はじめに
機械学習でも登場する情報理論におけるエントロピーを1つずつ確認していくシリーズです。
この記事では、平均情報量の最大値を扱います。
【前の内容】
【今回の内容】
平均情報量の最大値(最大エントロピー)の導出
平均情報量(average information)の最大値を導出して、グラフで確認します。平均情報量の最大値は最大エントロピー(maximum entropy)とも呼ばれます。
平均情報量については「平均情報量(エントロピー)の定義 - からっぽのしょこ」を参照してください。
最大値の計算式
まずは、平均情報量を数式で確認します。
排反な 個の事象からなる事象系
の確率分布を
を
として、平均情報量 は、自己情報量
の期待値で定義されるのでした。
1つの事象の確率が1のとき、最小値 になります。ただし、0と(負の)無限大の積を0とします。
全ての事象が等確率のとき、最大値 になります。
最大値の導出
次は、平均情報量の最大値の計算式を導出します。
平均情報量が最大となる確率分布
平均情報量 が最大となる確率分布
を求めます。
には、総和が1であるという制約条件があります。そこで、ラグランジュ乗数
を用いて式(
の関数)
を立てて、ラグランジュの未定乗数法を用いて制約条件付き最大化問題として解きます。
式を分かりやすくするため とおき、一般化するため底を
としています。
を
番目の事象の確率
に関して微分します。
番目の確率
と混同しないように 総和に関するインデックスを
で表記しています(数学的な意味はありません)。
式(1)の前の因子の微分は、 と無関係な項が微分によって消える(0になる)ので
番目の項のみ残ります。
さらに、積の微分 と合成関数の微分
、対数の微分
により
となります。 はネイピア数であり、
は自然対数です。
式(1)の後の因子の微分も、 と無関係な項が消えるので
番目の項のみ残り、
なので1になります。
式(2)と式(3)を式(1)に代入します。
ラグランジュ関数 の
に関する微分
が得られました。
ちなみに、底がネイピア数 のとき(自然対数を用いて情報量を定義する場合)、
なので、2つ目の項が
になります。
を
とおき、
に関して式を整理します。
底を として両辺の指数をとります。
両辺を に関して和をとると、制約条件
より
の項が消えます(1になります)。
底を として両辺の対数をとり、
に関して式を整理します。
この式を式(4)に代入します。
底を として両辺の指数をとります。
平均情報量を最大化する 番目の事象の確率
が得られました。
他の事象の確率についても同様に求められます。
このとき は、総和が1であるという制約条件を満たします。
全ての事象の確率が等しい(一様分布)とき平均情報量が最大になるのが分かりました。
平均情報量の最大値
平均情報量の定義式に一様な確率分布を代入して、最大値 を求めます。
対数の性質より です。
平均情報量の最大値の計算式が得られました。
可視化
最後に、事象の数と平均情報量の最大値の関係をグラフで確認します。
対数関数については「対数の定義 - からっぽのしょこ」を参照してください。
利用するパッケージを読み込みます。
# 利用パッケージ library(tidyverse)
この記事では、基本的にパッケージ名::関数名()の記法を使うので、パッケージを読み込む必要はありません。ただし、作図コードがごちゃごちゃしないようにパッケージ名を省略しているため、ggplot2を読み込む必要があります。
また、ネイティブパイプ演算子|>を使っています。magrittrパッケージのパイプ演算子%>%に置き換えても処理できますが、その場合はmagrittrも読み込む必要があります。
の事象数
が変化したときの、等確率となる各事象の確率と、最大となる平均情報量の変化を可視化します。
事象の数と対数の底を指定して、一様分布の平均情報量(最大エントロピー)を計算します。
# 事象数の最大値を指定 n_max <- 100 # 底を指定 a <- 2 # 最大エントロピーを計算 H_max_df <- tibble::tibble( n = 1:n_max, # 事象の数 p_x = 1 / n, # 各事象の確率:(等確率) #H_max = logb(n, base = a) # 平均情報量:(最大値) H_max = - logb(p_x, base = a) # 平均情報量:(最大値) ) H_max_df
## # A tibble: 100 × 3 ## n p_x H_max ## <int> <dbl> <dbl> ## 1 1 1 0 ## 2 2 0.5 1 ## 3 3 0.333 1.58 ## 4 4 0.25 2 ## 5 5 0.2 2.32 ## 6 6 0.167 2.58 ## 7 7 0.143 2.81 ## 8 8 0.125 3 ## 9 9 0.111 3.17 ## 10 10 0.1 3.32 ## # … with 90 more rows
事象の数 として使う最大の数を
n_maxとして整数を指定して、1からn_maxまでの整数を作成します。
事象の数ごとに、等確率の値(一様分布の各確率) を計算します。
事象の数ごとに、最大エントロピー を計算します。二進対数
の場合は
log2()、自然対数 の場合は
log()、任意の底の対数 の場合は
logb()を使います。
事象の数と一様分布の確率の関係のグラフを作成します。
# 事象の数と一様な確率の関係を作図 ggplot() + geom_line(data = H_max_df, mapping = aes(x = n, y = p_x)) + # 一様分布の確率 labs(title = "probability", subtitle = expression(list(x == (list(x[1], cdots, x[n])), p(x[i]) == frac(1, n))), x = expression(n), y = expression(p(x[i])))
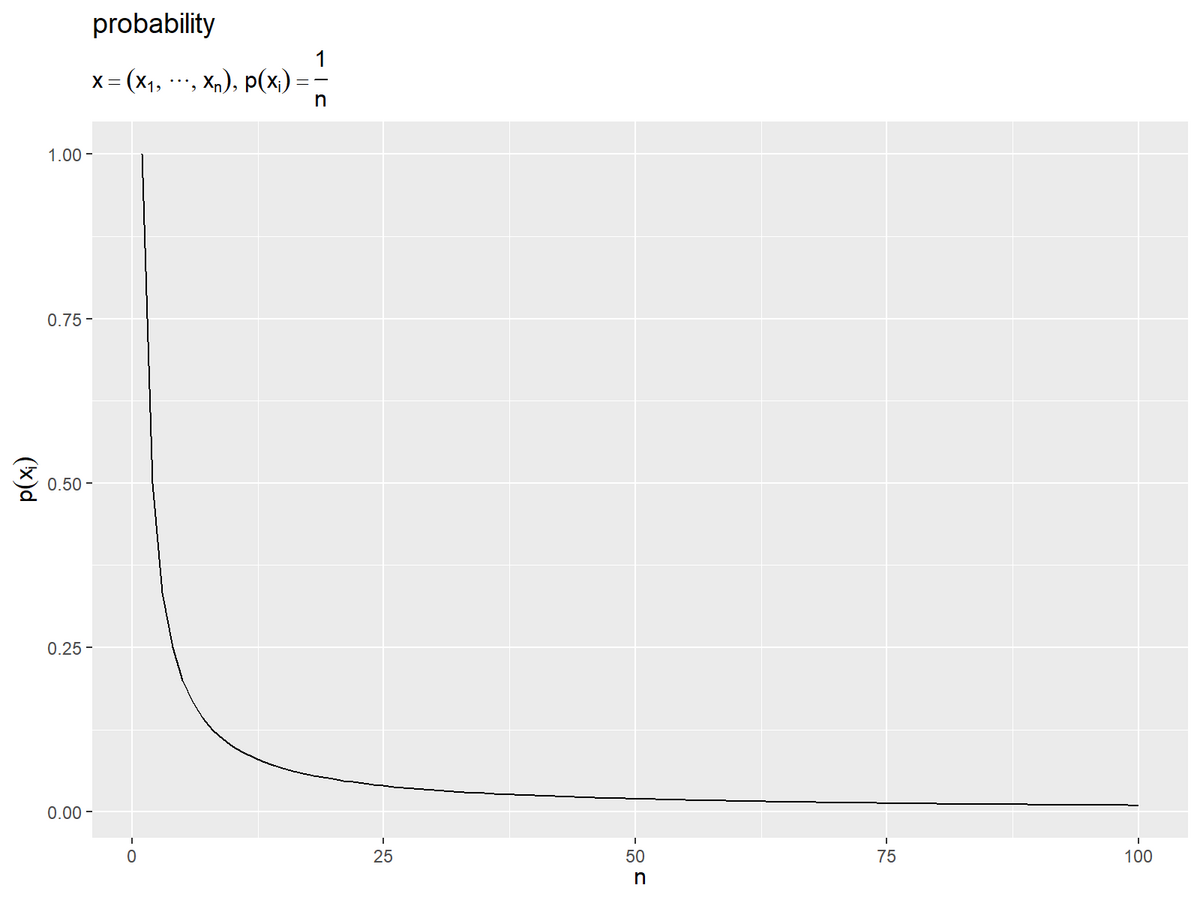
事象の数が増えるほど、各事象の確率が小さくなるのが分かります。
事象の数と最大エントロピーの関係のグラフを作成します。
# タイトル用の文字列を作成 title_label <- paste0( "list(", "a==", a, ", ", "x == (list(x[1], cdots, x[n])), ", "H[max](x) == log[a]*n", ")" ) # 事象の数と最大エントロピーの関係を作図 ggplot() + geom_line(data = H_max_df, mapping = aes(x = n, y = H_max)) + # 一様分布の平均情報量 labs(title = "maximum entropy", subtitle = parse(text = title_label), x = expression(n), y = expression(H[max](x)))
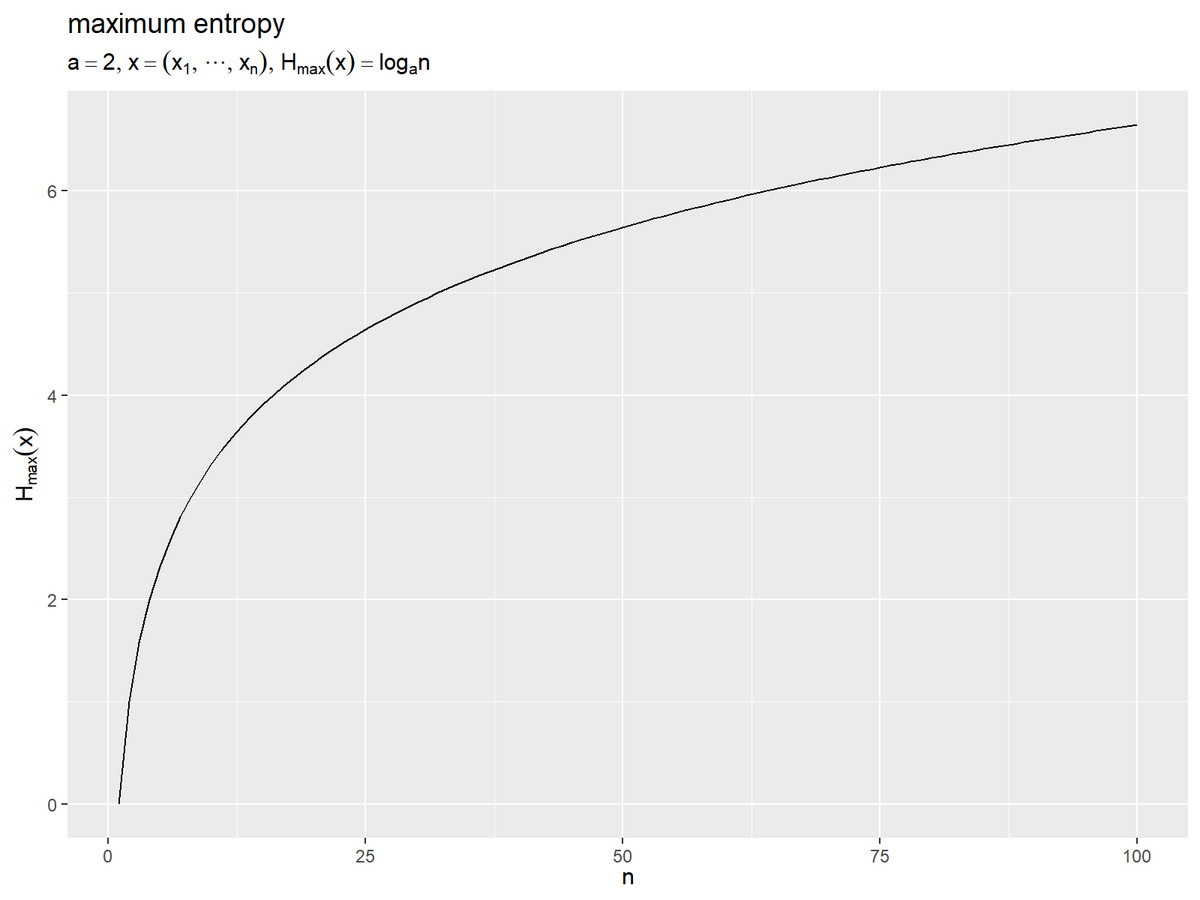
事象の数が増える(各事象の確率が小さくなる)ほど、最大エントロピーが大きくなるのが分かります。
この記事では、平均情報量(エントロピー)の最大値を導出しました。次の記事では、条件付きエントロピーの定義を確認します。
参考文献
- 『わかりやすい ディジタル情報理論』(改訂2版)塩野 充・蜷川 繁,オーム社,2021年.
おわりに
ラグランジュ乗数法だー懐かしーと思いながらサクっと書けました。参考にした本では2次元の例だったので単に微分しただけでしたが、せっかくなのでやってみました。
ところで、PRMLの続きを読む気が戻らないから、少し知っている内容を深めたり広げたりするような別の本を読んでお茶を濁しているのですが、この内容ってPRMLに載ってるんですね。相互情報量までほぼ書き終わってから、KL情報量と何が違うんだっけと調べてたら気付きました。でもPRML版のエントロピー関連の説明を読んでもよく分かりませんでした。やっぱりまだしばらくいいや。
【次の内容】