = c(1, N), ylim = c(0, max_val)) + # アスペクト比 theme(panel.grid.minor.x = element_blank(), legend.position = "none") + labs(title = "bucket sort", fill = "value", x = "index", y = "value") swap_graph
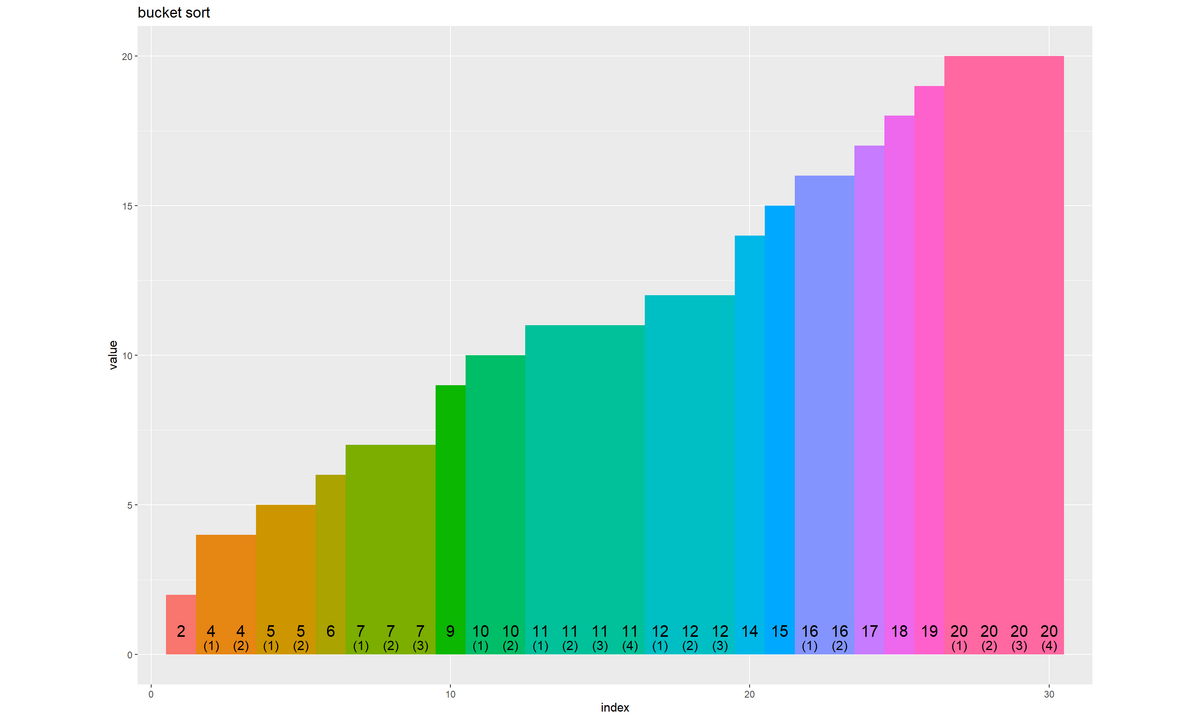
x軸(x 引数)を累積要素数(昇順の通し番号)、y軸(y 引数)を数列の半分の値、高さ(height 引数)を数列の値にすると、数列に対応した棒グラフを描画できます。
geom_bar() でバーを描画する場合は、y 引数に value 列を指定します。
各操作のグラフを並べて推移を確認します。
・作図コード(クリックで展開)
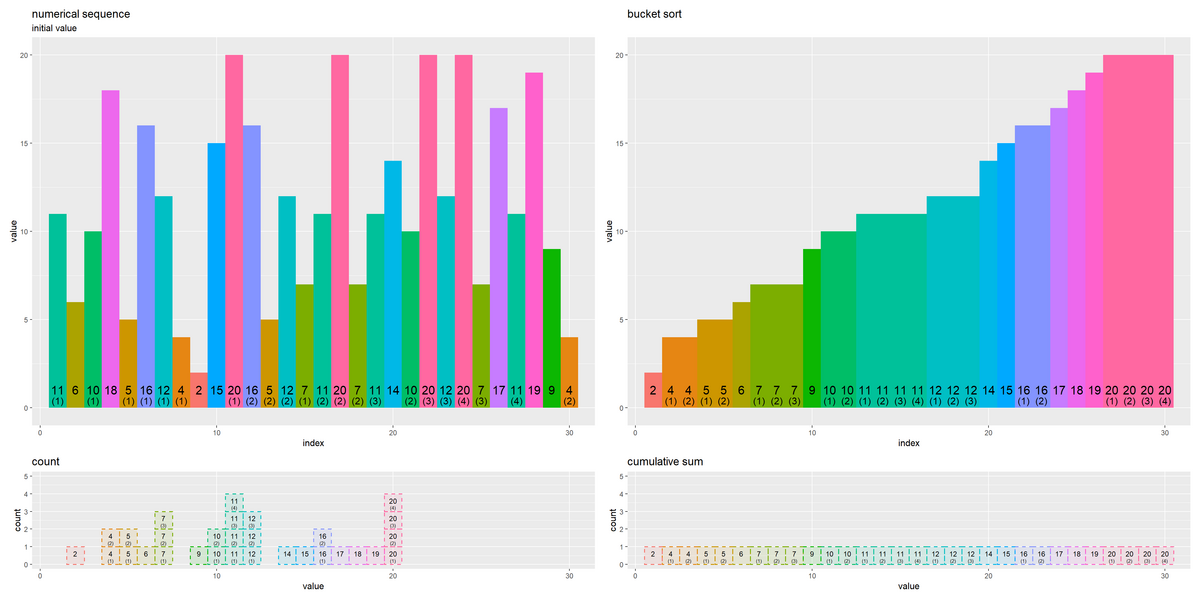
4つのグラフを並べて描画します。
# 並べて描画 patchwork::wrap_plots( sequence_graph, swap_graph, count_graph, reorder_graph, nrow = 2, ncol = 2, widths = 1, heights = c(1, max_cnt/max_val) )
wrap_plots() を使って複数のグラフを1つにまとめて描画します。
各操作のグラフを切り替えて推移を確認します。
・作図コード(クリックで展開)
4つのデータフレームをまとめます。
# データを結合 trace_df <- dplyr::bind_rows( sequence_df, count_df, reorder_df, swap_df ) trace_df |> dplyr::arrange(iteration, id)
## # A tibble: 120 × 14 ## iteration id index value x y height alpha linetype label_y dup_id ## <dbl> <int> <int> <int> <int> <dbl> <dbl> <dbl> <chr> <dbl> <int> ## 1 0 1 1 11 1 5.5 11 1 blank 0 1 ## 2 0 2 2 6 2 3 6 1 blank 0 1 ## 3 0 3 3 10 3 5 10 1 blank 0 1 ## 4 0 4 4 18 4 9 18 1 blank 0 1 ## 5 0 5 5 5 5 2.5 5 1 blank 0 1 ## 6 0 6 6 16 6 8 16 1 blank 0 1 ## 7 0 7 7 12 7 6 12 1 blank 0 1 ## 8 0 8 8 4 8 2 4 1 blank 0 1 ## 9 0 9 9 2 9 1 2 1 blank 0 1 ## 10 0 10 10 15 10 7.5 15 1 blank 0 1 ## # ℹ 110 more rows ## # ℹ 3 more variables: dup_num <int>, dup_label <chr>, count <int>
bind_rows() で複数のデータフレームを行方向に結合します。
4つの操作のアニメーションを作成します。
# ソートのアニメーションを作図 graph <- ggplot() + geom_tile(data = trace_df, mapping = aes(x = x, y = y, width = 1, height = height, fill = factor(value), color = factor(value), alpha = alpha, linetype = linetype, group = factor(id)), linewidth = 1) + # 全要素 geom_text(data = trace_df, mapping = aes(x = x, y = label_y, label = as.character(value), group = factor(id)), vjust = -1.5, size = 5) + # 要素ラベル geom_text(data = trace_df, mapping = aes(x = x, y = label_y, label = dup_label, group = factor(id)), vjust = -0.5, size = 4) + # 重複ラベル gganimate::transition_states(states = iteration, transition_length = 9, state_length = 1, wrap = FALSE) + # フレーム遷移 gganimate::ease_aes("cubic-in-out") + # 遷移の緩急 scale_linetype_identity() + scale_linewidth_identity() + scale_y_continuous(sec.axis = sec_axis(trans = ~-., name = "count")) + # (操作の確認用) coord_equal(ratio = 1) + # アスペクト比 theme(panel.grid.minor.x = element_blank(), legend.position = "none") + labs(title = "bucket sort", subtitle = "iteration: {next_state}", fill = "value", x = "index, value", y = "value, count") # フレーム数を取得 frame_num <- trace_df[["iteration"]] |> (\(vec) {max(vec) + 1})() # 1試行当たりのフレーム数を指定 s <- 20 # gif画像を作成 gganimate::animate( plot = graph, nframes = (frame_num + 2)*s, start_pause = s, end_pause = s, fps = 20, width = 1000, height = 800, renderer = gganimate::gifski_renderer() )
transition_states() のフレーム制御の引数 states にフレーム番号列 iteration を指定して、要素の値や要素数の対応関係が補完されるように geom_tile() で棒グラフを描画します。
animate() の plot 引数にグラフオブジェクト、nframes 引数にフレーム数を指定して、gif画像を作成します。
フレーム数は 4 です。transition_states() でアニメーションを作成すると、フレーム間の値を補完して、状態の遷移を描画します。遷移のフレームを s として、試行回数の s 倍の値を nframes 引数に指定します。
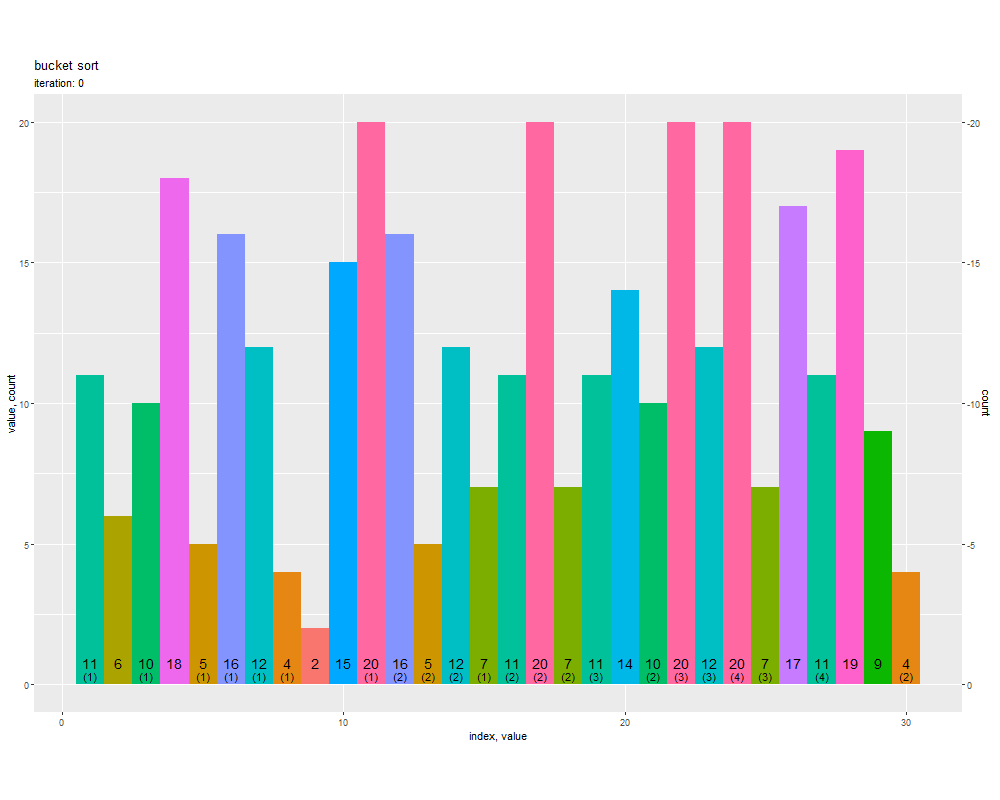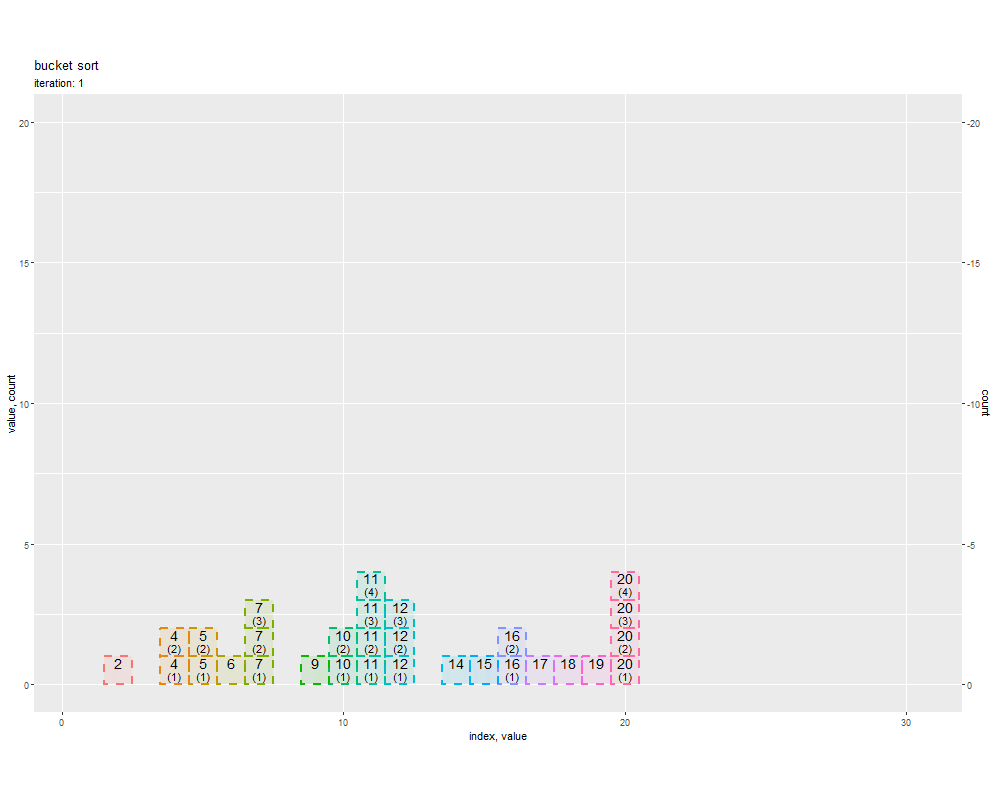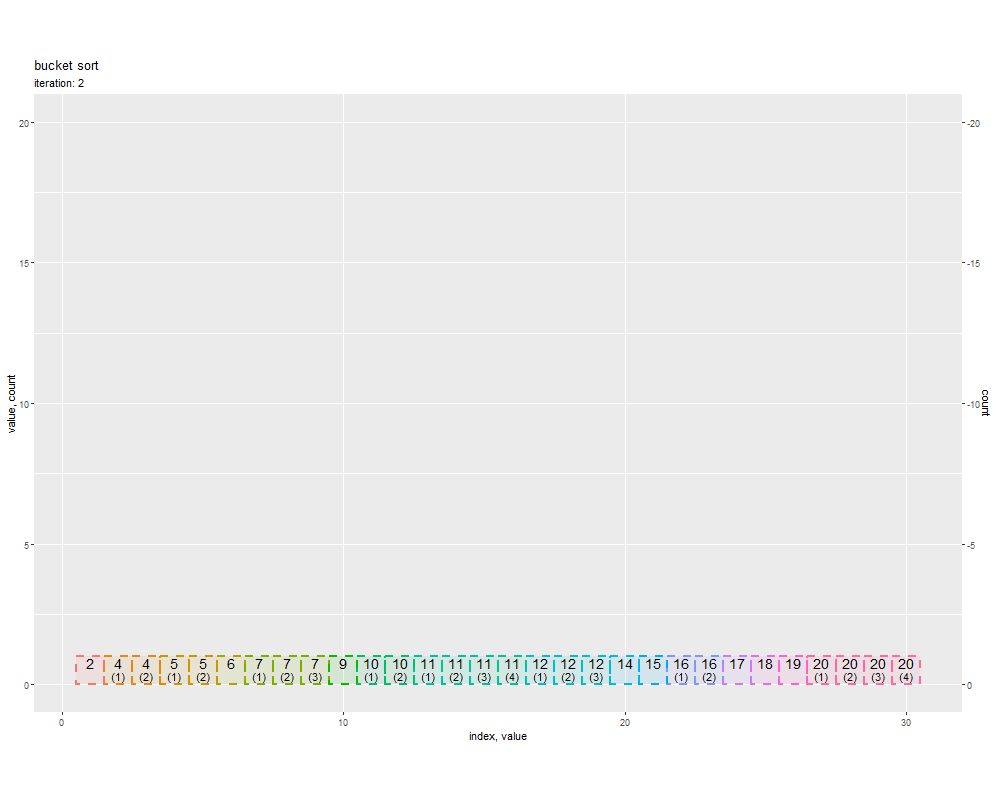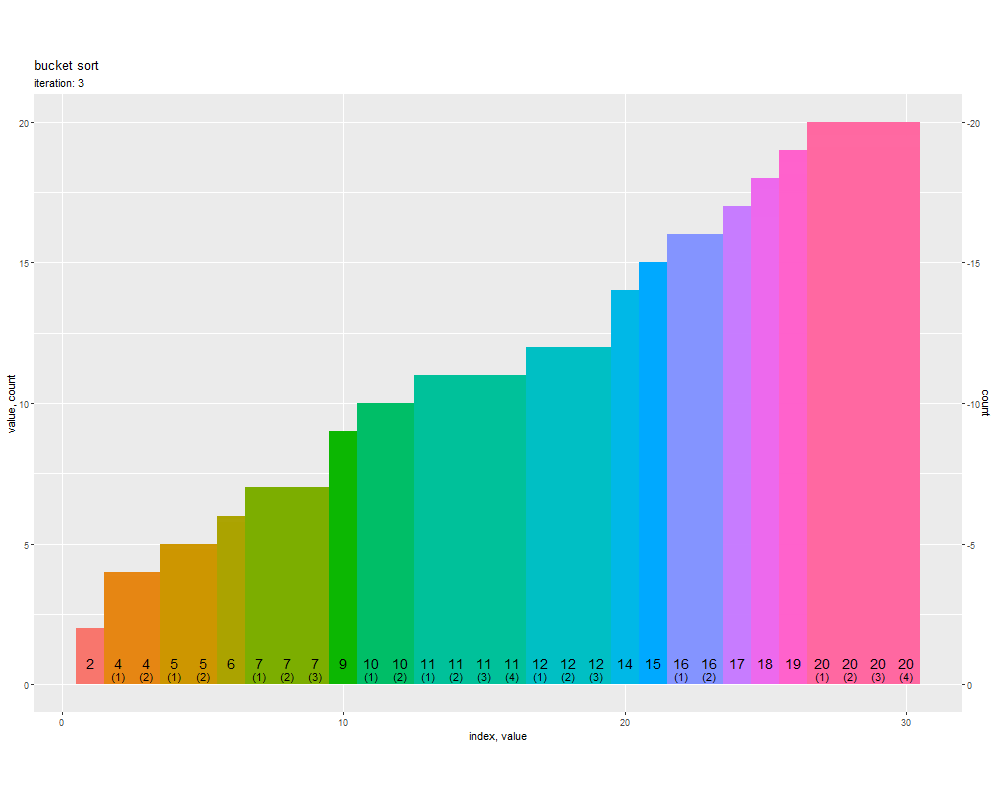
元の「数列の値」、「値ごとの要素数」、昇順にカウントした「累積要素数」、ソート後の「数列のインデックス」の対応関係を確認できます。
入替の確認
続いて「ソートの実装」のアルゴリズムに対応するように、数列の前の要素からカウントし、後の要素から配置していくデータを作成します。
・作図コード(クリックで展開)
カウント時の数列の描画用のデータフレームを作成します。
# インデックスの小さい順に要素を取り出す sequence_df <- tidyr::expand_grid( iteration = 0:N, # カウント時の試行回数 id = 1:N # 元のインデックス ) |> # 試行ごとに要素IDを複製 dplyr::mutate( # 数列用 index = id, value = a[id], # タイル用 x = index, y = 0.5 * value, height = value, alpha = 1, linetype = "blank", # ラベル用 label_y = 0 ) |> dplyr::group_by(iteration, value) |> # IDの割当用 dplyr::mutate( # 重複ラベル用 dup_id = dplyr::row_number(id), # 重複IDを割り当て dup_num = max(dup_id), # 重複の判定用 dup_label = dplyr::if_else( condition = dup_num > 1, true = paste0("(", dup_id, ")"), false = "" ) # 重複要素のみラベルを作成 ) |> dplyr::ungroup() |> dplyr::filter(iteration < id) # 未カウントの要素を抽出 sequence_df |> dplyr::select(!c(height, alpha, linetype, dup_id, dup_num)) # 資料作成用に間引き
## # A tibble: 465 × 8 ## iteration id index value x y label_y dup_label ## <int> <int> <int> <int> <int> <dbl> <dbl> <chr> ## 1 0 1 1 11 1 5.5 0 "(1)" ## 2 0 2 2 6 2 3 0 "" ## 3 0 3 3 10 3 5 0 "(1)" ## 4 0 4 4 18 4 9 0 "" ## 5 0 5 5 5 5 2.5 0 "(1)" ## 6 0 6 6 16 6 8 0 "(1)" ## 7 0 7 7 12 7 6 0 "(1)" ## 8 0 8 8 4 8 2 0 "(1)" ## 9 0 9 9 2 9 1 0 "" ## 10 0 10 10 15 10 7.5 0 "" ## # ℹ 455 more rows
試行番号(初期値を 0 として N までの整数)と要素ID(初期値のインデックス)(1 から N までの整数)の全ての組み合わせを expand_grid() で作成します。
「操作の確認」のときと同様に処理して、未カウントの要素(試行番号よりIDが大きい行)を抽出します。
カウント時の値ごとの要素数の描画用のデータフレームを作成します。
# インデックスの小さい順に要素を取り出してカウント count_df <- tidyr::expand_grid( iteration = 0:N, # カウント時の試行回数 id = 1:N # 元のインデックス ) |> # 試行ごとに要素IDを複製 dplyr::mutate( # 数列用 value = a[id], # タイル用 x = value, height = 1, alpha = 0.1, linetype = "dashed" ) |> dplyr::group_by(iteration, value) |> # IDの割当・カウント用 dplyr::mutate( # タイル用 count = dplyr::row_number(id), # 値ごとの要素数 y = -count + 0.5, # ラベル用 label_y = y - 0.5, # 重複ラベル用 dup_id = dplyr::row_number(id), # 重複IDを割り当て dup_num = max(dup_id), # 重複の判定用 dup_label = dplyr::if_else( condition = dup_num > 1, true = paste0("(", dup_id, ")"), false = "" ) # 重複要素のみラベルを作成 ) |> dplyr::ungroup() |> dplyr::filter(iteration >= id) # カウント済みの要素を抽出 count_df |> dplyr::select(!c(height, alpha, linetype, dup_id, dup_num)) # 資料作成用に間引き
## # A tibble: 465 × 8 ## iteration id value x count y label_y dup_label ## <int> <int> <int> <int> <int> <dbl> <dbl> <chr> ## 1 1 1 11 11 1 -0.5 -1 "(1)" ## 2 2 1 11 11 1 -0.5 -1 "(1)" ## 3 2 2 6 6 1 -0.5 -1 "" ## 4 3 1 11 11 1 -0.5 -1 "(1)" ## 5 3 2 6 6 1 -0.5 -1 "" ## 6 3 3 10 10 1 -0.5 -1 "(1)" ## 7 4 1 11 11 1 -0.5 -1 "(1)" ## 8 4 2 6 6 1 -0.5 -1 "" ## 9 4 3 10 10 1 -0.5 -1 "(1)" ## 10 4 4 18 18 1 -0.5 -1 "" ## # ℹ 455 more rows
「操作の確認」のときと同様に処理して、カウント済みの要素(試行番号がID以上の行)を抽出します。ただし、バーが重ならないようにカウントの符号を反転させた(-1 を掛けた)値をy軸の値とします。
昇順に配置時の累積要素数とインデックスの対応関係の描画用のデータフレームを作成します。
# インデックスの小さい順に要素を戻してカウント discount_df <- tidyr::expand_grid( iteration = 0:N + N+1, # 入替時の試行回数 id = 1:N # 元のインデックス ) |> # 試行ごとに要素IDを複製 dplyr::mutate( # 数列用 value = a[id], # タイル用 y = -0.5, height = 1, alpha = 0.1, linetype = "dashed", # ラベル用 label_y = y - 0.5 ) |> dplyr::arrange(iteration, value, id) |> # 累積カウント用 dplyr::group_by(iteration) |> # 累積カウント用 dplyr::mutate( # タイル用 x = dplyr::row_number() # 累積要素数 ) |> dplyr::arrange(iteration, id) |> dplyr::group_by(iteration, value) |> # IDの割当用 dplyr::mutate( # 重複ラベル用 dup_id = dplyr::row_number(id), # 重複IDを割り当て dup_num = max(dup_id), # 重複の判定用 dup_label = dplyr::if_else( condition = dup_num > 1, true = paste0("(", dup_id, ")"), false = "" ) # 重複要素のみラベルを作成 ) |> dplyr::ungroup() |> dplyr::filter(iteration-(N+1) < N+1-id) # 未入替の要素を抽出 discount_df |> dplyr::select(!c(height, alpha, linetype, dup_id, dup_num)) # 資料作成用に間引き
## # A tibble: 465 × 7 ## iteration id value y label_y x dup_label ## <dbl> <int> <int> <dbl> <dbl> <int> <chr> ## 1 31 1 11 -0.5 -1 13 "(1)" ## 2 31 2 6 -0.5 -1 6 "" ## 3 31 3 10 -0.5 -1 11 "(1)" ## 4 31 4 18 -0.5 -1 25 "" ## 5 31 5 5 -0.5 -1 4 "(1)" ## 6 31 6 16 -0.5 -1 22 "(1)" ## 7 31 7 12 -0.5 -1 17 "(1)" ## 8 31 8 4 -0.5 -1 2 "(1)" ## 9 31 9 2 -0.5 -1 1 "" ## 10 31 10 15 -0.5 -1 21 "" ## # ℹ 455 more rows
カウント時に続く試行番号(N+1 から 2*N+1 までの整数)と要素ID(1 から N までの整数)の全ての組み合わせを expand_grid() で作成します。
「操作の確認」のときと同様に処理して、入替前の要素(「試行番号」より「後から数えたID」が大きい行)を抽出します。
昇順に配置時の数列の描画用のデータフレームを作成します。
# インデックスの小さい順に要素を入れ替えて戻す swap_df <- tidyr::expand_grid( iteration = 0:N + N+1, # 入替時の試行回数 id = 1:N # 元のインデックス ) |> # 試行ごとに要素IDを複製 dplyr::mutate( # 数列用 value = a[id], # タイル用 y = 0.5 * value, height = value, alpha = 1, linetype = "blank", # ラベル用 label_y = 0 ) |> dplyr::arrange(iteration, value, id) |> # 入替用 dplyr::group_by(iteration) |> # 入替用 dplyr::mutate( # タイル用 index = dplyr::row_number(), # 入替後のインデックス x = index ) |> dplyr::arrange(iteration, id) |> dplyr::group_by(iteration, value) |> # IDの割当用 dplyr::mutate( # 重複ラベル用 dup_id = dplyr::row_number(id), # 重複IDを割り当て dup_num = max(dup_id), # 重複の判定用 dup_label = dplyr::if_else( condition = dup_num > 1, true = paste0("(", dup_id, ")"), false = "" ) # 重複要素のみラベルを作成 ) |> dplyr::ungroup() |> dplyr::filter(iteration-(N+1) >= N+1-id) # 入替済みの要素を抽出 swap_df |> dplyr::select(!c(height, alpha, linetype, dup_id, dup_num)) # 資料作成用に間引き
## # A tibble: 465 × 8 ## iteration id value y label_y index x dup_label ## <dbl> <int> <int> <dbl> <dbl> <int> <int> <chr> ## 1 32 30 4 2 0 3 3 "(2)" ## 2 33 29 9 4.5 0 10 10 "" ## 3 33 30 4 2 0 3 3 "(2)" ## 4 34 28 19 9.5 0 26 26 "" ## 5 34 29 9 4.5 0 10 10 "" ## 6 34 30 4 2 0 3 3 "(2)" ## 7 35 27 11 5.5 0 16 16 "(4)" ## 8 35 28 19 9.5 0 26 26 "" ## 9 35 29 9 4.5 0 10 10 "" ## 10 35 30 4 2 0 3 3 "(2)" ## # ℹ 455 more rows
「操作の確認」のときと同様に処理して、入替前の要素(「試行番号」が「後から数えたID」以上の行)を抽出します。
4つのデータフレームをまとめます。
# データを結合 trace_df <- dplyr::bind_rows( sequence_df, count_df, discount_df, swap_df ) trace_df
## # A tibble: 1,860 × 14 ## iteration id index value x y height alpha linetype label_y dup_id ## <dbl> <int> <int> <int> <int> <dbl> <dbl> <dbl> <chr> <dbl> <int> ## 1 0 1 1 11 1 5.5 11 1 blank 0 1 ## 2 0 2 2 6 2 3 6 1 blank 0 1 ## 3 0 3 3 10 3 5 10 1 blank 0 1 ## 4 0 4 4 18 4 9 18 1 blank 0 1 ## 5 0 5 5 5 5 2.5 5 1 blank 0 1 ## 6 0 6 6 16 6 8 16 1 blank 0 1 ## 7 0 7 7 12 7 6 12 1 blank 0 1 ## 8 0 8 8 4 8 2 4 1 blank 0 1 ## 9 0 9 9 2 9 1 2 1 blank 0 1 ## 10 0 10 10 15 10 7.5 15 1 blank 0 1 ## # ℹ 1,850 more rows ## # ℹ 3 more variables: dup_num <int>, dup_label <chr>, count <int>
カウント時と配置時のグラフを切り替えて推移を確認します。
「操作の確認」のときのコードで作図します(遷移フレーム数などは変更しています)。「初期値」の表示と「値ごとの要素数と累積要素数によるインデックス」の遷移を含めるため、フレーム数は 2*N + 2 です。
バーが重ならないように、要素数のカウントを逆向きの積み上げ棒グラフで表しています。
左(1番目)の要素から順番にカウントしていき、右(N番目)の要素から逆順に累積要素数に応じて配置していくことでソートされるのを確認できます。また、重複要素の順序が入れ替わらない(安定性・stable性)も確認できます。
ここでの試行回数(iterationの値)は、この可視化方法における試行番号(作図処理上の値)であり他の手法と対応していません。
この記事では、バケットソートを実装しました。
参考文献
")
おわりに
このアルゴリズムが一番面白かったです。なので、2つ飛ばしてこっちを先に書きました。1つは先に実装済みですが、もう1つはまだよく分かってません。これから読みます。
エンディングにこの曲を聴いてほしい…
のですが、アルバム曲なのでMVがないのでサンプルをば。サブスクもやってないのでサインインしてもフルでは聞けません…
【次節の内容】
いつか書くかもしれません。