はじめに
『パターン認識と機械学習』の独学時のまとめです。一連の記事は「数式の行間埋め」または「R・Pythonでのスクラッチ実装」からアルゴリズムの理解を補助することを目的としています。本とあわせて読んでください。
この記事は、3.1.4項「正則化最小二乗法」の内容です。リッジ回帰(Ridge回帰)の正則化項と最尤解の関係をR言語で可視化します。
【数式読解編】
【前節の内容】
【他の節一覧】
【この節の内容】
・リッジ回帰の正則化項と最尤解の関係
「二乗和誤差関数・正則化項」と「重みパラメータの最尤解」との関係をグラフで確認します。L2ノルムについては「【R】3.1.4.0:Lpノルムの作図【PRMLのノート】 - からっぽのしょこ」、リッジ回帰(L2正則化)の実装については「【R】3.1.4.a:リッジ回帰の実装【PRMLのノート】 - からっぽのしょこ」を参照してください。
利用するパッケージを読み込みます。
# 3.1.4項で利用するパッケージ library(tidyverse)
・モデルの設定とデータの生成
データ生成関数と基底関数を作成します。
# 真の関数を指定 y_true <- function(x) { # 計算式を指定 y <- sin(pi * x) return(y) } # 基底関数を指定 Phi <- function(x) { # 計算式を指定 phi_x <- cbind(x, x^2) return(phi_x) }
この例では、多項式基底関数を使います。また、2次元のグラフで可視化するため$M = 2$とし、バイアス$w_0$含めません($\phi_0(x) = 1$としません)。
データを生成して基底関数で変換します。
# データ数を指定 N <- 50 # (観測)データを生成 x_n <- runif(n = N, min = 0, max = 1) # 入力 t_n <- y_true(x_n) + rnorm(n = N, mean = 0, sd = 1) # 出力 # 基底関数により入力を変換 phi_x_nm <- Phi(x_n) # 確認 phi_x_nm[1:5, ]
## x ## [1,] 0.4298318 0.18475540 ## [2,] 0.2780212 0.07729579 ## [3,] 0.2587498 0.06695145 ## [4,] 0.6340887 0.40206845 ## [5,] 0.9521307 0.90655296
$N$個の観測データ(入力値$\mathbf{x} = \{x_1, \cdots, x_N\}$と目標値$\mathbf{t} = \{t_1, \cdots, t_N\}$)を作成して、計画行列
をphi_x_nmとします。また、$\boldsymbol{\phi}(x_n)$は$\boldsymbol{\Phi}$の$n$行目です。
作図用のパラメータの点を作成して、二乗和誤差関数と正則化項を計算します。
# 値を設定:(固定) q <- 2 # パラメータの次元数を設定:(固定) M <- 2 # 作図用のwの範囲を指定 w_i <- seq(-5, 5, by = 0.1) # 作図用のwの点を作成 w_im <- expand.grid(w_i, w_i) %>% as.matrix() # 正則化項を計算 E_df <- tidyr::tibble( w_1 = w_im[, 1], # x軸の値 w_2 = w_im[, 2], # y軸の値 E_D = colSums((t_n - phi_x_nm %*% t(w_im))^2) / N, # 二乗和誤差 E_W = abs(w_1)^q + abs(w_2)^q # 正則化項 ) # 確認 head(E_df)
## # A tibble: 6 x 4 ## w_1 w_2 E_D E_W ## <dbl> <dbl> <dbl> <dbl> ## 1 -5 -5 24.6 50 ## 2 -4.9 -5 24.1 49.0 ## 3 -4.8 -5 23.6 48.0 ## 4 -4.7 -5 23.1 47.1 ## 5 -4.6 -5 22.7 46.2 ## 6 -4.5 -5 22.2 45.2
パラメータの各要素$w_1, w_2$の値を作成してw_iとします。
w_iの全ての組み合わせを持つように点$\mathbf{w} = (w_1, w_2)^{\top}$を作成しw_imとします。w_imの各行は$\mathbf{w}$がとり得る点に対応します。
w_imの行数はw_iの2乗になります。処理が重い場合はw_iを調整してください。
二乗和誤差関数と正則化項(L2ノルムの2乗)を計算します。
二乗和誤差関数とL2正則化項の等高線図を作成します。
# 二乗和誤差関数の等高線図を作成 ggplot(E_df, aes(x = w_1, y = w_2)) + geom_contour_filled(aes(z = E_D, fill = ..level..), alpha = 0.7) + # 二乗和誤差関数:(塗りつぶし) #geom_contour(aes(z = E_D, color = ..level..)) + # 二乗和誤差関数:(等高線) coord_fixed(ratio = 1) + # アスペクト比 labs(title = expression(E[D](w)), subtitle = paste0("q=", q), x = expression(w[1]), y = expression(w[2]), fill = expression(E[D](w))) # 正則化項の等高線図を作成 ggplot(E_df, aes(x = w_1, y = w_2)) + geom_contour_filled(aes(z = E_W, fill = ..level..), alpha = 0.7) + # 正則化項:(塗りつぶし) #geom_contour(aes(z = E_W, color = ..level..)) + # 正則化項:(等高線) coord_fixed(ratio = 1) + # アスペクト比 labs(title = expression(E[W](w)), subtitle = paste0("q=", q), x = expression(w[1]), y = expression(w[2]), fill = expression(E[W](w)))
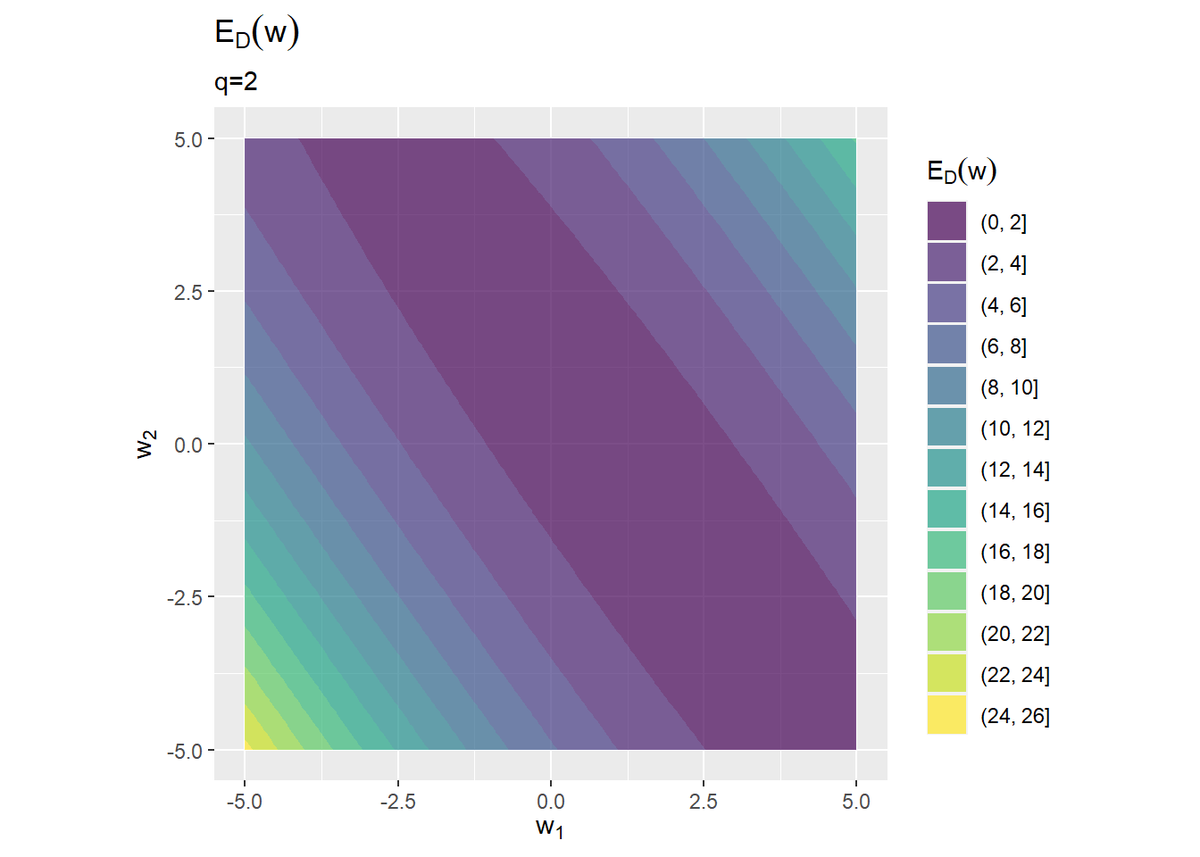
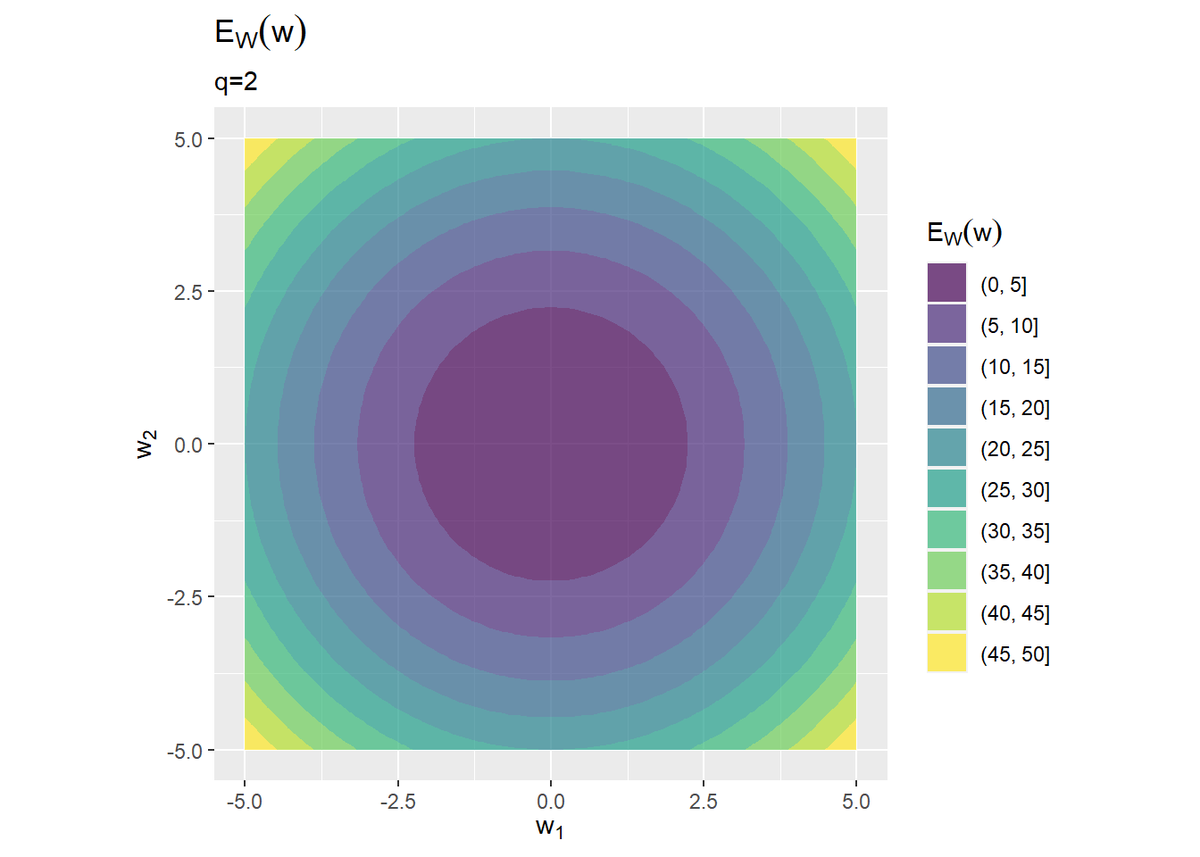
二乗和誤差関数は観測データに依存して形が決まります。
L2正則化項のグラフを真上から見ると円形をしていて、原点$\mathbf{w} = (0, 0)$のとき最小の0になります。
・最尤推定
正則化係数を指定して、重みパラメータの最尤解を計算します。
# 正則化係数を指定 lambda <- 5 # リッジ回帰の重みパラメータの最尤解を計算 w_ridge_m <- solve(lambda * diag(M) + t(phi_x_nm) %*% phi_x_nm) %*% t(phi_x_nm) %*% t_n %>% as.vector()
重みパラメータを計算します。
ただし、$t_n - \mathbf{w}^{\top} \phi(\mathbf{x}_n)$の計算を$N$個同時に行うため、$\mathbf{t} - \boldsymbol{\Phi} \mathbf{w}$で計算しています。
diag()で単位行列を作成できます。
正則化なしの最尤解も計算して、データフレームに格納します。
# 重みパラメータの最尤解を計算 w_ml_m <- solve(t(phi_x_nm) %*% phi_x_nm) %*% t(phi_x_nm) %*% t_n %>% as.vector() # 重みパラメータを格納 w_df <- tidyr::tibble( w_1 = c(w_ridge_m[1], w_ml_m[1]), # x軸の値 w_2 = c(w_ridge_m[2], w_ml_m[2]), # y軸の値 method = factor(c("ridge", "ml"), levels = c(c("ridge", "ml"))) # ラベル ) # 確認 w_df
## # A tibble: 2 x 3 ## w_1 w_2 method ## <dbl> <dbl> <fct> ## 1 0.580 0.230 ridge ## 2 2.01 -1.50 ml
正規化なしの最尤解は次の式で計算します。
重みパラメータの最尤解をプロットします。
# 推定したパラメータによる誤差項を計算 E_D <- sum((t_n - phi_x_nm %*% w_ridge_m)^2) / N E_W <- sum(abs(w_ridge_m)^q) # 最尤解を作図 ggplot() + geom_contour_filled(data = E_df, aes(x = w_1, y = w_2, z = E_D, fill = ..level..), alpha = 0.7) + # 二乗和誤差関数:(塗りつぶし) geom_contour(data = E_df, aes(x = w_1, y = w_2, z = E_D), color = "blue", breaks = E_D) + # 二乗和誤差関数:(等高線) geom_contour(data = E_df, aes(x = w_1, y = w_2, z = E_W), color = "red", breaks = E_W) + # 正則化項:(等高線) geom_point(data = w_df, aes(x = w_1, y = w_2, color = method), shape = 4, size = 5) + # パラメータの最尤解 coord_fixed(ratio = 1) + # アスペクト比 labs(title = "Ridge Regression", subtitle = paste0("lambda=", lambda, ", w_ridge=(", paste0(round(w_ridge_m, 2), collapse = ", "), ")", ", w_ml=(", paste0(round(w_ml_m, 2), collapse = ", "), ")"), x = expression(w[1]), y = expression(w[2]), fill = expression(E[D](w)))
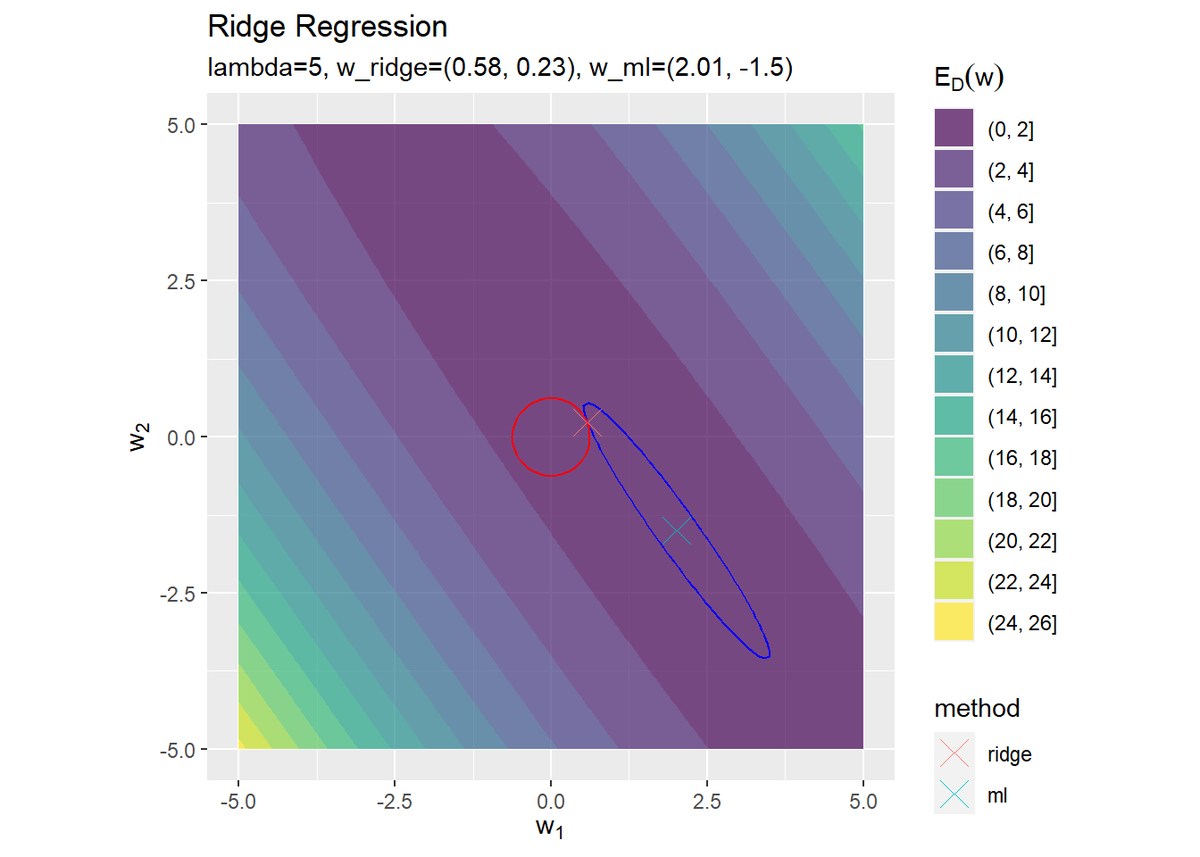
推定した重みパラメータを通る二乗和誤差関数と正則化項の等高線の1本をそれぞれ描画します。この図が、リッジ回帰の説明でよく見る図です(よね?)。
正則化なしの最尤推定で求めた値(青色のバツ印)$\mathbf{w}_{\mathrm{ML}}$は、誤差関数を最小化する値(点)なので、塗りつぶし等高線(青色の等高線)の中心に位置します。
正則化ありの最尤推定で求めた値(赤色のバツ印)$\mathbf{w}_{\mathrm{Ridge}}$は、正則化なしの位置から正則化項の等高線(赤色の等高線)の中心(原点)に近付きます。どれだけ変化するのかは、$\lambda$の大きさに依存します。
また、2つの等高線が接する点であるのも確認できます。
誤差関数の等高線も作図してみます。
# 正則化係数を指定 lambda <- 1 # 誤差関数を作図 ggplot(E_df, aes(x = w_1, y = w_2)) + geom_contour_filled(aes(z = E_D + lambda * E_W, fill = ..level..)) + # 二乗和誤差関数:(塗りつぶし) geom_contour(aes(z = E_D), color = "blue", alpha = 0.5, linetype = "dashed") + # 二乗和誤差関数:(等高線) geom_contour(aes(z = E_W), color = "red", alpha = 0.5, linetype = "dashed") + # 正則化項 coord_fixed(ratio = 1) + # アスペクト比 labs(title = expression(E(w) == E[D](w) + lambda * E[w](w)), subtitle = paste0("q=", q, ", lambda=", lambda), x = expression(w[1]), y = expression(w[2]), fill = expression(E(w)))
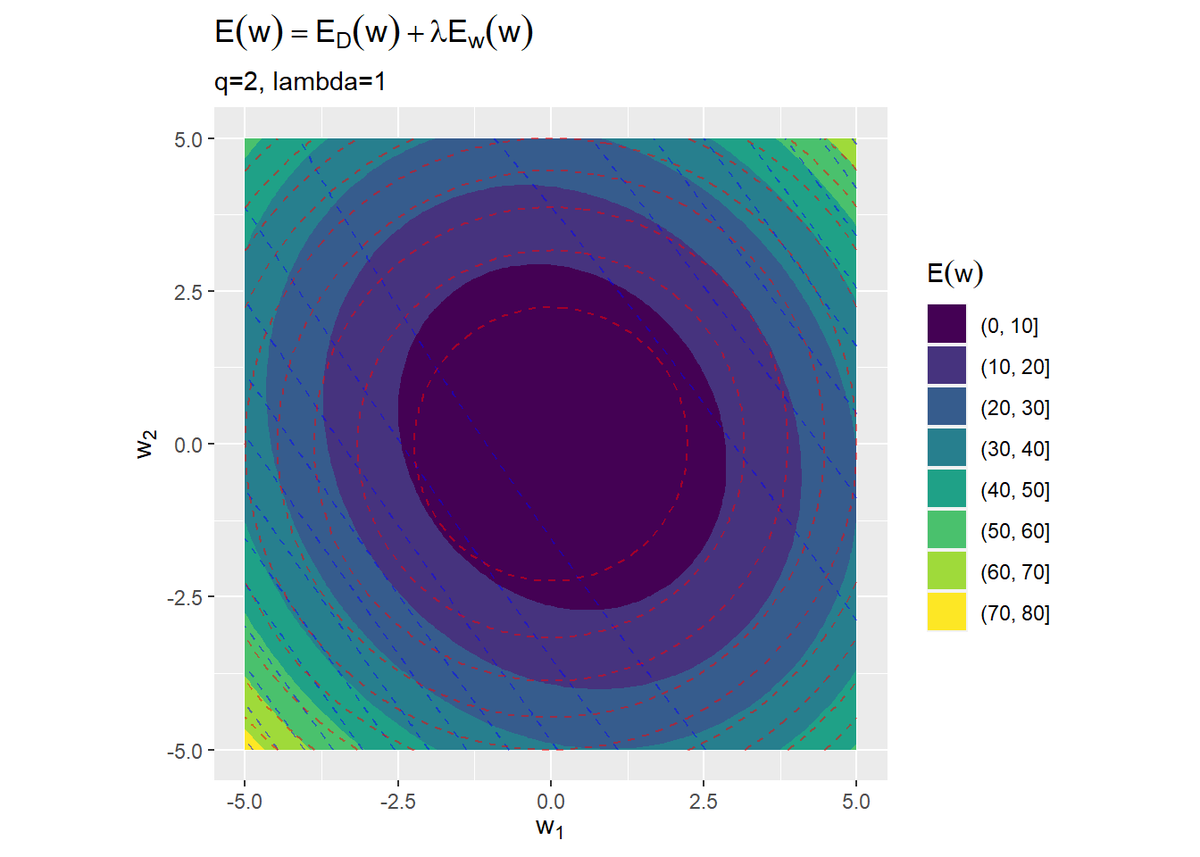
誤差関数は、$E_{\mathrm{Ridge}}(\mathbf{w}) = E_D(\mathbf{w}) + \lambda E_W(\mathbf{w})$で計算します。
2つの破線は、確認用に表示しているだけです。
・おまけ:正則化係数と最尤解の関係
最後に、正則化係数の値と最尤解の関係をアニメーションで確認します。
・作図コード(クリックで展開)
アニメーション(gif画像)の作成にgganimateパッケージを利用します。
# 追加パッケージ library(gganimate)
接線のアニメーション用に細かい$\mathbf{w}$の点を作成します。
# 接線用に細かいwの点を作成 w_vals <- seq(-5, 5, by = 0.005) # 刻み幅を変更 w_point <- expand.grid(w_vals, w_vals) %>% as.matrix() hd_E_df <- tidyr::tibble( w_1 = w_point[, 1], # x軸の値 w_2 = w_point[, 2], # y軸の値 E_D = colSums((t_n - phi_x_nm %*% t(w_point))^2) / N, # 二乗和誤差 E_W = abs(w_1)^q + abs(w_2)^q # 正則化項 )
この例だと、誤差項と正則化項の等高線の接線を描画するのに細かい点が必要です。しかしw_imを細かくすると、塗りつぶし等高線用のデータフレームanime_E_dfの行数が無駄に増えてしまいます。そこで、E_dfとは別にhd_E_dfとして作成しておきます。
for()ループで正則化係数lambdaの値を変更して繰り返しパラメータを計算して、接線となる等高線を計算します。
# 使用するlambdaの値を作成 lambda_vals <- seq(0, 20, by = 0.2) # lambdaごとに最尤解を計算 anime_w_df <- tidyr::tibble() # パラメータの最尤解 anime_E_D_df <- tidyr::tibble() # 誤差項:(接線) anime_E_W_df <- tidyr::tibble() # 正則化項:(接線) anime_E_df <- tidyr::tibble() # 誤差関数 for(lambda in lambda_vals) { # 重みパラメータの最尤解を計算 w_ridge_m <- solve(lambda * diag(M) + t(phi_x_nm) %*% phi_x_nm) %*% t(phi_x_nm) %*% t_n %>% as.vector() # 推定したパラメータによる誤差項を計算 E_D_val <- sum((t_n - phi_x_nm %*% w_ridge_m)^2) / N # 二乗和誤差 E_W_val <- sum(abs(w_ridge_m)^q) # 正則化項 # アニメーション用のラベルを作成 label_txt <- paste0( "lambda=", lambda, ", E=", round(E_D_val + lambda * E_W_val, 2), ", E_D=", round(E_D_val, 2), ", E_W=", round(E_W_val, 2), ", w=(", paste0(round(w_ridge_m, 2), collapse = ", "), ")" ) # 推定したパラメータを格納 tmp_w_df <- tidyr::tibble( w_1 = c(w_ridge_m[1], w_ml_m[1]), # x軸の値 w_2 = c(w_ridge_m[2], w_ml_m[2]), # y軸の値 method = factor(c("ridge", "ml"), levels = c(c("ridge", "ml"))), # ラベル label = as.factor(label_txt) # フレーム切替用のラベル ) # 結果を結合 anime_w_df <- rbind(anime_w_df, tmp_w_df) # 接線となる誤差項の等高線を抽出 anime_E_D_df <- hd_E_df %>% dplyr::select(w_1, w_2, E_D) %>% # dplyr::mutate( E_D = dplyr::if_else( round(E_D, 2) == round(E_D_val, 2), true = round(E_D_val, 2), false = 0 ) ) %>% # 接線となる誤差項の点以外を0に置換 cbind(label = as.factor(label_txt)) %>% # フレーム切替用のラベル列を追加 rbind(anime_E_D_df, .) %>% # 結果を結合 dplyr::filter(E_D > 0) # 接線となる誤差項の点を抽出:(最後でないと接線となる点がなかった時にエラーになる) # 接線となる正則化項の等高線を抽出 anime_E_W_df <- hd_E_df %>% dplyr::select(w_1, w_2, E_W) %>% # 利用する列を抽出 dplyr::mutate( E_W = dplyr::if_else( round(E_W, 2) == round(E_W_val, 2), true = round(E_W_val, 2), false = 0 ) ) %>% # 接線となる正則化項の点以外を0に置換 cbind(label = as.factor(label_txt)) %>% # フレーム切替用のラベル列を追加 rbind(anime_E_W_df, .) %>% # 結合 dplyr::filter(E_W > 0) # 接線となる正則化項の点を抽出:(最後でないと接線となる点がなかった時にエラーになる) # アニメーション用に複製 anime_E_df <- E_df %>% dplyr::mutate(E = E_D + lambda * E_W) %>% # 誤差を計算 #dplyr::select(w_1, w_2, E) %>% # 使用する列を抽出 cbind(label = as.factor(label_txt)) %>% # フレーム切替用のラベル列を追加 rbind(anime_E_df, .) # 結果を結合 # 途中経過を表示 #message("\r", rep(" ", 30), appendLF = FALSE) # 前回のメッセージを初期化 #message("\r", "lambda=", lambda, " (", round(lambda / max(lambda_vals) * 100, 2), "%)", appendLF = FALSE) } # 確認 head(anime_w_df)
## # A tibble: 6 x 4 ## w_1 w_2 method label ## <dbl> <dbl> <fct> <fct> ## 1 2.01 -1.50 ridge lambda=0, E=0.9, E_D=0.9, E_W=6.29, w=(2.01, -1.5) ## 2 2.01 -1.50 ml lambda=0, E=0.9, E_D=0.9, E_W=6.29, w=(2.01, -1.5) ## 3 1.48 -0.782 ridge lambda=0.2, E=1.47, E_D=0.91, E_W=2.81, w=(1.48, -0.78) ## 4 2.01 -1.50 ml lambda=0.2, E=1.47, E_D=0.91, E_W=2.81, w=(1.48, -0.78) ## 5 1.24 -0.456 ridge lambda=0.4, E=1.61, E_D=0.91, E_W=1.75, w=(1.24, -0.46) ## 6 2.01 -1.50 ml lambda=0.4, E=1.61, E_D=0.91, E_W=1.75, w=(1.24, -0.46)
# 確認 head(anime_E_D_df) head(anime_E_W_df) head(anime_E_df)
## w_1 w_2 E_D label ## 1 2.490 -2.215 0.9 lambda=0, E=0.9, E_D=0.9, E_W=6.29, w=(2.01, -1.5) ## 2 2.495 -2.215 0.9 lambda=0, E=0.9, E_D=0.9, E_W=6.29, w=(2.01, -1.5) ## 3 2.500 -2.215 0.9 lambda=0, E=0.9, E_D=0.9, E_W=6.29, w=(2.01, -1.5) ## 4 2.505 -2.215 0.9 lambda=0, E=0.9, E_D=0.9, E_W=6.29, w=(2.01, -1.5) ## 5 2.510 -2.215 0.9 lambda=0, E=0.9, E_D=0.9, E_W=6.29, w=(2.01, -1.5) ## 6 2.515 -2.215 0.9 lambda=0, E=0.9, E_D=0.9, E_W=6.29, w=(2.01, -1.5) ## w_1 w_2 E_W label ## 1 -0.140 -2.505 6.29 lambda=0, E=0.9, E_D=0.9, E_W=6.29, w=(2.01, -1.5) ## 2 -0.135 -2.505 6.29 lambda=0, E=0.9, E_D=0.9, E_W=6.29, w=(2.01, -1.5) ## 3 -0.130 -2.505 6.29 lambda=0, E=0.9, E_D=0.9, E_W=6.29, w=(2.01, -1.5) ## 4 -0.125 -2.505 6.29 lambda=0, E=0.9, E_D=0.9, E_W=6.29, w=(2.01, -1.5) ## 5 -0.120 -2.505 6.29 lambda=0, E=0.9, E_D=0.9, E_W=6.29, w=(2.01, -1.5) ## 6 -0.115 -2.505 6.29 lambda=0, E=0.9, E_D=0.9, E_W=6.29, w=(2.01, -1.5) ## w_1 w_2 E_D E_W E ## 1 -5.0 -5 24.60832 50.00 24.60832 ## 2 -4.9 -5 24.11181 49.01 24.11181 ## 3 -4.8 -5 23.62057 48.04 23.62057 ## 4 -4.7 -5 23.13462 47.09 23.13462 ## 5 -4.6 -5 22.65394 46.16 22.65394 ## 6 -4.5 -5 22.17855 45.25 22.17855 ## label ## 1 lambda=0, E=0.9, E_D=0.9, E_W=6.29, w=(2.01, -1.5) ## 2 lambda=0, E=0.9, E_D=0.9, E_W=6.29, w=(2.01, -1.5) ## 3 lambda=0, E=0.9, E_D=0.9, E_W=6.29, w=(2.01, -1.5) ## 4 lambda=0, E=0.9, E_D=0.9, E_W=6.29, w=(2.01, -1.5) ## 5 lambda=0, E=0.9, E_D=0.9, E_W=6.29, w=(2.01, -1.5) ## 6 lambda=0, E=0.9, E_D=0.9, E_W=6.29, w=(2.01, -1.5)
$\lambda$として使う値lambda_valsを作成します。
lambda_valsから値を順番に取り出して、パラメータの最尤解を計算します。計算結果はanime_lasso_dfに追加していきます。
また誤差関数のデータフレームについても、同じ試行(フレーム)のlabel列を持つように複製しておく必要があります。
作図してgif画像として出力します。
# 誤差項と最尤解の関係を作図 anime_graph <- ggplot() + geom_contour_filled(data = anime_E_df, aes(x = w_1, y = w_2, z = E_D, fill = ..level..), alpha = 0.7) + # 誤差項:(塗りつぶし等高線) geom_contour(data = E_df, aes(x = w_1, y = w_2, z = E_W), color = "red", linetype = "dashed", breaks = seq(1, 3, by = 1)) + # 正則化項:(等高線) geom_point(data = anime_E_D_df, aes(x = w_1, y = w_2), color = "blue", shape = ".", size = 0.1) + # 誤差項:(接線) geom_point(data = anime_E_W_df, aes(x = w_1, y = w_2), color = "red", shape = ".", size = 0.1) + # 正則化項:(接線) geom_point(data = anime_w_df, aes(x = w_1, y = w_2, color = method), shape = 4, size = 5) + # パラメータの最尤解 gganimate::transition_manual(label) + # フレーム coord_fixed(ratio = 1) + # アスペクト比 labs(title = "Ridge Regression", subtitle = "{current_frame}", x = expression(w[1]), y = expression(w[2]), fill = expression(E[D](w))) # gif画像に変換 gganimate::animate(anime_graph, nframes = length(lambda_vals), fps = 10)
# 誤差関数と最尤解の関係を作図 anime_graph <- ggplot() + geom_contour_filled(data = anime_E_df, aes(x = w_1, y = w_2, z = E, fill = ..level..), alpha = 0.7) + # 誤差関数:(塗りつぶし等高線) geom_contour(data = E_df, aes(x = w_1, y = w_2, z = E_D), color = "blue", linetype = "dashed", breaks = seq(1, 10, length.out = 3)) + # 誤差項:(等高線) geom_contour(data = E_df, aes(x = w_1, y = w_2, z = E_W), color = "red", linetype = "dashed", breaks = seq(1, 3, by = 1)) + # 正則化項:(等高線) geom_point(data = anime_E_D_df, aes(x = w_1, y = w_2), color = "blue", shape = ".", size = 0.1) + # 誤差項:(接線) geom_point(data = anime_E_W_df, aes(x = w_1, y = w_2), color = "red", shape = ".", size = 0.1) + # 正則化項:(接線) geom_point(data = anime_w_df, aes(x = w_1, y = w_2, color = method), shape = 4, size = 5) + # パラメータの最尤解 gganimate::transition_manual(label) + # フレーム coord_fixed(ratio = 1) + # アスペクト比 labs(title = "Ridge Regression", subtitle = "{current_frame}", x = expression(w[1]), y = expression(w[2]), fill = expression(E[D](w))) # gif画像に変換 gganimate::animate(anime_graph, nframes = length(lambda_vals), fps = 10)
接線(等高線の一本)だけをgeom_contour()で引くのは非効率なので、散布図geom_point()で線に見えるように引くことにします。
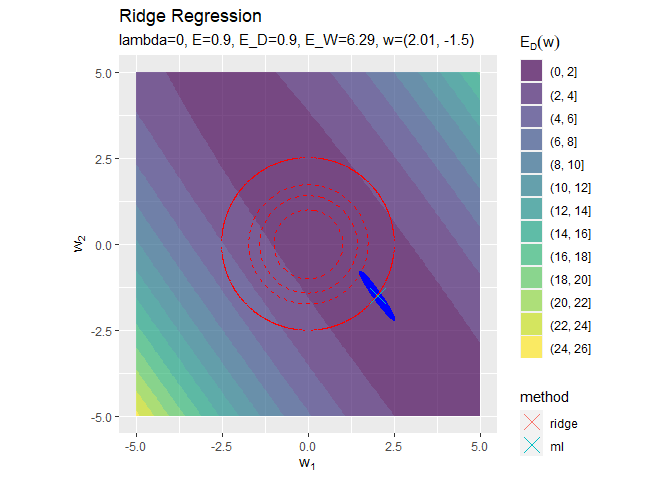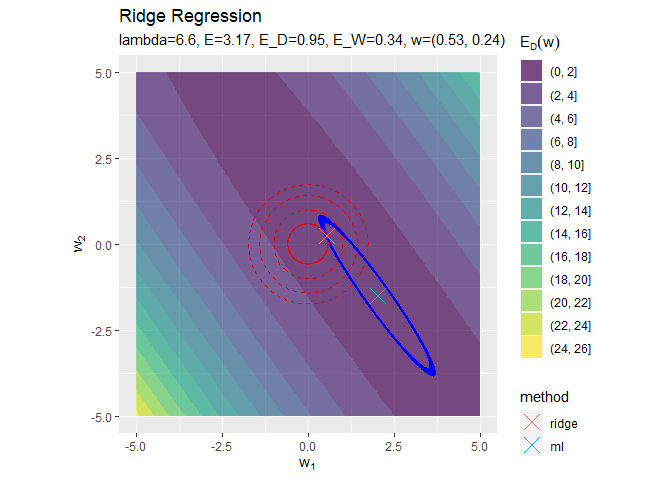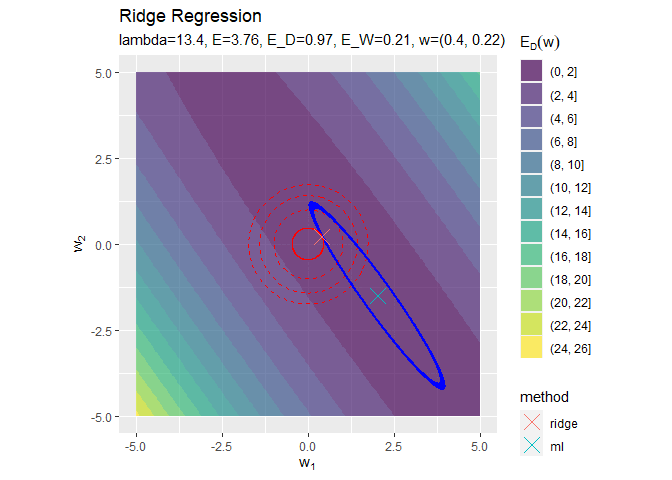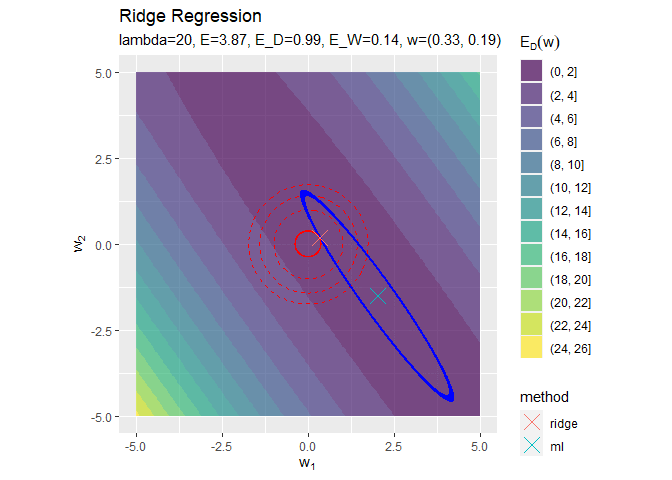
正則化係数が大きくなるほど「二乗和誤差関数が最小となる点(青色のバツ印)」から「正則化項の最小値となる点(赤色の円の中心)」に移動しているのを確認できます。
円の中心(原点)に近付いていくことから、パラメータの値が小さくなっていくのが分かります。
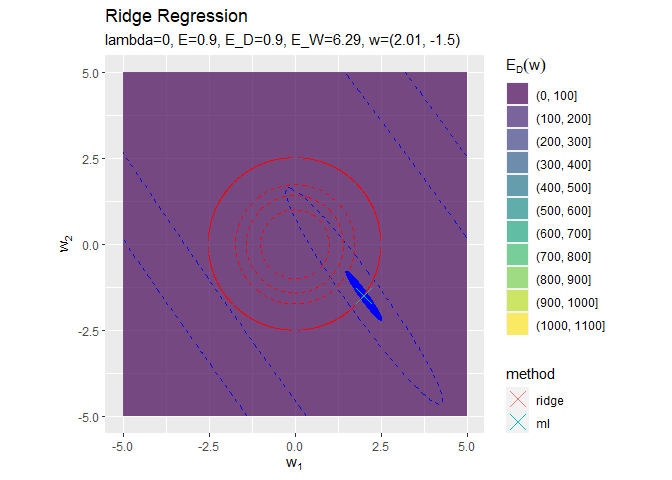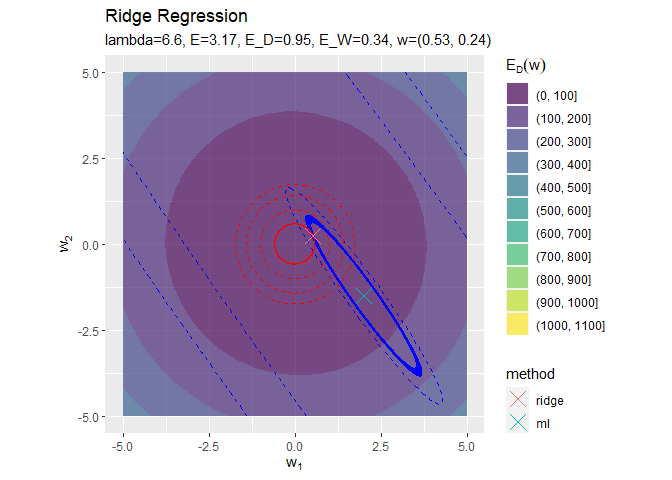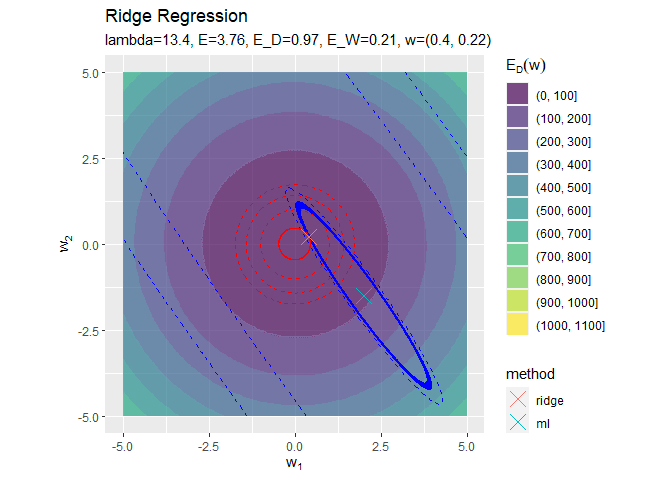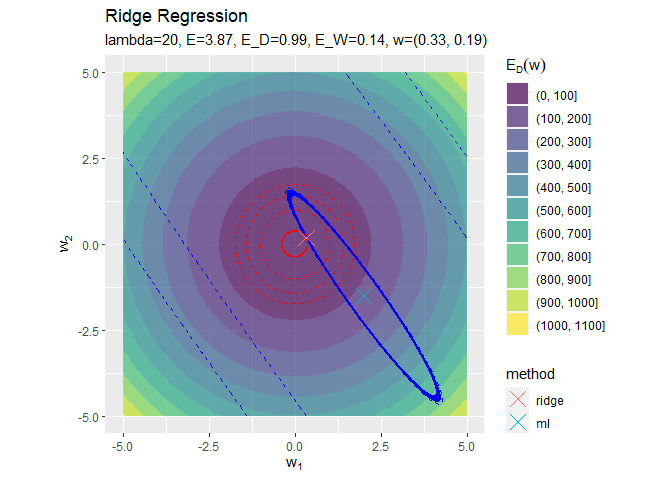
正則化係数が大きくなるほど誤差関数に対する正則化項の影響が強くなっているのを確認できます。
参考文献
- C.M.ビショップ著,元田 浩・他訳『パターン認識と機械学習 上下』,丸善出版,2012年.
おわりに
- 2021.12.21:追記した際に記事を分割しました。
【次節の内容】
【関連する内容】