はじめに
『パターン認識と機械学習』の独学時のまとめです。一連の記事は「数式の行間埋め」または「R・Pythonでの実装」からアルゴリズムの理解を補助することを目的としています。本とあわせて読んでください。
この記事は、10.1.3項の内容です。平均と精度が未知の1次元ガウス分布(正規分布)に対する変分推論(変分ベイズ)をPythonで実装します。
【数式読解編】
【他の節一覧】
【この節の内容】
Pythonで実装
人工データを用いて、EMアルゴリズムによる最尤推定を行ってみましょう。
利用するライブラリを読み込みます。
# 10.1.3項で利用するライブラリ import numpy as np from scipy.stats import norm, gamma # 1次元ガウス分布, ガンマ分布 import matplotlib.pyplot as plt
scipyライブラリのstatsから、1次元ガウス分布normとガンマ分布gammaのクラスを利用します。確率密度の計算にpdf()を使います。
・真の分布の設定
まずは、真の分布を設定します。この項では、真の分布を平均$\mu$、精度$\tau$の1次元ガウス分布$\mathcal{N}(x | \mu, \tau^{-1})$とします。
真の分布のパラメータを設定します。
# 真の平均パラメータを指定 mu_truth = 5.0 # 真の精度パラメータを指定 tau_truth = 0.5
真の平均パラメータ$\mu$をmu_truthとして値を指定します。
真の精度パラメータ$\tau$をtau_truthとして0より大きい値$\tau > 0$を指定します。精度は分散の逆数$\sigma^2 = \frac{1}{\tau}$です。値が大きいほど、散らばり具合が小さくなります。
この例では、この2つのパラメータの値を分布推定するのが目的です。
真の分布をグラフで確認しましょう。作図用の点を作成します。
# 作図用のxの値を作成 x_line = np.linspace( mu_truth - 4.0 * np.sqrt(1.0 / tau_truth), mu_truth + 4.0 * np.sqrt(1.0 / tau_truth), num=1000 )
作図用に、ガウス分布に従う変数$x$がとり得る値をnp.linspace()で作成してx_lineとします。この例では、平均値を中心に標準偏差の4倍を範囲とします。np.linspace()を使うと指定した要素数で等間隔に切り分けます。np.arange()を使うと切り分ける間隔を指定できます。処理が重い場合は、この値を調整してください。
作成した配列は次のようになります。
# 確認 print(x_line[:10])
[-0.65685425 -0.64552922 -0.63420418 -0.62287915 -0.61155412 -0.60022908
-0.58890405 -0.57757901 -0.56625398 -0.55492895]
真の分布を計算します。
# 真の分布を計算 model_dens = norm.pdf(x=x_line, loc=mu_truth, scale=np.sqrt(1.0 / tau_truth))
x_lineの値ごとに確率密度を計算します。1次元ガウス分布の確率密度は、norm.pdf()で計算できます。値の引数xにx_line、平均の引数lecにmu_truth、標準偏差の引数scaleにtauの逆数の平方根np.sqrt(1.0 / tau_truth)を指定します。精度$\tau$は分散の逆数なので、その平方根が真の標準偏差$\sigma = \sqrt{\frac{1}{\tau}}$になります。
作成した配列は次のようになります。
# 確認 print(model_dens[:10])
[9.46322602e-05 9.77094621e-05 1.00880257e-04 1.04147270e-04
1.07513190e-04 1.10980775e-04 1.14552854e-04 1.18232322e-04
1.22022150e-04 1.25925383e-04]
真の分布を作図します。
# 真の分布を作図 plt.figure(figsize=(12, 9)) plt.plot(x_line, model_dens, label='true model') # 真の分布 plt.xlabel('x') plt.ylabel('density') plt.suptitle('Gaussian Distribution', fontsize=20) plt.title('$\mu=' + str(mu_truth) + ', \\tau=' + str(tau_truth) + '$', loc='left') plt.legend() # 凡例 plt.grid() # グリッド線 plt.show()
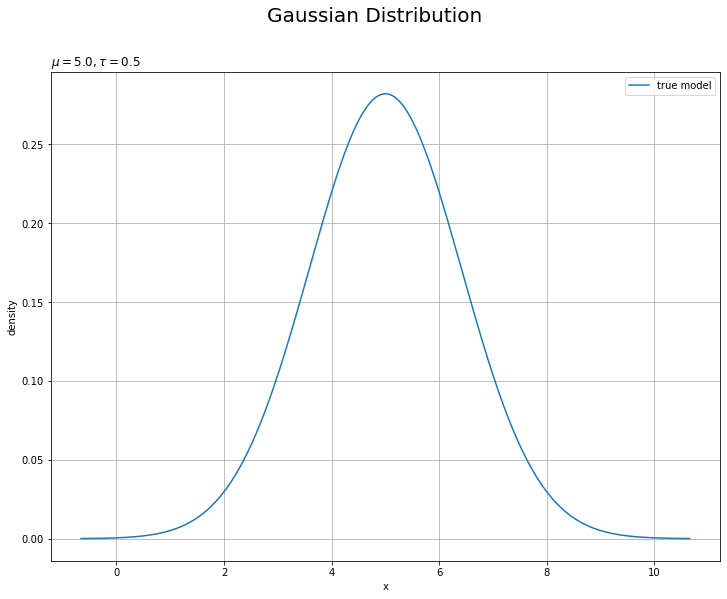
・観測データの生成
続いて、設定した真の分布に従って観測データ$\mathcal{D} = \{x_1, x_2, \cdots, x_N\}$を生成します。
ガウス分布に従う$N$個のデータをランダムに生成します。
# (観測)データ数を指定 N = 50 # ガウス分布に従うデータを生成 x_n = np.random.normal(loc=mu_truth, scale=np.sqrt(1 / tau_truth), size=N)
生成するデータ数$N$をNとして値を指定します。
ガウス分布に従う乱数は、np.random.normal()で生成できます。データ数の引数sizeにNを指定します。他の引数についてはnorm.pdf()と同じです。生成したN個のデータをx_nとします。
観測したデータをグラフで確認しましょう。観測データのヒストグラムを作成します。
# 観測データのヒストグラムを作図 plt.figure(figsize=(12, 9)) plt.hist(x=x_n, bins=50, label='data') # 観測データ:(度数) #plt.hist(x=x_n, density=True, bins=50, label='data') # 観測データ:(相対度数) #plt.plot(x_line, model_dens, color='red', linestyle='--', label='true model') # 真の分布:(相対度数用) plt.xlabel('x') plt.ylabel('count') # (度数用) #plt.ylabel('density') # (相対度数用) plt.suptitle('Gaussian Distribution', fontsize=20) plt.title('$N=' + str(N) + ', \mu=' + str(mu_truth) + ', \\tau=' + str(tau_truth) + '$', loc='left') plt.legend() # 凡例 plt.grid() # グリッド線 plt.show()

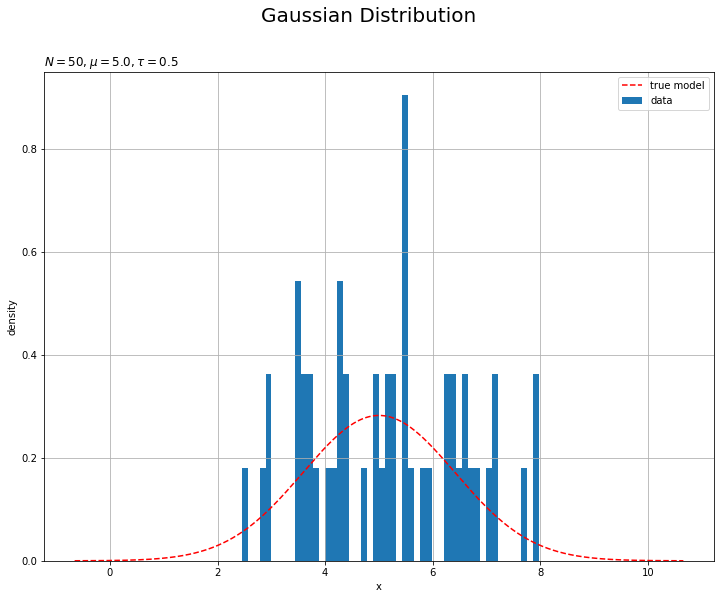
左の図のy軸はデータ数です。右の図のy軸は相対度数です。カウントする間隔はbinsによって調整されます。density=Trueを指定すると相対度数のヒストグラムになります。
・事前分布の設定
次に、尤度に対する共役事前分布を設定します。1次元ガウス分布の平均・精度パラメータ$\mu,\ \tau$の同時事前分布$p(\mu, \tau)$として、ガウス-ガンマ分布$\mathrm{NG}(\mu, \tau | \mu_0, \lambda_0, a_0, b_0)$を設定します。
$\mu$と$\tau$の事前分布のパラメータ(超パラメータ)を指定します。
# muの事前分布のパラメータを指定 mu_0 = 0.0 lambda_0 = 0.1 # tauの事前分布のパラメータを指定 a_0 = 1.0 b_0 = 1.0
$\mu$の事前分布$\mathcal{N}(\mu | \mu_0, (\lambda_0 \tau)^{-1})$の平均パラメータ$\mu_0$と精度パラメータの係数$\lambda_0$をそれぞれmu_0, lambda_0として$\lambda_0 > 0$の値を指定します。
$\tau$の事前分布$\mathrm{Gam}(\tau | a_0, b_0)$のパラメータ$a_0,\ b_0$をa_0, b_0として$a_0 > 0,\ b_0 > 0$の値を指定します。
$\mu,\ \tau$の事前分布をグラフで確認しましょう。作図用の点を作成します。
# 作図用のmuの値を作成 mu_line = np.linspace( mu_truth - 4.0 * np.sqrt(1.0 / tau_truth), mu_truth + 4.0 * np.sqrt(1.0 / tau_truth), num=500 ) # 作図用のtauの値を作成 tau_line = np.linspace(0.0, 4 * tau_truth, num=500)
1次元ガウス分布に従う変数$\mu$がとり得る値を作成してmu_lineとします。この例では、真の平均値を中心に真の標準偏差の4倍を範囲とします。
ガンマ分布に従う変数$\tau$がとり得る値を作成してtau_lineとします。この例では、0から真の精度の4倍を範囲とします。
格子状の点を作成します。
# 格子状の点を作成 mu_grid, tau_grid = np.meshgrid(mu_line, tau_line) point_dims = mu_grid.shape print(point_dims)
(500, 500)
np.meshgrid()を使って、mu_lineとtau_lineの要素の全ての組み合わせを持つ配列を作成して、それぞれmu_grid, tau_gridとします。これは、ガウス-ガンマ分布の確率密度を等高線図にする際に格子状の点(2軸の全ての値が直交する点)を渡す必要があるためです。
また、確率密度の計算結果は1次元配列になります。作図時にmu_grid, tau_gridと同じ形状にする必要があるため、形状をpoint_dimsとして保存しておきます。
作成した$\mu$と$\tau$の点は次のようになります。
# 確認 print(mu_grid.flatten()) print(tau_grid.flatten())
[-0.65685425 -0.63418149 -0.61150872 ... 10.61150872 10.63418149
10.65685425]
[0. 0. 0. ... 2. 2. 2.]
$\mu,\ \tau$の事前分布を計算します。
# muの事前分布を計算 mu_prior_dens = norm.pdf( x=mu_grid.flatten(), loc=mu_0, scale=np.sqrt(1.0 / (lambda_0 * tau_grid.flatten() + 1e-7)) ) # tauの事前分布を計算 tau_prior_dens = gamma.pdf(x=tau_grid.flatten(), a=a_0, scale=1.0 / b_0) # 同時事前分布を計算 prior_dens = mu_prior_dens * tau_prior_dens
ガウス-ガンマ分布の確率密度は、次のガウス分布とガンマ分布の確率密度の積です。
真の分布のときと同様に、ガウス分布の確率密度をnorm.pdf()で計算します。引数xには格子状の点に変換した$\mu$の値mu_gridをflatten()で1次元配列に変換して指定します。また、標準偏差は$\sqrt{\frac{1}{\lambda_0 \tau}}$です。$\tau$として格子状の点に変換した$\tau$の値tau_gridを使います。ただし、tau_gridは0を含むように作成したため、0除算にならないように分母に微小な値1e-7を加えておきます。
ガンマ分布の確率密度は、gamma.pdf()で計算できます。値の引数xにtau_grid.flatten()、パラメータの引数aにa_0、scaleにb_0の逆数を指定します。
作成したデータフレームは次のようになります。
# 確認 print(prior_dens)
[1.26156623e-04 1.26156624e-04 1.26156624e-04 ... 3.10812932e-07
2.96195987e-07 2.82237431e-07]
$\mu,\ \tau$の事前分布を作図します。
# 事前分布を作図 plt.figure(figsize=(12, 9)) plt.scatter(x=mu_truth, y=tau_truth, color='red', s=100, marker='x', label='true val') # 真の値 plt.contour(mu_grid, tau_grid, prior_dens.reshape(point_dims)) # 事前分布 plt.xlabel('$\mu$') plt.ylabel('$\\tau$') plt.suptitle('Gaussian-Gamma Distribution', fontsize=20) plt.title('$\mu_0=' + str(mu_0)+ ', \lambda_0=' + str(lambda_0) + ', a_0=' + str(a_0) + ', b_0=' + str(b_0) + '$', loc='left') plt.colorbar() # 等高線の値 plt.legend() # 凡例 plt.show()
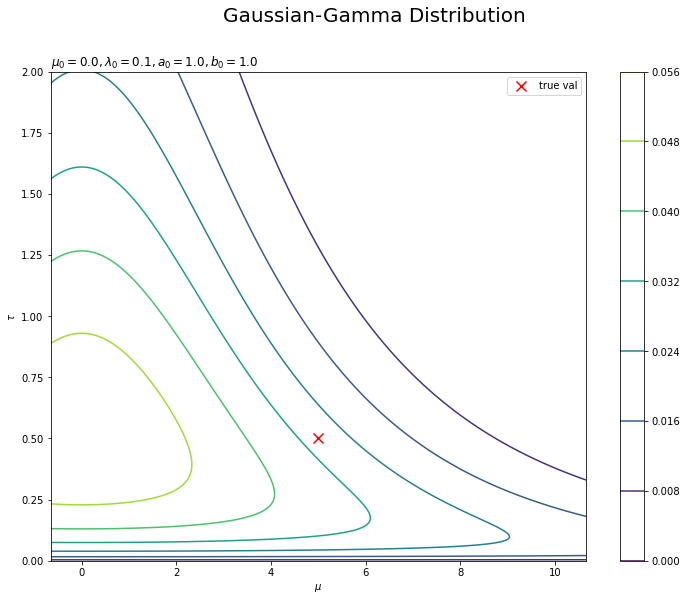
等高線図はplt.contour()で描画します。また、真のパラメータを事前分布と重ねてプロットしています。
・真の事後分布の計算
この項では、変分推論により事後分布の近似分布$q(\mu, \tau)$を求めます。ただし、この問題は解析的に求められます。解析的に求めた真の事後分布$p(\mu, \tau | \mathcal{D})$を確認します。事後分布もガウス-ガンマ分布$\mathrm{NG}(\mu, \tau | \hat{\mu}, \hat{\lambda}, \hat{a}, \hat{b})$になります。
$\mu$の真の事後分布のパラメータを計算します。
# muの真の事後分布のパラメータを計算 lambda_hat = lambda_0 + N mu_hat = (lambda_0 * mu_0 + sum(x_n)) / lambda_hat
解析的に求めた$\mu$の事後分布の平均パラメータ$\hat{\mu}$、精度パラメータの係数$\hat{\lambda}$を次の式で計算します。
計算結果は次のようになります。
# 確認 print(lambda_hat) print(mu_hat)
50.1
5.1555627648666205
$\tau$の真の事後分布のパラメータを計算します。
# lambdaの真の事後分布のパラメータを計算 a_hat = a_0 + 0.5 * N b_hat = b_0 + 0.5 * (sum(x_n**2) + lambda_0 * mu_0**2 - lambda_hat * mu_hat**2)
解析的に求めた$\tau$の事後分布のパラメータ$\hat{a},\ \hat{b}$を次の式で計算します。
計算結果は次のようになります。
# 確認 print(a_hat) print(b_hat)
26.0
52.022881790482074
$\mu,\ \tau$の真の事後分布を作図します。
# muの真の事後分布を計算 mu_true_posterior_dens = norm.pdf( x=mu_grid.flatten(), loc=mu_hat, scale=np.sqrt(1.0 / (lambda_hat * tau_grid.flatten() + 1e-7)) ) # tauの真の事後分布を計算 tau_true_posterior_dens = gamma.pdf(x=tau_grid.flatten(), a=a_hat, scale=1.0 / b_hat) # 真の同時事後分布を計算 posterior_truth_dens = mu_true_posterior_dens * tau_true_posterior_dens
# 真の事後分布を作図 plt.figure(figsize=(12, 9)) plt.scatter(x=mu_truth, y=tau_truth, color='red', s=100, marker='x', label='true val') # 真の値 plt.contour(mu_grid, tau_grid, posterior_truth_dens.reshape(point_dims)) # 真の事後分布 plt.xlabel('$\mu$') plt.ylabel('$\\tau$') plt.suptitle('Gaussian-Gamma Distribution', fontsize=20) plt.title('$N=' + str(N) + ', \hat{\mu}=' + str(np.round(mu_hat, 1))+ ', \hat{\lambda}=' + str(np.round(lambda_hat, 5)) + ', \hat{a}=' + str(a_hat) + ', \hat{b}=' + str(np.round(b_hat, 1)) + '$', loc='left') plt.xlim(mu_truth - 0.5 * np.sqrt(1.0 / tau_truth), mu_truth + 0.5 * np.sqrt(1.0 / tau_truth)) plt.ylim(0.0, 2.0 * tau_truth) plt.colorbar() # 等高線の値 plt.legend() # 凡例 plt.show()
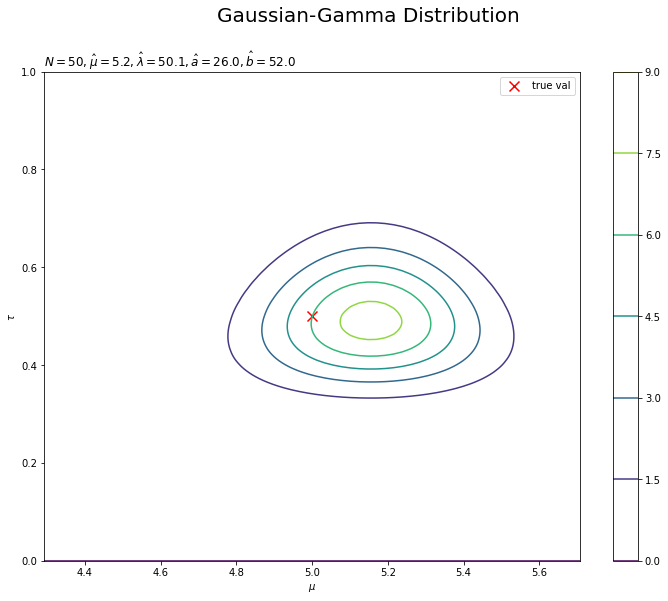
事前分布のときと同様に計算して作図します。
各パラメータの真の事後分布も確認しましょう。
・コード(クリックで展開)
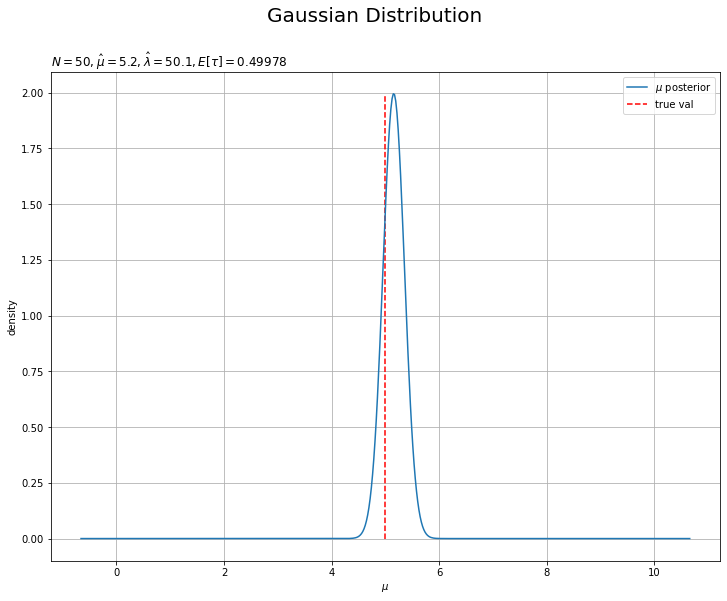
$\mu$の真の事後分布を作図します。
# muの真の事後分布を作図 mu_true_posterior_dens = norm.pdf( x=mu_line, loc=mu_hat, scale=np.sqrt(1.0 / (lambda_hat * a_hat / b_hat)) ) # muの真の事後分布を作図 plt.figure(figsize=(12, 9)) plt.plot(mu_line, mu_true_posterior_dens, label='$\mu$ posterior') # muの事後分布 plt.vlines(x=mu_truth, ymin=0.0, ymax=np.nanmax(mu_true_posterior_dens), color='red', linestyle='--', label='true val') # muの真の値 plt.xlabel('$\mu$') plt.ylabel('density') plt.suptitle('Gaussian Distribution', fontsize=20) plt.title('$N=' + str(N) + ', \hat{\mu}=' + str(np.round(mu_hat, 1)) + ', \hat{\\lambda}=' + str(lambda_hat) + ', E[\\tau]=' + str(np.round(a_hat / b_hat, 5)) + '$', loc='left') plt.legend() # 凡例 plt.grid() # グリッド線 plt.show()
重複していない$\mu$の値mu_lineの要素ごとに確率密度を計算します。ただし、$\tau$の代わりに、ガンマ分布の期待値(B.27)より、$\tau$の期待値$\mathbb{E}[\tau] = \frac{\hat{a}}{\hat{b}}$を用いて確率密度を計算します。
真の値を垂直線plt.vlines()で示しています。
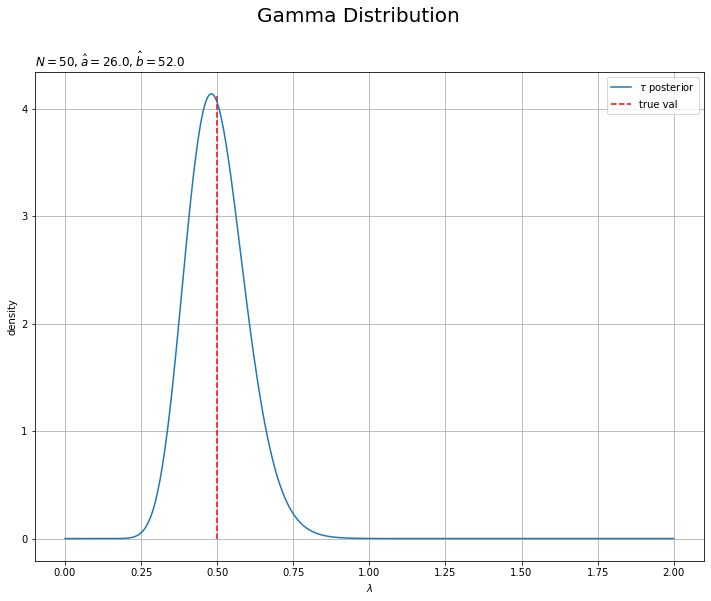
同様に、$\tau$の真の事後分布を作図します。
# tauの真の事後分布を計算 tau_true_posterior_dens = gamma.pdf(x=tau_line, a=a_hat, scale=1.0 / b_hat) # lambdaの真の事後分布を作図 plt.figure(figsize=(12, 9)) plt.plot(tau_line, tau_true_posterior_dens, label='$\\tau$ posterior') # tauの事後分布 plt.vlines(x=tau_truth, ymin=0.0, ymax=np.nanmax(tau_true_posterior_dens), color='red', linestyle='--', label='true val') # tauの真の値 plt.xlabel('$\lambda$') plt.ylabel('density') plt.suptitle('Gamma Distribution', fontsize=20) plt.title('$N=' + str(N) + ', \hat{a}=' + str(a_hat) + ', \hat{b}=' + str(np.round(b_hat, 1)) + '$', loc='left') plt.legend() # 凡例 plt.grid() # グリッド線 plt.show()
こちらも重複していない$\tau$の値tau_lineの要素ごとに確率密度を計算します。
以上でモデルの構築ができたので、次は推論処理を行います。
・変分推論
変分推論により$\mu,\ \tau$の近似事後分布$q(\mu, \tau)$を求めます。近似事後分布もガウス-ガンマ分布$\mathrm{NG}(\mu, \tau | \mu_N, \lambda_N, a_N, b_N)$になります。
変分推論では、$\mu$の近似事後分布$q_{\mu}(\mu)$(のパラメータ$\mu_N,\ \lambda_N$)と$\tau$の近似事後分布$q_{\tau}(\tau)$(のパラメータ$a_N,\ b_N$)の更新を交互に行います。
・コード全体
事前分布のパラメータの値を初期値として持つように近似事後分布のパラメータを作成しておきます。
また、後で各パラメータの更新値や分布の推移を確認するために、それぞれ試行ごとにtrace_***に値を保存していきます。ただし、この例はすぐに収束してしまうので、$q_{\mu}(\mu)$と$q_{\tau}(\tau)$をそれぞれ更新する度に値を記録することにします。
# 試行回数を指定 MaxIter = 5 # 初期値を代入 mu_N = mu_0 lambda_N = lambda_0 * a_0 / a_0 a_N = a_0 b_N = b_0 # 推移の確認用の受け皿を作成 trace_mu_i = [mu_0] trace_lambda_i = [lambda_N] trace_a_i = [a_N] trace_b_i = [b_N] # 変分推論 for i in range(MaxIter): # mu の近似事後分布のパラメータを計算: 式 (10.26)(10.27) mu_N = (lambda_0 * mu_0 + np.sum(x_n)) / (lambda_0 + N) lambda_N = (lambda_0 + N) * a_N / b_N # i回目のmuの近似事後分布の更新後の結果を記録 trace_mu_i.append(mu_N) trace_lambda_i.append(lambda_N) trace_a_i.append(a_N) trace_b_i.append(b_N) # tauの近似事後分布のパラメータを計算:式(10.29)(10.30) a_N = a_0 + 0.5 * (N + 1) b_N = b_0 + 0.5 * (lambda_0 * mu_0**2 + np.sum(x_n**2)) b_N += 0.5 * (lambda_0 + N) * (mu_N**2 + 1.0 / lambda_N) b_N -= (lambda_0 * mu_0 + np.sum(x_n)) * mu_N # i回目のtauの近似事後分布の更新後の結果を記録 trace_mu_i.append(mu_N) trace_lambda_i.append(lambda_N) trace_a_i.append(a_N) trace_b_i.append(b_N) # 動作確認 #print(str(i + 1) + ' (' + str(np.round((i + 1) / MaxIter * 100, 1)) + ')%')
・処理の解説
続いて、変分推論で行う処理を確認していきます。
・平均パラメータの近似事後分布の更新
先に、$q_{\tau}(\tau)$を固定した下での$\mu$の近似事後分布の最適解$q_{\mu}^{*}(\mu)$を計算します。
$\mu$の近似事後分布のパラメータを計算します。
# mu の近似事後分布のパラメータを計算: 式 (10.26)(10.27)
mu_N = (lambda_0 * mu_0 + np.sum(x_n)) / (lambda_0 + N)
lambda_N = (lambda_0 + N) * a_N / b_N
変分推論により求めた$\mu$の事後分布の平均パラメータ$\mu_N$、精度パラメータ$\lambda_N$を次の式で計算します。
$\lambda_N$は、これまでのように精度パラメータの係数ではなく、精度パラメータそのものであることに注意してください。
計算結果は次のようになります。
# 確認 print(mu_N) print(lambda_N)
5.1555627648666205
25.038983573130885
・精度パラメータの近似事後分布の更新
続いて、$q_{\mu}(\mu)$を固定した下での$\tau$の近似事後分布の最適解$q_{\tau}^{*}(\tau)$を計算します。
$\tau$の近似事後分布のパラメータを計算します。
# tauの近似事後分布のパラメータを計算:式(10.29)(10.30) a_N = a_0 + 0.5 * (N + 1) b_N = b_0 + 0.5 * (lambda_0 * mu_0**2 + np.sum(x_n**2)) b_N += 0.5 * (lambda_0 + N) * (mu_N**2 + 1.0 / lambda_N) b_N -= (lambda_0 * mu_0 + np.sum(x_n)) * mu_N
変分推論により求めた$\tau$の事後分布のパラメータを$a_N,\ b_N$を次の式で計算します。
計算結果は次のようになります。
# 確認 print(a_N) print(b_N)
26.5
53.02332176149116
これで超パラメータ$\mu_N,\ \lambda_N$と$a_N,\ b_N$を更新できました。
以上が変分推論で行う個々の処理です。繰り返し行うことで、徐々に真の事後分布に近付けていきます。閾値に達するまでループすることもできますが、この例では簡単に、試行回数を設定してループすることにします。
・推論結果の確認
推論結果を確認していきます。
・事後分布の確認
mu_N, lambda_N、a_N, b_Nの最後の更新値を用いて、$\mu,\ \tau$の近似事後分布を計算します。
# muの近似事後分布を計算 E_tau = a_N / b_N # tauの期待値 mu_posterior_dens = norm.pdf( x=mu_grid.flatten(), loc=mu_N, scale=np.sqrt(1.0 / (lambda_N / E_tau * tau_grid.flatten() + 1e-7)) ) # tauの近似事後分布を計算 tau_posterior_dens = gamma.pdf(x=tau_grid.flatten(), a=a_N, scale=1.0 / b_N) # 同時近似事後分布を計算 posterior_dens = mu_posterior_dens * tau_posterior_dens
事前分布のときと同様に計算します。ただし、$\mu$の近似事後分布の精度パラメータ$\lambda_N$には、既に$\tau$の情報が期待値$\mathbb{E}[\tau]$として含まれています。そこで、$\mathbb{E}[\tau] = \frac{a_N}{b_N}$の逆数を掛けて打ち消してから、$\tau$の値tau_grid.flatten()を掛けて確率密度を計算します。(本当にこんなことをしていいのかよく分かっていません。やるにしてももう少し納得できる理由が欲しい。)
$\mu,\ \tau$の同時近似事後分布を作図します。
# 近似事後分布を作図 plt.figure(figsize=(12, 9)) plt.scatter(x=mu_truth, y=tau_truth, color='red', s=100, marker='x', label='true val') # 真の値 plt.contour(mu_grid, tau_grid, posterior_truth_dens.reshape(point_dims), alpha=0.5, linestyles='--') # 真の事後分布 plt.contour(mu_grid, tau_grid, posterior_dens.reshape(point_dims)) # 近似事後分布 plt.xlabel('$\mu$') plt.ylabel('$\\tau$') plt.suptitle('Gaussian-Gamma Distribution', fontsize=20) plt.title('$N=' + str(N) + ', \mu_N=' + str(np.round(mu_N, 1))+ ', \lambda_N\ /\ E[\\tau]=' + str(np.round(lambda_N / E_tau, 1)) + ', a_N=' + str(a_N) + ', b_N=' + str(np.round(b_N, 1)) + '$', loc='left') plt.xlim(mu_truth - 0.5 * np.sqrt(1.0 / tau_truth), mu_truth + 0.5 * np.sqrt(1.0 / tau_truth)) plt.ylim(0.0, 2.0 * tau_truth) plt.colorbar() # 等高線の値 plt.legend() # 凡例 plt.show()
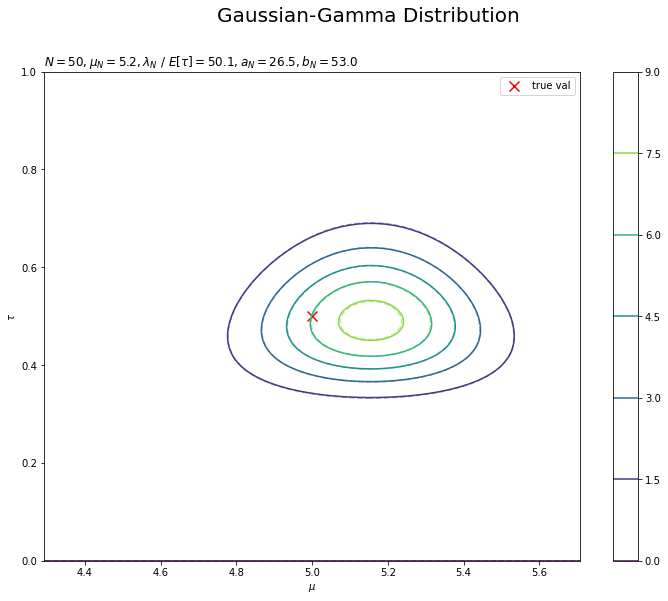
事前分布のときと同様に作図できます。真の事後分布と重ねて描画しています。
真の事後分布を近似できています。
各パラメータの近似事後分布も確認しましょう。
・コード(クリックで展開)
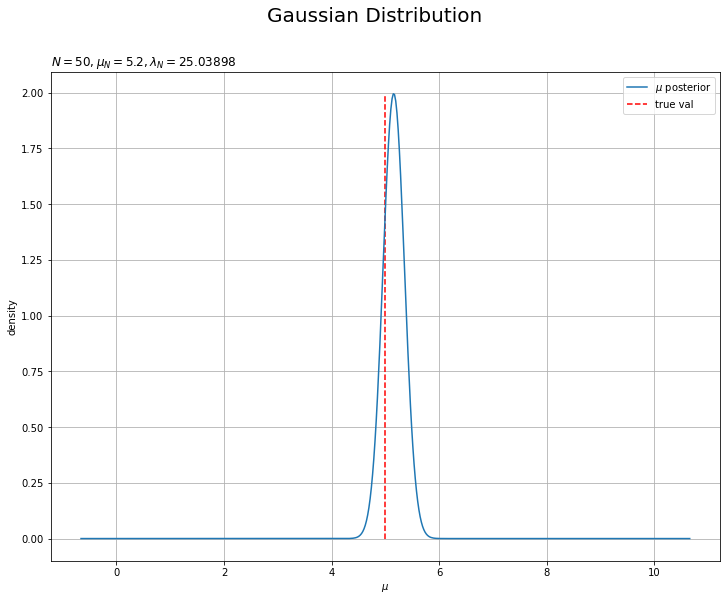
$\mu$の近似事後分布を作図します。
# muの近似事後分布を作図 mu_posterior_dens = norm.pdf( x=mu_line, loc=mu_N, scale=np.sqrt(1.0 / lambda_N) ) # muの近似事後分布を作図 plt.figure(figsize=(12, 9)) plt.plot(mu_line, mu_posterior_dens, label='$\mu$ posterior') # muの近似事後分布 plt.vlines(x=mu_truth, ymin=0.0, ymax=np.nanmax(mu_posterior_dens), color='red', linestyle='--', label='true val') # muの真の値 plt.xlabel('$\mu$') plt.ylabel('density') plt.suptitle('Gaussian Distribution', fontsize=20) plt.title('$N=' + str(N) + ', \mu_N=' + str(np.round(mu_N, 1)) + ', \\lambda_N=' + str(np.round(lambda_N, 5)) + '$', loc='left') plt.legend() # 凡例 plt.grid() # グリッド線 plt.show()
こちらは、lambda_Nをそのまま精度パラメータとして用います。
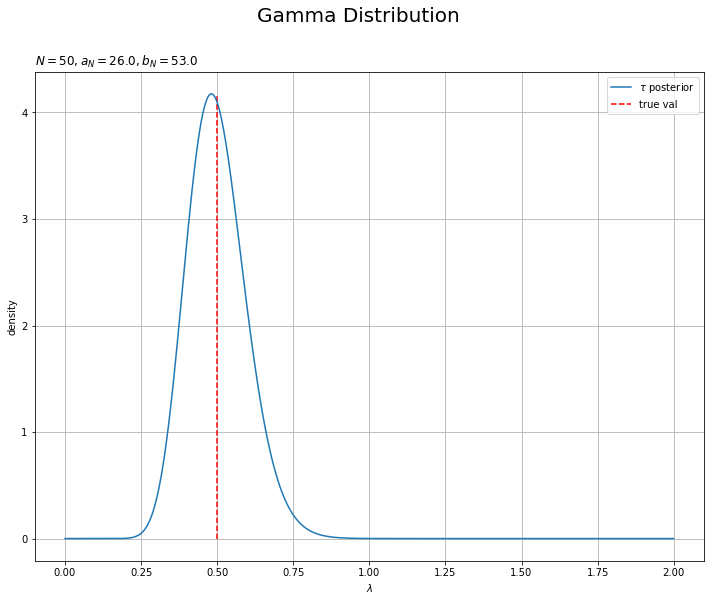
$\tau$の近似事後分布を作図します。
# tauの近似事後分布を計算 tau_posterior_dens = gamma.pdf(x=tau_line, a=a_N, scale=1.0 / b_N) # lambdaの近似事後分布を作図 plt.figure(figsize=(12, 9)) plt.plot(tau_line, tau_posterior_dens, label='$\\tau$ posterior') # tauの事後分布 plt.vlines(x=tau_truth, ymin=0.0, ymax=np.nanmax(tau_posterior_dens), color='red', linestyle='--', label='true val') # tauの真の値 plt.xlabel('$\lambda$') plt.ylabel('density') plt.suptitle('Gamma Distribution', fontsize=20) plt.title('$N=' + str(N) + ', a_N=' + str(a_hat) + ', b_N=' + str(np.round(b_N, 1)) + '$', loc='left') plt.legend() # 凡例 plt.grid() # グリッド線 plt.show()
真の事後分布のときと同様に作図できます。
・超パラメータの推移の確認
超パラメータの更新値の推移を確認します。
・コード(クリックで展開)
初期値とMaxIter * 2個の値を格納した各パラメータのリストtrace_***を使って作図します。
# mu_Nの推移を作図 plt.figure(figsize=(12, 9)) plt.plot(np.arange(0.0, MaxIter + 0.1, 0.5), trace_mu_i) plt.xlabel('iteration') plt.ylabel('value') plt.suptitle('Variational Inference', fontsize=20) plt.title('$\mu_N$', loc='left') plt.grid() # グリッド線 plt.show()
# lambda_Nの推移を作図 plt.figure(figsize=(12, 9)) plt.plot(np.arange(0.0, MaxIter + 0.1, 0.5), trace_lambda_i) plt.xlabel('iteration') plt.ylabel('value') plt.suptitle('Variational Inference', fontsize=20) plt.title('$\lambda_N$', loc='left') plt.grid() # グリッド線 plt.show()
# a_Nの推移を作図 plt.figure(figsize=(12, 9)) plt.plot(np.arange(0.0, MaxIter + 0.1, 0.5), trace_a_i) plt.xlabel('iteration') plt.ylabel('value') plt.suptitle('Variational Inference', fontsize=20) plt.title('$a_N$', loc='left') plt.grid() # グリッド線 plt.show()
# b_Nの推移を作図 plt.figure(figsize=(12, 9)) plt.plot(np.arange(0.0, MaxIter + 0.1, 0.5), trace_b_i) plt.xlabel('iteration') plt.ylabel('value') plt.suptitle('Variational Inference', fontsize=20) plt.title('$b_N$', loc='left') plt.grid() # グリッド線 plt.show()
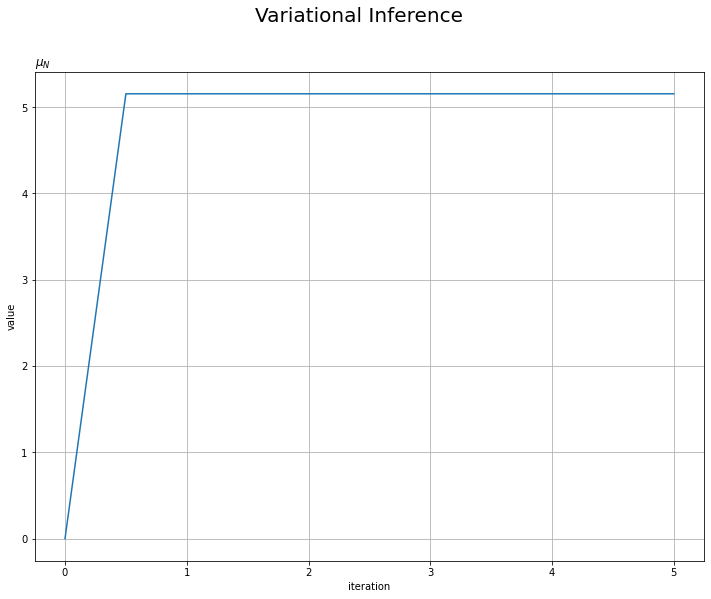
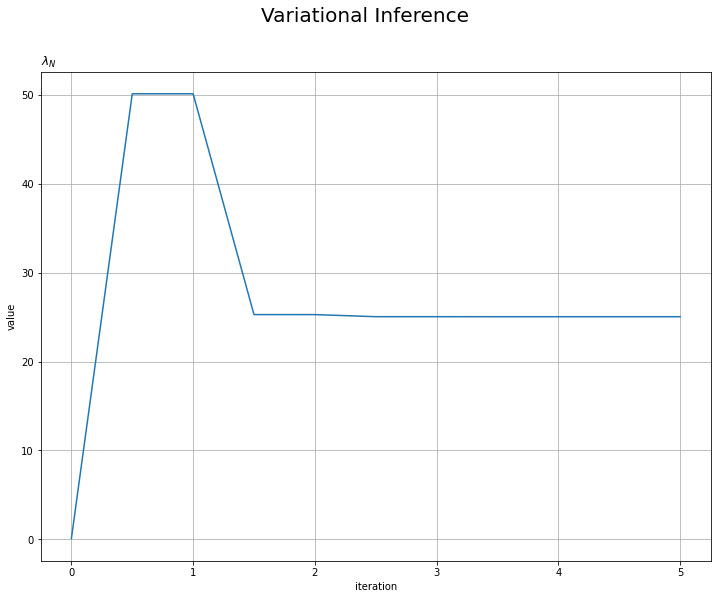
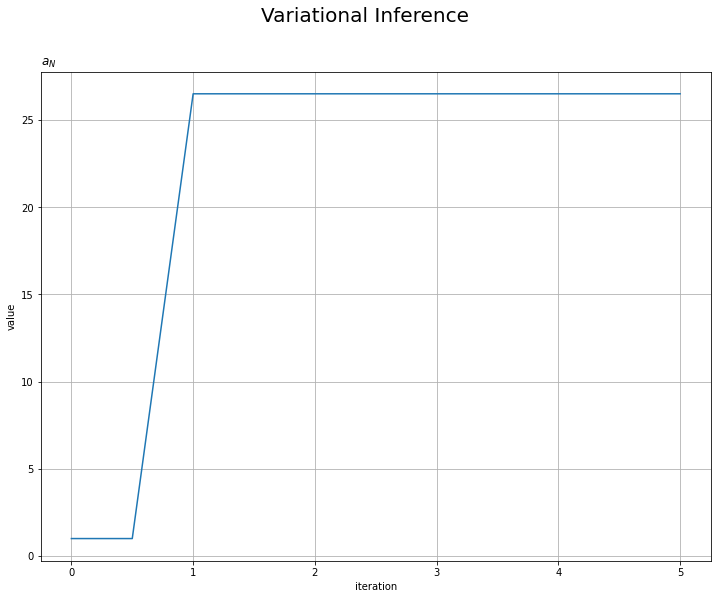
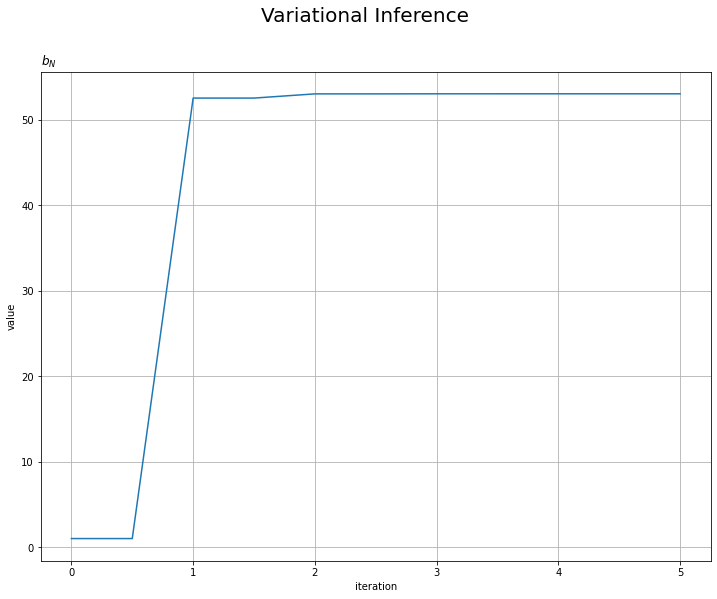
平均パラメータに関しては1回の試行で、精度パラメータに関しては2回の試行で収束しているのが確認できます。平均パラメータが1回で収束するのは、$\mu_N$の更新式に$\tau$の近似事後分布のパラメータを含んでいないことからも分かります。
・おまけ:アニメーションによる推移の確認
gganimateパッケージを利用して、分布の推移のアニメーション(gif画像)を作成するためのコードです。
・コード(クリックで展開)
# 追加ライブラリ import matplotlib.animation as animation
・$\mu,\ \tau$の同時近似事後分布の推移
# 画像サイズを指定 fig = plt.figure(figsize=(12, 9)) # 作図処理を関数として定義 def update_posterior(i): # i回目の同時近似事後分布を計算 E_tau = trace_a_i[i] / trace_b_i[i] # tauの期待値 posterior_dens = norm.pdf( x=mu_grid.flatten(), loc=trace_mu_i[i], scale=np.sqrt(1.0 / (trace_lambda_i[i] / E_tau * tau_grid.flatten() + 1e-7)) ) posterior_dens *= gamma.pdf( x=tau_grid.flatten(), a=trace_a_i[i], scale=1.0 / trace_b_i[i] ) # 前フレームのグラフを初期化 plt.cla() # 近似事後分布を作図 plt.scatter(x=mu_truth, y=tau_truth, color='red', s=100, marker='x', label='true val') # 真の値 plt.contour(mu_grid, tau_grid, posterior_truth_dens.reshape(point_dims), alpha=0.5, linestyles='--') # 真の事後分布 plt.contour(mu_grid, tau_grid, posterior_dens.reshape(point_dims)) # 近似事後分布 plt.xlabel('$\mu$') plt.ylabel('$\\tau$') plt.suptitle('Gaussian-Gamma Distribution', fontsize=20) plt.title('$iter:' + str(i * 0.5) + ', N=' + str(N) + ', \mu_N=' + str(np.round(trace_mu_i[i], 1))+ ', \lambda_N=' + str(np.round(trace_lambda_i[i], 5)) + ', a_N=' + str(trace_a_i[i]) + ', b_N=' + str(np.round(trace_b_i[i], 1)) + '$', loc='left') plt.xlim(mu_truth - np.sqrt(1.0 / tau_truth), mu_truth + np.sqrt(1.0 / tau_truth)) plt.ylim(0.0, 2.0 * tau_truth) plt.legend() # 凡例 plt.grid() # グリッド線 # gif画像を作成 posterior_anime = animation.FuncAnimation(fig, update_posterior, frames=MaxIter * 2 + 1, interval=200) posterior_anime.save("ch10_1_3_Posterior.gif")
初期値を含み各試行で2回記録しているため、フレーム数framesにはMaxIter * 2 + 1を指定します。
(よく理解していないので、animationの解説は省略…とりあえずこれで動きます……)
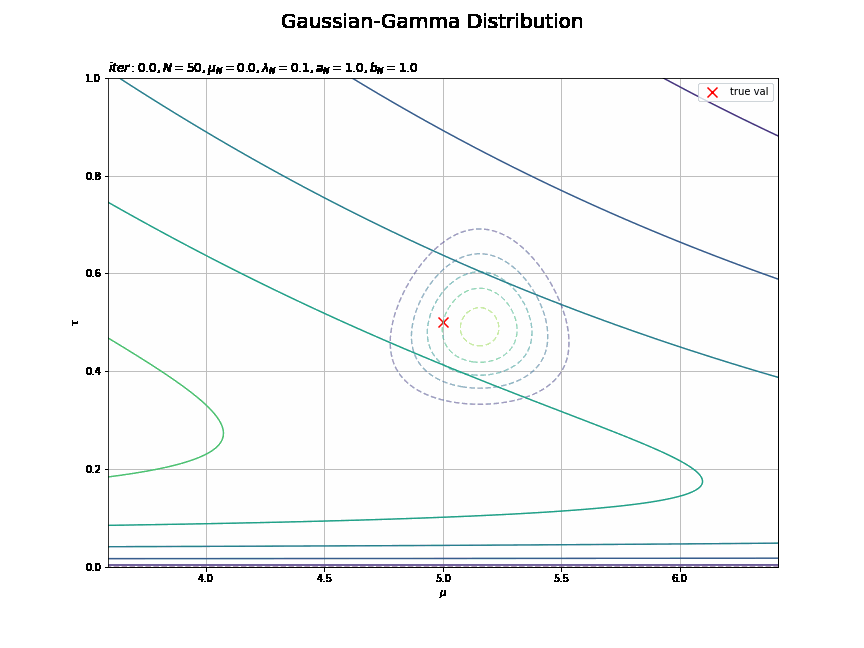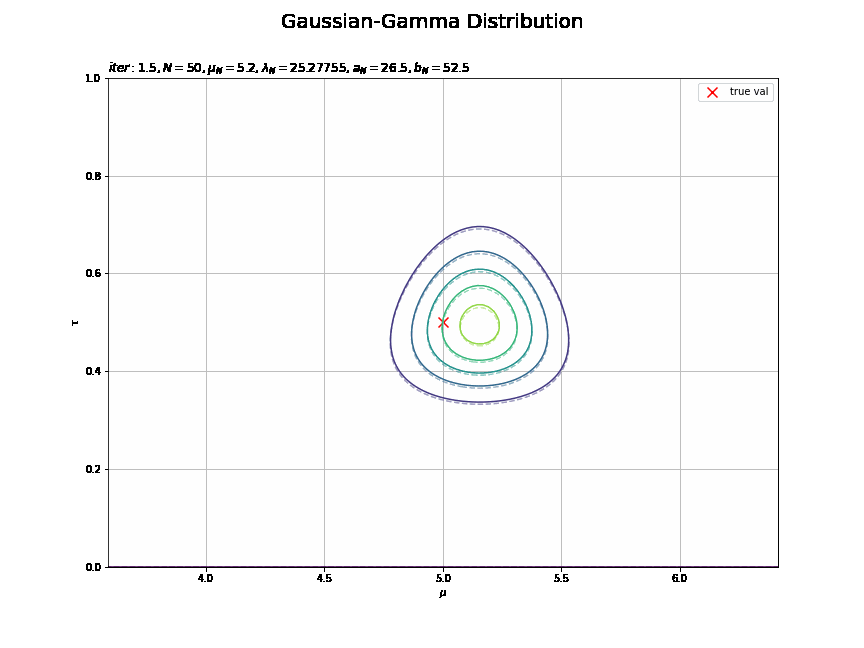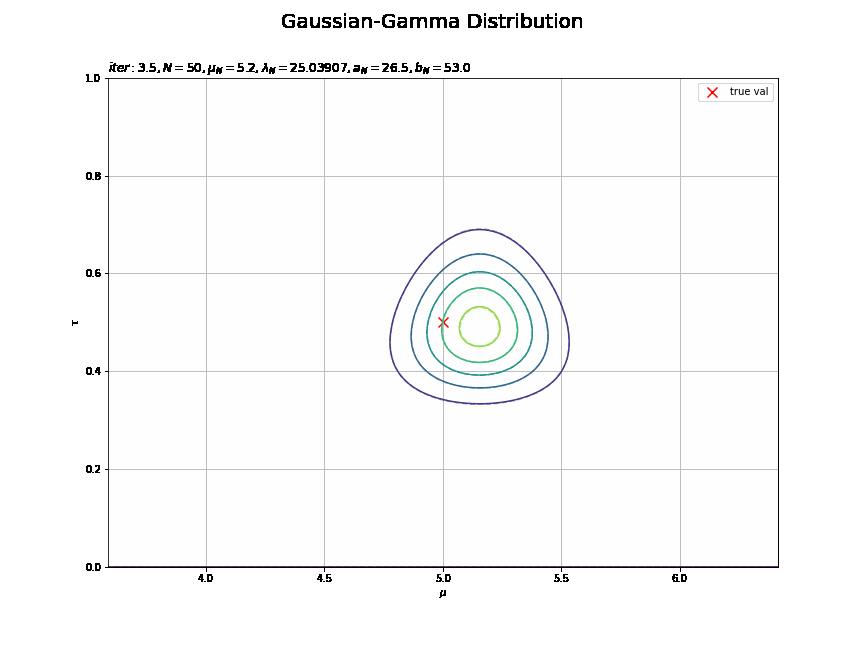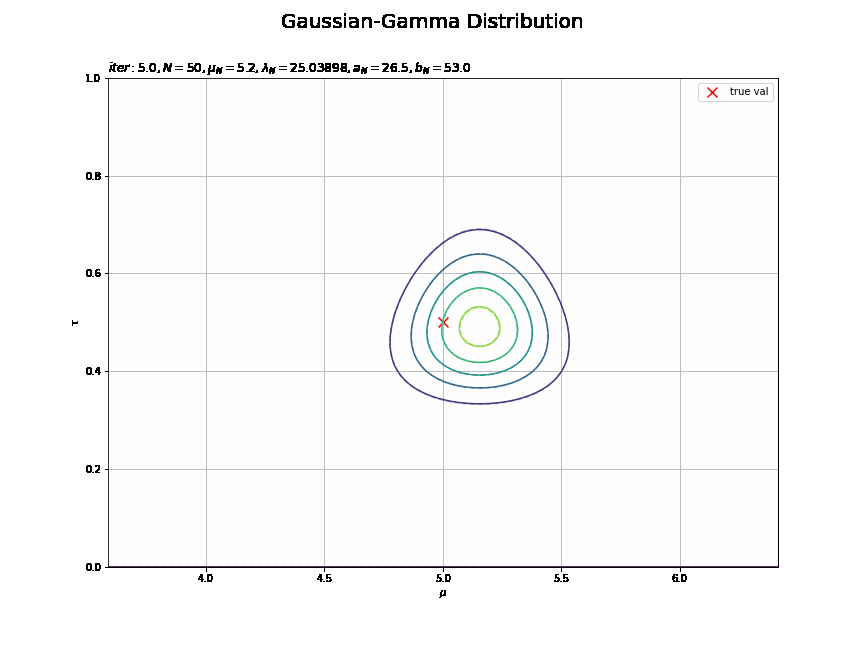
平均は0.5回目の試行で、精度は2回目の試行で収束しているのが分かります。
参考文献
- C.M.ビショップ著,元田 浩・他訳『パターン認識と機械学習 上下』,丸善出版,2012年.
おわりに
本の図と違って真の事後分布と近似分布がぴったり一致したんだけど逆にこれで良いのか不安になってきた。
嬉しいので今日も貼っておく。このブログの投稿前日に活動再開した「りさまる」を観て!
おめでとうございます!雑音に負けずに自由にやってほしい。
【関連する内容】
解析的に解く(真の事後分布を求める)のはこちらの記事でやりました。