はじめに
『パターン認識と機械学習』の独学時のまとめです。一連の記事は「数式の行間埋め」または「R・Pythonでのスクラッチ実装」からアルゴリズムの理解を補助することを目的としています。本とあわせて読んでください。
この記事は、3.1.4項「正則化最小二乗法」の内容です。リッジ回帰(Ridge回帰)の最尤推定をR言語で実装します。
【数理読解編】
【前節の内容】
【他の節一覧】
【この節の内容】
・リッジ回帰の実装
リッジ回帰(L2正則化)を実装します。線形基底関数モデルについては「【R】3.1.1:線形基底関数モデルの実装【PRMLのノート】 - からっぽのしょこ」を参照してください。
この記事では、リッジ回帰により観測データから真のモデルを推定(近似)します。
利用するパッケージを読み込みます。
# 3.1.4項で利用するパッケージ library(tidyverse)
・モデルの設定とデータの生成
データを生成する関数を設定して、利用するデータを人工的に生成します。処理の流れは3.1.1項と同じなので、詳しくはそちらを参照してください。
データ生成関数(推定対象の関数)と基底関数を作成します。
# 真の関数を作成 y_true <- function(x) { # 計算式を指定 y <- sin(2 * pi * x) return(y) } # 多項式基底関数を作成 phi_poly <- function(x, m) { # m乗を計算 y <- x^m return(y) } # 計画行列を作成 Phi <- function(x_n, M) { # 変数を初期化 x_nm <- matrix(0, nrow = length(x_n), ncol = M) # m列目を計算 for(m in 0:(M-1)) { x_nm[, m+1] <- phi_poly(x_n, m) } return(x_nm) }
この例では、多項式基底関数を使います。ガウス基底関数やシグモイド基底関数を使う場合は3.1.1項を参照してください。
真のモデルの精度パラメータを指定して出力を計算します。
# データの範囲を指定 x_min <- 0 x_max <- 1 # 作図用のxの値を作成 x_vals <- seq(x_min, x_max, by = 0.01) # 真の精度パラメータを指定 beta_true <- 3 sigma_true <- sqrt(1 / beta_true) # 真の標準偏差 # 真のモデルを計算 model_df <- tidyr::tibble( x = x_vals, # x軸の値 y = y_true(x_vals), # y軸の値 minus_sigma = y - 2 * sigma_true, # μ - 2σ plus_sigma = y + 2 * sigma_true # μ + 2σ )
設定したモデルに従って、データを生成します。
# データ数を指定 N <- 100 # (観測)データを生成 x_n <- runif(n = N, min = x_min, max = x_max) # 入力 t_n <- y_true(x_n) + rnorm(n = N, mean = 0, sd = sigma_true) # 出力 # 観測データをデータフレームに格納 data_df <- tidyr::tibble( x_n = x_n, # 入力 t_n = t_n # 出力 )
$N$個の観測データ(入力値$\mathbf{x} = \{x_1, \cdots, x_N\}$と目標値$\mathbf{t} = \{t_1, \cdots, t_N\}$)を作成できました。
・最尤推定
正則化しない場合と正則化する場合の最尤推定を行いパラメータ$\mathbf{w} = (w_0, w_1, \cdots, w_{M-1})^{\top}$を求めて、結果を比較します。
パラメータの数(数基底関数の数)$M$を指定して、入力値を基底関数により変換します。
# 重みパラメータの次元数(基底関数の数)を指定 M <- 6 # 基底関数により入力を変換 phi_x_nm <- Phi(x_n, M)
計画行列
をphi_x_nmとします。また、$\boldsymbol{\phi}(x_n)$は$\boldsymbol{\Phi}$の$n$行目です。
・正則化しない場合
まずは、正則化を行わない場合の重みパラメータと分散パラメータの最尤解を計算します。
# 重みパラメータの最尤解を計算 w_ml_m <- solve(t(phi_x_nm) %*% phi_x_nm) %*% t(phi_x_nm) %*% t_n %>% as.vector() # 分散パラメータの最尤解を計算 sigma2_ml <- sum((t_n - phi_x_nm %*% w_ml_m)^2) / N # 精度パラメータの最尤解を計算 beta_ml <- 1 / sigma2_ml # 確認 w_ml_m beta_ml
## [1] 0.07435094 2.49476598 23.49882292 -113.08672718 137.94215416 ## [6] -50.62912633 ## [1] 3.153926
重みパラメータ、分散パラメータ、精度パラメータをそれぞれ次の式で計算します。
ただし、$t_n - \mathbf{w}^{\top} \phi(\mathbf{x}_n)$の計算を$N$個同時に行うため、$\mathbf{t} - \boldsymbol{\Phi} \mathbf{w}$で計算しています。
推定した線形回帰のパラメータを使って回帰曲線を計算します。
# 推定したパラメータによるモデルを計算 ml_df <- tidyr::tibble( x = x_vals, # x軸の値 t = Phi(x_vals, M) %*% w_ml_m %>% as.vector(), # y軸の値 minus_sigma = t - 2 * sqrt(sigma2_ml), # μ - 2σ plus_sigma = t + 2 * sqrt(sigma2_ml) # μ + 2σ ) # 確認 head(ml_df)
## # A tibble: 6 x 4 ## x t minus_sigma plus_sigma ## <dbl> <dbl> <dbl> <dbl> ## 1 0 0.0744 -1.05 1.20 ## 2 0.01 0.102 -1.02 1.23 ## 3 0.02 0.133 -0.993 1.26 ## 4 0.03 0.167 -0.959 1.29 ## 5 0.04 0.205 -0.921 1.33 ## 6 0.05 0.245 -0.882 1.37
未知の入力値(x軸の値)$x_{*}$に対する予測値(y軸の値)$t_{*}$を次の式で計算します。
さらに、分散パラメータsigma2_mlを使って、推定した精度を求めます。
ここまでは、3.1.1項と同様の処理です。
・正則化する場合
続いて、正則化を行う場合の重みパラメータと分散パラメータの最尤解を計算します。
# 正則化係数を指定 lambda <- 0.5 # リッジ回帰の重みパラメータの最尤解を計算 w_ridge_m <- solve(lambda * diag(M) + t(phi_x_nm) %*% phi_x_nm) %*% t(phi_x_nm) %*% t_n %>% as.vector() # リッジ回帰の分散パラメータの最尤解を計算 sigma2_ridge <- sum((t_n - phi_x_nm %*% w_ridge_m)^2) / N # リッジ回帰の精度パラメータの最尤解を計算 beta_ridge <- 1 / sigma2_ridge # 確認 w_ridge_m beta_ridge
## [1] 0.7343945 -0.5998903 -1.7423368 -0.7757288 0.4985178 1.5943355 ## [1] 2.235324
重みパラメータ、分散パラメータ、精度パラメータをそれぞれ次の式で計算します。
こちらも、$N$個同時に計算(処理)します。
diag()で単位行列を作成できます。
推定したリッジ回帰のパラメータを使って回帰曲線を計算します。
# 推定したパラメータによるモデルを計算 ridge_df <- tidyr::tibble( x = x_vals, # x軸の値 t = Phi(x_vals, M) %*% w_ridge_m %>% as.vector(), # y軸の値 minus_sigma = t - 2 * sqrt(sigma2_ridge), # μ - 2σ plus_sigma = t + 2 * sqrt(sigma2_ridge) # μ + 2σ ) # 確認 head(ridge_df)
## # A tibble: 6 x 4 ## x t minus_sigma plus_sigma ## <dbl> <dbl> <dbl> <dbl> ## 1 0 0.734 -0.603 2.07 ## 2 0.01 0.728 -0.609 2.07 ## 3 0.02 0.722 -0.616 2.06 ## 4 0.03 0.715 -0.623 2.05 ## 5 0.04 0.708 -0.630 2.05 ## 6 0.05 0.700 -0.638 2.04
先ほどと同様に、y軸の値を計算します。
以上がリッジ回帰の推定処理です。推定したパラメータの各要素の値が小さくなっているのを確認できます。
・推定結果の確認
リッジ回帰により推定した回帰曲線(近似曲線)を作図します。
# 推定したパラメータによるモデルを作図 ggplot() + geom_point(data = data_df, aes(x = x_n, y = t_n)) + # 観測データ geom_line(data = model_df, aes(x = x, y = y), color = "cyan4") + # 真のモデル geom_ribbon(data = model_df, aes(x = x, ymin = minus_sigma, ymax = plus_sigma), fill = "cyan4", alpha = 0.1, color = "cyan4", linetype = "dotted") + # 真のノイズ範囲 geom_line(data = ml_df, aes(x = x, y = t), color = "blue", linetype ="dashed") + # 推定したモデル:(正則化なし) geom_line(data = ridge_df, aes(x = x, y = t), color = "blue") + # 推定したモデル:(L2正則化) geom_ribbon(data = ridge_df, aes(x = x, ymin = minus_sigma, ymax = plus_sigma), fill = "blue", alpha = 0.1, color = "blue", linetype = "dotted") + # 推定したノイズ範囲 #ylim(c(-5, 5)) + # y軸の表示範囲 labs(title = "Ridge Regression", subtitle = paste0("N=", N, ", M=", M, ", q=", 2, ", lambda=", lambda, ", w=(", paste0(round(w_ridge_m, 2), collapse = ", "), ")", ", beta=", round(beta_ridge, 2)), x = "x", y = "t")

緑の実線が真のモデル、青の実線がリッジ回帰(L2正則化)による近似曲線、青の破線が正則化なしの近似曲線です。
この例だと、正則化しない方がうまく近似できていますね。
$\lambda$の値が大きいほど、正則化の効果が強まります。
正則化の効果を見るために、観測データ数を減らしパラメータ数を増やして、過学習が起きやすい設定にしてみます。

正則化していない方(青の破線)はデータに過剰に適合しているのが分かります。正則化している方(青の実線)は過剰適合を回避できています。
以上でリッジ回帰を実装できました。
・おまけ:正則化係数と回帰曲線の関係
最後に、正則化係数と回帰曲線(近似曲線)の関係をアニメーションで確認します。
・作図コード(クリックで展開)
アニメーション(gif画像)の作成にgganimateパッケージを利用します。
# 追加パッケージ library(gganimate)
for()ループで正則化係数$\lambda$の値を変更しながら繰り返しパラメータと回帰曲線を計算します。
# 使用するlambdaの値を作成 lambda_vec <- seq(0, 0.05, by = 0.001) # lambdaごとに最尤解を計算 anime_ridge_df <- dplyr::tibble() for(lambda in lambda_vec) { # 重みパラメータの最尤解を計算 w_ridge_m <- solve(lambda * diag(M) + t(phi_x_nm) %*% phi_x_nm) %*% t(phi_x_nm) %*% t_n %>% as.vector() # 分散パラメータの最尤解を計算 sigma2_ridge <- sum((t_n - t(w_ridge_m) %*% t(phi_x_nm))^2) / N # 精度パラメータの最尤解を計算 beta_ridge <- 1 / sigma2_ridge # 推定したパラメータによるモデルを計算 tmp_ridge_df <- tidyr::tibble( x = x_vals, # x軸の値 t = Phi(x_vals, M) %*% w_ridge_m %>% as.vector(), # y軸の値 minus_sigma = t - 2 * sqrt(sigma2_ridge), # μ - 2σ plus_sigma = t + 2 * sqrt(sigma2_ridge), # μ + 2σ label = paste0( "lambda=", lambda, ", w=(", paste0(round(w_ridge_m, 2), collapse = ", "), ")", ", beta=", round(beta_ridge, 2) ) %>% as.factor() # フレーム切替用のラベル ) # 結果を結合 anime_ridge_df <- rbind(anime_ridge_df, tmp_ridge_df) } # 確認 head(anime_ridge_df)
## # A tibble: 6 x 5 ## x t minus_sigma plus_sigma label ## <dbl> <dbl> <dbl> <dbl> <fct> ## 1 0 -12.2 -13.1 -11.2 lambda=0, w=(-12.18, 589.6, -9177.01, 67~ ## 2 0.01 -7.14 -8.10 -6.18 lambda=0, w=(-12.18, 589.6, -9177.01, 67~ ## 3 0.02 -3.56 -4.52 -2.60 lambda=0, w=(-12.18, 589.6, -9177.01, 67~ ## 4 0.03 -1.13 -2.09 -0.172 lambda=0, w=(-12.18, 589.6, -9177.01, 67~ ## 5 0.04 0.411 -0.549 1.37 lambda=0, w=(-12.18, 589.6, -9177.01, 67~ ## 6 0.05 1.29 0.329 2.25 lambda=0, w=(-12.18, 589.6, -9177.01, 67~
$\lambda$として使う値を作成してlambda_valsとします。
lambda_valsから値を順番に取り出して、パラメータの最尤解を求めて回帰曲線を計算します。計算結果はanime_ridge_dfに追加していきます。
作図してgif画像として出力します。
# 推定したパラメータによるモデルを作図 anime_graph <- ggplot() + geom_point(data = data_df, aes(x = x_n, y = t_n)) + # 観測データ geom_line(data = model_df, aes(x = x, y = y), color = "cyan4") + # 真のモデル geom_ribbon(data = model_df, aes(x = x, ymin = minus_sigma, ymax = plus_sigma), fill = "cyan4", alpha = 0.1, color = "cyan4", linetype = "dotted") + # 真のノイズ範囲 geom_line(data = ml_df, aes(x = x, y = t), color = "blue", linetype ="dashed") + # 推定したモデル:(正則化なし) geom_line(data = anime_ridge_df, aes(x = x, y = t), color = "blue") + # 推定したモデル:(L2正則化) geom_ribbon(data = anime_ridge_df, aes(x = x, ymin = minus_sigma, ymax = plus_sigma), fill = "blue", alpha = 0.1, color = "blue", linetype = "dotted") + # 推定したノイズ範囲 gganimate::transition_manual(label) + # フレーム ylim(c(-4, 4)) + # y軸の表示範囲 labs(title = "Ridge Regression", subtitle = "{current_frame}", x = "x", y = "t") # gif画像に変換 gganimate::animate(anime_graph, nframes = length(lambda_vec), fps = 10)
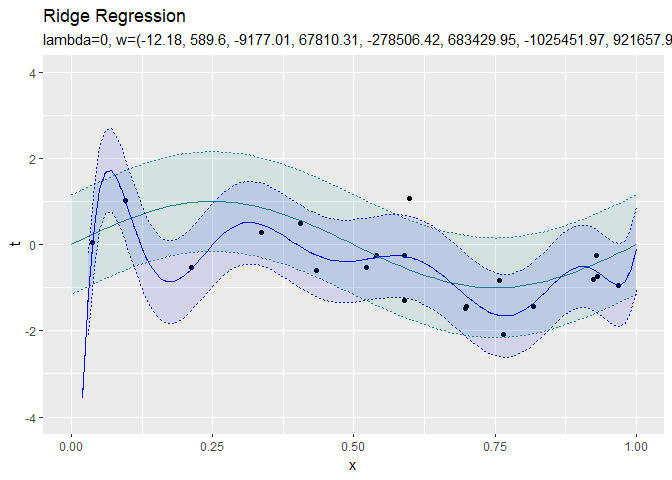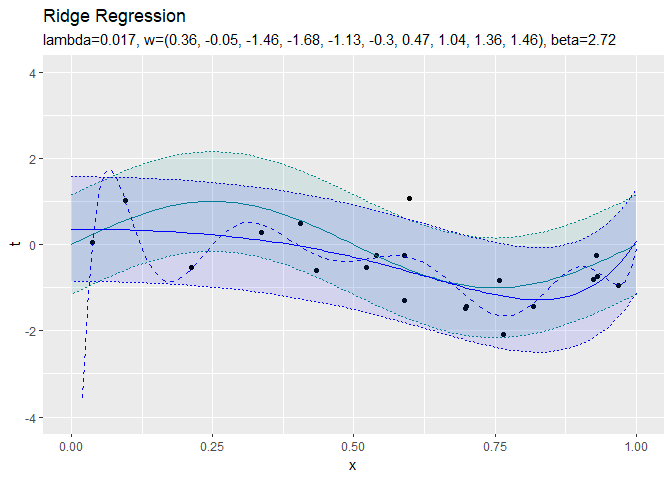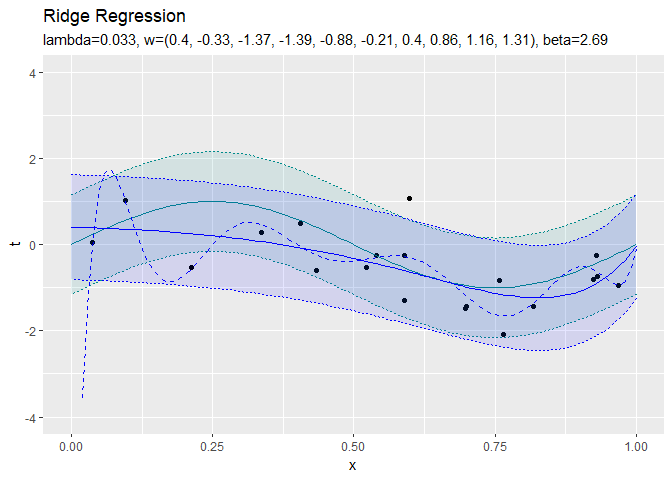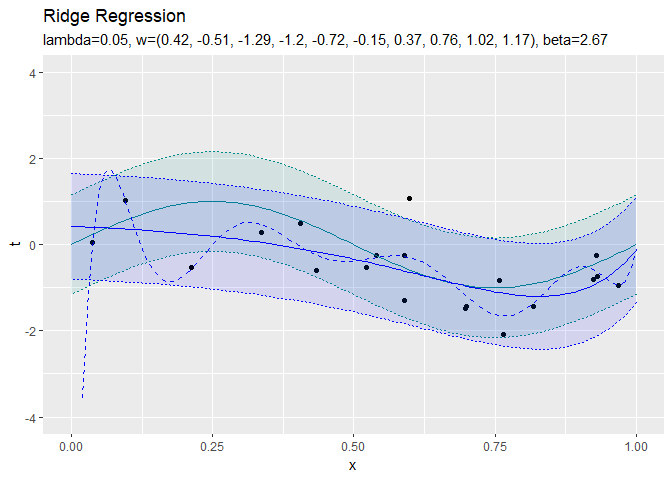
正則化係数が大きくなるほど、パラメータの値が小さくなっていき、回帰曲線がシンプルになっていくことから、正則化の効果が強まるのを確認できます。
$\lambda = 0$のとき正則化しない最尤解と一致しているのが分かります。
参考文献
- C.M.ビショップ著,元田 浩・他訳『パターン認識と機械学習 上下』,丸善出版,2012年.
おわりに
こっちは問題なくできた問題はラッソ回帰...
先ほど配信されたモーニング娘。'21の新曲MVをどうぞ!
してほしーい🔫
- 2021.12.21:追記して記事を分割しました。
【次節の内容】
【関連する内容】