はじめに
『ベイズ推論による機械学習入門』の学習時のノートです。「数式の行間を読んでみた」とそれを「RとPythonで組んでみた」によって、「数式」と「プログラム」から理解するのが目標です。
省略してある内容等ありますので、本とあわせて読んでください。
この記事では、「尤度関数を平均が未知の多次元ガウス分布(多変量正規分布)」、「事前分布を多次元ガウス分布」とした場合の「パラメータの事後分布」と「未観測値の予測分布」の計算をR言語で実装します。
【数式読解編】
【前の節の内容】
【他の節の内容】
【この節の内容】
3.4.1 多次元ガウス分布の学習と予測:平均が未知の場合
尤度関数を多次元ガウス分布(Multivariate Gaussian Distribution)・多変量正規分布(Multivariate Normal Distribution)、事前分布を多次元ガウス分布とするモデルに対するベイズ推論を実装します。人工的に生成したデータを用いて、ガウス分布の平均パラメータを推定し、また未観測データに対する予測分布を求めます。
ガウス分布については「多次元ガウス分布の定義式 - からっぽのしょこ」を参照してください。
利用するパッケージを読み込みます。
# 利用パッケージ library(tidyverse) library(mvnfast) library(gganimate)
この記事では、基本的にパッケージ名::関数名()の記法を使うので、パッケージを読み込む必要はありません。ただし、作図コードがごちゃごちゃしないようにパッケージ名を省略しているため、ggplot2は読み込む必要があります。
magrittrパッケージのパイプ演算子%>%ではなく、ネイティブパイプ(ベースパイプ)演算子|>を使っています。%>%に置き換えても処理できます。
学習の推移をアニメーション(gif画像)で確認するのにgganimateパッケージを利用します。不要であれば省略してください。
ベイズ推論の実装
まずは、モデルを設定して、データを生成します。生成したデータを用いて、事後分布のパラメータを計算します。さらに、事後分布のパラメータを用いて、予測分布のパラメータを計算します。
生成分布の設定
データの生成分布(真の分布)として、多次元ガウス分布$\mathcal{N}(\mathbf{x}_n | \boldsymbol{\mu}, \boldsymbol{\Lambda}^{-1})$を設定します。
ガウス分布のグラフ作成については「【R】2次元ガウス分布の作図 - からっぽのしょこ」を参照してください。
真の分布($D$次元ガウス分布)のパラメータ$\boldsymbol{\mu}, \boldsymbol{\Sigma} = \boldsymbol{\Lambda}^{-1}$を設定します。この例では2次元のグラフで表現するため、次元数を$D = 2$とします。パラメータの計算自体は次元数に関わらず行えます。
# 次元数を指定 D <- 2 # 真の平均ベクトルを指定 mu_truth_d <- c(25, 50) # (既知の)分散共分散行列を指定 sigma_dd <- matrix(c(900, -100, -100, 400), nrow = D, ncol = D) # (既知の)精度行列を計算 lambda_dd <- solve(sigma_dd) lambda_dd
## [,1] [,2] ## [1,] 0.0011428571 0.0002857143 ## [2,] 0.0002857143 0.0025714286
平均ベクトル$\boldsymbol{\mu} = (\mu_1, \mu_2)^{\top}$をmu_truth_dとして値を指定します。mu_truth_dが真の値であり、この値を求めるのがここでの目的です。
分散共分散行列$\boldsymbol{\Sigma} = (\sigma_1^2, \sigma_{2,1}, \sigma_{1,2}, \sigma_2^2)$をsigma_ddとして値を指定します。$\sigma_d$は$x_d$の標準偏差、$\sigma_d^2$は$x_d$の分散、$\sigma_{i,j}$は$x_i, x_j$の共分散であり、$\sigma_d^2$は正の実数、$\sigma_{i,j} = \sigma_{j,i}$は実数、また$\boldsymbol{\Sigma}$は正定値行列を満たす必要があります。
精度行列$\boldsymbol{\Lambda} = \boldsymbol{\Sigma}^{-1}$を計算してlambda_ddとします。逆行列はsolve()で計算できます。
真の分布の確率変数がとり得る値$\mathbf{x}$を作成します。
# グラフ用のxの値を作成 x_1_vec <- seq( mu_truth_d[1] - sqrt(sigma_dd[1, 1]) * 3, mu_truth_d[1] + sqrt(sigma_dd[1, 1]) * 3, length.out = 301 ) x_2_vec <- seq( mu_truth_d[2] - sqrt(sigma_dd[2, 2]) * 3, mu_truth_d[2] + sqrt(sigma_dd[2, 2]) * 3, length.out = 301 ) # グラフ用のxの点を作成 x_mat <- tidyr::expand_grid( x_1 = x_1_vec, x_2 = x_2_vec ) |> # 格子点を作成 as.matrix() # マトリクスに変換 head(x_mat)
## x_1 x_2 ## [1,] -65 -10.0 ## [2,] -65 -9.6 ## [3,] -65 -9.2 ## [4,] -65 -8.8 ## [5,] -65 -8.4 ## [6,] -65 -8.0
$x_1$(x軸)の値をx_1_vals、$x_2$(y軸)の値をx_2_valsとします。この例では、それぞれ平均を中心に標準偏差の3倍を範囲とします。
x_1_valsとx_2_valsの要素の全ての組み合わせ(格子状の点)をexpand_grid()で作成します。データフレームが出力されるので、as.matrix()でマトリクスに変換してx_matとします。x_matの各行が点$\mathbf{x} = (x_1, x_2)^{\top}$に対応します。
真の分布を計算して、作図用のデータフレームを作成します。
# 真の分布(多次元ガウス分布)を計算:式(2.72) model_df <- tibble::tibble( x_1 = x_mat[, 1], # x軸の値 x_2 = x_mat[, 2], # y軸の値 dens = mvnfast::dmvn(X = x_mat, mu = mu_truth_d, sigma = sigma_dd) # 確率密度 ) model_df
## # A tibble: 90,601 × 3 ## x_1 x_2 dens ## <dbl> <dbl> <dbl> ## 1 -65 -10 0.00000000549 ## 2 -65 -9.6 0.00000000590 ## 3 -65 -9.2 0.00000000633 ## 4 -65 -8.8 0.00000000680 ## 5 -65 -8.4 0.00000000730 ## 6 -65 -8 0.00000000783 ## 7 -65 -7.6 0.00000000839 ## 8 -65 -7.2 0.00000000899 ## 9 -65 -6.8 0.00000000963 ## 10 -65 -6.4 0.0000000103 ## # … with 90,591 more rows
x_matの行ごとに確率密度を計算します。多次元ガウス分布の確率密度は、mvnfastパッケージのdmvn()で計算できます。確率変数の引数Xにx_mat、平均ベクトルの引数muにmu_truth_d、分散共分散行列の引数sigmaにsigma_ddまたはlambda_ddの逆行列を指定します。
真の分布のグラフを作成します。
# パラメータラベル用の文字列を作成 model_param_text <- paste0( "list(mu==(list(", paste(round(mu_truth_d, 1), collapse = ", "), "))", ", Lambda==(list(", paste(round(lambda_dd, 5), collapse = ", "), ")))" ) # 真の分布を作図 ggplot() + geom_contour(data = model_df, mapping = aes(x = x_1, y = x_2, z = dens, color = ..level..)) + # 真の分布:(等高線図) #geom_contour_filled(data = model_df, mapping = aes(x = x_1, y = x_2, z = dens, fill = ..level..), alpha = 0.8) + # 真の分布:(塗りつぶし等高線図) labs(title = "Multivariate Gaussian Distribution", subtitle = parse(text = model_param_text), color = "density", fill = "density", x = expression(x[1]), y = expression(x[2]))
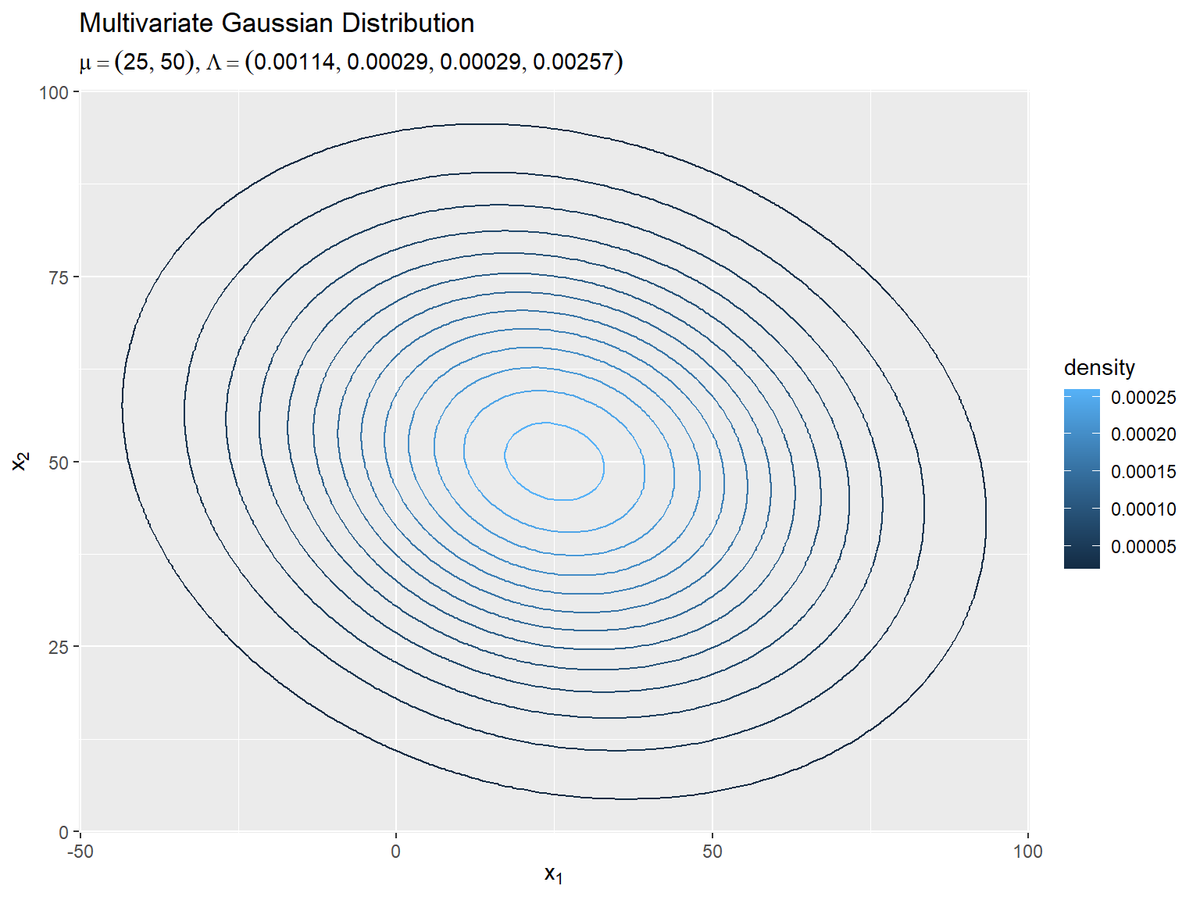
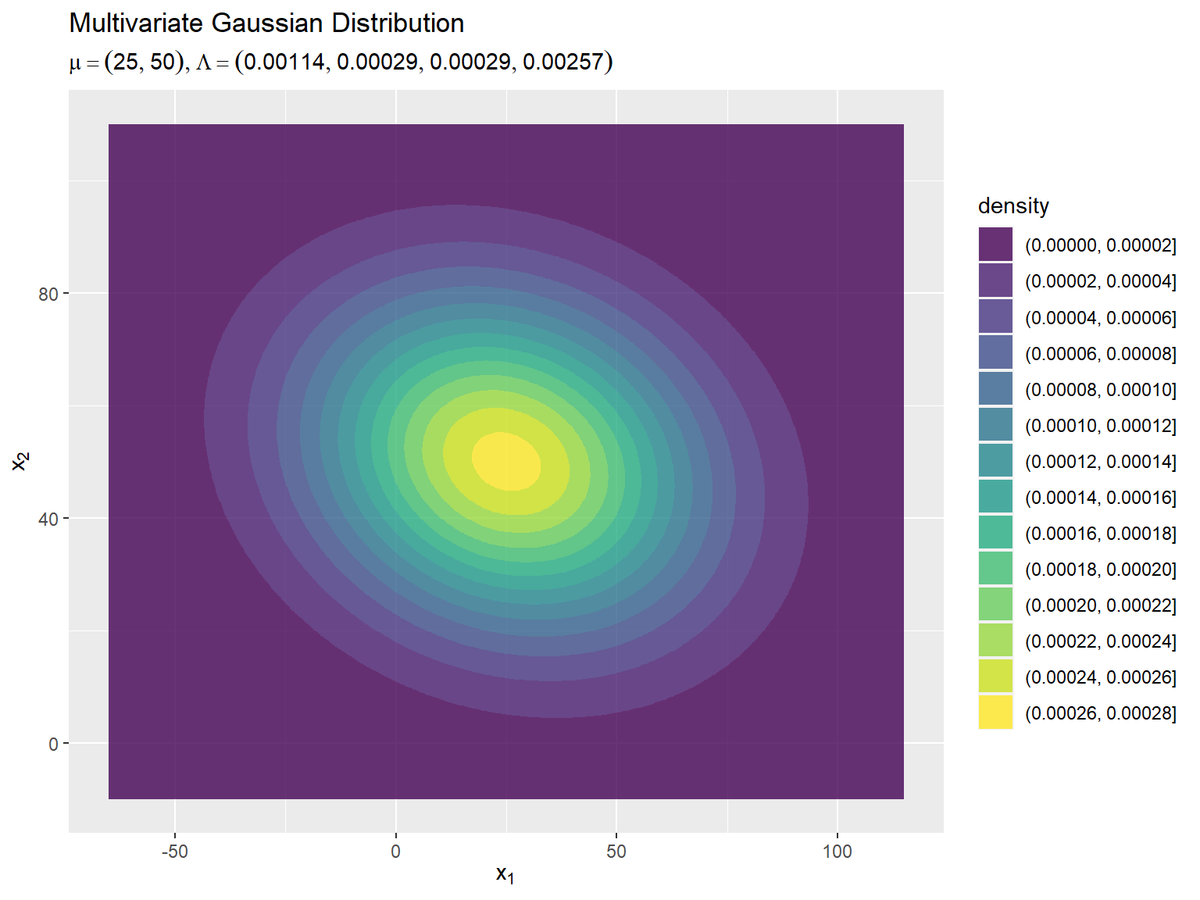
geom_contour()またはgeom_contour_filled()で等高線グラフを描画します。
真のパラメータを求めることは、真の分布を求めることを意味します。
データの生成
続いて、構築したモデルに従って観測データ$\mathbf{X} = \{\mathbf{x}_1, \mathbf{x}_2, \cdots, \mathbf{x}_N\}$、$\mathbf{x}_n = (x_{n,1}, x_{n,2}, \cdots, x_{n,D})^{\top}$を生成します。
多次元ガウス分布の乱数生成については「【R】多次元ガウス分布の乱数生成 - からっぽのしょこ」参照してください。
多次元ガウス分布に従う$N$個のデータをランダムに生成します。
# (観測)データ数を指定 N <- 100 # 多次元ガウス分布に従うデータを生成 x_nd <- mvnfast::rmvn(n = N, mu = mu_truth_d, sigma = sigma_dd) head(x_nd)
## [,1] [,2] ## [1,] 23.06616 84.33939 ## [2,] 72.41147 44.67731 ## [3,] 66.59815 11.48065 ## [4,] -47.41186 102.59454 ## [5,] 30.89041 83.17240 ## [6,] -4.35591 40.12426
多次元ガウス分布に従う乱数は、mvnfastパッケージのrmvn()で生成できます。データ数の引数nにN、平均ベクトルの引数muにmu_truth_d、分散共分散行列の引数sigmaにsigma_ddまたはlambda_ddの逆行列を指定します。生成したN個のデータをx_ndとします。
観測データの散布図を真の分布と重ねて確認します。
# 観測データを格納 data_df <- tibble::tibble( x_1 = x_nd[, 1], # x軸の値 x_2 = x_nd[, 2] # y軸の値 ) # パラメータラベル用の文字列を作成 sample_param_text <- paste0( "list(mu==(list(", paste(round(mu_truth_d, 1), collapse = ", "), "))", ", Lambda==(list(", paste(round(lambda_dd, 5), collapse = ", "), "))", ", N==", N, ")" ) # 観測データの散布図を作成 ggplot() + geom_contour(data = model_df, aes(x = x_1, y = x_2, z = dens, color = ..level..)) + # 真の分布:(等高線図) #geom_contour_filled(data = model_df, aes(x = x_1, y = x_2, z = dens, fill = ..level..), alpha = 0.8) + # 真の分布:(塗りつぶし等高線図) geom_point(data = data_df, aes(x = x_1, y = x_2), color = "orange") + # 観測データ labs(title = "Multivariate Gaussian Distribution", subtitle = parse(text = sample_param_text), color = "density", fill = "density", x = expression(x[1]), y = expression(x[2]))
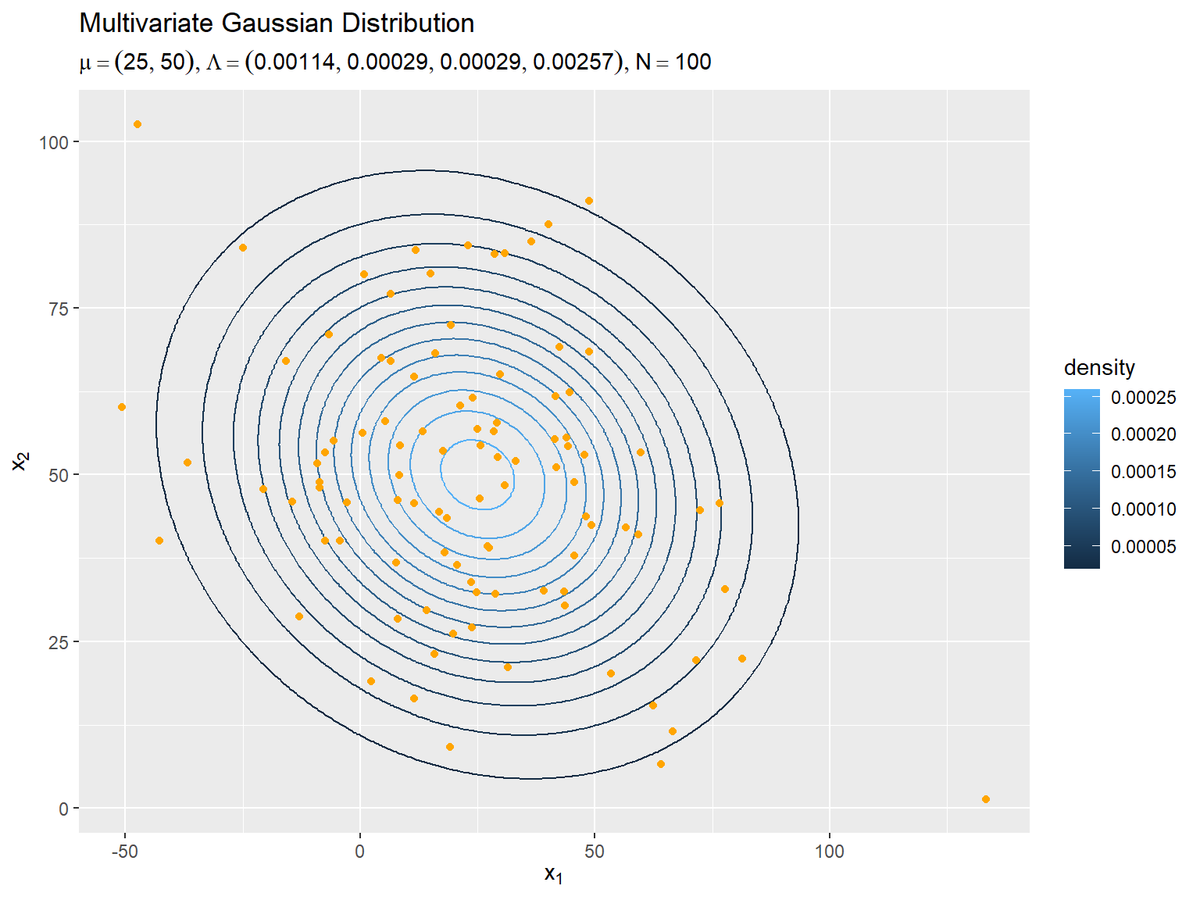
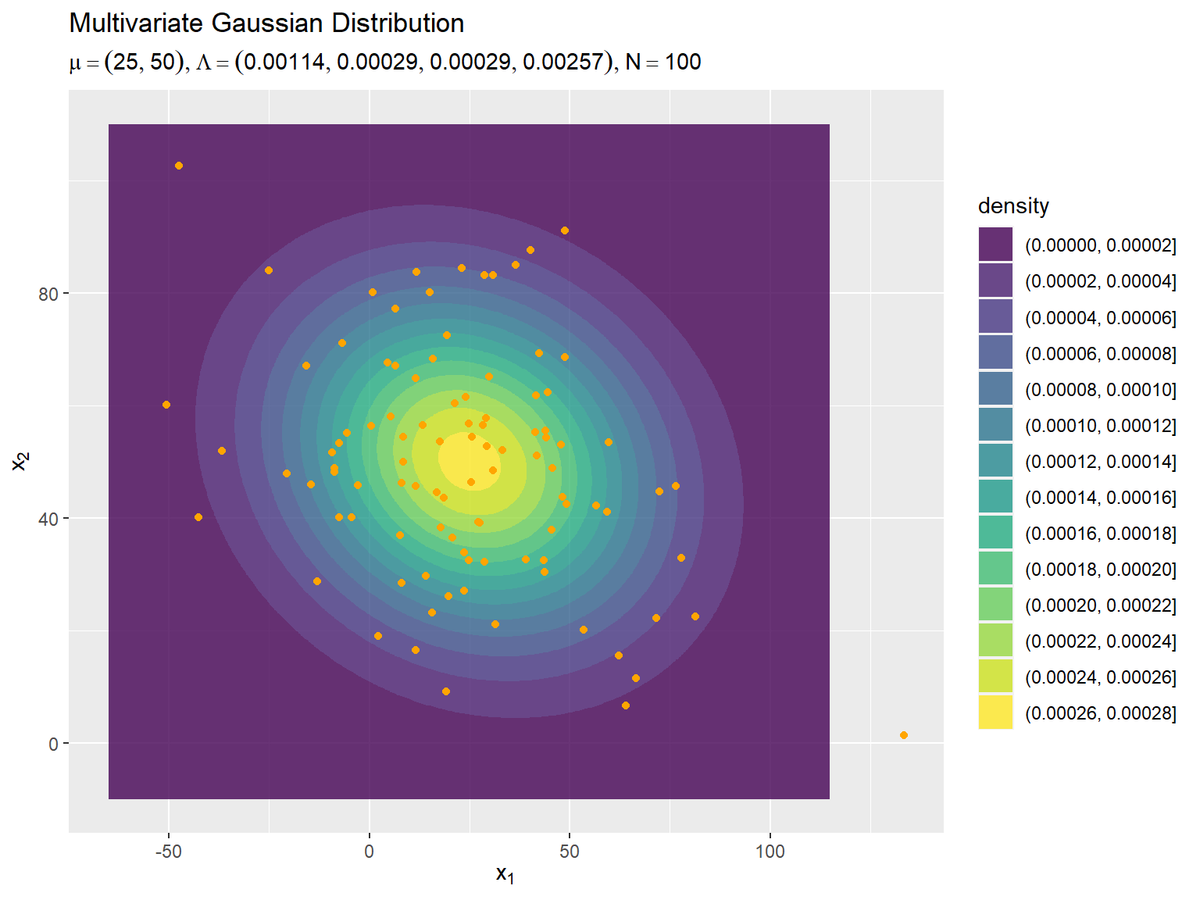
事前分布の設定
次は、尤度に対する共役事前分布を設定します。多次元ガウス分布の平均パラメータ$\boldsymbol{\mu}$の事前分布$p(\boldsymbol{\mu})$として多次元ガウス分布$\mathcal{N}(\boldsymbol{\mu} | \mathbf{m}, \boldsymbol{\Lambda}_{\boldsymbol{\mu}}^{-1})$を設定します。
$\boldsymbol{\mu}$の事前分布($D$次元ガウス分布)のパラメータ(超パラメータ)$\mathbf{m}, \boldsymbol{\Sigma}_{\boldsymbol{\mu}} = \boldsymbol{\Lambda}_{\boldsymbol{\mu}}^{-1}$を設定します。
# μの事前分布の平均ベクトルを指定 m_d <- rep(0, times = D) # μの事前分布の分散共分散行列を指定 sigma_mu_dd <- diag(D) * 10000 # μの事前分布の精度行列を計算 lambda_mu_dd <- solve(sigma_mu_dd) lambda_mu_dd
## [,1] [,2] ## [1,] 1e-04 0e+00 ## [2,] 0e+00 1e-04
真の分布と同様に、平均ベクトル$\mathbf{m} = (m_1, m_2)^{\top}$をm_d、分散共分散行列$\boldsymbol{\Sigma}_{\boldsymbol{\mu}} = (\sigma_1^2, \sigma_{2,1}, \sigma_{1,2}, \sigma_2^2)$をsigma_mu_ddとして値を指定して、精度行列$\boldsymbol{\Lambda}_{\boldsymbol{\mu}} = \boldsymbol{\Sigma}_{\boldsymbol{\mu}}^{-1}$を計算してlambda_mu_ddとします。
$\boldsymbol{\mu}$の事前分布の確率変数がとり得る値$\boldsymbol{\mu}$を作成します。
# グラフ用のμの値を作成 mu_1_vec <- seq( mu_truth_d[1] - sqrt(sigma_mu_dd[1, 1]), mu_truth_d[1] + sqrt(sigma_mu_dd[1, 1]), length.out = 301 ) mu_2_vec <- seq( mu_truth_d[2] - sqrt(sigma_mu_dd[2, 2]), mu_truth_d[2] + sqrt(sigma_mu_dd[2, 2]), length.out = 301 ) # グラフ用のμの点を作成 mu_mat <- tidyr::expand_grid( mu_1 = mu_1_vec, mu_2 = mu_2_vec ) |> # 格子点を作成 as.matrix() # マトリクスに変換 head(mu_mat)
## mu_1 mu_2 ## [1,] -75 -50.00000 ## [2,] -75 -49.33333 ## [3,] -75 -48.66667 ## [4,] -75 -48.00000 ## [5,] -75 -47.33333 ## [6,] -75 -46.66667
$\mathbf{x}$と同様に、$\boldsymbol{\mu} = (\mu_1, \mu_2)^{\top}$がとり得る値を作成してmu_matとします。この例では、真の値を中心に事前分布の標準偏差を範囲とします。
$\boldsymbol{\mu}$の事前分布を計算します。
# μの事前分布(多次元ガウス分布)を計算:式(2.72) prior_df <- tibble::tibble( mu_1 = mu_mat[, 1], # x軸の値 mu_2 = mu_mat[, 2], # y軸の値 dens = mvnfast::dmvn(X = mu_mat, mu = m_d, sigma = sigma_mu_dd) # 確率密度 ) prior_df
## # A tibble: 90,601 × 3 ## mu_1 mu_2 dens ## <dbl> <dbl> <dbl> ## 1 -75 -50 0.0000106 ## 2 -75 -49.3 0.0000106 ## 3 -75 -48.7 0.0000107 ## 4 -75 -48 0.0000107 ## 5 -75 -47.3 0.0000107 ## 6 -75 -46.7 0.0000108 ## 7 -75 -46 0.0000108 ## 8 -75 -45.3 0.0000108 ## 9 -75 -44.7 0.0000109 ## 10 -75 -44 0.0000109 ## # … with 90,591 more rows
真の分布と同様に、mu_matの行ごとに確率密度を計算します。
$\boldsymbol{\mu}$の事前分布のグラフを作成します。
# 真のμを格納 param_df <- tibble::tibble( mu_1 = mu_truth_d[1], # x軸の値 mu_2 = mu_truth_d[2] # y軸の値 ) # パラメータラベル用の文字列を作成 prior_param_text <- paste0( "list(m==(list(", paste(round(m_d, 1), collapse = ", "), "))", ", Lambda[mu]==(list(", paste(round(lambda_mu_dd, 5), collapse = ", "), ")))" ) # μの事前分布を作図 ggplot() + geom_contour(data = prior_df, mapping = aes(x = mu_1, y = mu_2, z = dens, color = ..level..)) + # μの事前分布:(等高線図) #geom_contour_filled(data = prior_df, mapping = aes(x = mu_1, y = mu_2, z = dens, fill = ..level..), alpha = 0.8) + # μの事前分布:(塗りつぶし等高線図) geom_point(data = param_df, mapping = aes(x = mu_1, y = mu_2, shape = "param"), color = "red", size = 6) + # 真のμ scale_shape_manual(breaks = "param", values = 4, labels = "true parameter", name = "") + # (凡例表示用の黒魔術) labs(title = "Multivariate Gaussian Distribution", subtitle = parse(text = prior_param_text), color = "density", fill = "density", x = expression(mu[1]), y = expression(mu[2]))
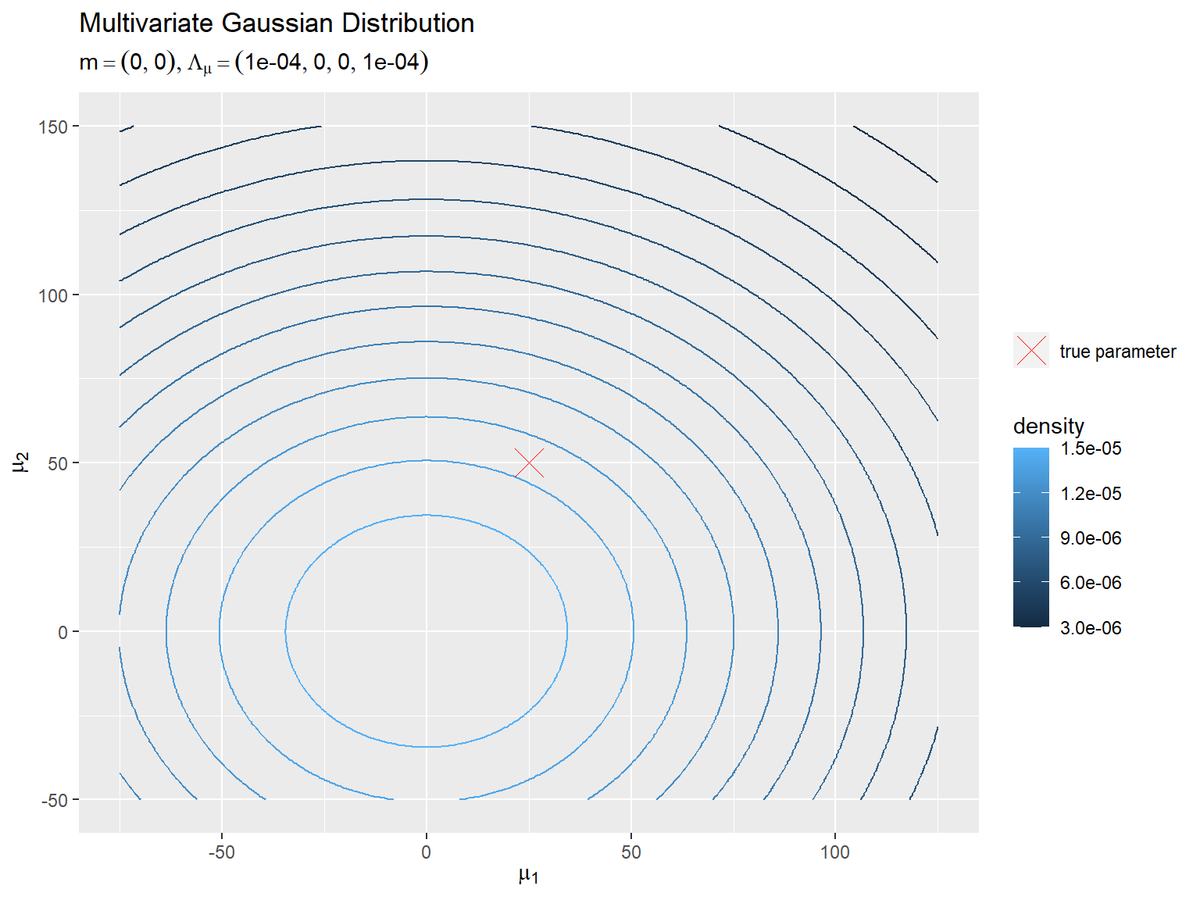
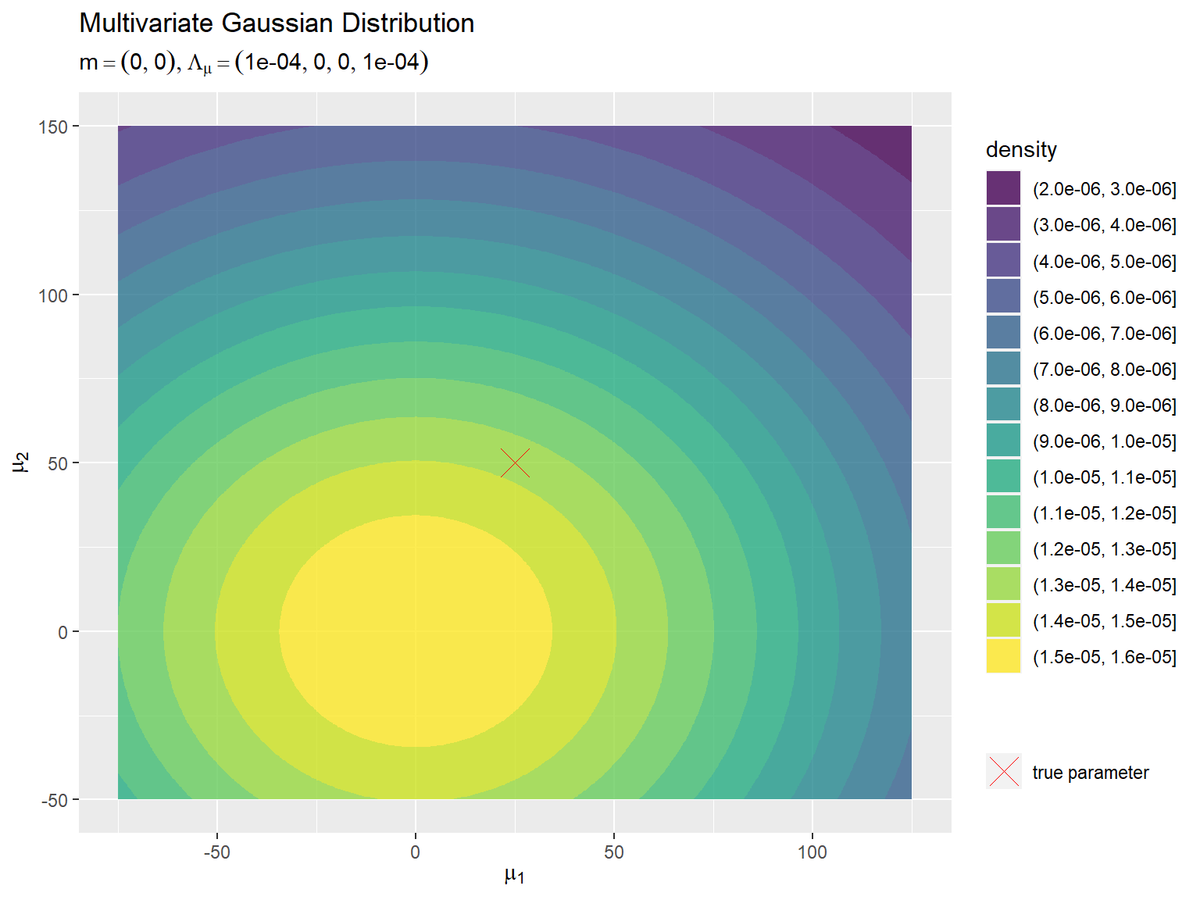
$\boldsymbol{\mu}$の真の値を赤色のバツ印で示します。
事後分布の計算
観測データ$\mathbf{X}$から平均パラメータ$\boldsymbol{\mu}$の事後分布$p(\boldsymbol{\mu} | \mathbf{X}) = \mathcal{N}(\boldsymbol{\mu} | \hat{\mathbf{m}}, \hat{\boldsymbol{\Lambda}}_{\boldsymbol{\mu}}^{-1})$を求めます(平均パラメータ$\boldsymbol{\mu}$を分布推定します)。
観測データ$\mathbf{X}$を用いて、$\boldsymbol{\mu}$の事後分布($D$次元ガウス分布)のパラメータ$\hat{\mathbf{m}}, \hat{\boldsymbol{\Lambda}}_{\boldsymbol{\mu}}$を計算します。
# μの事後分布の精度行列を計算:式(3.102) lambda_mu_hat_dd <- N * lambda_dd + lambda_mu_dd # μの事後分布の平均ベクトルを計算:式(3.103) m_hat_d <- (solve(lambda_mu_hat_dd) %*% (lambda_dd %*% colSums(x_nd) + lambda_mu_dd %*% m_d)) |> as.vector() m_hat_d; lambda_mu_hat_dd
## [1] 23.54102 49.23560 ## [,1] [,2] ## [1,] 0.11438571 0.02857143 ## [2,] 0.02857143 0.25724286
$\boldsymbol{\mu}$の事後分布のパラメータを次の式で計算します。
$\boldsymbol{\mu}$の事後分布を計算します。
# μの事後分布(多次元ガウス分布)を計算:式(2.72) posterior_df <- tibble::tibble( mu_1 = mu_mat[, 1], # x軸の値 mu_2 = mu_mat[, 2], # y軸の値 dens = mvnfast::dmvn(X = mu_mat, mu = m_hat_d, sigma = solve(lambda_mu_hat_dd)) # 確率密度 ) posterior_df
## # A tibble: 90,601 × 3 ## mu_1 mu_2 dens ## <dbl> <dbl> <dbl> ## 1 -75 -50 0 ## 2 -75 -49.3 0 ## 3 -75 -48.7 0 ## 4 -75 -48 0 ## 5 -75 -47.3 0 ## 6 -75 -46.7 0 ## 7 -75 -46 0 ## 8 -75 -45.3 0 ## 9 -75 -44.7 0 ## 10 -75 -44 0 ## # … with 90,591 more rows
更新した超パラメータm_hat_d, lambda_mu_hat_ddを使って、事前分布のときと同様にして処理します。
$\boldsymbol{\mu}$の事後分布のグラフを作成します。
# パラメータラベル用の文字列を作成 posterior_param_text <- paste0( "list(N ==", N, ", hat(m)==(list(", paste(round(m_hat_d, 1), collapse = ", "), "))", ", hat(Lambda)[mu]==(list(", paste(round(lambda_mu_hat_dd, 5), collapse = ", "), ")))" ) # μの事後分布を作図 ggplot() + geom_contour(data = posterior_df, mapping = aes(x = mu_1, y = mu_2, z = dens, color = ..level..)) + # μの事後分布:(等高線図) #geom_contour_filled(data = posterior_df, mapping = aes(x = mu_1, y = mu_2, z = dens, fill = ..level..), alpha = 0.8) + # μの事後分布:(塗りつぶし等高線図) geom_point(data = param_df, mapping = aes(x = mu_1, y = mu_2, shape = "param"), color = "red", size = 6) + # 真のμ scale_shape_manual(breaks = "param", values = 4, labels = "true parameter", name = "") + # (凡例表示用の黒魔術) #coord_cartesian(xlim = c(min(mu_1_vec), max(mu_1_vec)), ylim = c(min(mu_2_vec), max(mu_2_vec))) + # 表示範囲 labs(title = "Multivariate Gaussian Distribution", subtitle = parse(text = posterior_param_text), color = "density", fill = "density", x = expression(mu[1]), y = expression(mu[2]))
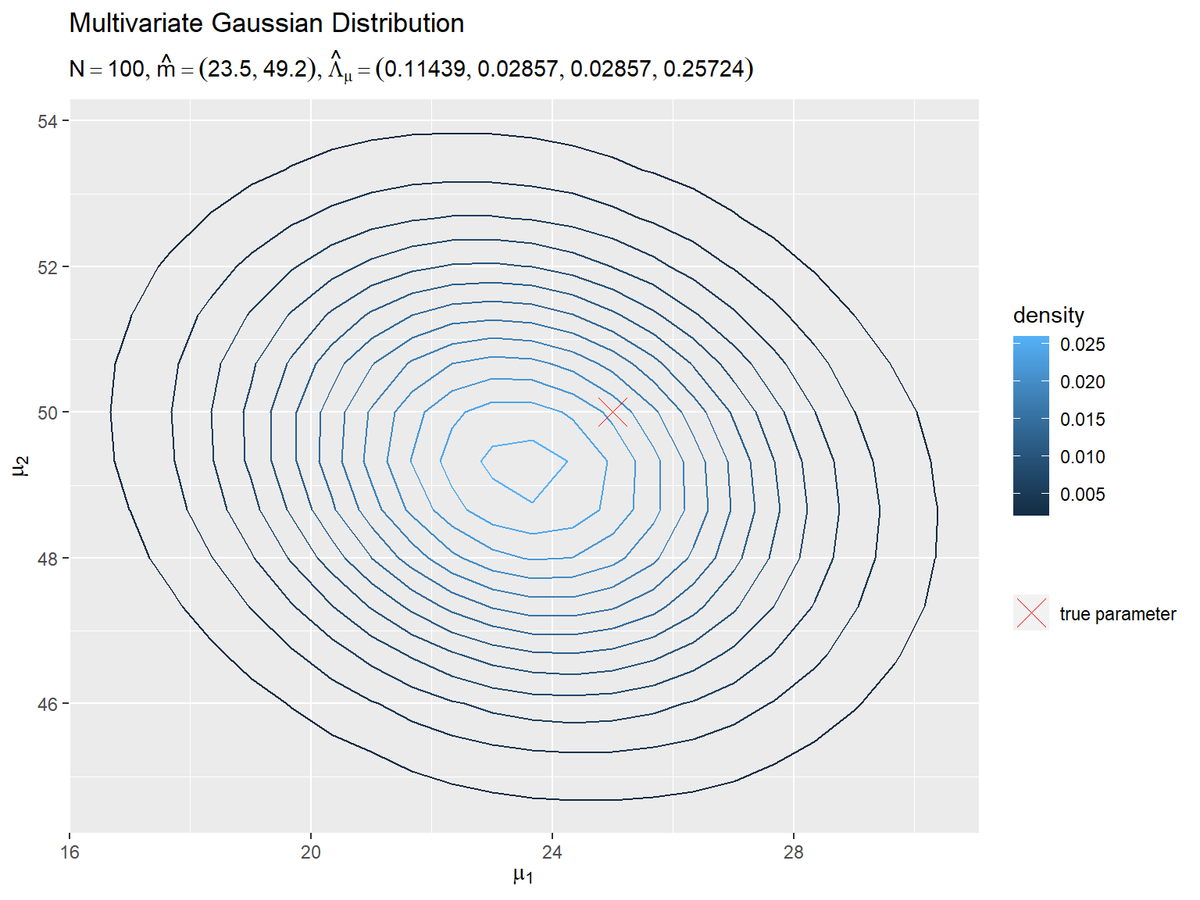
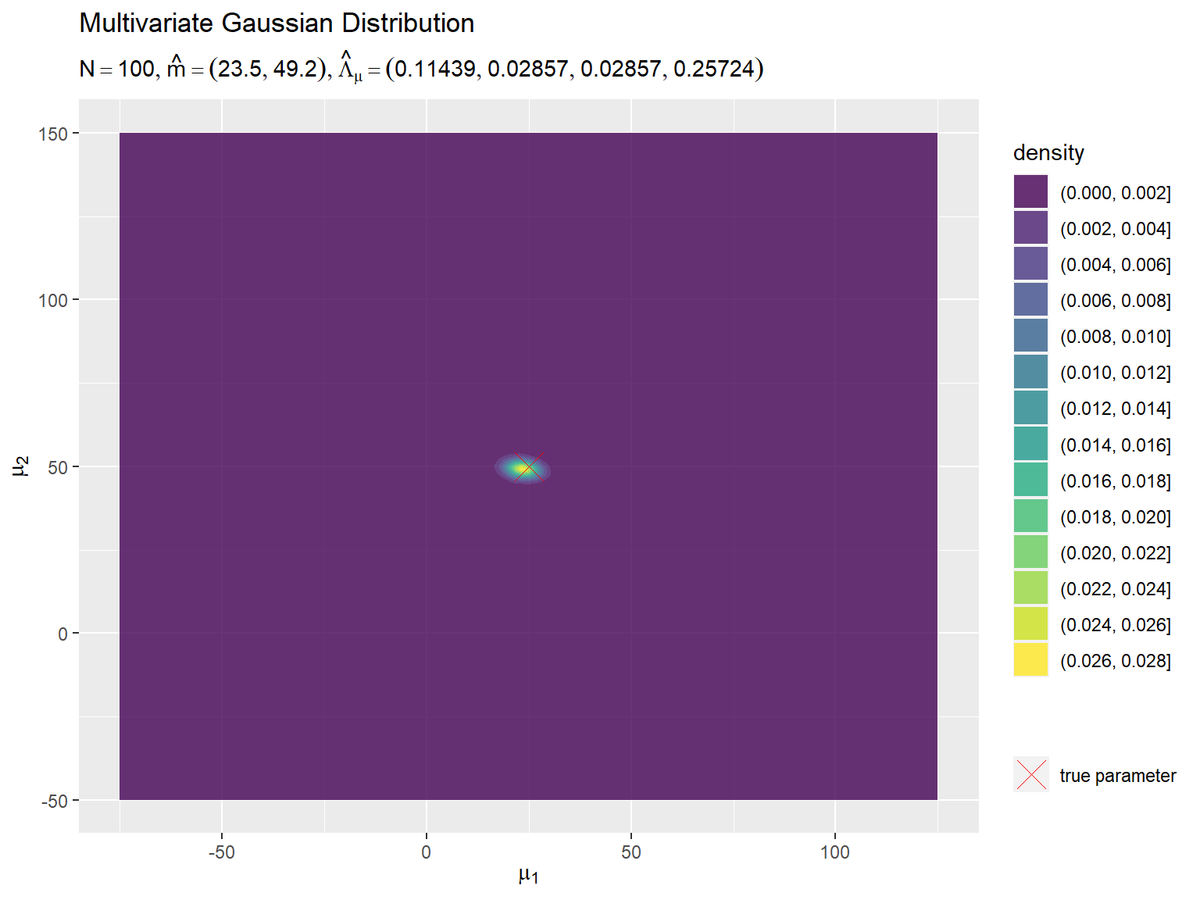
$\boldsymbol{\mu}$の真の値付近をピークとする分布になっています。左の図は、右の図を拡大した図になっています。そのため、描画に使う点の数が少なく、等高線が角張っています。
予測分布の計算
最後に、(観測データ$\mathbf{X}$から求めた)事後分布のパラメータ$\hat{\mathbf{m}}, \hat{\boldsymbol{\Lambda}}_{\boldsymbol{\mu}}$から未観測のデータ$\mathbf{x}_{*}$の予測分布$p(\mathbf{x}_{*} | \mathbf{X}) = \mathcal{N}(\mathbf{x}_{*} | \hat{\boldsymbol{\mu}}_{*}, \hat{\boldsymbol{\Lambda}}_{*}^{-1})$を求めます。
$\boldsymbol{\mu}$の事後分布のパラメータ$\hat{\mathbf{m}}, \hat{\boldsymbol{\Lambda}}_{\boldsymbol{\mu}}$を用いて、予測分布($D$次元ガウス分布)のパラメータ$\hat{\boldsymbol{\mu}}_{*}, \hat{\boldsymbol{\Lambda}}_{*}$を計算します。
# 予測分布の平均ベクトルを計算:式(3.110') mu_s_hat_d <- m_hat_d # 予測分布の精度行列を計算:式(3.109') lambda_s_hat_dd <- solve(solve(lambda_dd) + solve(lambda_mu_hat_dd)) mu_s_hat_d; lambda_s_hat_dd
## [1] 23.54102 49.23560 ## [,1] [,2] ## [1,] 0.0011315515 0.0002828854 ## [2,] 0.0002828854 0.0025459787
予測分布のパラメータを次の式で計算します。
予測分布を計算します。
# 予測分布(多次元ガウス分布)を計算:式(2.72) predict_df <- tibble::tibble( x_1 = x_mat[, 1], # x軸の値 x_2 = x_mat[, 2], # y軸の値 dens = mvnfast::dmvn(X = x_mat, mu = mu_s_hat_d, sigma = solve(lambda_s_hat_dd)) # 確率密度 ) predict_df
## # A tibble: 90,601 × 3 ## x_1 x_2 dens ## <dbl> <dbl> <dbl> ## 1 -65 -10 0.00000000822 ## 2 -65 -9.6 0.00000000882 ## 3 -65 -9.2 0.00000000946 ## 4 -65 -8.8 0.0000000101 ## 5 -65 -8.4 0.0000000109 ## 6 -65 -8 0.0000000116 ## 7 -65 -7.6 0.0000000124 ## 8 -65 -7.2 0.0000000133 ## 9 -65 -6.8 0.0000000142 ## 10 -65 -6.4 0.0000000152 ## # … with 90,591 more rows
求めたパラメータmu_s_hat_d, lambda_s_hat_ddを使って、真の分布のときと同様にして処理します。
予測分布のグラフを真の分布と重ねて作成します。
# パラメータラベル用の文字列を作成 predict_param_text <- paste0( "list(N==", N, ", hat(mu)[s]==(list(", paste(round(mu_s_hat_d, 1), collapse = ", "), "))", ", hat(Lambda)[s]==(list(", paste(round(lambda_s_hat_dd, 5), collapse = ", "), ")))" ) # 予測分布を作図 ggplot() + geom_contour(data = model_df, mapping = aes(x = x_1, y = x_2, z = dens, color = ..level..), alpha = 0.5, linetype = "dashed") + # 真の分布 geom_contour(data = predict_df, mapping = aes(x = x_1, y = x_2, z = dens, color = ..level..)) + # 予測分布:(等高線図) #geom_contour_filled(data = predict_df, mapping = aes(x = x_1, y = x_2, z = dens, fill = ..level..), alpha = 0.8) + # 予測分布:(塗りつぶし等高線図) labs(title = "Multivariate Gaussian Distribution", subtitle = parse(text = predict_param_text), color = "density", fill = "density", x = expression(x[1]), y = expression(x[2]))
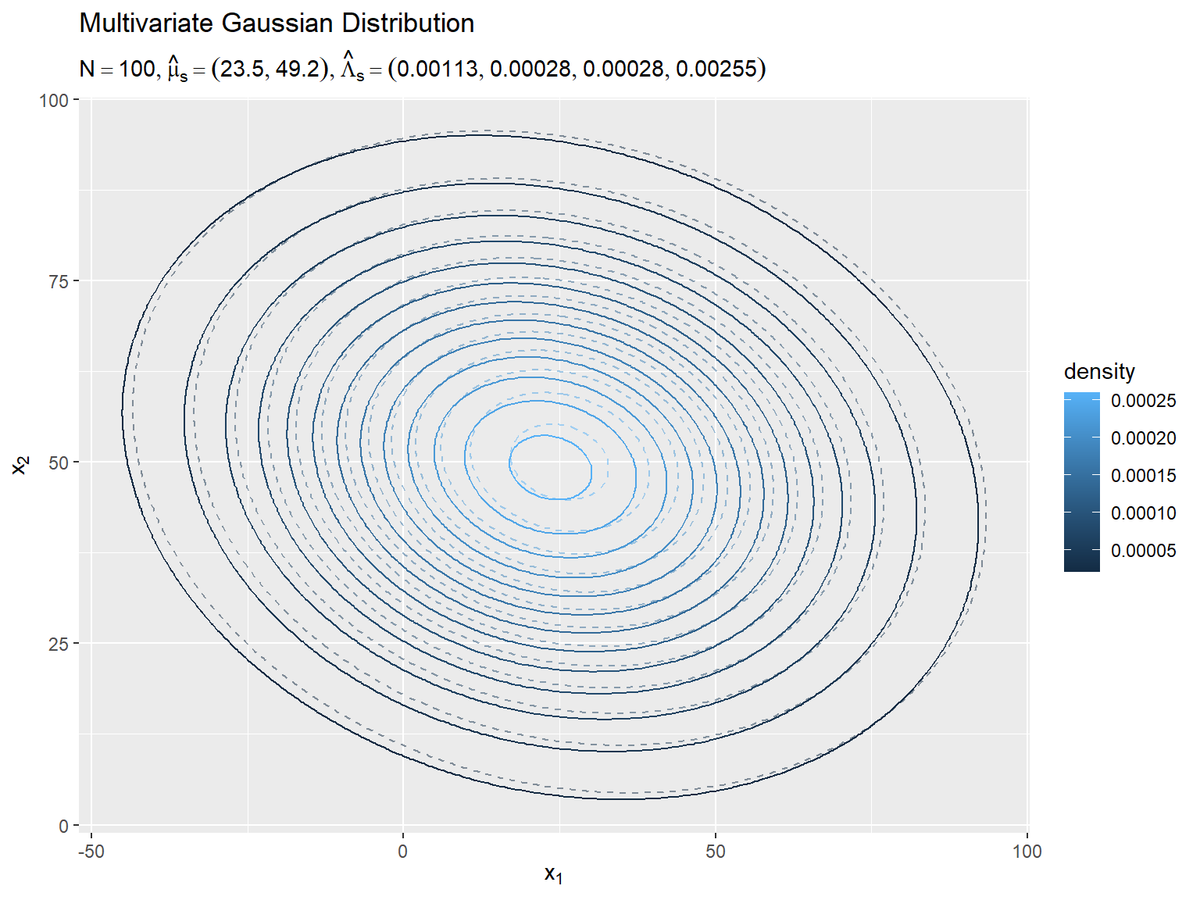
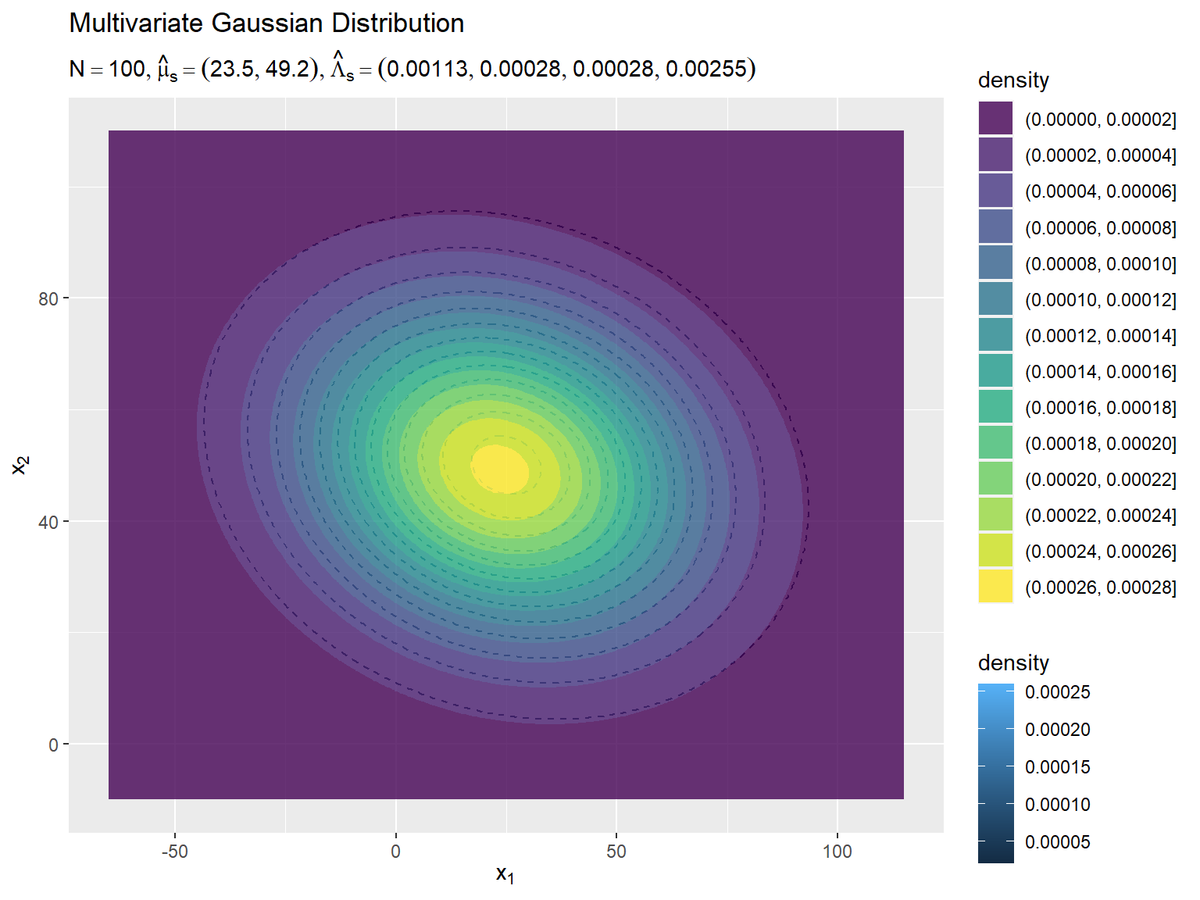
真の分布の等高線を破線で示します。
観測データが増えると、予測分布が真の分布に近付きます。
以上で、ガウス分布のベイズ推論を実装できました。
学習推移の可視化
gganimateパッケージを利用して、パラメータの推定値(更新値)の推移(分布の変化)をアニメーション(gif画像)で確認します。
モデルの設定
真の分布のパラメータ$\boldsymbol{\mu}, \boldsymbol{\Lambda}$と、$\boldsymbol{\mu}$の事前分布のパラメータ(の初期値)$\mathbf{m}, \boldsymbol{\Lambda}_{\boldsymbol{\mu}}$、試行回数$N$を設定します。
# 次元数を指定 D <- 2 # 真の平均ベクトルを指定 mu_truth_d <- c(25, 50) # (既知の)分散共分散行列を指定 sigma_dd <- matrix(c(900, -100, -100, 400), nrow = D, ncol = D) # (既知の)精度行列を計算 lambda_dd <- solve(sigma_dd) # μの事前分布の平均ベクトルを指定 m_d <- rep(0, times = D) # μの事前分布の分散共分散行列を指定 sigma_mu_dd <- diag(D) * 10000 # μの事前分布の精度行列を計算 lambda_mu_dd <- solve(sigma_mu_dd) # データ数(試行回数)を指定 N <- 100
「ベイズ推論の実装」と同じく、パラメータを指定します。
・コード(クリックで展開)
真の分布の確率変数がとり得る値$\mathbf{x}$と、事前分布がとり得る値$\boldsymbol{\mu}$を作成します。
# グラフ用のμの値を作成 mu_1_vec <- seq( mu_truth_d[1] - sqrt(sigma_mu_dd[1, 1]), mu_truth_d[1] + sqrt(sigma_mu_dd[1, 1]), length.out = 201 ) mu_2_vec <- seq( mu_truth_d[2] - sqrt(sigma_mu_dd[2, 2]), mu_truth_d[2] + sqrt(sigma_mu_dd[2, 2]), length.out = 201 ) # グラフ用のμの点を作成 mu_mat <- tidyr::expand_grid(mu_1 = mu_1_vec, mu_2 = mu_2_vec ) |> # 格子点を作成 as.matrix() # マトリクスに変換 # グラフ用のxの値を作成 x_1_vec <- seq( mu_truth_d[1] - sqrt(sigma_dd[1, 1]) * 3, mu_truth_d[1] + sqrt(sigma_dd[1, 1]) * 3, length.out = 201 ) x_2_vec <- seq( mu_truth_d[2] - sqrt(sigma_dd[2, 2]) * 3, mu_truth_d[2] + sqrt(sigma_dd[2, 2]) * 3, length.out = 201 ) # グラフ用のxの点を作成 x_mat <- tidyr::expand_grid(x_1 = x_1_vec, x_2 = x_2_vec) |> # 格子点を作成 as.matrix() # マトリクスに変換
確率変数がとり得る値(x軸とy軸の値)を作成します。グラフが粗い場合や処理が重い場合は、mu_*_vec, x_*_vecの要素数(by引数の値)または値の間隔(length.out引数の値)を調整してください。
事後分布と予測分布のパラメータの計算(更新)処理について、2通りの方法を載せます。目的に応じて使い分けてください。
推論処理:for関数による処理
1つ目の処理方法では、for()を使って、1データずつ生成してパラメータの更新を繰り返し処理します。こちらの方が、前ステップで求めた事後分布(のパラメータ)を次ステップの事前分布(のパラメータ)として用いる逐次学習をイメージしやすいです。
・コード(クリックで展開)
超パラメータの初期値を使って、事前分布を計算します。
# μの事前分布(多次元ガウス分布)を計算:式(2.72) anime_posterior_df <- tibble::tibble( mu_1 = mu_mat[, 1], mu_2 = mu_mat[, 2], dens = mvnfast::dmvn(X = mu_mat, mu = m_d, sigma = solve(lambda_mu_dd)), # 確率密度 param = paste0( "N=", 0, ", m=(", paste(round(m_d, 1), collapse = ", "), ")", ", lambda_mu=(", paste(round(lambda_mu_dd, 5), collapse = ", "), ")" ) |> as.factor() # フレーム切替用ラベル ) anime_posterior_df
## # A tibble: 40,401 × 4 ## mu_1 mu_2 dens param ## <dbl> <dbl> <dbl> <fct> ## 1 -75 -50 0.0000106 N=0, m=(0, 0), lambda_mu=(1e-04, 0, 0, 1e-04) ## 2 -75 -49 0.0000107 N=0, m=(0, 0), lambda_mu=(1e-04, 0, 0, 1e-04) ## 3 -75 -48 0.0000107 N=0, m=(0, 0), lambda_mu=(1e-04, 0, 0, 1e-04) ## 4 -75 -47 0.0000108 N=0, m=(0, 0), lambda_mu=(1e-04, 0, 0, 1e-04) ## 5 -75 -46 0.0000108 N=0, m=(0, 0), lambda_mu=(1e-04, 0, 0, 1e-04) ## 6 -75 -45 0.0000109 N=0, m=(0, 0), lambda_mu=(1e-04, 0, 0, 1e-04) ## 7 -75 -44 0.0000109 N=0, m=(0, 0), lambda_mu=(1e-04, 0, 0, 1e-04) ## 8 -75 -43 0.0000110 N=0, m=(0, 0), lambda_mu=(1e-04, 0, 0, 1e-04) ## 9 -75 -42 0.0000110 N=0, m=(0, 0), lambda_mu=(1e-04, 0, 0, 1e-04) ## 10 -75 -41 0.0000110 N=0, m=(0, 0), lambda_mu=(1e-04, 0, 0, 1e-04) ## # … with 40,391 more rows
現在のパラメータを文字列結合し因子型に変換して、フレーム切替用のラベル列とします。
また、事前分布のパラメータを使って、予測分布のパラメータと予測分布を計算します。
# 初期値による予測分布のパラメータを計算:式(3.109-10) mu_s_d <- m_d lambda_s_dd <- solve(solve(lambda_dd) + solve(lambda_mu_dd)) # 予測分布(多次元ガウス分布)を計算:式(2.72) anime_predict_df <- tibble::tibble( x_1 = x_mat[, 1], x_2 = x_mat[, 2], dens = mvnfast::dmvn(X = x_mat, mu = mu_s_d, sigma = solve(lambda_s_dd)), # 確率密度 param = paste0( "N=", 0, ", mu_s=(", paste(round(mu_s_d, 1), collapse = ", "), ")", ", lambda_s=(", paste(round(lambda_s_dd, 5), collapse = ", "), ")" ) |> as.factor() # フレーム切替用ラベル ) anime_predict_df
## # A tibble: 40,401 × 4 ## x_1 x_2 dens param ## <dbl> <dbl> <dbl> <fct> ## 1 -65 -10 0.0000122 N=0, mu_s=(0, 0), lambda_s=(9e-05, 0, 0, 1e-04) ## 2 -65 -9.4 0.0000123 N=0, mu_s=(0, 0), lambda_s=(9e-05, 0, 0, 1e-04) ## 3 -65 -8.8 0.0000123 N=0, mu_s=(0, 0), lambda_s=(9e-05, 0, 0, 1e-04) ## 4 -65 -8.2 0.0000123 N=0, mu_s=(0, 0), lambda_s=(9e-05, 0, 0, 1e-04) ## 5 -65 -7.6 0.0000123 N=0, mu_s=(0, 0), lambda_s=(9e-05, 0, 0, 1e-04) ## 6 -65 -7 0.0000123 N=0, mu_s=(0, 0), lambda_s=(9e-05, 0, 0, 1e-04) ## 7 -65 -6.4 0.0000123 N=0, mu_s=(0, 0), lambda_s=(9e-05, 0, 0, 1e-04) ## 8 -65 -5.8 0.0000123 N=0, mu_s=(0, 0), lambda_s=(9e-05, 0, 0, 1e-04) ## 9 -65 -5.2 0.0000123 N=0, mu_s=(0, 0), lambda_s=(9e-05, 0, 0, 1e-04) ## 10 -65 -4.6 0.0000123 N=0, mu_s=(0, 0), lambda_s=(9e-05, 0, 0, 1e-04) ## # … with 40,391 more rows
同様に、フレーム切替用のラベル列を作成します。
パラメータの更新処理をN回繰り返します。
# 観測データの受け皿を作成 x_nd <- matrix(NA, nrow = N, ncol = D) # ベイズ推論 for(n in 1:N) { # 多次元ガウス分布に従うデータを生成 x_nd[n, ] <- mvnfast::rmvn(n = 1, mu = mu_truth_d, sigma = sigma_dd) |> as.vector() # μの事後分布のパラメータを更新:式(3.102-3) old_lambda_mu_dd <- lambda_mu_dd lambda_mu_dd <- lambda_dd + lambda_mu_dd m_d <- solve(lambda_mu_dd) %*% (lambda_dd %*% x_nd[n, ] + old_lambda_mu_dd %*% m_d) |> as.vector() # μの事後分布(多次元ガウス分布)を計算:式(2.72) tmp_posterior_df <- tibble::tibble( mu_1 = mu_mat[, 1], mu_2 = mu_mat[, 2], dens = mvnfast::dmvn(X = mu_mat, mu = m_d, sigma = solve(lambda_mu_dd)), # 確率密度 param = paste0( "N=", n, ", m=(", paste(round(m_d, 1), collapse = ", "), ")", ", lambda_mu=(", paste(round(lambda_mu_dd, 5), collapse = ", "), ")" ) |> as.factor() # フレーム切替用ラベル ) # 予測分布のパラメータを更新:式(3.109-10) mu_s_d <- m_d lambda_s_dd <- solve(solve(lambda_dd) + solve(lambda_mu_dd)) # 予測分布(多次元ガウス分布)を計算:式(2.72) tmp_predict_df <- tibble::tibble( x_1 = x_mat[, 1], x_2 = x_mat[, 2], dens = mvnfast::dmvn(X = x_mat, mu = mu_s_d, sigma = solve(lambda_s_dd)), # 確率密度 param = paste0( "N=", n, ", mu_s=(", paste(round(mu_s_d, 1), collapse = ", "), ")", ", lambda_s=(", paste(round(lambda_s_dd, 5), collapse = ", "), ")" ) |> as.factor() # フレーム切替用ラベル ) # 推論結果を結合 anime_posterior_df <- rbind(anime_posterior_df, tmp_posterior_df) anime_predict_df <- rbind(anime_predict_df, tmp_predict_df) # 動作確認 #print(paste0("n=", n, " (", round(n / N * 100, 1), "%)")) }
超パラメータに関して、$\hat{\mathbf{m}}, \hat{\boldsymbol{\Lambda}}_{\boldsymbol{\mu}}$に対応するm_hat_d, lambda_mu_hat_ddを新たに作るのではなく、m_d, lambda_mu_ddを繰り返し更新(上書き)していきます。これにより、事後分布のパラメータの計算式(3.102),(3.103)の$N \boldsymbol{\Lambda}$と$\sum_{n=1}^N \mathbf{x}_n$の計算は、ループ処理によってN回繰り返しlambda_ddとx_nd[n, ]を加えることで行います。n回目のループ処理のときには、n-1回分のlambda_ddとx_nd[n, ]が既にm_dとlambda_mu_ddに加えられています。ただし、更新前(1ステップ前)のパラメータを使うため、old_lambda_mu_ddとして値を一時的に保存しておきます。
更新したパラメータを使って事後分布と予測分布を計算して、それぞれ計算結果をanime_***_dfに結合していきます。
結果を確認します。
# 確認 head(x_nd); anime_posterior_df; anime_predict_df
## [,1] [,2] ## [1,] 29.493750 62.67222 ## [2,] -4.759984 42.71972 ## [3,] 7.334008 43.78913 ## [4,] 34.794634 86.12035 ## [5,] 32.627858 36.96906 ## [6,] 35.095138 62.04701 ## # A tibble: 4,080,501 × 4 ## mu_1 mu_2 dens param ## <dbl> <dbl> <dbl> <fct> ## 1 -75 -50 0.0000106 N=0, m=(0, 0), lambda_mu=(1e-04, 0, 0, 1e-04) ## 2 -75 -49 0.0000107 N=0, m=(0, 0), lambda_mu=(1e-04, 0, 0, 1e-04) ## 3 -75 -48 0.0000107 N=0, m=(0, 0), lambda_mu=(1e-04, 0, 0, 1e-04) ## 4 -75 -47 0.0000108 N=0, m=(0, 0), lambda_mu=(1e-04, 0, 0, 1e-04) ## 5 -75 -46 0.0000108 N=0, m=(0, 0), lambda_mu=(1e-04, 0, 0, 1e-04) ## 6 -75 -45 0.0000109 N=0, m=(0, 0), lambda_mu=(1e-04, 0, 0, 1e-04) ## 7 -75 -44 0.0000109 N=0, m=(0, 0), lambda_mu=(1e-04, 0, 0, 1e-04) ## 8 -75 -43 0.0000110 N=0, m=(0, 0), lambda_mu=(1e-04, 0, 0, 1e-04) ## 9 -75 -42 0.0000110 N=0, m=(0, 0), lambda_mu=(1e-04, 0, 0, 1e-04) ## 10 -75 -41 0.0000110 N=0, m=(0, 0), lambda_mu=(1e-04, 0, 0, 1e-04) ## # … with 4,080,491 more rows ## # A tibble: 4,080,501 × 4 ## x_1 x_2 dens param ## <dbl> <dbl> <dbl> <fct> ## 1 -65 -10 0.0000122 N=0, mu_s=(0, 0), lambda_s=(9e-05, 0, 0, 1e-04) ## 2 -65 -9.4 0.0000123 N=0, mu_s=(0, 0), lambda_s=(9e-05, 0, 0, 1e-04) ## 3 -65 -8.8 0.0000123 N=0, mu_s=(0, 0), lambda_s=(9e-05, 0, 0, 1e-04) ## 4 -65 -8.2 0.0000123 N=0, mu_s=(0, 0), lambda_s=(9e-05, 0, 0, 1e-04) ## 5 -65 -7.6 0.0000123 N=0, mu_s=(0, 0), lambda_s=(9e-05, 0, 0, 1e-04) ## 6 -65 -7 0.0000123 N=0, mu_s=(0, 0), lambda_s=(9e-05, 0, 0, 1e-04) ## 7 -65 -6.4 0.0000123 N=0, mu_s=(0, 0), lambda_s=(9e-05, 0, 0, 1e-04) ## 8 -65 -5.8 0.0000123 N=0, mu_s=(0, 0), lambda_s=(9e-05, 0, 0, 1e-04) ## 9 -65 -5.2 0.0000123 N=0, mu_s=(0, 0), lambda_s=(9e-05, 0, 0, 1e-04) ## 10 -65 -4.6 0.0000123 N=0, mu_s=(0, 0), lambda_s=(9e-05, 0, 0, 1e-04) ## # … with 4,080,491 more rows
それぞれ「mu_mat, x_matの行数」掛ける「N+1」行のデータフレームになります。行数が増えすぎないように注意してください。
推論処理:tidyverseパッケージによる処理
2つ目の処理方法では、tidyverseパッケージの関数を使って、一度の処理でN+1回分の計算をします。こちらの方が、処理時間が短いです(が、こんな処理をしていいのかは知りません)。
・コード(クリックで展開)
ガウス分布に従う$N$個のデータを生成します。
# 多次元ガウス分布に従うデータを生成 x_nd <- mvnfast::rmvn(n = N, mu = mu_truth_d, sigma = sigma_dd) head(x_nd)
## [,1] [,2] ## [1,] 29.493750 62.67222 ## [2,] -4.759984 42.71972 ## [3,] 7.334008 43.78913 ## [4,] 34.794634 86.12035 ## [5,] 32.627858 36.96906 ## [6,] 35.095138 62.04701
事前分布を含めたN+1回分の事後分布を計算します。
# 試行ごとにμの事後分布を計算 anime_posterior_df <- tidyr::expand_grid( n = 0:N, # データ番号(試行回数) mu_1 = mu_1_vec, mu_2 = mu_2_vec ) |> # 試行ごとに格子点を複製 dplyr::group_by(n) |> # 分布の計算用にグループ化 dplyr::mutate( # μの事後分布のパラメータを計算:式(3.102-3) lambda_mu_lt = (unique(n) * lambda_dd + lambda_mu_dd) |> list(), # リストに格納 m_lt = dplyr::if_else( n > 0, # 事前分布を除く true = (solve(lambda_mu_lt[[1]]) %*% (lambda_dd %*% colSums(x_nd[0:unique(n), , drop = FALSE]) + lambda_mu_dd %*% m_d)) |> as.vector() |> list(), # リストに格納 false = m_d |> list() # リストに格納 ), # μの事後分布(多次元ガウス分布)を計算:式(2.72) dens = mvnfast::dmvn( X = mu_mat, mu = m_lt[[1]], sigma = solve(lambda_mu_lt[[1]]) ), # 確率密度 param = paste0( "N=", unique(n), ", m=(", paste(round(m_lt[[1]], 1), collapse = ", "), ")", ", lambda_mu=(", paste(round(lambda_mu_lt[[1]], 5), collapse = ", "), ")" ) |> (\(.){factor(., levels = unique(.))})() # フレーム切替用ラベル ) |> dplyr::ungroup() # グループ化を解除 anime_posterior_df
## # A tibble: 4,080,501 × 7 ## n mu_1 mu_2 lambda_mu_lt m_lt dens param ## <int> <dbl> <dbl> <list> <list> <dbl> <fct> ## 1 0 -75 -50 <dbl [2 × 2]> <dbl [2]> 0.0000106 N=0, m=(0, 0), lambda_mu… ## 2 0 -75 -49 <dbl [2 × 2]> <dbl [2]> 0.0000107 N=0, m=(0, 0), lambda_mu… ## 3 0 -75 -48 <dbl [2 × 2]> <dbl [2]> 0.0000107 N=0, m=(0, 0), lambda_mu… ## 4 0 -75 -47 <dbl [2 × 2]> <dbl [2]> 0.0000108 N=0, m=(0, 0), lambda_mu… ## 5 0 -75 -46 <dbl [2 × 2]> <dbl [2]> 0.0000108 N=0, m=(0, 0), lambda_mu… ## 6 0 -75 -45 <dbl [2 × 2]> <dbl [2]> 0.0000109 N=0, m=(0, 0), lambda_mu… ## 7 0 -75 -44 <dbl [2 × 2]> <dbl [2]> 0.0000109 N=0, m=(0, 0), lambda_mu… ## 8 0 -75 -43 <dbl [2 × 2]> <dbl [2]> 0.0000110 N=0, m=(0, 0), lambda_mu… ## 9 0 -75 -42 <dbl [2 × 2]> <dbl [2]> 0.0000110 N=0, m=(0, 0), lambda_mu… ## 10 0 -75 -41 <dbl [2 × 2]> <dbl [2]> 0.0000110 N=0, m=(0, 0), lambda_mu… ## # … with 4,080,491 more rows
観測データ数(試行回数)を表す0からNまでのN+1個の整数と、x軸とy軸の値mu_1_vec, mu_2_vecの全ての組み合わせをexpand_grid()で作成します。これにより、mu_matに対応する行をN+1フレーム分に複製できます。
n列でグループ化することで、mu_matごとに確率密度を計算できます。
事前分布とN回分の事後分布のパラメータ$\hat{\boldsymbol{\mu}}, \hat{\boldsymbol{\Lambda}}_{\boldsymbol{\mu}}$をそれぞれ上手いこと計算してリストに格納します(もっといい処理方法があれば教えてください)。
確率変数(mu_matの各行)とパラメータ(n列の値)の組み合わせごとに確率密度を計算して、パラメータごとにフレーム切替用のラベルを作成します。
因子型への変換処理では、無名関数function()の省略記法\()を使って、(\(引数){引数を使った具体的な処理})()としています。直前のパイプ演算子を%>%にすると、行全体(\(引数){処理})()を{}の中の処理(この例だとfactor(., levels = unique(.)))に置き換えられます(置き換えられるように引数名を.にしています)。
同様に、初期値を含めたN+1回分の予測分布を計算します。
# 試行ごとに予測分布を計算 anime_predict_df <- tidyr::expand_grid( n = 0:N, # データ番号(試行回数) x_1 = x_1_vec, x_2 = x_2_vec ) |> # 試行ごとに格子点を複製 dplyr::group_by(n) |> # 分布の計算用にグループ化 dplyr::mutate( # μの事後分布のパラメータを計算:式(3.102) lambda_mu_lt = (unique(n) * lambda_dd + lambda_mu_dd) |> list(), # リストに格納 # 予測分布のパラメータを計算:式(3.103,9') mu_s_lt = dplyr::if_else( n > 0, # 事前分布を除く true = (solve(lambda_mu_lt[[1]]) %*% (lambda_dd %*% colSums(x_nd[0:unique(n), , drop = FALSE]) + lambda_mu_dd %*% m_d)) |> as.vector() |> list(), # リストに格納 false = m_d |> list() # リストに格納 ), sigma_s_lt = (solve(lambda_dd) + solve(lambda_mu_lt[[1]])) |> list(), # 予測分布(多次元ガウス分布)を計算:式(2.72) dens = mvnfast::dmvn( X = x_mat, mu = mu_s_lt[[1]], sigma = sigma_s_lt[[1]] ), # 確率密度 param = paste0( "N=", unique(n), ", mu_s=(", paste(round(mu_s_lt[[1]], 1), collapse = ", "), ")", ", lambda_s=(", paste(round(solve(sigma_s_lt[[1]]), 5), collapse = ", "), ")" ) |> (\(.){factor(., levels = unique(.))})() # フレーム切替用ラベル ) |> dplyr::ungroup() # グループ化を解除 anime_predict_df
## # A tibble: 4,080,501 × 8 ## n x_1 x_2 lambda_mu_lt mu_s_lt sigma_s_lt dens param ## <int> <dbl> <dbl> <list> <list> <list> <dbl> <fct> ## 1 0 -65 -10 <dbl [2 × 2]> <dbl [2]> <dbl [2 × 2]> 0.0000122 N=0, mu_s=… ## 2 0 -65 -9.4 <dbl [2 × 2]> <dbl [2]> <dbl [2 × 2]> 0.0000123 N=0, mu_s=… ## 3 0 -65 -8.8 <dbl [2 × 2]> <dbl [2]> <dbl [2 × 2]> 0.0000123 N=0, mu_s=… ## 4 0 -65 -8.2 <dbl [2 × 2]> <dbl [2]> <dbl [2 × 2]> 0.0000123 N=0, mu_s=… ## 5 0 -65 -7.6 <dbl [2 × 2]> <dbl [2]> <dbl [2 × 2]> 0.0000123 N=0, mu_s=… ## 6 0 -65 -7 <dbl [2 × 2]> <dbl [2]> <dbl [2 × 2]> 0.0000123 N=0, mu_s=… ## 7 0 -65 -6.4 <dbl [2 × 2]> <dbl [2]> <dbl [2 × 2]> 0.0000123 N=0, mu_s=… ## 8 0 -65 -5.8 <dbl [2 × 2]> <dbl [2]> <dbl [2 × 2]> 0.0000123 N=0, mu_s=… ## 9 0 -65 -5.2 <dbl [2 × 2]> <dbl [2]> <dbl [2 × 2]> 0.0000123 N=0, mu_s=… ## 10 0 -65 -4.6 <dbl [2 × 2]> <dbl [2]> <dbl [2 × 2]> 0.0000123 N=0, mu_s=… ## # … with 4,080,491 more rows
0からNまでの整数と、x軸とy軸の値x_1_vec, x_2_vecの全ての組み合わせを作成して、同様に処理します。
作図処理
事後分布と予測分布の推移をそれぞれアニメーションで可視化します。
・コード(クリックで展開)
観測データと対応するラベルをデータフレームに格納します。
# 観測データを格納 anime_data_df <- tibble::tibble( x_1 = c(NA, x_nd[, 1]), # x軸の値 x_2 = c(NA, x_nd[, 2]), # y軸の値 param = unique(anime_posterior_df[["param"]]) # フレーム切替用ラベル ) anime_data_df
## # A tibble: 101 × 3 ## x_1 x_2 param ## <dbl> <dbl> <fct> ## 1 NA NA N=0, m=(0, 0), lambda_mu=(1e-04, 0, 0, 1e-04) ## 2 29.5 62.7 N=1, m=(27.6, 60.5), lambda_mu=(0.00124, 0.00029, 0.00029, 0.00… ## 3 -4.76 42.7 N=2, m=(12.1, 51.7), lambda_mu=(0.00239, 0.00057, 0.00057, 0.00… ## 4 7.33 43.8 N=3, m=(10.5, 49.1), lambda_mu=(0.00353, 0.00086, 0.00086, 0.00… ## 5 34.8 86.1 N=4, m=(16.5, 58.3), lambda_mu=(0.00467, 0.00114, 0.00114, 0.01… ## 6 32.6 37.0 N=5, m=(19.7, 54.1), lambda_mu=(0.00581, 0.00143, 0.00143, 0.01… ## 7 35.1 62.0 N=6, m=(22.2, 55.4), lambda_mu=(0.00696, 0.00171, 0.00171, 0.01… ## 8 -12.2 68.2 N=7, m=(17.3, 57.2), lambda_mu=(0.0081, 0.002, 0.002, 0.0181) ## 9 105. 43.4 N=8, m=(28.2, 55.5), lambda_mu=(0.00924, 0.00229, 0.00229, 0.02… ## 10 34.2 47.0 N=9, m=(28.8, 54.6), lambda_mu=(0.01039, 0.00257, 0.00257, 0.02… ## # … with 91 more rows
事前分布には観測データが影響しないので欠損値NAとして、anime_posterior_dfのラベル列と合わせて格納します。
参考として、各試行における観測データを描画するのに使います。
事後分布の推移のアニメーションを作成します。
# 真のμを格納 param_df <- tibble::tibble( mu_1 = mu_truth_d[1], # x軸の値 mu_2 = mu_truth_d[2] # y軸の値 ) # μの事後分布のアニメーションを作図 anime_posterior_graph <- ggplot() + geom_contour(data = anime_posterior_df, mapping = aes(x = mu_1, y = mu_2, z = dens, color = ..level..)) + # μの事後分布:(等高線図) #geom_contour_filled(data = anime_posterior_df, mapping = aes(x = mu_1, y = mu_2, z = dens, fill = ..level..), alpha = 0.8) + # μの事後分布:(塗りつぶし等高線図) geom_point(data = param_df, mapping = aes(x = mu_1, y = mu_2, shape = "param"), color = "red", size = 6) + # 真のμ geom_point(data = anime_data_df, mapping = aes(x = x_1, y = x_2, shape = "data"), color = "orange", size = 3) + # 観測データ gganimate::transition_manual(param) + # フレーム scale_shape_manual(breaks = c("param", "data"), values = c(4, 19), labels = c("true parameter", "observation data"), name = "") + # (凡例表示用の黒魔術) guides(shape = guide_legend(override.aes = list(color = c("red", "orange"), size = c(6, 3), shape = c(4, 19)))) + # (凡例表示用の黒魔術) #coord_cartesian(xlim = c(min(mu_1_vec), max(mu_2_vec)), ylim = c(min(mu_2_vec), max(mu_2_vec))) + # 表示範囲 labs(title = "Multivariate Gaussian Distribution", subtitle = "{current_frame}", color = "density", fill = "density", x = expression(mu[1]), y = expression(mu[2])) # gif画像を作成 gganimate::animate(anime_posterior_graph, nframes = N+1+10, end_pause = 10, fps = 10, width = 800, height = 600)
フレームの順番を示す列をtransition_manual()に指定して、animate()でgif画像を作成します。事前分布(初期値)を含むため、フレーム数はN+1です。
続いて、anime_predict_dfのラベル列を使って観測データを格納します。
# 観測データを格納 anime_data_df <- tibble::tibble( x_1 = c(NA, x_nd[, 1]), # x軸の値 x_2 = c(NA, x_nd[, 2]), # y軸の値 param = unique(anime_predict_df[["param"]]) # フレーム切替用ラベル ) anime_data_df
## # A tibble: 101 × 3 ## x_1 x_2 param ## <dbl> <dbl> <fct> ## 1 NA NA N=0, mu_s=(0, 0), lambda_s=(9e-05, 0, 0, 1e-04) ## 2 29.5 62.7 N=1, mu_s=(27.6, 60.5), lambda_s=(6e-04, 0.00014, 0.00014, 0.00… ## 3 -4.76 42.7 N=2, mu_s=(12.1, 51.7), lambda_s=(0.00077, 0.00019, 0.00019, 0.… ## 4 7.33 43.8 N=3, mu_s=(10.5, 49.1), lambda_s=(0.00086, 0.00021, 0.00021, 0.… ## 5 34.8 86.1 N=4, mu_s=(16.5, 58.3), lambda_s=(0.00092, 0.00023, 0.00023, 0.… ## 6 32.6 37.0 N=5, mu_s=(19.7, 54.1), lambda_s=(0.00096, 0.00024, 0.00024, 0.… ## 7 35.1 62.0 N=6, mu_s=(22.2, 55.4), lambda_s=(0.00098, 0.00024, 0.00024, 0.… ## 8 -12.2 68.2 N=7, mu_s=(17.3, 57.2), lambda_s=(0.001, 0.00025, 0.00025, 0.00… ## 9 105. 43.4 N=8, mu_s=(28.2, 55.5), lambda_s=(0.00102, 0.00025, 0.00025, 0.… ## 10 34.2 47.0 N=9, mu_s=(28.8, 54.6), lambda_s=(0.00103, 0.00026, 0.00026, 0.… ## # … with 91 more rows
各試行における観測データを描画するのに使います。
また、各試行までの観測データを格納します。
# 過去の観測データを格納 anime_alldata_df <- tidyr::expand_grid( frame = 1:N, # フレーム番号 n = 1:N # 試行回数 ) |> # 全ての組み合わせを作成 dplyr::filter(n < frame) |> # フレーム番号以前のデータを抽出 dplyr::mutate( x_1 = x_nd[n, 1], # x軸の値 x_2 = x_nd[n, 2], # y軸の値 param = unique(anime_predict_df[["param"]])[frame+1] # フレーム切替用ラベル ) anime_alldata_df
## # A tibble: 4,950 × 5 ## frame n x_1 x_2 param ## <int> <int> <dbl> <dbl> <fct> ## 1 2 1 29.5 62.7 N=2, mu_s=(12.1, 51.7), lambda_s=(0.00077, 0.00019, … ## 2 3 1 29.5 62.7 N=3, mu_s=(10.5, 49.1), lambda_s=(0.00086, 0.00021, … ## 3 3 2 -4.76 42.7 N=3, mu_s=(10.5, 49.1), lambda_s=(0.00086, 0.00021, … ## 4 4 1 29.5 62.7 N=4, mu_s=(16.5, 58.3), lambda_s=(0.00092, 0.00023, … ## 5 4 2 -4.76 42.7 N=4, mu_s=(16.5, 58.3), lambda_s=(0.00092, 0.00023, … ## 6 4 3 7.33 43.8 N=4, mu_s=(16.5, 58.3), lambda_s=(0.00092, 0.00023, … ## 7 5 1 29.5 62.7 N=5, mu_s=(19.7, 54.1), lambda_s=(0.00096, 0.00024, … ## 8 5 2 -4.76 42.7 N=5, mu_s=(19.7, 54.1), lambda_s=(0.00096, 0.00024, … ## 9 5 3 7.33 43.8 N=5, mu_s=(19.7, 54.1), lambda_s=(0.00096, 0.00024, … ## 10 5 4 34.8 86.1 N=5, mu_s=(19.7, 54.1), lambda_s=(0.00096, 0.00024, … ## # … with 4,940 more rows
フレーム番号と試行回数(データ番号)の全ての組み合わせを作成して、フレーム番号未満のデータを抽出します。フレーム切替用のラベルは、フレーム番号を使って抽出します。
各試行以前のデータを描画するのに使うので、フレーム番号が2からになります。
予測分布の推移のアニメーションを作成します。
# 真の分布(多次元ガウス分布)を計算:式(2.72) model_df <- tibble::tibble( x_1 = x_mat[, 1], # x軸の値 x_2 = x_mat[, 2], # y軸の値 dens = mvnfast::dmvn(X = x_mat, mu = mu_truth_d, sigma = sigma_dd) # 確率密度 ) # 予測分布のアニメーションを作図 predict_graph <- ggplot() + geom_contour(data = model_df, aes(x = x_1, y = x_2, z = dens, color = ..level..), alpha = 0.5, linetype = "dashed") + # 真の分布 geom_contour(data = anime_predict_df, aes(x = x_1, y = x_2, z = dens, color = ..level..)) + # 予測分布:(等高線図) #geom_contour_filled(data = anime_predict_df, aes(x = x_1, y = x_2, z = dens, fill = ..level..), alpha = 0.8) + # 予測分布:(塗りつぶし等高線図) geom_point(data = anime_alldata_df, aes(x = x_1, y = x_2), color = "orange", alpha = 0.5) + # 過去の観測データ geom_point(data = anime_data_df, aes(x = x_1, y = x_2), color = "orange", size = 3) + # 観測データ gganimate::transition_manual(param) + # フレーム labs(title = "Multivariate Gaussian Distribution", subtitle = "{current_frame}", color = "density", fill = "density", x = expression(x[1]), y = expression(x[2])) # gif画像を作成 gganimate::animate(predict_graph, nframes = N+1+10, end_pause = 10, fps = 10, width = 800, height = 600)
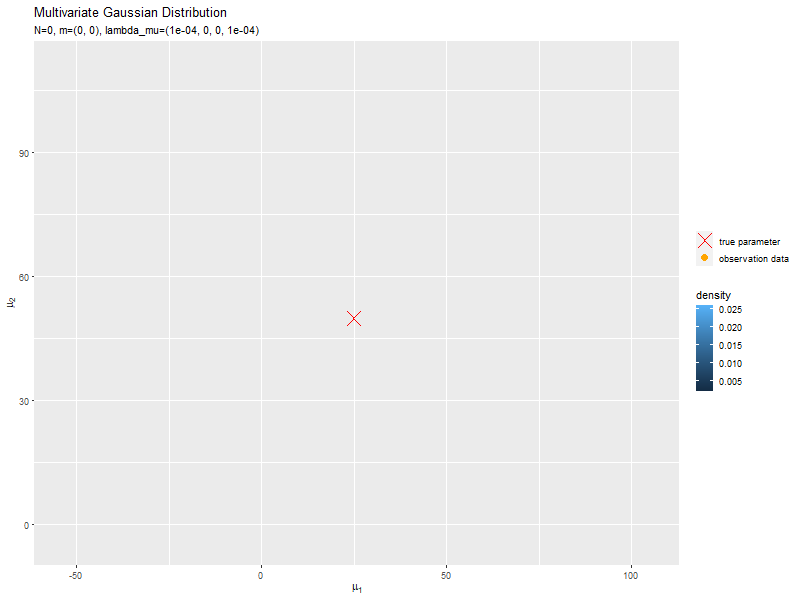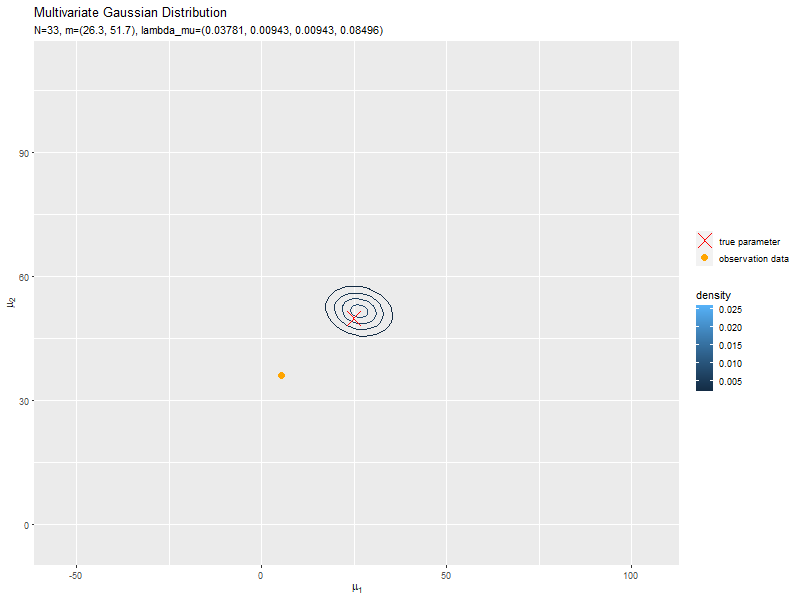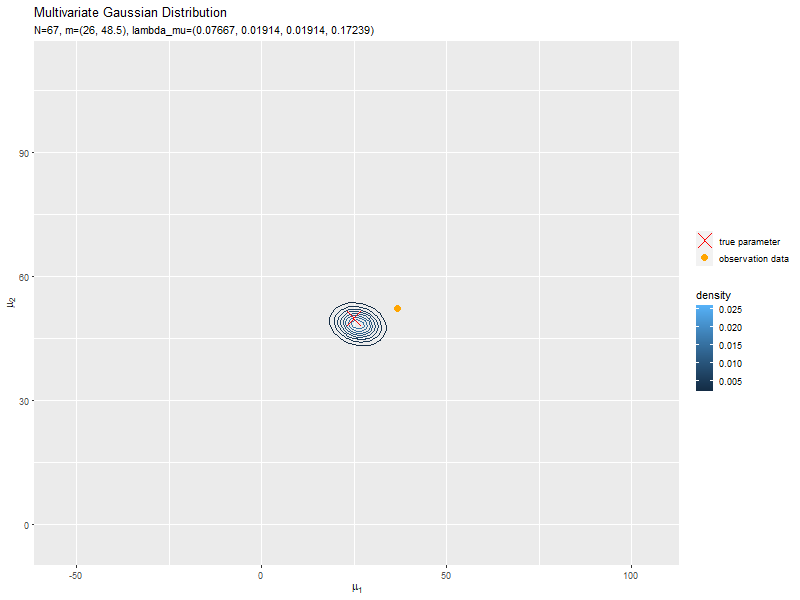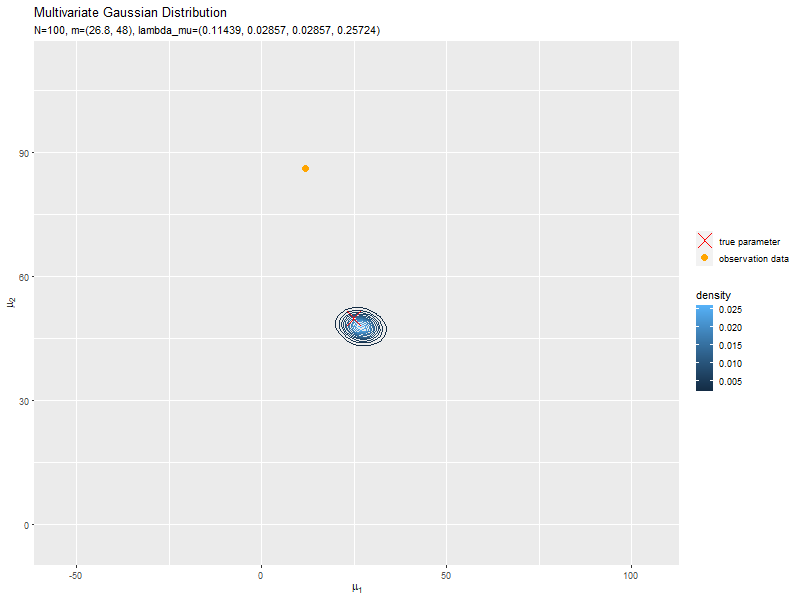
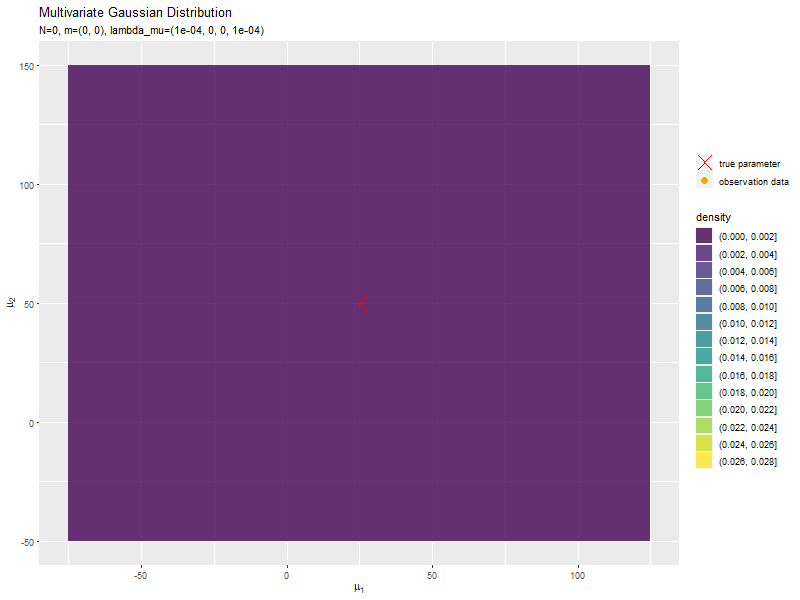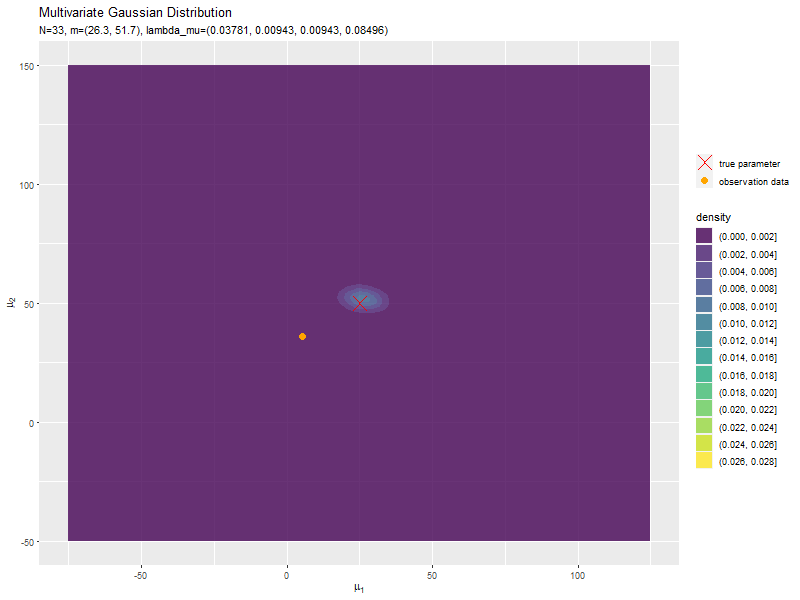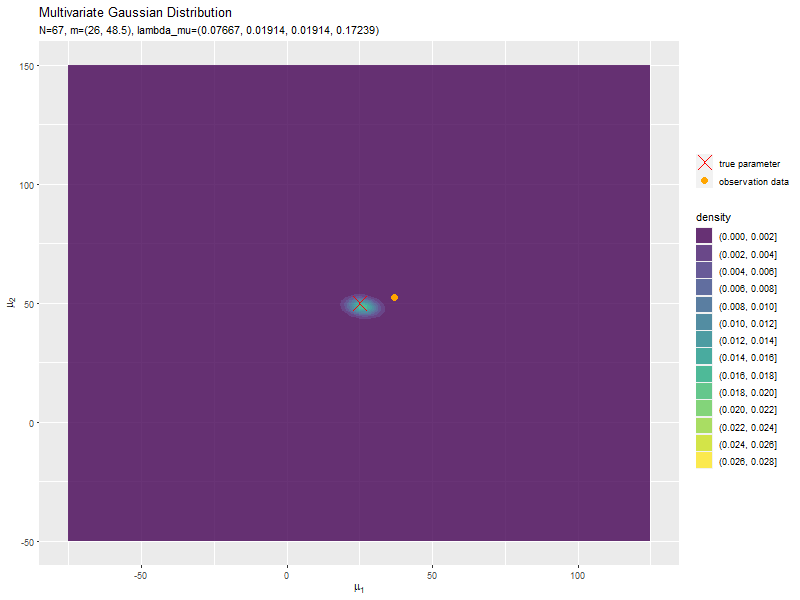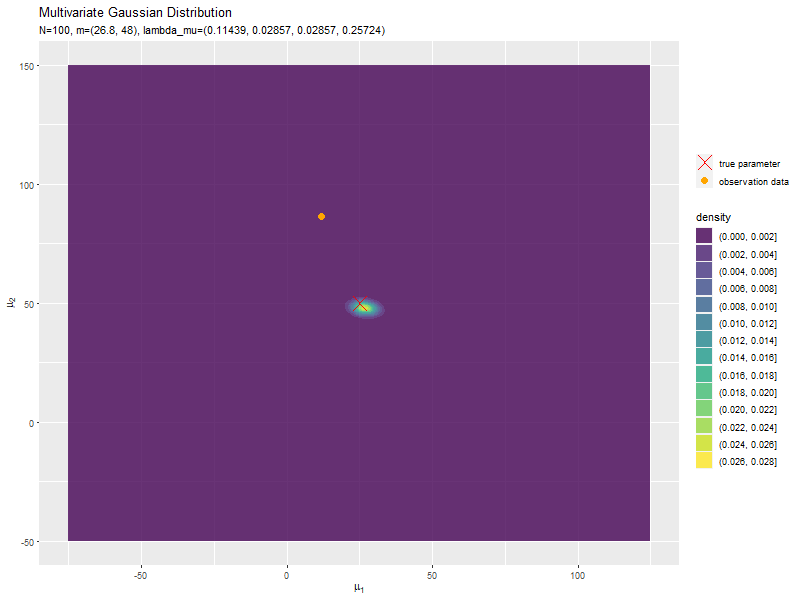
データが増えるにつれて、真のパラメータ付近の確率密度が大きくなっていくのを確認できます。
始めの頃は、分散が大きく確率密度が小さいため、等高線が描画されていません。
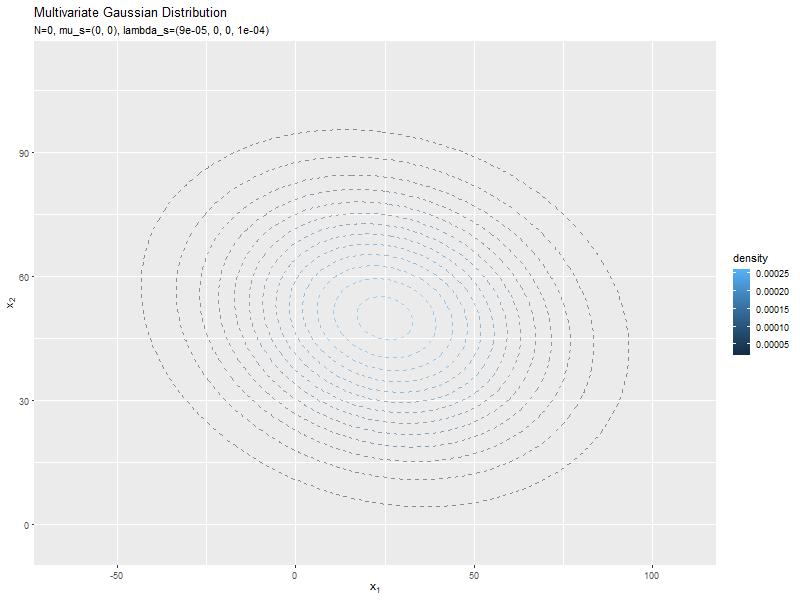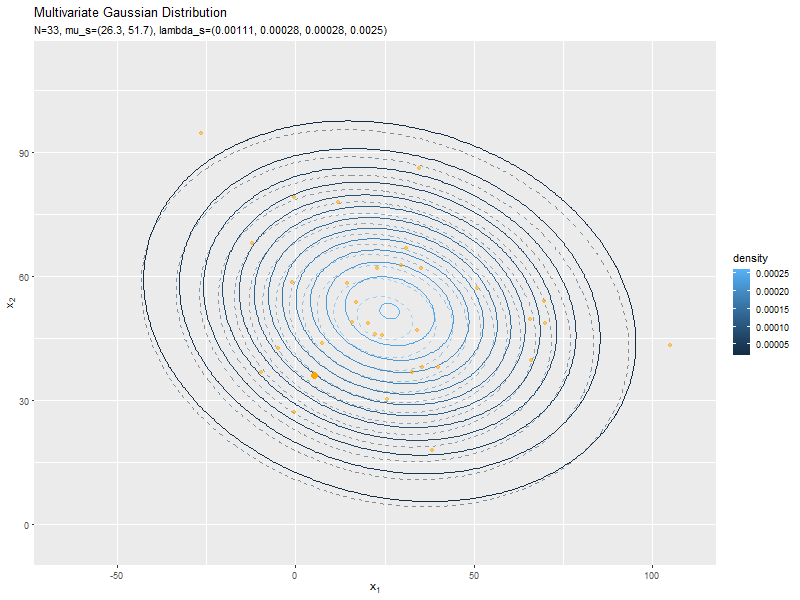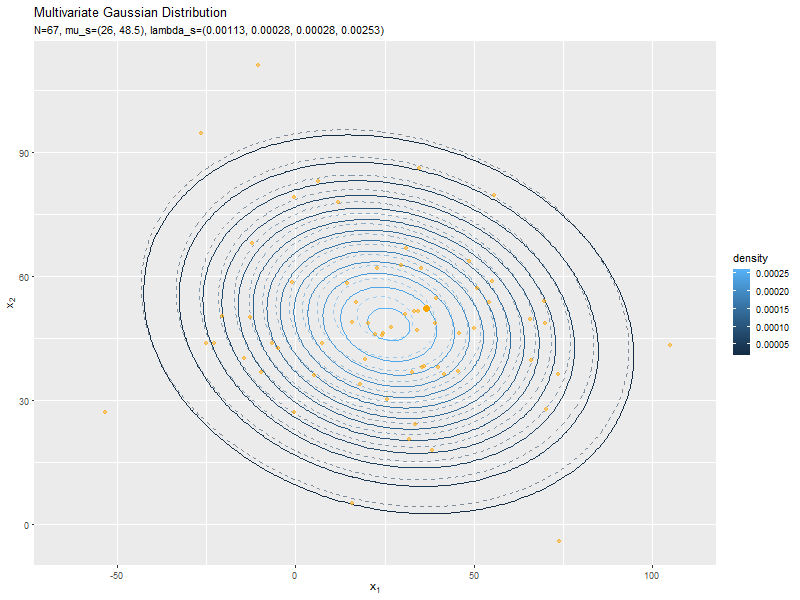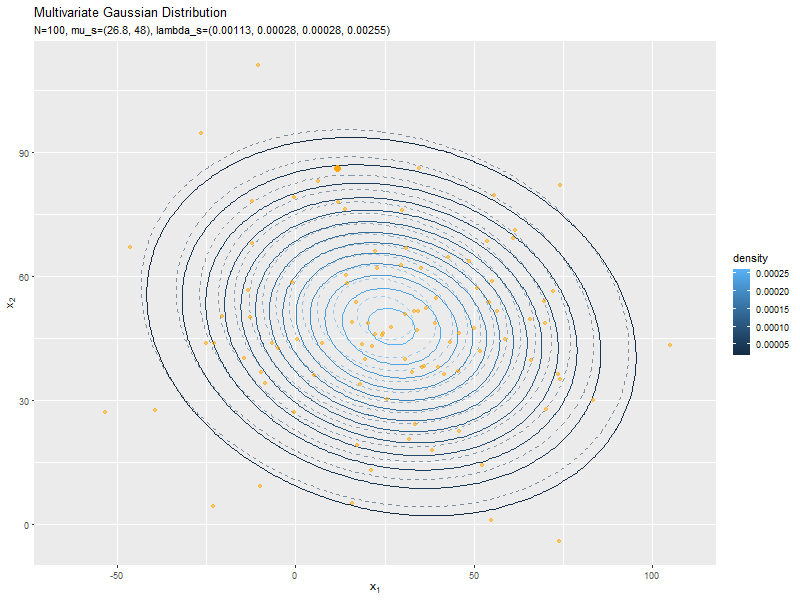
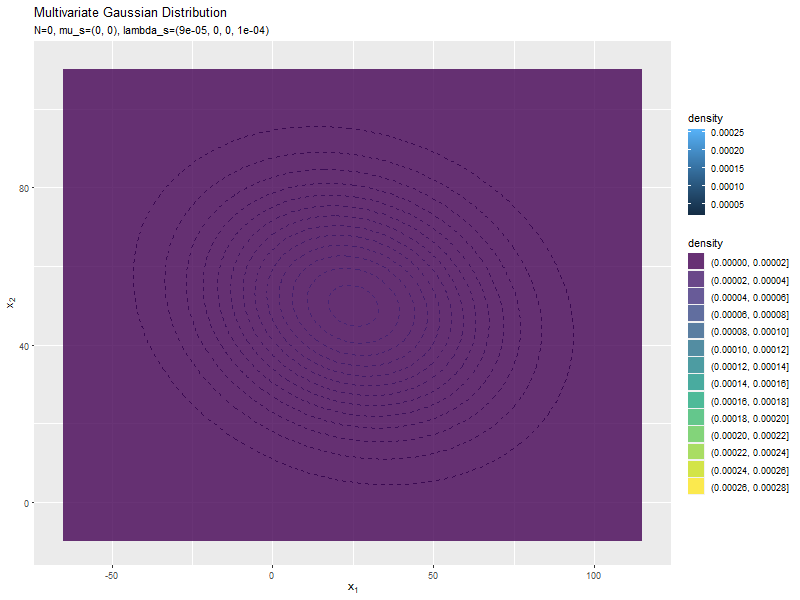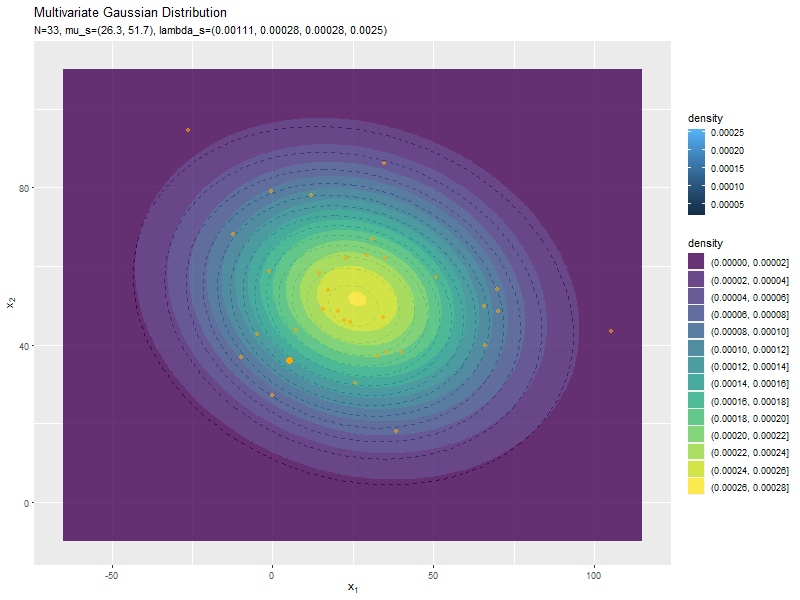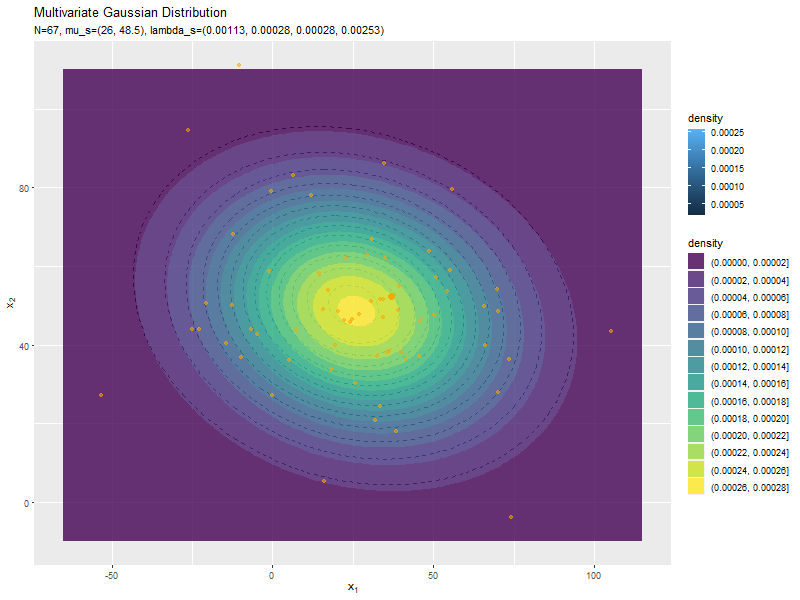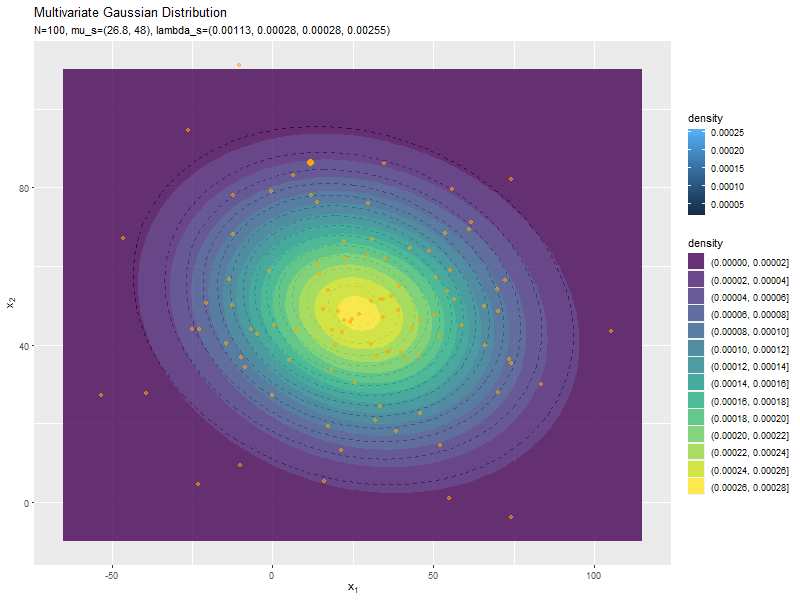
新たなデータによって平均(分布の中心)が推移しているのを確認できます。
参考文献
- 須山敦志『ベイズ推論による機械学習入門』(機械学習スタートアップシリーズ)杉山将監修,講談社,2017年.
おわりに
その時々では理解したつもりで記事にしているのですが、勉強を続けていると勘違いしていたことに気付くことも多々あります。適宜修正していきたいですけど結構大変。独学あるある?
- 2021/04/10:加筆修正しました。その際に数式読解編と記事を分割しました。
- 2022/09/20:加筆修正しました。
多次元編でもfor()からtidyverseの関数に置き換えられそうで良かったです。推移の可視化の方で自分でもよく分からない処理をしていますがまぁ。
【次の節の内容】